
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 XPath(XML Path Language)是一种用于在XML文档中导航和查询数据的查询语言。它是W3C(World Wide Web Consortium)定义的标准,常用于从XML文档中提取信息,特别是在Web开发和数据抓取领域。XPath提供了一种结构化的方式来定位和访问XML文档中的元素和属性。

在学习本教程之前,您需要具备八爪鱼基础操作和XPath相关知识,如果还未掌握,请先学习以下课程。 自定义模式入门:https://www.bazhuayu.com/tutorial8/xsrm/81zdyrm XPath 系统学习与实例:https://www.bazhuayu.com/tutorial8/81xpath 一、相对XPath 相对Xpath,即相对于循环框的Xpath,有两个典型特征:跟随循环联动;与循环框的XPath合并成一条完整的定位XPath。 有两种常见应用场景:提取循环内的数据;提取循…
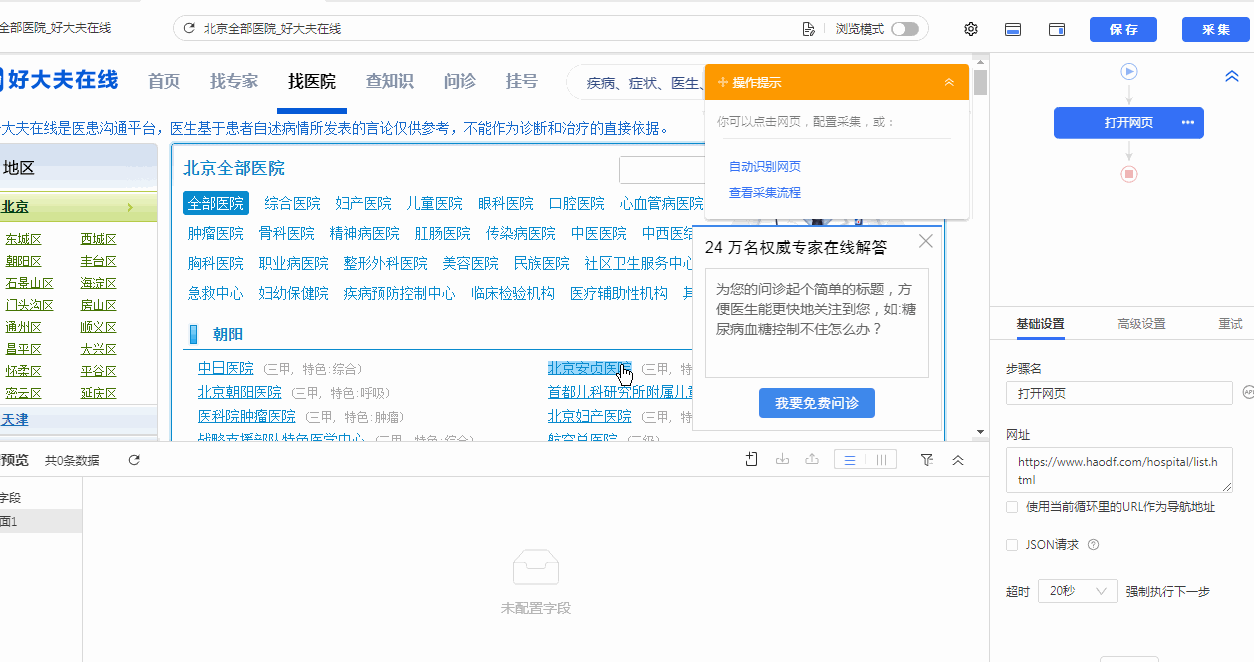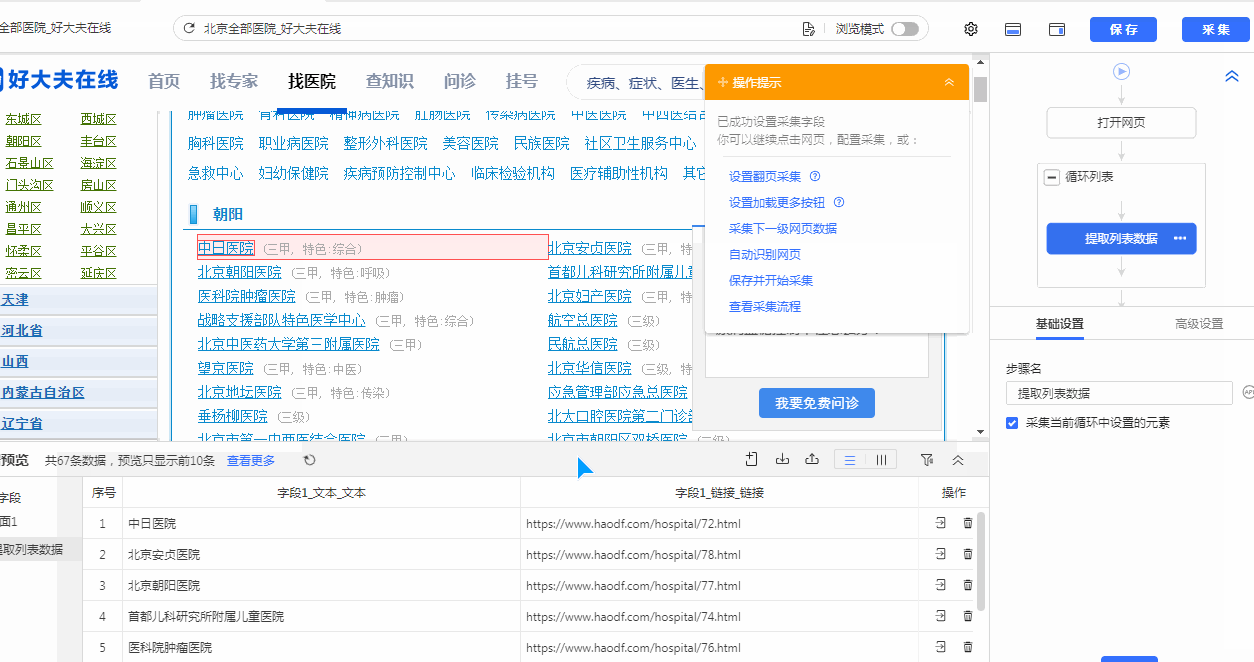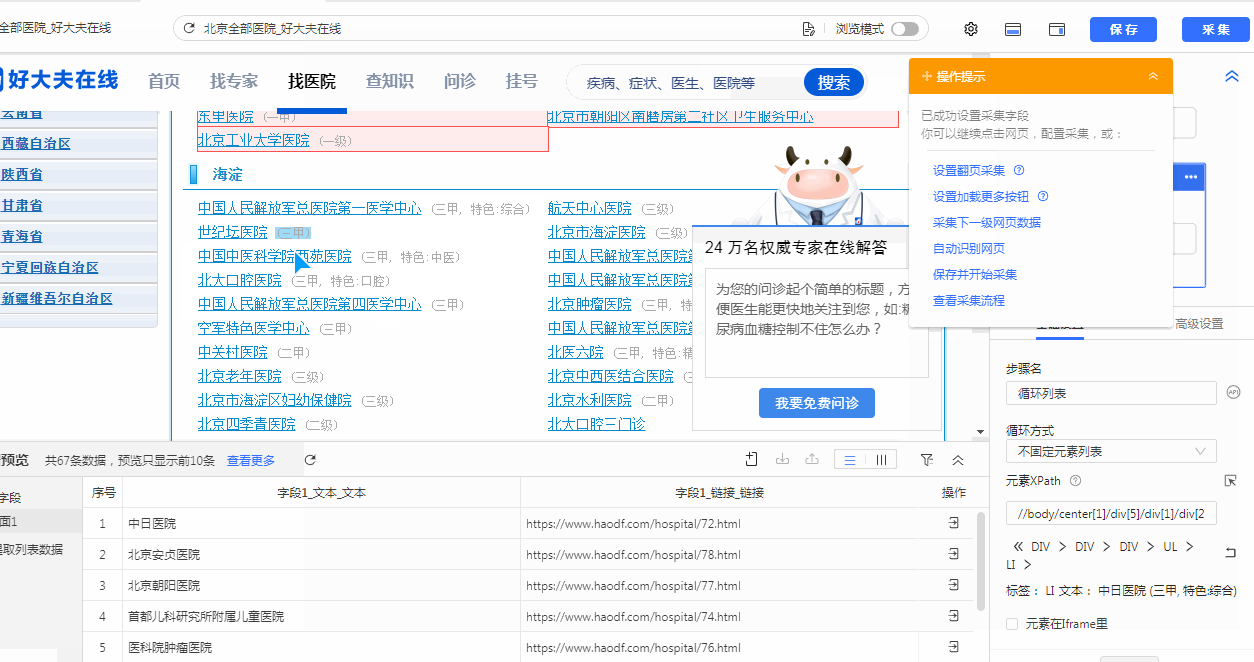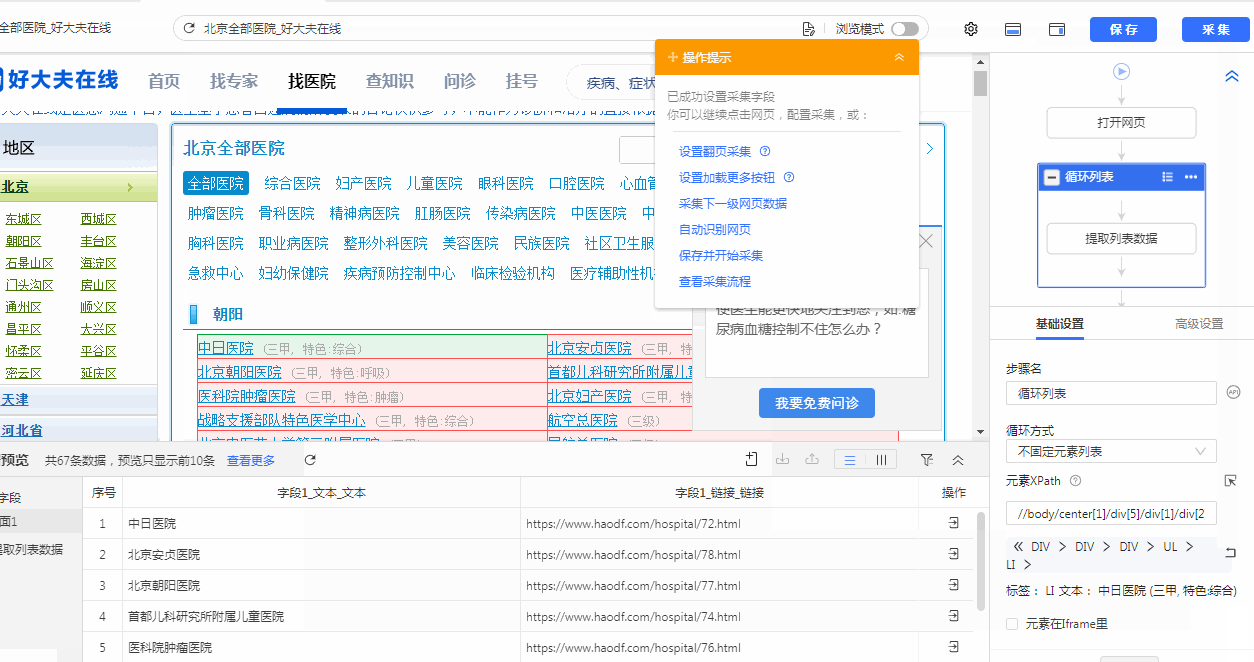
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。 一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。 但有时候我们点击了列表页某一项数据之后,点击“选中全部”,但是循环定位到的数据并没有包含咱们要的所有数据项,这个时候可以通过手动修改xpath,让循环定位到咱们所有需要的数据, 这就是我们本节课所要讲的内容。 实例网址:https://www.haodf.com/hospital/list.html 基础操作:…
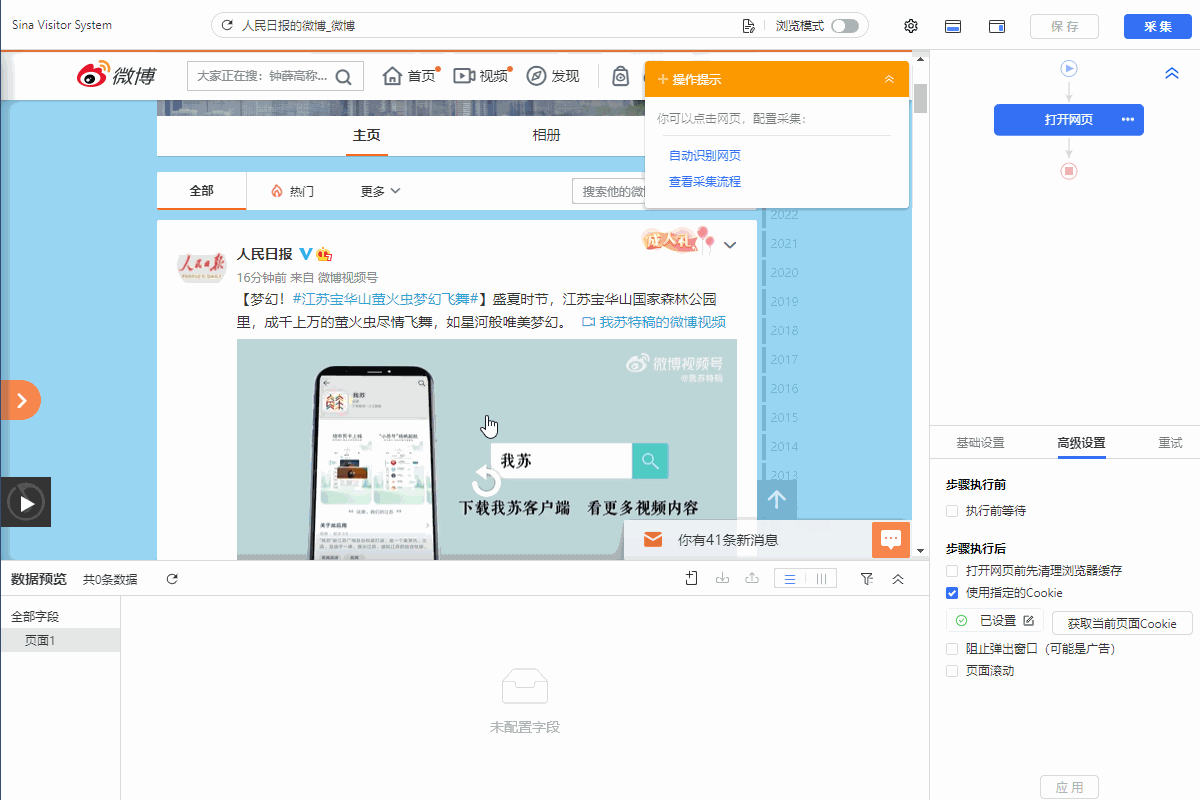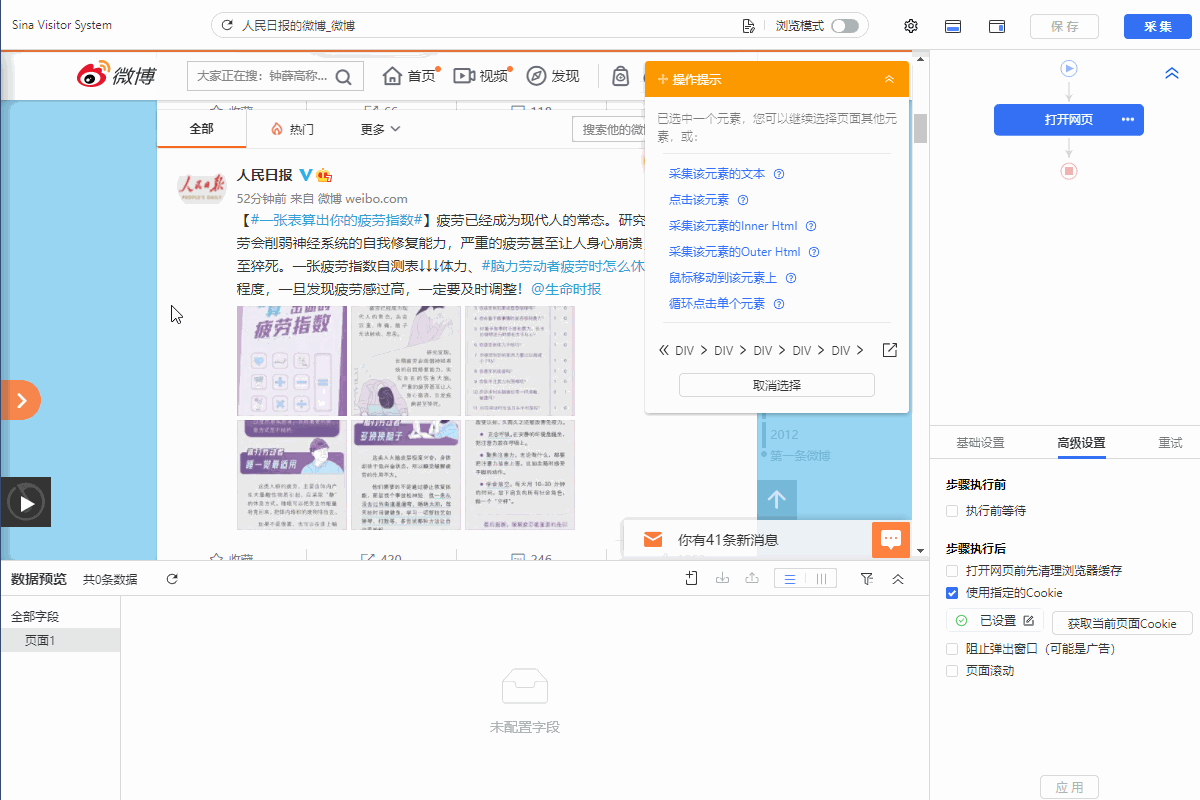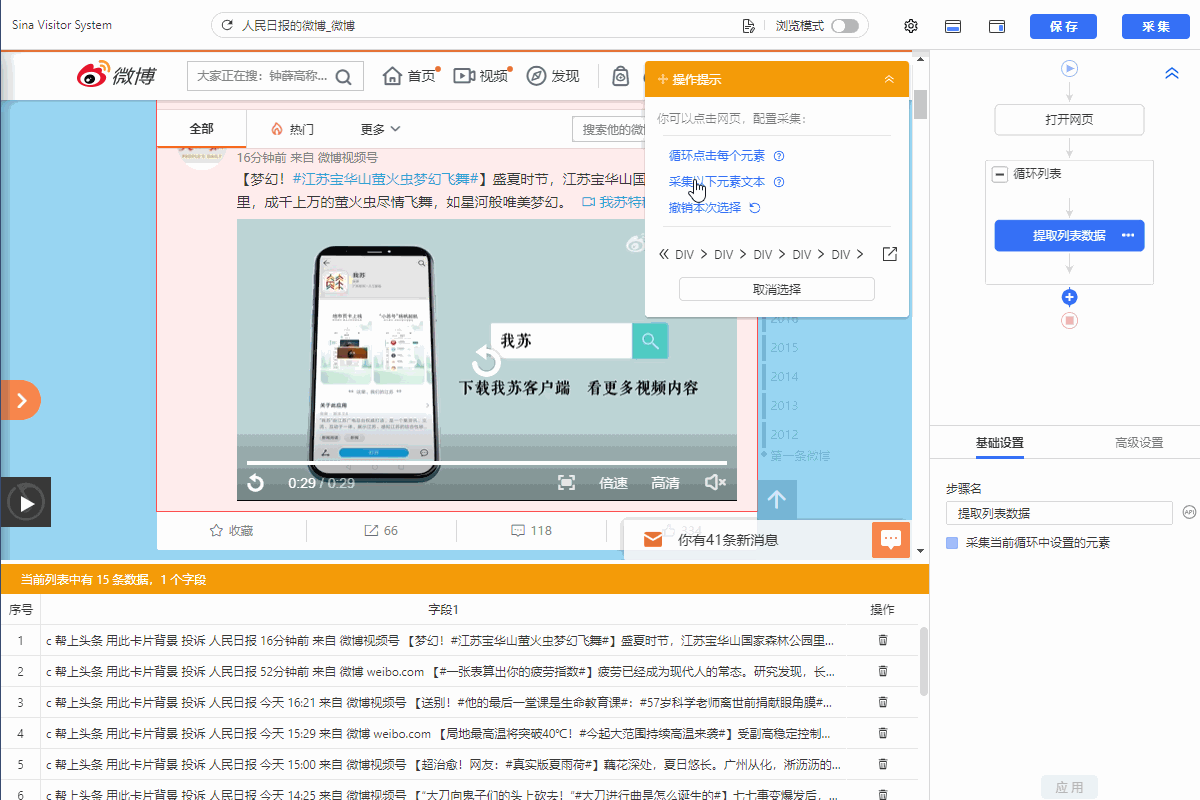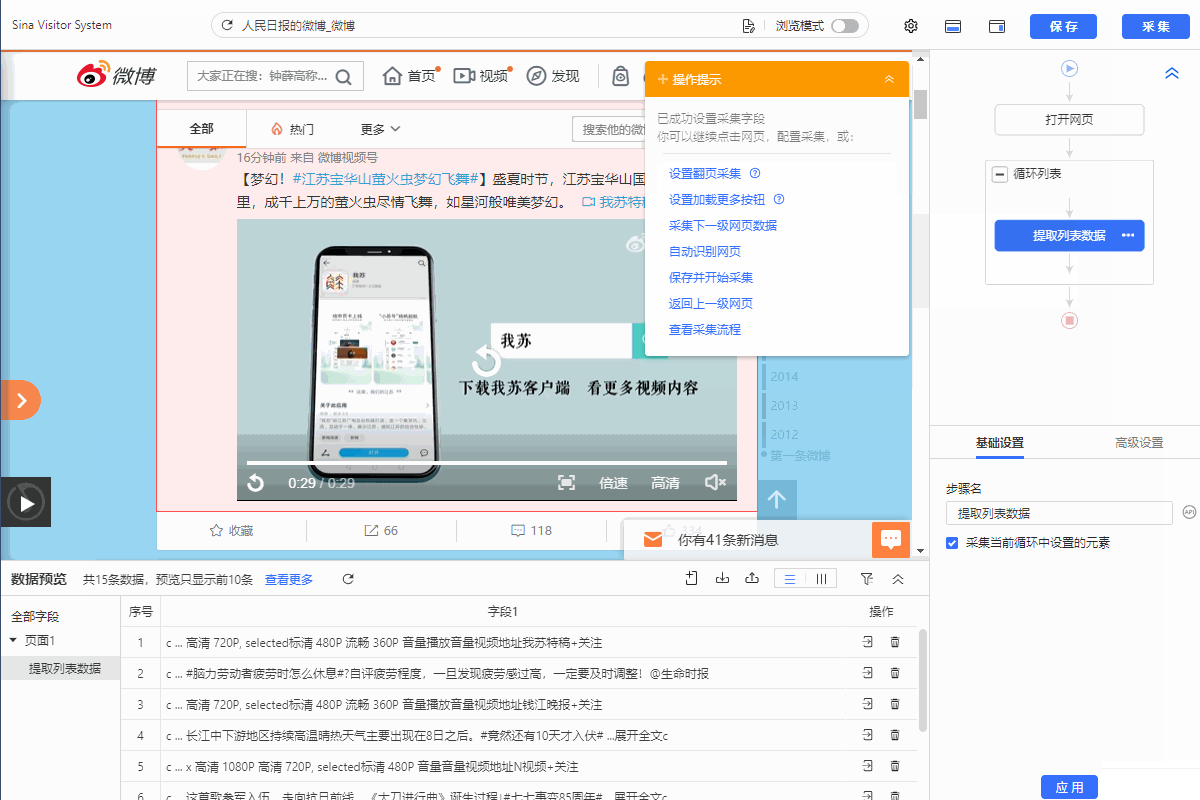
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。 一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。但有时候也会遇到一些问题:比如列表中有的部分不是我们想要的,需要进行丢弃。 这时候,可以手动修改XPath去定位列表丢弃不需要的部分。也可以用分支判断丢弃。 以下通过实例进行说明。 实例网址:https://weibo.com/2803301701?refer_flag=1001030103_ 一…

我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。 一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到我们想要的全部数据。但有时候也会遇到一些问题:比如滚动后加载出100个列表,为什么只采集到20个?有一些列表并不是我们需要的,如何将其排除掉? 页面本来有30条列表,为什么却只能采集到10条? 这时候,就需要手动修改XPath去精准定位列表。 以下通过实例进行说明。 实例网址:https://www.made-in-chi…
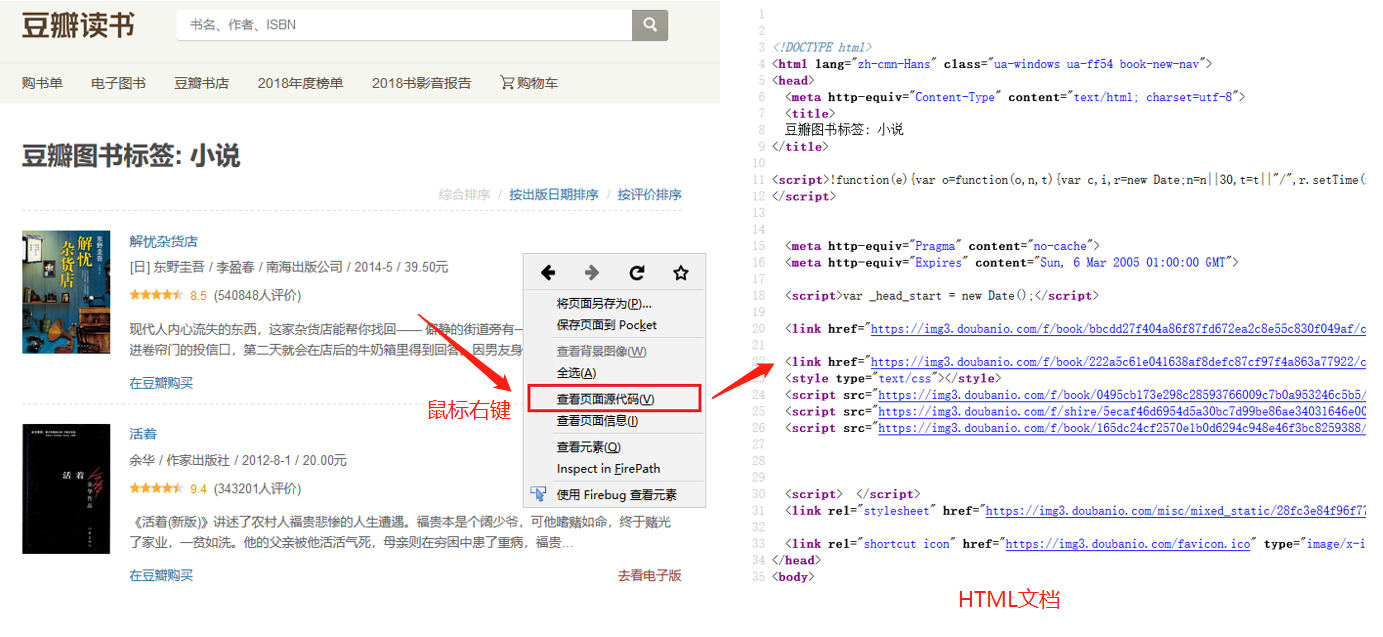
XPath对于八爪鱼数据采集十分重要。绝大多数的数据采集问题,都可以通过写一条正确的XPath解决。 本课将详细讲解XPath相关的问题。 一、HTML 与 XPath 我们日常浏览的网页本质上都是一个个HTML文档。打开网页后,鼠标右键打开菜单,选择【查看网页源代码】,就能看到该网站的HTML文档。网页上的数据,在其HTML文档中都有一个对应位置。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 如何在HTML文档中找到想要的数据?XPath是最常用的语言…
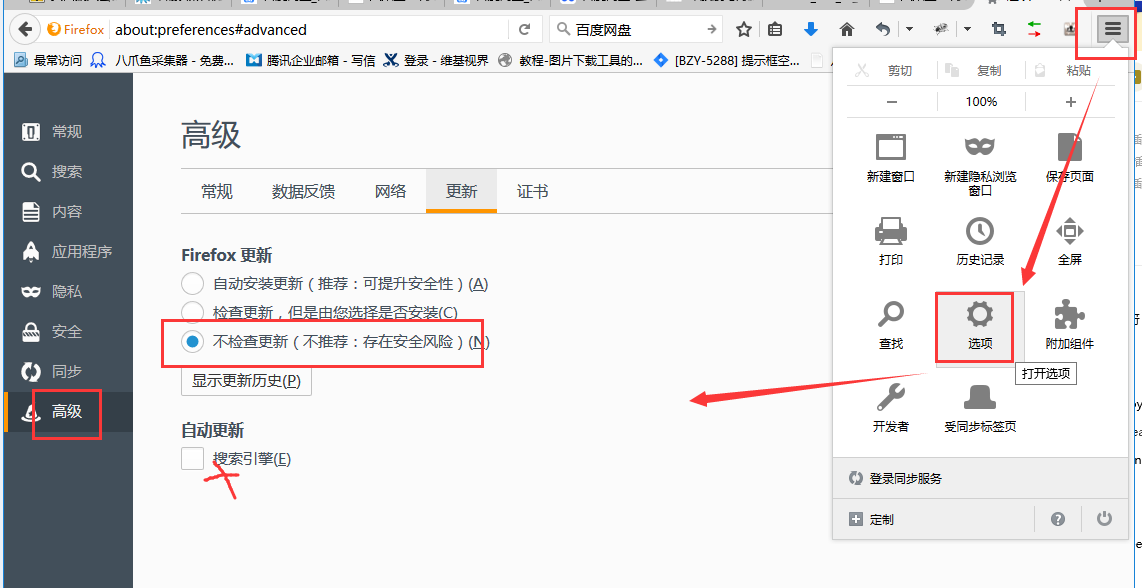
火狐浏览器firebug和firepath插件安装方法(最新)。以下为具体步骤。 第1步:下载火狐55以内版本安装包,安装时迅速设置禁止自动更新版本,取消勾选自动更新(目的是防止火狐浏览器自动升级) 54版本火狐浏览器的下载地址:64位火狐54:http://ftp.mozilla.org/pub/firefox/releases/54.0.1/win64/zh-CN/ 32位火狐54:http://ftp.mozilla.org/pub/firefox/releases/54.0.1/win32/zh-C…
