作者:巴德博·贝洛 软件工程师 作者选择了免费和开源基金作为“为捐赠而写”计划的一部分来接受捐赠。 介绍 网页抓取是从网络自动收集数据的过程。该过程通常会部署一个“爬网程序”,该爬虫会自动上网并从所选页面抓取数据。您可能想要抓取数据的原因有很多。首先,它通过消除手动数据收集过程使数据收集速度更快。当需要或需要数据收集但网站不提供 API 时,抓取也是一种解决方案。 在本教程中,您将使用 Node.js 和 Puppeteer 构建一个 Web 抓取应用程序。随着您的进步,您的应用将变得越来越复杂。首先,您将编写应用…

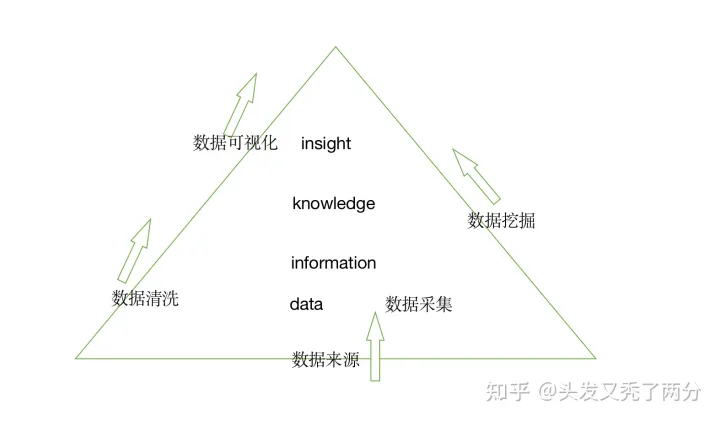
如何进行数据采集以及数据分析? 让我们先从数据采集说起~ 下图是一个完整的数据分析过程: 一个完整的数据分析过程 数据采集: 首先,我们先对数据采集的方式进行一个简单的分类介绍。 接下来,我们分别介绍每一种数据采集形式,其中需要注意的要点。 1. 按数据采集方式 1.1 线下(问卷、实地调研)——注意要点:遵循5大要素! 5个要素: 1)主题和目的 在设计问卷之前你就要很清晰你设计这个问卷的目的和主题,才能很好的设计里面的问题,达到你想要的效果,而且我们开展问卷调查的本质目的也是调查相关要素和调研群体背后千丝万缕的…
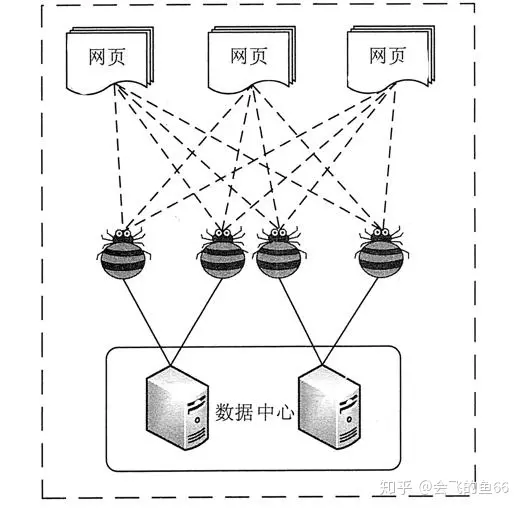
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。 在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。 在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。目前已经知道的各种网络爬虫工具已经有上百个,网络爬虫工具基本可以分为 3 类。 分布式网络爬虫工具,如 Nutch。 Java 网络爬虫工具,如 Crawler4…
爬虫入门系列教程: python爬虫入门教程(一):开始爬虫前的准备工作 python爬虫入门教程(二):开始一个简单的爬虫 python爬虫入门教程(三):淘女郎爬虫 ( 接口解析 | 图片下载 ) 等待更新… 上一篇讲了开始爬虫前的准备工作。当我们完成开发环境的安装、IDE的配置之后,就可以开始开发爬虫了。 这一篇,我们开始写一个超级简单的爬虫。 1.爬虫的过程分析 当人类去访问一个网页时,是如何进行的? ①打开浏览器,输入要访问的网址,发起请求。 ②等待服务器返回数据,通过浏览器加载网页。 ③从网页中找…
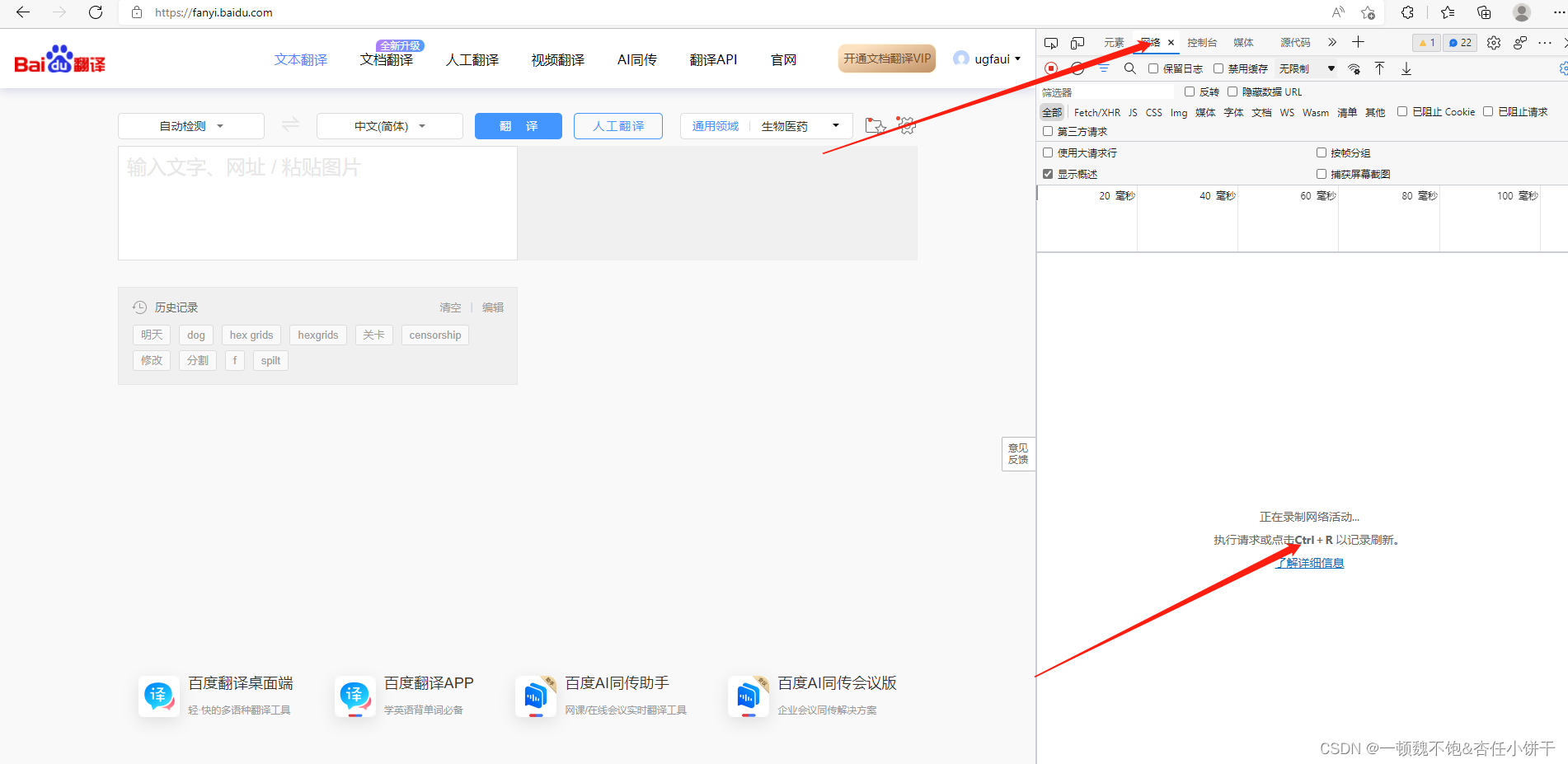
关于爬虫是什么,怎样保证爬虫的合法性小编在这就不再过多的阐述,从本章起,小编将和大家一起分享在学习python爬虫中的所学,希望可以和大家一起进步,也希望各位可以关注一下我!首先我们来初步了解下如何使用开发者工具进行抓包。以 https://fanyi.baidu.com/ 为例。在网页界面右键点击检查,或使用CTRL+SHIFT+I打开。如图打开了开发者工具后我们点击网络得到如上界面。接着按照提示按CTRL+R进行刷新。刷新后如下图所示:此时我们即可看到我们获取到了很多很多的数据包,但是想要完成一个爬虫程序的第一…

这是一篇详细介绍 Python 爬虫入门的教程,从实战出发,适合初学者。读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫。这篇 Python 爬虫教程主要讲解以下 5 部分内容: 了解网页; 使用 requests 库抓取网站数据; 使用 Beautiful Soup 解析网页; 清洗和组织数据; 爬虫攻防战; 了解网页 以中国旅游网首页(http://www.cntour.cn/)为例,抓取中国旅游网首页首条信息(标题和链接),数据以明文的形式出面在源码中。在中…

爬虫一直是一种有效的数据采集方式,但从技术层面来说,它并不是一种完全符合规则的技术,根据国内现有的法律和司法实践,它有可能违反了以下几个方面的法律规定。 一、反不公平竞争法维度 如果没有得到被爬行者的许可,那么就会破坏 Robots的规则。Robots是一种由机器人编程实现的,它是一种由机器人和被爬行者在攀爬过程中进行交流的方法。十二个公司于2012年11月1号联合发布了《互联网搜索引擎服务自律公约》,该公约规定所有的公司必须严格按照 Robots的规则行事。 在实际操作中, Robots协定虽然不在12个公司的管…

全公司上下仅有1个人,每年竟能赚上1400多万美元(1亿多元)。 这并不是什么天方夜谭,而是现实生活中上演的真人真事。 故事的主人公叫做Gary Brewer(简称“盖哥”),而他之所以能如此猛猛吸金,靠的就是自己创办的网站BuiltWith。 这个网站也是比较神奇,它主要做的一件事,就是专扒别人家网站用了哪些技术。 很多小伙伴肯定要感慨了:“这也行???” 对,是真行,而且人家盖哥的网站现在每月的浏览量都达到200万了…… 靠扒技术赚钱 咱们打开盖哥的网站后,明晃晃的几个大字便会映入眼帘: 发现网站是采用什么技术…

就在前段时间,一项由卫健委发起的脱发人群调查数据显示:中国受脱发问题困扰的人群高达2.5亿。听到这儿,远在韩国的各家媒体又开始出来搞事情了。 根据他们的计算,这些人完全脱发时的总脱发面积大约可达5900平方公里,相当于首尔市面积(605平方公里)的十倍,那么今天小编就以一个数据分析师的身份来为这些人群出出主意,挑几款相对合适的防脱发洗发水给他们来使用。 1. 聊聊脱发困扰 脱发其实分为很多种情况,如脂溢性脱发,表现为头屑增多、头皮痛痒、头发油脂分泌旺盛。还有营养性脱发,当饮食作息不规律时,脱发情况就会愈发地严重,以…
