
作者:巴德博·贝洛
软件工程师
作者选择了免费和开源基金作为“为捐赠而写”计划的一部分来接受捐赠。
介绍
网页抓取是从网络自动收集数据的过程。该过程通常会部署一个“爬网程序”,该爬虫会自动上网并从所选页面抓取数据。您可能想要抓取数据的原因有很多。首先,它通过消除手动数据收集过程使数据收集速度更快。当需要或需要数据收集但网站不提供 API 时,抓取也是一种解决方案。
在本教程中,您将使用 Node.js 和 Puppeteer 构建一个 Web 抓取应用程序。随着您的进步,您的应用将变得越来越复杂。首先,您将编写应用程序代码以打开 Chromium 并加载一个设计为网络抓取沙箱的特殊网站:books.toscrape.com。在接下来的两个步骤中,您将在 books.toscrape 的单页上抓取所有书籍,然后在多个页面上抓取所有书籍。在其余步骤中,您将按书籍类别过滤抓取,然后将数据另存为 JSON 文件。
警告:网络抓取的道德和合法性非常复杂且不断发展。它们还根据您的位置、数据的位置和相关网站而有所不同。本教程抓取了一个特殊的网站 books.toscrape.com,该网站专门用于测试刮板应用程序。抓取任何其他域不在本教程的讨论范围之内。
先决条件
- 节点.js安装在开发计算机上。本教程在 Node.js 版本 12.18.3 和 npm 版本 6.14.6 上进行了测试。您可以按照本指南在 macOS 或 Ubuntu 18.04 上安装 Node.js,也可以按照本指南使用 PPA 在 Ubuntu 18.04 上安装 Node.js。
第 1 步 — 设置网络抓取工具
安装 Node.js 后,您可以开始设置网络抓取工具。首先,您将创建一个项目根目录,然后安装所需的依赖项。本教程只需要一个依赖项,您将使用 Node.js 的默认包管理器 npm 安装它。npm 预装了 Node.js,所以你不需要安装它。
为此项目创建一个文件夹,然后在其中移动:
复制
您将从此目录运行所有后续命令。
我们需要使用 npm 或节点包管理器安装一个包。首先初始化 npm 以创建一个文件,该文件将管理项目的依赖项和元数据。packages.json
初始化项目的 npm:
复制
npm 将显示一系列提示。您可以按每个提示,也可以添加个性化描述。确保在提示输入 和 时按住默认值并将其保留在原位。或者,您可以将标志传递给 ——,它将为您提交所有默认值。ENTERENTERentry point:test command:ynpmnpm init -y
您的输出将如下所示:
Output{
"name": "sammy_scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "sammy the shark",
"license": "ISC"
}
Is this OK? (yes) yes
键入并按 。npm 会将此输出另存为文件。yesENTERpackage.json
现在使用 npm 安装 Puppeteer:
复制
此命令将安装 Puppeteer 和 Puppeteer 团队知道将与其 API 配合使用的 Chromium 版本。
在 Linux 计算机上,Puppeteer 可能需要一些额外的依赖项。
如果您使用的是 Ubuntu 18.04,请查看 Puppeteer 故障排除文档的“Chrome headless 无法在 UNIX 上启动”部分中的“Debian 依赖项”下拉列表。您可以使用以下命令来帮助查找任何缺少的依赖项:
复制
安装 npm、Puppeteer 和任何其他依赖项后,文件在开始编码之前需要进行最后一次配置。在本教程中,您将使用 .您必须将有关此脚本的一些信息添加到 中。具体来说,您必须在有关命令的指令下添加一行。package.jsonnpm run startstartpackage.jsonscriptsstart
在首选文本编辑器中打开文件:
复制
找到该部分并添加以下配置。请记住在脚本行的末尾放置一个逗号,否则您的文件将无法正确解析。scripts:test
Output{
. . .
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
. . .
"dependencies": {
"puppeteer": "^5.2.1"
}
}
您还会注意到它现在出现在文件末尾附近。您的文件将不再需要任何修订。保存更改并关闭编辑器。puppeteerdependenciespackage.json
您现在可以开始对抓取工具进行编码了。在下一步中,您将设置一个浏览器实例并测试抓取工具的基本功能。
步骤 2 — 设置浏览器实例
打开传统浏览器时,可以执行单击按钮、使用鼠标导航、键入、打开开发工具等操作。像 Chromium 这样的无头浏览器允许您执行相同的操作,但以编程方式执行,并且没有用户界面。在此步骤中,您将设置爬虫的浏览器实例。当您启动应用程序时,它将自动打开 Chromium 并导航到 books.toscrape.com。这些初始操作将构成您的计划的基础。
您的网络爬虫将需要四个文件:、 、 和 。在此步骤中,您将创建所有四个文件,然后随着程序的复杂程度不断更新它们。入手;此文件将包含启动浏览器的脚本。.jsbrowser.jsindex,jspageController.jspageScraper.jsbrowser.js
在项目的根目录中,创建并在文本编辑器中打开:browser.js
复制
首先,您将 Puppeteer,然后创建一个名为 .此函数将启动浏览器并返回浏览器的实例。添加以下代码:requireasyncstartBrowser()
./book-scraper/browser.jsconst puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};
复制
傀儡师有个方法.launch()启动浏览器的实例。此方法返回一个 Promise,因此您必须确保 Promise 通过使用 或 块进行解析.thenawait.
你正在使用 确保 Promise 解析,将这个实例包装起来await代码块try-catch,然后返回浏览器的实例。
请注意,该方法采用具有多个值的 JSON 参数:.launch()
- 无头 - 表示浏览器将与界面一起运行,以便您可以观看脚本的执行,同时意味着浏览器将在无头模式下运行。但是请注意,如果要将爬虫部署到云中,请设置回 .大多数虚拟机都是无外设的,不包含用户界面,因此只能在无外设模式下运行浏览器。Puppeteer 还包括一个模式,但该模式只能用于测试目的。falsetrueheadlesstrueheadful
- ignoreHTTPSErrors - 允许您访问未通过安全 HTTPS 协议托管的网站,并忽略任何与 HTTPS 相关的错误。true
保存并关闭文件。
现在创建您的第二个文件:.jsindex.js
复制
在这里,您将和.然后,您将调用该函数并将创建的浏览器实例传递给我们的页面控制器,该控制器将指导其操作。添加以下代码:requirebrowser.jspageController.jsstartBrowser()
./book-scraper/index.jsconst browserObject = require('./browser');
const scraperController = require('./pageController');
//Start the browser and create a browser instance
let browserInstance = browserObject.startBrowser();
// Pass the browser instance to the scraper controller
scraperController(browserInstance)
复制
保存并关闭文件。
创建第三个文件:.jspageController.js
复制
pageController.js控制您的抓取过程。它使用浏览器实例来控制文件,这是所有抓取脚本执行的地方。最终,您将使用它来指定要抓取的书籍类别。但是,现在,您只想确保可以打开 Chromium 并导航到网页:pageScraper.js
./book-scraper/pageController.jsconst pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
复制
此代码导出一个函数,该函数接受浏览器实例并将其传递给名为 的函数。反过来,此函数将此实例作为参数传递给该参数,该参数使用它来抓取页面。scrapeAll()pageScraper.scraper()
保存并关闭文件。
最后,创建最后一个文件:.jspageScraper.js
复制
在这里,您将创建一个具有属性和方法的对象文本。是要抓取的网页的 Web URL,而该方法包含将执行实际抓取的代码,尽管在此阶段它只是导航到 URL。添加以下代码:urlscraper()urlscraper()
./book-scraper/pageScraper.jsconst scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;
复制
傀儡师有个方法newPage()这会在浏览器中创建一个新的页面实例,这些页面实例可以做很多事情。在我们的方法中,您创建了一个页面实例,然后使用scraper()page.goto()方法导航到 books.toscrape.com 主页。
保存并关闭文件。
程序的文件结构现已完成。项目目录树的第一级将如下所示:
Output.
├── browser.js
├── index.js
├── node_modules
├── package-lock.json
├── package.json
├── pageController.js
└── pageScraper.js
现在运行命令并观察您的爬虫应用程序执行:npm run start
复制
它将自动打开 Chromium 浏览器实例,在浏览器中打开一个新页面,然后导航到 books.toscrape.com。
在此步骤中,您创建了一个 Puppeteer 应用程序,该应用程序打开 Chromium 并加载了虚拟在线书店 books.toscrape.com 的主页。在下一步中,您将抓取该主页上每本书的数据。
步骤 3 — 从单个页面抓取数据
在向抓取应用程序添加更多功能之前,请打开您喜欢的 Web 浏览器并手动导航到要抓取主页的书籍。浏览网站并了解数据的结构。
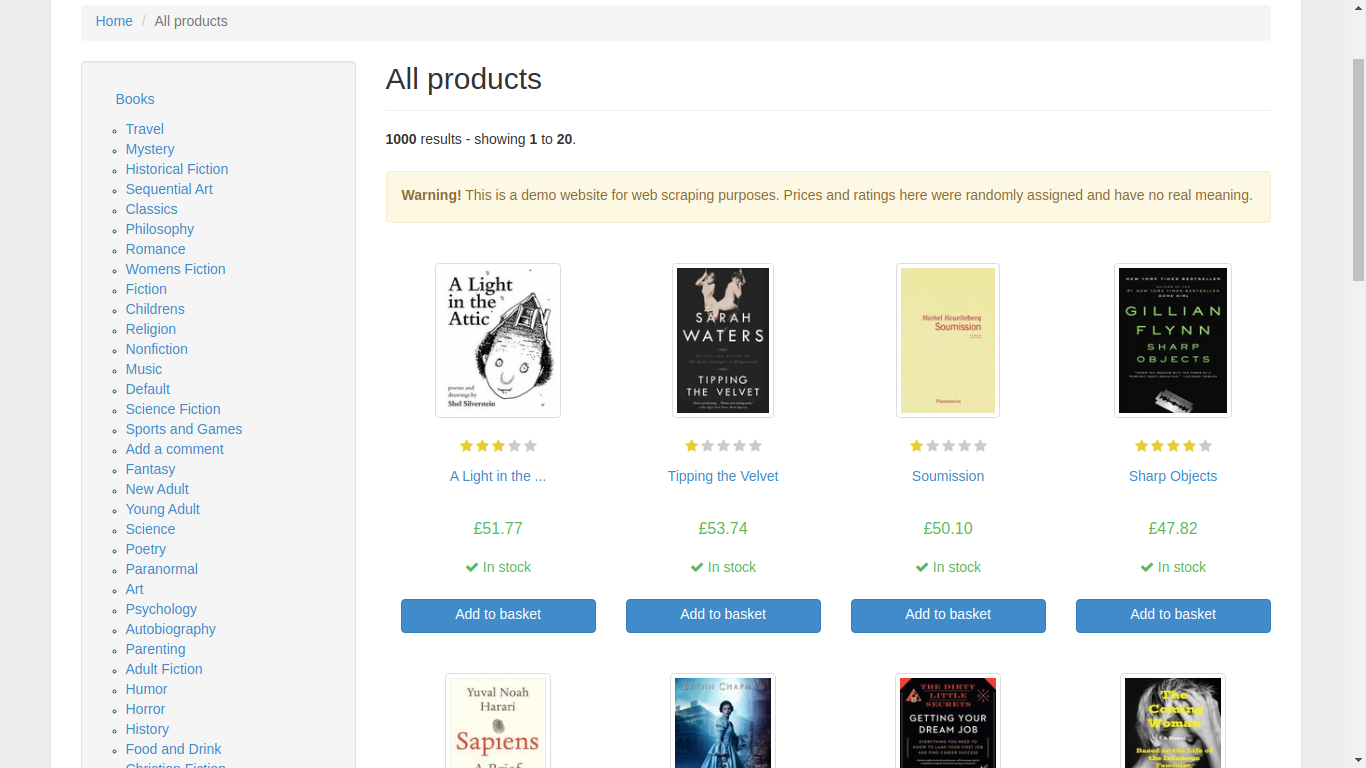
您会在左侧找到一个类别部分,在右侧显示书籍。当您单击一本书时,浏览器会导航到一个新的 URL,该 URL 显示有关该特定书籍的相关信息。
在此步骤中,您将复制此行为,但使用代码;您将自动化浏览网站和使用其数据的业务。
首先,如果您使用浏览器中的开发工具检查主页的源代码,您会注意到该页面在标签下列出了每本书的数据。在标签内,每本书都在 () 标签下,您可以在这里找到指向该书专用页面的链接、价格和库存可用性。sectionsectionlistli
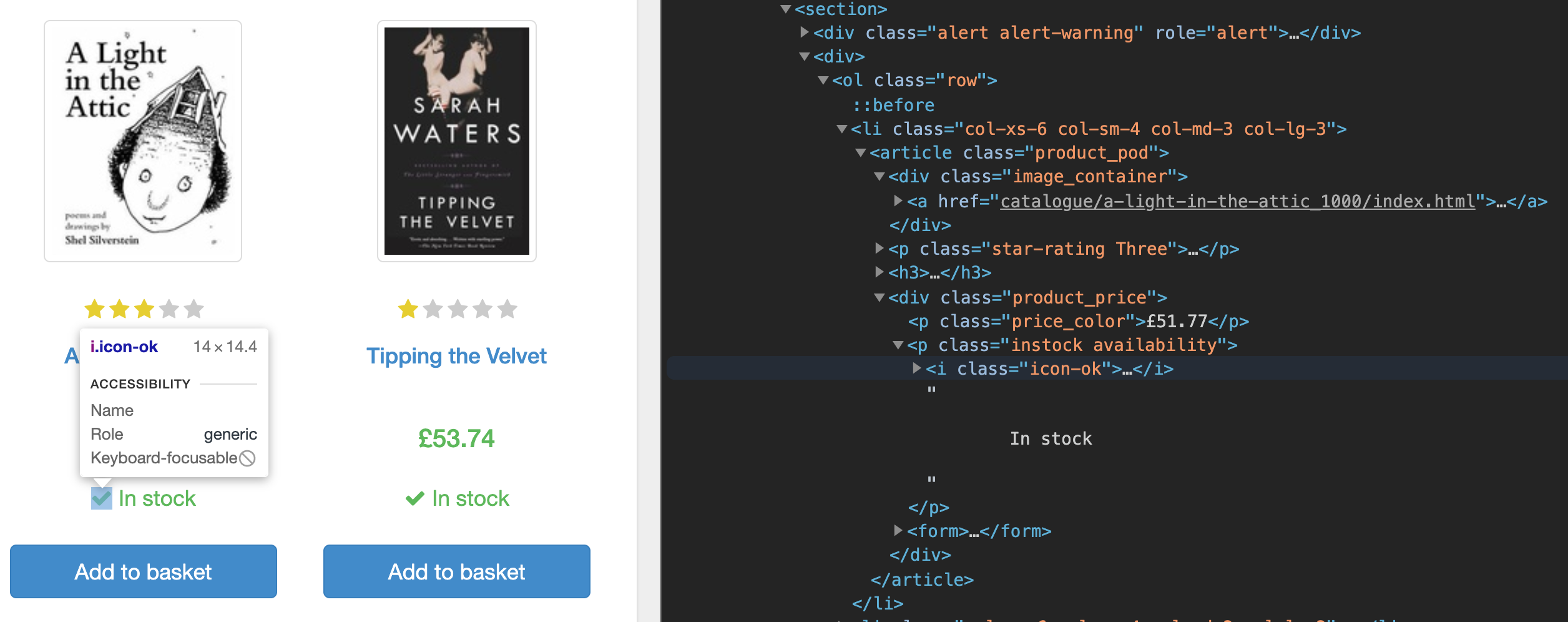
您将抓取这些图书网址,筛选有货的图书,导航到每个单独的图书页面,并抓取该图书的数据。
重新打开您的文件:pageScraper.js
复制
添加以下突出显示的内容。您将在其中嵌套另一个块:awaitawait page.goto(this.url);
./book-scraper/pageScraper.js
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
复制
在此代码块中,您调用了方法page.waitForSelector().这等待包含所有书籍相关信息的 div 在 DOM 中呈现,然后您调用方法page.$$eval().此方法使用选择器获取 URL 元素(确保始终仅从 和 方法返回字符串或数字)。section ol lipage.$eval()page.$$eval()
每本书都有两种状态;一本书要么是 ,要么是 .你只想抓取 .由于返回一个包含所有匹配元素的数组,因此您已经过滤了此数组,以确保您只使用库存图书。您通过搜索和评估类来执行此操作。然后,映射出书籍链接的属性,并从方法中返回它。In StockOut of stockIn Stockpage.$$eval().instock.availabilityhref
保存并关闭文件。
重新运行应用程序:
复制
浏览器将打开,导航到网页,然后在任务完成后关闭。现在检查您的控制台;它将包含所有抓取的 URL:
Output> [email protected] start /Users/sammy/book-scraper
> node index.js
Opening the browser......
Navigating to http://books.toscrape.com...
[
'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
'http://books.toscrape.com/catalogue/soumission_998/index.html',
'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
'http://books.toscrape.com/catalogue/olio_984/index.html',
'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
]
这是一个很好的开始,但您希望抓取特定书籍的所有相关数据,而不仅仅是其 URL。现在,您将使用这些 URL 打开每个页面并抓取图书的标题、作者、价格、可用性、UPC、描述和图像 URL。
重开:pageScraper.js
复制
添加以下代码,该代码将遍历每个抓取的链接,打开一个新的页面实例,然后检索相关数据:
./book-scraper/pageScraper.jsconst scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
// scrapedData.push(currentPageData);
console.log(currentPageData);
}
}
}
module.exports = scraperObject;
复制
您有一个包含所有 URL 的数组。您想要遍历此数组,在新页面中打开 URL,抓取该页面上的数据,关闭该页面,然后为数组中的下一个 URL 打开一个新页面。请注意,您已将此代码包装在 Promise 中。这是因为您希望能够等待循环中的每个操作完成。因此,每个 Promise 都会打开一个新的 URL,直到程序抓取 URL 上的所有数据,然后该页面实例关闭后才会解析。
警告:请注意,您使用循环等待 Promise。任何其他循环就足够了,但请避免使用数组迭代方法(如 )或任何其他使用回调函数的方法遍历 URL 数组。这是因为回调函数必须首先经历回调队列和事件循环,因此,多个页面实例将同时打开。这将给你的记忆带来更大的压力。for-inforEach
仔细看看你的功能。您的抓取工具首先为每个 URL 创建一个新页面,然后您使用该功能将要在新页面上抓取的相关详细信息的选择器定位到。某些文本包含空格、制表符、换行符和其他非字母数字字符,您可以使用正则表达式将其剥离。然后,将此页面中抓取的每条数据的值附加到一个对象并解析该对象。pagePromisepage.$eval()
保存并关闭文件。
再次运行脚本:
复制
浏览器打开主页,然后打开每个书籍页面,并记录每个页面的抓取数据。此输出将打印到您的控制台:
OutputOpening the browser......
Navigating to http://books.toscrape.com...
{
bookTitle: 'A Light in the Attic',
bookPrice: '£51.77',
noAvailable: '22',
imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
upc: 'a897fe39b1053632'
}
{
bookTitle: 'Tipping the Velvet',
bookPrice: '£53.74',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
upc: '90fa61229261140a'
}
{
bookTitle: 'Soumission',
bookPrice: '£50.10',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
bookDescription: 'Dans une France assez proche de la nôtre, [...]',
upc: '6957f44c3847a760'
}
...
在此步骤中,您抓取了 books.toscrape.com 主页上每本书的相关数据,但您可以添加更多功能。例如,每一页书都是分页的;你如何从这些其他页面获得书籍?此外,在网站的左侧,您可以找到书籍类别;如果你不想要所有的书,但你只想要特定类型的书怎么办?现在,您将添加这些功能。
步骤 4 — 从多个页面抓取数据
books.toscrape.com 上分页的页面在其内容下方有一个按钮,而未分页的页面则没有。next
您将使用此按钮来确定页面是否已分页。由于每个页面上的数据都具有相同的结构并具有相同的标记,因此您不会为每个可能的页面编写抓取工具。相反,您将使用递归的做法。
首先,您需要稍微更改代码的结构,以适应递归导航到多个页面。
重开:pagescraper.js
复制
您将向方法添加一个调用的新函数。此函数将包含从特定页面抓取数据的所有代码,然后单击“下一步”按钮(如果存在)。添加以下突出显示的代码:scrapeCurrentPage()scraper()
./book-scraper/pageScraper.js scraper()const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
复制
最初将变量设置为 false,然后检查该按钮是否存在。如果该按钮存在,则设置为并继续单击该按钮,然后以递归方式调用此函数。nextButtonExistnextnextButtonExiststruenext
如果为 false,则像往常一样返回数组。nextButtonExistsscrapedData
保存并关闭文件。
再次运行脚本:
复制
这可能需要一段时间才能完成;毕竟,您的应用程序现在正在从 800 多本书中抓取数据。随意关闭浏览器或按下取消该过程。CTRL + C
您现在已经最大限度地发挥了抓取工具的功能,但在此过程中产生了一个新问题。现在的问题不是数据太少,而是数据太多。在下一步中,您将微调您的应用程序,以按书籍类别过滤您的抓取。
步骤 5 — 按类别抓取数据
要按类别抓取数据,您需要修改文件和文件。pageScraper.jspageController.js
在文本编辑器中打开:pageController.js
nano pageController.js
呼叫刮刀,使其仅刮擦旅行书籍。添加以下代码:
./book-scraper/pageController.jsconst pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
复制
现在,您将两个参数传递到方法中,第二个参数是要抓取的书籍类别,在本例中为 。但是您的文件尚无法识别此参数。您还需要调整此文件。pageScraper.scraper()TravelpageScraper.js
保存并关闭文件。
打开:pageScraper.js
复制
添加以下代码,该代码将添加类别参数,导航到该类别页面,然后开始抓取分页结果:
./book-scraper/pageScraper.jsconst scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser, category){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Select the category of book to be displayed
let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
// Search for the element that has the matching text
links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
let link = links.filter(tx => tx !== null)[0];
return link.href;
}, category);
// Navigate to the selected category
await page.goto(selectedCategory);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
复制
此代码块使用您传入的类别来获取该类别的书籍所在的 URL。
可以通过将参数作为第三个参数传递给方法,并在回调中将其定义为第三个参数来接收参数,如下所示:page.$$eval()$$eval()
示例 page.$$eval() 函数page.$$eval('selector', function(elem, args){
// .......
}, args)
复制
这就是您在代码中所做的;您传递了要抓取的书籍类别,映射了所有类别以检查哪一个匹配,然后返回了该类别的 URL。
然后,此 URL 用于导航到显示要使用该方法抓取的书籍类别的页面。page.goto(selectedCategory)
保存并关闭文件。
再次运行应用程序。您会注意到,它会导航到该类别,逐页递归打开该类别中的书籍,并记录结果:Travel
复制
在此步骤中,您跨多个页面抓取数据,然后跨一个特定类别的多个页面抓取数据。在最后一步中,您将修改脚本以跨多个类别抓取数据,然后将此抓取的数据保存到字符串化的 JSON 文件中。
步骤 6 — 从多个类别中抓取数据并将数据另存为 JSON
在最后一步中,您将使脚本从任意数量的类别中抓取数据,然后更改输出方式。您不会记录结果,而是将它们保存在名为 的结构化文件中。data.json
您可以快速添加更多类别进行抓取;这样做只需要每种流派增加一行。
打开:pageController.js
复制
调整代码以包含其他类别。下面的示例将 和 添加到我们现有的类别中:HistoricalFictionMysteryTravel
./book-scraper/pageController.jsconst pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
复制
保存并关闭文件。
再次运行脚本,并观察它抓取所有三个类别的数据:
复制
随着抓取工具功能齐全,您的最后一步是以更有用的格式保存您的数据。现在,您将使用Node.js 中的模块fs.
首先,重新打开:pageController.js
复制
添加以下突出显示的代码:
./book-scraper/pageController.jsconst pageScraper = require('./pageScraper');
const fs = require('fs');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
if(err) {
return console.log(err);
}
console.log("The data has been scraped and saved successfully! View it at './data.json'");
});
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
复制
首先,您需要 Node,js 的模块。这可确保您可以将数据另存为 JSON 文件。然后,您添加代码,以便在抓取完成并且浏览器关闭时,程序将创建一个名为 .请注意,的内容是字符串化的 JSON。因此,在读取 的内容时,始终在重用数据之前将其解析为 JSON。fspageController.jsdata.jsondata.jsondata.json
保存并关闭文件。
您现在已经构建了一个网络抓取应用程序,该应用程序可以跨多个类别抓取书籍,然后将抓取数据存储在 JSON 文件中。随着应用程序复杂性的增加,您可能希望将此抓取数据存储在数据库中或通过 API 提供。如何使用这些数据实际上取决于您。
结论
在本教程中,您构建了一个 Web 爬网程序,该爬网程序以递归方式跨多个页面抓取数据,然后将其保存在 JSON 文件中。简而言之,您学习了一种从网站自动收集数据的新方法。
Puppeteer有很多不在本教程范围内的功能。要了解更多信息,请查看使用木偶轻松控制无头Chrome。您还可以访问木偶师的官方文档。
来源:https://www.digitalocean.com/community/tutorials/how-to-scrape-a-website-using-node-js-and-puppeteer

文章评论