
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 列表页通常是指网站或应用程序中的一个页面,它用于展示多个项目、文章、产品或其他内容的摘要,以帮助用户快速浏览并选择他们感兴趣的内容。列表页上通常包含多个项目,这些项目可以是文章、产品、服务、新闻、用户等。每个项目通常由一些基本信息组成,如标题、摘要、发布日期、图片等。如果项目数量很大,列表页可能会分为多个页面,用户可以通过分页按钮或无限滚动来查看更多项目。
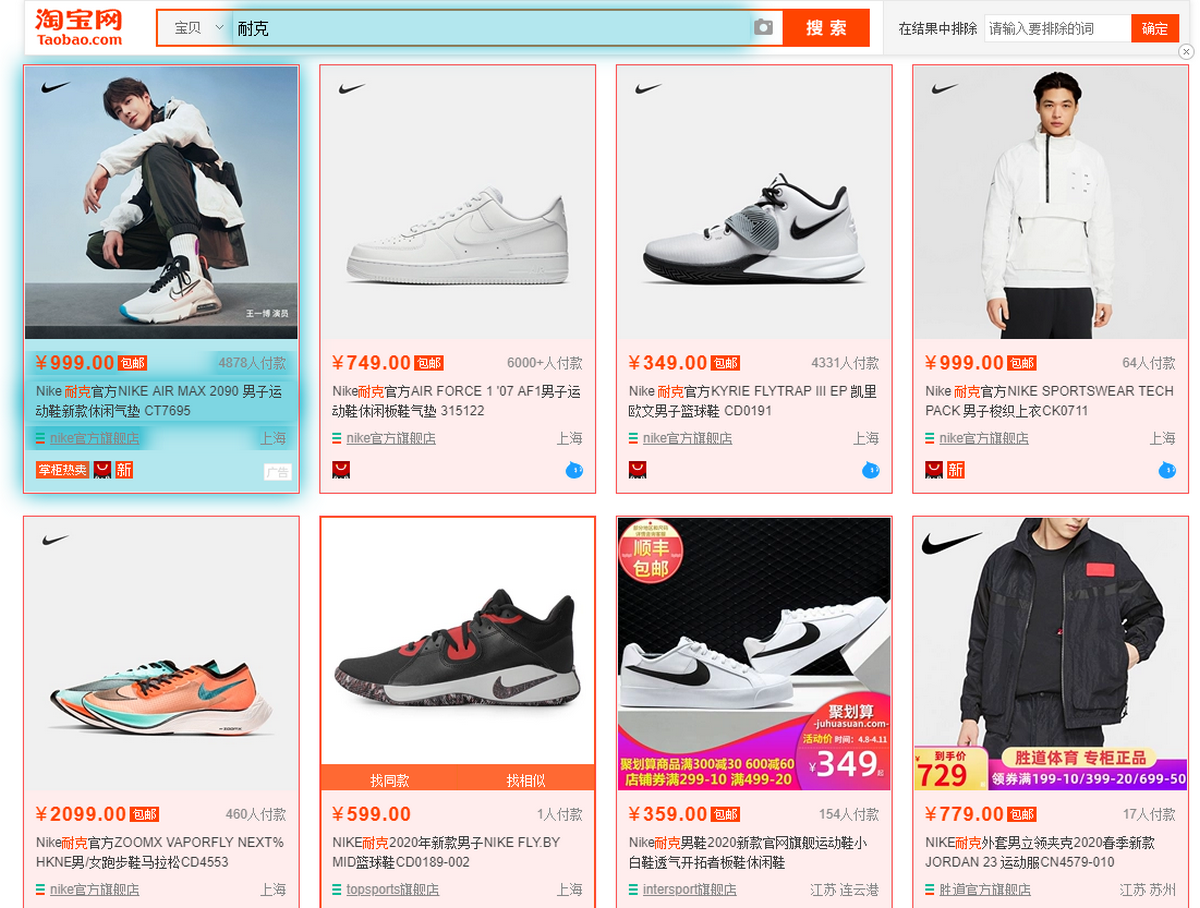
采集场景 在淘宝首页(https://s.taobao.com/)输入关键词搜索,采集搜索后得到的商品列表页数据。示例中关键词为【耐克】,可根据需求进行更换,同时支持自动批量输入多个关键词。 采集字段 采集字段包括关键字文本值,产品标题,店铺名称,产品价格,付款人数,商品链接,店铺名,品牌,发货地等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇…
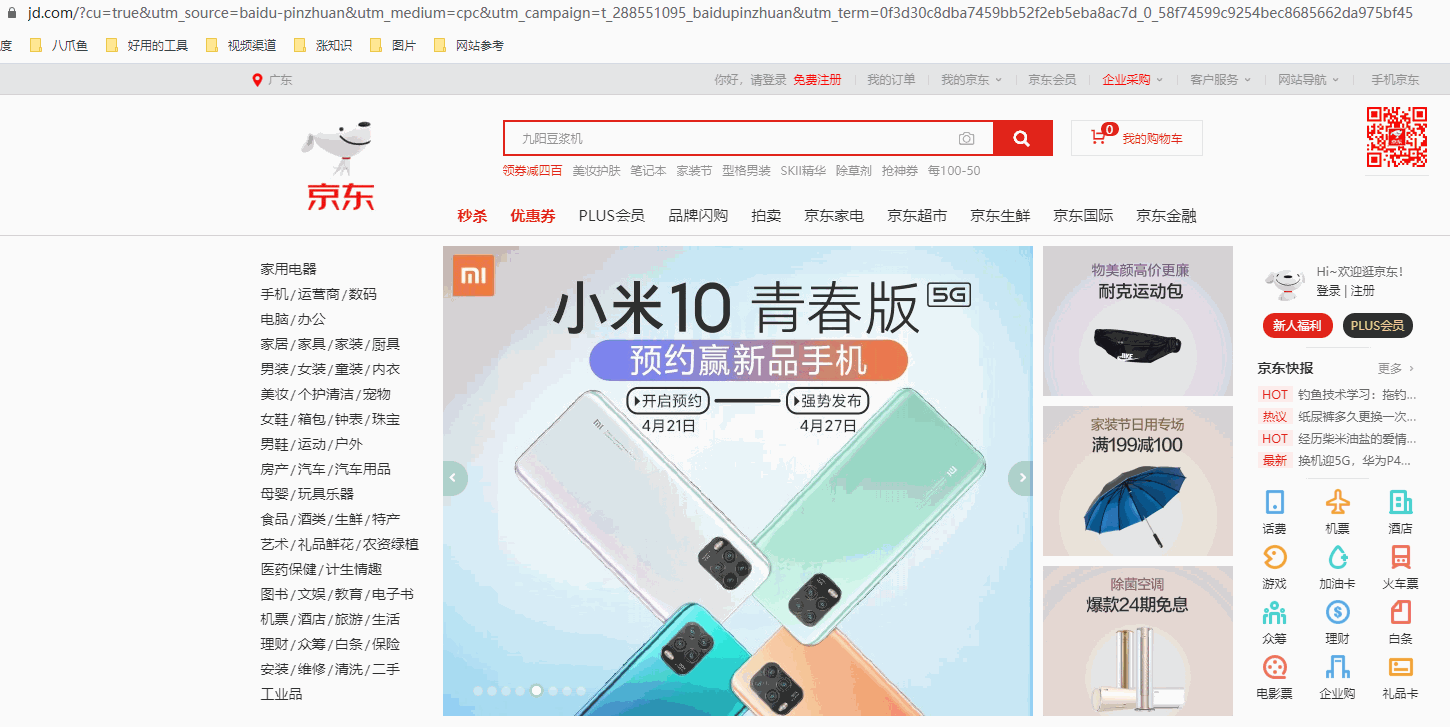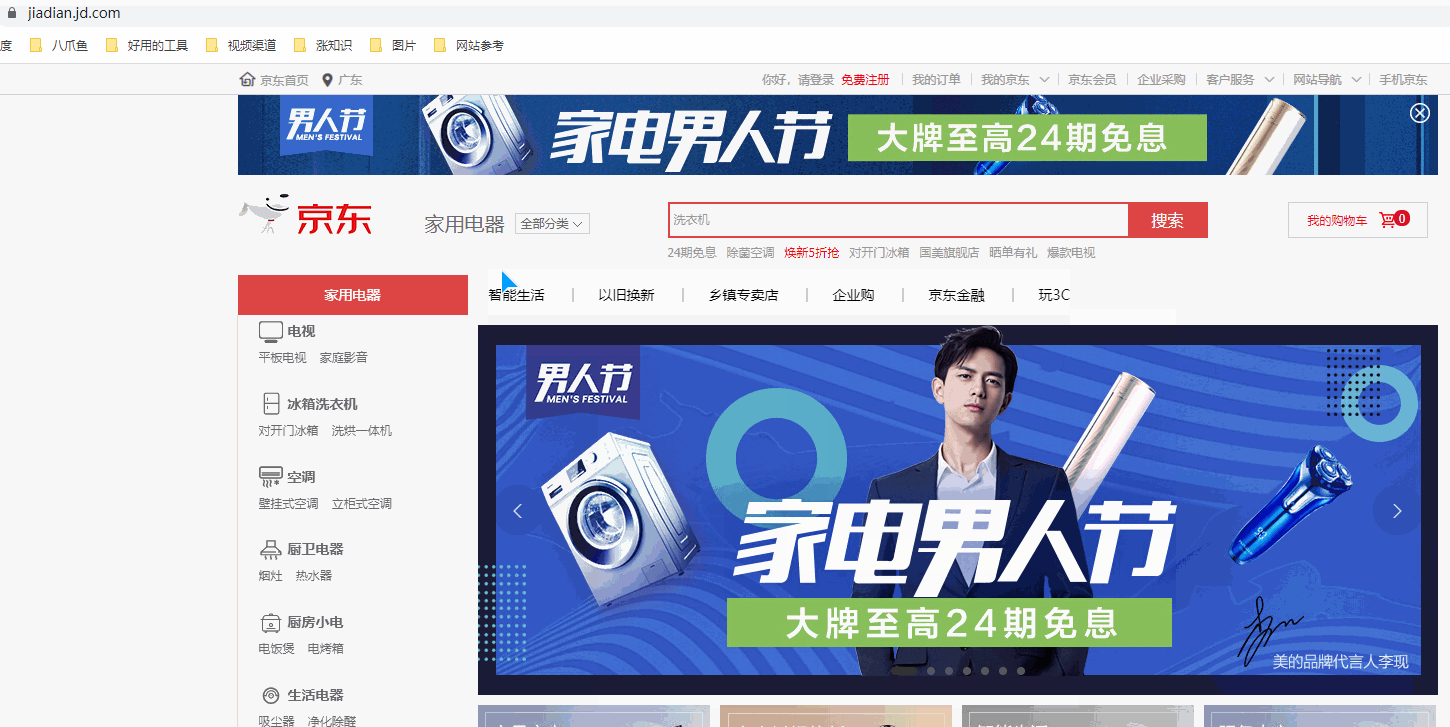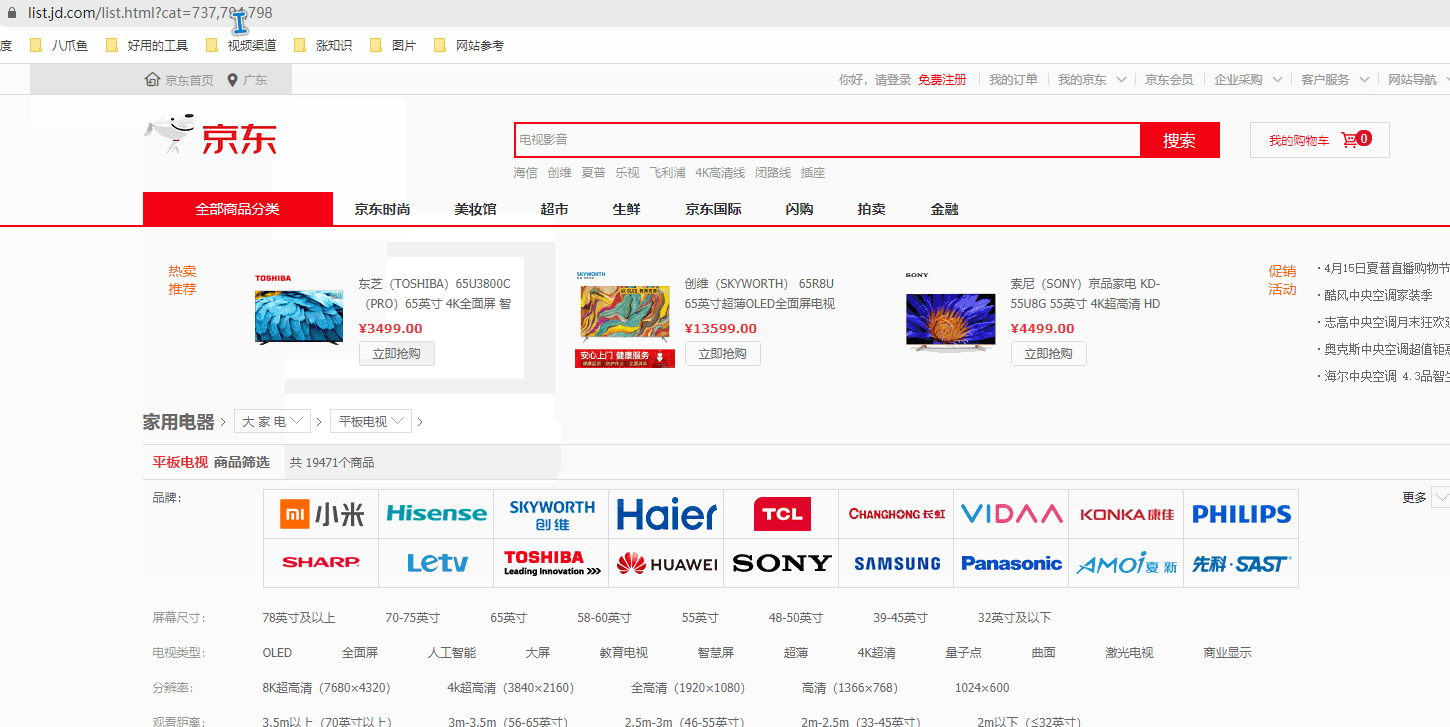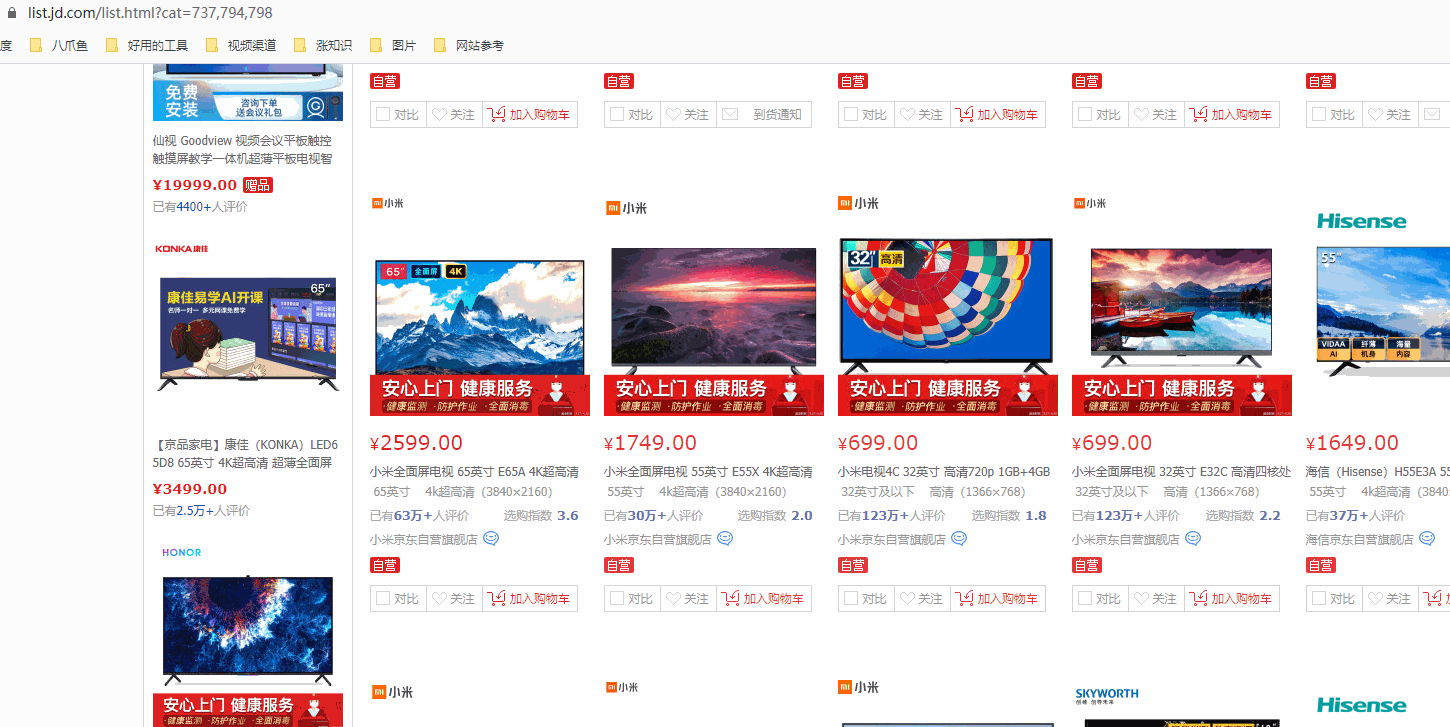
采集场景 京东首页(https://www.jd.com/)有很多商品分类,商品分类共三级。鼠标点击三级分类中的某个具体类别后,跳转到此类别的商品列表,跳转网址以list开头。采集list开头的商品列表数据。 实例:点击【家用电器】-【电视】-【平板电视】这个分类,跳转到【平板电视】分类的商品列表,跳转网址为 https://list.jd.com/list.html?cat=737,794,798 。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集字段 商品…
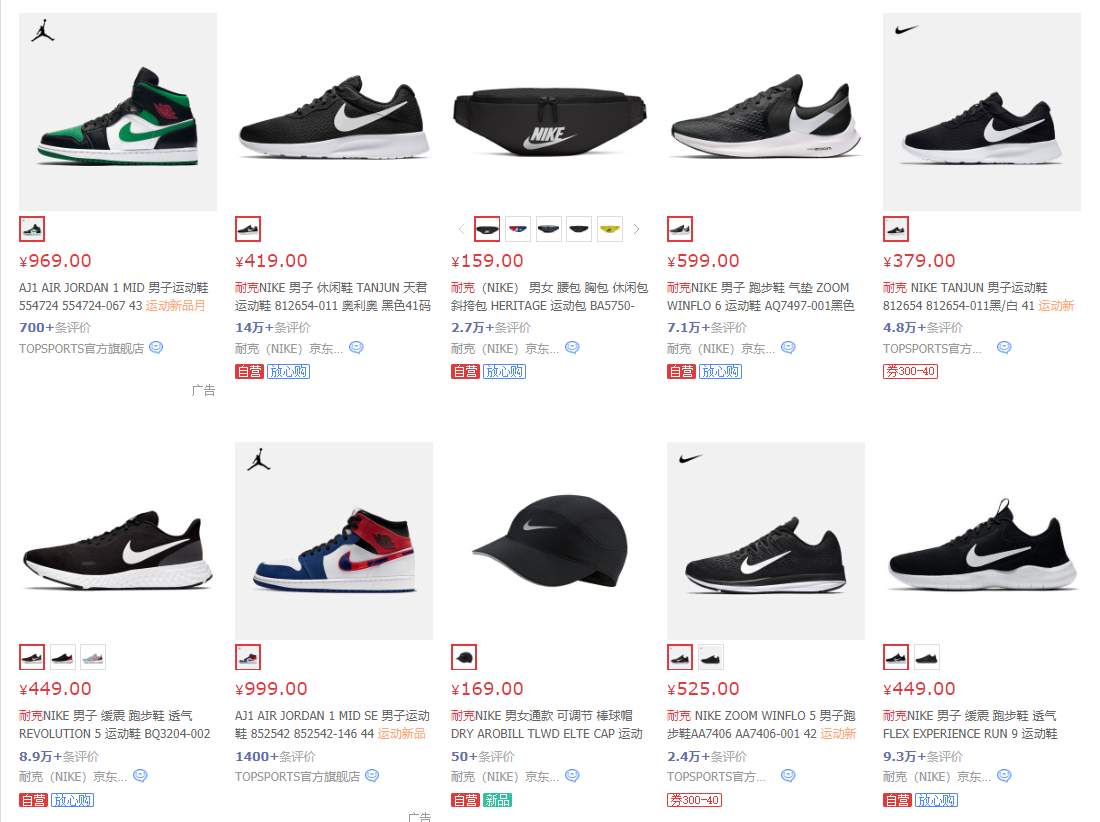
采集场景 在京东搜索页 https://search.jd.com/Search 输入搜索,搜出后得到的多个商品列表数据。 点击图片上,选择【在新标签页中打开图片】即可查看大图 其他图片同理 征地 商品名称、价格、评论数、店铺名称、店铺链接等字段。 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等格式。导出为Excel示例: 教程说明 本篇更新时间:2022/5/10 八爪鱼版本:V8.5.2 如果因网页改版导致网址或步骤无效,无法获取到目标数据,请联系官方客服,我们将及时修…
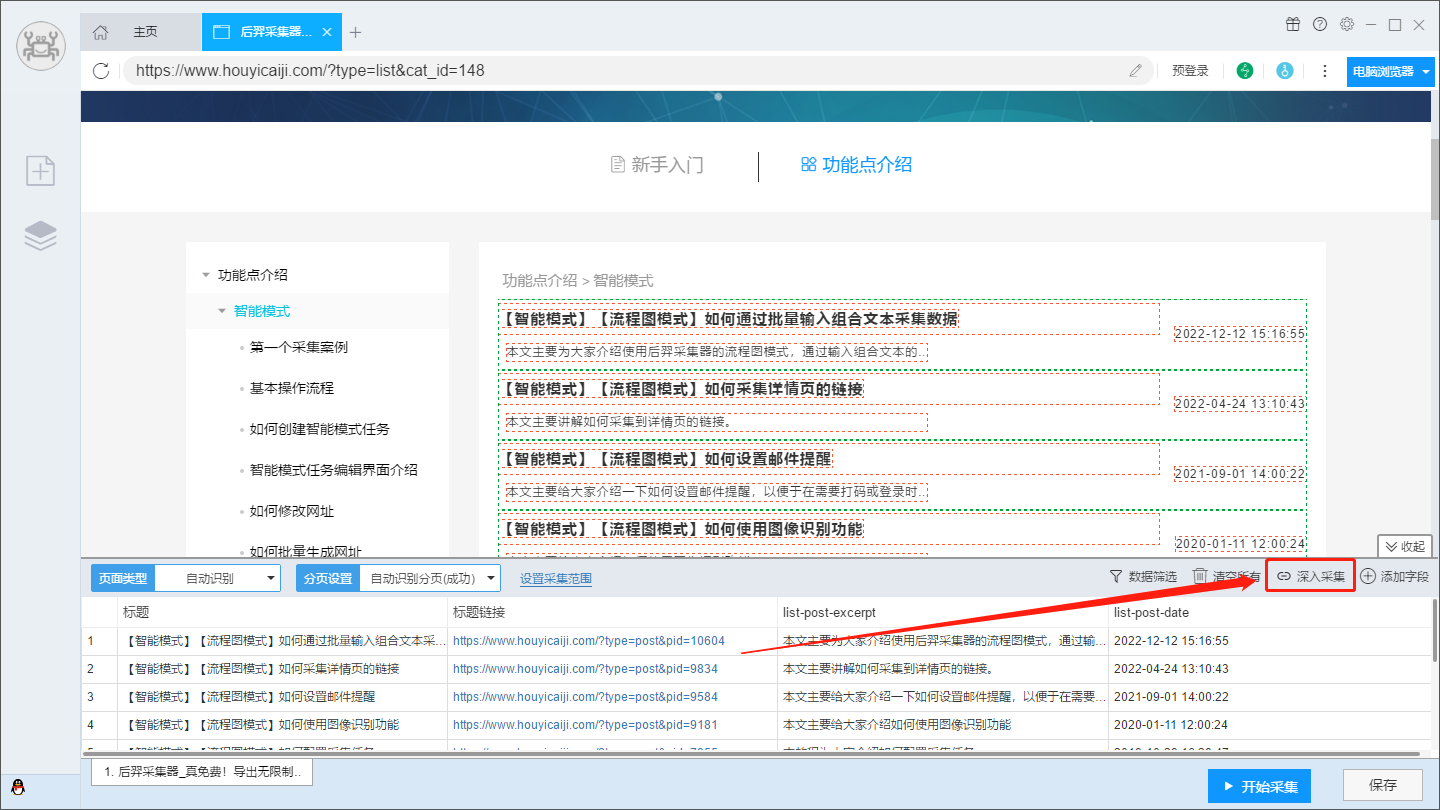
问题: 如何既采集列表,又采集详情中的数据 / 如何采集详情页? 回答: 后羿采集器有深入采集的功能,只需要点击“深入采集”按钮,或者点击已经采集到的链接就能进入详情页进行采集。 具体操作请参考教程: 如何设置深入采集
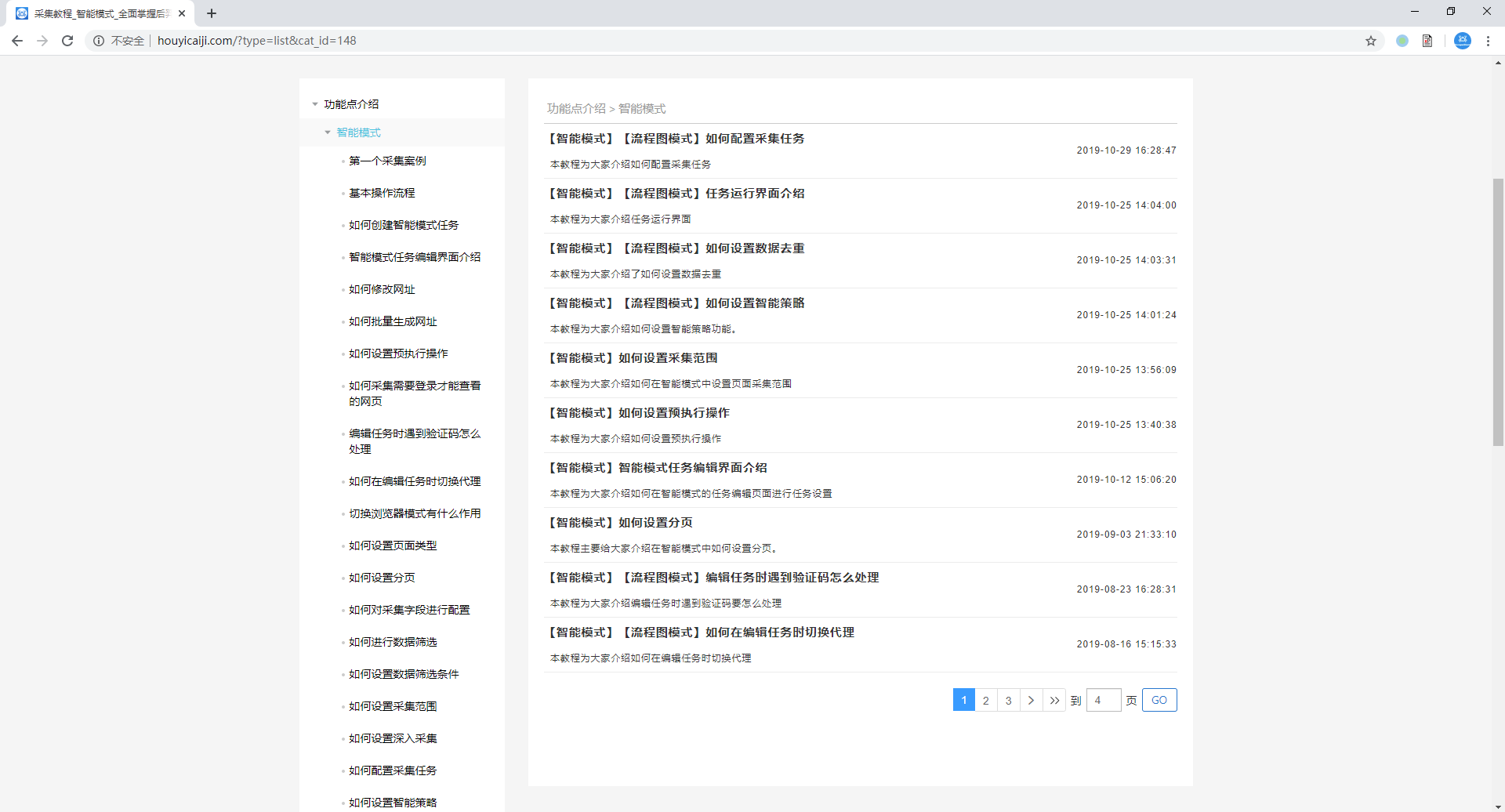
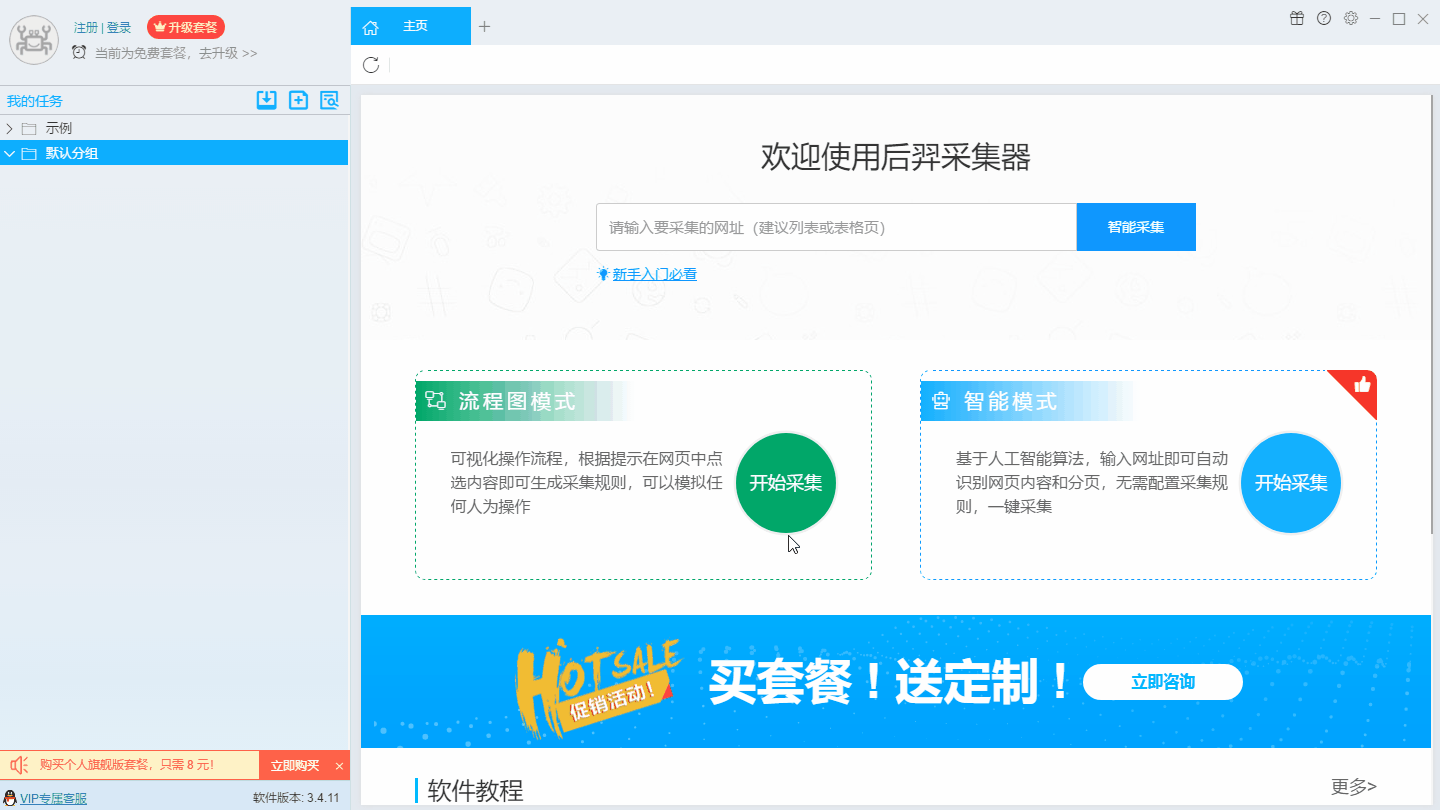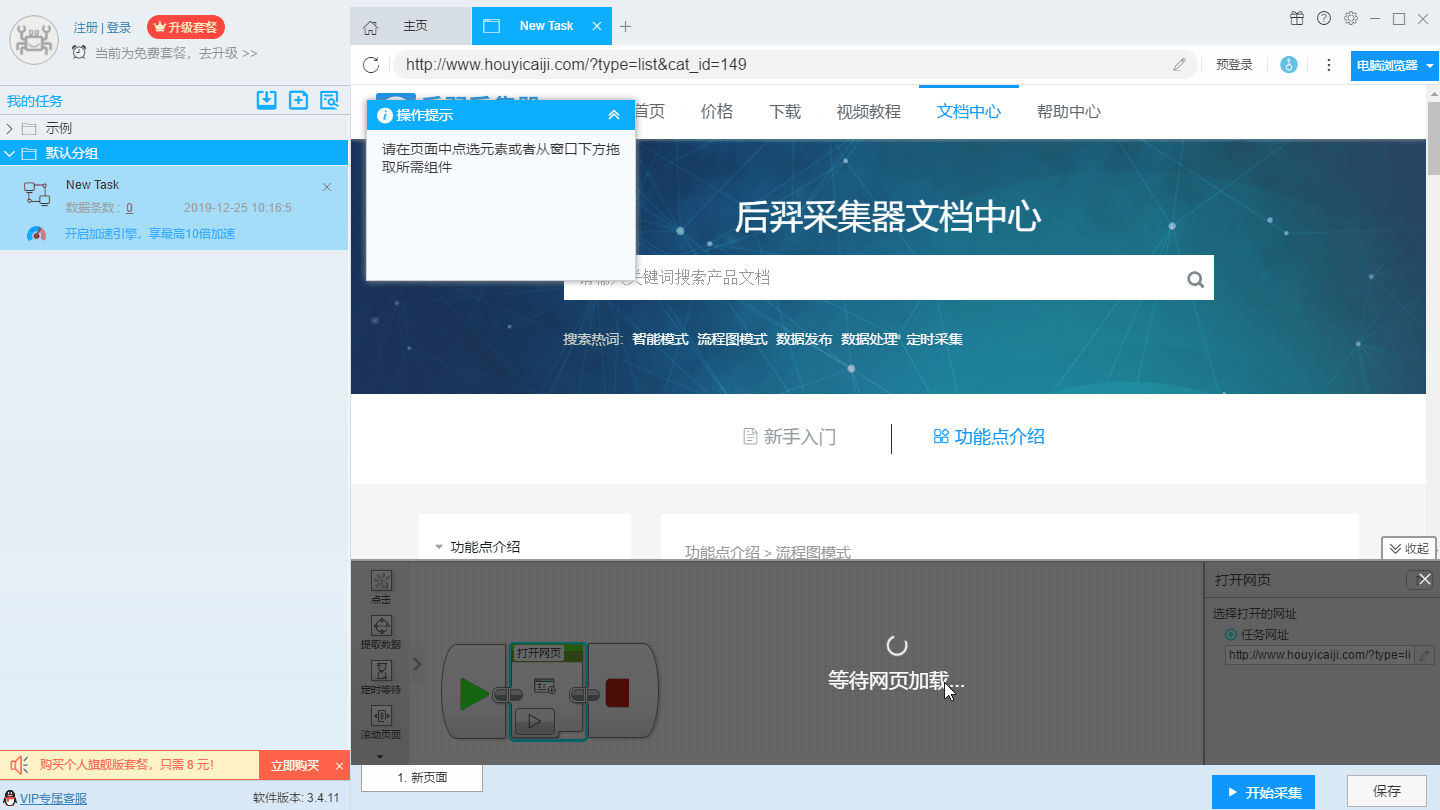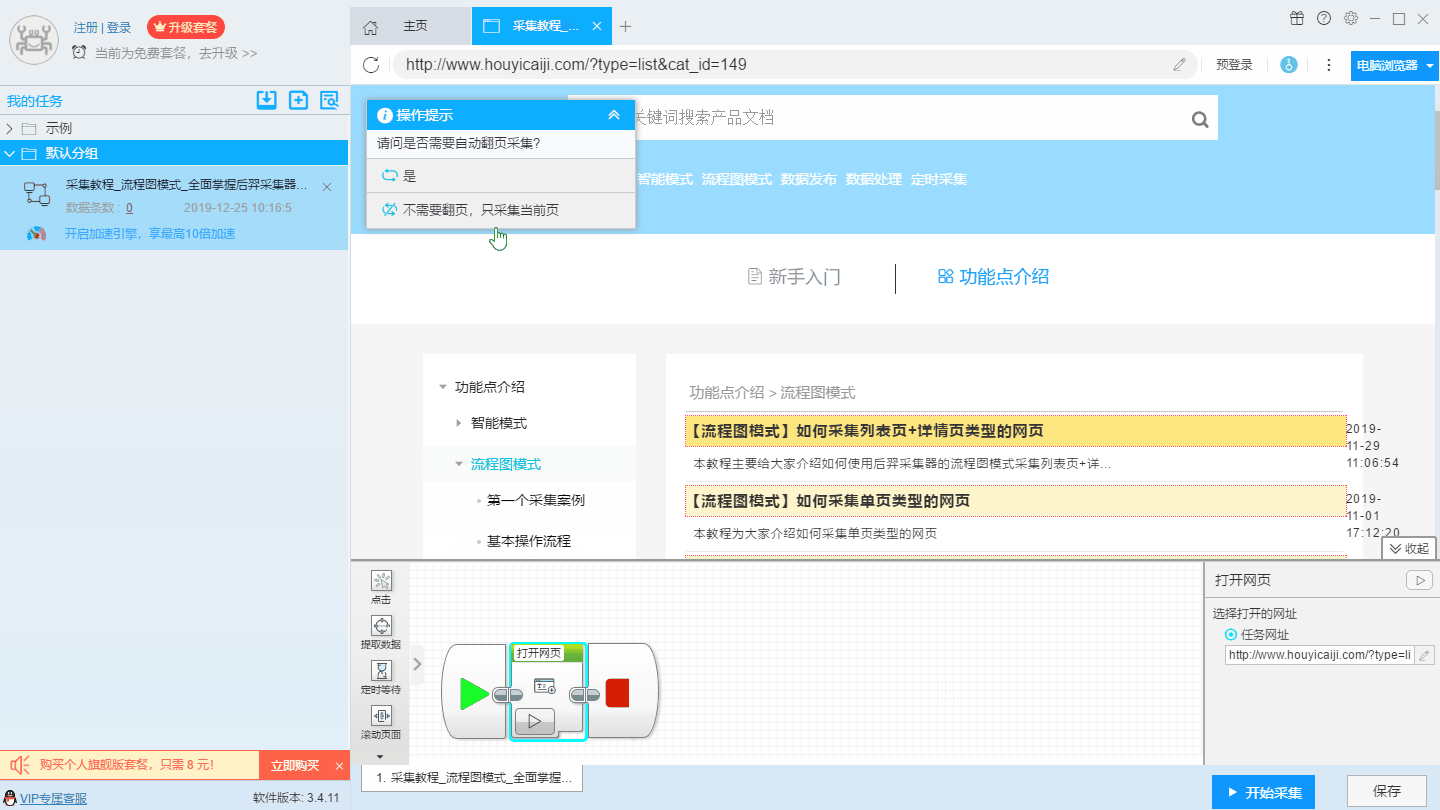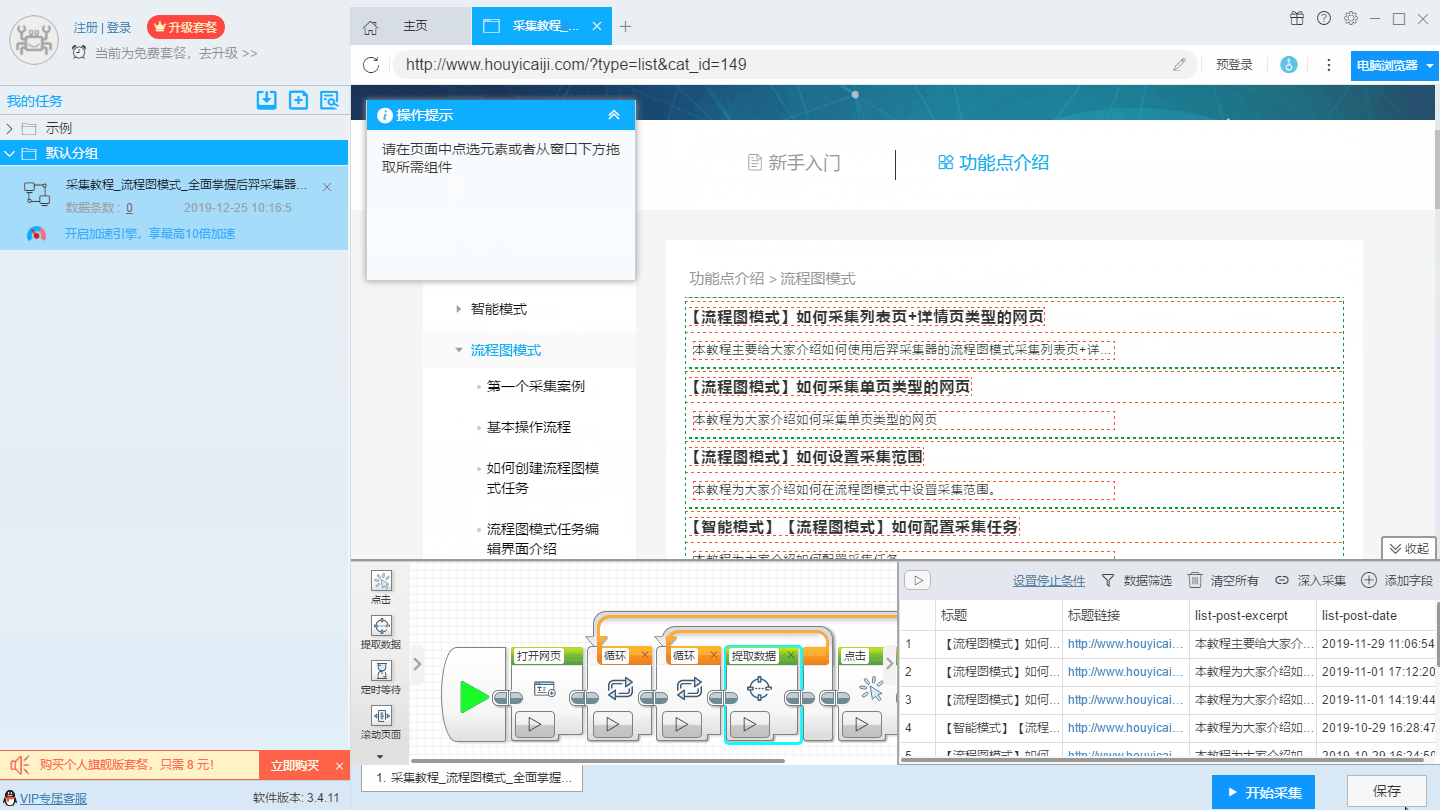
1、什么样的网页是列表类型的网页 列表类型的网页是具有相同元素的内容页按照一定的线性顺序排列分布的网页,如下图所示: 2、如何采集列表类型的网页 在智能模式下,后羿采集器默认按照列表类型的网页进行智能识别,并完成页面列表元素内部所有字段的自动识别和采集。 如果后羿采集器自动识别的结果不符合您的需求,您可以手动点选列表。 (1)软件自动识别列表元素内部字段并进行采集 (2)手动点选列表 关于采集字段的设置可以看这里→_→ 如何对采集字段进行配置
后羿采集器的智能模式的强大之处在于它不仅可以采集单页类型和列表类型的网页,还能够支持采集列表页+详情页的网页类型。 下面我们来详细介绍一下如何采集采集列表页+详情页内容。 第一步:采集列表页内容 更多详情内容,请参考以下教程: 如何采集列表类型的网页 第二步:深入采集 在第一步中,软件会识别出列表内容中的链接,用户也可以通过手动设置提取到链接,在此基础上,我们如果需要采集到链接对应的详情页的内容,需要用到深入采集功能。 更多详情内容,请参考以下教程: 如何设置深入采集 第三步:设置详情页数据 详情页的采集和单页类型…
在数据采集过程中,有时候我们会遇到采集到详情页时需要点击某一按钮之后才能获得数据的情况,下面我们给大家介绍一下如何采集这一类的数据。 第一步:采集列表页内容 更多详情内容,请参考以下教程: 如何采集列表类型的网页 第二步:使用深入采集进入详情页 完成列表页数据采集后,如果想要采集详情页上的数据,可以点击深入采集按钮或者点击列表识别结果中任意一个标题,然后在左侧操作栏内点击“依次点击全部元素”按钮,跳转到详情页进行采集。 更多详情内容,请参考以下教程: 如何实现深入采集 第三步:提取详情页数据 跳转到详情页之后,点击…
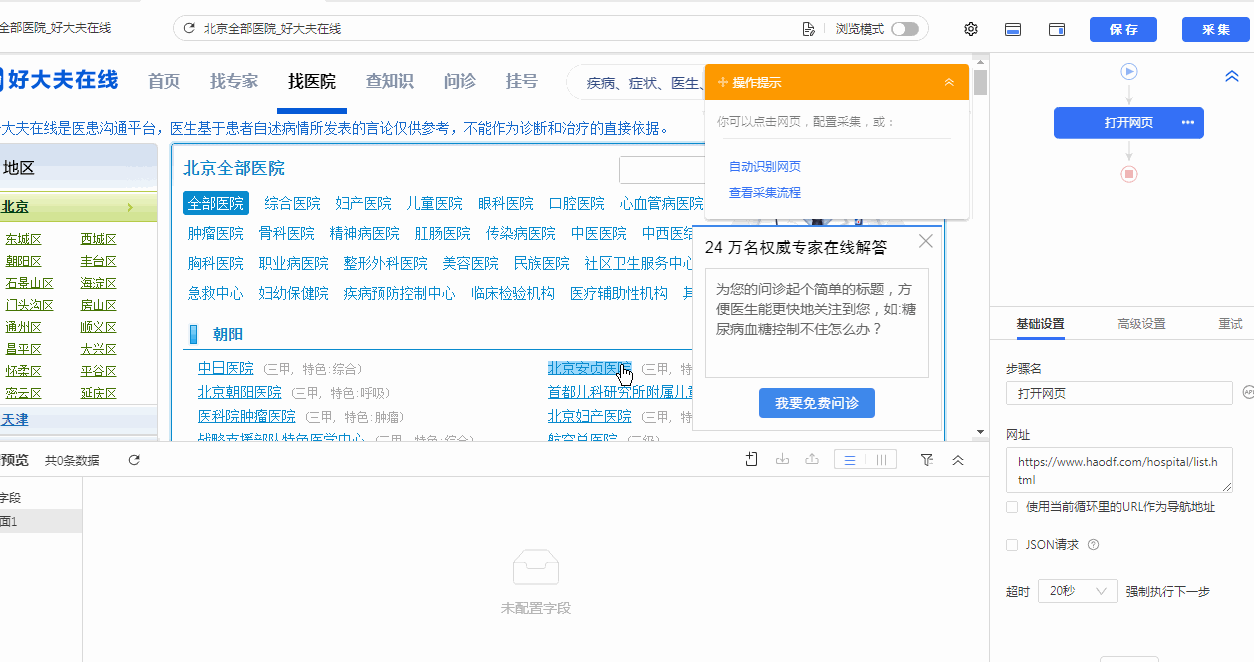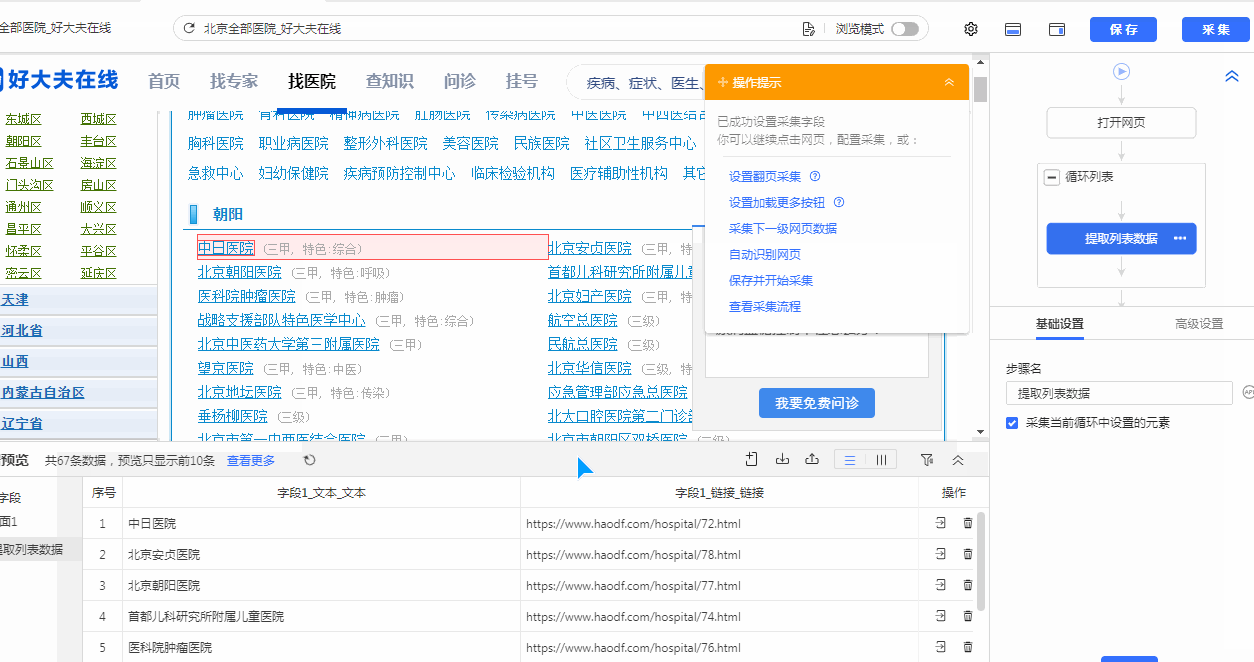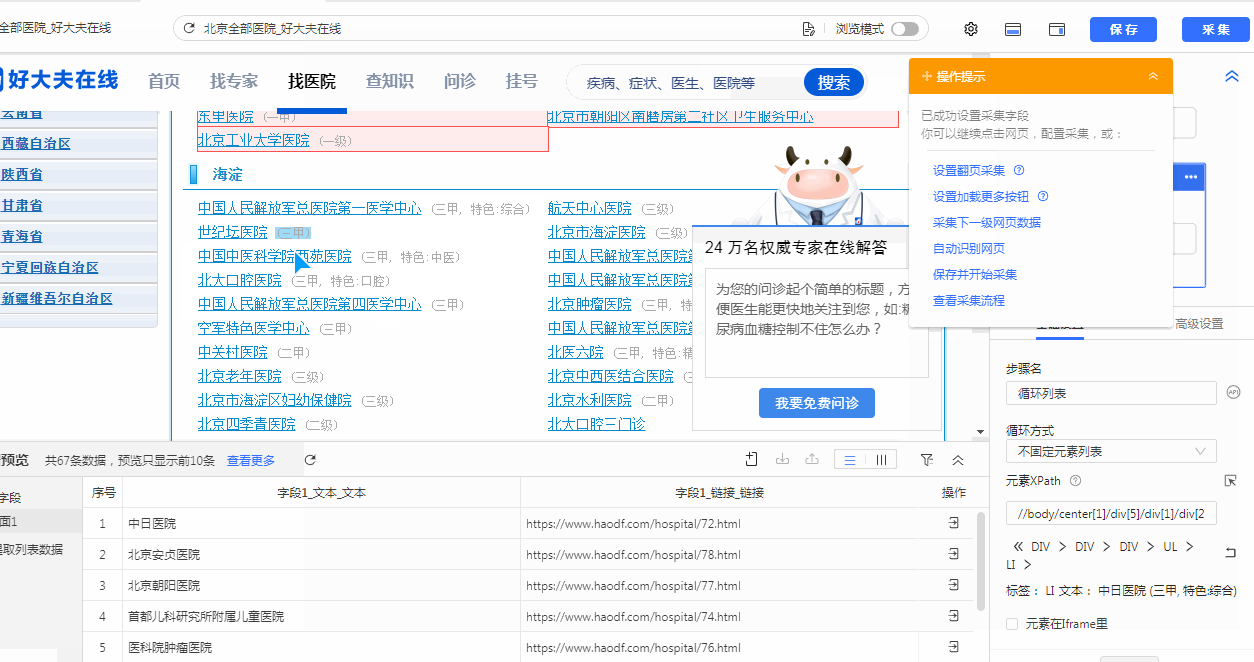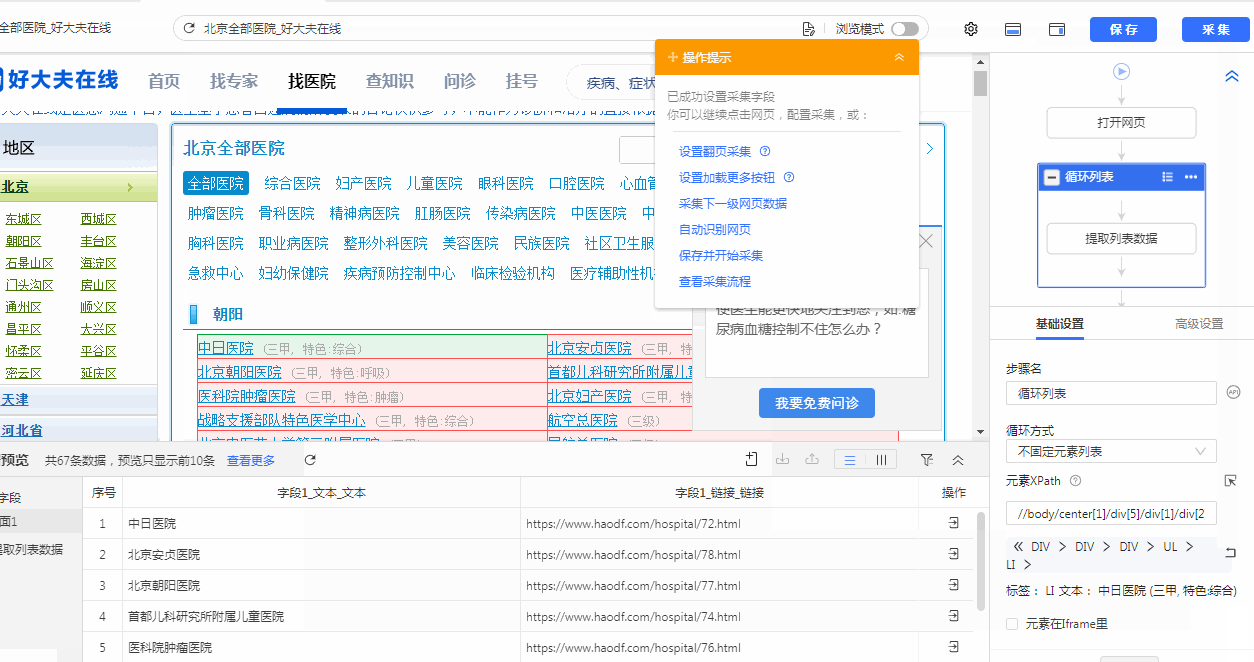
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。 一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。 但有时候我们点击了列表页某一项数据之后,点击“选中全部”,但是循环定位到的数据并没有包含咱们要的所有数据项,这个时候可以通过手动修改xpath,让循环定位到咱们所有需要的数据, 这就是我们本节课所要讲的内容。 实例网址:https://www.haodf.com/hospital/list.html 基础操作:…
在数据采集过程中,有时候我们会遇到采集到详情页时需要点击某一按钮之后才能获得数据的情况,本文将为大家介绍如何采集这一类的数据。 第一步:采集列表页数据 输入网址后,软件会自动识别列表上的数据,用户可以在这个基础上对字段进行设置。 点此了解更多如何采集列表页数据 第二步:使用深入采集进入详情页 采集完列表页上的数据后,我们需要采集详情页上的数据,可以选中链接使用深入采集,也可以点击链接直接进入详情页。 点此了解如何使用深入采集功能。 第三步:点击页面上按钮获得采集字段 当遇到详情页信息需要点击才会显示的情况,我们可以…
