
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。
一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。
但有时候我们点击了列表页某一项数据之后,点击“选中全部”,但是循环定位到的数据并没有包含咱们要的所有数据项,这个时候可以通过手动修改xpath,让循环定位到咱们所有需要的数据,
这就是我们本节课所要讲的内容。
实例网址:https://www.haodf.com/hospital/list.html
基础操作:输入网址 —— 开始采集 —— 点击‘朝阳区某一个医院’ —— 选中全部 —— 采集以下链接文本+链接
可以看到,这样操作下来后只是定位到了朝阳区的所有医院,并没有定位到我们所要的其他区的医院。
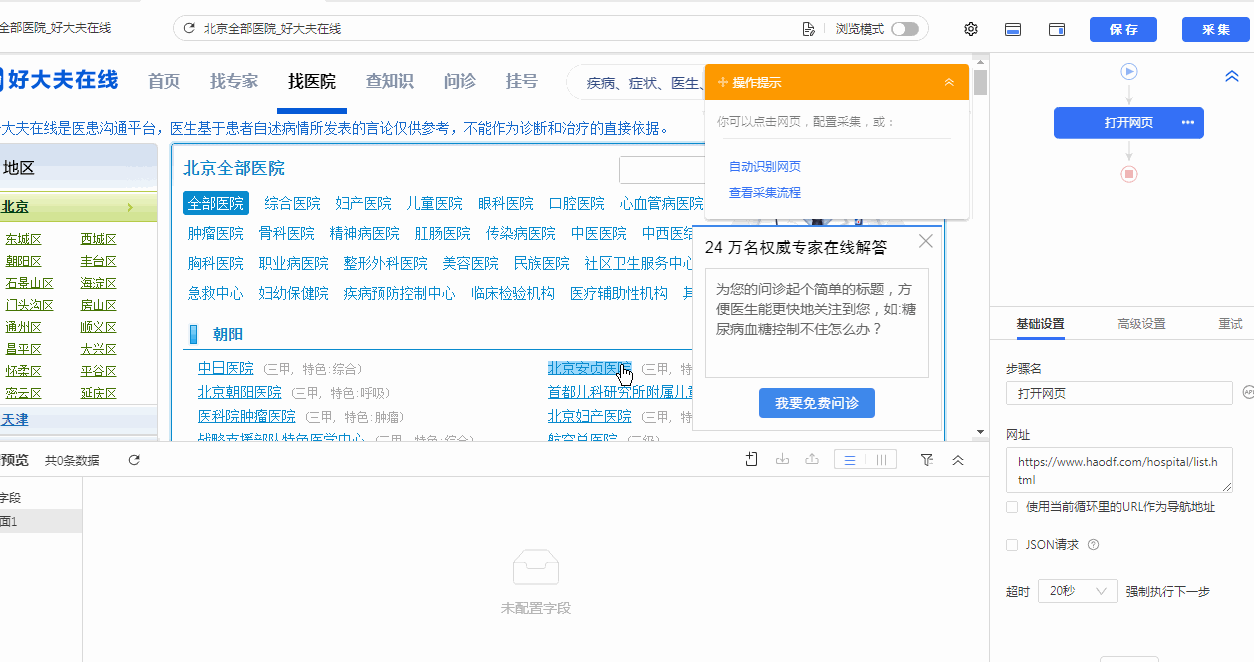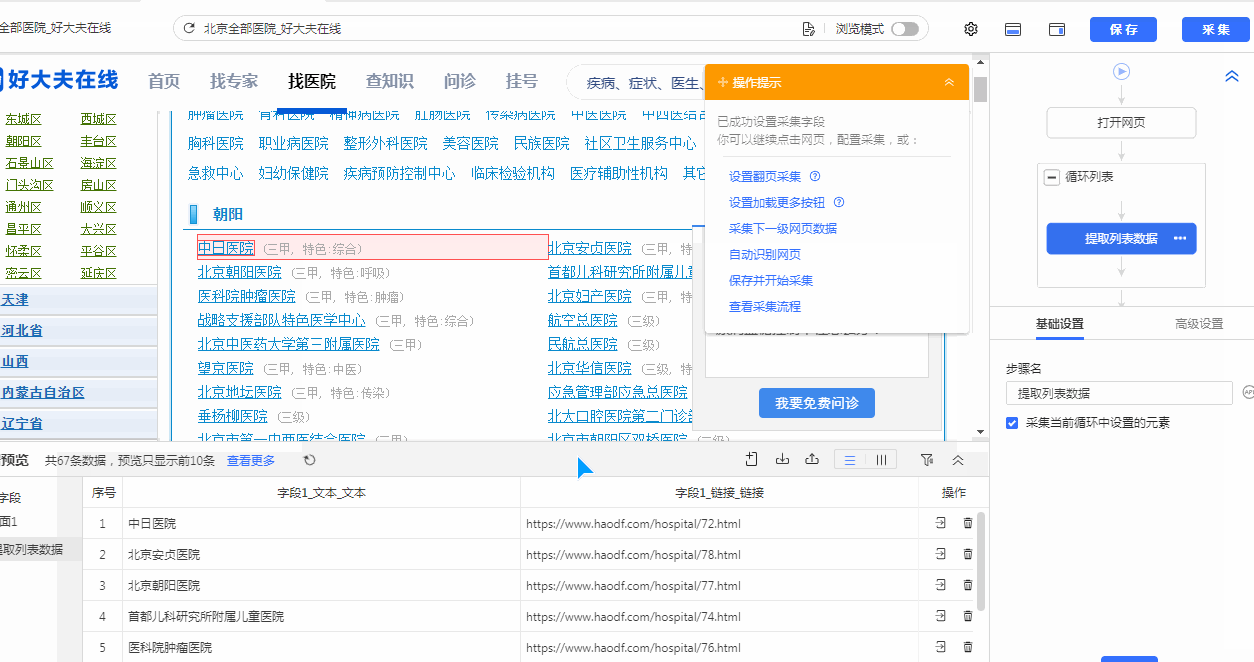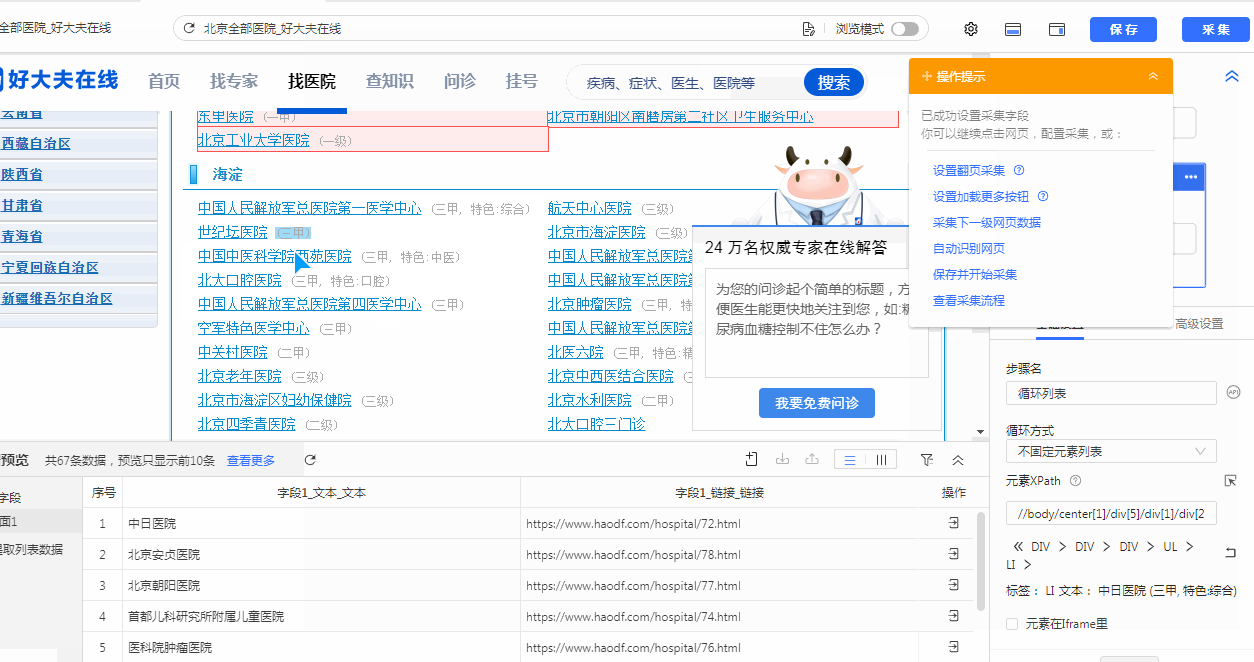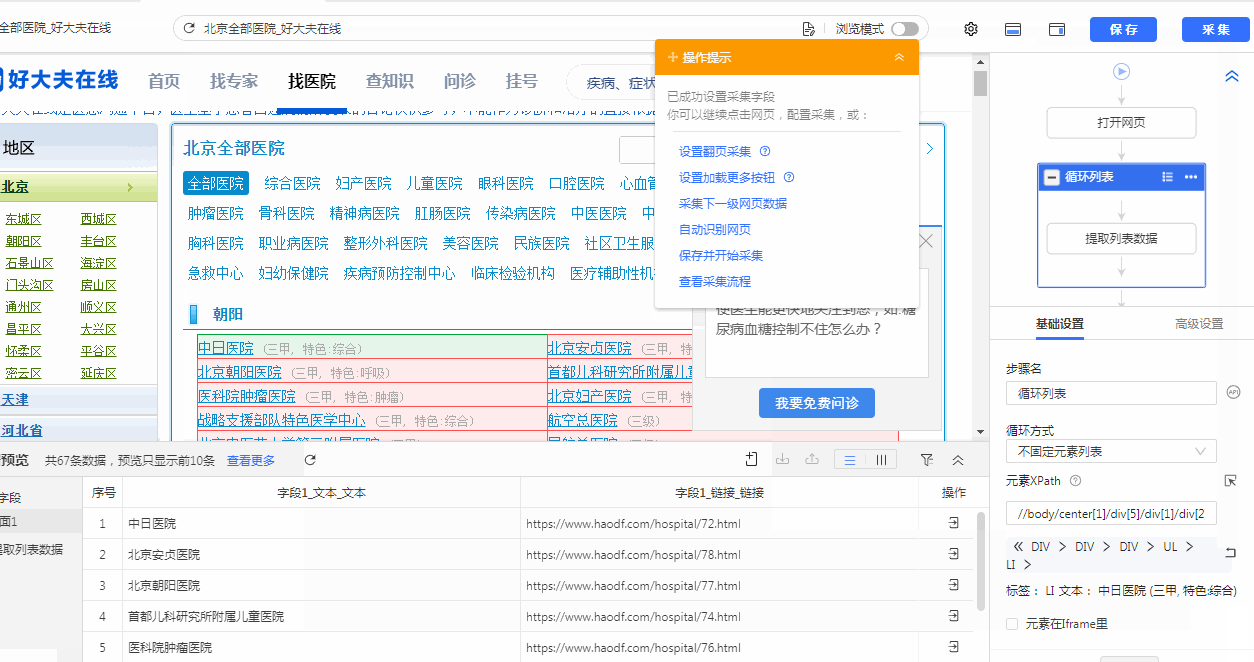
这个时候我们就可以通过自己写一条xpath,来让循环定位到全部的医院。
注意: 如何修改需要一定的XPath知识,请看之前的 XPath系统学习教程 。
第一步入手我们可以先定位到我们所需的中间包含我们所需要数据的红框这块区域。通过观察属性可以很快写
出//div[@id="el_result_content"]//div[@class="ct"]来定位到这块区域的内容
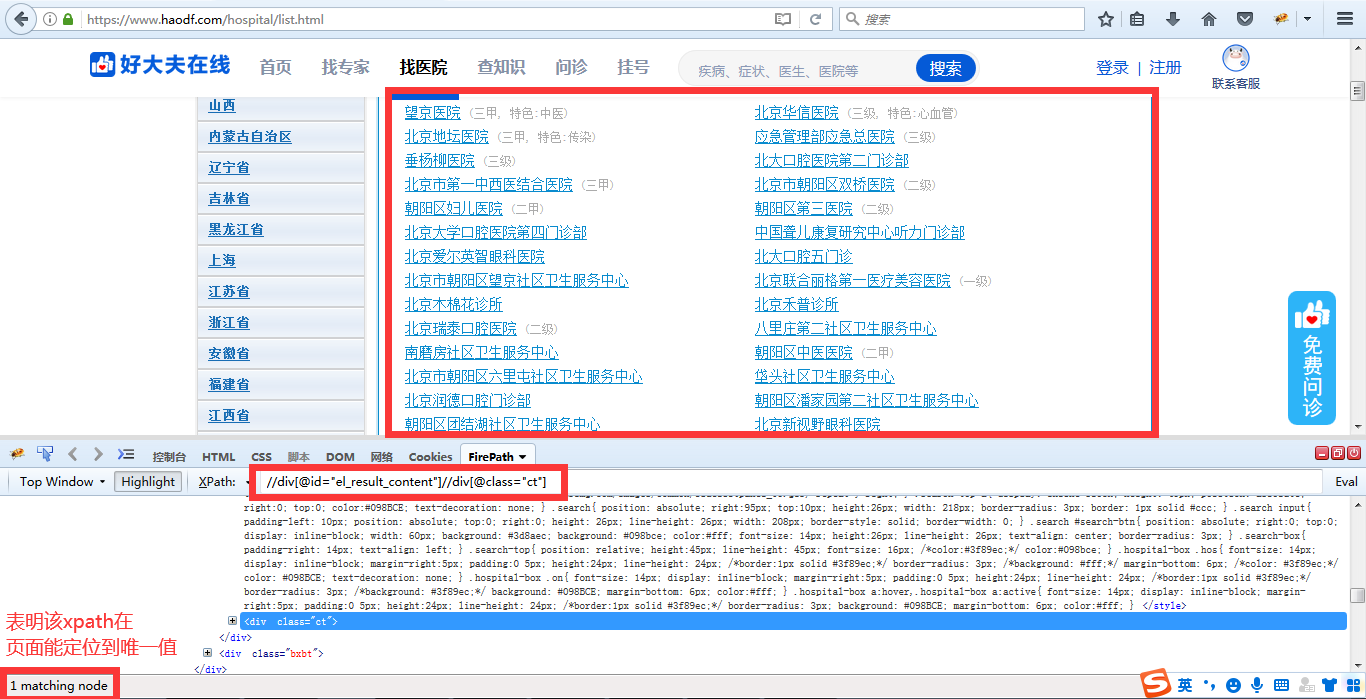
第二步我们需要再深层定位到每个北京市每个城区的区域块,通过观察可以发现,每个数据块div层级都有一个共同的属性
class="m_ctt_green",我们继续通过绝对路径的写法‘//’,把//div[@class="m_ctt_green"]与第一步我们的出的大区域xpath连接起来,
也就是//div[@id="el_result_content"]//div[@class="ct"]//div[@class="m_ctt_green"]
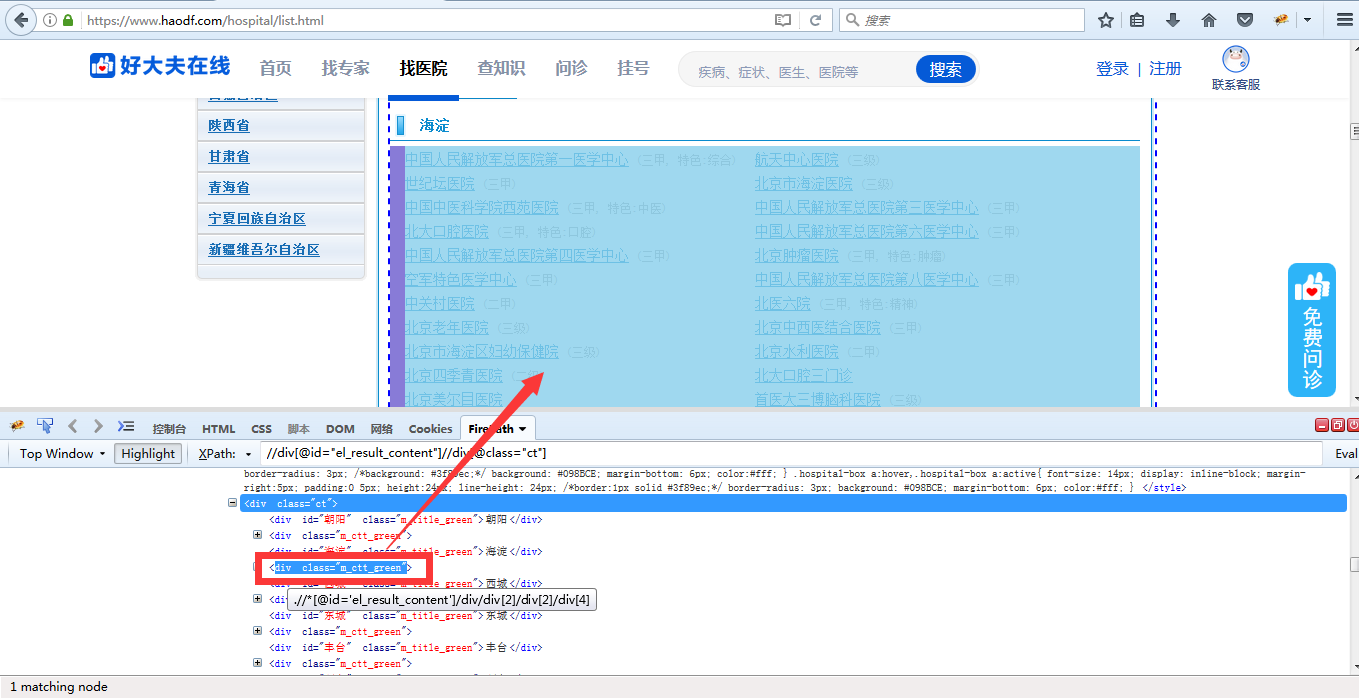
可以发现已经定位到了北京市19个城区的医院区块了
但是我们的需求是精准定位到每个医院的名称,所以需要再继续往深层挖掘。
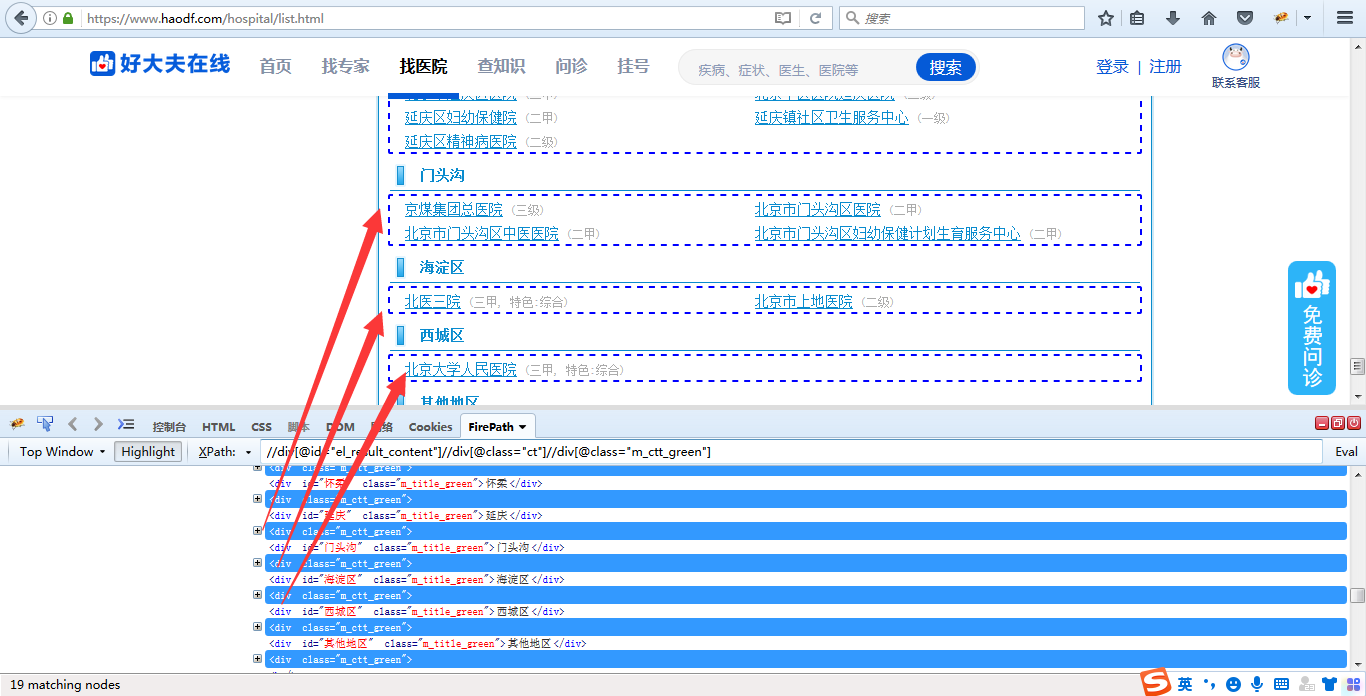
第三步,可以点击“+”号展开“朝阳区”这块的div层级,再点击展开“ul”层级,通过鼠标移动可以发现,每一个“li”层级就是一个医院名称了,
所以此时只要再添加一个层级//li,就可以定位到所有的医院了,得出最终我们所要的
xpath://div[@id="el_result_content"]//div[@class="ct"]//div[@class="m_ctt_green"]//li,定位到了所有医院,总共是340条。
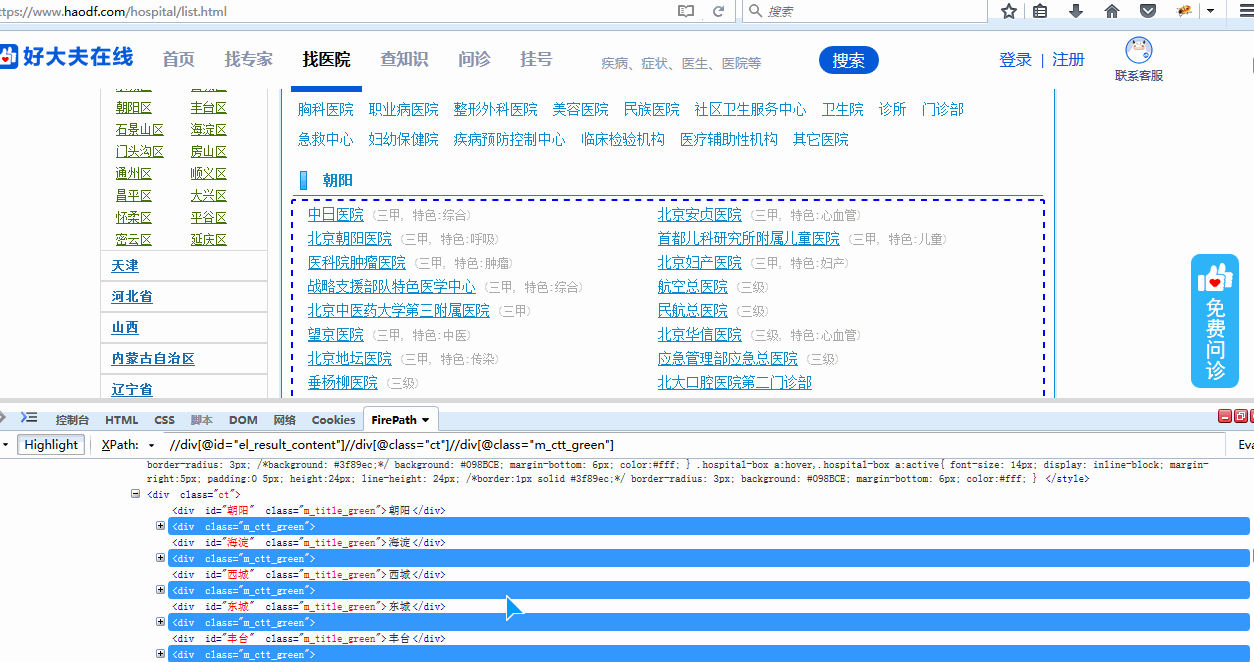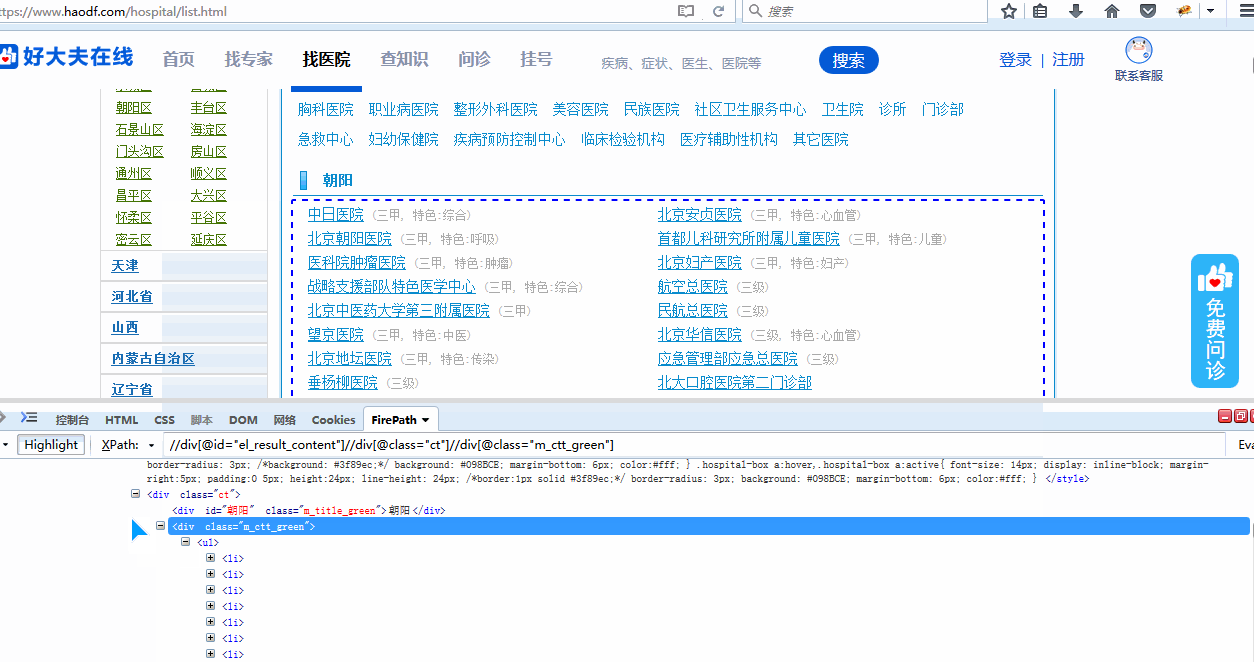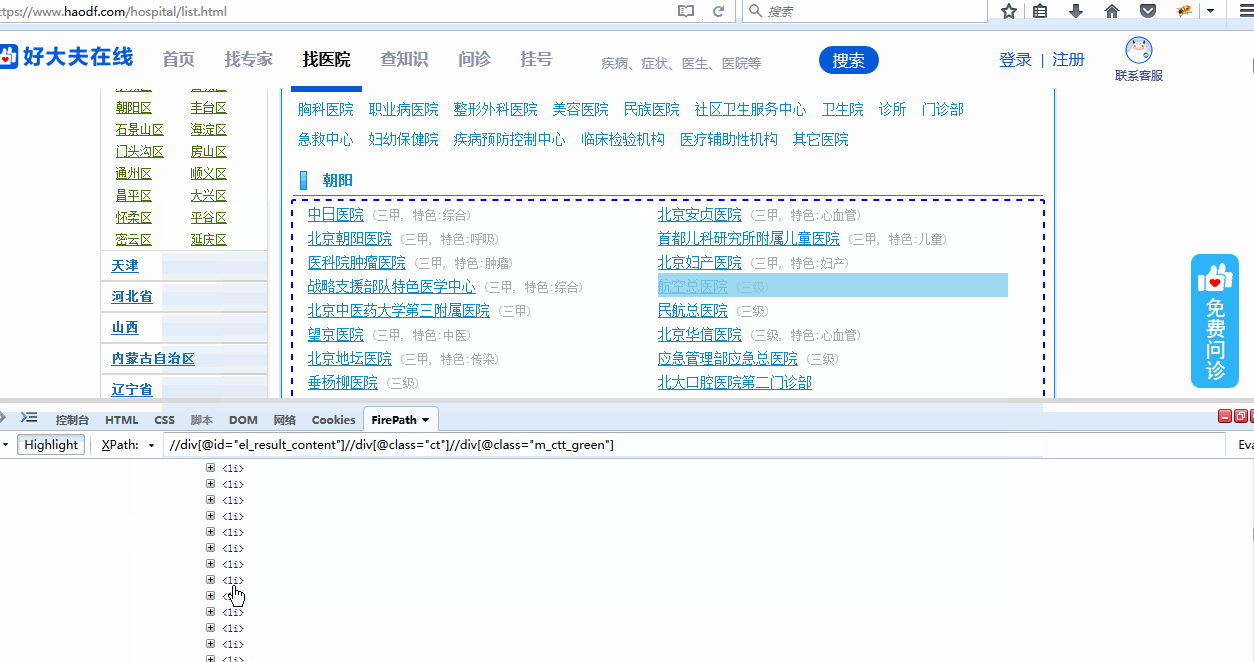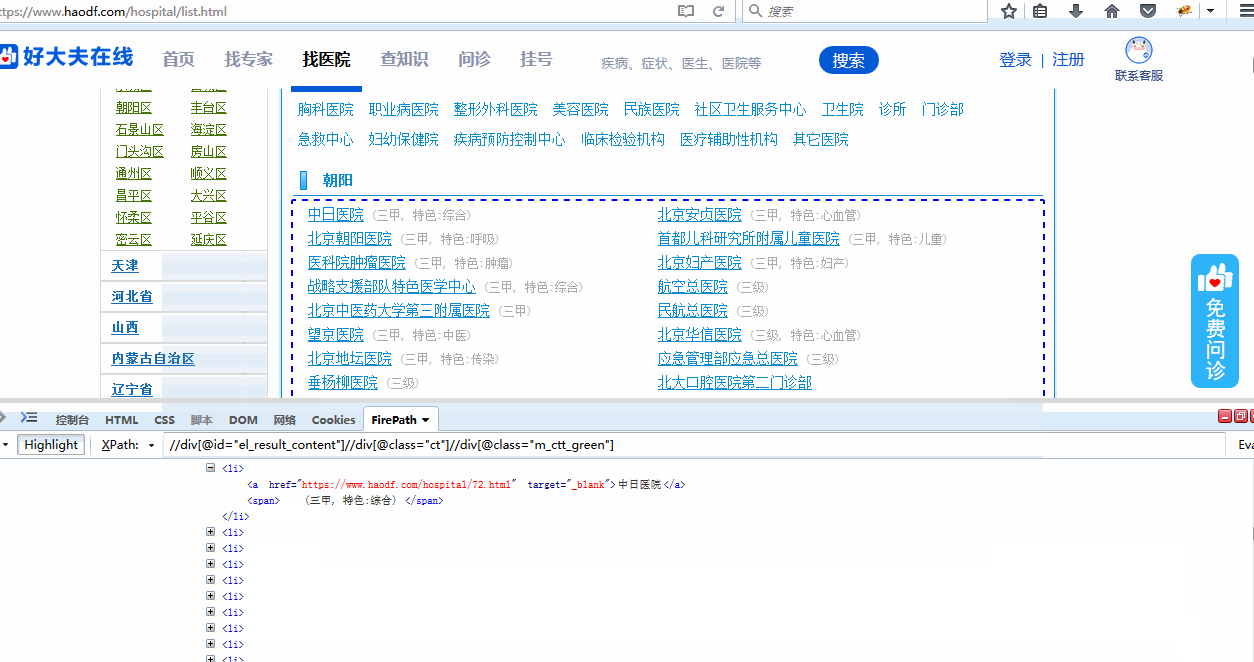
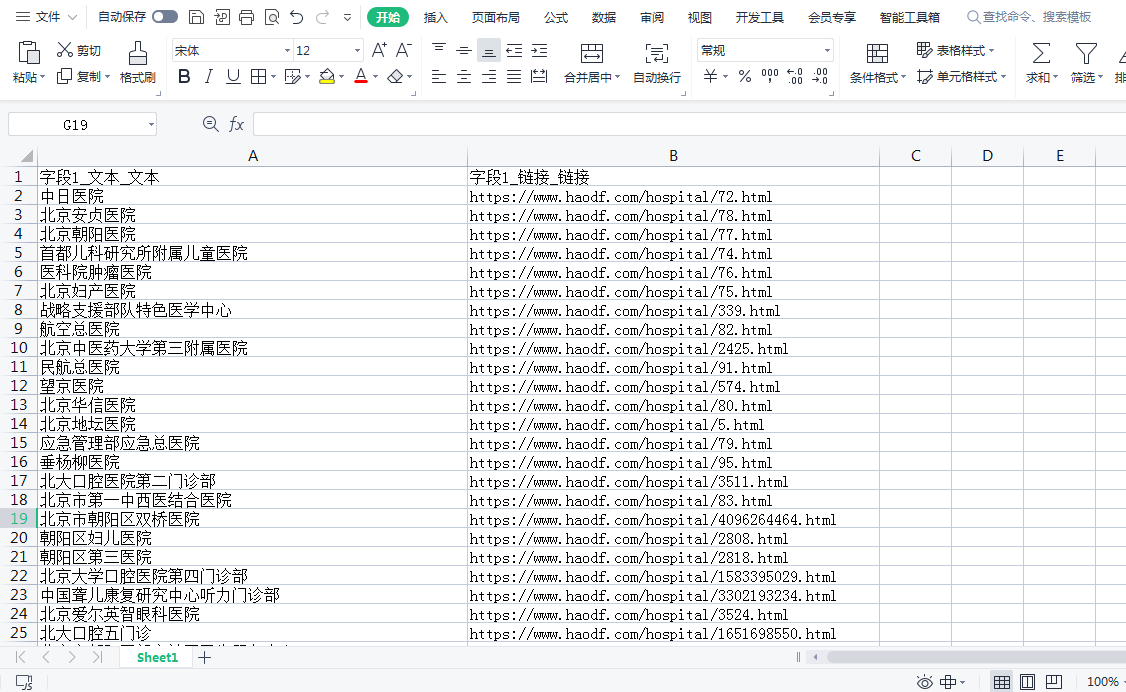
把第三步所获得的最终xpath复制到八爪鱼内,点击循环列表,覆盖掉原来默认生成的xpath,点击“应用”,再重新点击下列表循环,可以发现正确的定位到了340条数据了。
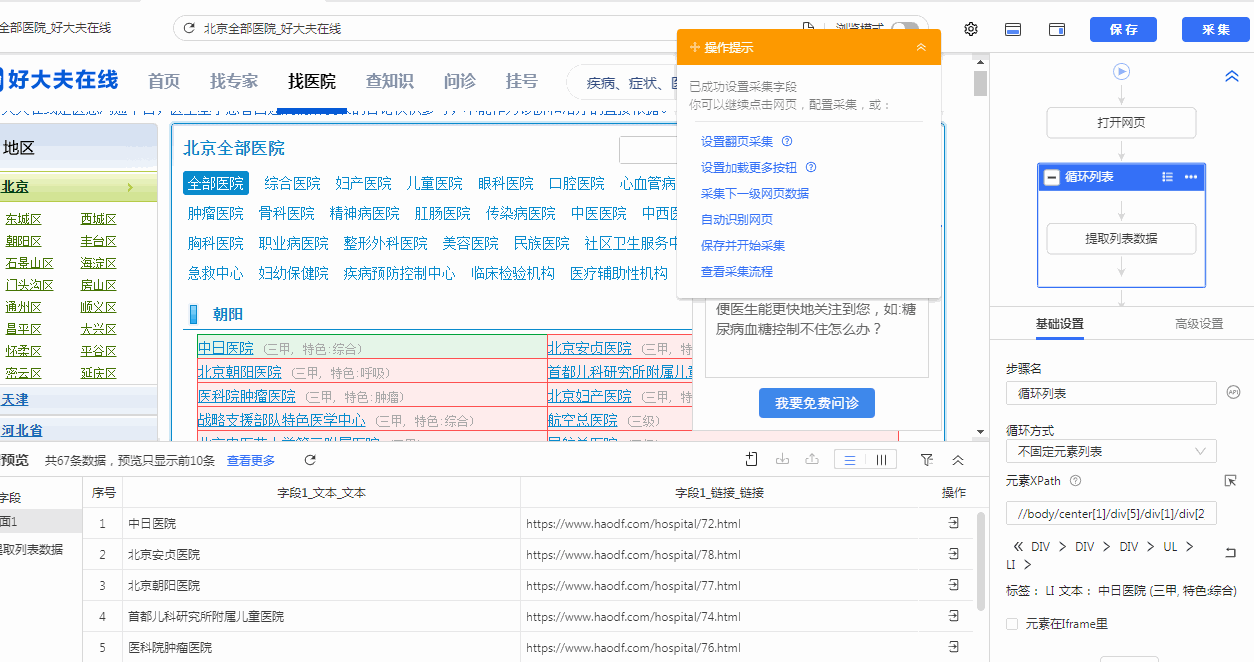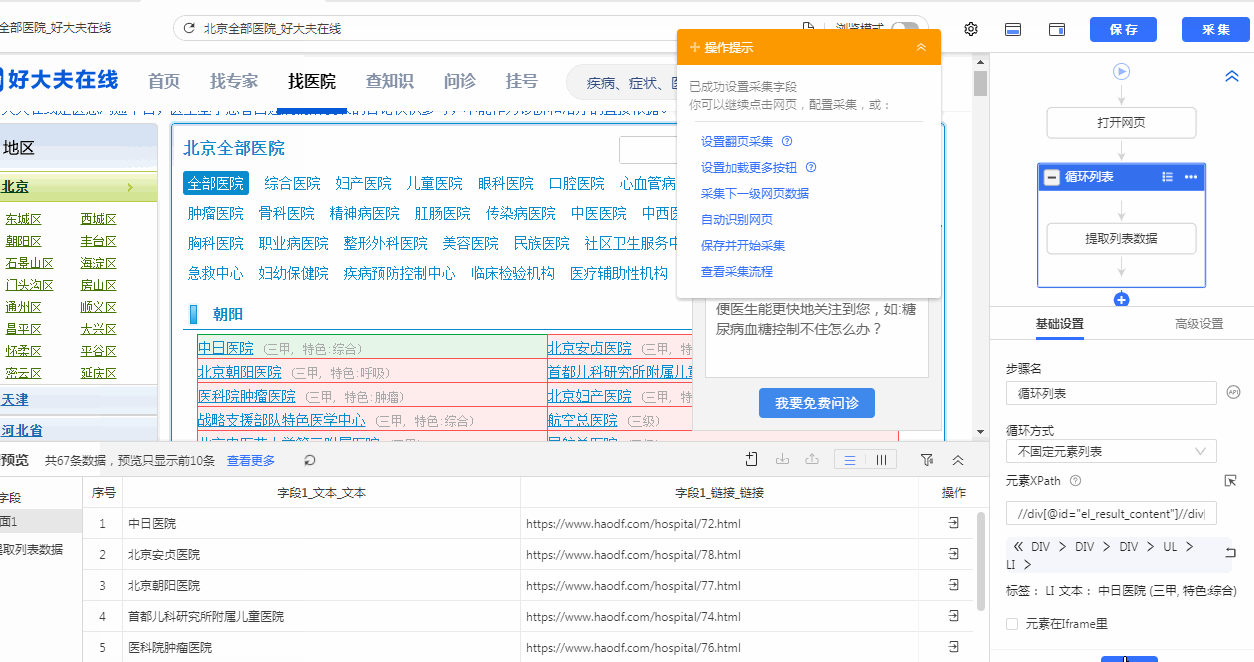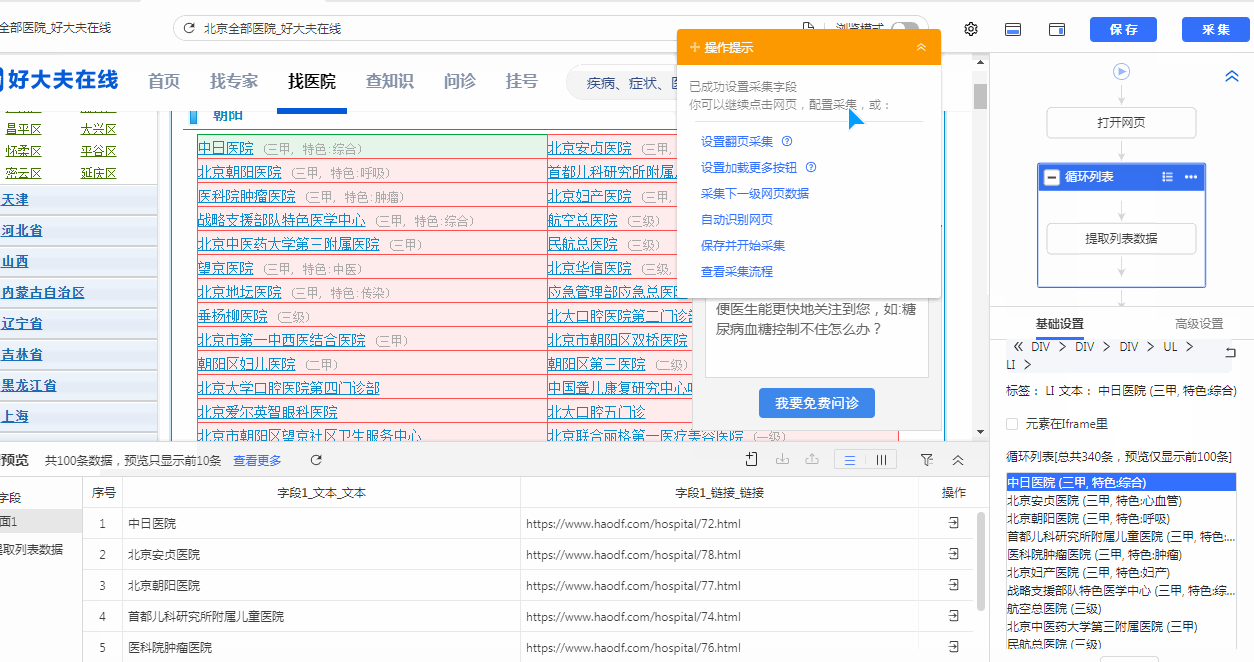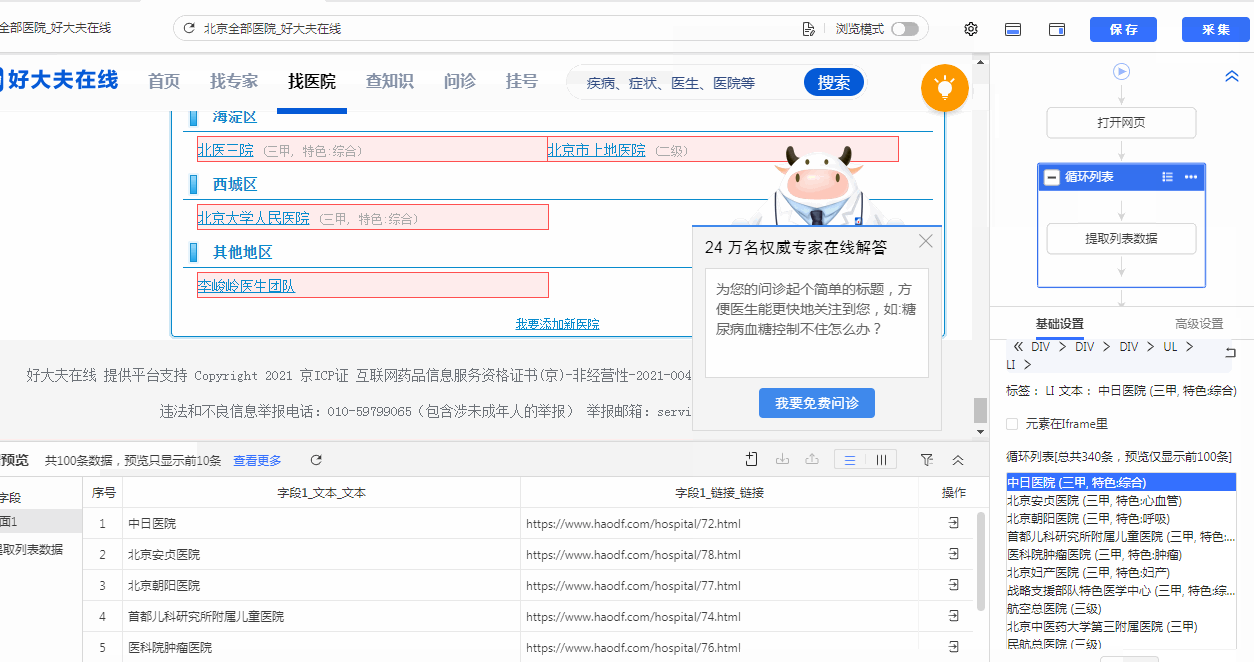
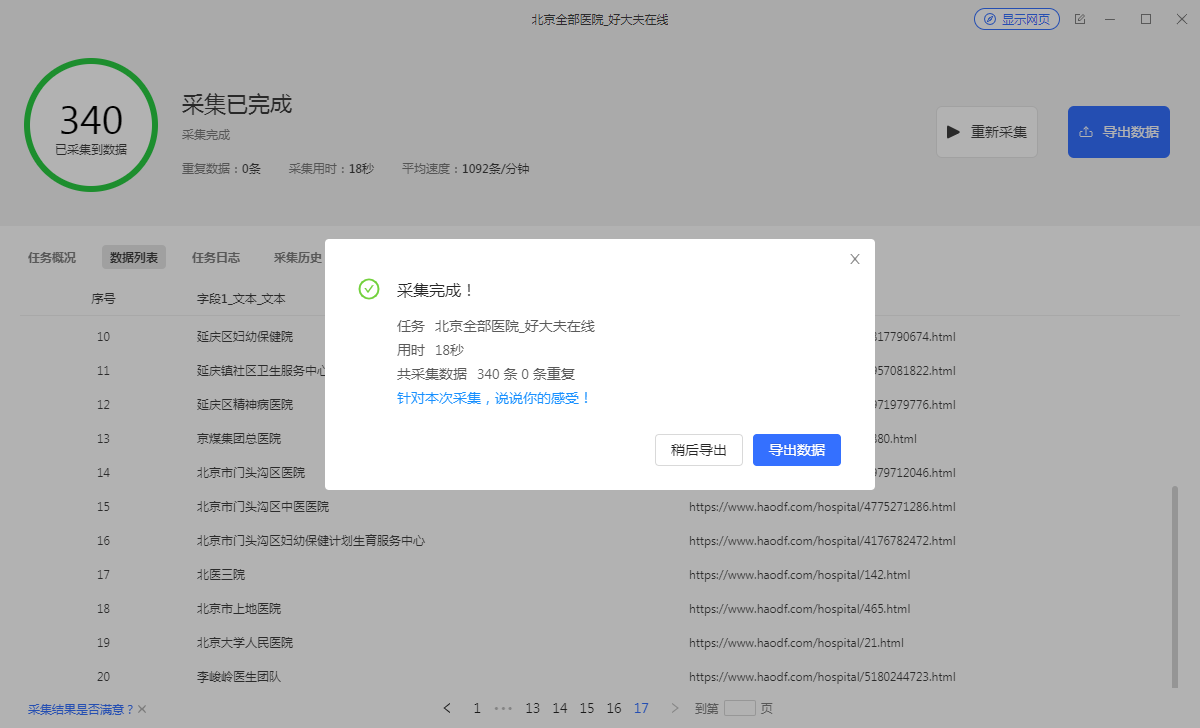
采集后得到的数据:

文章评论