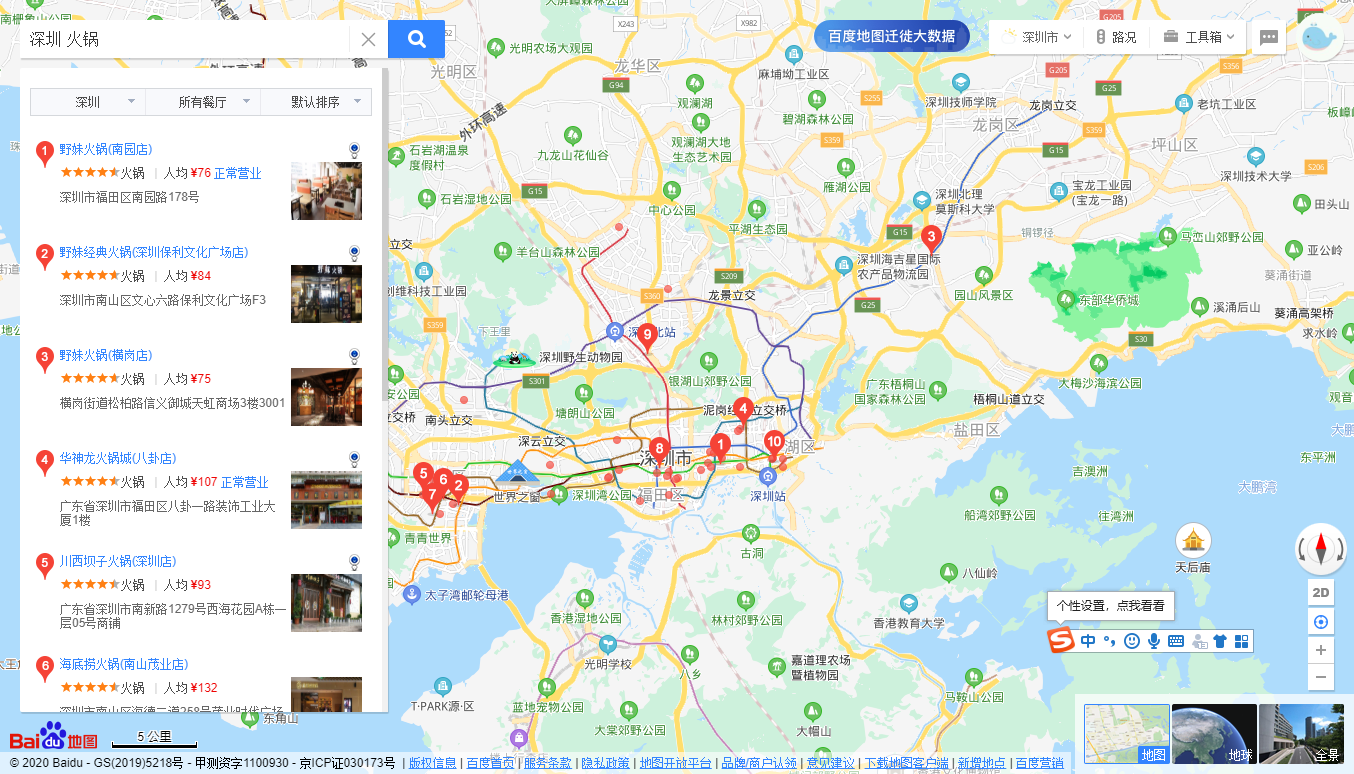
采集场景 在百度地图首页(https://map.baidu.com)输入【城市+关键词】搜索,采集搜索结果列表页。示例中关键词为【深圳 火锅】,可根据需求进行更换,同时支持自动批量输入多个关键词。 采集字段 搜索关键词、商家名称、人均、地址等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/6/16 八爪鱼版本:V8…
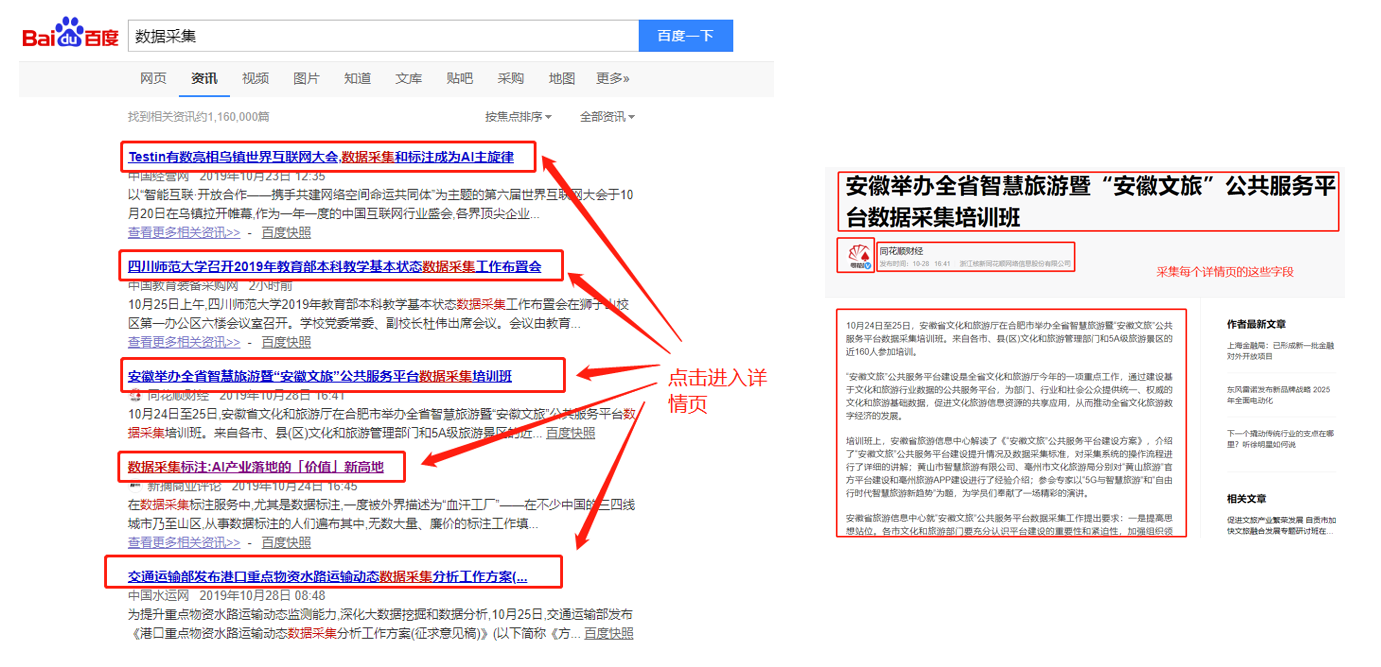
通过前几课的学习,我们已经学会了 采集列表数据、采集表格数据。如果一个页面上很多同类链接,需要依次点击每个链接进入详情页,然后采集每个详情页中的数据呢? 以百度百家号为例。现在有一个百家号资讯列表的网页:https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86&medium=2 可以看到,网页上有很多资讯链接,点击每个资讯链接进入详情页,每个详情页都有…
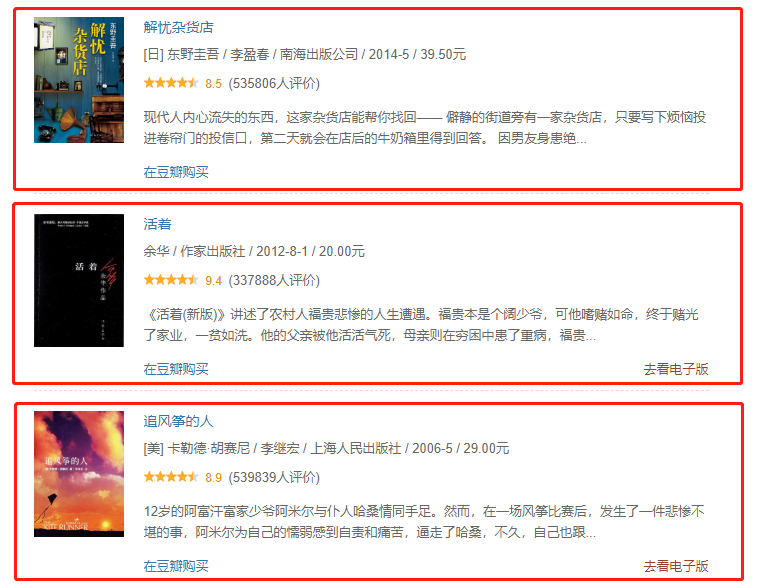
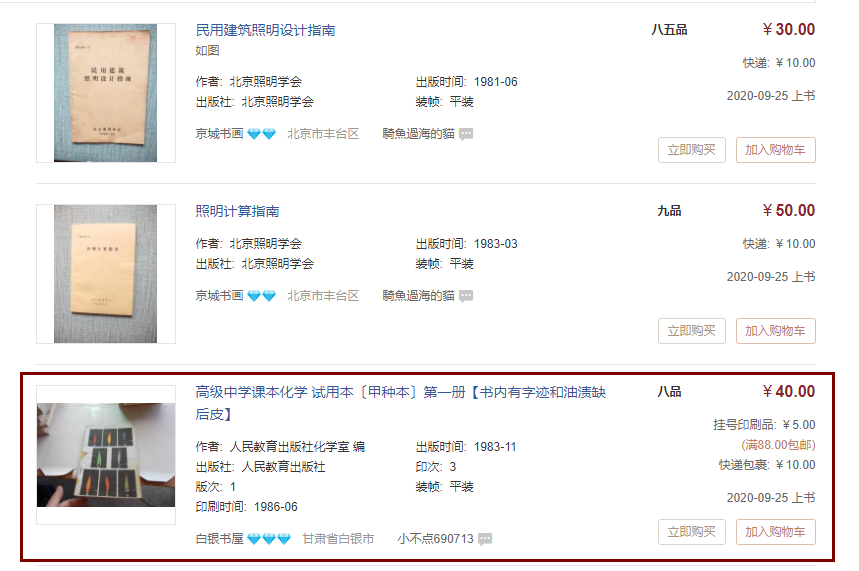
采集场景 孔夫子旧书网有非常多的类目,本教程讲解如何分类目采集图书列表页数据。 示例网址 http://book.kongfz.com/Cjishu/n1004000000/ 是【图书-工程技术-改革开放与80年代】类目的网址。 采集字段 书名、出版社、店铺名称、发货地址、品相、售价等字段。 点击查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/6/08 八爪鱼版本:…
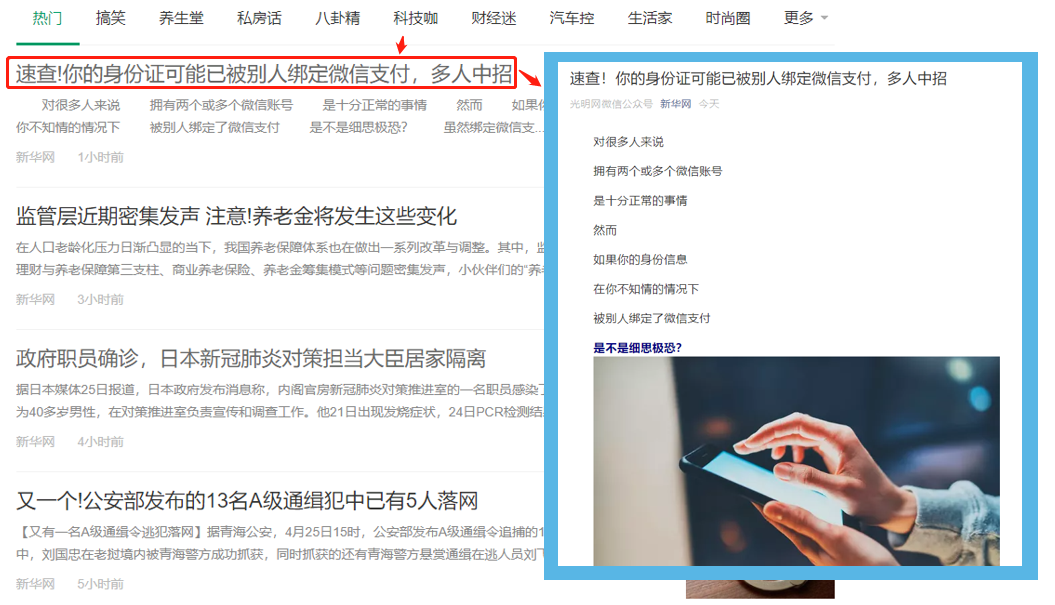
采集场景 进入搜狗微信首页,(https://weixin.sogou.com/),采集【热门】分类下的文章列表数据。同时,点击每一篇文章的链接,进入文章详情页,采集文章正文和图片。 采集字段 标题、文章链接、封面图、简介、来源、发布时间、正文、图片链接。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2020/4/24 …
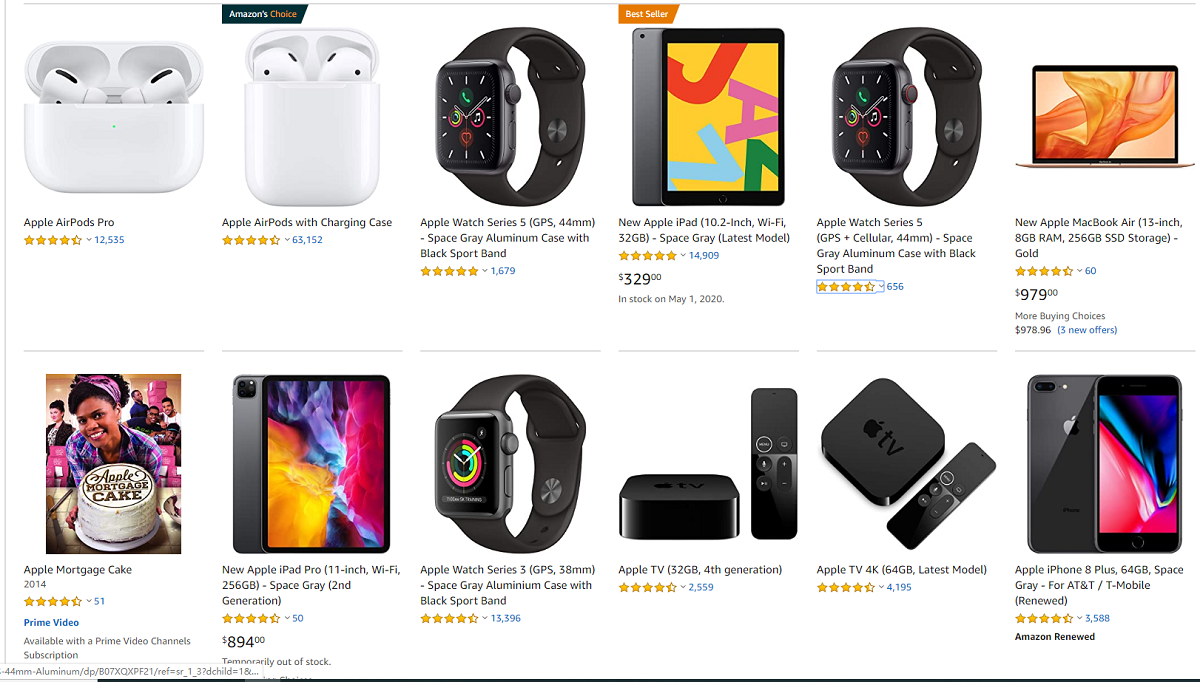
采集场景 在Amazon首页(https://www.amazon.com)输入关键词搜索,采集搜索后得到的商品列表数据。实例网址 https://www.amazon.com/s?k=Apple&ref=nb_sb_noss_2,是搜索关键词 Apple后得到的商品列表页。 采集字段 商品标题、图片URL、商品链接、商品价格、商品评分、评论数等字段。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTM…
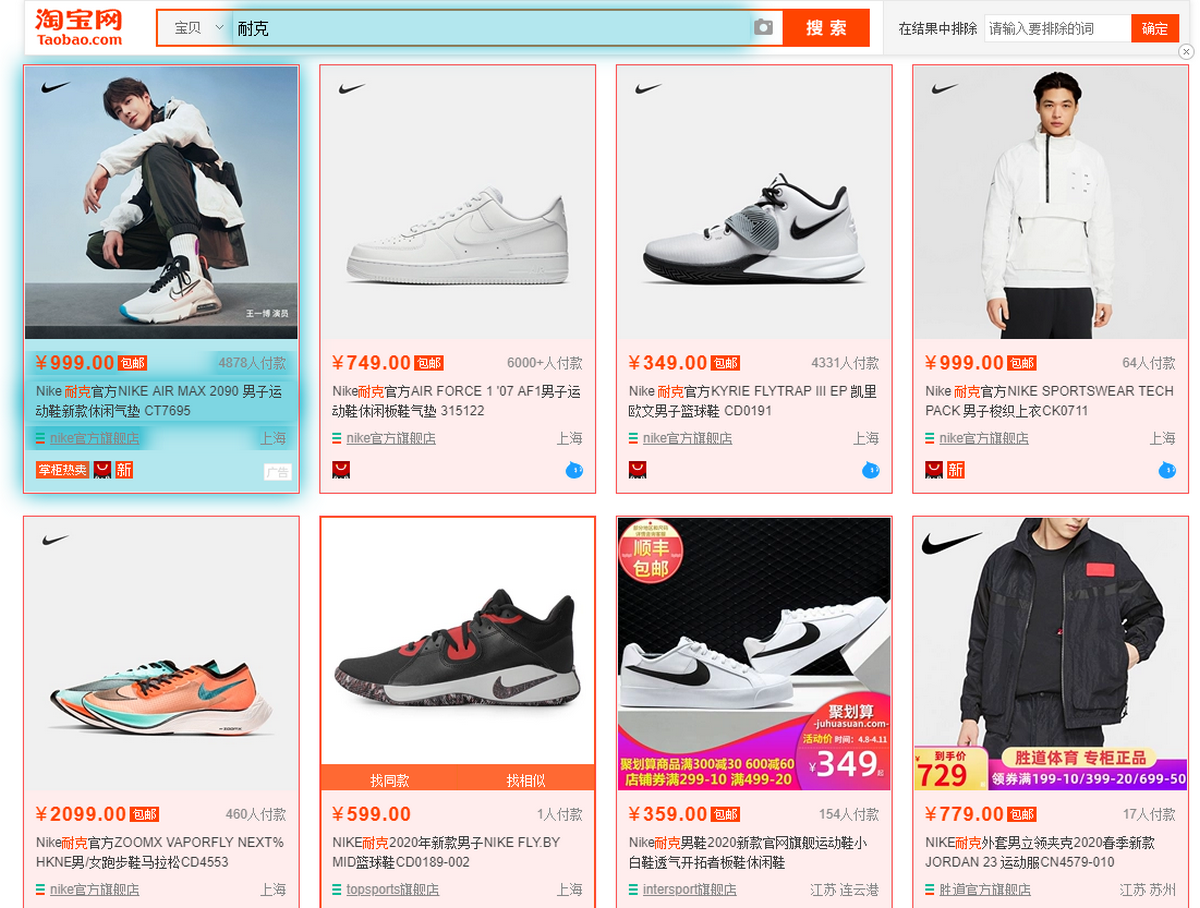
采集场景 在淘宝首页(https://s.taobao.com/)输入关键词搜索,采集搜索后得到的商品列表页数据。示例中关键词为【耐克】,可根据需求进行更换,同时支持自动批量输入多个关键词。 采集字段 采集字段包括关键字文本值,产品标题,店铺名称,产品价格,付款人数,商品链接,店铺名,品牌,发货地等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇…
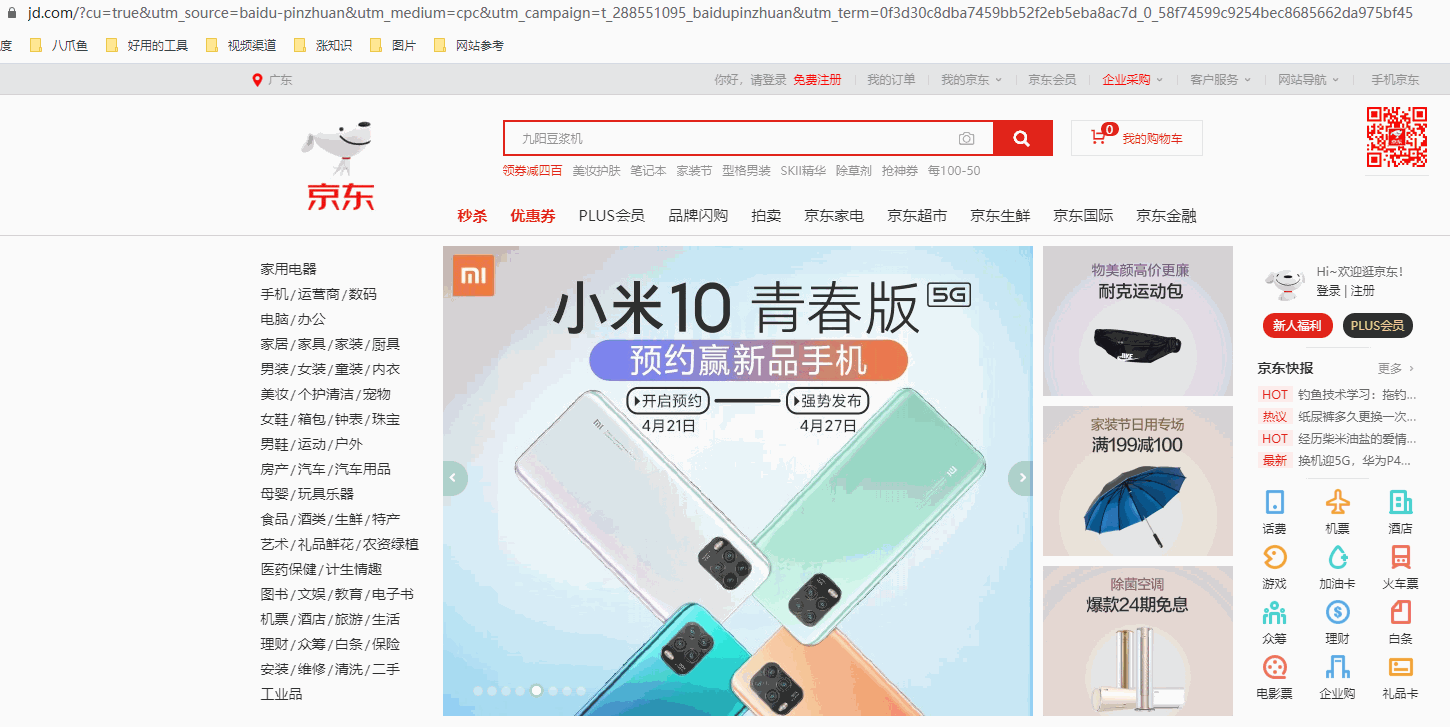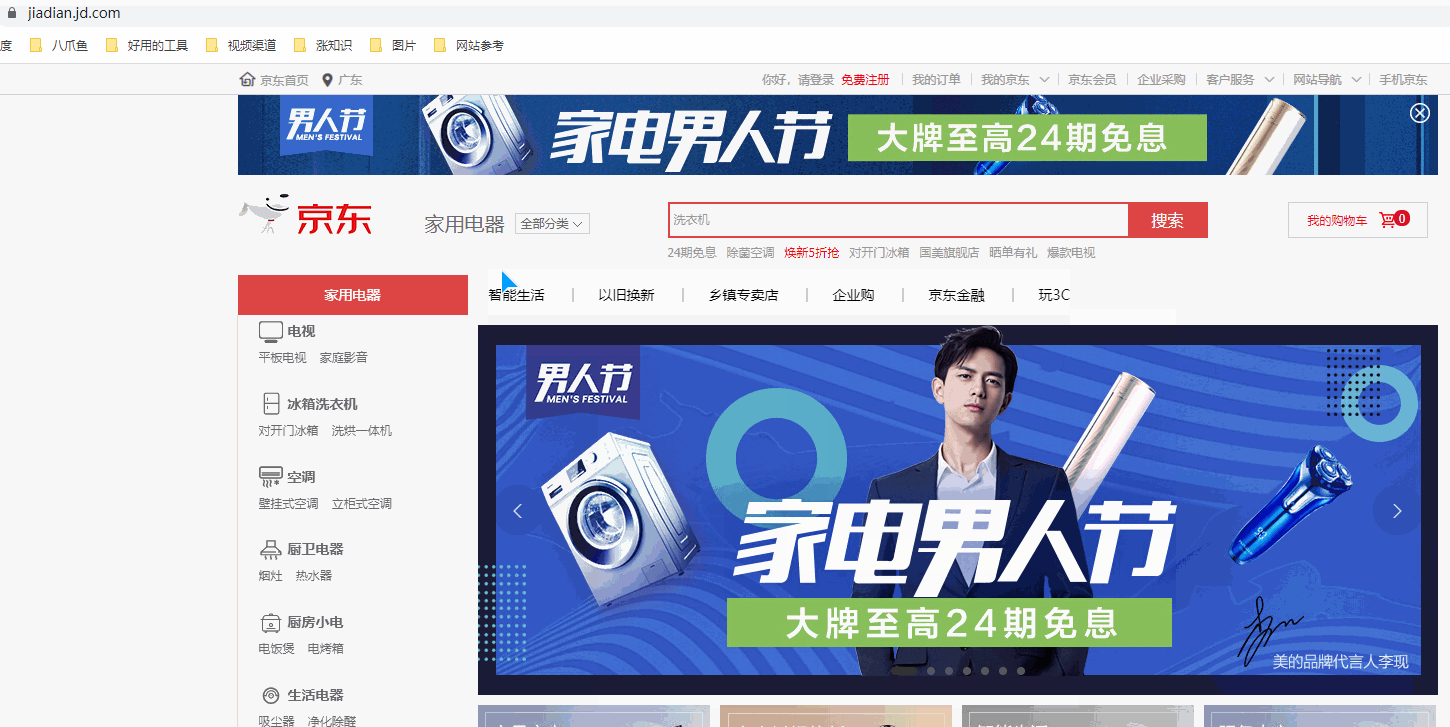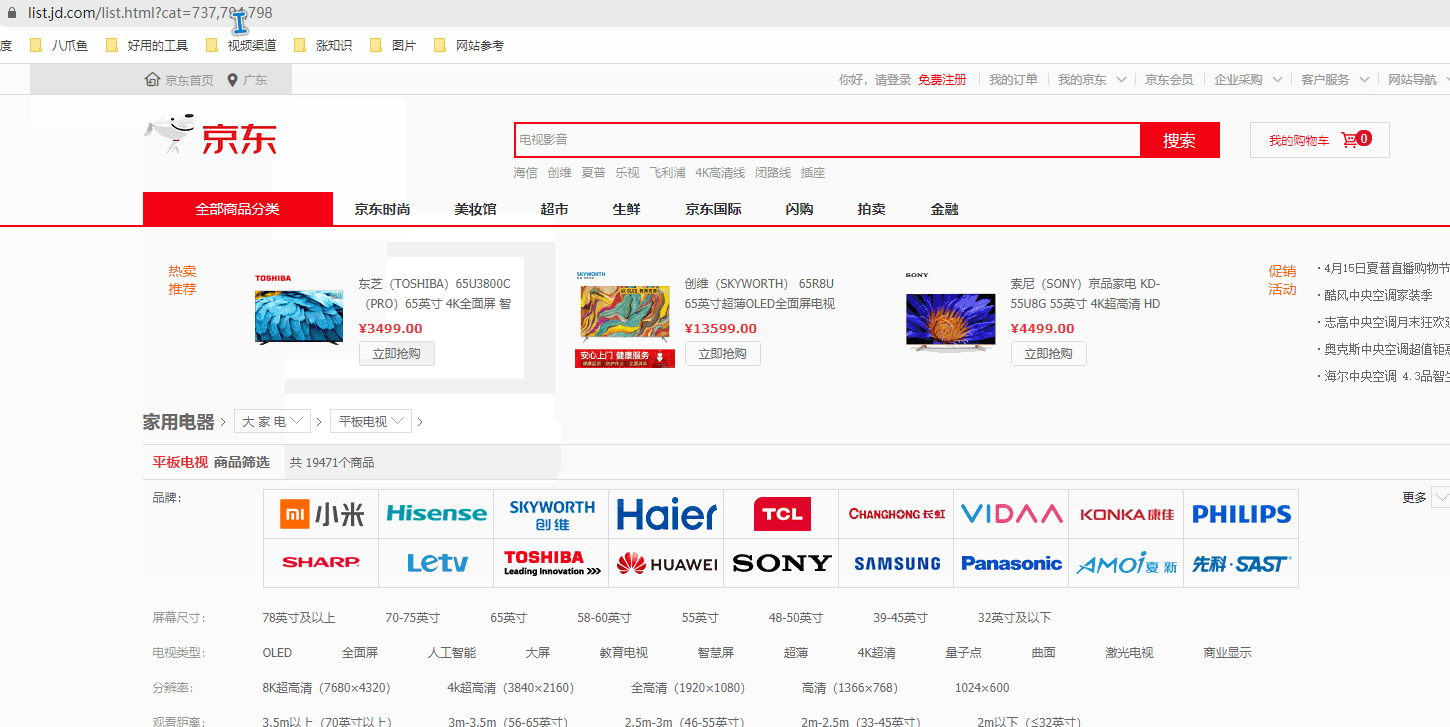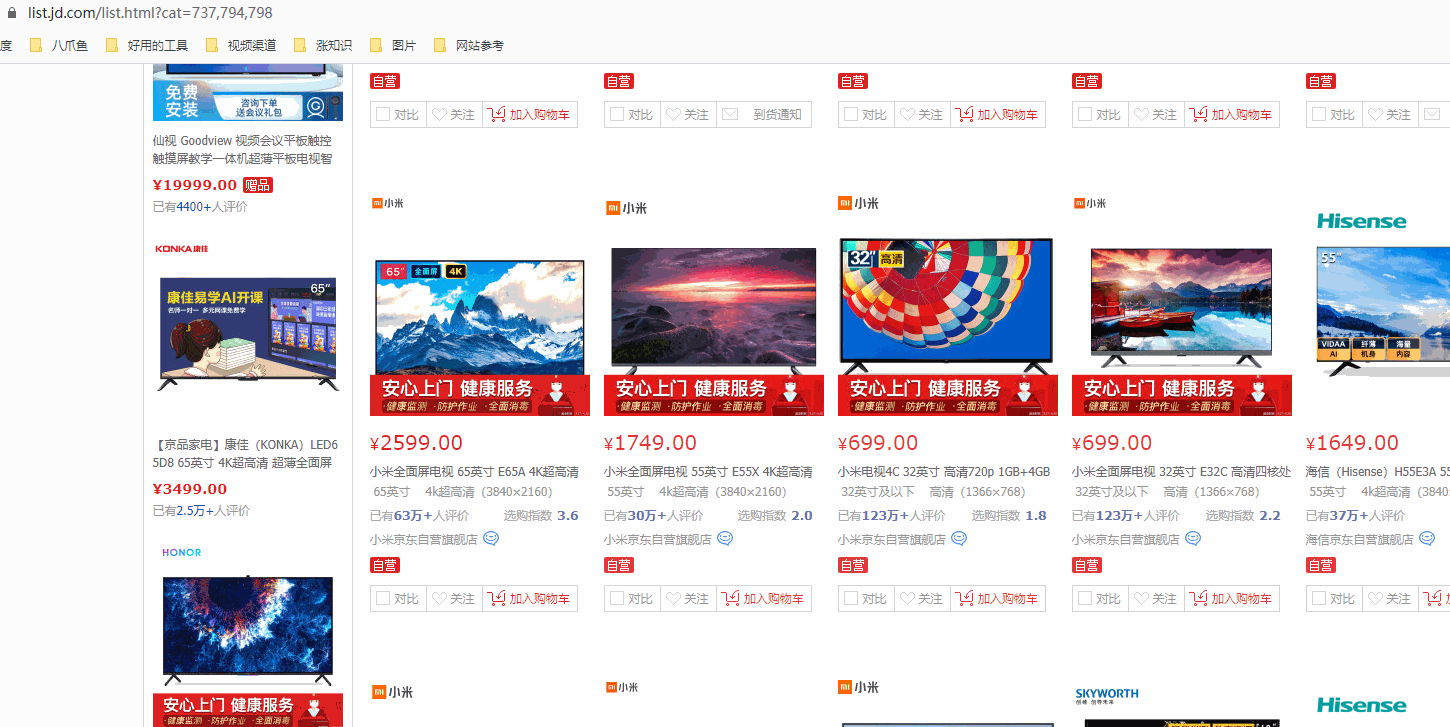
采集场景 京东首页(https://www.jd.com/)有很多商品分类,商品分类共三级。鼠标点击三级分类中的某个具体类别后,跳转到此类别的商品列表,跳转网址以list开头。采集list开头的商品列表数据。 实例:点击【家用电器】-【电视】-【平板电视】这个分类,跳转到【平板电视】分类的商品列表,跳转网址为 https://list.jd.com/list.html?cat=737,794,798 。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集字段 商品…
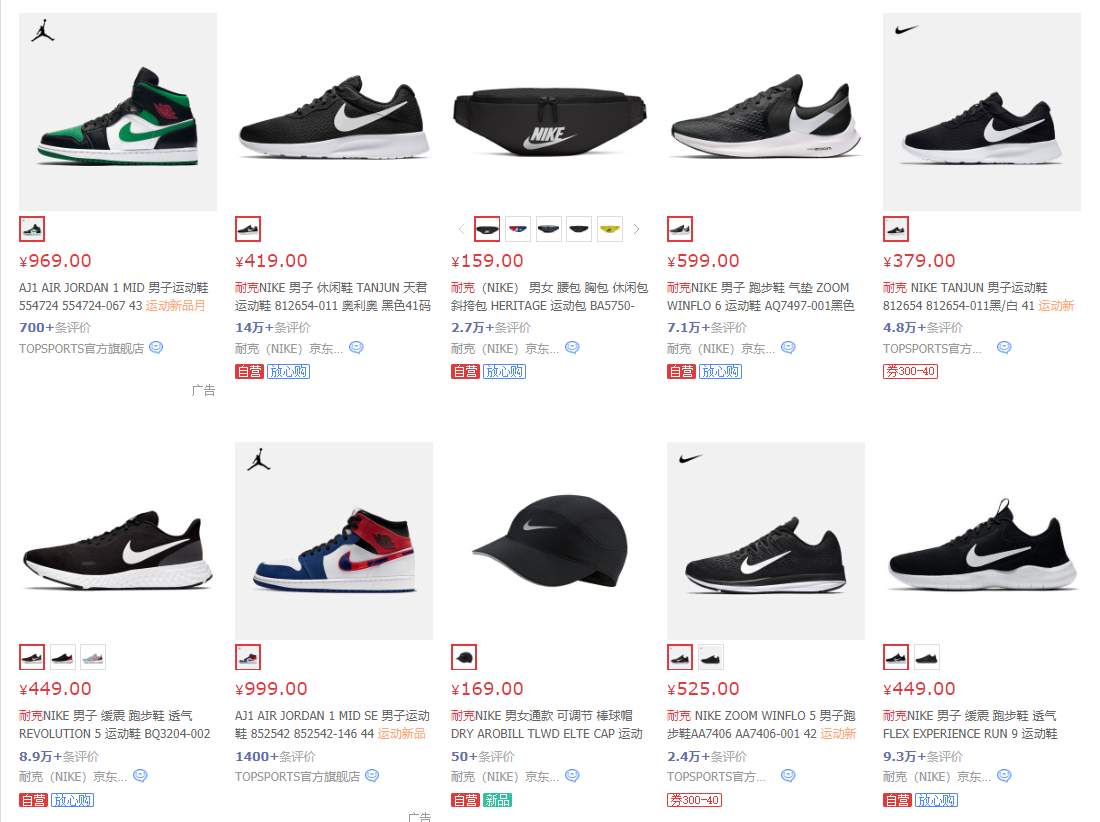
采集场景 在京东搜索页 https://search.jd.com/Search 输入搜索,搜出后得到的多个商品列表数据。 点击图片上,选择【在新标签页中打开图片】即可查看大图 其他图片同理 征地 商品名称、价格、评论数、店铺名称、店铺链接等字段。 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等格式。导出为Excel示例: 教程说明 本篇更新时间:2022/5/10 八爪鱼版本:V8.5.2 如果因网页改版导致网址或步骤无效,无法获取到目标数据,请联系官方客服,我们将及时修…
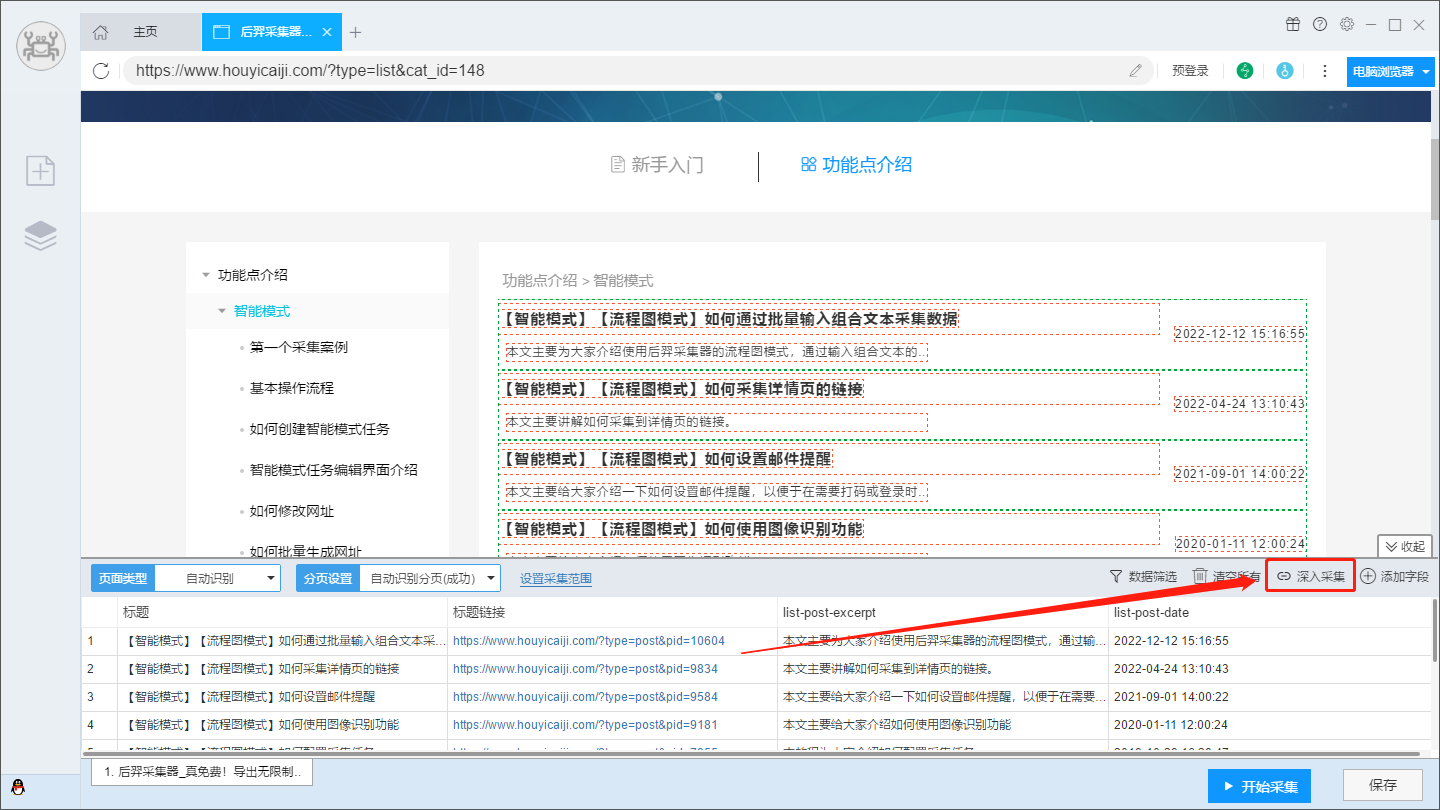
问题: 如何既采集列表,又采集详情中的数据 / 如何采集详情页? 回答: 后羿采集器有深入采集的功能,只需要点击“深入采集”按钮,或者点击已经采集到的链接就能进入详情页进行采集。 具体操作请参考教程: 如何设置深入采集
