
XPath对于八爪鱼数据采集十分重要。绝大多数的数据采集问题,都可以通过写一条正确的XPath解决。
本课将详细讲解XPath相关的问题。
一、HTML 与 XPath
我们日常浏览的网页本质上都是一个个HTML文档。打开网页后,鼠标右键打开菜单,选择【查看网页源代码】,就能看到该网站的HTML文档。网页上的数据,在其HTML文档中都有一个对应位置。
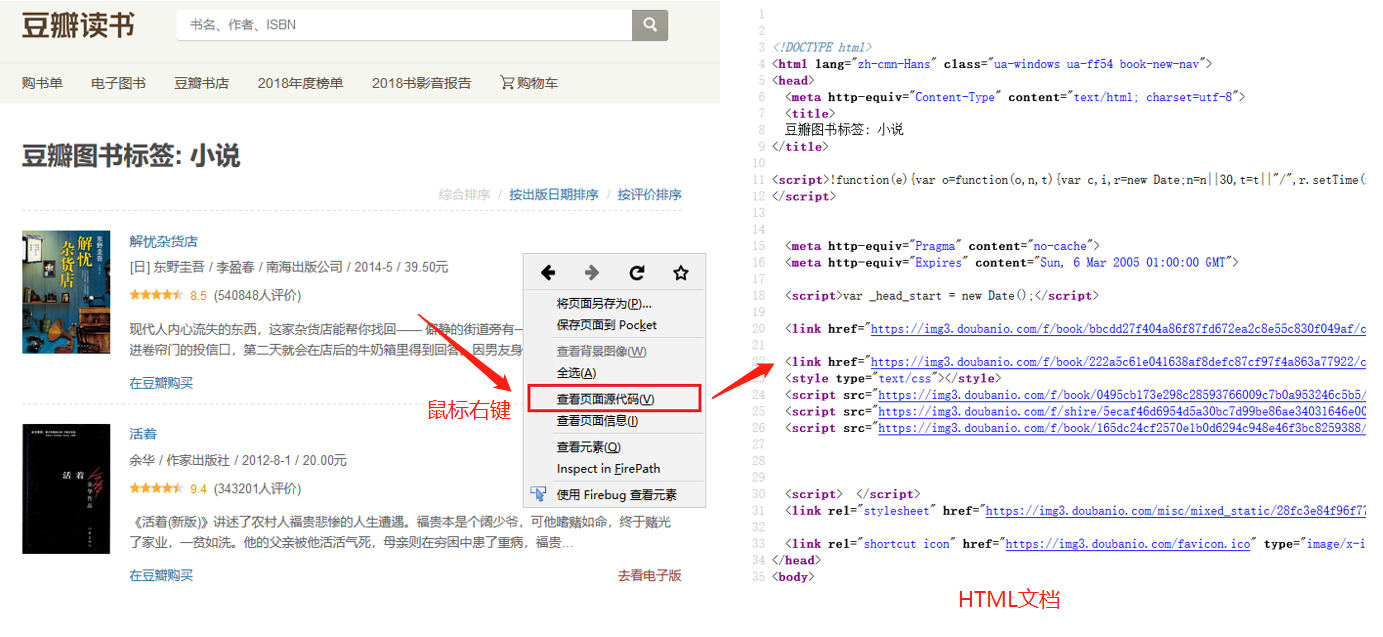
鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
如何在HTML文档中找到想要的数据?XPath是最常用的语言。火狐浏览器的XPath工具,可以帮助普通用户在HTML文档中快速定位到想要的数据,并自动生成定位数据的XPath路径表达式。(点击查看火狐XPath工具安装与使用说明)
XPath工具装好以后,浏览器右上角会出现一个灰色的昆虫图标  ,灰色为未启用状态。点击一下图标变成彩色
,灰色为未启用状态。点击一下图标变成彩色 ,启动XPath工具,出现XPath工具面板。
,启动XPath工具,出现XPath工具面板。
点击XPath工具面板顶部左侧的  按钮,当其状态为
按钮,当其状态为  时,移动鼠标去网页上想要定位的数据位置并点击,XPath工具面板则自动生成定位的XPath路径表达式。
时,移动鼠标去网页上想要定位的数据位置并点击,XPath工具面板则自动生成定位的XPath路径表达式。

此时,要定位的网页数据、定位XPath、HTML文档3者的关系如下:

二、HTML、 XPath 与 八爪鱼
我用八爪鱼采数据?为什么要学XPath?很多人都有这样的疑惑。
八爪鱼采集网页数据,本质上是在HTML文档中采集数据。配置采集任务时,也是使用XPath路径表达式在HTML文档中定位想要的数据。
以配置【循环翻页】步骤为例。在网页上选中【下一页】按钮建立【循环翻页】时,八爪鱼内置的XPath工具自动将【下一页】按钮在HTML文档中的位置找出来,并生成一条XPath路径表达式,记录【下一页】按钮在HTML文档中的位置。
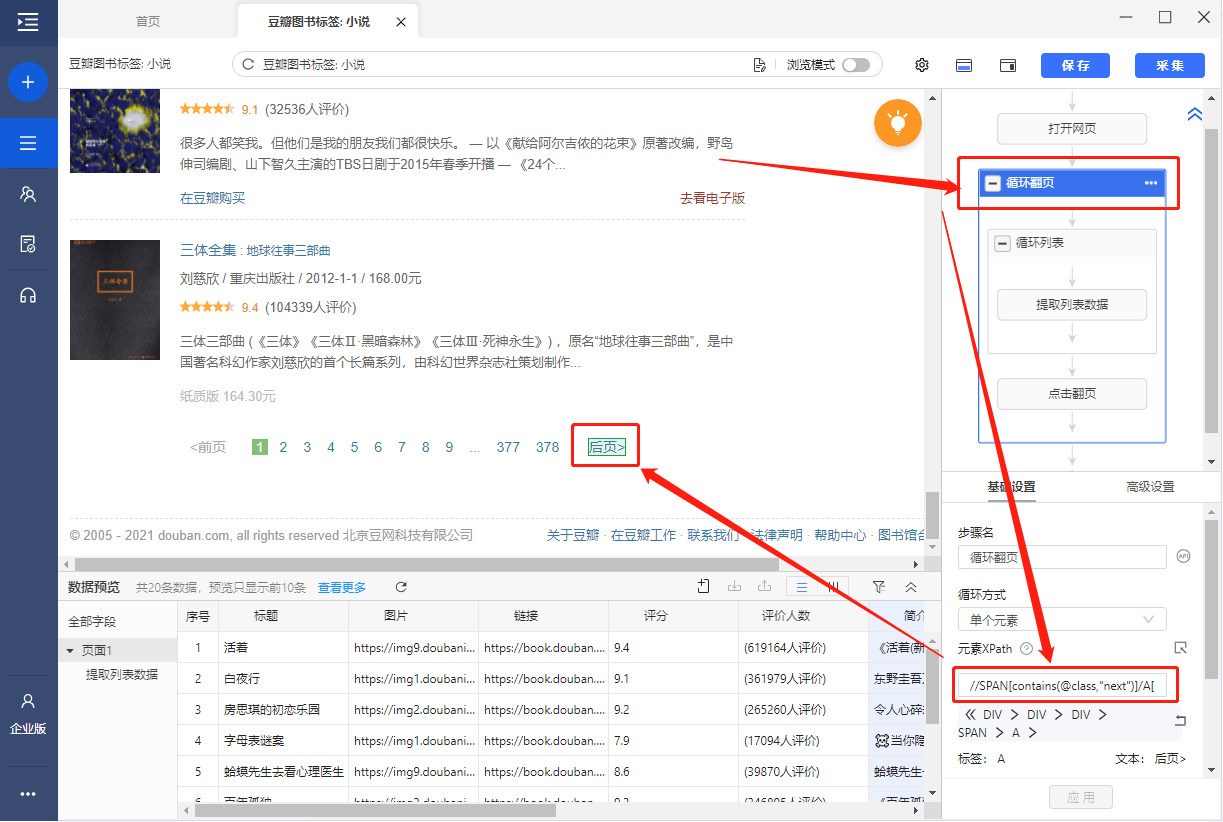
八爪鱼能自动生成定位XPath,为什么我们还要学XPath?还是以【循环翻页】步骤为例。大多数情况下,自动生成的定位XPath没有问题,可正常翻页。少数情况下,自动生成的定位XPath有问题,出现 “直接从第2页跳到最后1页” “在某几页之间重复翻页” 等翻页问题。这时候,我们就需要学习XPath知识,去写一条符合需求的、正确的XPath。
XPath路径表达式是通用的。由于八爪鱼中不方便查看HTML文档,我们通常使用火狐XPath工具去找到正确的XPath,然后再将其复制到八爪鱼中去。
三、认识XPath的结构
先自己自动生成几个XPath,看一下XPath结构有什么规律。几个示例XPath:
.//*[@id='subject_list']/ul/li[1]
.//*[@id='subject_list']/ul/li[1]/div[2]/p
html/body//li[@class='next']/a[1]
我们发现,XPath都具有相似的结构,都由3部分组成。

是的,XPath通过HTML标签和属性查找数据:
标签:html body ul li div p a ......
连接标签的符号:/ //
属性和属性值:[@id='subject_list'] [@class='next']
弄清楚HTML标签、属性及其组合规律,是学会写一条正确XPath的关键。
四、HTML标签、属性与XPath
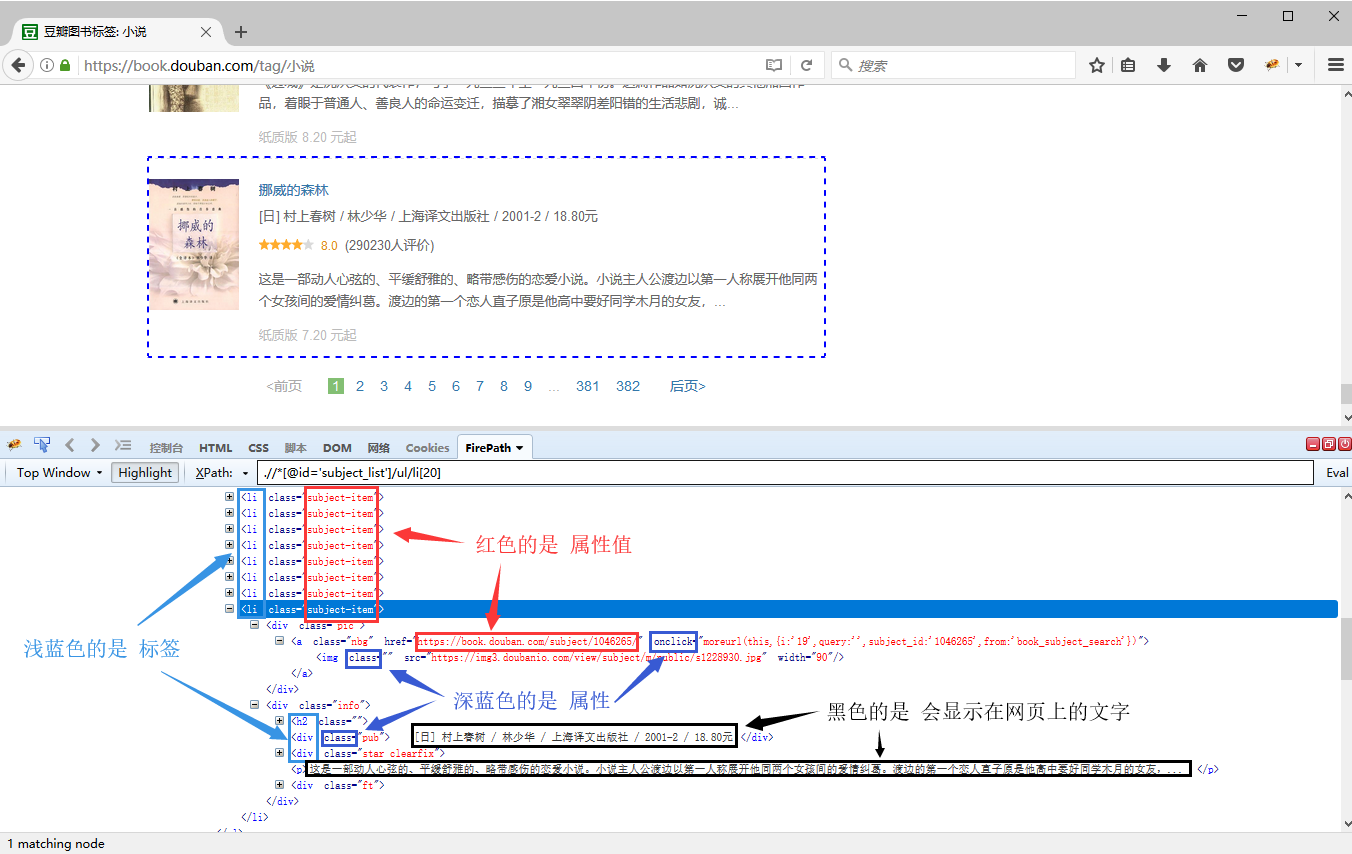
通过火狐浏览器的XPath工具,我们来看一个HTML实例文档。此时HTML文档中各部分十分清楚:
浅蓝色的 html body li div p 等是标签;
深蓝色的 class id href src 等是属性;
引号中的红色部分是属性值;
黑色的文字是会直接显示在网页上的文字。
下面介绍HTML文档中最常见的标签、属性。
1、标签
① 常见标签
<a> </a> 定义超链接,用于从一张页面链接到另一张页面
<p> </p> 段落标记标签
<div> </div> 可定义文档中的区域或节、可以把文档分割为不同的部分,是一个块级元素
<li> </li> 创建列表内容项
<img> </img> 向网页中嵌入一幅图像,从网页中链接图像
<table> </table> 创建一个表格
<tr> </tr> 表格中的每一行
<td> </td> 表格中的标准单元格
② 标签之间的层级
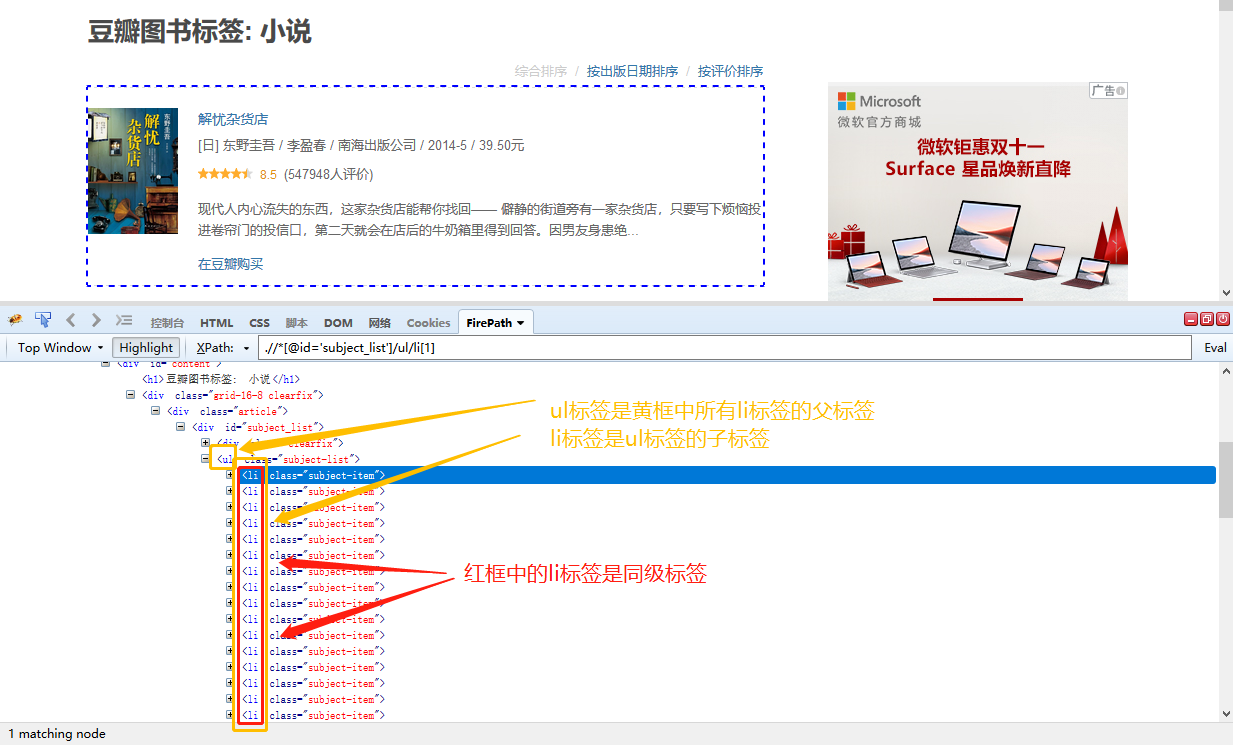
HTML文档是树状结构,标签具有层级,标签之间具有父、子、兄弟的关系。
父(Parent):每个标签都有一个父标签。如下图,ul标签是黄框中所有li标签的父标签。
子(Children):一个标签可有零个、一个或多个子标签。如下图,li标签是ul标签的字标签。
兄弟(Sibling):同级标签,拥有相同的父标签。如下图,红框中的li标签是兄弟(同级)标签。
③ 连接标签
在XPath中,HTML标签用 单斜杠 / 或 双斜杠 // 连接,两者有何不同?
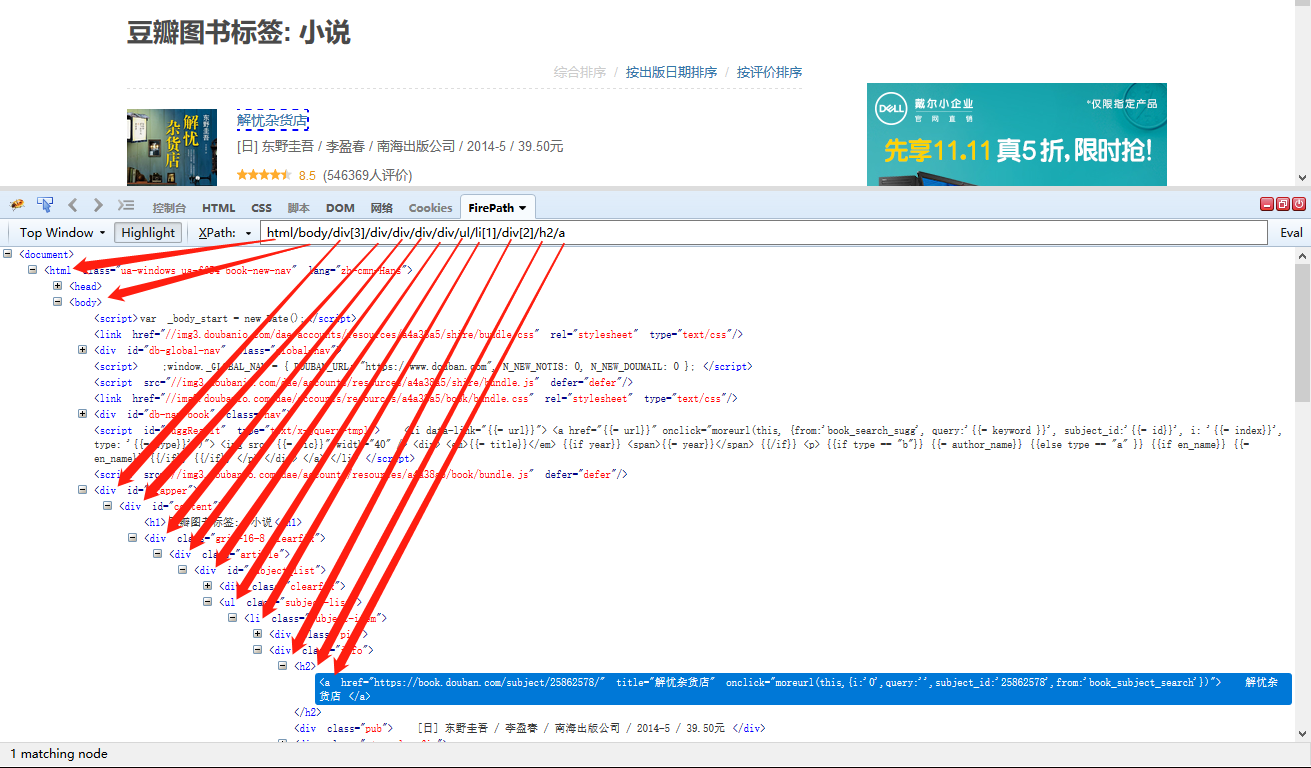
示例网址:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4,我想要定位到第一本书《解忧杂货店》的标题。
/:用绝对路径定位
从根标签开始,一层一层往下定位,直到标题所在的位置,不可跨层级。
实例写法为:html/body/div[3]/div/div/div/div/ul/li[1]/div[2]/h2/a 。
可以看到,此种定位方法很死板,一旦中间的层级发生改变,整条定位XPath就失效了。比如,另一个相似网页,在ul前多了一个div,那以上XPath html/body/div[3]/div/div/div/div/ul/li[1]/div[2]/h2/a 就会失效,找不到【标题】这个目标数据。
特别说明:
a. 标签后紧跟的[1]、[2]、[3]是序号。[1]表示选择同级标签的第1个。[2]、[3]以此类推。
b. 在火狐浏览器的XPath工具中写好定位XPath以后,需按一下键盘上的【回车】键,工具就会自动定位并提示满足定位条件的结果有多少个。
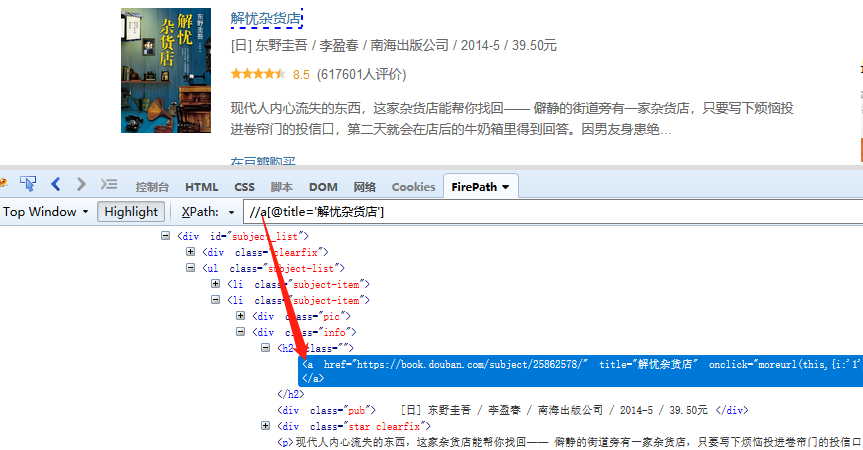
//:用相对路径定位(推荐)
直接找到标题所在层级的标签和属性定位,可以跨层级。
实例写法为://a[@title='解忧杂货店']
这种定位方法就比较灵活,因为它是直接用目标标签的属性定位的,属性一般不发生改变。还是上面那个例子,另一个相似网页,在a标签前多了一个div标签,//a[@title='解忧杂货店'] 这条XPath依旧有效,多了一个div标签并不对其造成影响。只要源码中存在 title 为 解忧杂货店 的 a 标签,就能直接定位到。
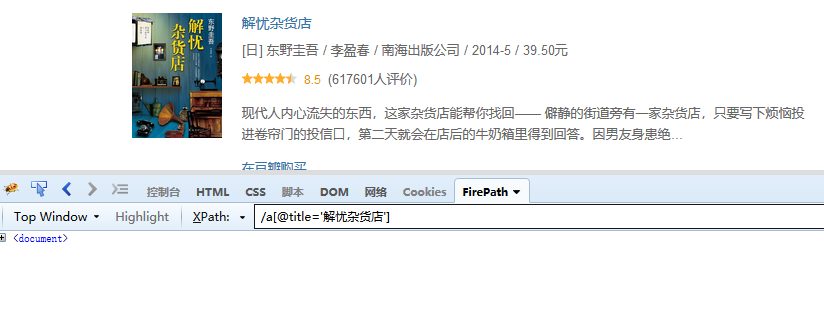
注意:因为这里是跨层级定位到a标签,所以需要用 //。如果将 // 换成 / ,XPath 写作 /a[@title='解忧杂货店'],则定位不到标题。
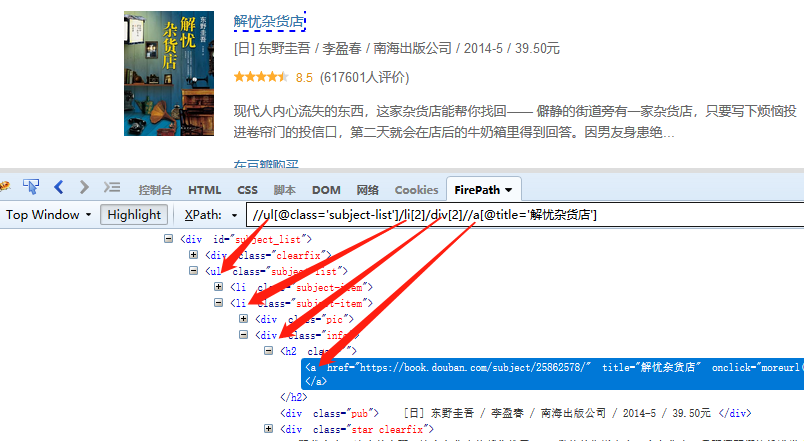
/ 和 // 是可以组合使用的,本质上是需要把握好标签之间的层级关系,请根据网页情况灵活使用。
2、属性
① 常见属性
class 规定元素的类名,大多数时候用于指定样式表中的类
id 唯一标识一个元素的属性,在html里面必须是唯一的
href 指定超链接目标的url
src 图像文件的url(直接复制到浏览器中,可打开图片)
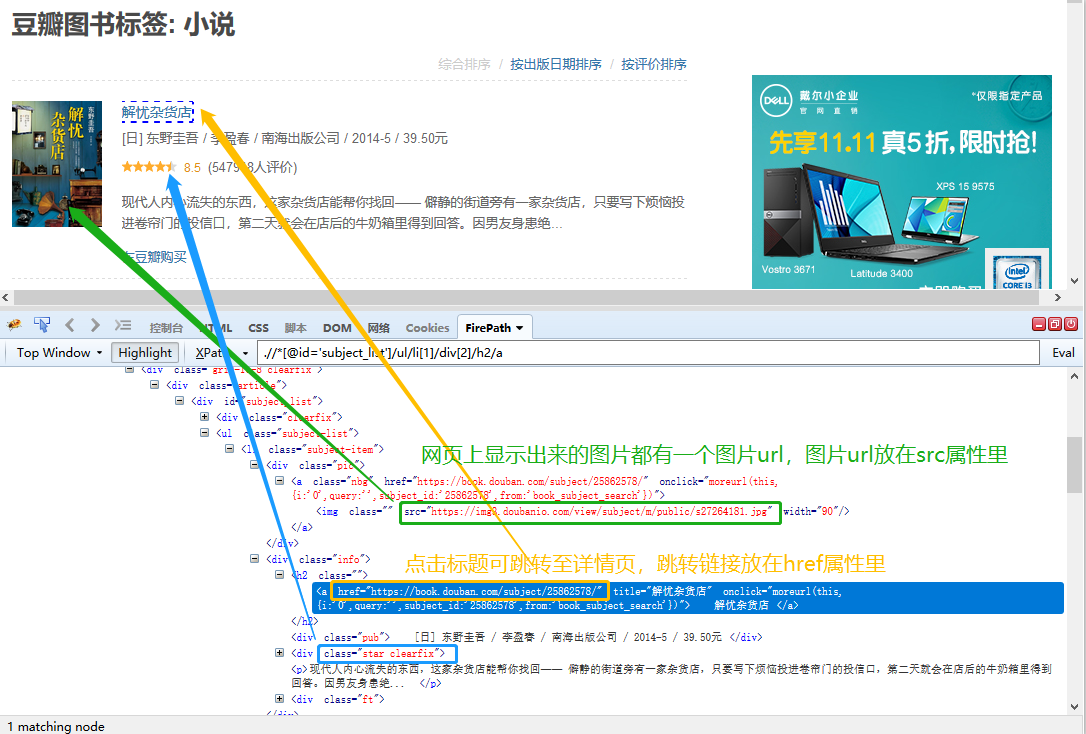
关于属性,我们不用明白每一个属性的属性值到底是什么意思,只需根据定位需求,找到标签的属性/属性值的相同/不同之处,以实现精准定位。
② 属性和标签的关系
属性是用来修饰标签的。XPath中,属性和属性值有固定写法:属性放在标签后面的[ ]里,属性前加@,属性值放在引号内。
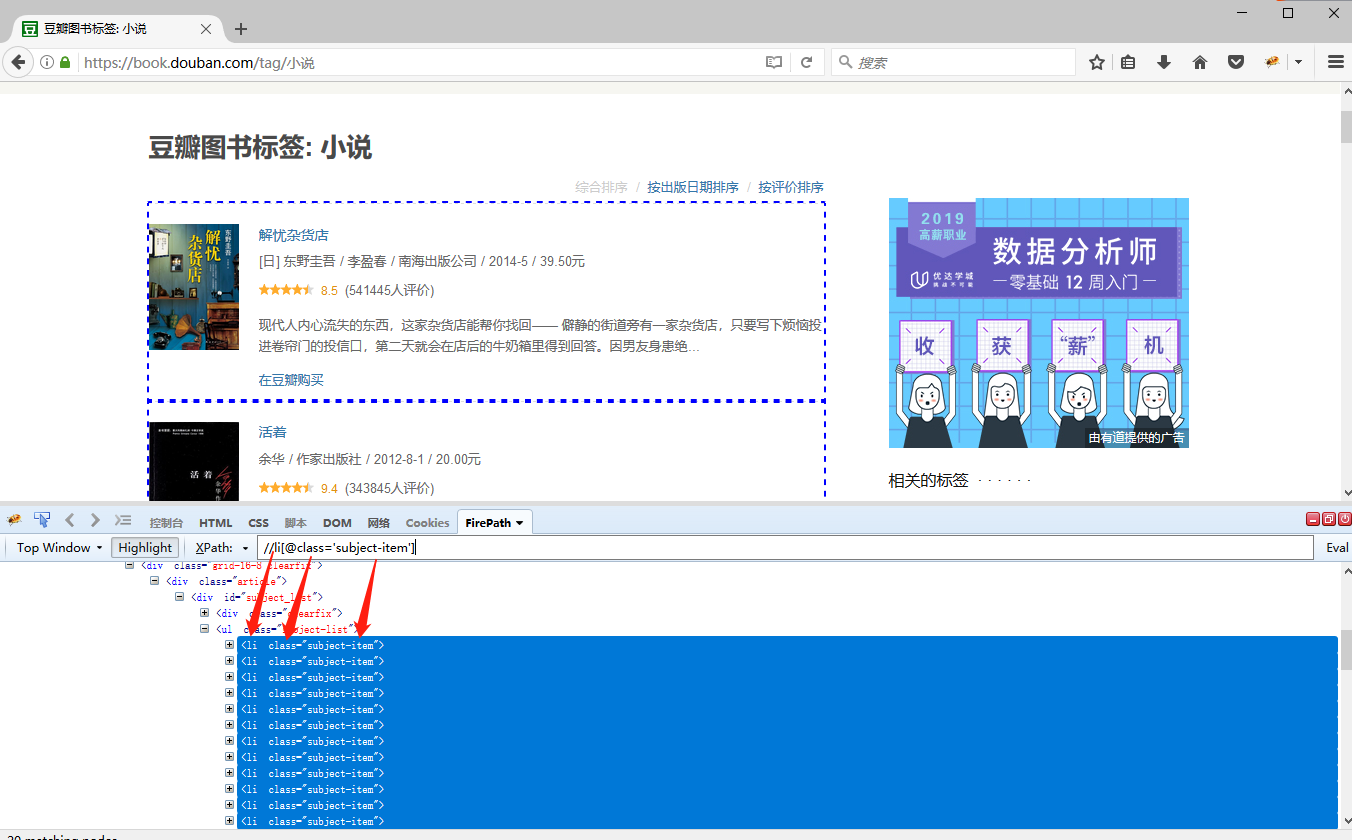
例://li[@class='subject-item']。
这条XPath的意思是,定位HTML文档中 所有 class 属性值为 subject-item 的 li 标签。
3、常用的XPath函数
网页情况十分复杂,仅通过标签和属性,难以将我们需要的数据精准定位出来。XPath有一套XPath函数,便于我们更精准定位。
下面是一些常见XPath函数,在八爪鱼数据抓取中应用十分广泛,请大家认真学习。
在开始学习XPath函数之前,有2点特别强调:
XPath函数有其固定写法,请遵循其固定写法;
XPath中的所有符号() [] ''均为英文符号,不可用中文符号。
以下示例网址均为:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4
① text() 用文本定位位置
text()='xxx' 精确定位,引号中的内容需与HTML文档中的文本完全一样
contains(text(),'xxx') 模糊定位,HTML文档中的文本,包含引号中的内容即可
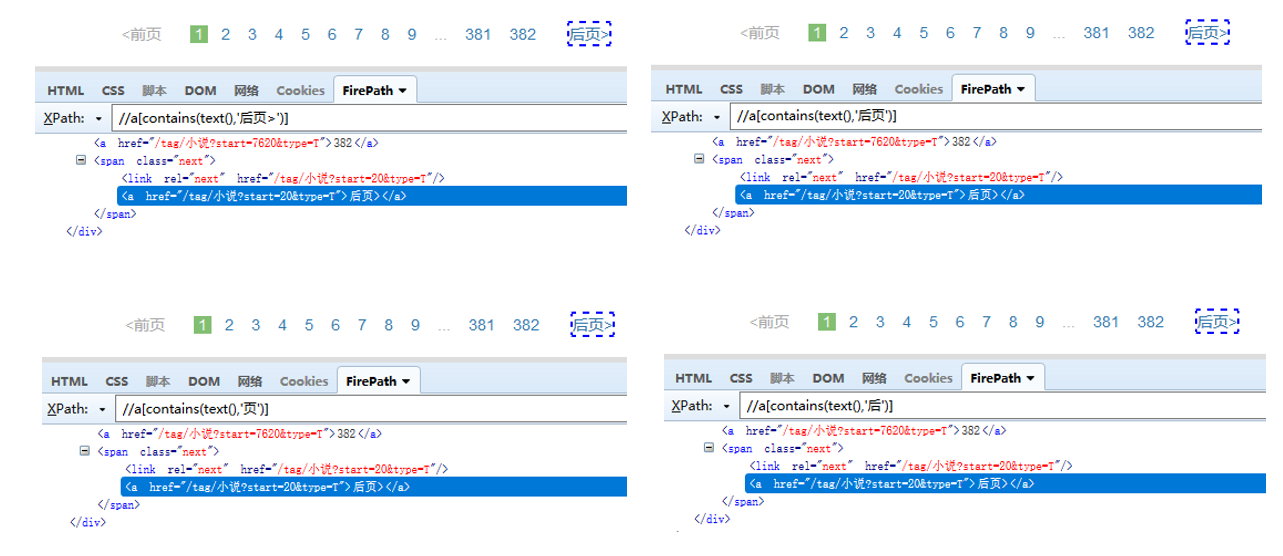
如果需要定位到此网页中的【后页>】按钮。
用 text()='xxx' 定位,则XPath为://a[text()='后页>'] ,引号中的文本一定要为 '后页>',如果换成 '后页' (少了一个>),则定位不到【后页>】按钮。

用 contains(text(),'xxx') 定位,则XPath为://a[contains(text(),'后页>')] ;//a[contains(text(),'后页')] ;//a[contains(text(),'页')] ;//a[contains(text(),'后')] 均可(包含文本中相连的一段字符即可,不用全部复制)。
② contains() 用于判断文本的一部分是否包含XXX,或者属性值是否包含XXX
contains(text(),'xxx') 判断文本的一部分是否包含XXX,上面已经详细说明
contains(@class,'xxx') 判断属性值是否包含XXX
如果需要定位到此网页中的所有图书列表。
直接用属性定位,则XPath为://li[@class='subject-item'] ,引号中的属性值一定要为 'subject-item',跟HTML文档中的属性值完全一致。
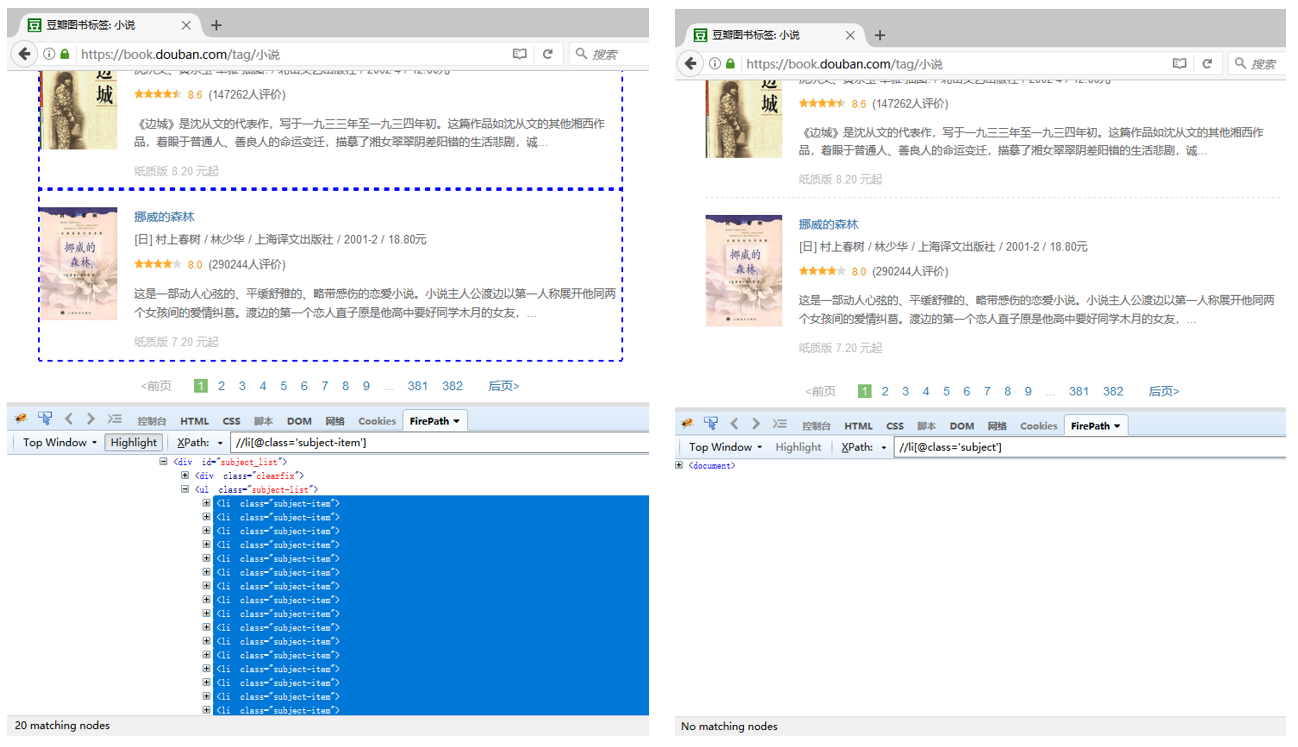
如果用 contains(@class,'xxx') 定位 ,则XPath为://li[contains(@class,'subject-item')];//li[contains(@class,'subject')] 均可(包含属性中相连的一段即可,不用全部复制)。
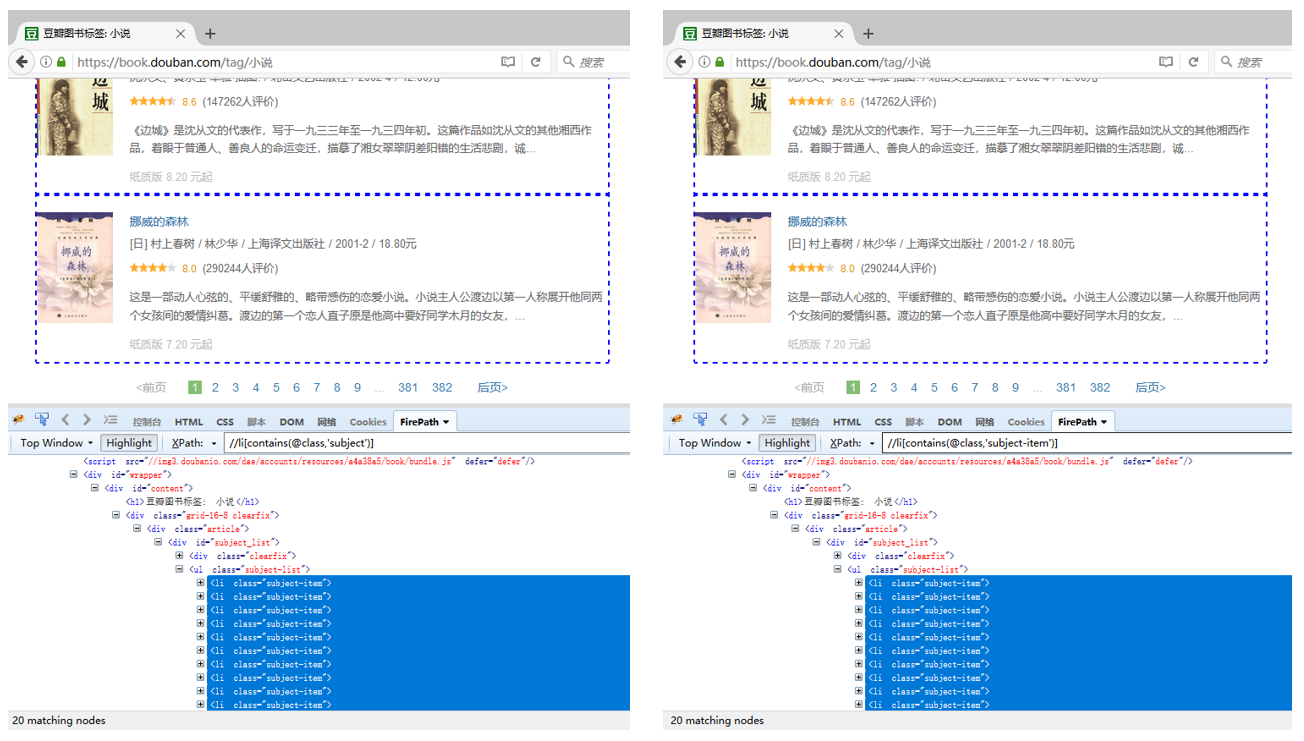
③ position() 用于定位节点的位置和限制节点的范围
position()=1 同级标签的第1个
position()>1 and position()<10 同级标签的第2-9个
常用于控制循环列表的项。如图,//ul[@class='subject-list']/li[position()>1 and position()<10],定位的是第2-9个li标签。
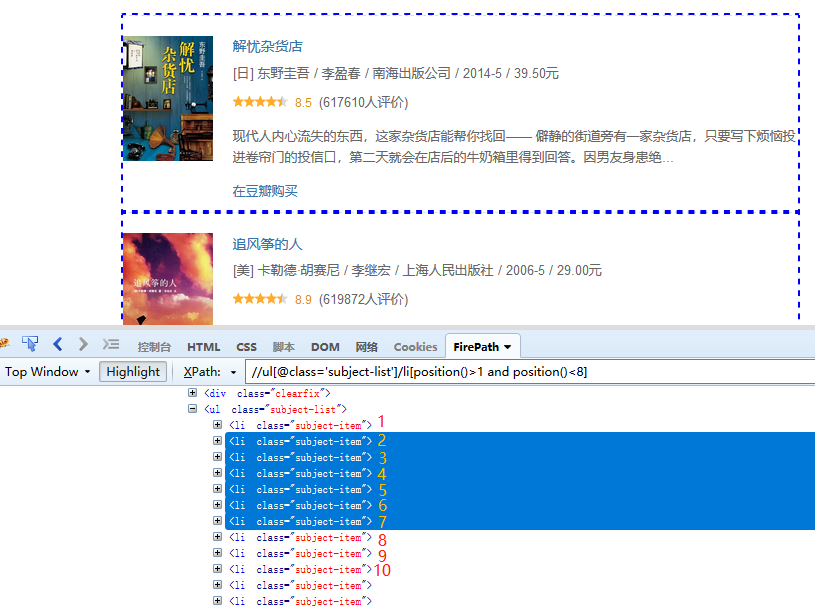
④ last() 最后1个
last() 最后1个标签
last()-1 倒数第2个标签
last()-2 倒数第3个标签
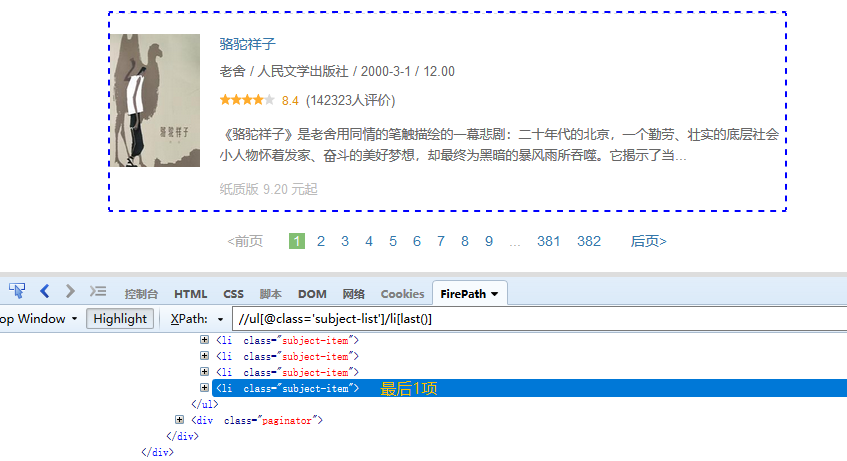
如图,//ul[@class='subject-list']/li[last()],定位的是最后1个li标签。
⑤ and/or/not 同时满足/满足其中1个即可/无
and 且,同时满足 a[@class and @href] 既有class属性,又有href属性的a标签
or 或,满足其中1个即可 a[@class or @href] 有class属性,或者有href属性的a标签
not 无 a[not(@class)] 不含class属性的a标签
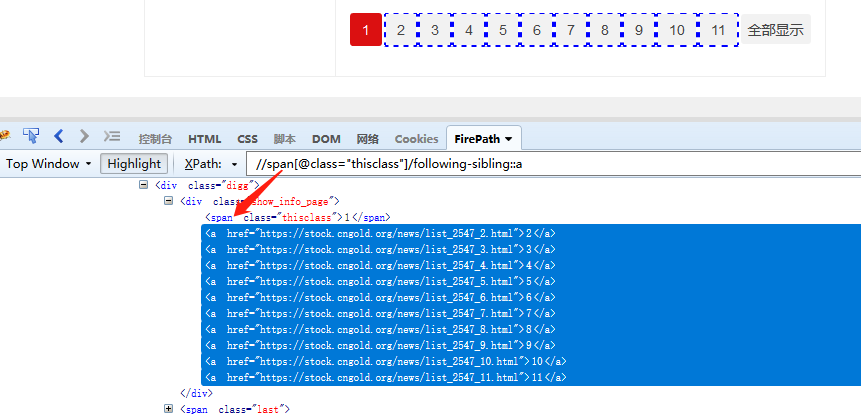
⑥ following-sibling:: 选取当前节点之后的所有同级节点
在八爪鱼中常用于数字翻页,点击查看 数字翻页教程。
如图,//span[@class="thisclass"]/following-sibling::a ,定位到span节点之后的所有同级a节点
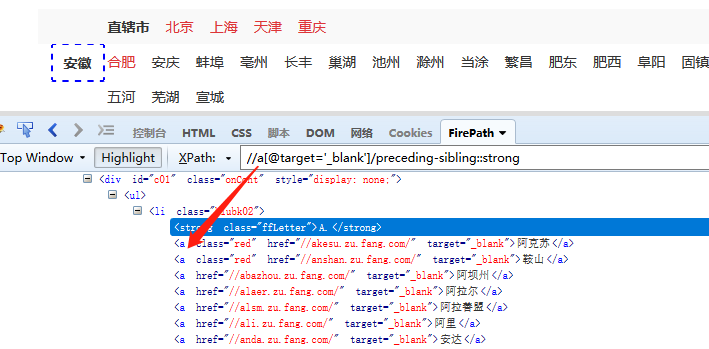
⑦ preceding-sibling:: 选取当前节点之前的所有同级节点
如图,//a[@target='_blank']/preceding-sibling::strong ,定位到a节点之前的所有同级strong节点
五、实战演练
题1:采集以下网址,全部的列表数据。
http://newhouse.sz.fang.com/house/s/b91/?ctm=1.sz.xf_search.page.1

2、按需求编辑采集下来的字段,如图。
3、启动采集,我们发现,有非常多的重复数据。观察重复数据发现,是从第2页后开始重复的。为什么?
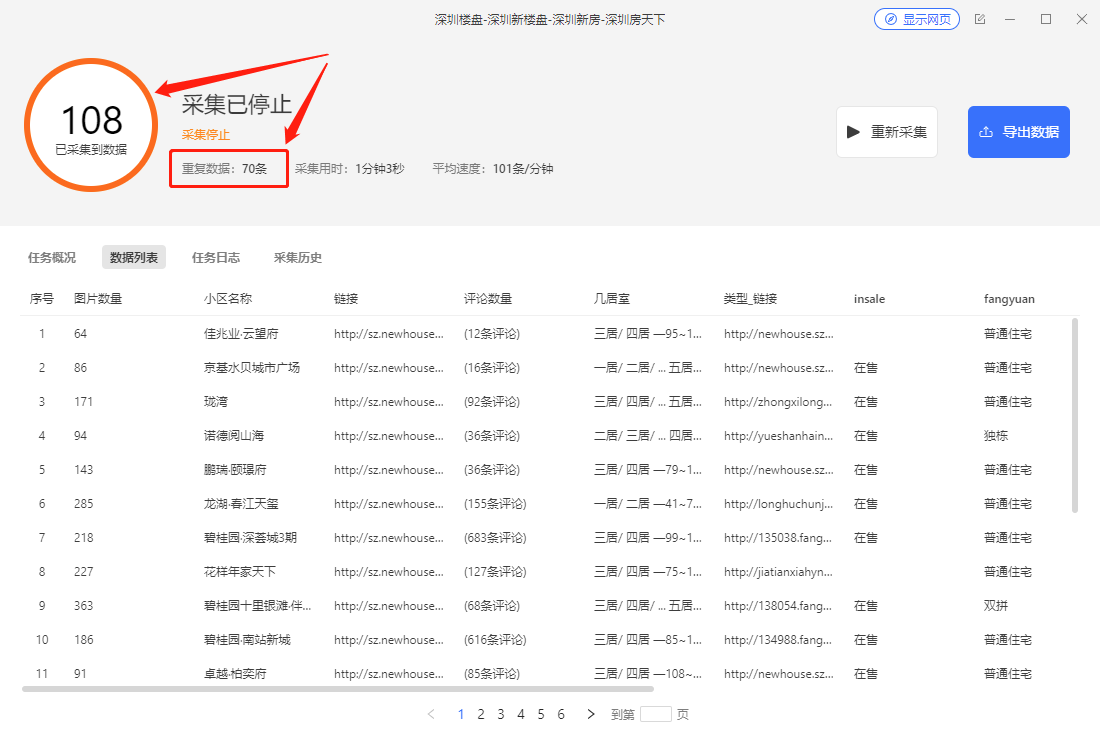
4、找到规则中,翻页的XPath://a[@class="next"] ,并将其复制下来。
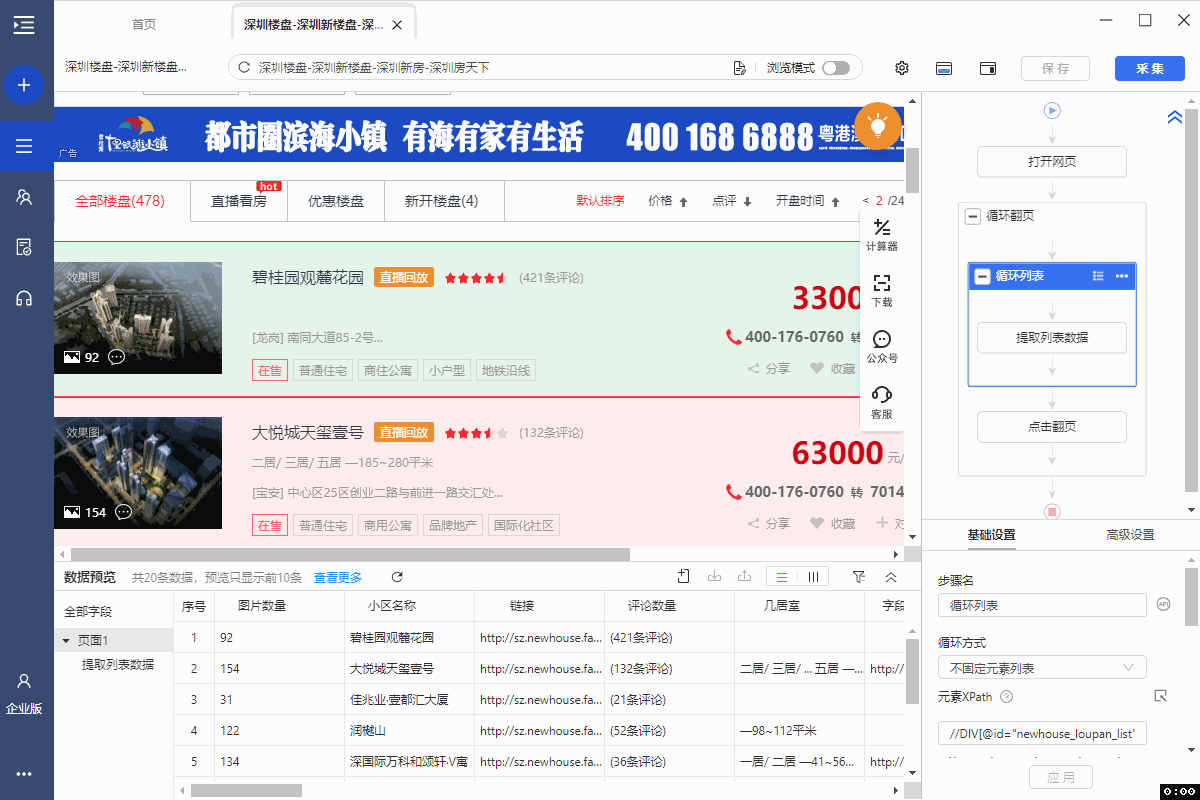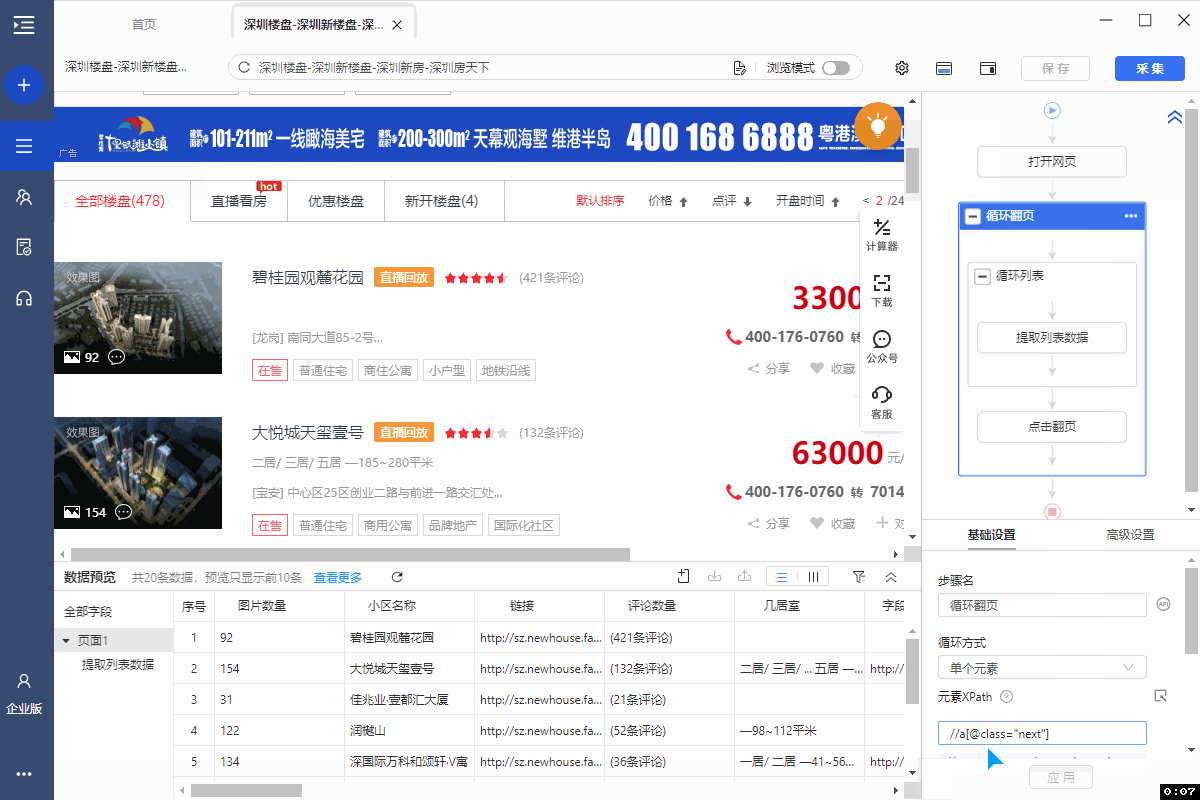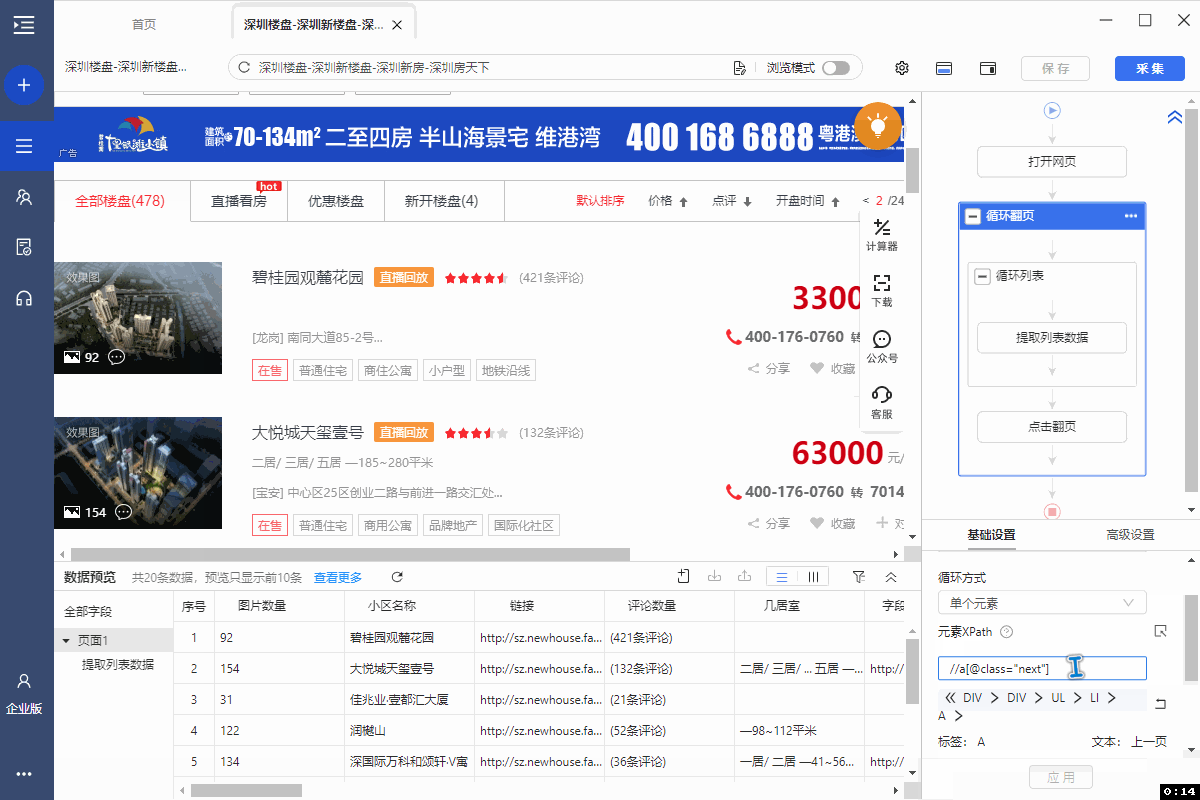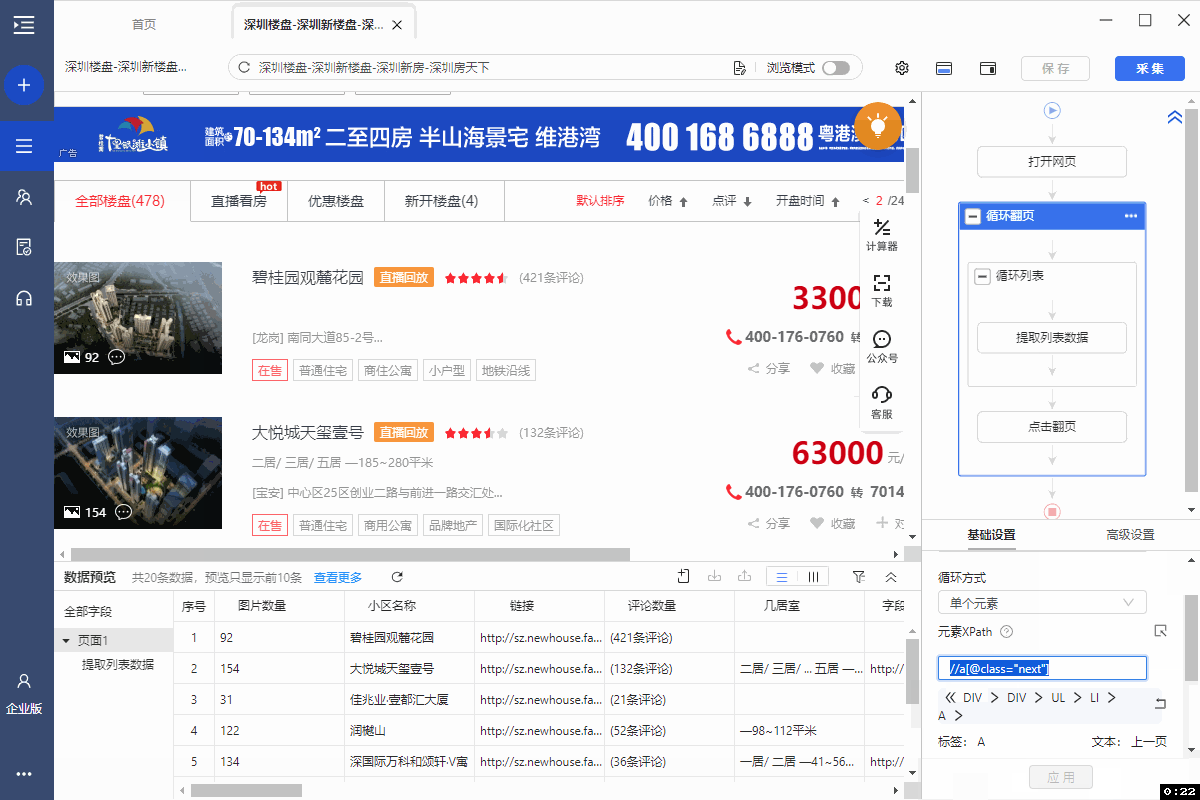
5、将翻页的XPath://a[@class="next"] 复制进火狐浏览器的XPath工具中并开始调试。第1页,通过 //a[@class="next"] 定位到的是【下一页】按钮,没问题。但是第2页出问题了,通过//a[@class="next"] 定位到【上一页】和【下一页】2个按钮,因【上一页】按钮在前,会先执行前一个。因此,在第2页的时候,会点【上一页】回到第1页,翻页就无法正常进行了。
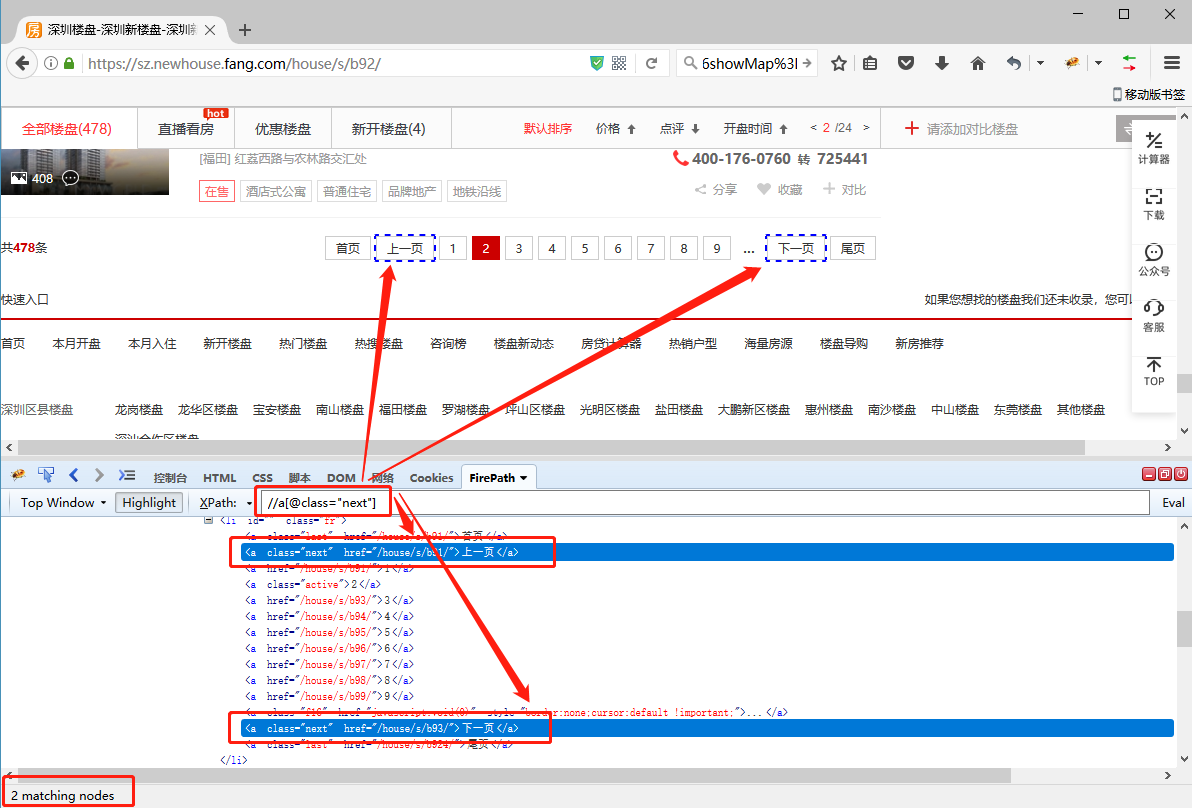
我们需要在第2页(应该说是除最后1页的所有页)都只定位到【下一页】按钮,对吧?XPath怎么改?观察第2页中,【上一页】和【下一页】按钮的源码区别。很明显,文字不同,一个是【上一页】,一个是【下一页】。
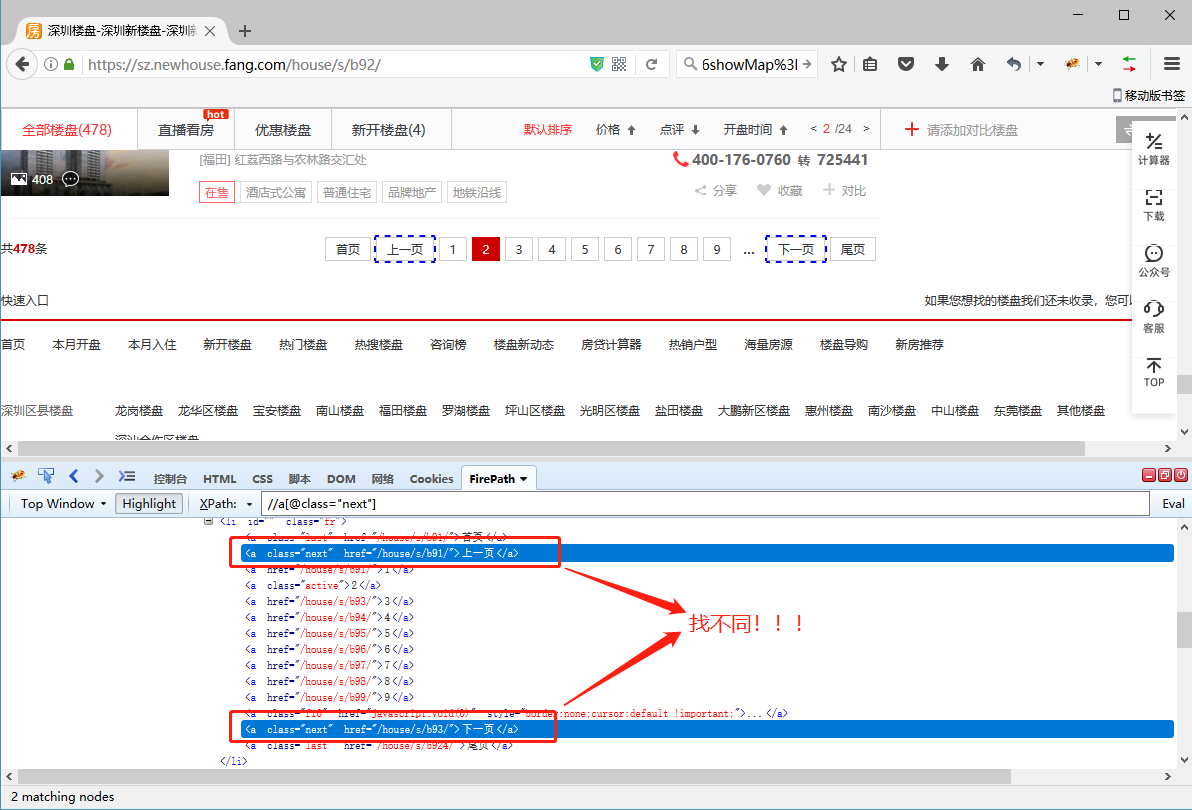
利用这个特征和XPath的 Text函数(忘了Text函数怎么用?返回本教程 3、常用的XPath函数 中查看),我们可以写出一条定位XPath://A[text()='下一页']。将这条新的XPath,放到每一页去检查一下,发现在除最后1页的所有页中都能精准定位到【下一页】按钮,正符合我们的翻页需求。
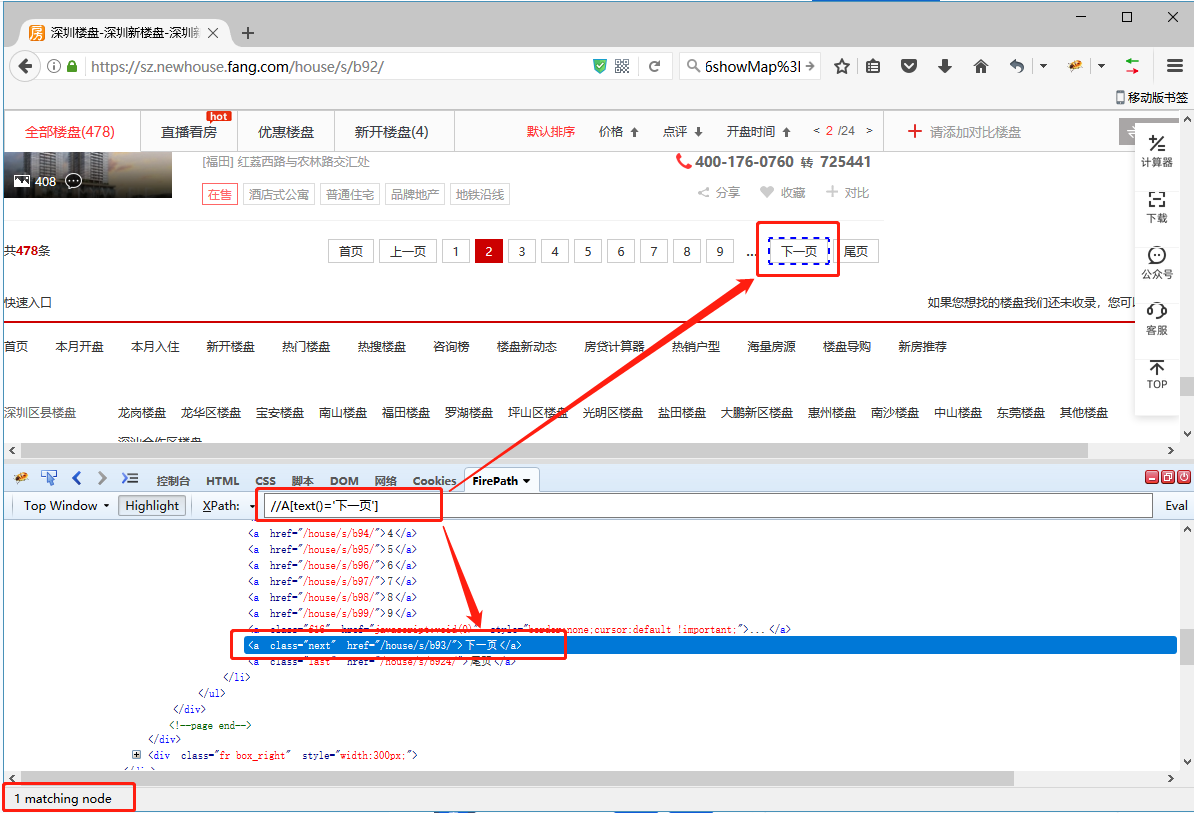
6、将改好的这条XPath://A[text()='下一页'],复制进八爪鱼的相应位置即可。再次启动采集,会发现正常翻页,无重复数据。
以上是一个【翻页】定位出错的实例。在实际采集数据过程中,【循环列表】、【点击元素】、【提取数据】步骤均可能定位不准。就需要我们进行错误排查并修改定位XPath。
作者:Aisling
编辑:Aisling

文章评论