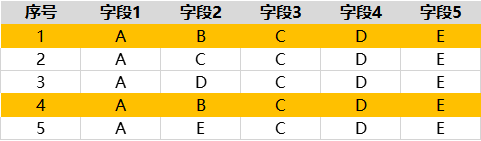
在进行数据采集时,可能会遇到这样的情况:采集结果中有重复数据。 八爪鱼提供两种数据去重方式,满足不同程度的去重需求。 一、按整条数据去重(默认) 在数据采集完成后,系统有一套默认的去重机制:某一行数据(一行数据即一条数据)的全部字段内容与其他行内全部字段内容都相同,则认为该行数据是重复数据,去重后仅保留重复数据中的第1条。 例1:第1、4条数据全部字段内容都相同,它们是重复数据,去重后仅保留第1条数据。 二、按字段去重(需手动设置,8.1.16及以上版本支持) 在制作规则时,可以设置按字段…
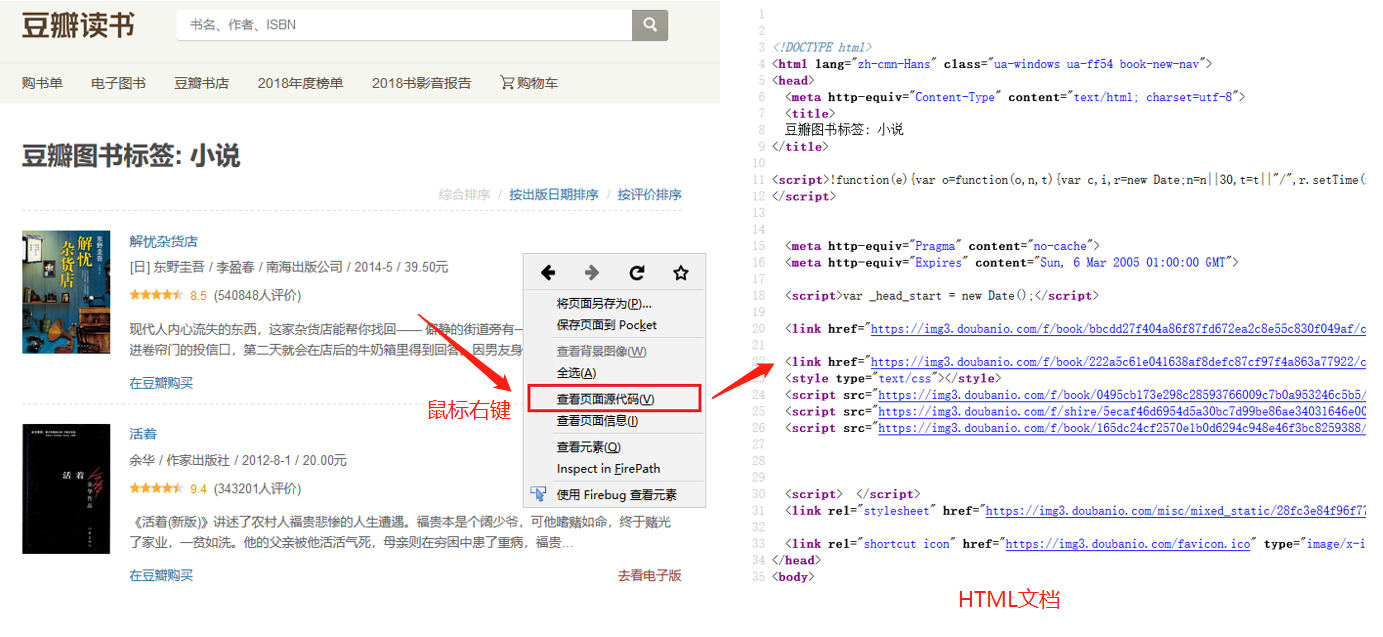
XPath对于八爪鱼数据采集十分重要。绝大多数的数据采集问题,都可以通过写一条正确的XPath解决。 本课将详细讲解XPath相关的问题。 一、HTML 与 XPath 我们日常浏览的网页本质上都是一个个HTML文档。打开网页后,鼠标右键打开菜单,选择【查看网页源代码】,就能看到该网站的HTML文档。网页上的数据,在其HTML文档中都有一个对应位置。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 如何在HTML文档中找到想要的数据?XPath是最常用的语言…
