
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。
一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。但有时候也会遇到一些问题:比如列表中有的部分不是我们想要的,需要进行丢弃。
这时候,可以手动修改XPath去定位列表丢弃不需要的部分。也可以用分支判断丢弃。
以下通过实例进行说明。
实例网址:https://weibo.com/2803301701?refer_flag=1001030103_
一、用XPath过滤多余的项
Step1:按照常规操作创建流程
这个网页采集列表信息,我们按登录网站后常规的采集列表的方法创建循环列表。

Step2:手动执行规则
配置好后,手动执行规则发现:当页面处于第一页时,所有博文都选中了采集,如果我们只想要带视频的博文内容,就需要把纯文字或带图片的博文丢弃。
这里通过修改【循环列表】XPath筛选只包含视频的博文。
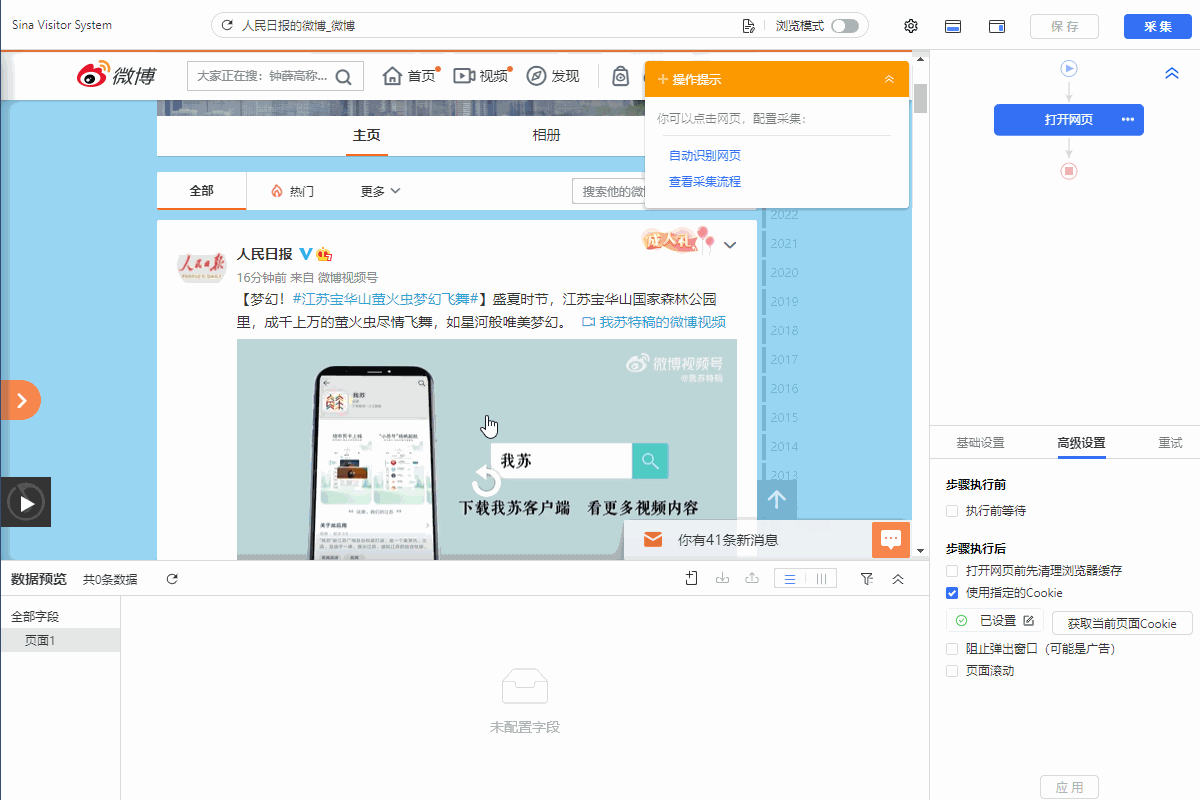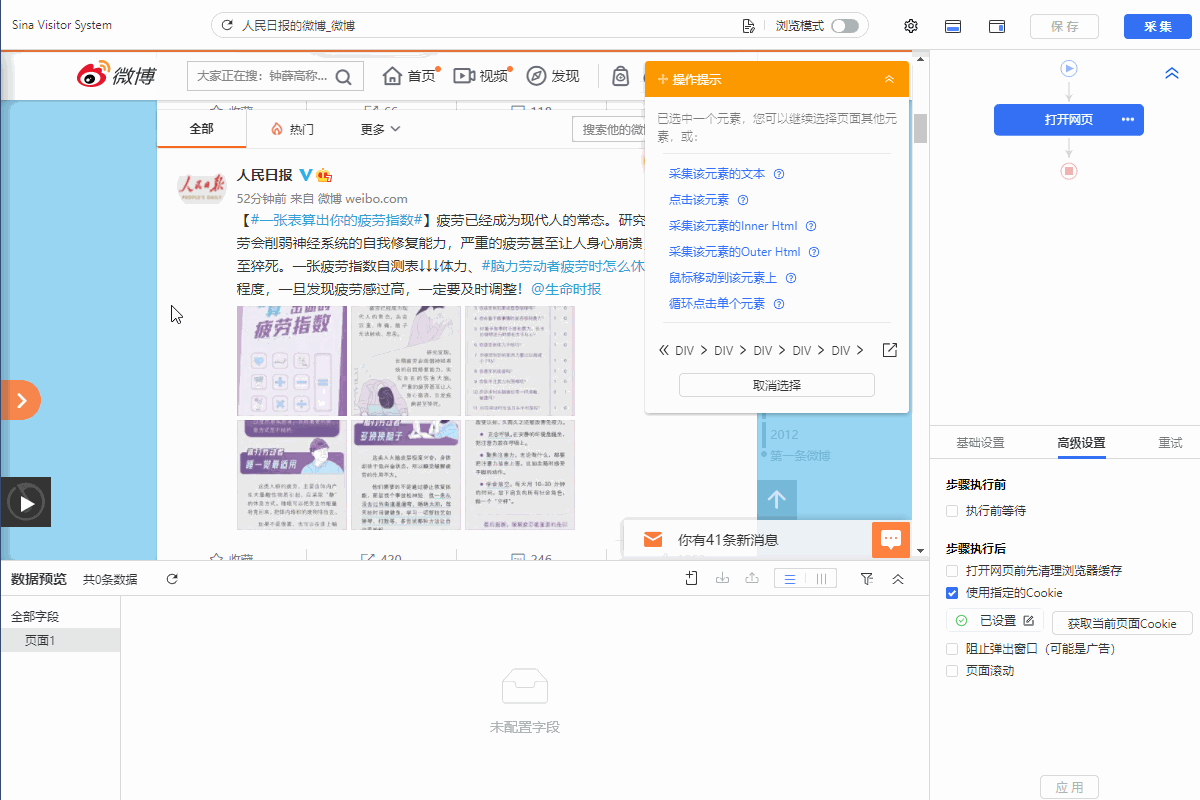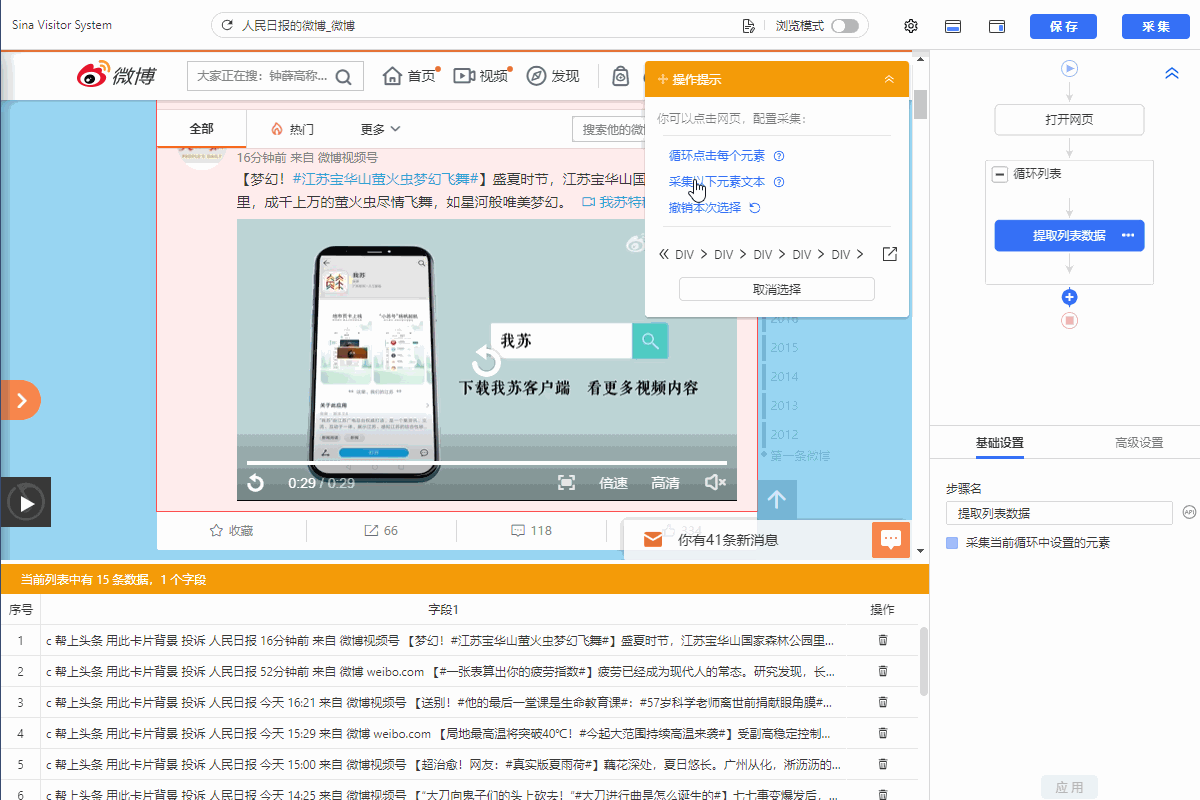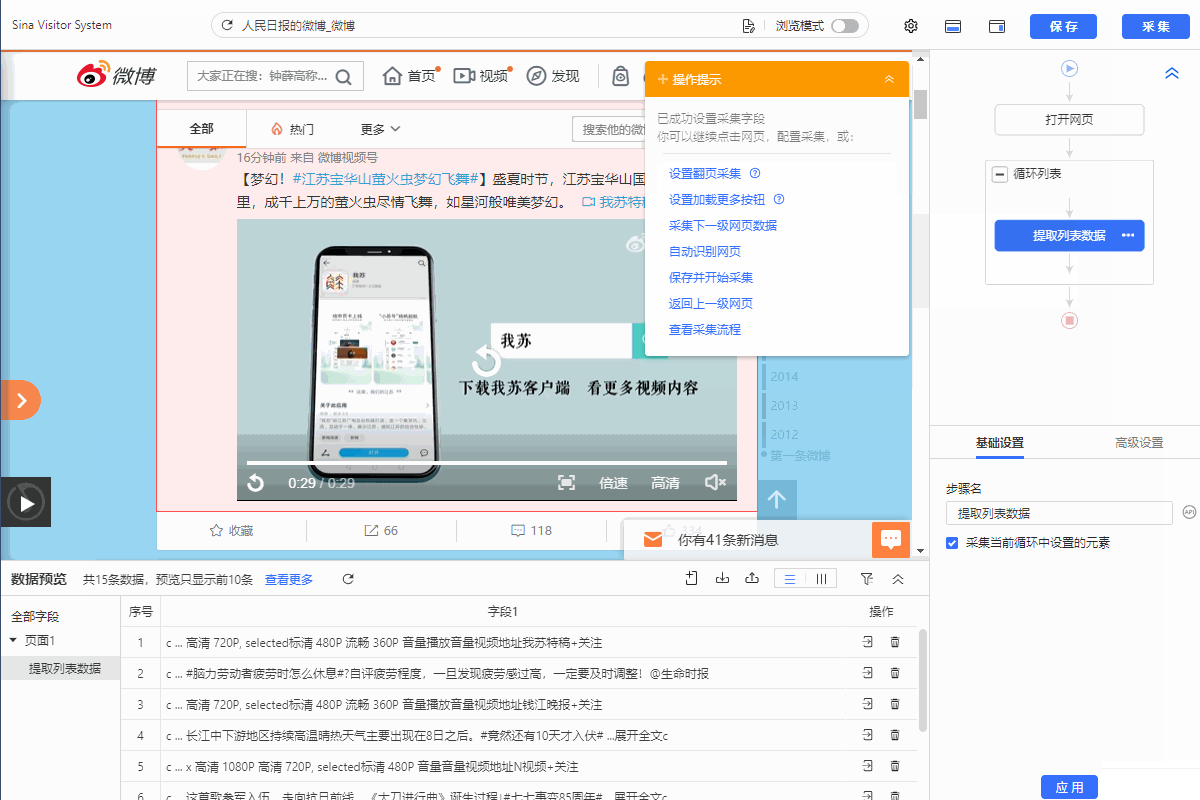
Step3:修改【循环列表】XPath
进入【循环列表】的设置页面,修改xpath为//a[@class="WB_video_h5"]/../../../..
修改点击应用后可以发现之选中了包含视频的博文。
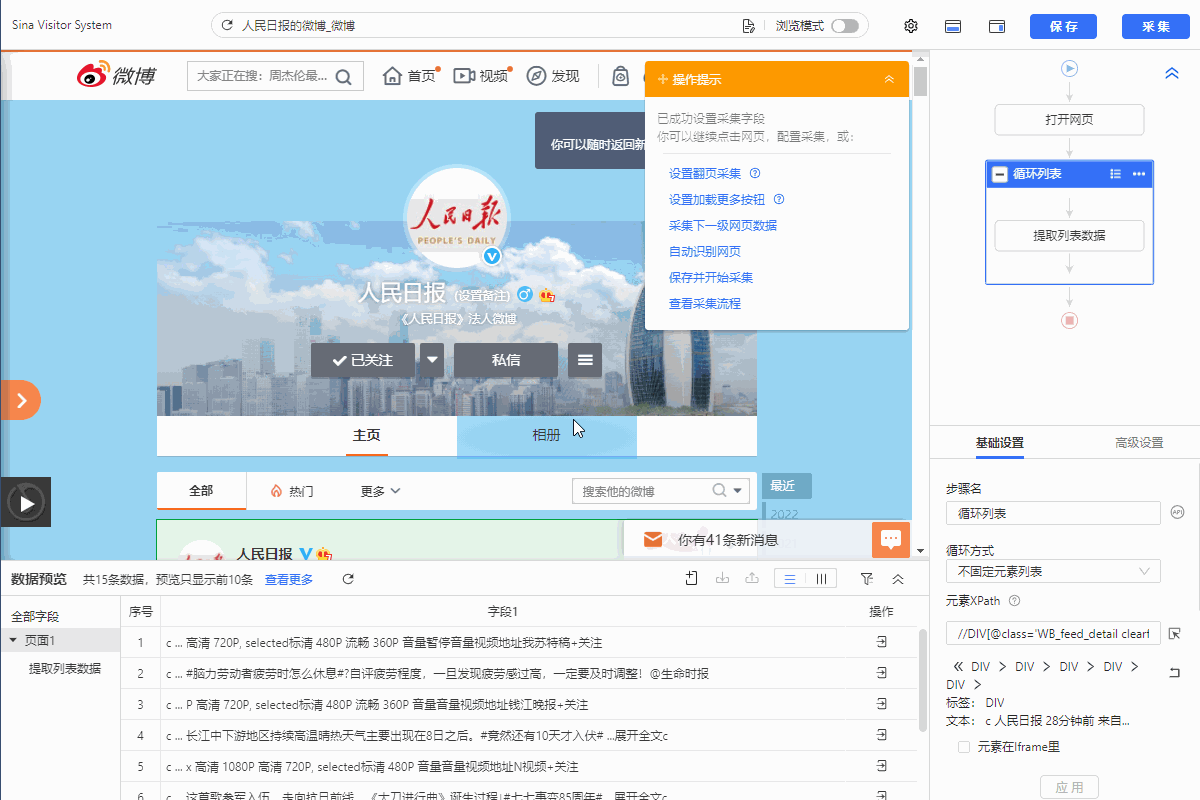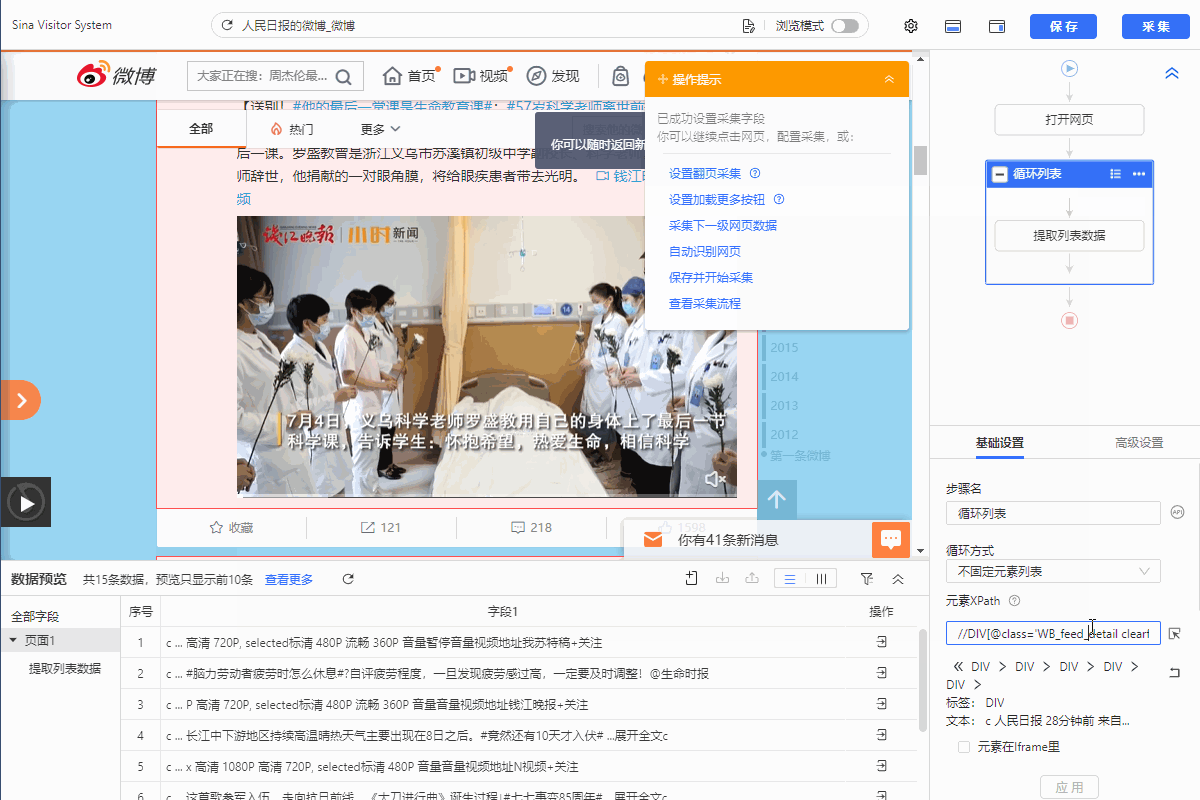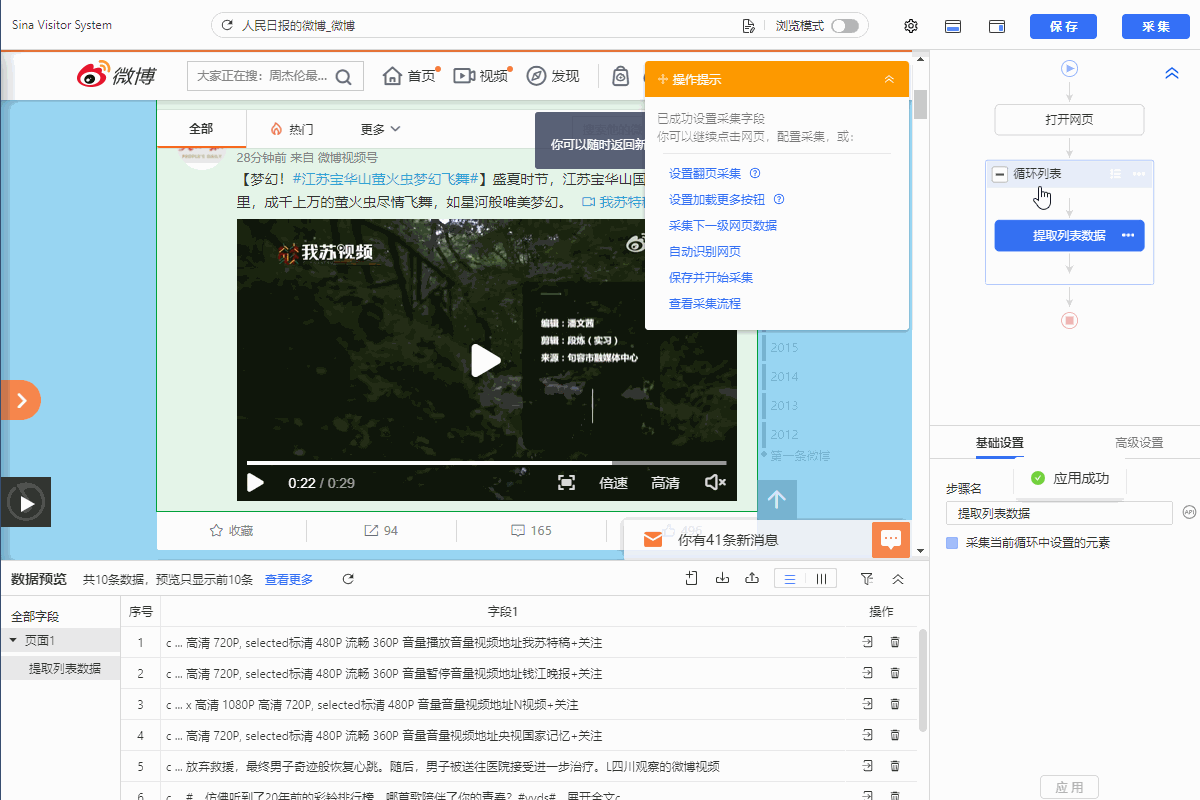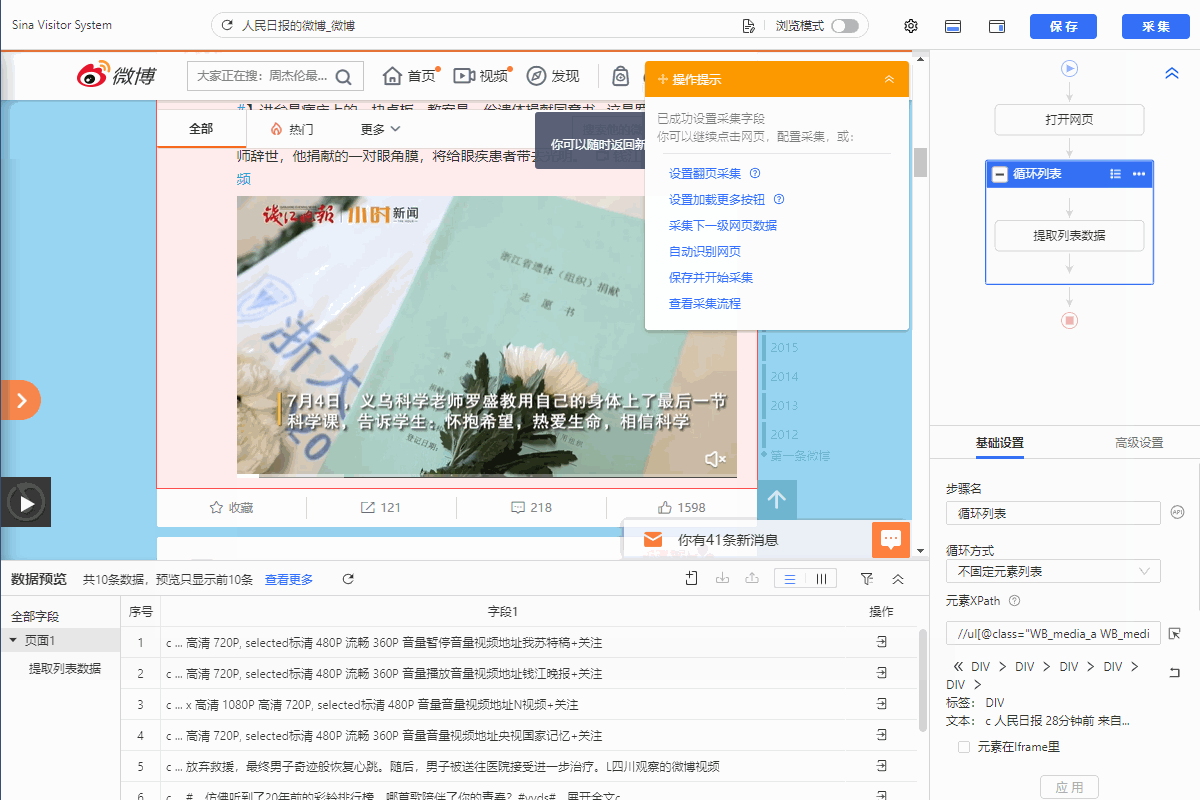
这里为什么要改用这个xpath呢,因为我们要去找包含视频博文特有的xpath,通过观察可以发现视频特有的xpath是//ul[@class="WB_media_a WB_media_a_m1 clearfix"] 
然后符号\.. 表示返回父级标签,\..\..表示返回到父级的父级标签,以此类推下去。

这里总结一下:当发现列表定位过多,需要过滤多余的项,就需要修改【循环列表】的定位XPath
如何修改需要一定的XPath知识,请看之前的 XPath系统学习教程 。
二、分支判断丢弃不需要的列表数据
Step1:按照常规操作创建流程
同上面所讲述方法一致,我们按登录网站后常规的采集列表的方法创建循环列表。
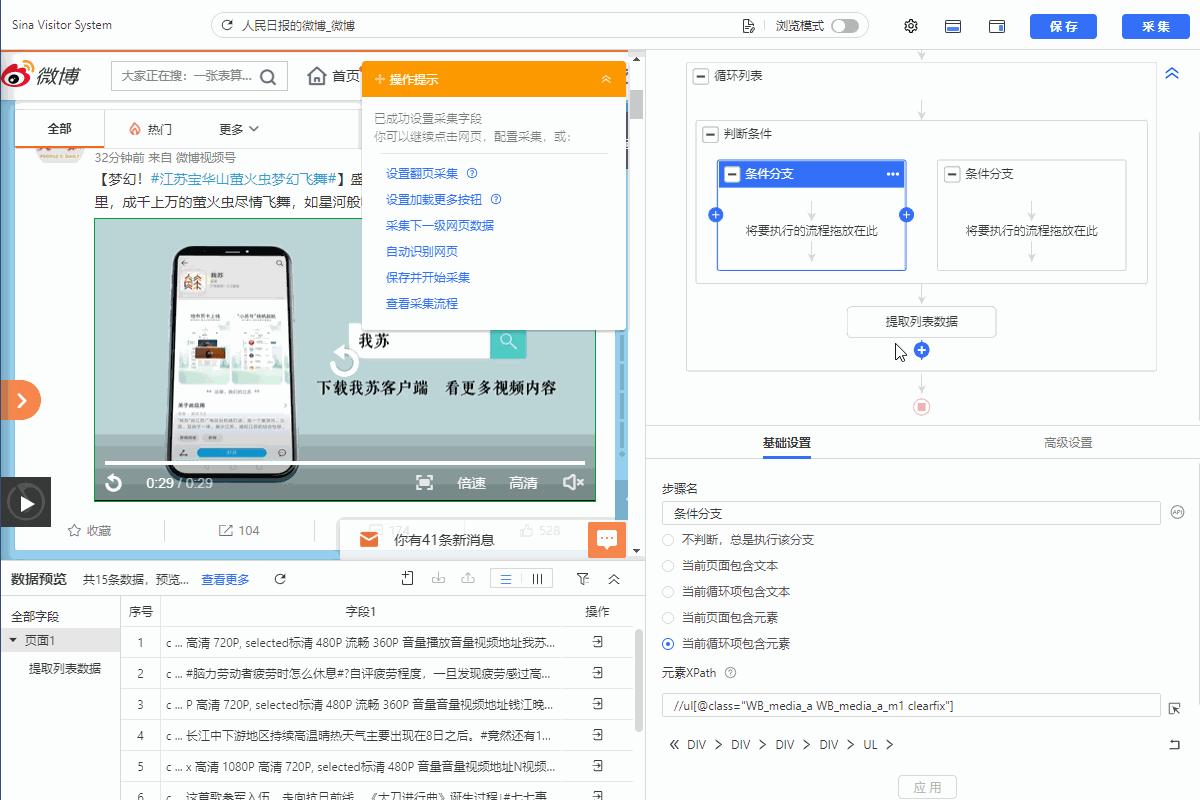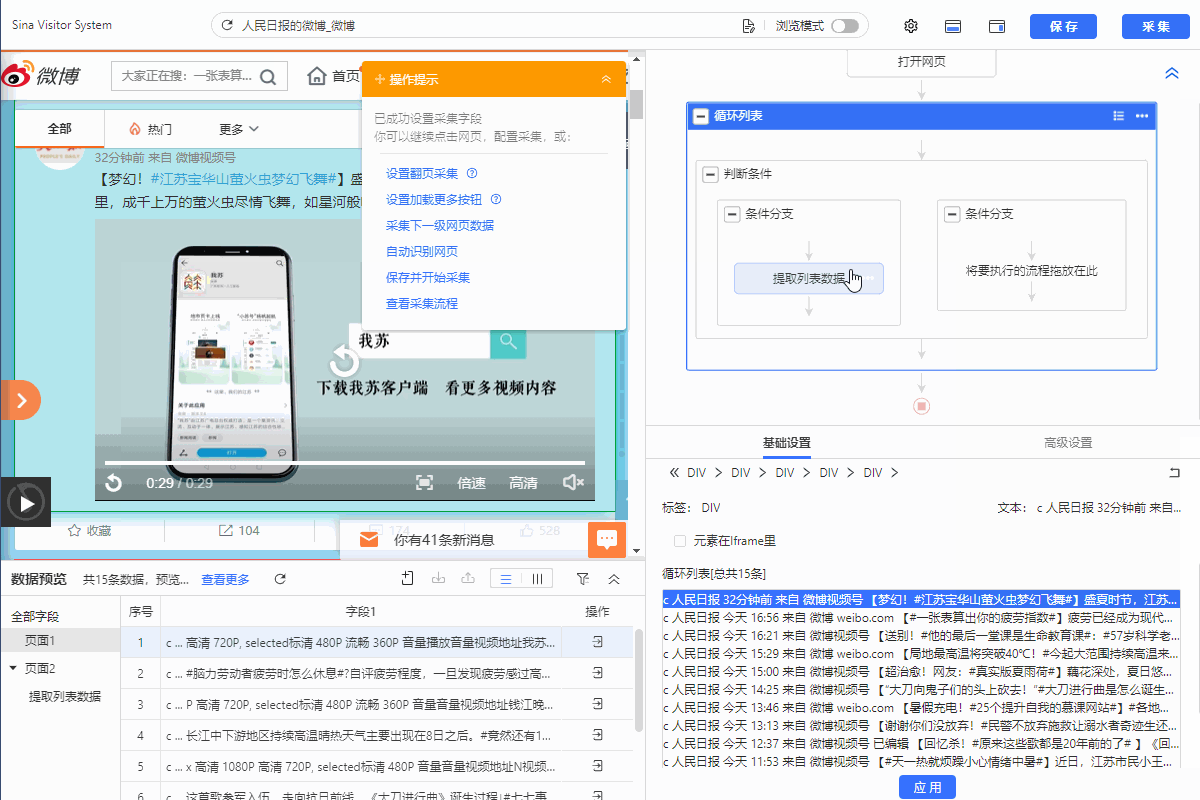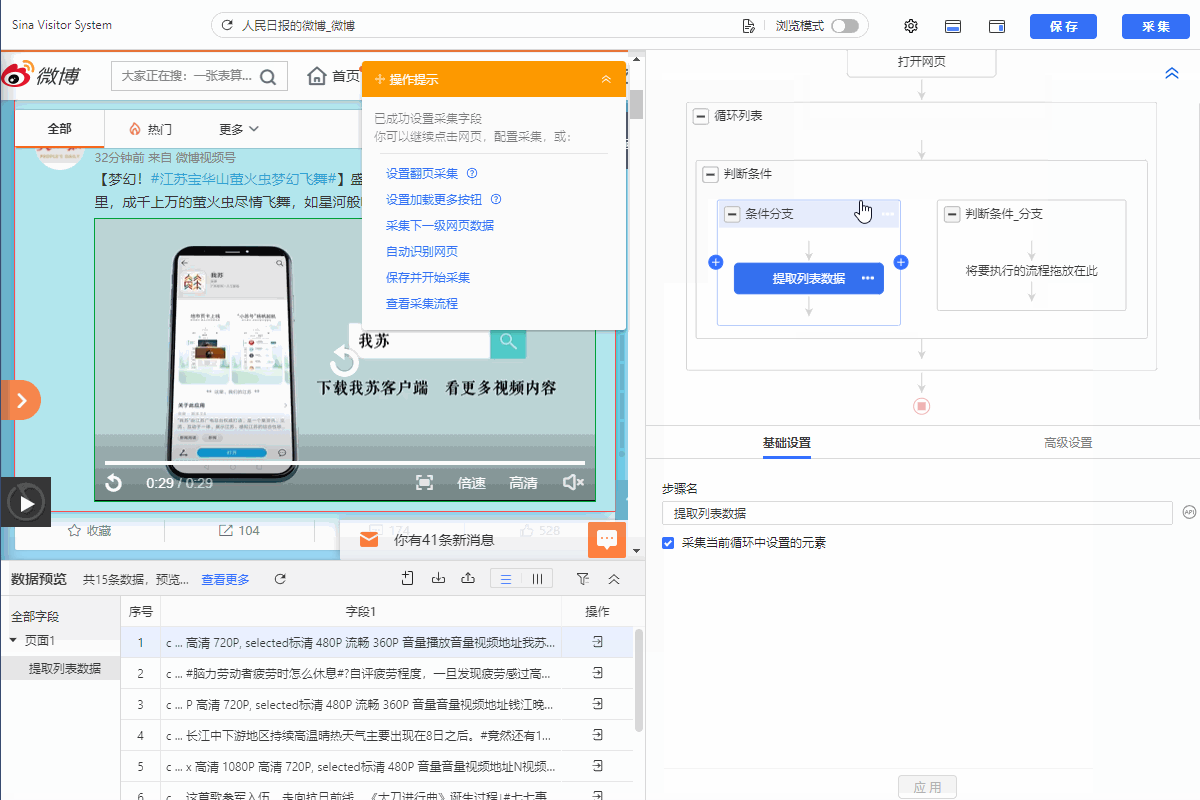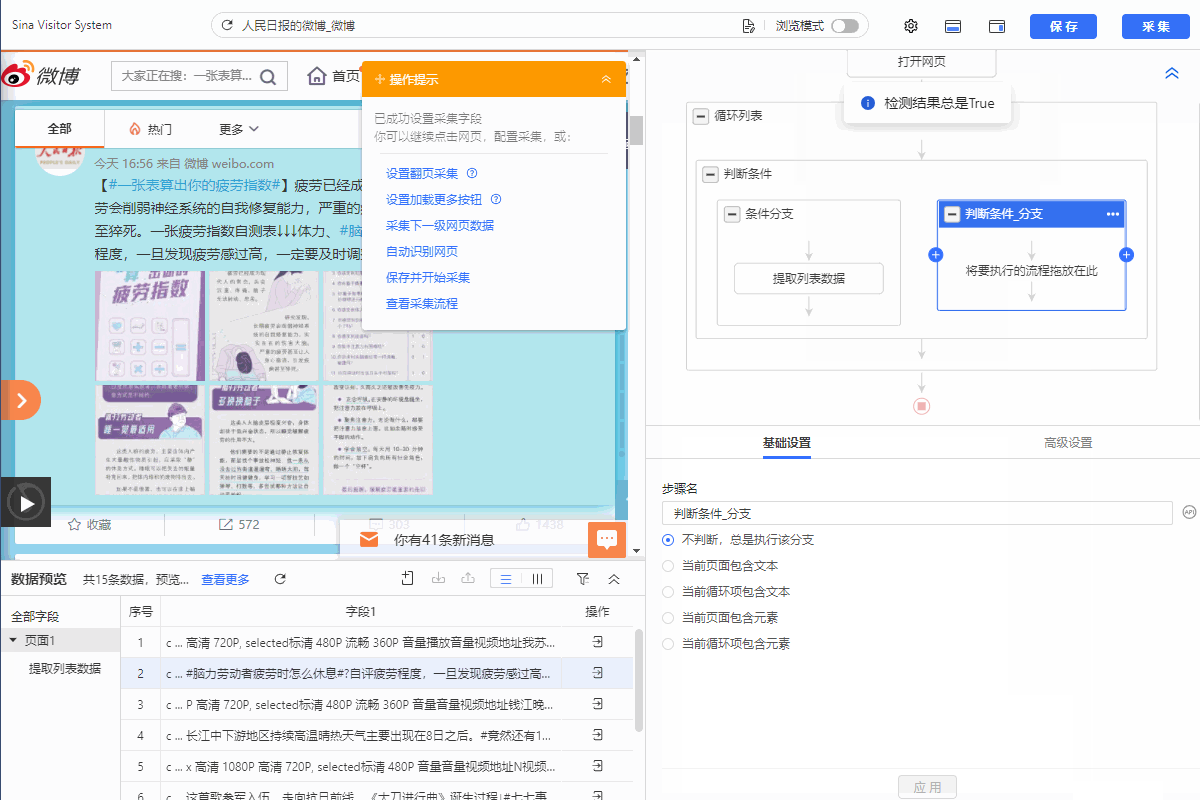
Step2:添加判断条件
1.如下所示添加判断条件
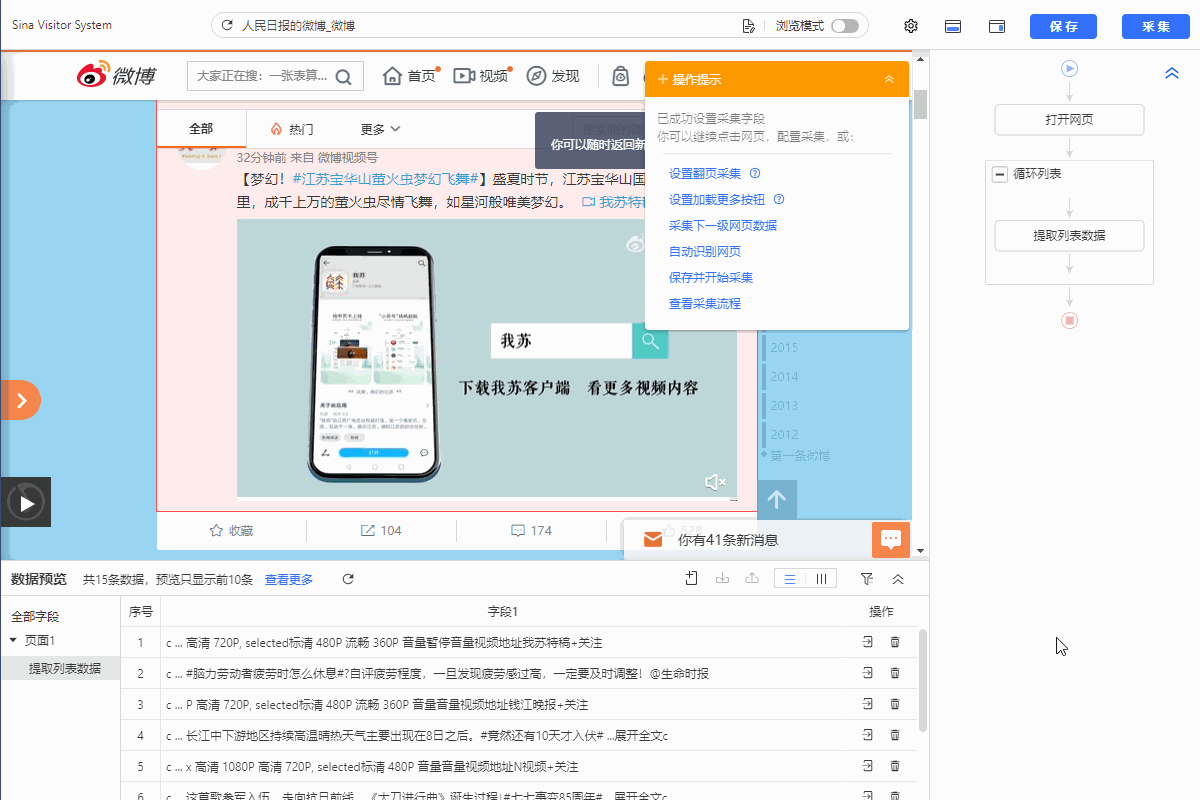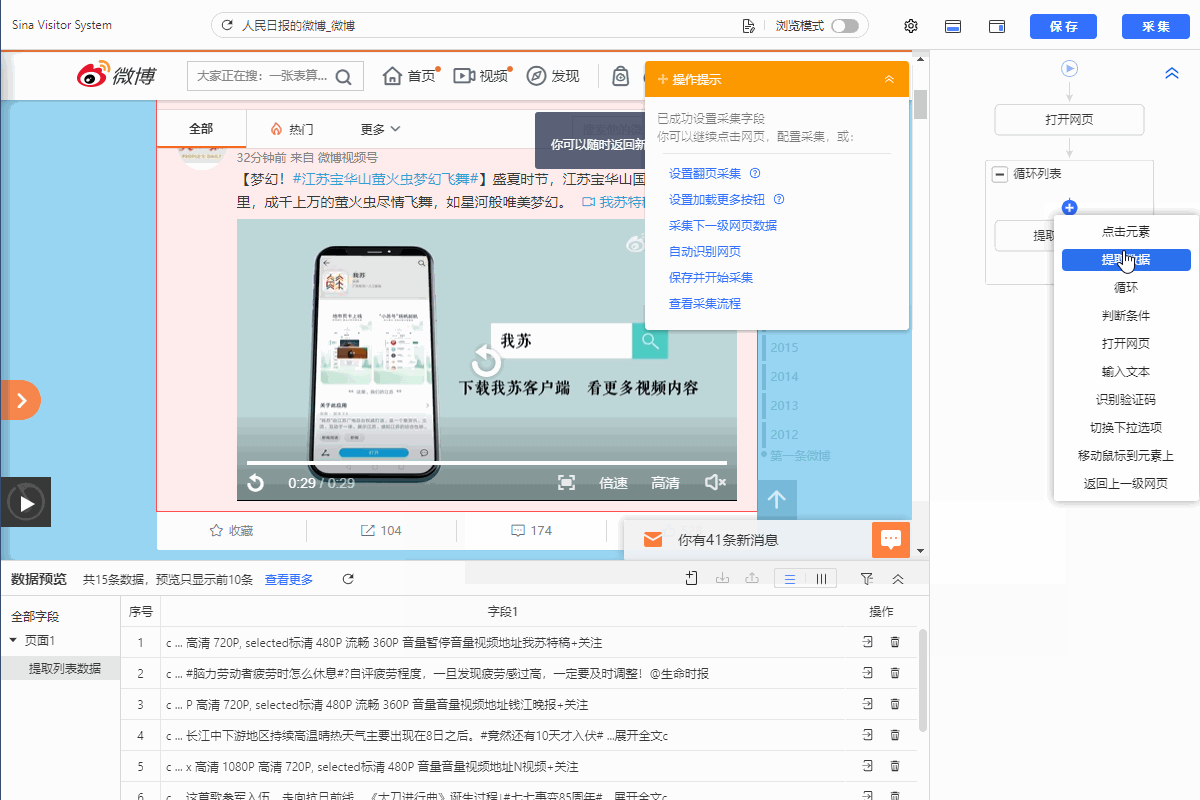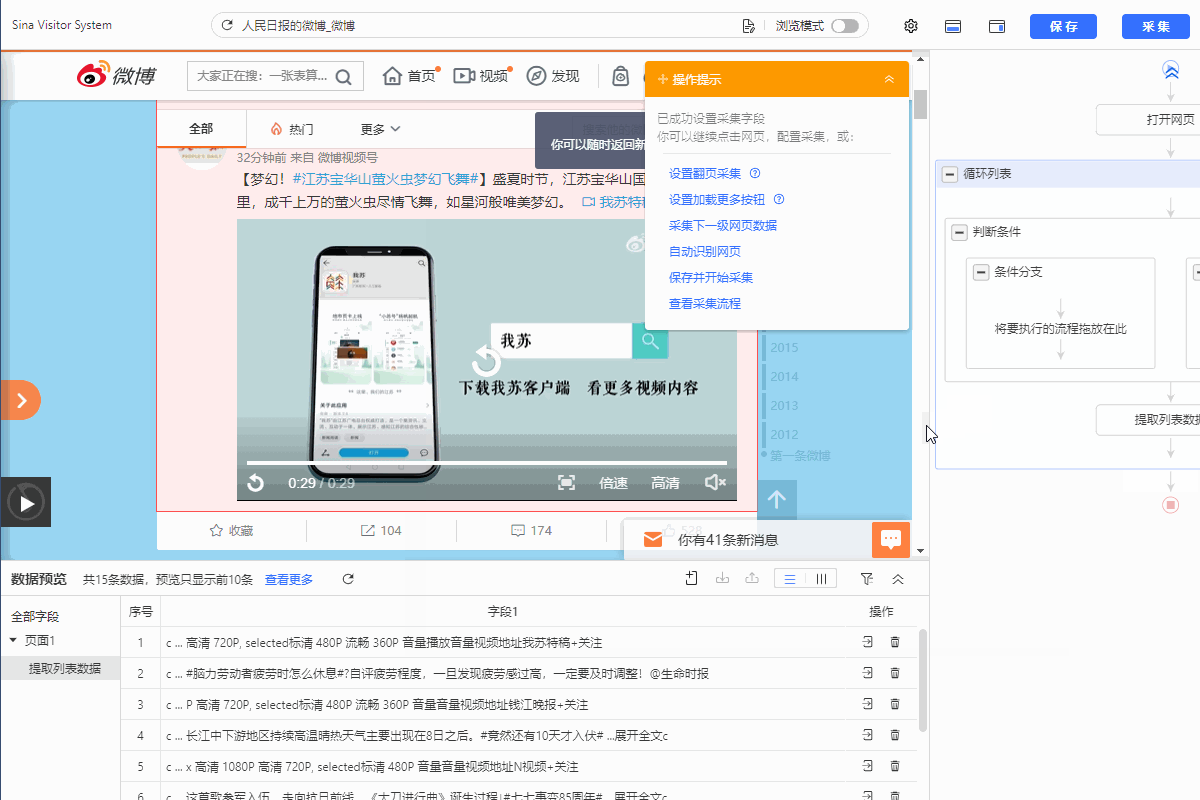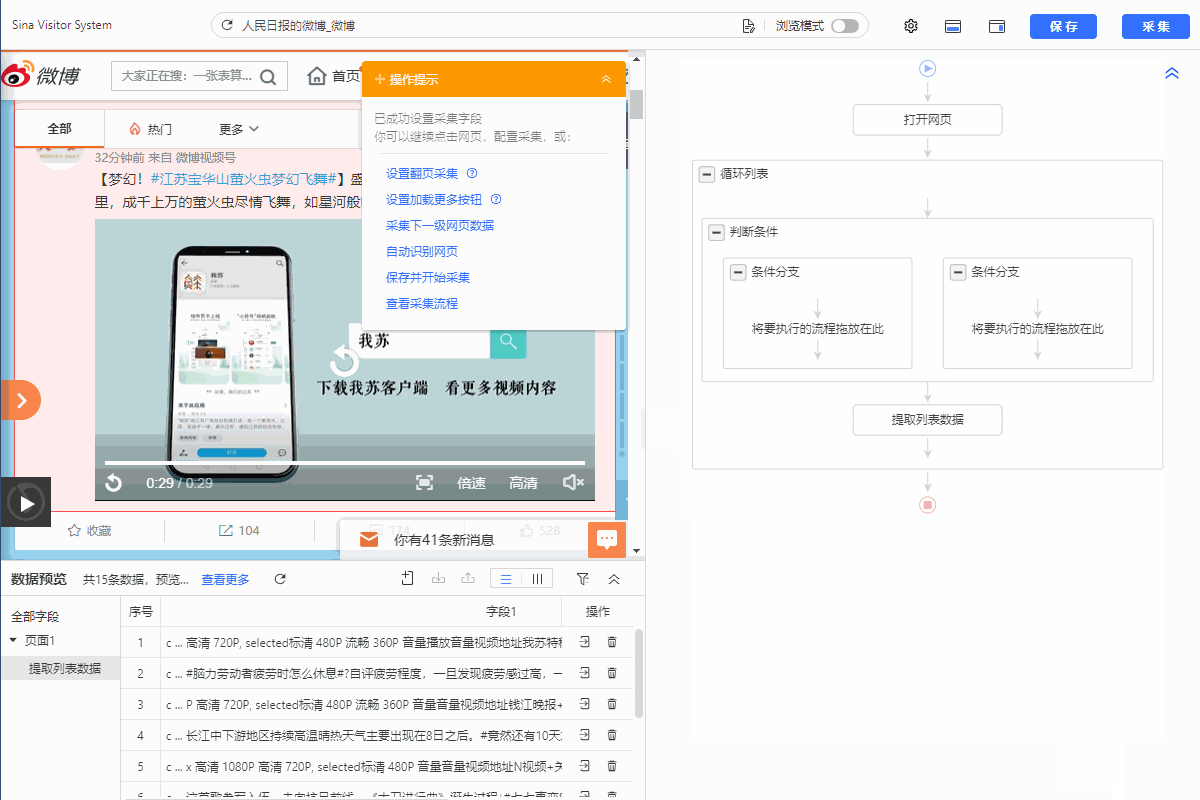

2.左侧分支条件勾选【当前循环项包含元素】,然后填入xpath://ul[@class="WB_media_a WB_media_a_m1 clearfix"]

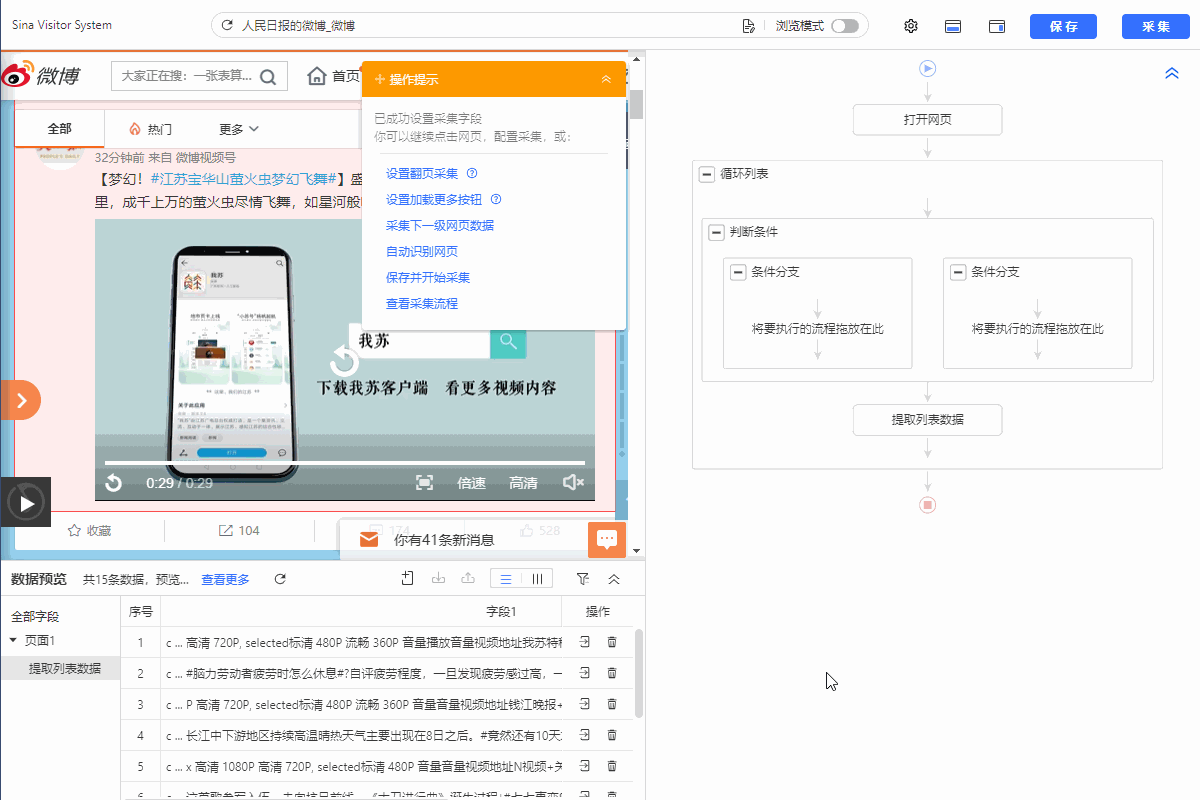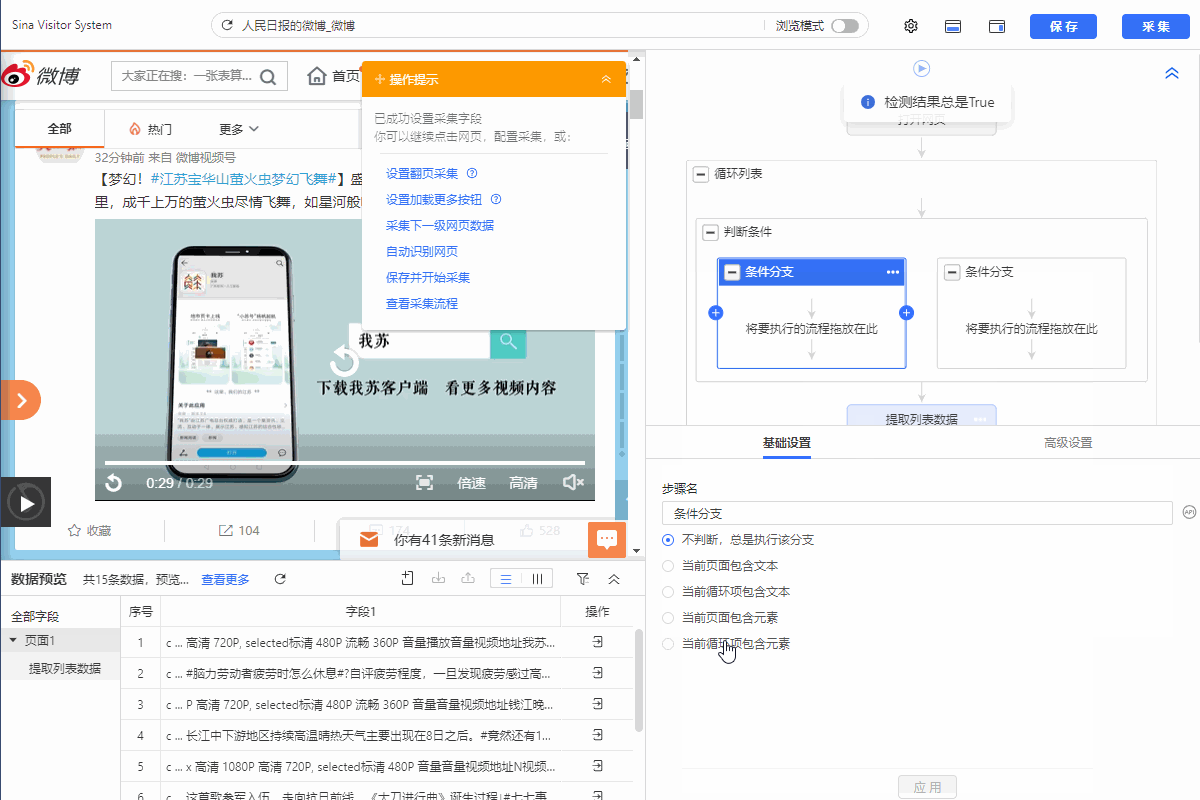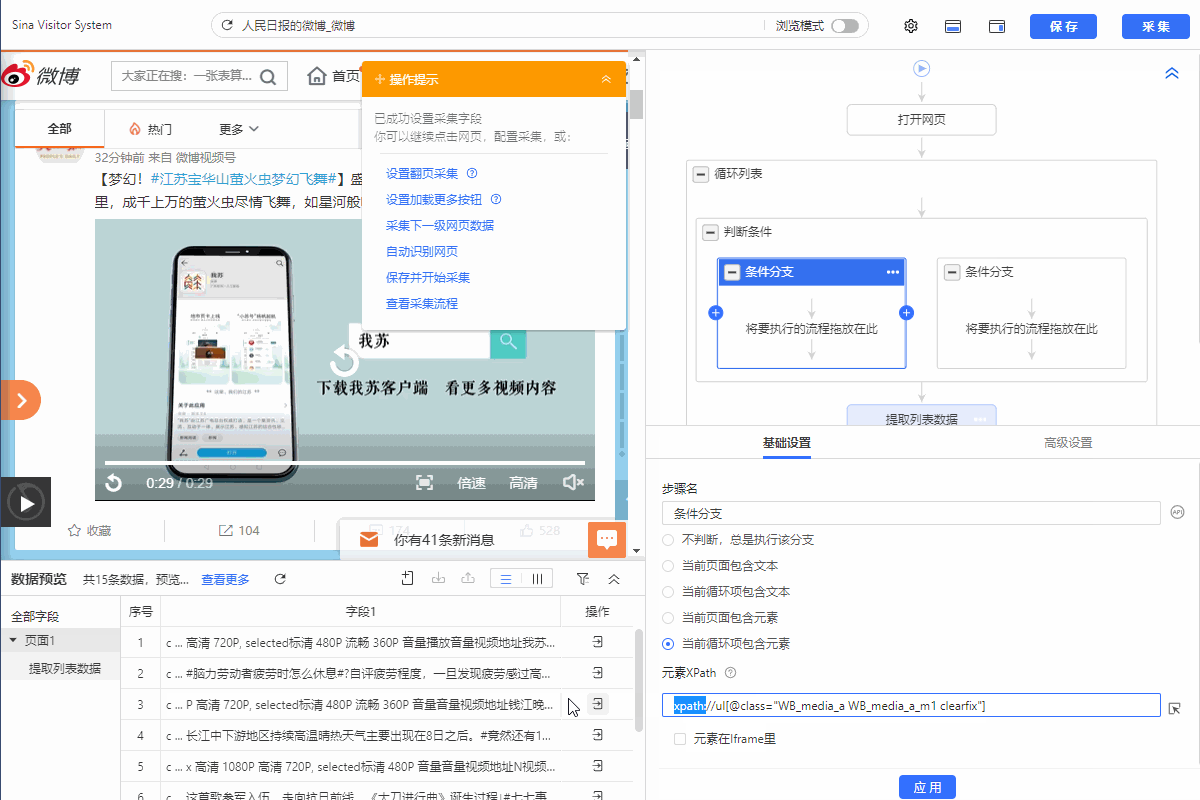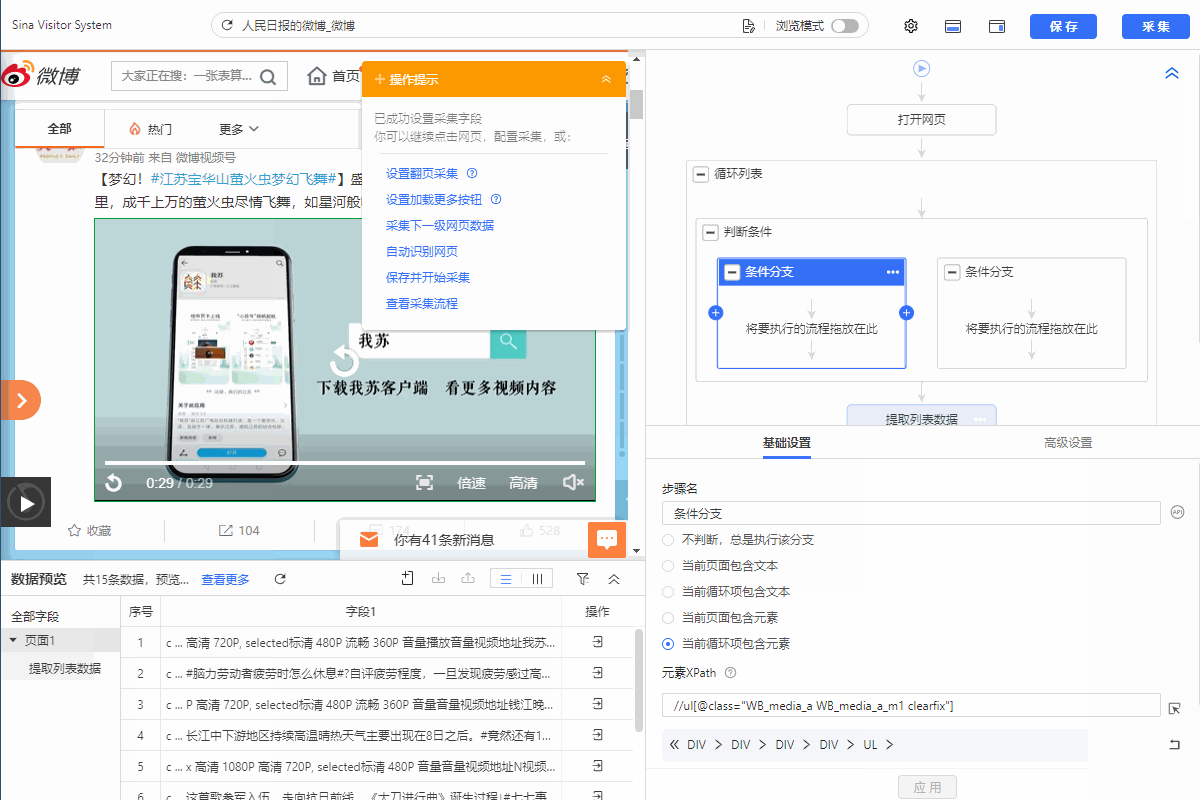
3.把提取数据拖入左侧分支条件,从而实现采集视频的博文。右侧分支不设置提取数据。

提示:
关于判断设置,可学习判断条件教程

文章评论