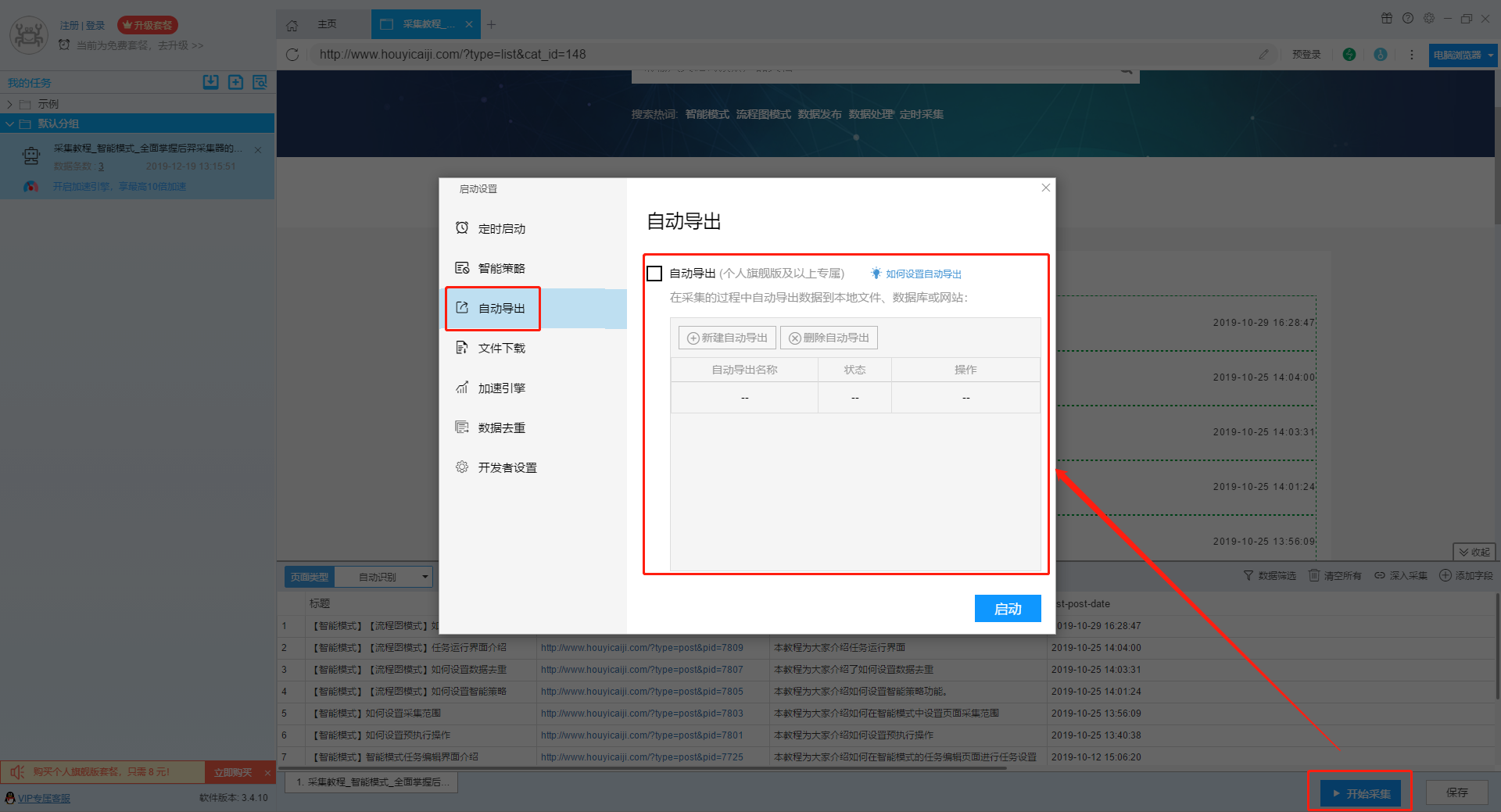
后羿采集器支持自动导出功能,通过使用该功能,可以实现在采集数据的过程中自动导出采集结果到本地文件和数据库,不需要等到任务运行结束后手动导出数据。 开启自动导出有两种方式: 第一种是直接在启动任务时进行设置,这种设置方式可以对同一个采集任务添加多个自动导出。 在编辑任务界面,点击右下角“开始采集”按钮,在弹出的设置框中,点击“自动导出”选项可以切换到自动导出设置界面。 勾选“自动导出”功能,点击“新建自动导出”按钮,新建自动导出的设置。 点击这个按钮后,软件会打开导出设置界面,在该界面中我们可以选择具体的导出方式。后…
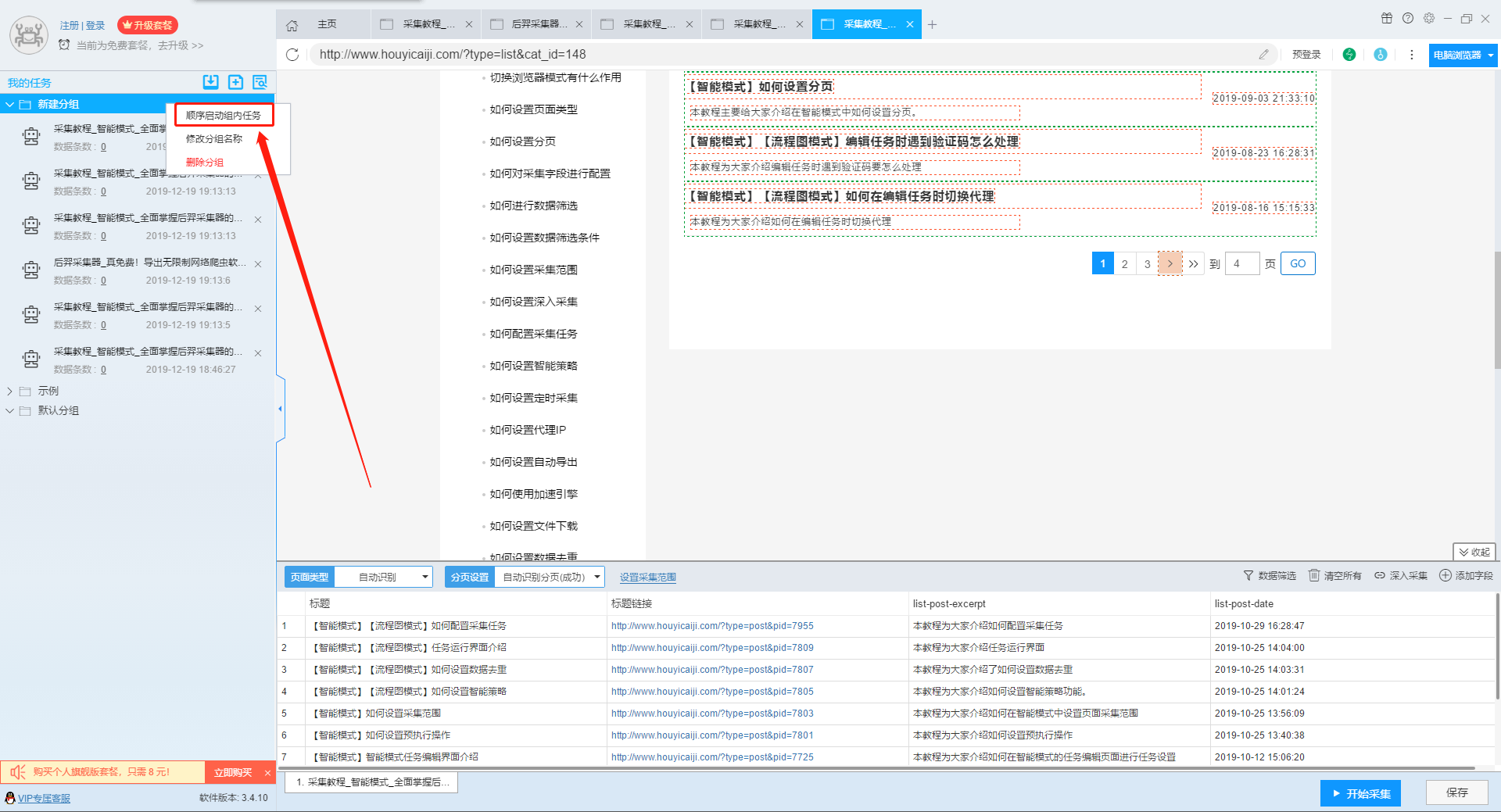
用户在采集数据时,有时候需要启动很多任务进行采集,这时候如果要一个个启动任务就会花费比较多的时间。为了给用户更好的体验,我们开发出了组批量启动功能,大家只要选中组就可以批量启动任务了。 大家可以把需要采集的任务放在一个分组中,然后展开分组,点击顺序启动组内任务,如下图所示: 注意,需要把组展开才能够批量启动组内任务,未打开分组使用此功能会出现如下报错: 按组批量启动任务后,会跳转到启动页面,此时在启动页面进行的所有设置会应用给组内的每一个任务。 点此了解更多关于采集任务设置的内容。 注意一点,如果在此时勾选加速引擎…
在新建流程图模式任务之后,软件会打开任务编辑界面,本教程为大家介绍如何在流程图模式的任务编辑页面进行任务设置。 1、刷新网页 如果遇到网页加载不出来的情况,可以点击刷新按钮刷新网页。 2、修改任务网址 用户可以在下图的两个位置对网址进行编辑,超过200个请直接修改本地文件。 注意:如果是从本地文件中导入的网址,这里的修改不会影响本地文件。 更多详情内容,请参考以下教程: 如何修改网址 3、预登录功能 遇到需要登录的网页,可以点击此位置使用预登录功能。 更多详情内容,请参考以下教程: 如何采集需要登录才能查看的网页 …
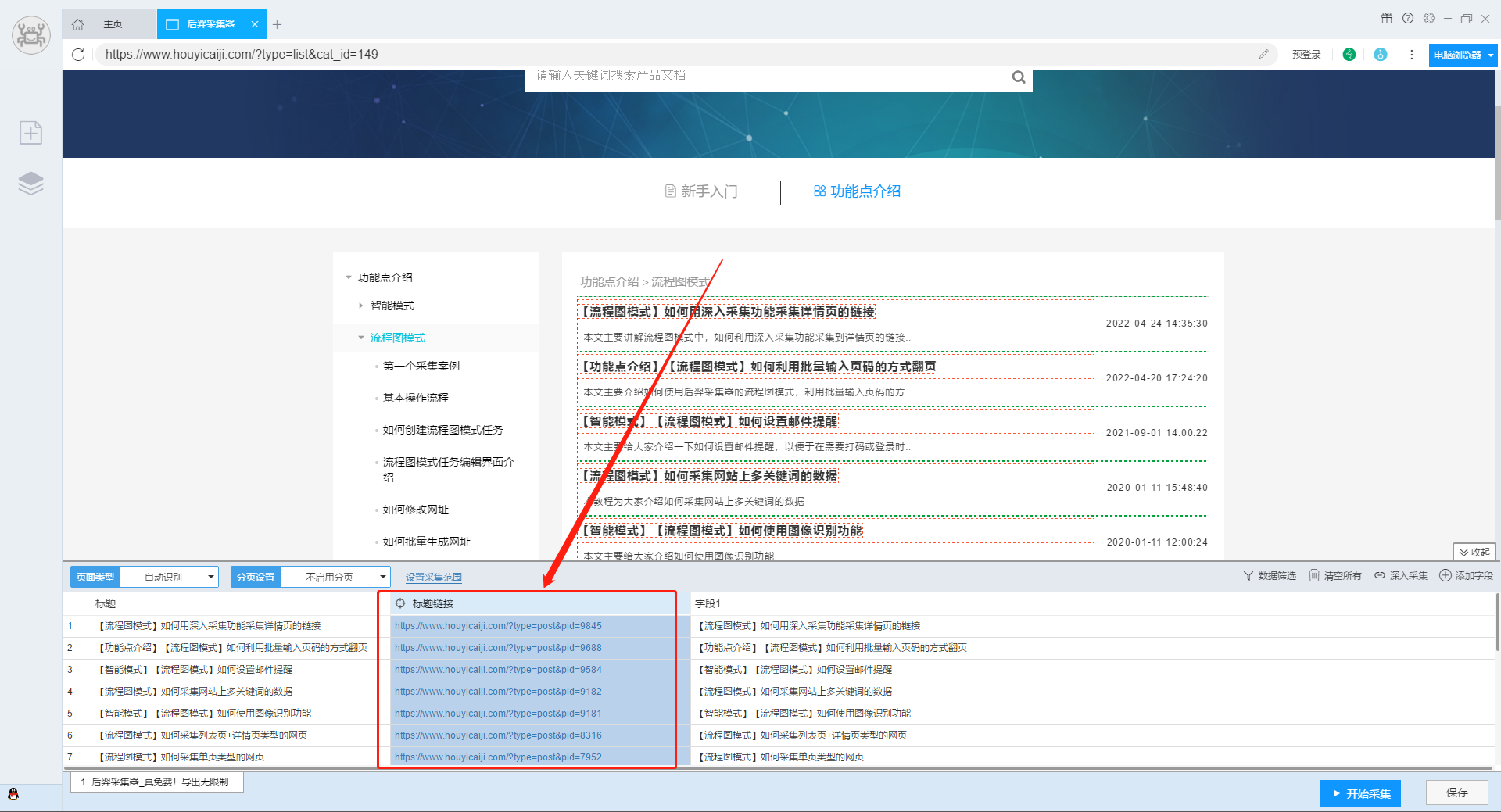
在数据采集的时候,经常会需要采集详情页链接。本文通过三种方式来讲解如何利用我们后羿采集器的智能模式采集到详情页的链接,流程图模式同理。 方法一:通过自动识别获取 后羿采集器的智能模式会自动识别列表,一般网站在识别到列表的同时,就会将详情页的链接一并识别出来。 【温馨提示】如果自动识别不准确,也可以用手动点选的方式进行列表识别。 点此深入了解如何识别列表 方法二:通过深入采集获取 在软件的列表识别过程中,有时候会遇到无法识别到详情页链接的情况。这时候我们就能用深入采集功能进入详情页,采集详情页的链接。 1.在识别到列…
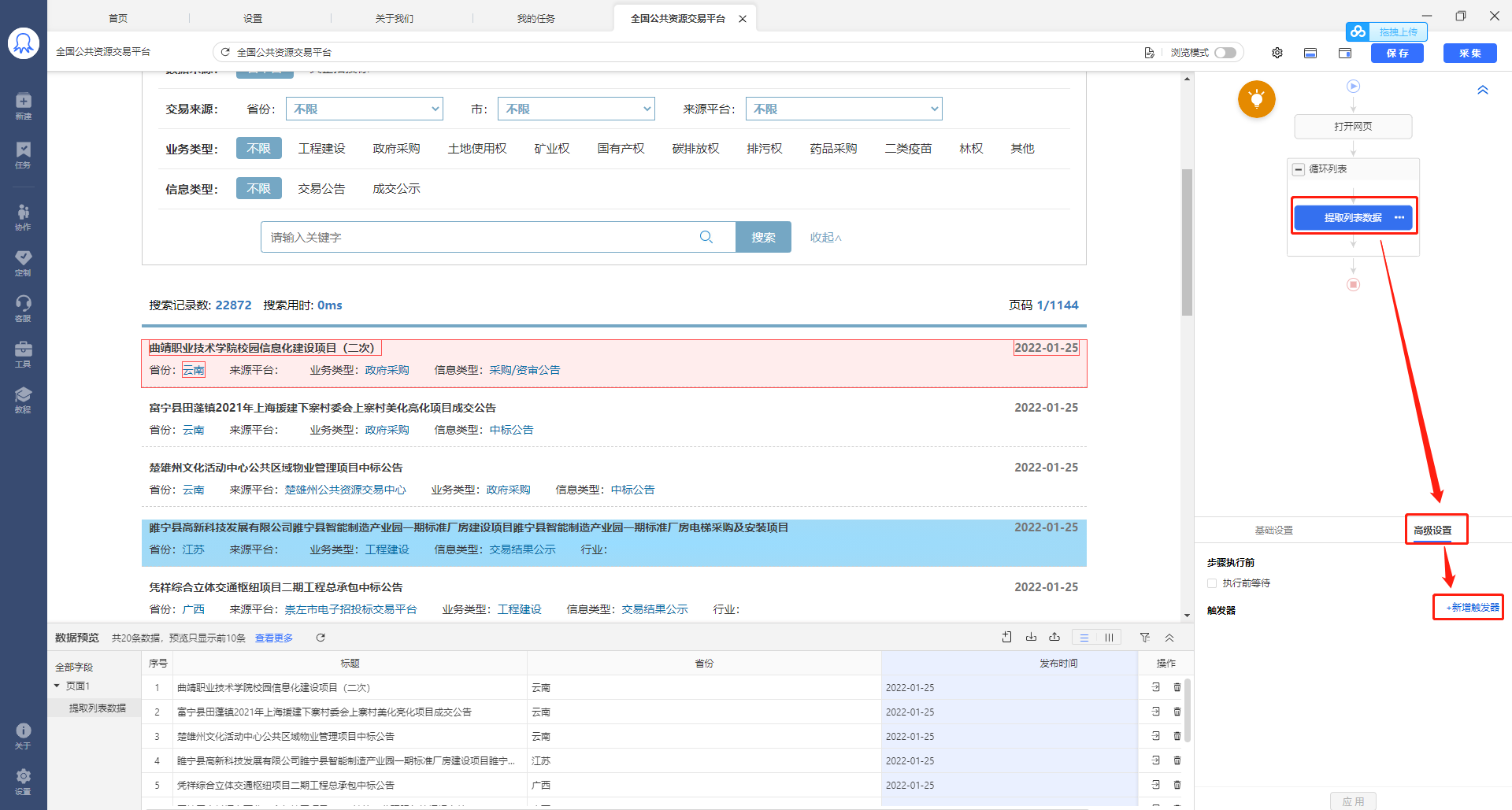
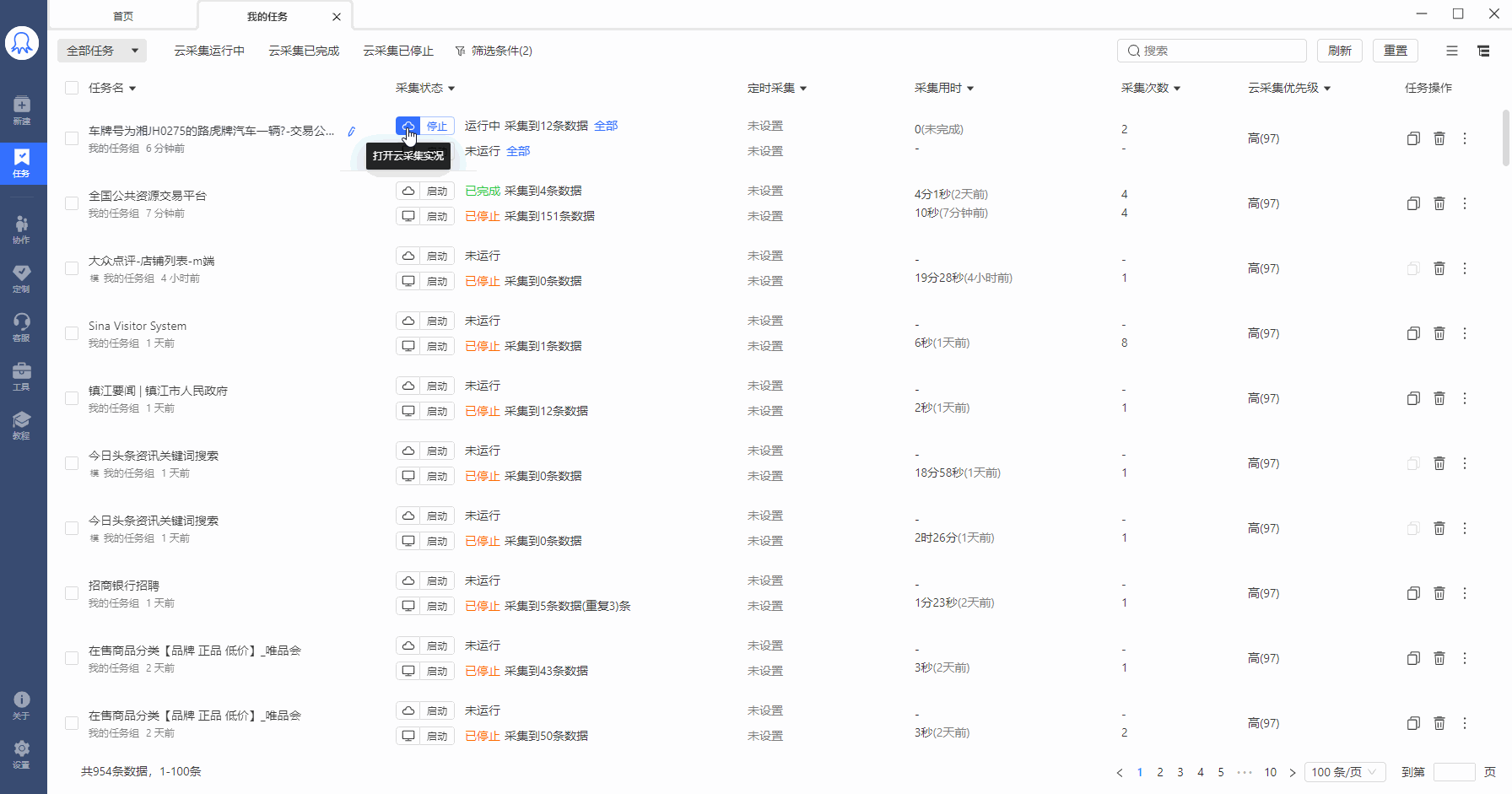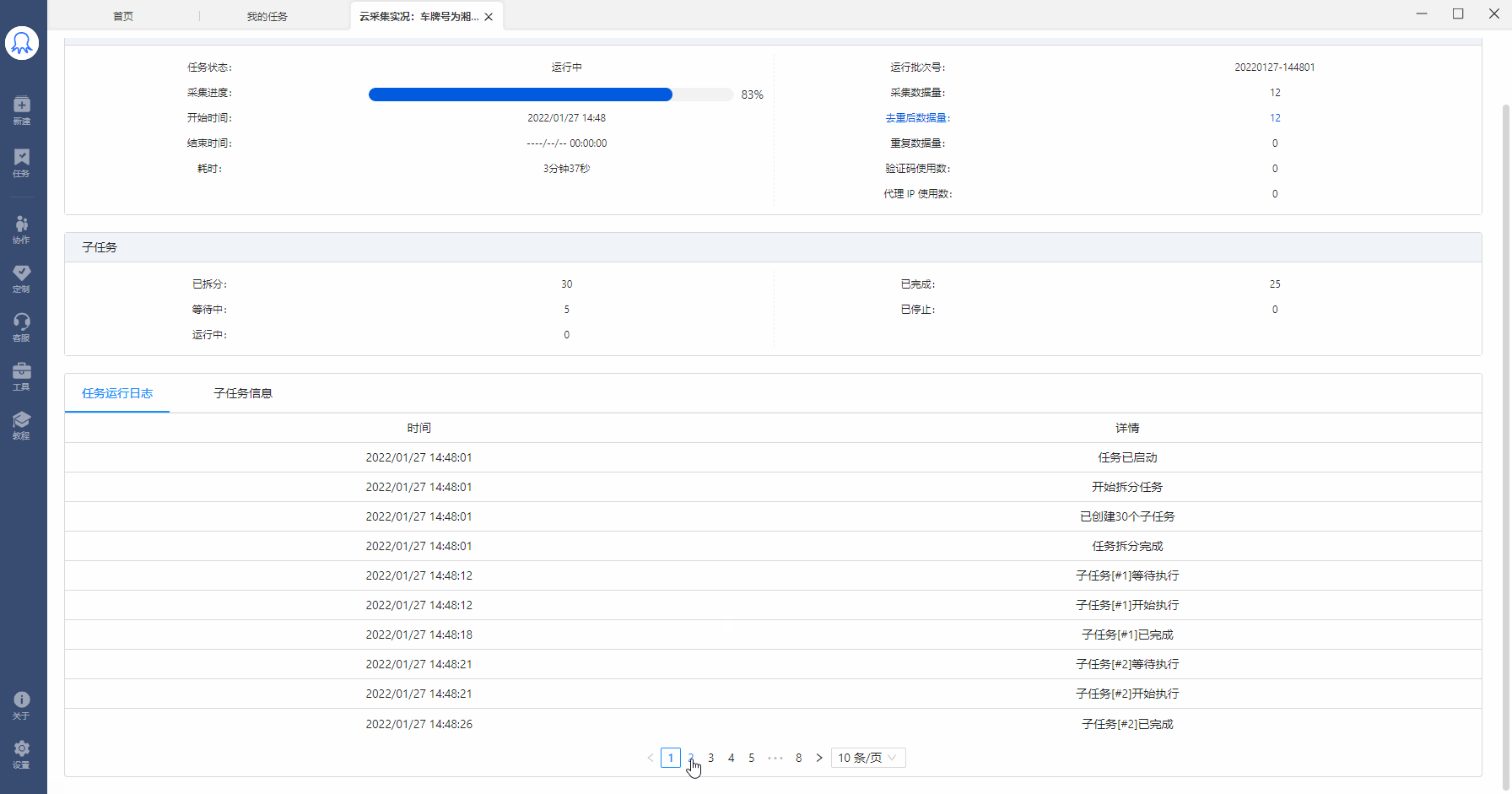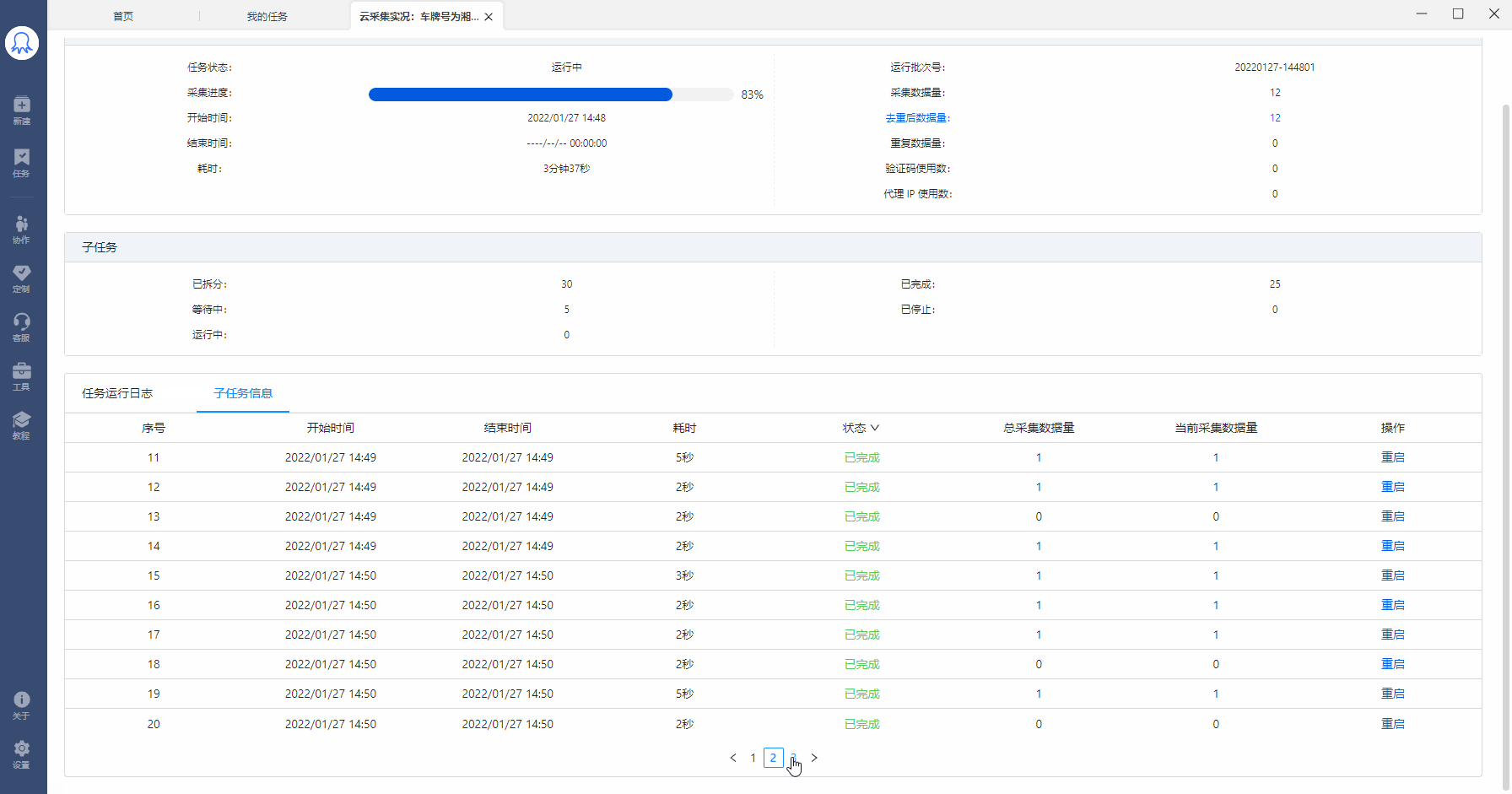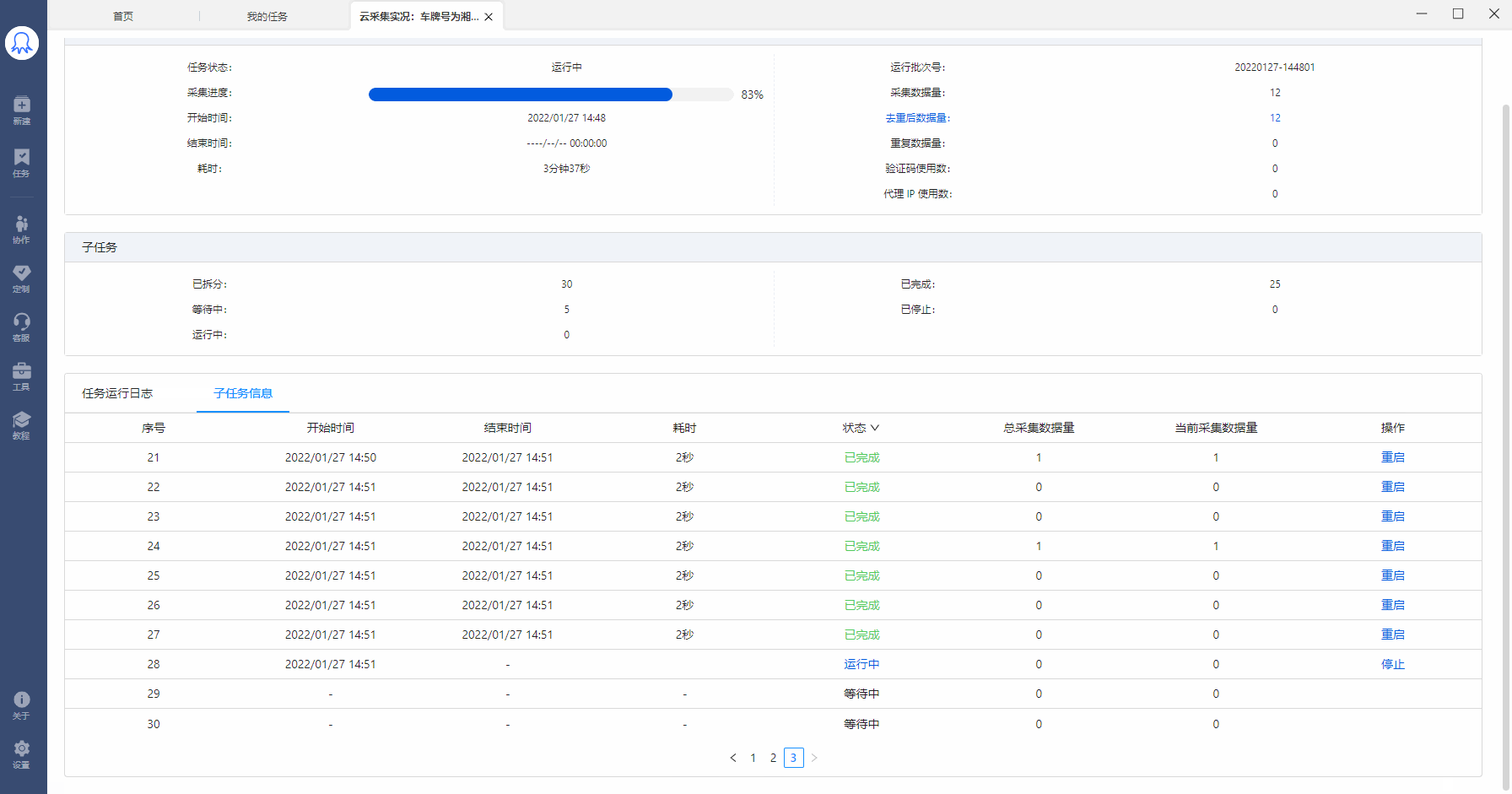
通过八爪鱼云采集,可以实现多个任务并发采集,极大提高采集效率。 云采集原理是什么?什么样的规则可实现云加速?本文将详细讲解。 一、云采集原理 云采集是指,使用由八爪鱼提供的云服务集群进行数据采集。八爪鱼拥有5000+云服务器,7*24小时不间断运行(一台云服务器可看做一个云节点)。 八爪鱼的采集任务运行在云节点上时: a. 在满足可拆分的情况下,1个任务最多拆成100个子任务。(3类任务可拆分,下文将详细讲解) b. 1个任务/子任务需占用一个云节点进行采集。也就是说,1个云节点同时只能运行一个任务/子任务…

有很多网站,通过点击【加载更多】或【再显示20条】等按钮进行翻页。像 搜狗微信首页 、微博评论 等页面都是这种情况。 针对这种网页,八爪鱼V8.4.0版本新增【边点击边采集】功能,可以边点击【加载更多按钮】,加载出新数据,边采集每次加载的新数据。 例:设置点击20次,则点击1次后,采集第1次点击后加载的数据,继续点击第2次,采集第2次点击后加载的数据.......直至点击20次,采集第20次点击后加载的数据。 使用智能识别和自行配置的采集规则,都能实现【边点击边采集】,具体设置方法如下。 一、使用智…
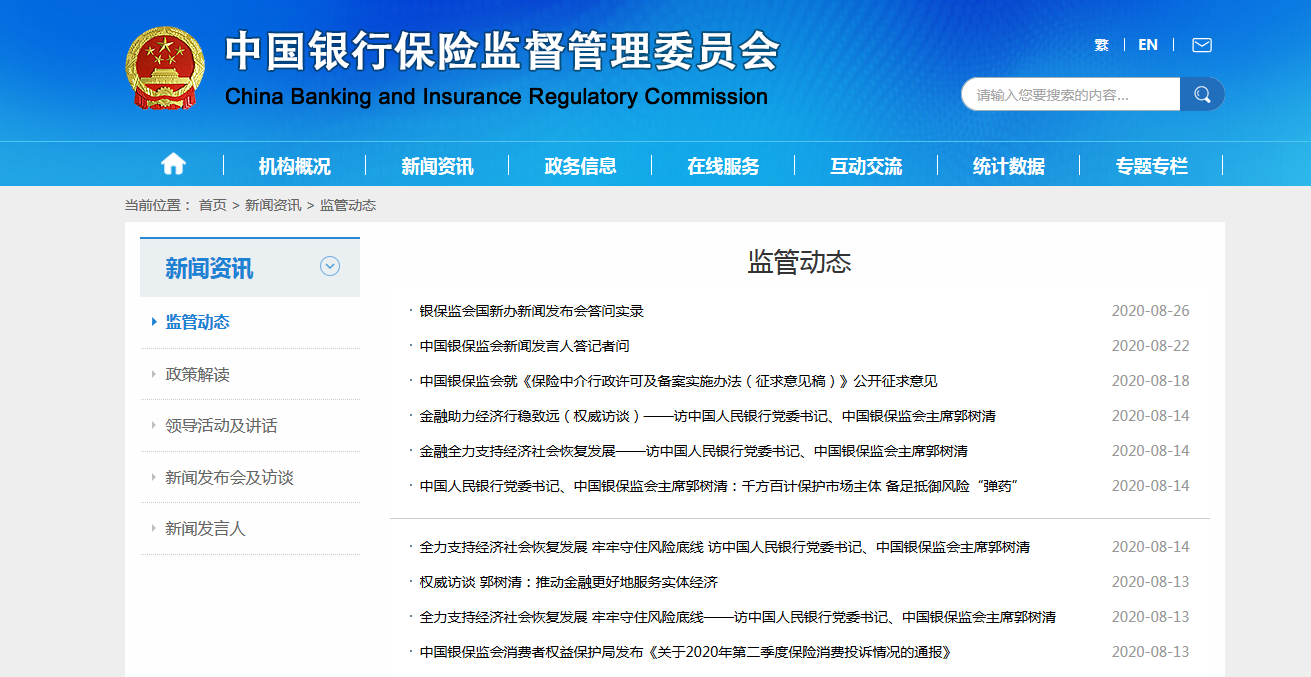
采集场景 进入中国银行保险监督管理委员会【新闻资讯】版块下的【监管动态】栏目 http://www.cbirc.gov.cn/cn/view/pages/ItemList.html?itemPId=914&itemId=915&itemUrl=ItemListRightList.html&itemName=%E7%9B%91%E7%AE%A1%E5%8A%A8%E6%80%81 ,进入每条监管动态详情,采集其详情页信息。 采集字段 当前位置、标题、标题链接、发布时间、来源、正文、当前采…
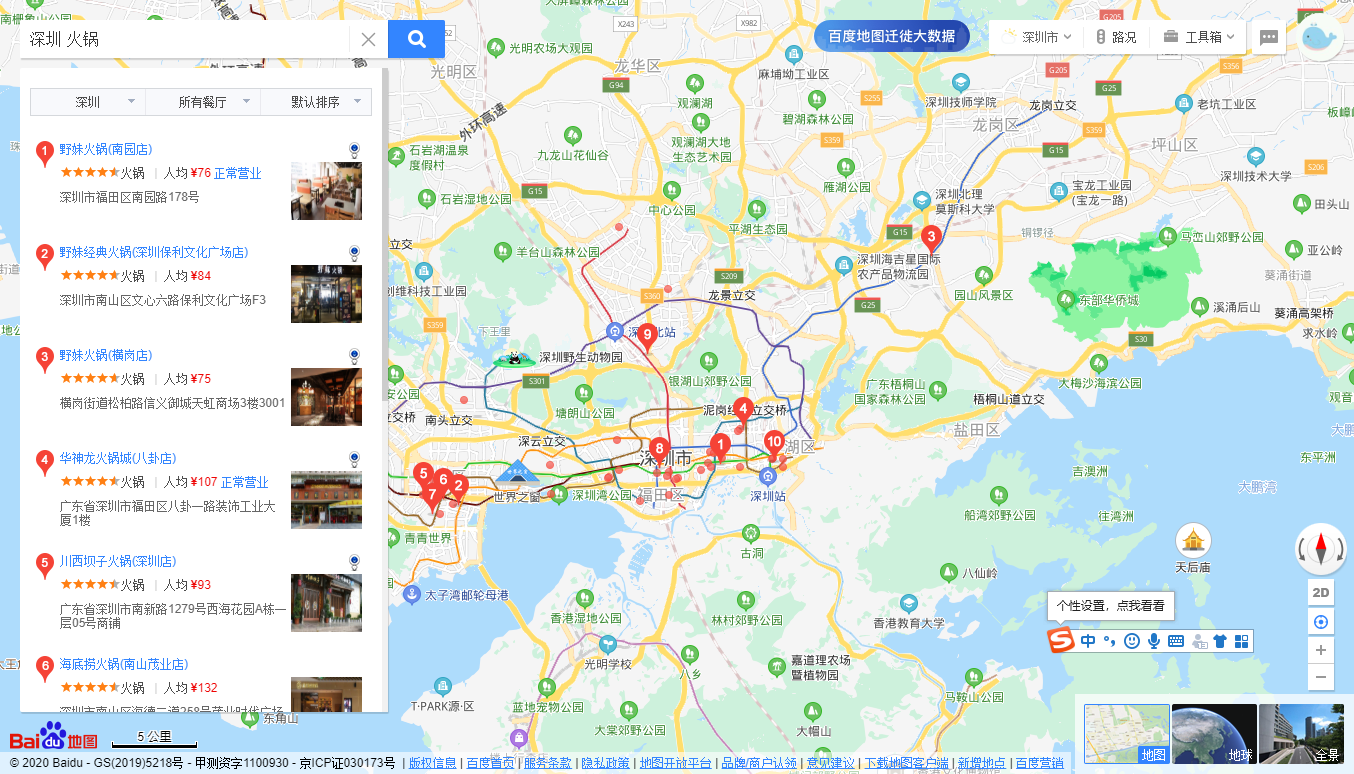
采集场景 在百度地图首页(https://map.baidu.com)输入【城市+关键词】搜索,采集搜索结果列表页。示例中关键词为【深圳 火锅】,可根据需求进行更换,同时支持自动批量输入多个关键词。 采集字段 搜索关键词、商家名称、人均、地址等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/6/16 八爪鱼版本:V8…
在 客户端界面介绍 里,我们简单讲了数据采集的2种模式:【使用模板采集数据】和【自定义配置采集数据】。【使用模板采集数据】之前已经讲过,点击学习 【自定义配置采集数据】稍微复杂一点,我们将用1个系列的8节课来学习。在这8节课中,我们将介绍使用八爪鱼自行配置采集流程,进行网页数据采集的基础知识。学完这8节课,能够轻松采集到90%的网页数据。 第1课:自定义配置采集数据基本介绍(含智能识别) 本课 第2课:采集单个数据 第3课:采集列表数据 第4课:采集表格数据 第5课:需依次点击多个链接进入详情,采集每个详情…
