
通过八爪鱼云采集,可以实现多个任务并发采集,极大提高采集效率。
云采集原理是什么?什么样的规则可实现云加速?本文将详细讲解。
一、云采集原理
云采集是指,使用由八爪鱼提供的云服务集群进行数据采集。八爪鱼拥有5000+云服务器,7*24小时不间断运行(一台云服务器可看做一个云节点)。
八爪鱼的采集任务运行在云节点上时:
a. 在满足可拆分的情况下,1个任务最多拆成100个子任务。(3类任务可拆分,下文将详细讲解)
b. 1个任务/子任务需占用一个云节点进行采集。也就是说,1个云节点同时只能运行一个任务/子任务。
c. 不同版本的云节点数是不一样的。团队版:4个云节点。企业版:16个动态云节点。
d. 基于以上信息,可能会出现任务/拆分子任务数>云节点数的情况。如果账号内的云节点数已被运行中的任务/子任务占满,则新启动的任务/被拆分的子任务会进入等待队列,直到某个任务/子任务采集完成,释放出多余的节点资源,它们才会有节点进行采集。
如何查看任务的子任务拆分和运行情况?
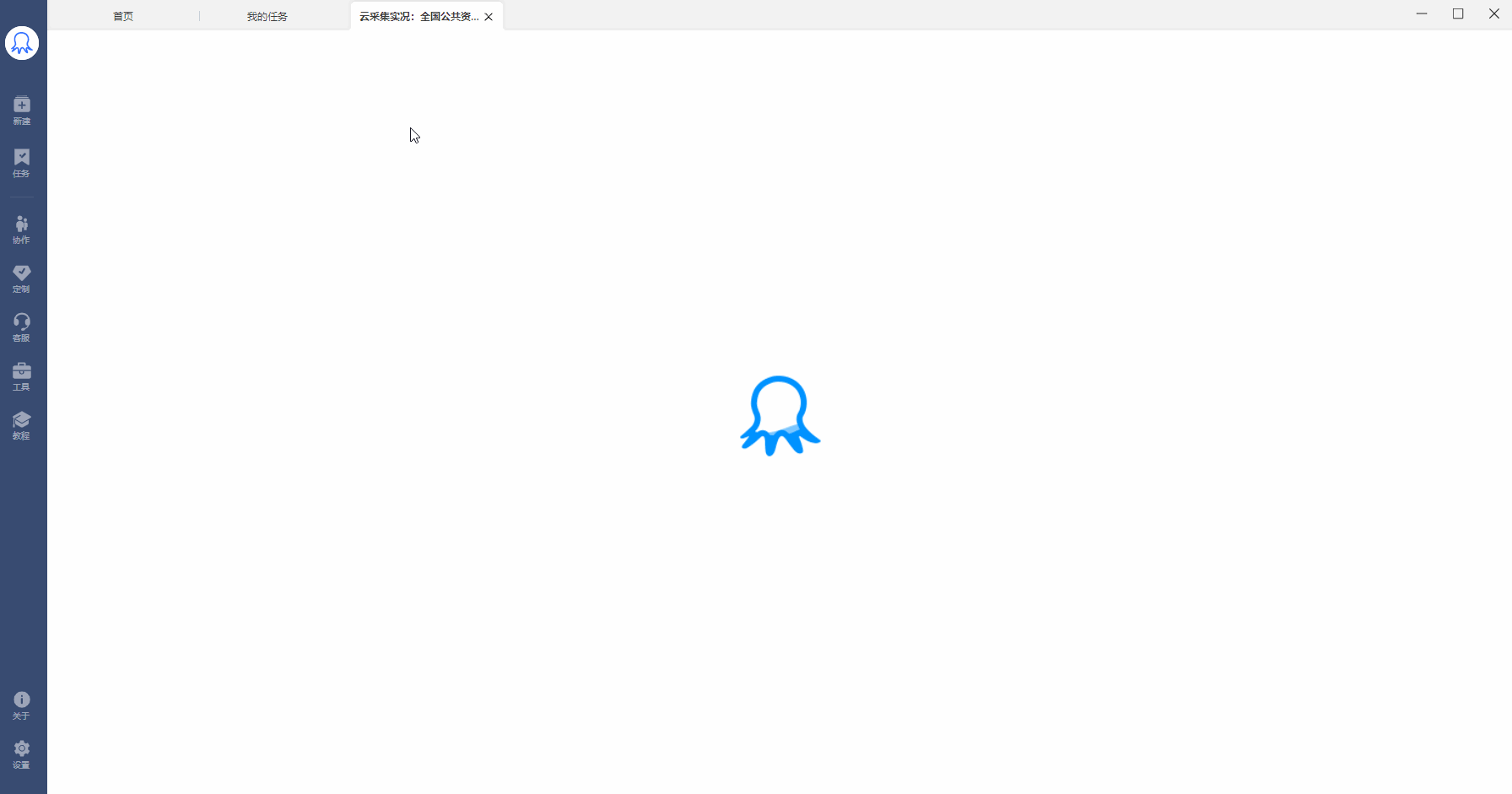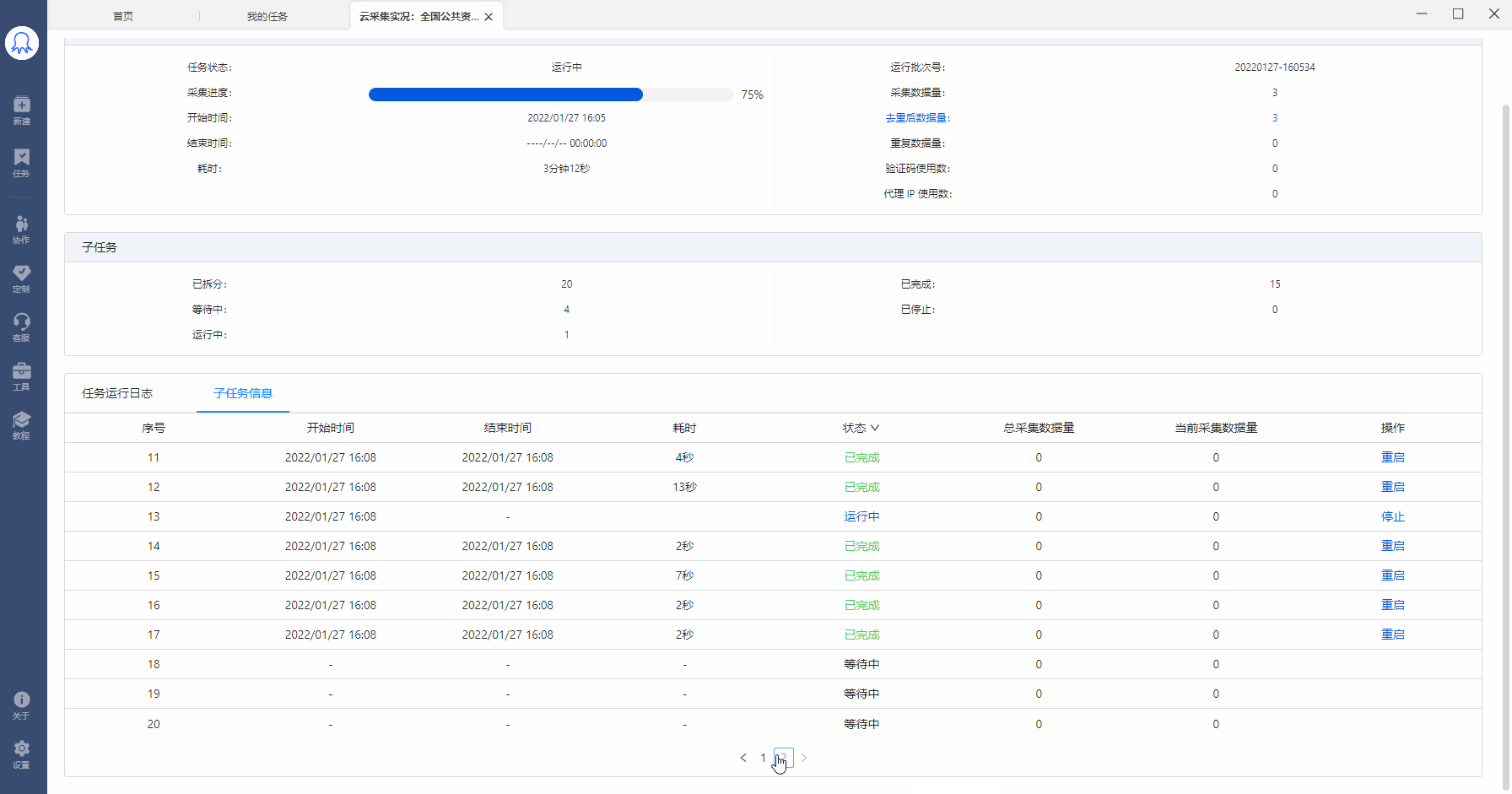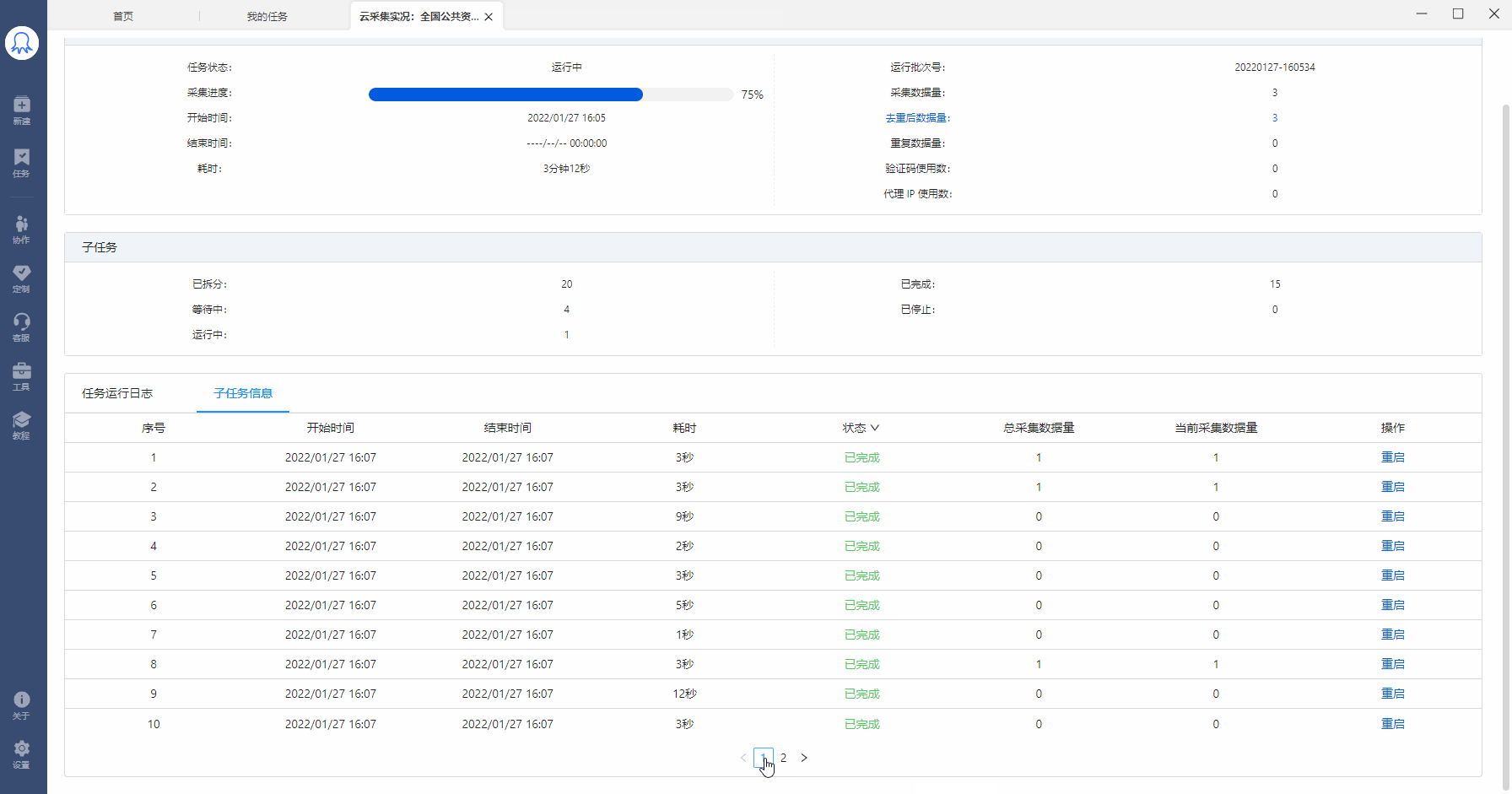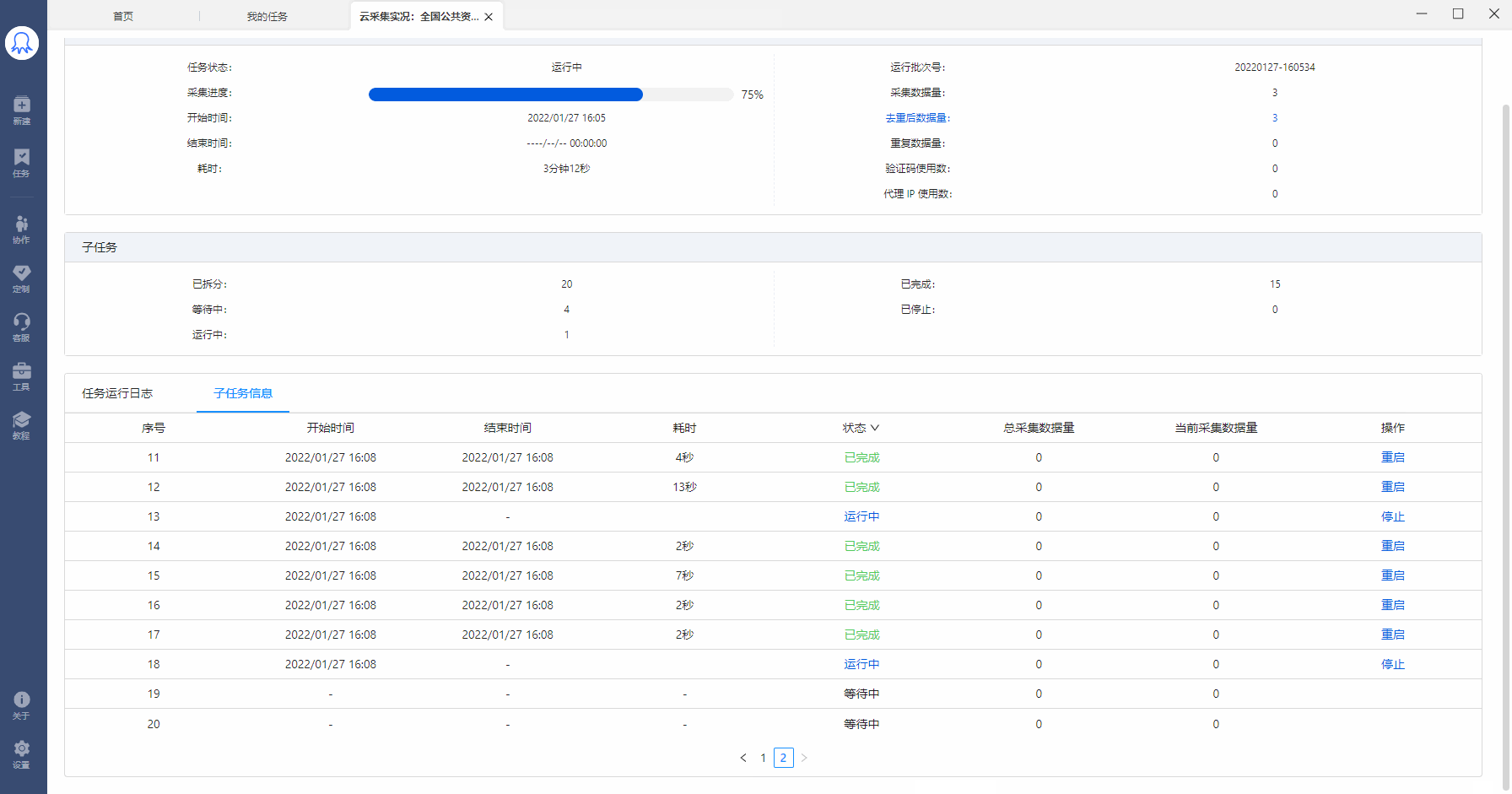
在【我的任务】中找到已运行云采集的任务,点击【详情】,查看当前任务的子任务拆分和运行情况。如图,该任务拆分了30个子任务,其中1个在运行中,4个已完成,25个已完成。
子任务的状态有以下几种:
已拆分:当前任务拆分成了多少个子任务。为1时,表示该任务未进行拆分(任务本身不支持拆分或勾选了云采集不拆分)。大于1时,表示已进行拆分。图中任务拆分成了30个子任务。
等待中:还未运行采集的子任务个数。
运行中:当前正在采集数据的子任务个数。每个任务会占用一个云节点,故所有任务在运行的子任务数之和小于等于账号节点数。
已完成:已完成采集的子任务个数。
已停止:程序自动停止采集或人为手动停止采集的子任务个数。
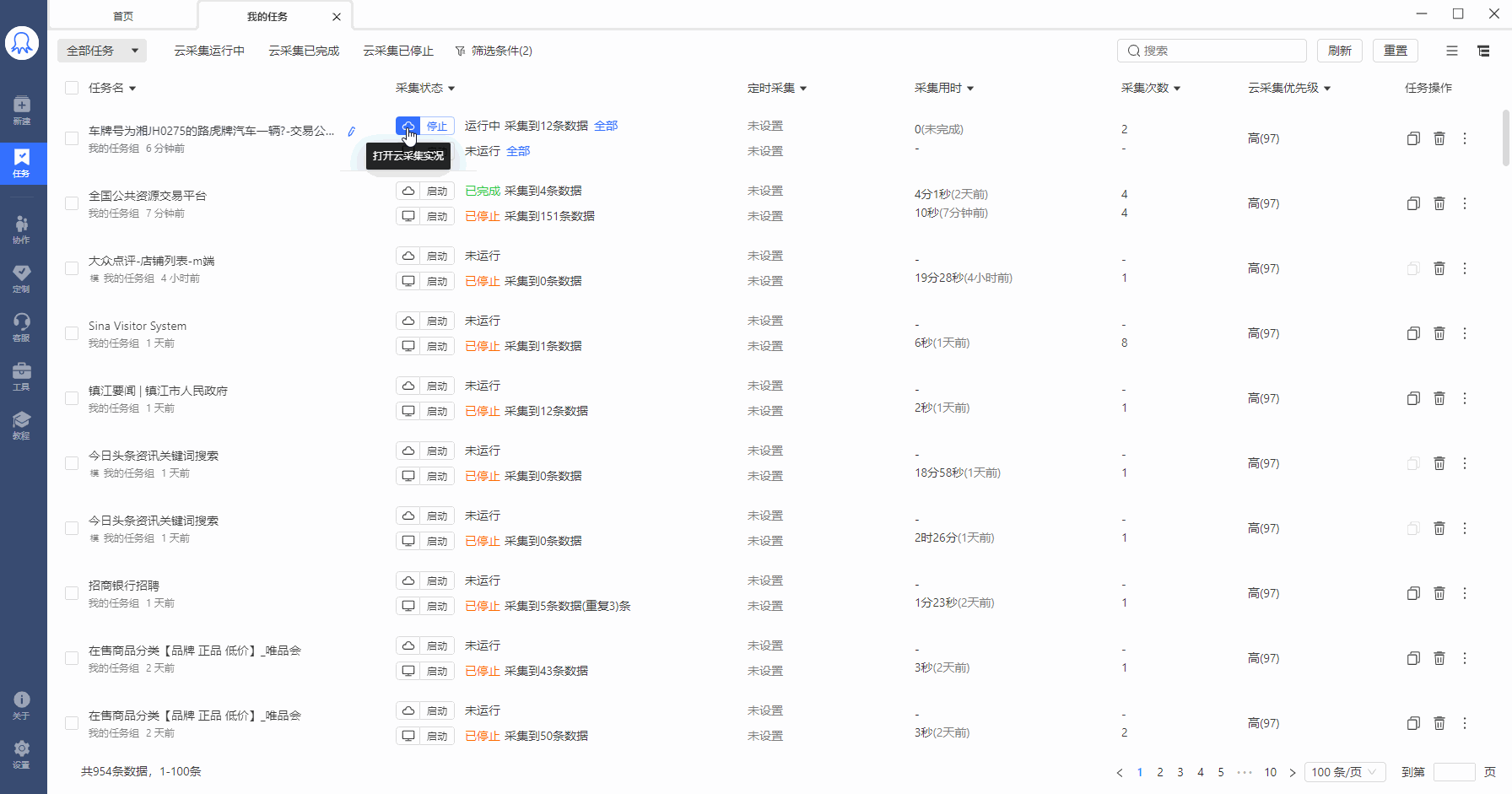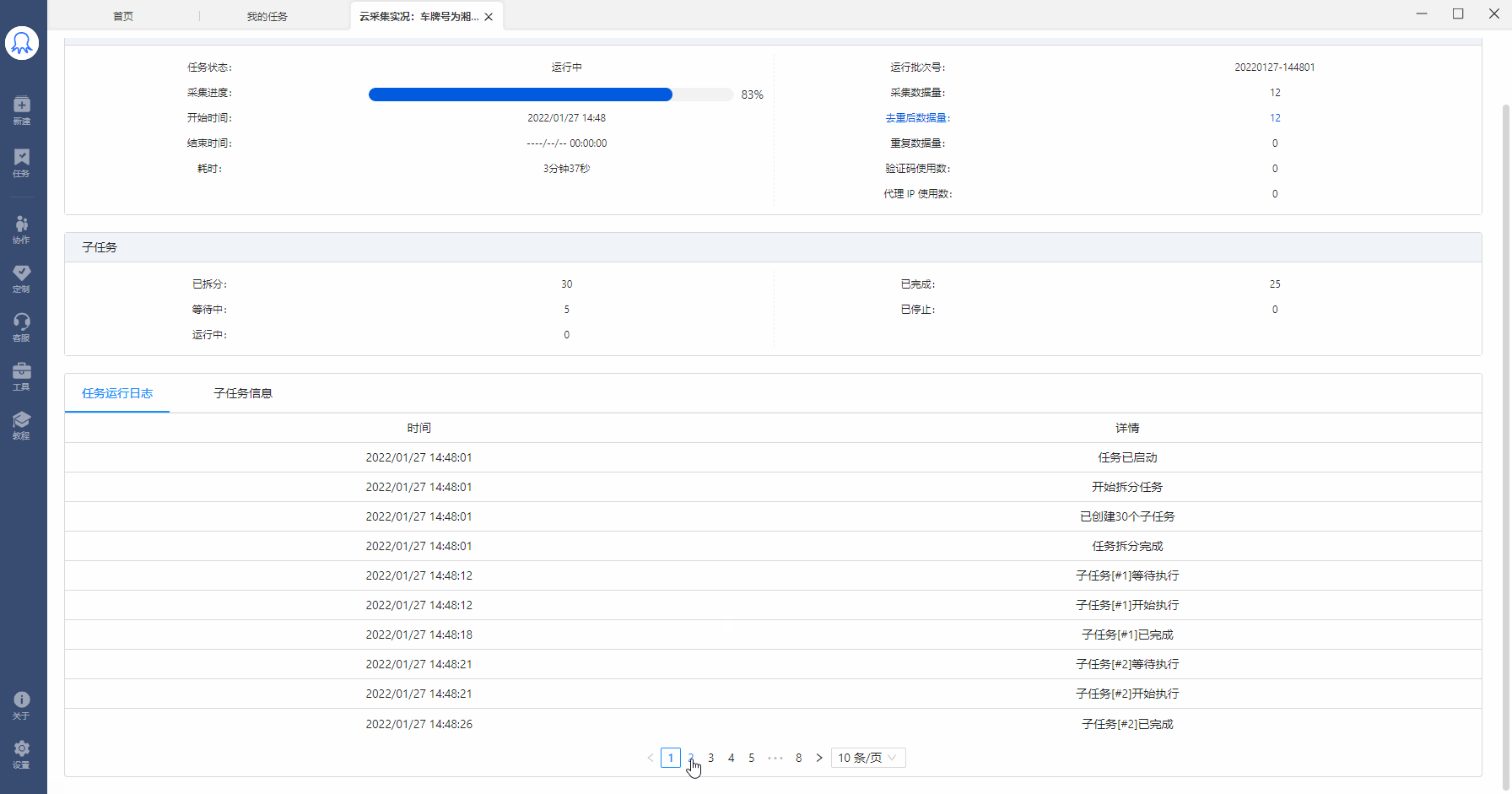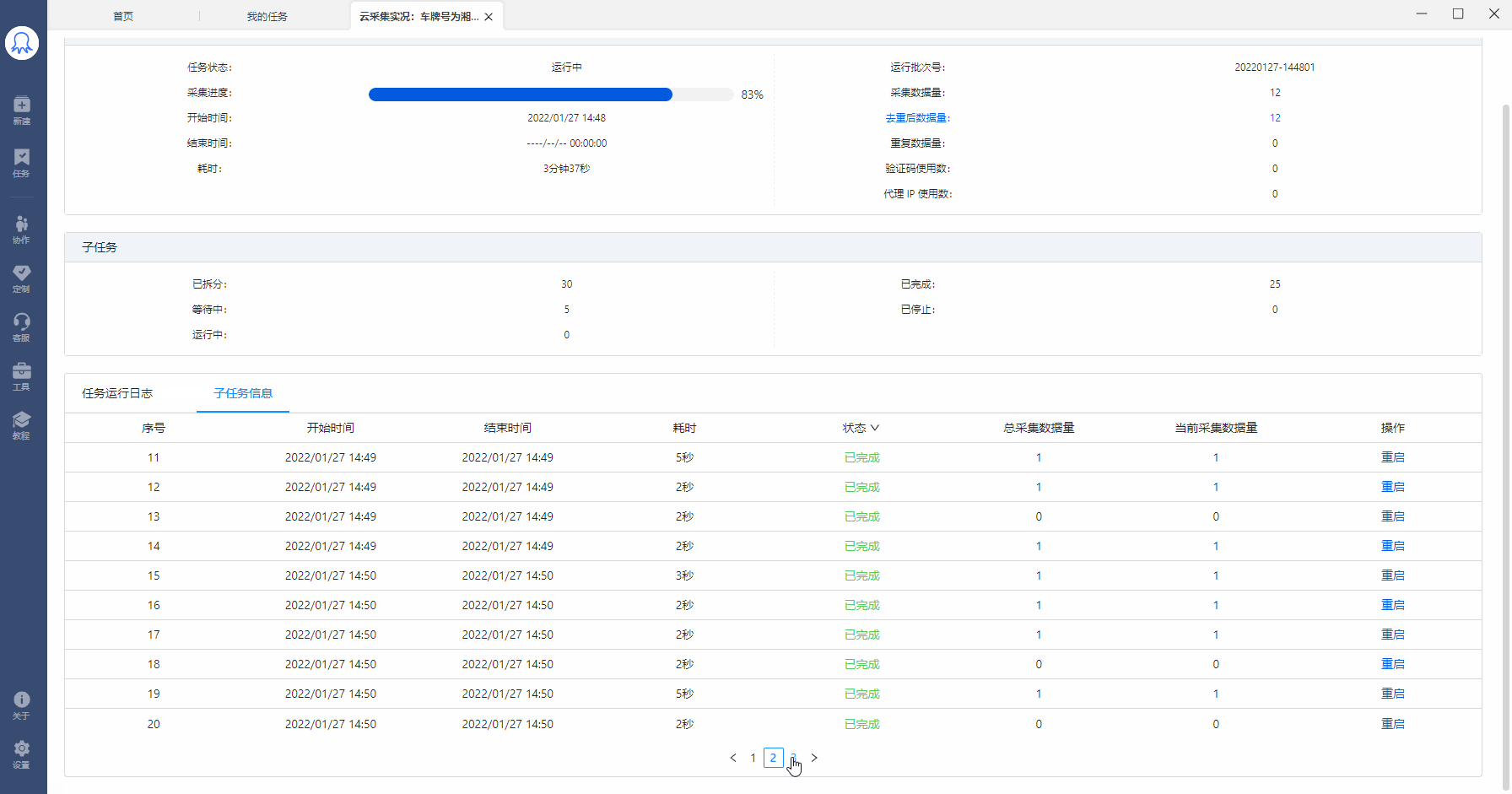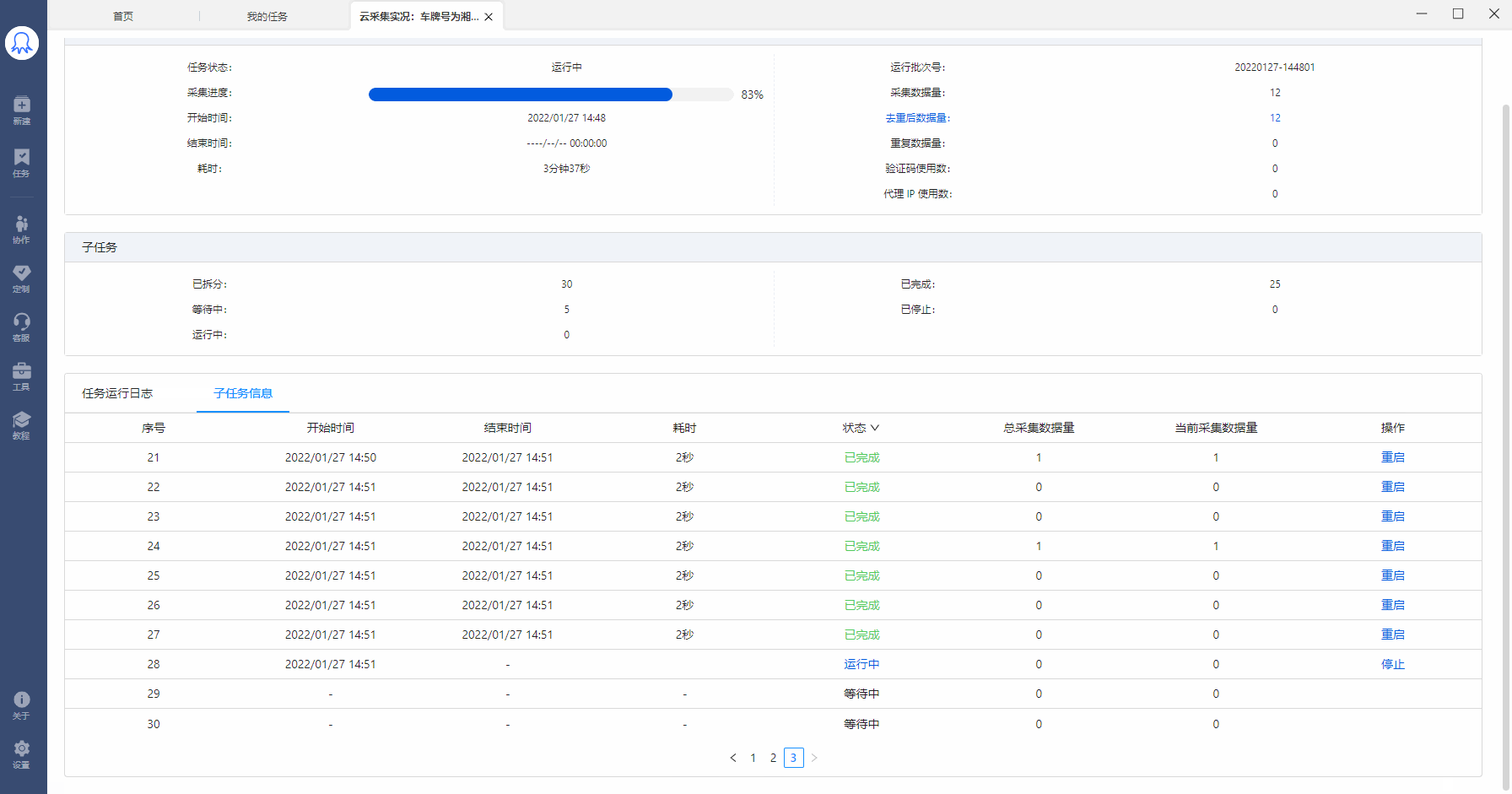
如果运行了某个云采集任务,但是一直没有采集到数据, 可以在子任务状态中查看是否有子任务在运行,如果子任务都是等待中状态,说明该账号的云节点已被其他任务占满。请等待多余的云节点资源释放出来。
二、云采集加速设置
由云采集原理可知,一个任务要拆分成多个子任务,使用更多的云节点同时运行多个子任务,才能实现加速采集的效果。
任务如果要拆分成子任务,需满足一定条件。以下三类任务是可以拆分的:
1、URL循环
2、文本循环
3、固定元素循环
1、URL循环
URL循环类的规则,可拆分成多个子任务,同时运行在多个云节点上,实现加速。
当URL数<=100时,拆分成与URL数相同的子任务数。当URL数>100时,拆分成URL数/100的子任务数(取整数)。例,循环中有30个URL,将被拆分成30个子任务;循环中有278个URL,将被拆分成2个子任务。

示例网址:
http://www.ggzy.gov.cn/information/html/a/310000/9002/202112/07/0031236998b01f4446f08757e7e483ab1f3f.shtml
http://www.ggzy.gov.cn/information/html/a/320000/0105/202201/27/003270bfa2bc66b04b528235ec83d0093a45.shtml
.......
http://www.ggzy.gov.cn/information/html/a/310000/0203/202201/27/0031cef8eda48eb542f1b1088460fb51643f.shtml
http://www.ggzy.gov.cn/information/html/a/310000/0203/202201/27/0031b7d56a97e52a45c4b457e7ff3775db01.shtml
等30个详情页网址,需要采集每个详情页中的数据。
Step1:建立URL循环
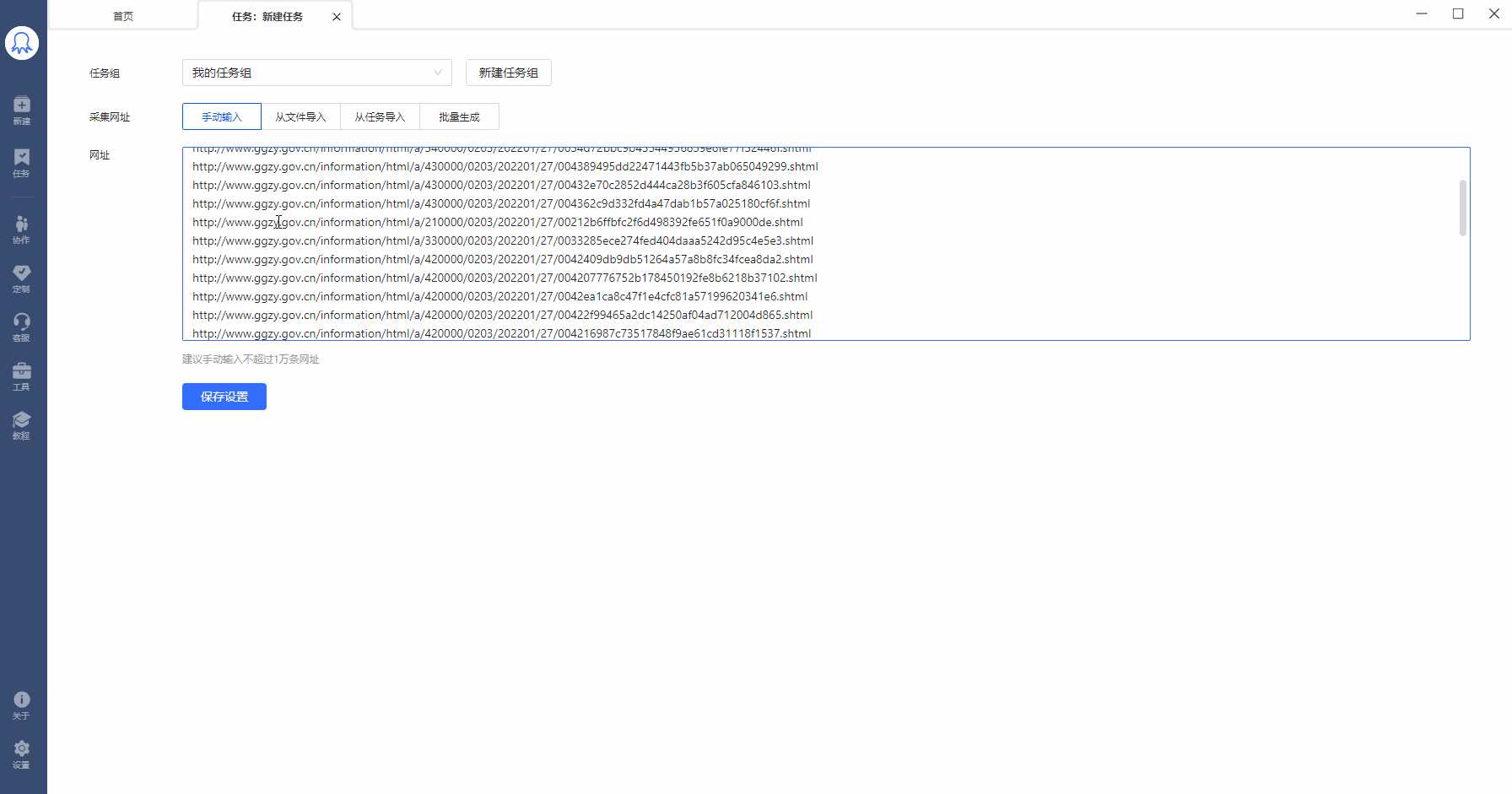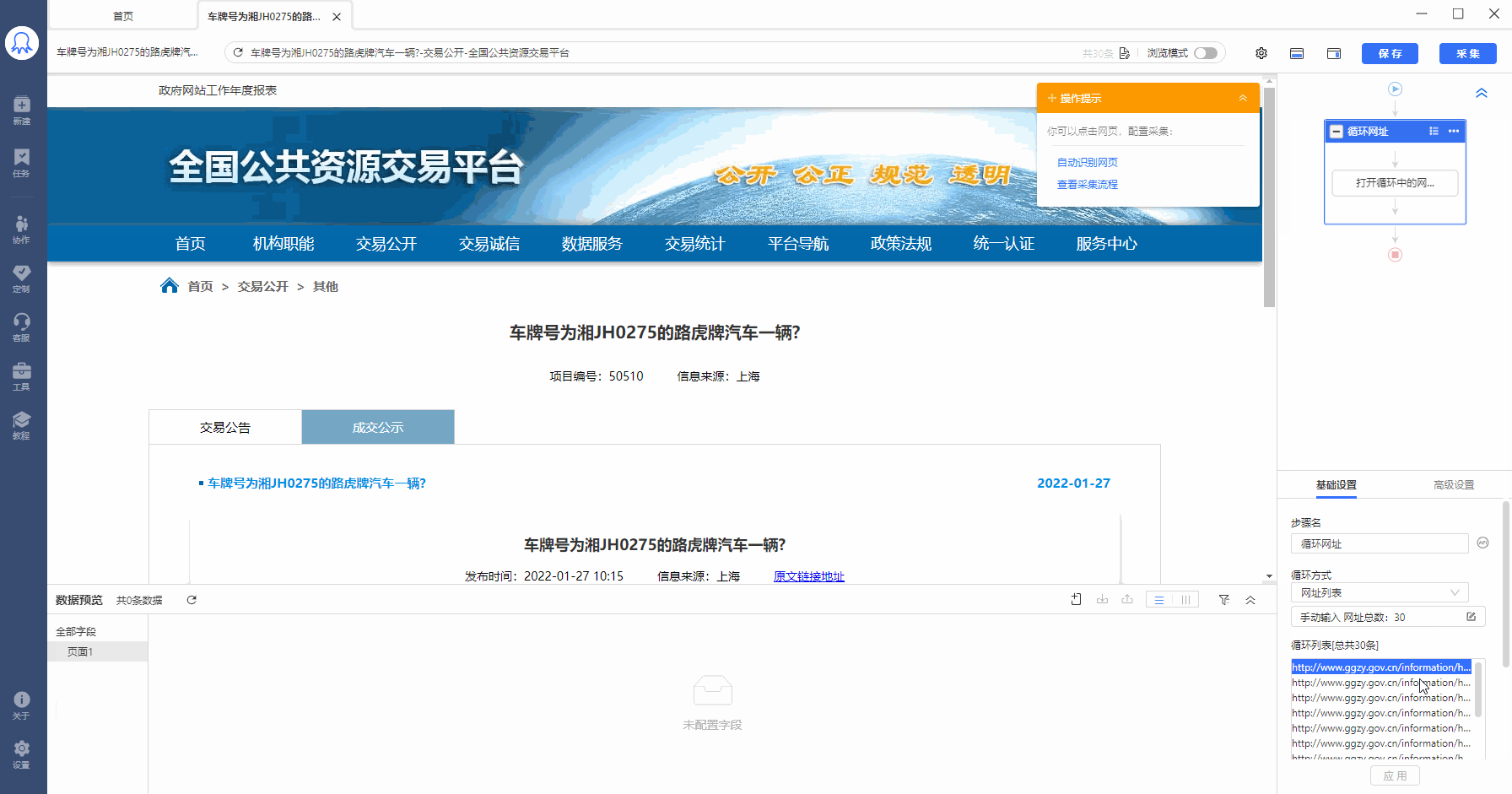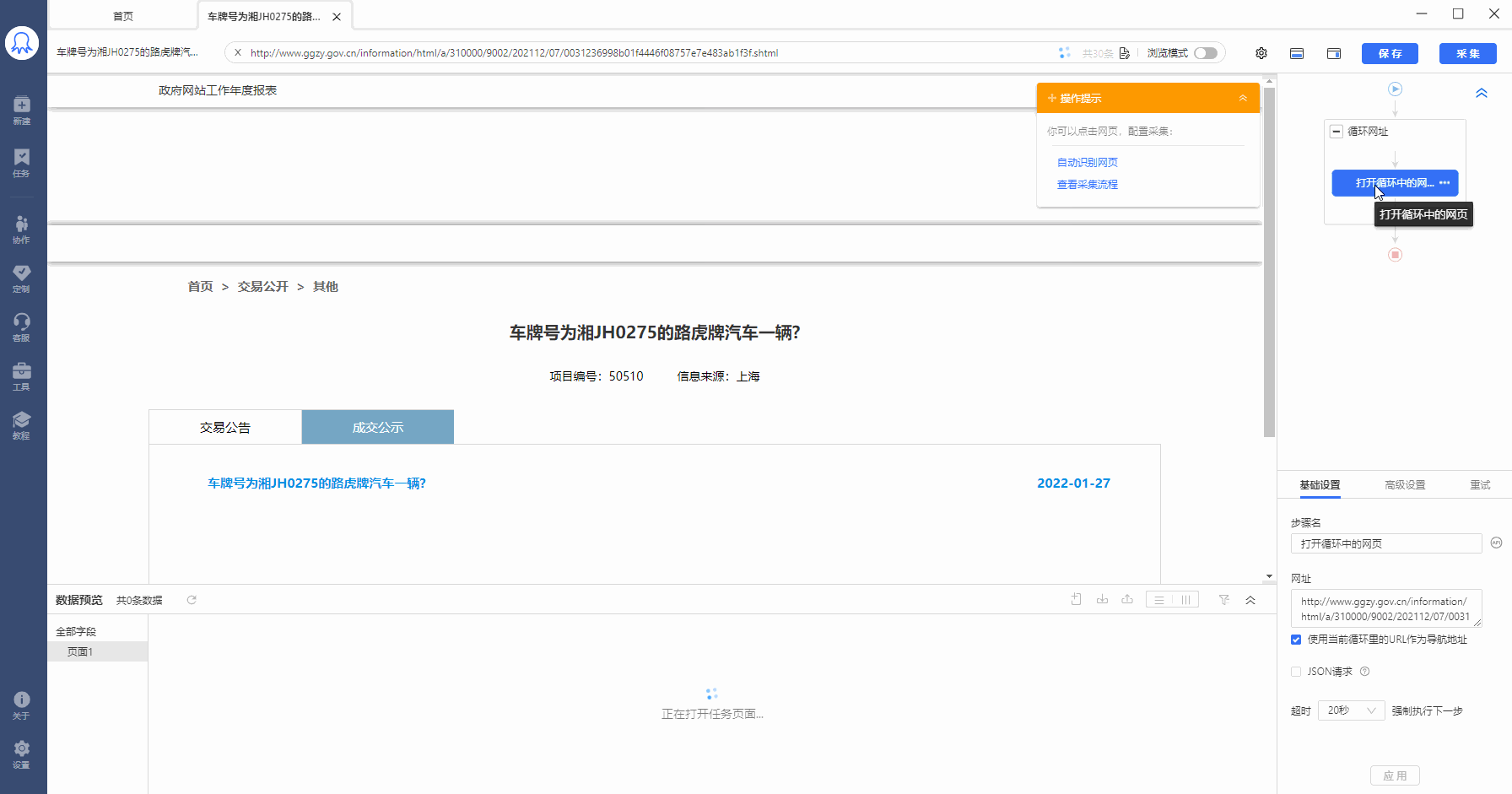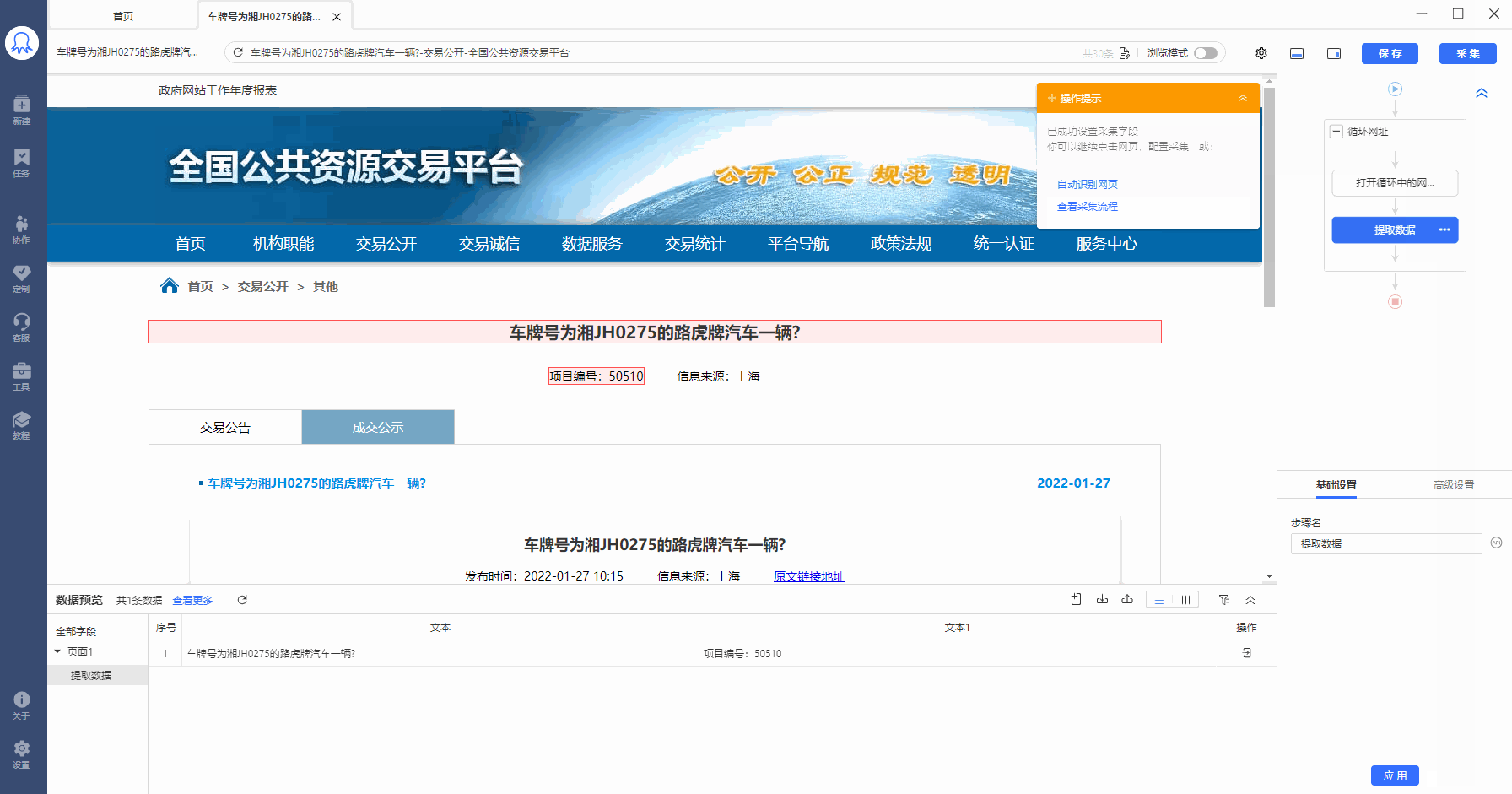
Step2:启动云采集,点击【详情】,可以看到此任务的30条URL,拆分成30个子任务同时采集,加快采集速度
常用场景:当有一个商品/文章列表,需要点击商品/文章链接,进入详情页采集时,我们可以做一个【循环-点击链接-提取详情数据】的规则,在一个任务中依次点击进入详情页采集数据。也可以先采集列表的商品/文章链接,然后使用URL循环,配合云采集将其拆分成多个子任务,分配到多个云节点上同时采集,极大加快采集速度。
示例网址:http://deal.ggzy.gov.cn/ds/deal/dealList.jsp
先获得列表页商品网址,然后再用上文讲的方法,用URL循环,配合云采集加速采集。获得列表页网址演示如下:

2、文本循环
文本循环类的规则,可拆分成多个子任务,同时运行在多个云节点上,实现加速。
当输入的文本数<=100时,拆分成与输入文本数相同的子任务数。当输入文本数>100时,拆分成输入文本数/100的子任务数。
文本循环拆分原理和URL循环一致,通过对文本循环的拆分,达到加速采集的效果。具体可见 批量输入关键词查询,采集查询结果 教程。

3、固定元素列表循环
固定元素列表类的规则,可拆分成多个子任务,同时运行在多个云节点上,实现加速。
当固定元素列表类数<=100时,拆分成与固定元素列表数相同的子任务数。当固定元素列表数>100时,拆分成固定元素列表数/100的子任务数。
值得注意的是,【循环-点击元素】类规则,使用【固定元素列表】的循环方式后云拆分,才会有明显加速效果,如下图所示:
【循环-点击元素】有2种常见采集场景:① 点击商品/文章链接进入详情页,采集详情页数据的情况。② 点击条件类链接进行分类采集。

如果是【循环-提取数据】类规则,没有点击步骤,则使用【固定元素列表】的循环方式后云拆分,加速效果并不明显,如下图所示:

下面讲一个【循环-点击元素】类规则使用【固定元素列表】进行云拆分的实例:
示例网址:http://deal.ggzy.gov.cn/ds/deal/dealList.jsp
采集需求:点击进入商品详情页,采集每个详情页中的数据。
Step1:建立循环列表,查看自动生成的循环方式。可以看到,循环方式为固定元素列表循环:使用XPath定位,一条XPath对应循环列表中的一个列表。如图示例中,20条XPath对应20个商品列表。
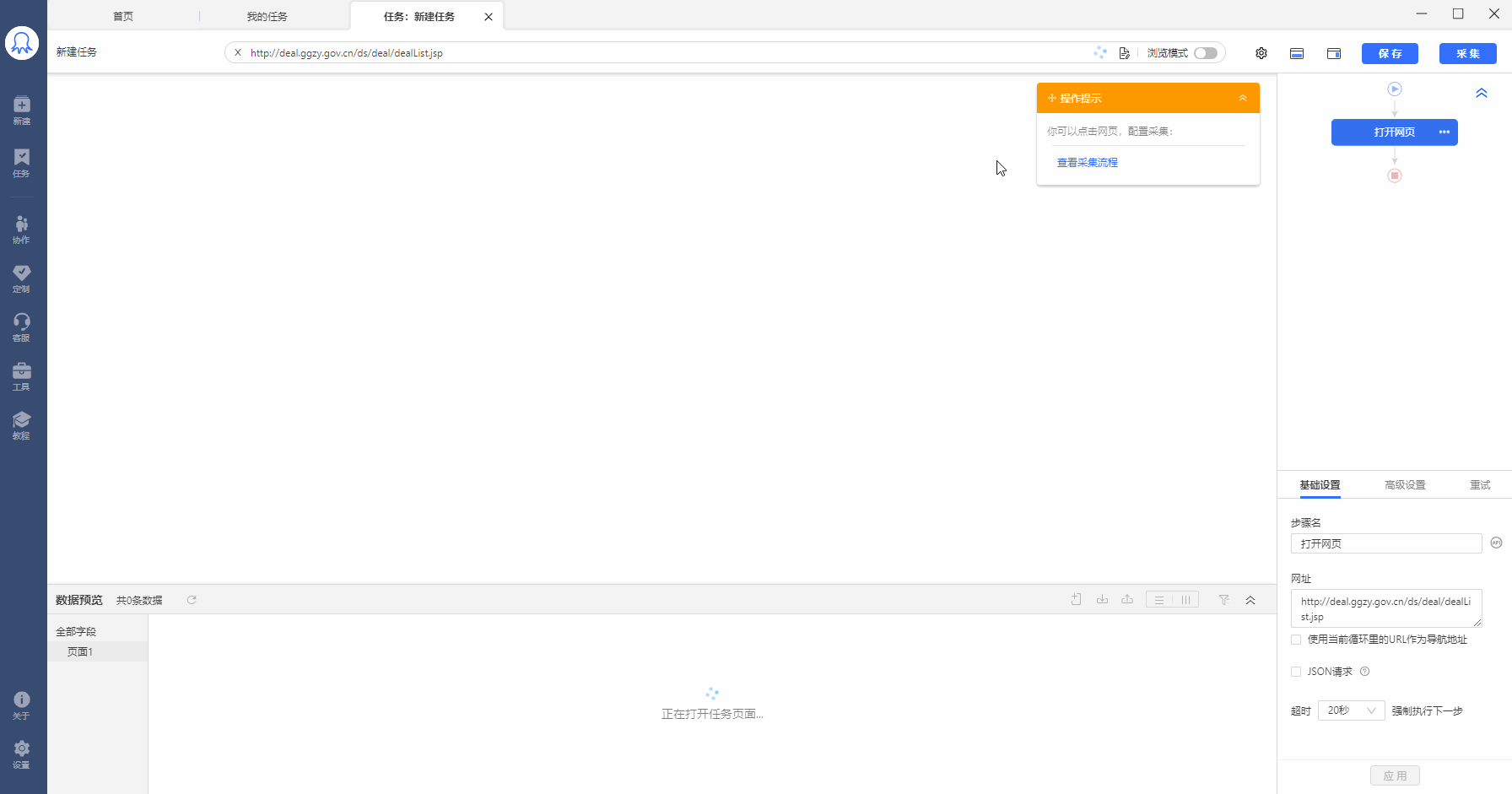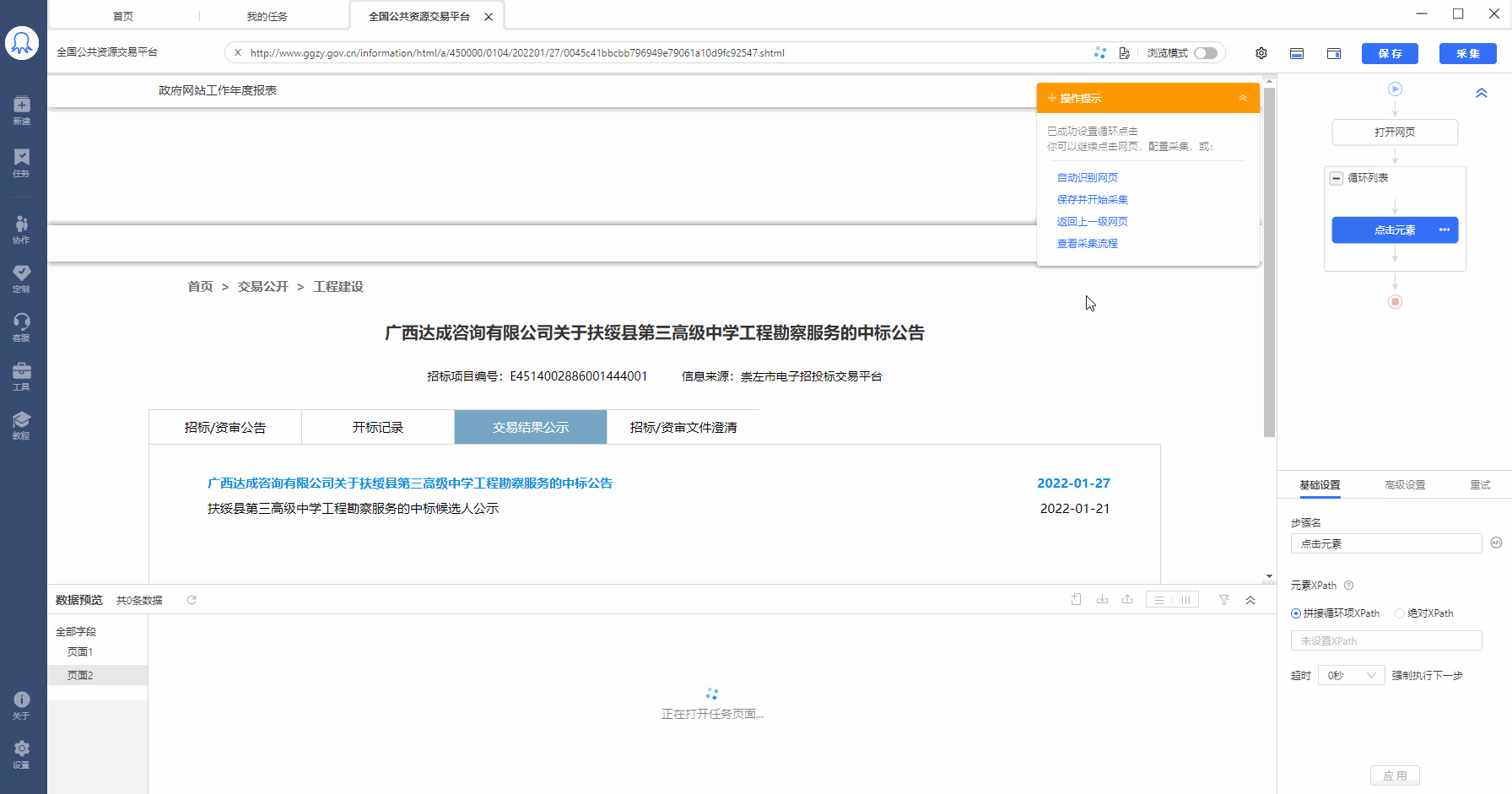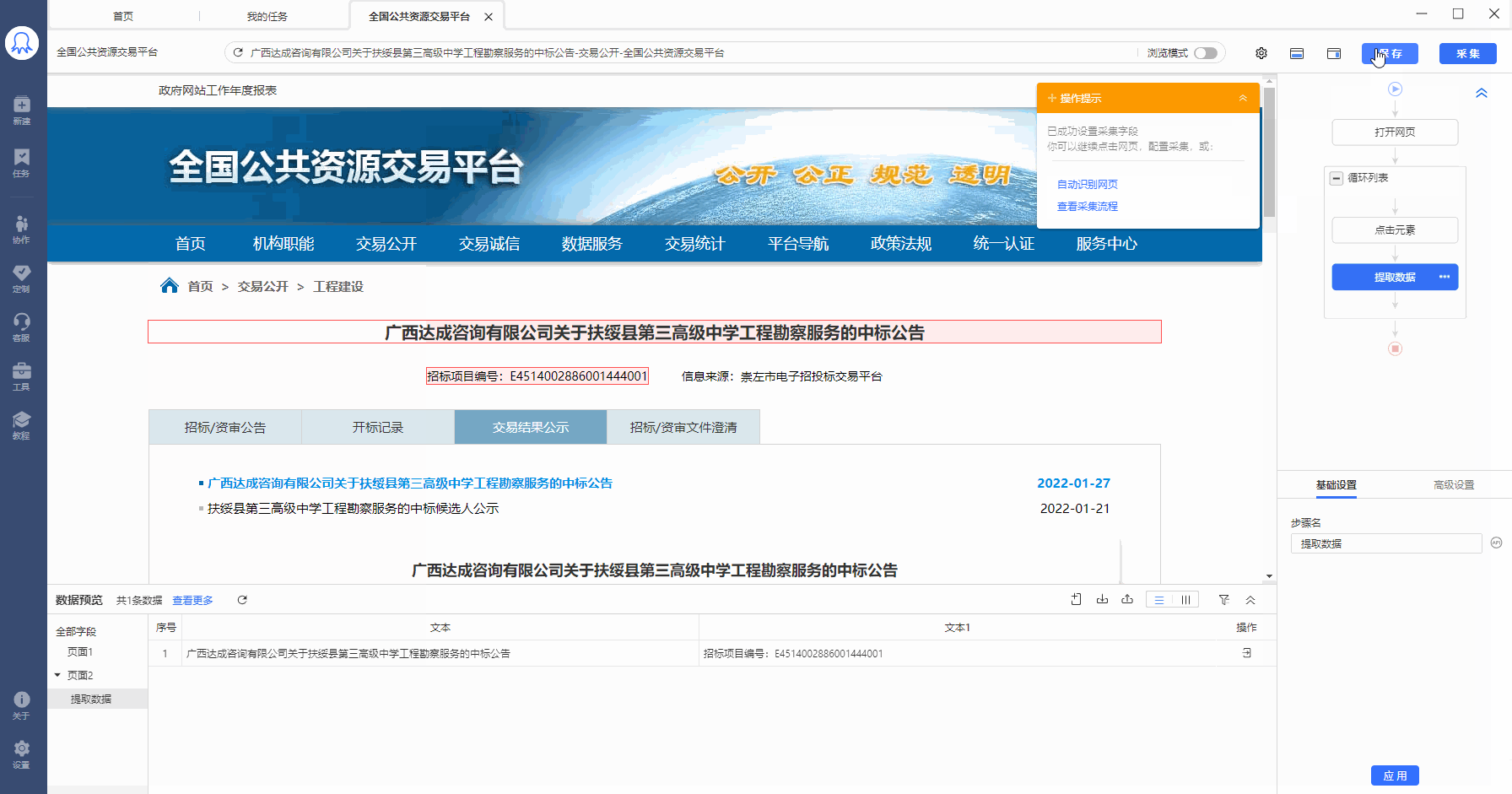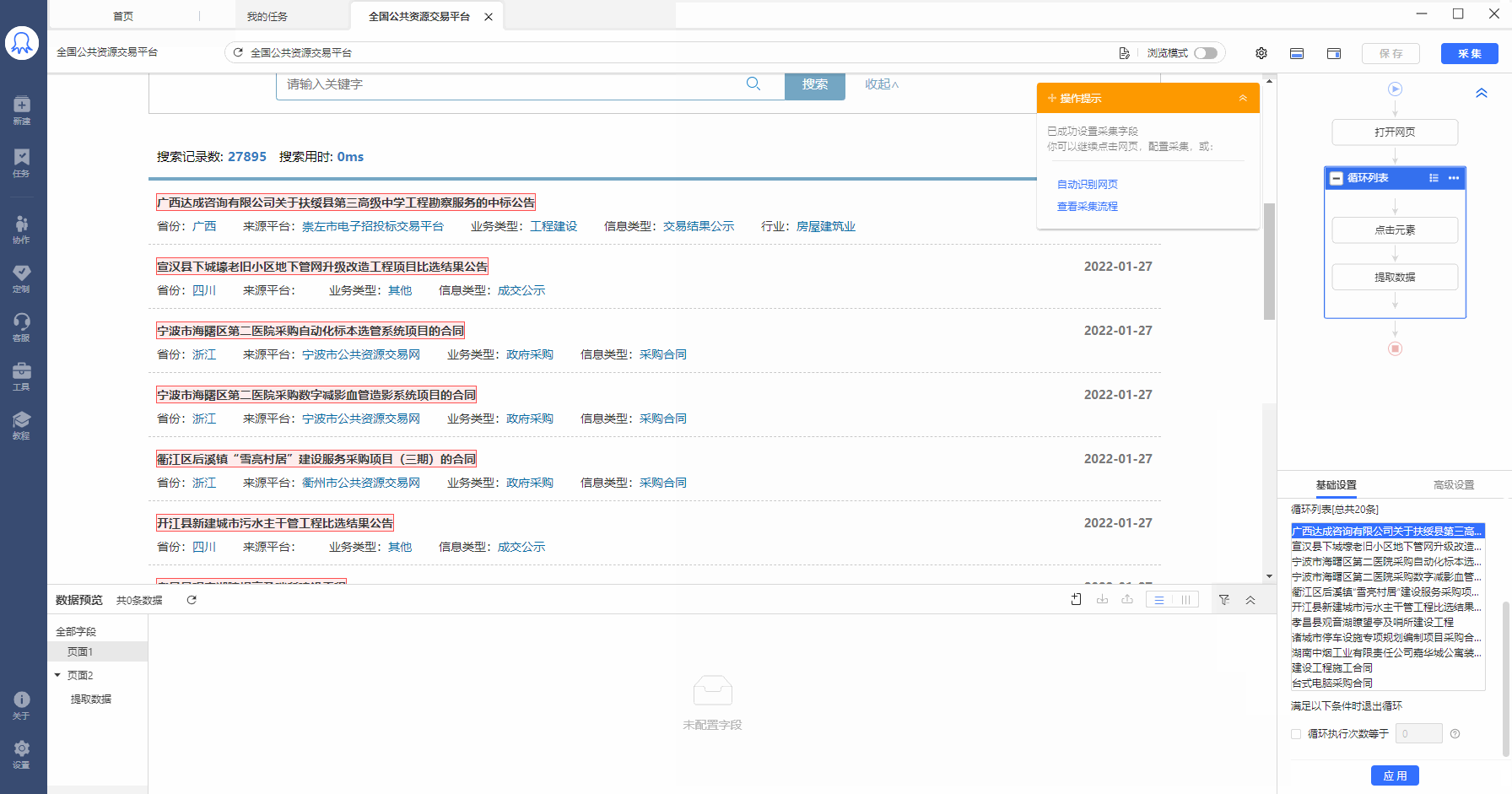
Step2:启动云采集,点击【详情】,可以看到此任务的20条固定元素列表,拆分成20个子任务,加快采集速度。
【不固定元素列表】为【固定元素列表】的关系
对于【循环-点击元素】类规则,八爪鱼自动生成的循环方式一般为【不固定元素列表】,以便于云上拆分加速。
本质上【不固定元素列表】和【固定元素列表】都是使用XPath进行定位,两者可以相互改写。下面看2个改写实例。
将【不固定元素列表】改为【固定元素列表】
示例网址:https://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=%B4%F3%CA%FD%BE%DD、
采集需求:采集页面前20个图片的地址
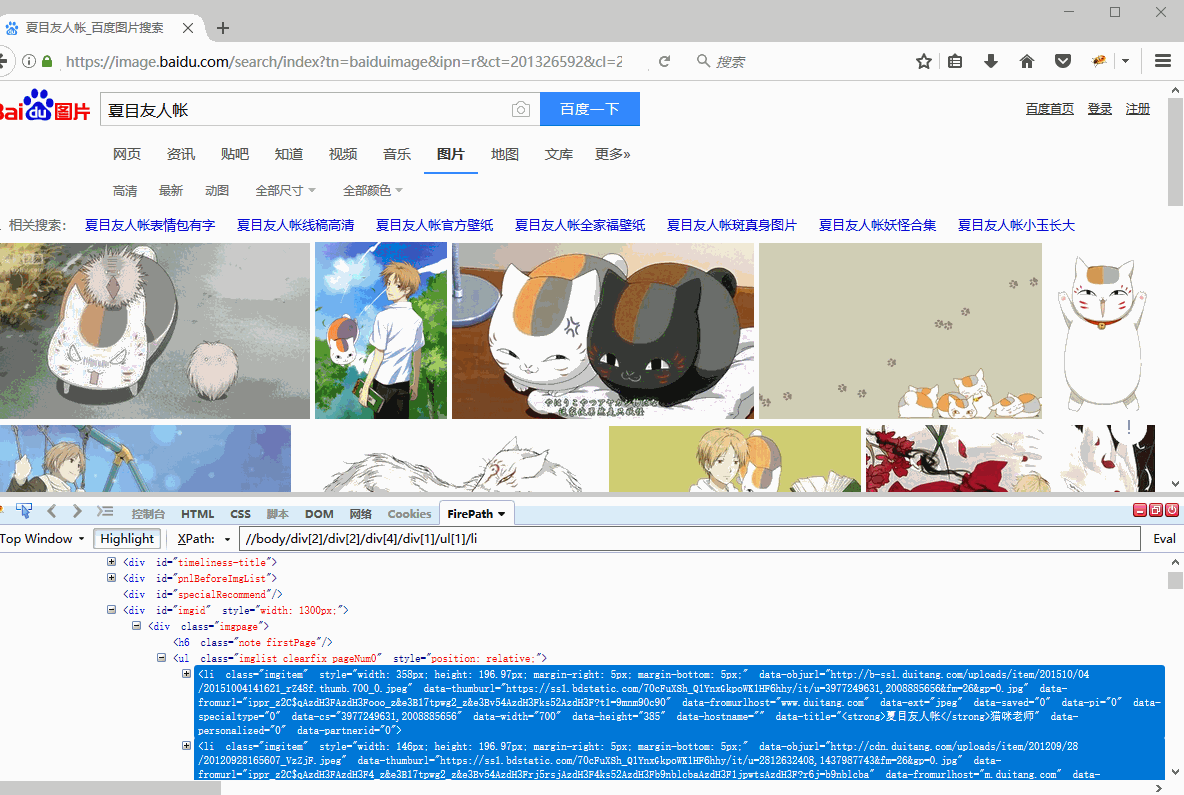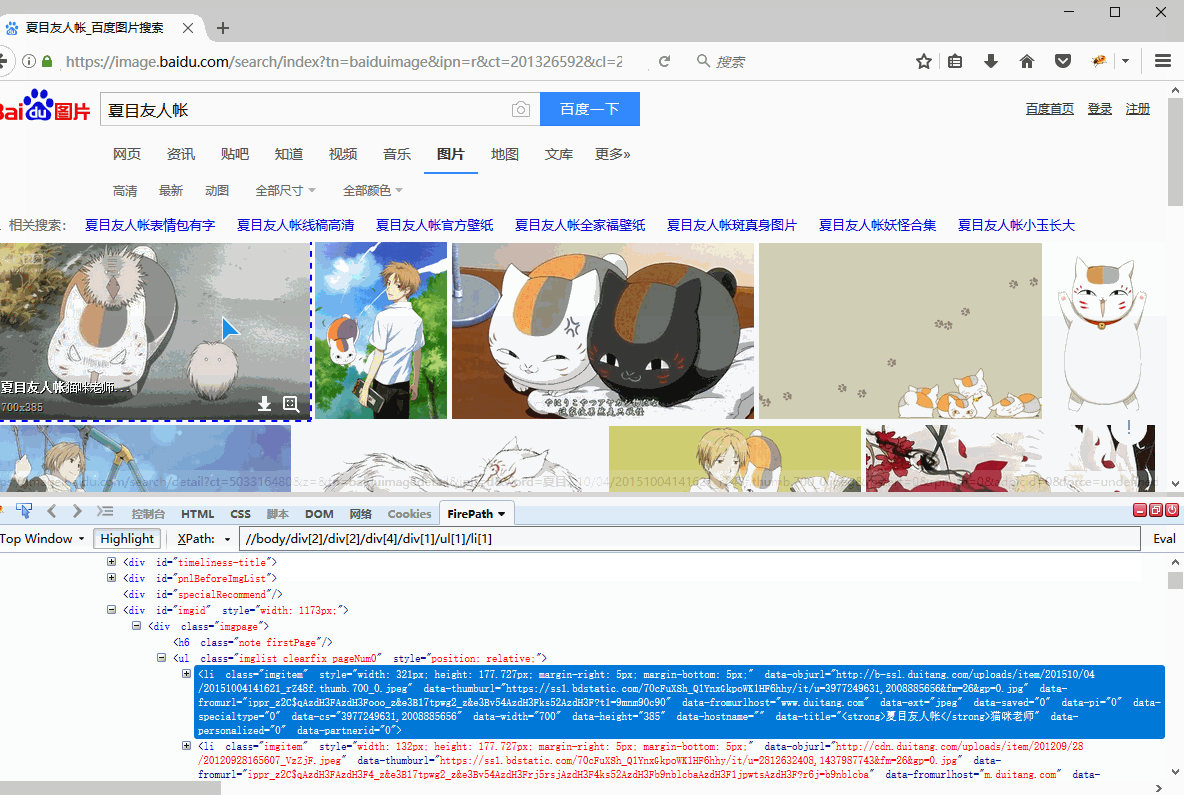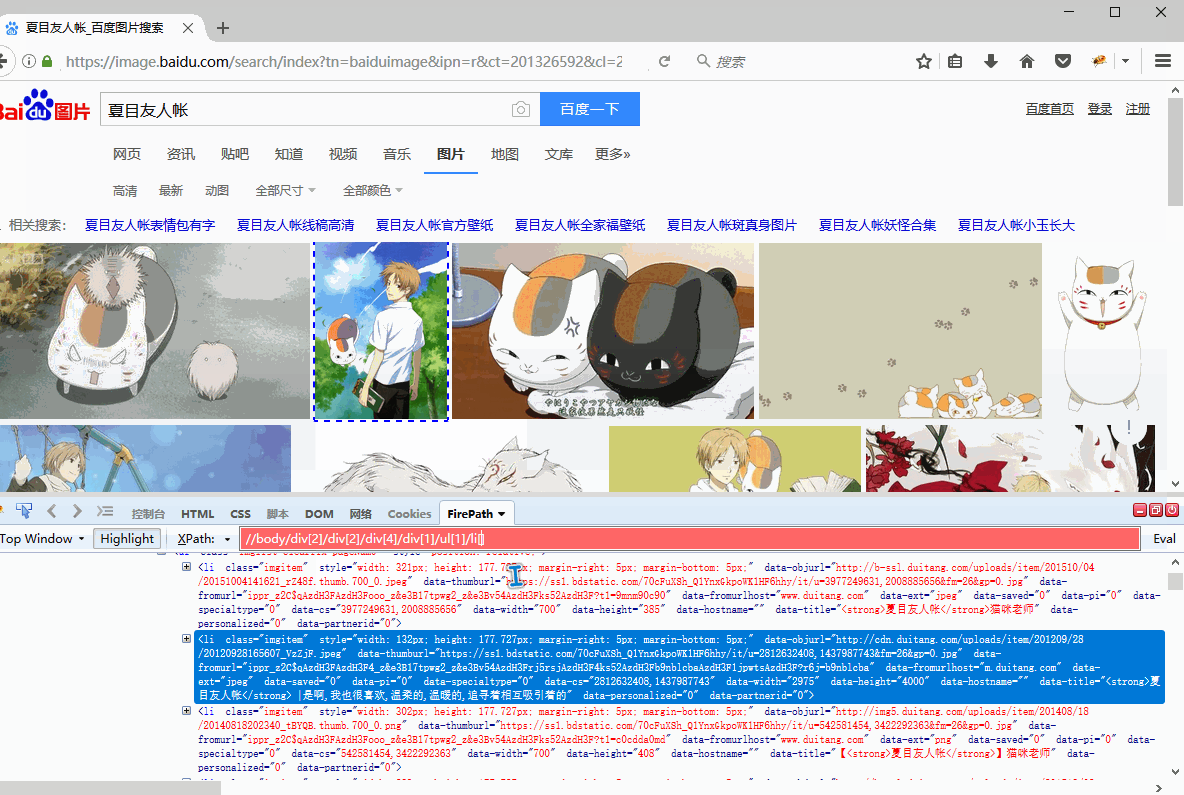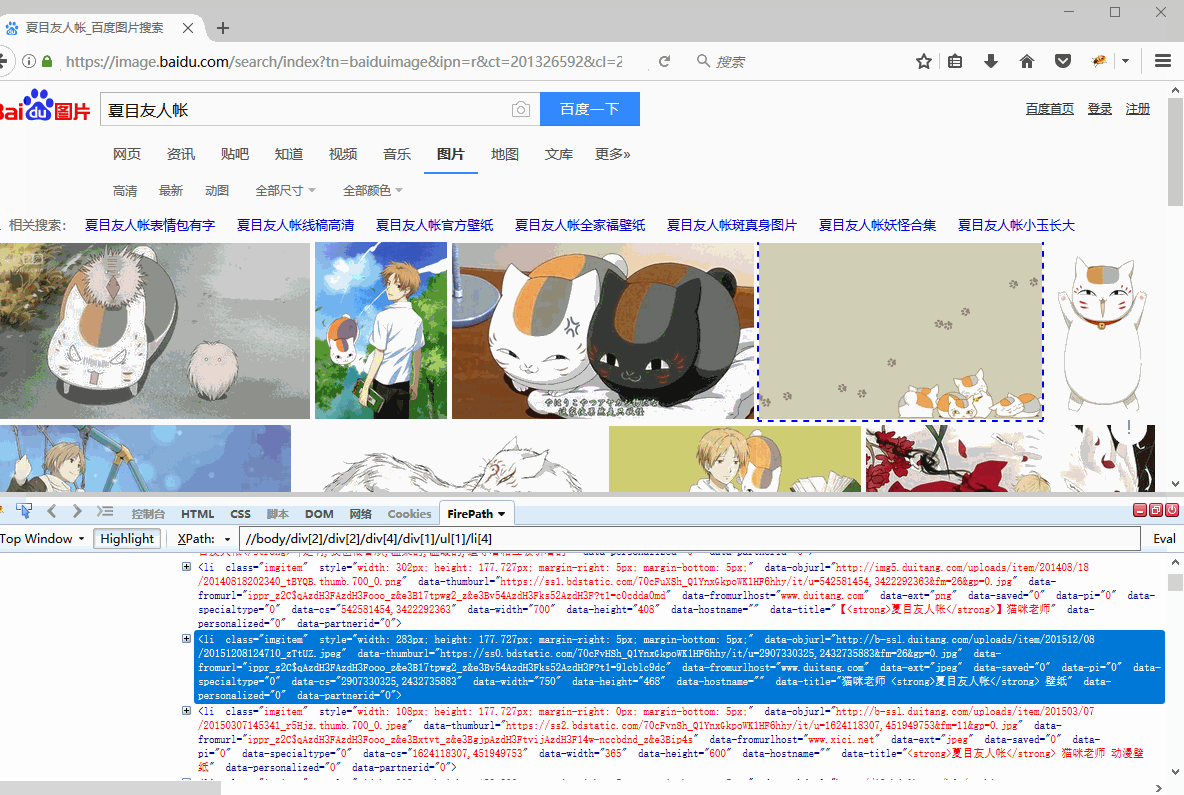
按照采集列表数据的方法,配置规则。自动生成的循环方式为【不固定元素列表】,定位XPath为://body/div[2]/div[2]/div[4]/div[1]/ul[1]/li。
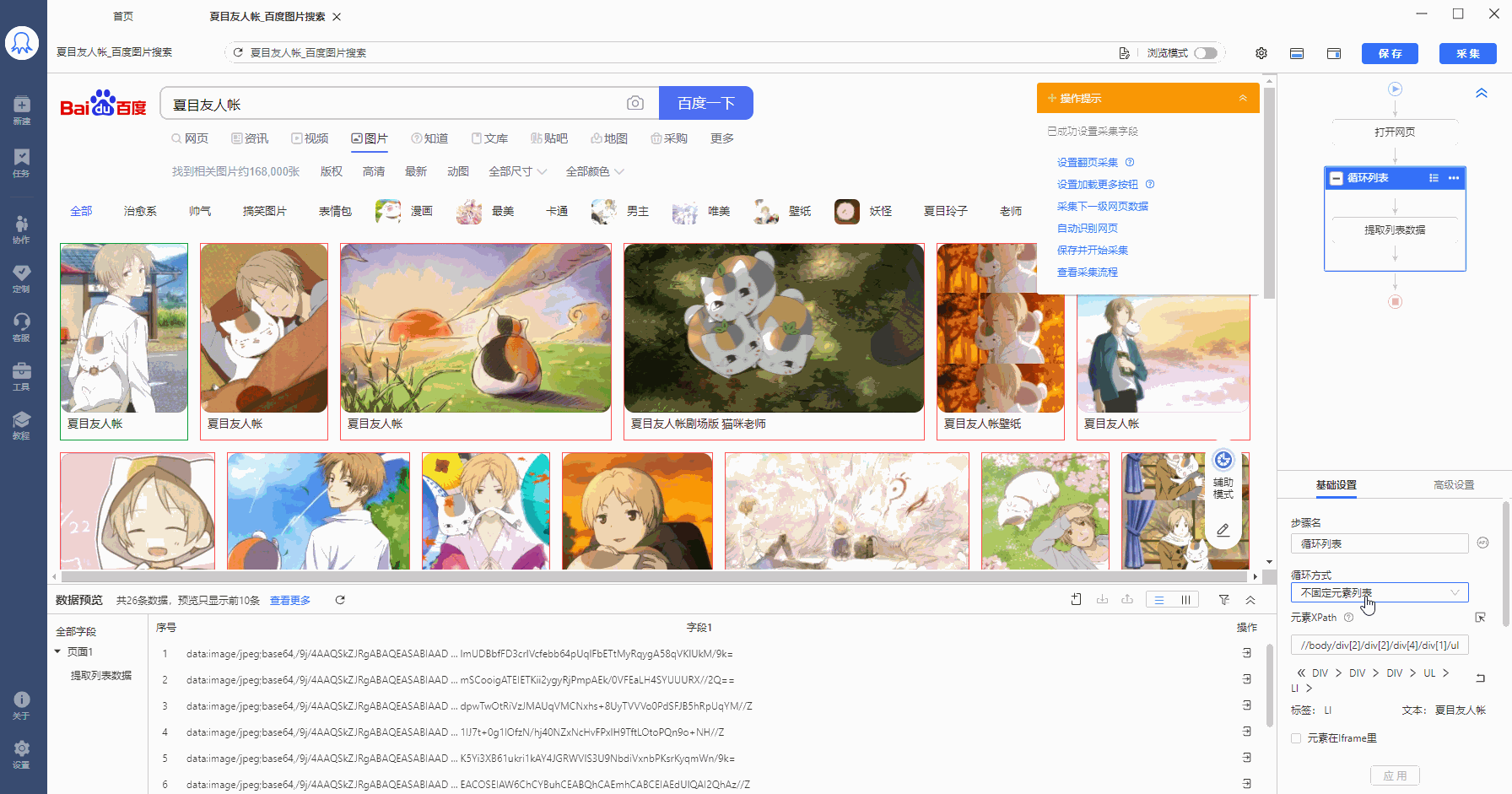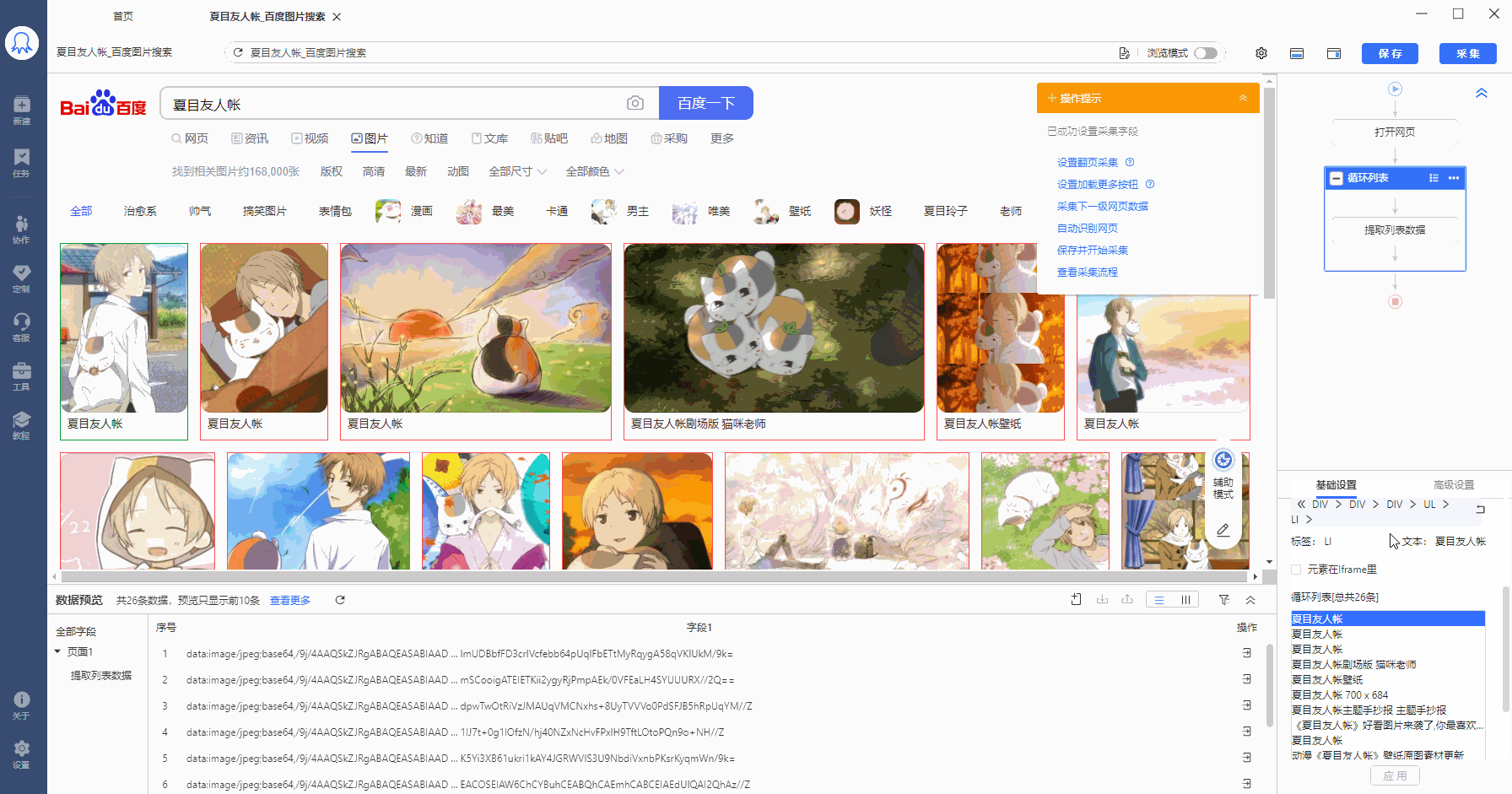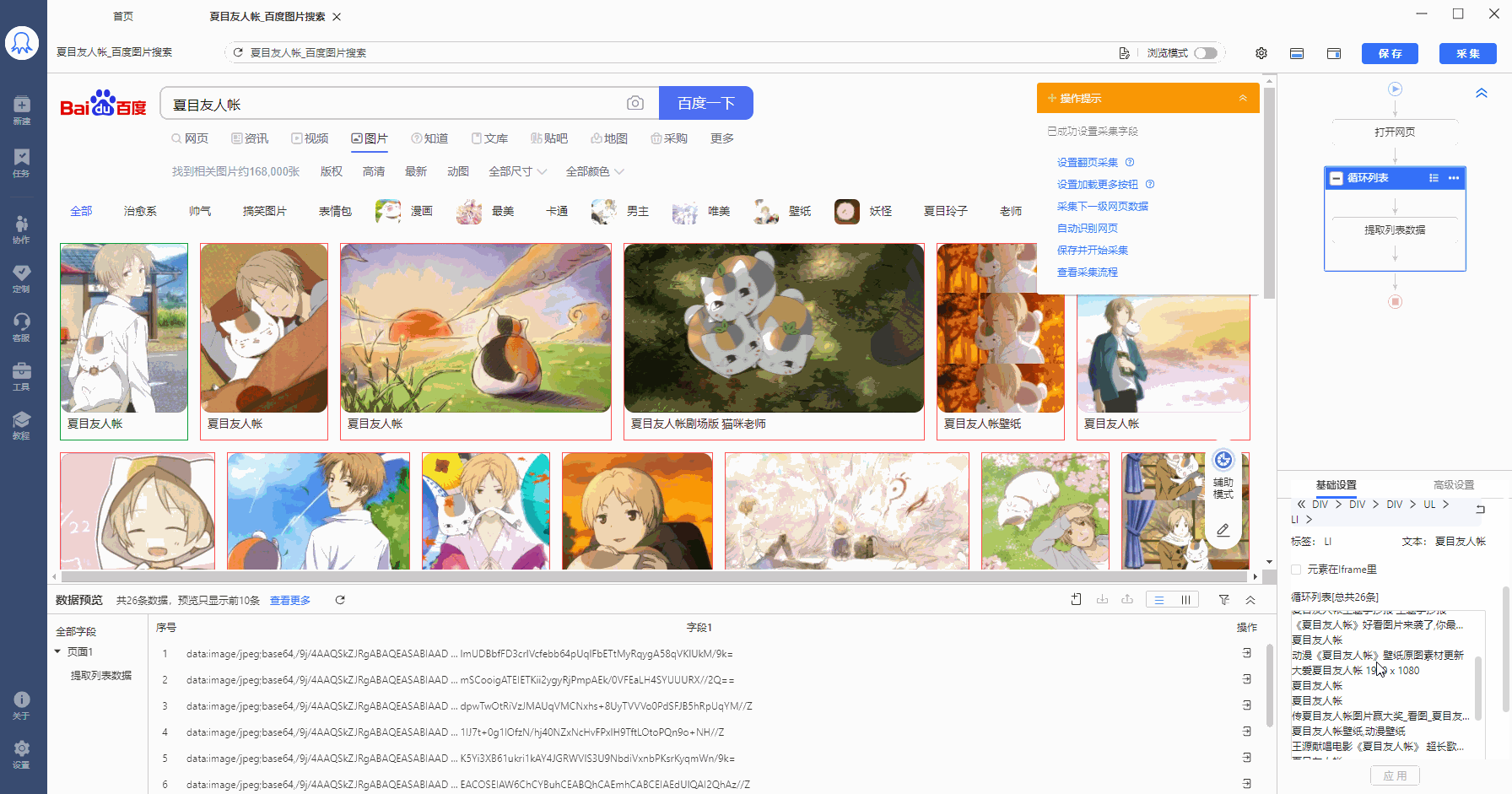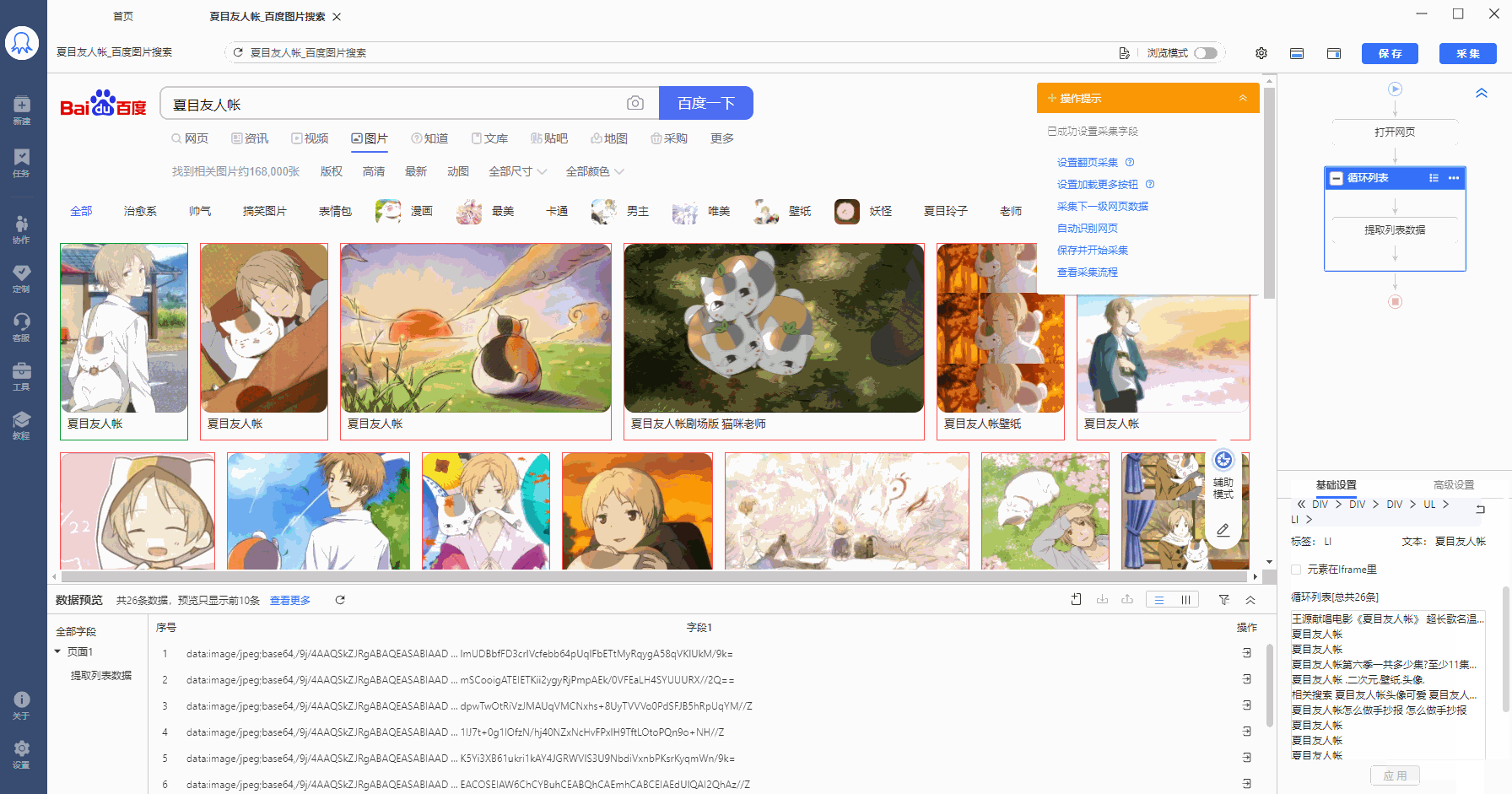
将//body/div[2]/div[2]/div[4]/div[1]/ul[1]/li 复制到在火狐浏览器中观察,LI代表列表,LI[1]是指第1个列表,LI[2]是指第2个列表......按照这个规律,20个列表的【固定元素列表】定位XPath为:
//body/div[2]/div[2]/div[4]/div[1]/ul[1]/li[1]
//body/div[2]/div[2]/div[4]/div[1]/ul[1]/li[2]
......
//body/div[2]/div[2]/div[4]/div[1]/ul[1]/li[19]
//body/div[2]/div[2]/div[4]/div[1]/ul[1]/li[20]
(如果固定元素列表很多,可以借助于Excel批量生成功能,根据数字变化规律,自动生成XPath。)
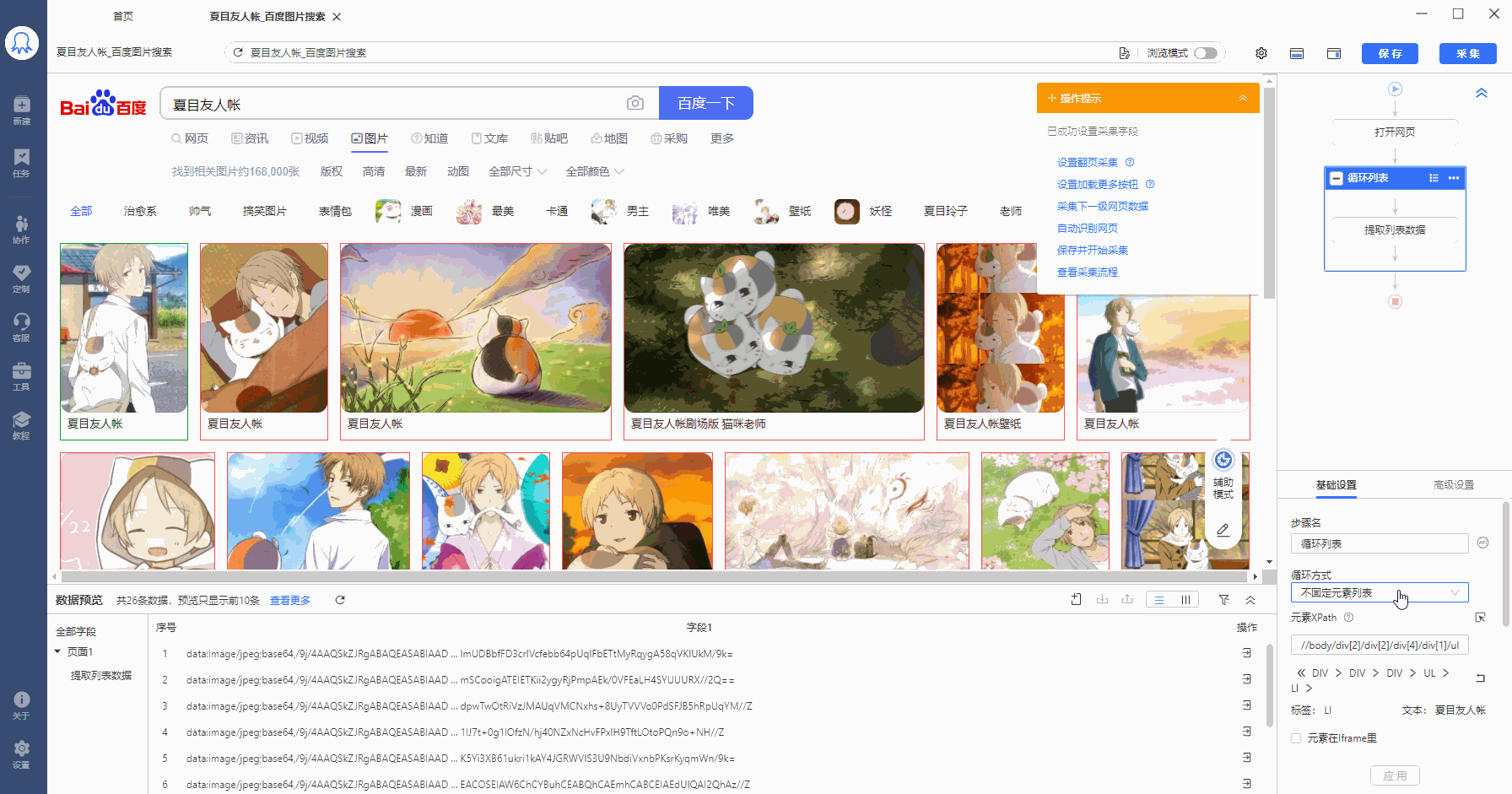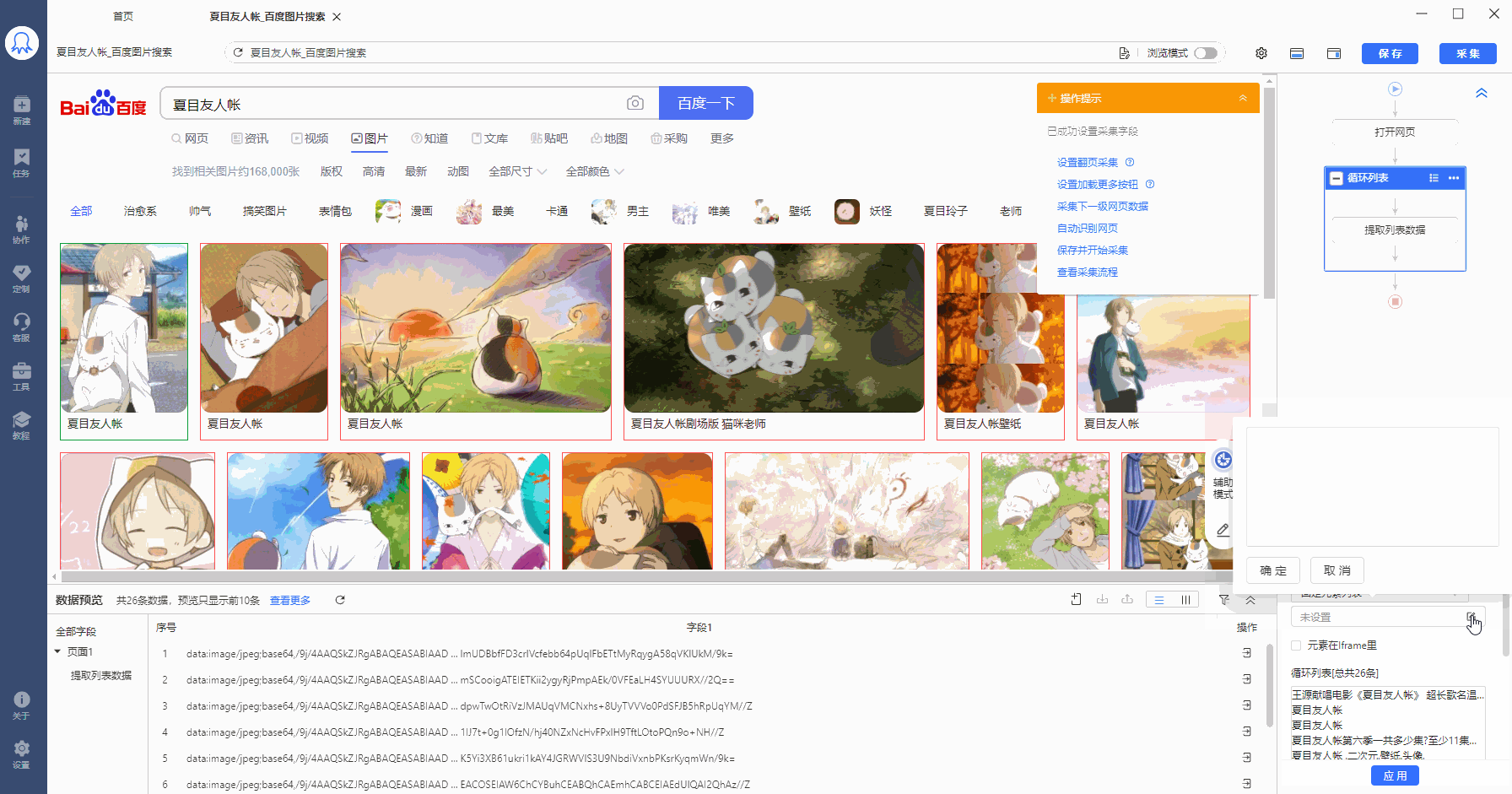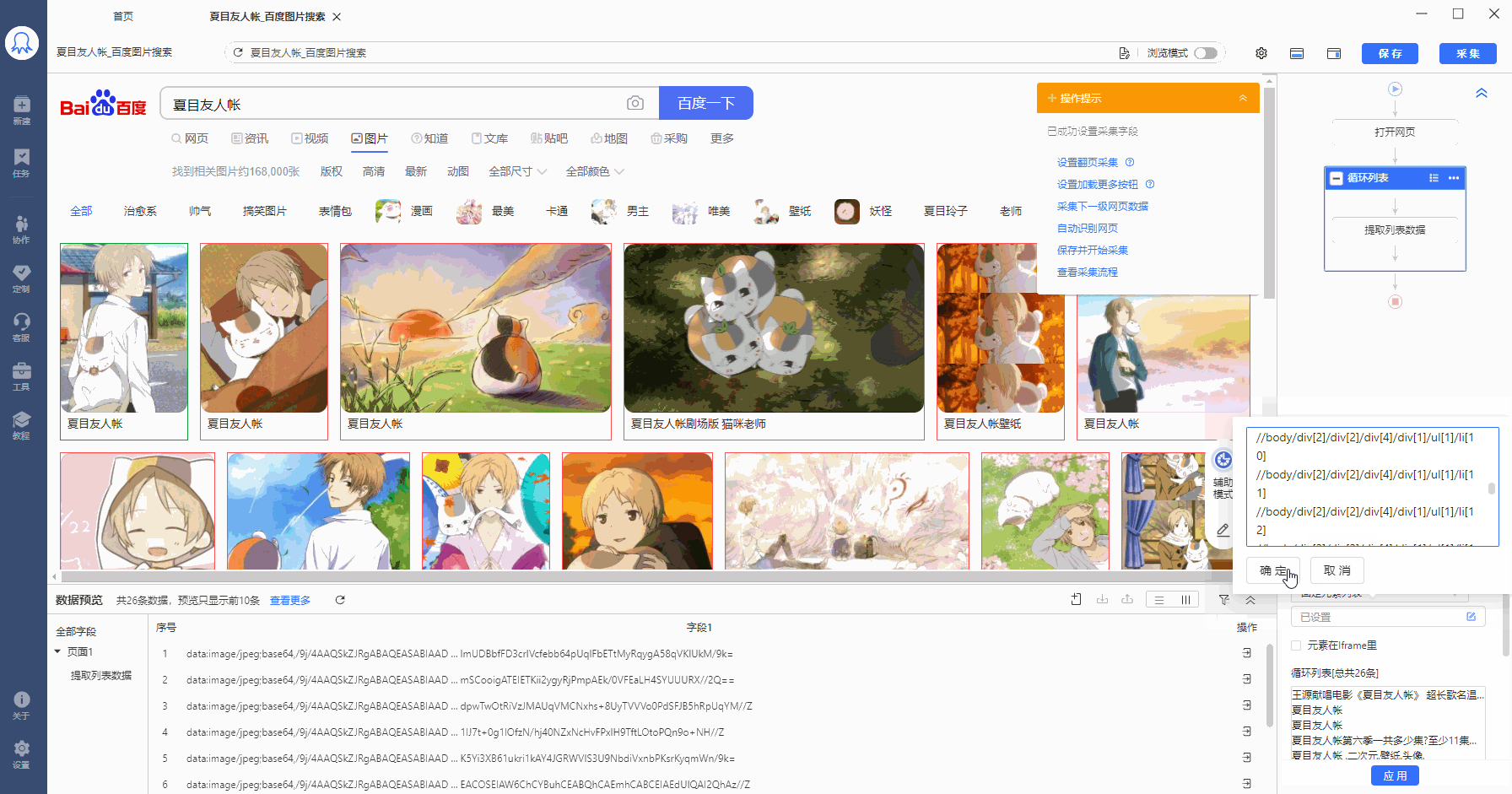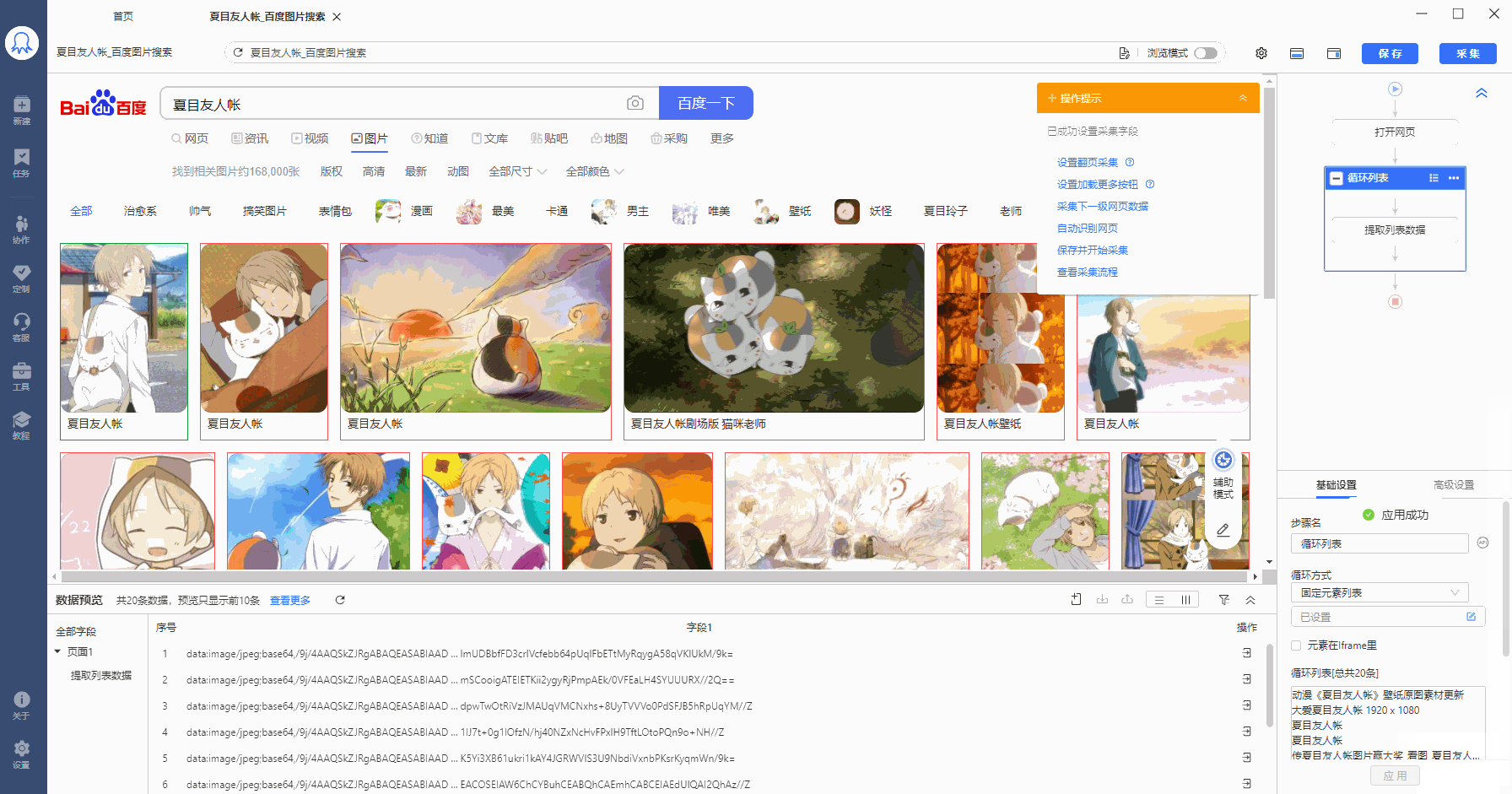
在八爪鱼中做相应修改。选择循环方式为【固定元素列表】,并将以上XPath复制到文本框中,然后点击【应用】保存。可以看到,定位到页面中的全部20个图片列表。
将【固定元素列表】改为【不固定元素列表】
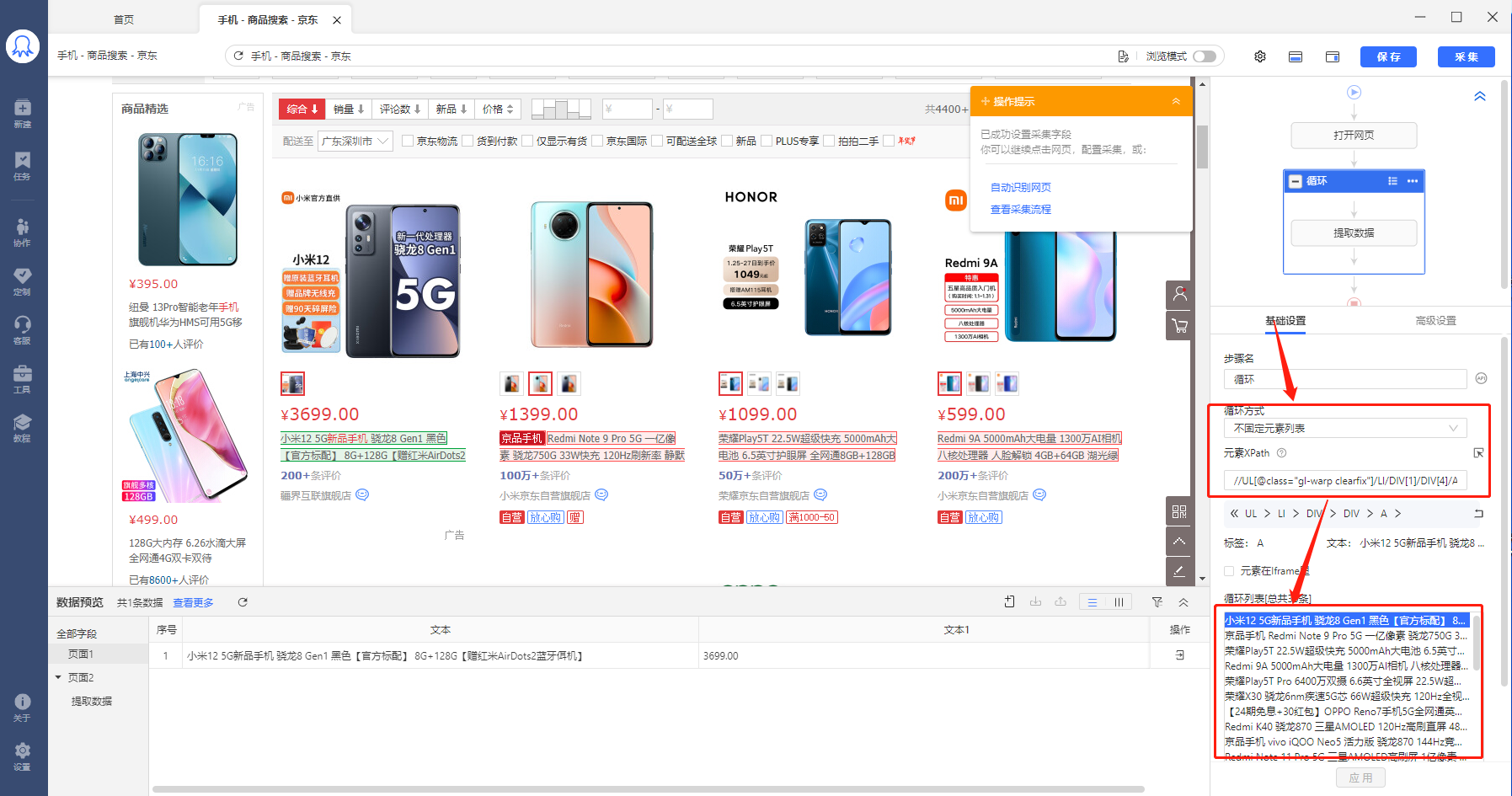
以京东规则为例,https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=dec6e6740f13487bb6c1fa73d88cfa52
观察以上固定元素列表循环中生成的XPath:
//UL[@class="gl-warp clearfix"]/LI[1]/DIV[1]/DIV[4]/A[1]
//UL[@class="gl-warp clearfix"]/LI[2]/DIV[1]/DIV[4]/A[1]
.......
//UL[@class="gl-warp clearfix"]/LI[29]/DIV[1]/DIV[4]/A[1]
//UL[@class="gl-warp clearfix"]/LI[30]/DIV[1]/DIV[4]/A[1]
30条XPath具有相同的特征:只有LI后面的数字不同(不同的数字代表不同的列表,LI[1]是指第1个列表,LI[2]是指第2个列表)。根据这个特征,我们可以写一条通用XPath://UL[@class="gl-warp clearfix"]/LI/DIV[1]/DIV[4]/A[1]。
在八爪鱼中做相应修改。选择循环方式为【不固定元素列表】,并将//UL[@class="gl-warp clearfix"]/LI/DIV[1]/DIV[4]/A[1] 复制到文本框中。可以看到,定位到页面中的全部30个商品链接。

文章评论