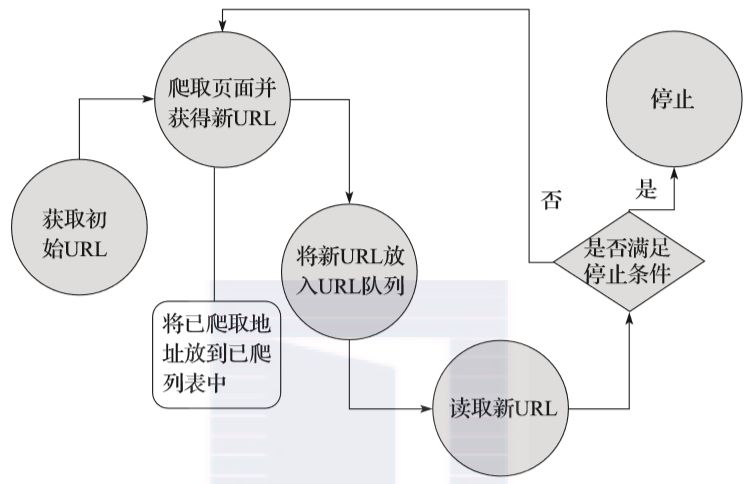
01 网络爬虫实现原理详解 不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。在此,我们将以两种典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。 1. 通用网络爬虫 首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要概括如下(见图3-1)。 ▲图3-1 通用网络爬虫的实现原理及过程 获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。 根据初始的URL爬取页面并获得新的URL。获…

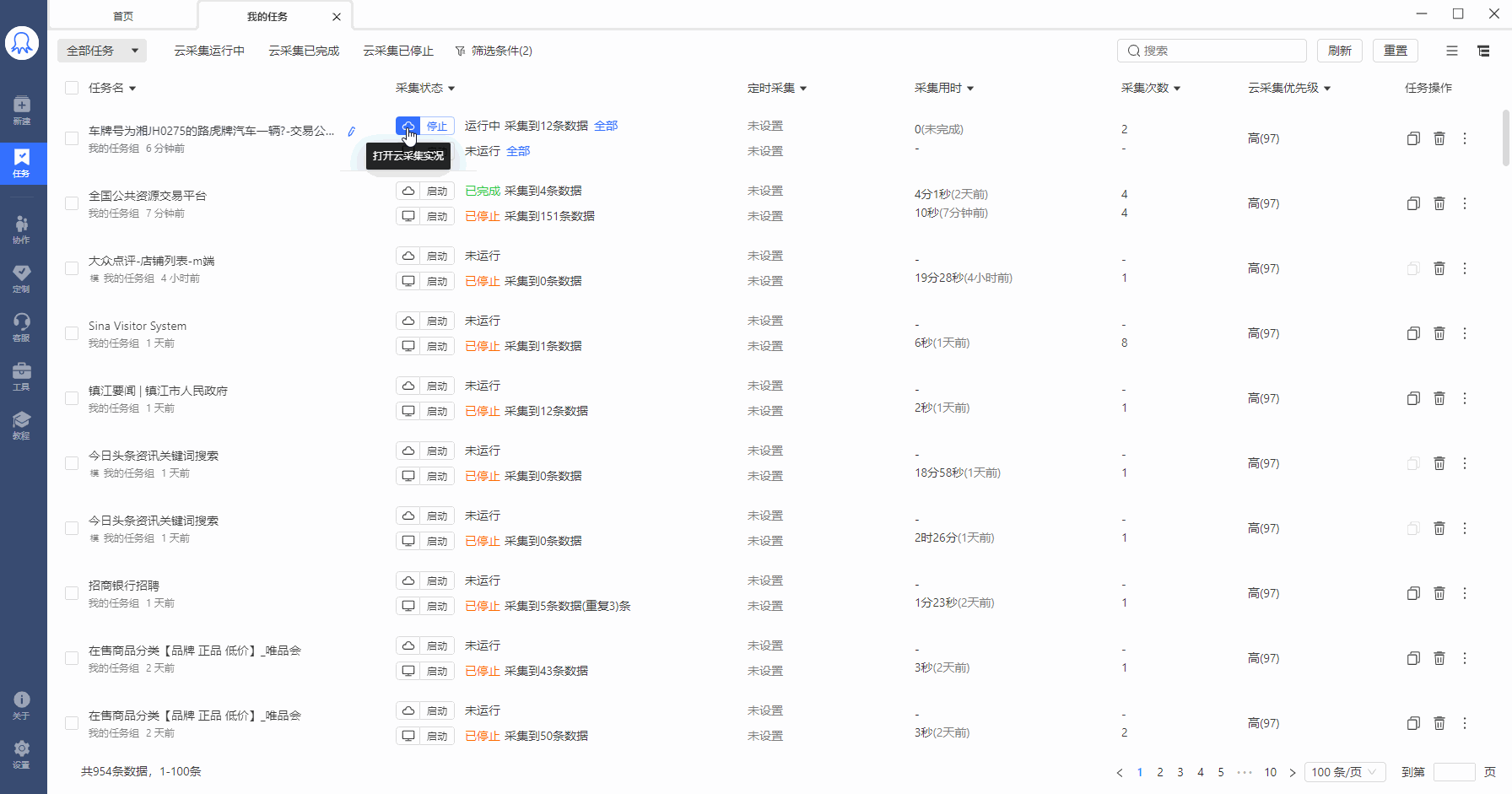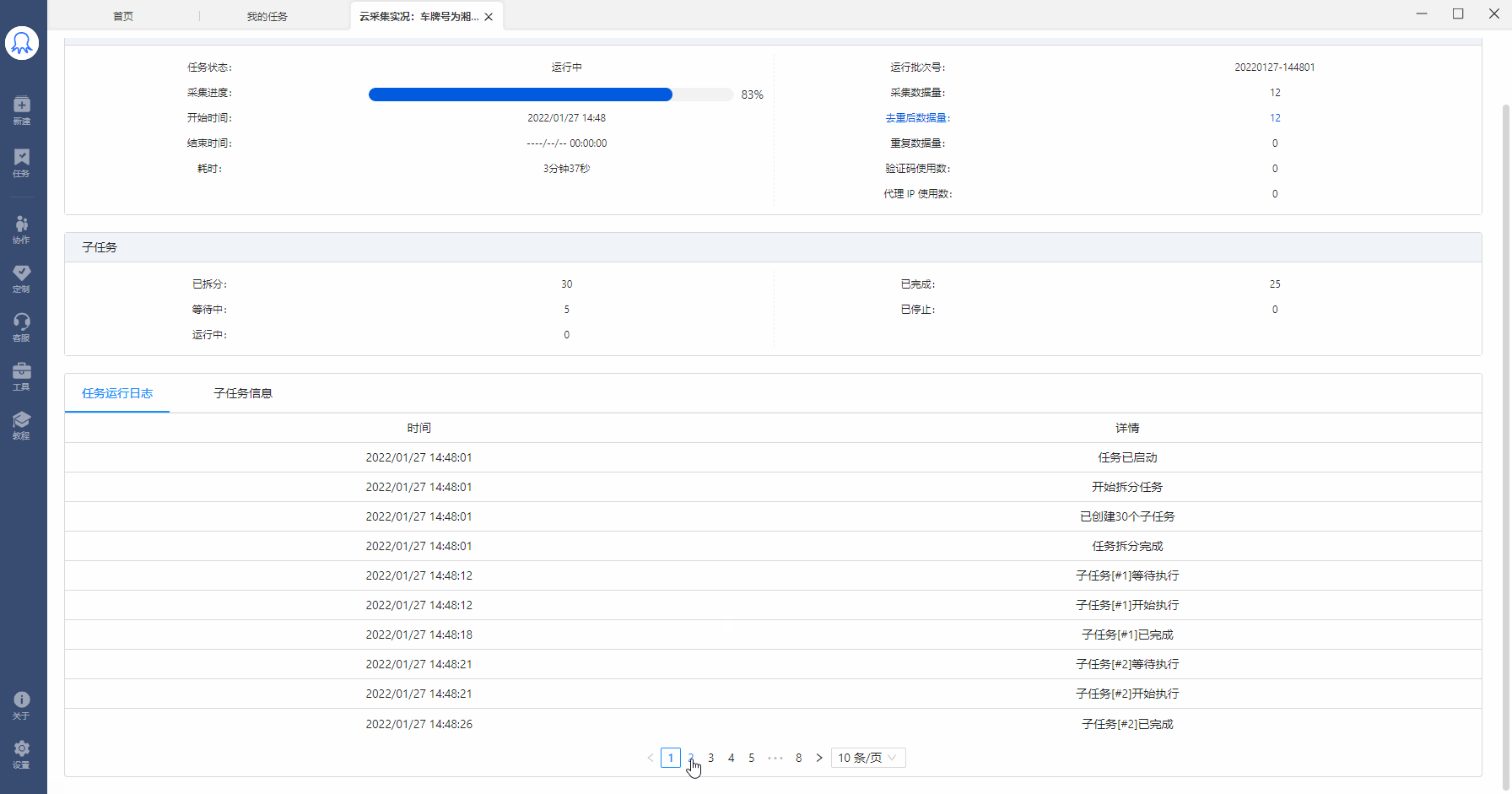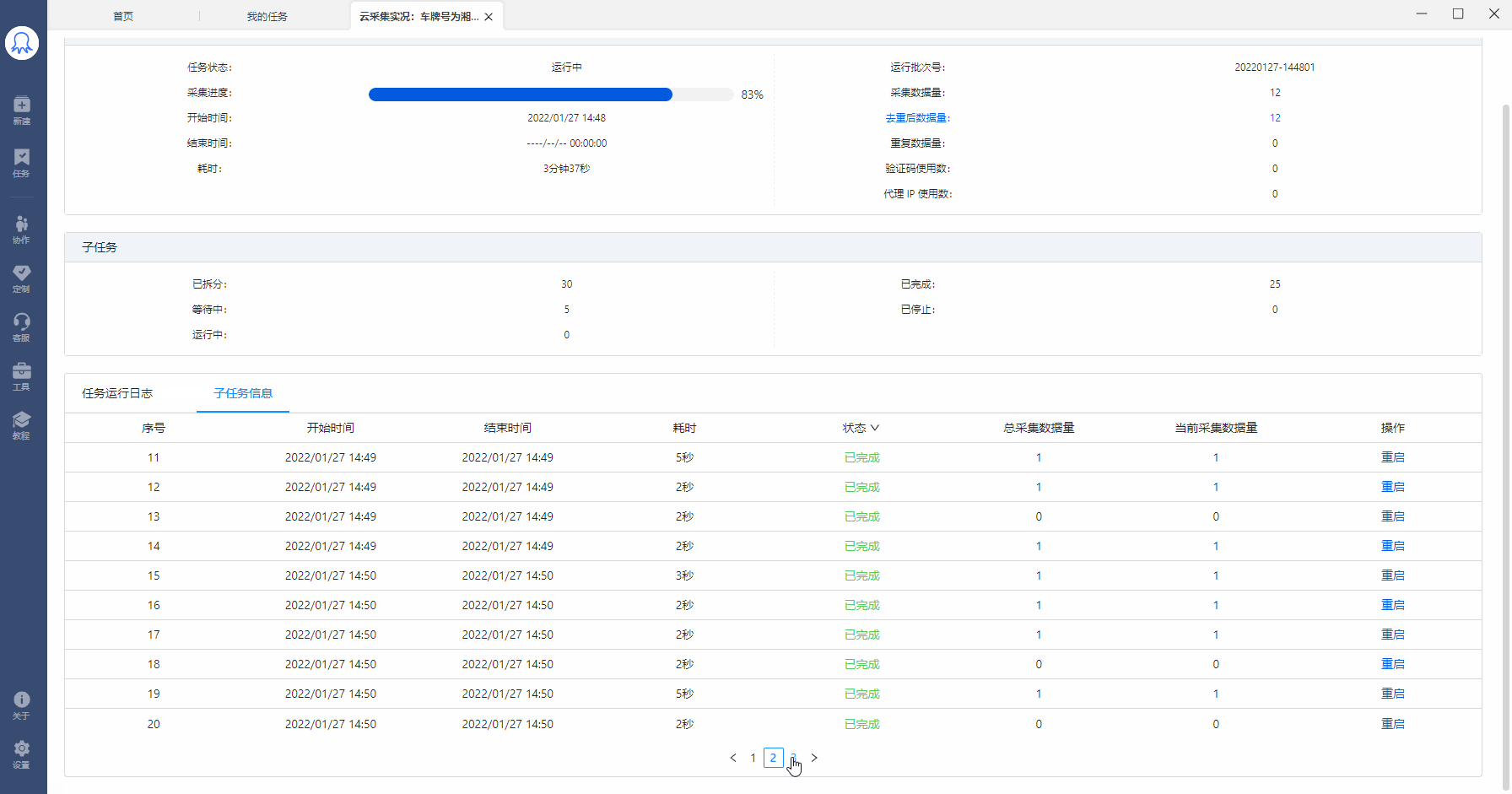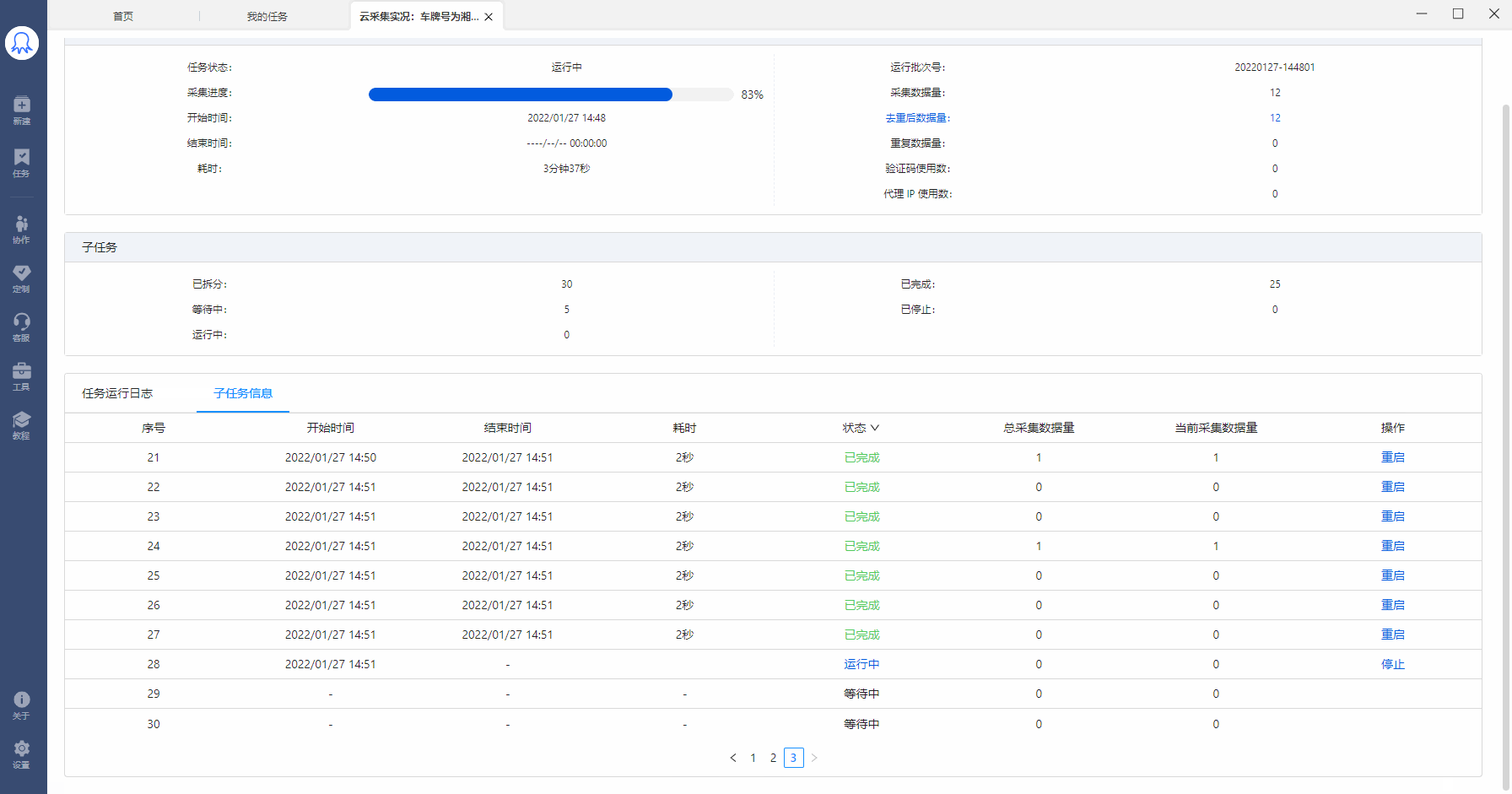
通过八爪鱼云采集,可以实现多个任务并发采集,极大提高采集效率。 云采集原理是什么?什么样的规则可实现云加速?本文将详细讲解。 一、云采集原理 云采集是指,使用由八爪鱼提供的云服务集群进行数据采集。八爪鱼拥有5000+云服务器,7*24小时不间断运行(一台云服务器可看做一个云节点)。 八爪鱼的采集任务运行在云节点上时: a. 在满足可拆分的情况下,1个任务最多拆成100个子任务。(3类任务可拆分,下文将详细讲解) b. 1个任务/子任务需占用一个云节点进行采集。也就是说,1个云节点同时只能运行一个任务/子任务…
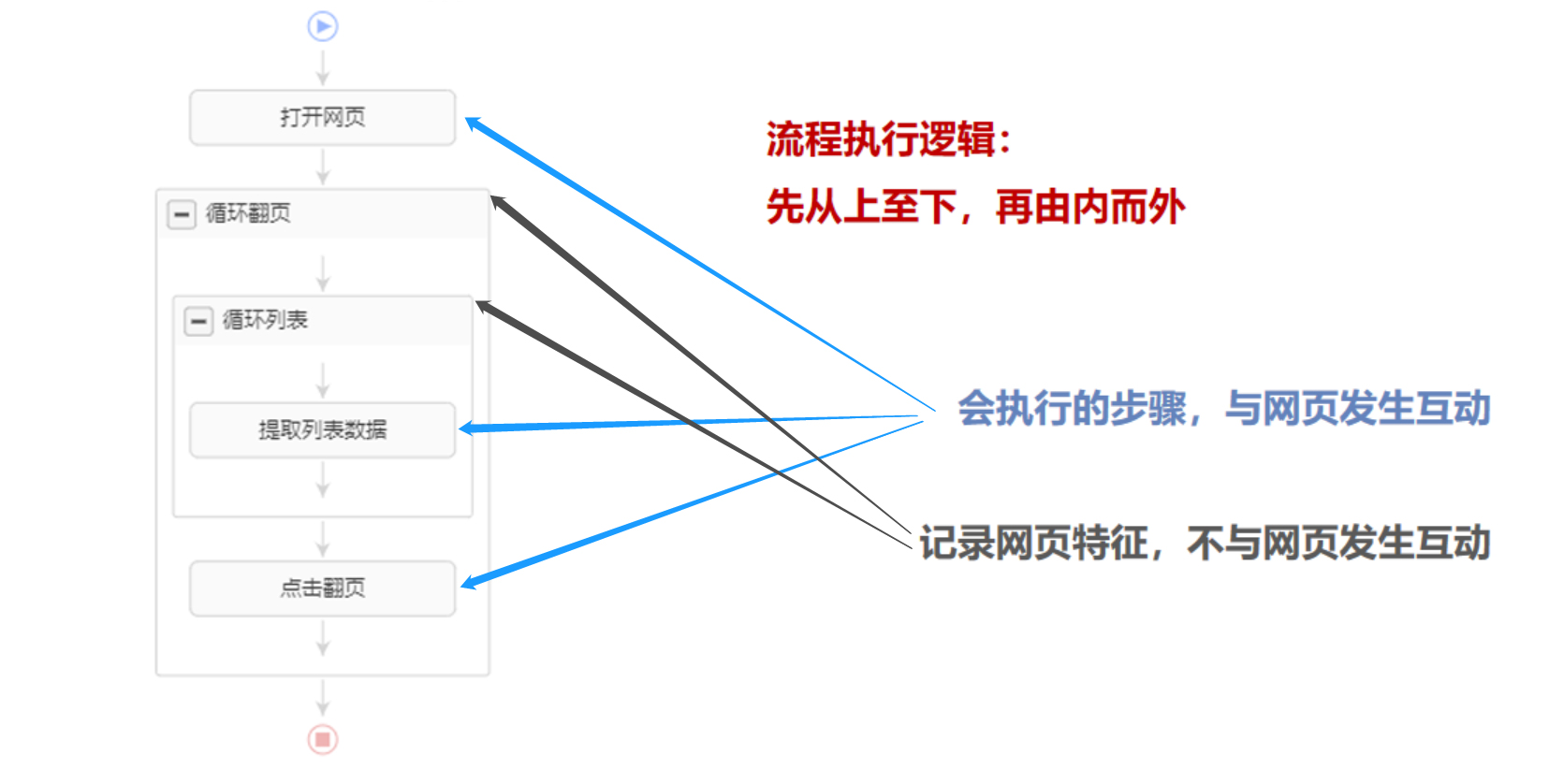
经过前几课的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详情页数据、实现翻页 的任务配置方法。 在此基础上,本课将详解八爪鱼的采集原理和流程执行逻辑,让大家对八爪鱼采集数据的方法有一个更深入的理解。 一、八爪鱼采集原理 1、模拟人的行为,通过内置Chrome浏览器浏览网页数据。 所以采集数据的第一步永远是找到目标网址并输入。这跟通过普通浏览器访问网页完全一样。 在普通浏览器中需要点击链接进入详情、点击翻页按钮查看更多数据,在八爪鱼中也需如此操作。 2、根据网页特性和采集需求,设计采…

区间变化的变化原理为:地址中的两个参数以固定的间隔进行增长,并且相邻两组值的结束值与起始值间隔为1,以这种形式变化增长的地址格式可以使用区间变化来处理。 比如以https://www.powerchina.cn/col/col7440/index.html?uid=46098&pageNum=1,网址为例,我们使用fiddler抓包网址变化如下: 第一页:https://www.powerchina.cn/module/web/jpage/dataproxy.jsp?startrecord=1…
