
经过前几课的学习,我们已经掌握了列表数据、表格数据、点击多个链接后的详情页数据、实现翻页 的任务配置方法。
在此基础上,本课将详解八爪鱼的采集原理和流程执行逻辑,让大家对八爪鱼采集数据的方法有一个更深入的理解。
一、八爪鱼采集原理
1、模拟人的行为,通过内置Chrome浏览器浏览网页数据。
所以采集数据的第一步永远是找到目标网址并输入。这跟通过普通浏览器访问网页完全一样。
在普通浏览器中需要点击链接进入详情、点击翻页按钮查看更多数据,在八爪鱼中也需如此操作。
2、根据网页特性和采集需求,设计采集流程,八爪鱼根据流程全自动采集数据。
平常我们浏览网页的动作不会被记录下来。例如:这次在京东上输入关键词【手机】查询相关商品数据,下次还需要输。
在用八爪鱼采集数据的时候,我们就需要根据网页特性和采集需求,设计采集流程,将我们的采集需求记录下来。之后八爪鱼就能根据设计好的采集流程,全自动的采集数据。
例如:在前几课中学到的,需采集页面上的所有商品列表,我们就做一个【循环-提取数据】的步骤。采集时有很多页,需要翻页,我们就做一个【循环翻页】的步骤。
二、【采集流程】执行逻辑
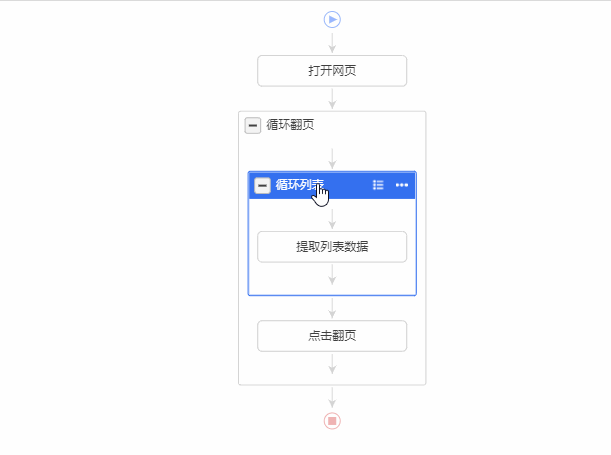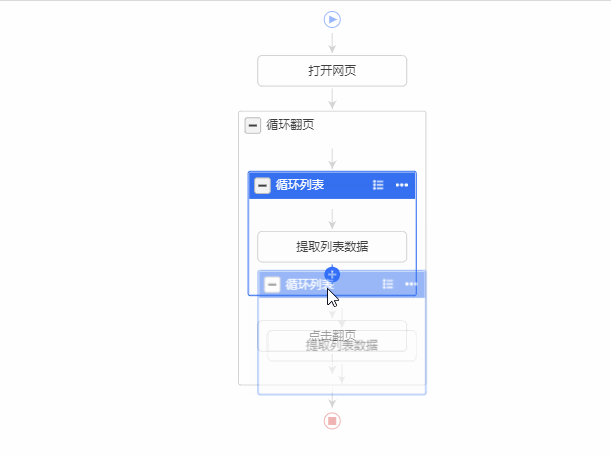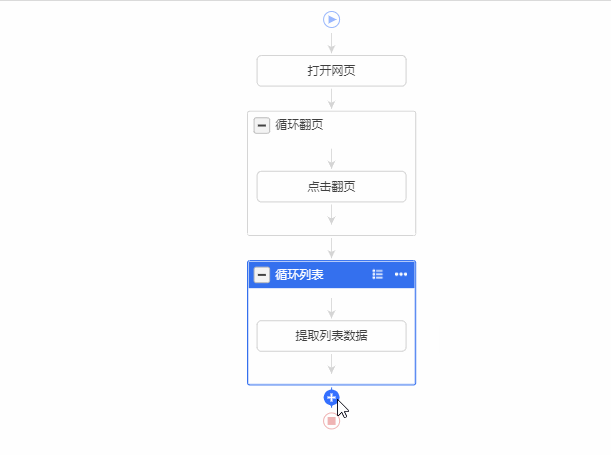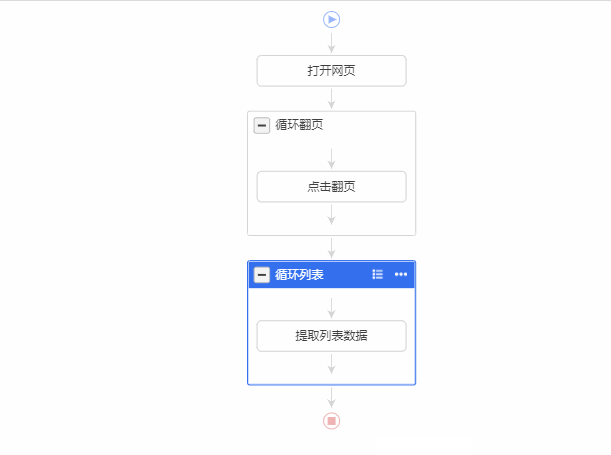
八爪鱼通过【采集流程】全自动采集数据。【采集流程】执行逻辑遵循2个原则:先从上至下、再由内而外。
【采集流程】由【蓝色步骤】和【灰色框】两大部分组成。【蓝色步骤】是会执行的步骤,八爪鱼与网页发生互动。【灰色框】起记录网页的作用。
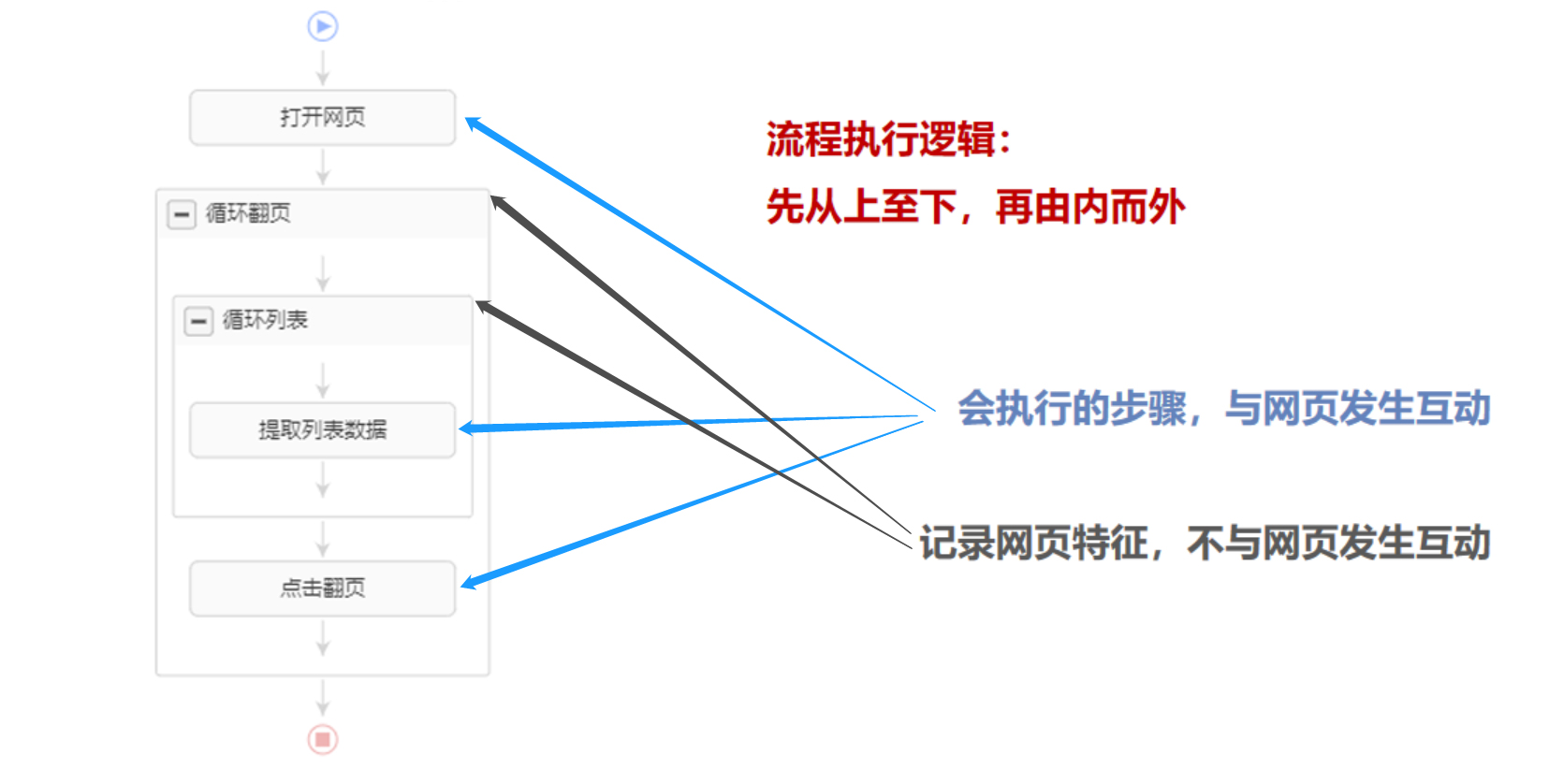
鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
来看几个实例,更深入理解【采集流程】执行逻辑。
实例1:

实例2:

实例3:

特别说明:
a. 【采集流程】无固定标准,符合网页本身的跳转逻辑即可。
b. 【采集流程】中可设置多个点击步骤、多个嵌套循环,以实现网页多层级的数据采集。
c. 【采集流程】中的步骤,可以拖动调整位置。鼠标选中步骤并拖住移动至想要的 ![]() 位置。
位置。
看到这里的小伙伴,恭喜您已经完成了【自定义配置采集数据】全部的入门课程。现在,您已经掌握基础的数据采集技能啦!
如果您有任何的问题与建议,请通过官网右侧QQ、电话、客服系统等多种渠道联系我们!
作者:Echo
编辑:Echo

文章评论