经常有用户来问我们,你们后羿采集器是不是免费的啊? 我们说那是必须的啊! 你看我们连导出数据都不限制,这是下了多大的决心啊!~~~ 然后用户就会扔给我们一张度娘的搜索结果截图, “这年头,还有哪家采集器说自己不免费啊?老实说吧,下载图片、导出数据这些需要多少积分?积分多少钱?我懂的!” 面对这种结果,我们也是很无奈的。 目前市面上几乎所有的数据采集软件都宣称自己是免费的,但是往往都会对基本功能进行限制,比如必须使用积分才能进行数据导出;或是限制授权电脑数量;或是不能下载图片;或着是对导出数据的格式进行严格的限制,免…

智能模式是后羿采集器团队基于人工智能技术研发的新一代采集模式,操作极其简单,只需要输入被采集的网址就能智能识别出网页中的内容和分页按钮,无需配置采集规则就能够完成数据的采集。 本文以后羿采集器官网问答社区为例,为大家演示智能模式的使用方法,更多详细的介绍请大家参考智能模式的系列课程。
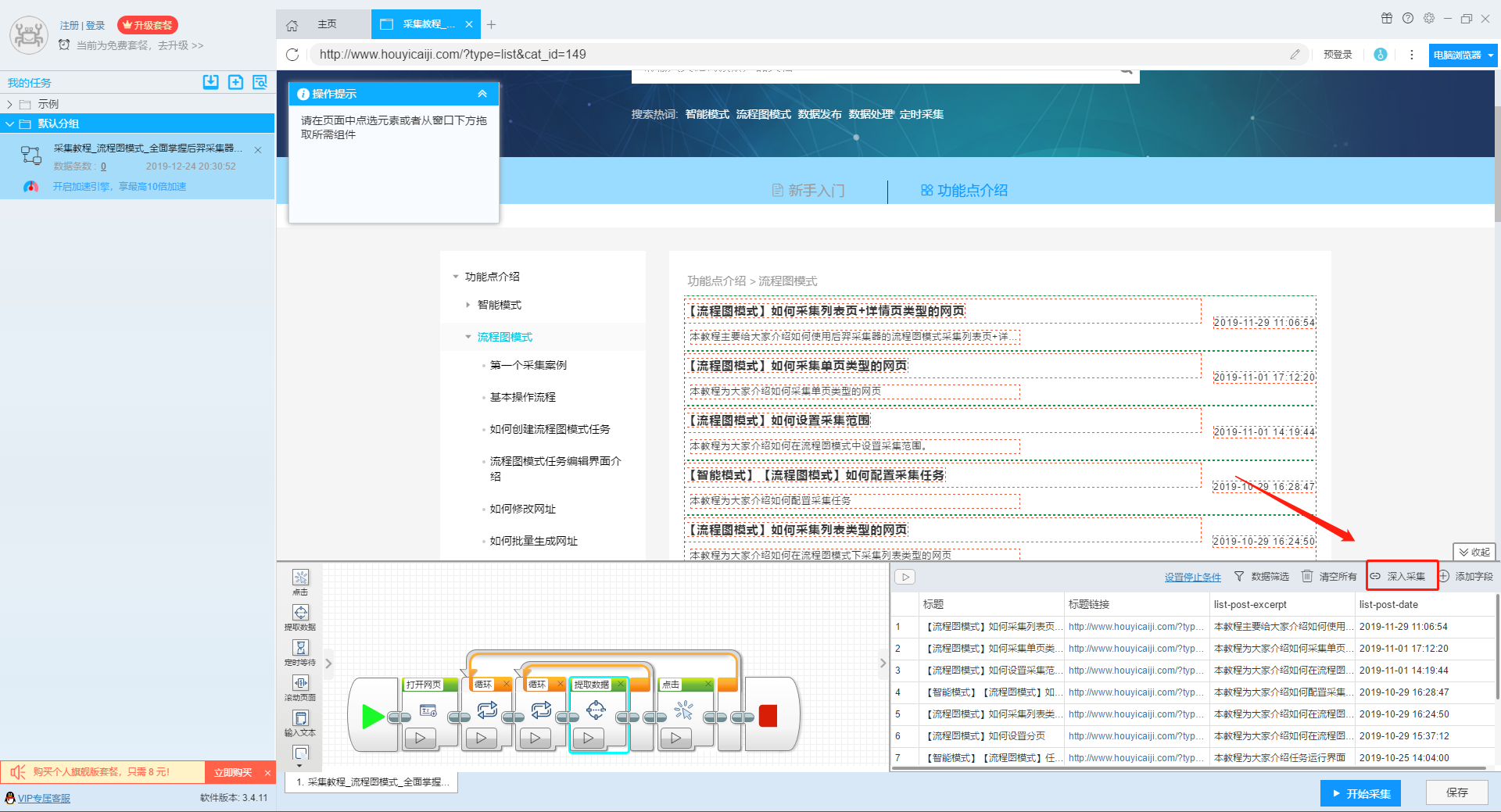
流程图模式中支持两种深入采集的方式,第一种和智能模式相同,点击深入采集按钮或者链接进行深入采集;第二种是通过点击页面元素,然后根据软件提示进行深入采集。 其中第二种方式是对第一种方式的补充,主要针对一些第一种方式不支持的场景,包括: (1)列表页中没有详情页的链接,并且点击列表页中的详情页的标题之后,打开的详情页与列表页网址相同 (2)列表页中没有详情页的链接,并且点击列表页的详情页标题之后会在原网页中弹出新的窗口,详情页内容在窗口中,弹窗需要手动关闭后才能查看下一个详情页内容 下面我们分别介绍一下两种深入采集的设…
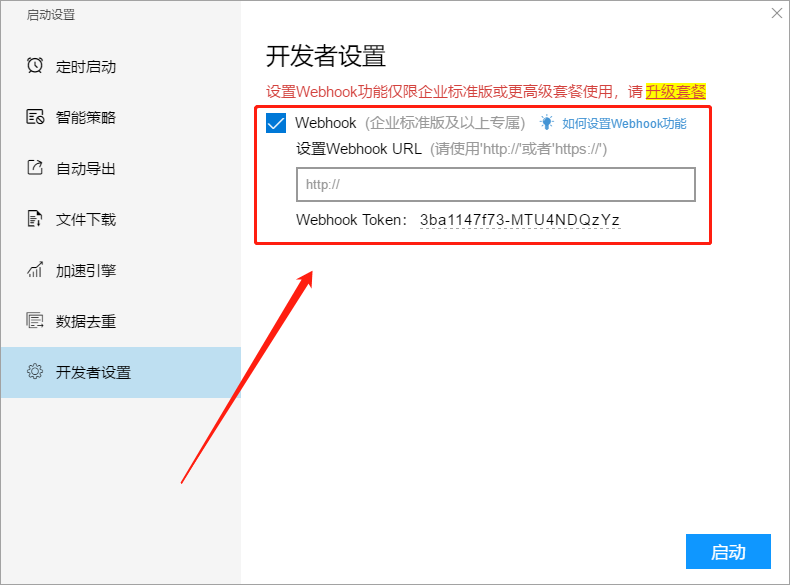
后羿采集器支持Webhook功能,通过使用该功能,后羿采集器可以将采集到的数据实时发布到用户的HTTP地址,用户需要自行开发Webhook接收端代码。 Webhook的设置在启动任务的设置中,具体如下图所示: 开启Webhook功能之后,采集到的数据将以JSON格式进行发送。在任务采集结束时会发送一个采集结束的事件通知。 Webhook以HTTP POST的方式发送数据到用户的HTTP地址。 HTTP Header为"Content-Type: application/json; charset=utf-8"。 用…
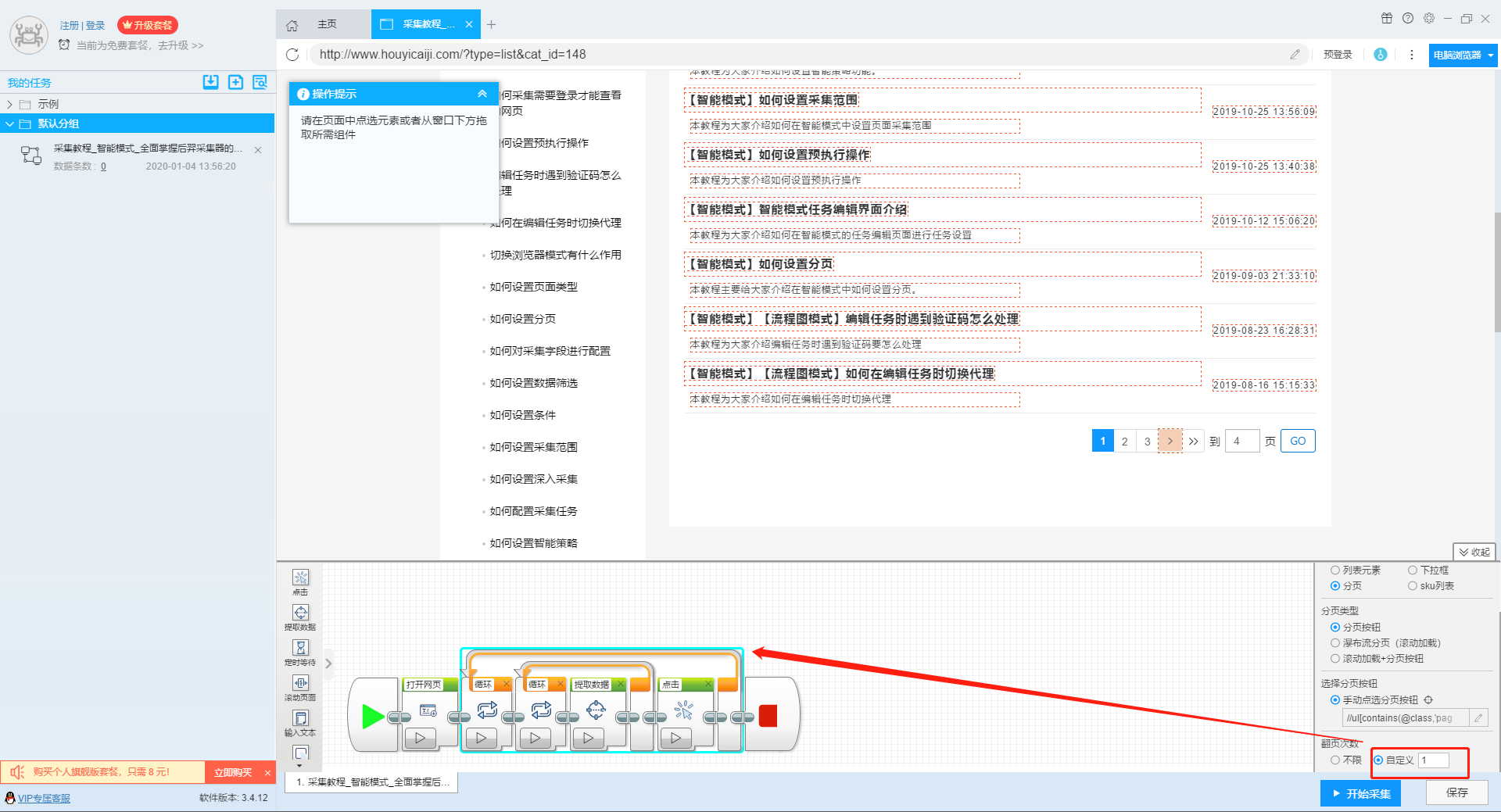
不同于智能模式可以直接设置采集范围,流程图模式采集范围的设置比较复杂一些。 1、只设置结束页面,不设置开始页面的采集范围设置 这种设置比较简单,不管是有分页按钮的网页、瀑布流加载的网页还是瀑布流+分页加载的网页,都只需要选中翻页循环设置,然后在翻页次数那里设置自定义次数,用户想要在哪个页数停止,就选择填相应的页数。 1)分页按钮 2)瀑布流分页 3)瀑布流+分页按钮 2、设置开始采集页面,不设置结束页面的采集范围设置 1)网址会随着页码的变动而变动的网站 用户可以直接复制新的开始采集的网址,在页面上修改网址。 2)…
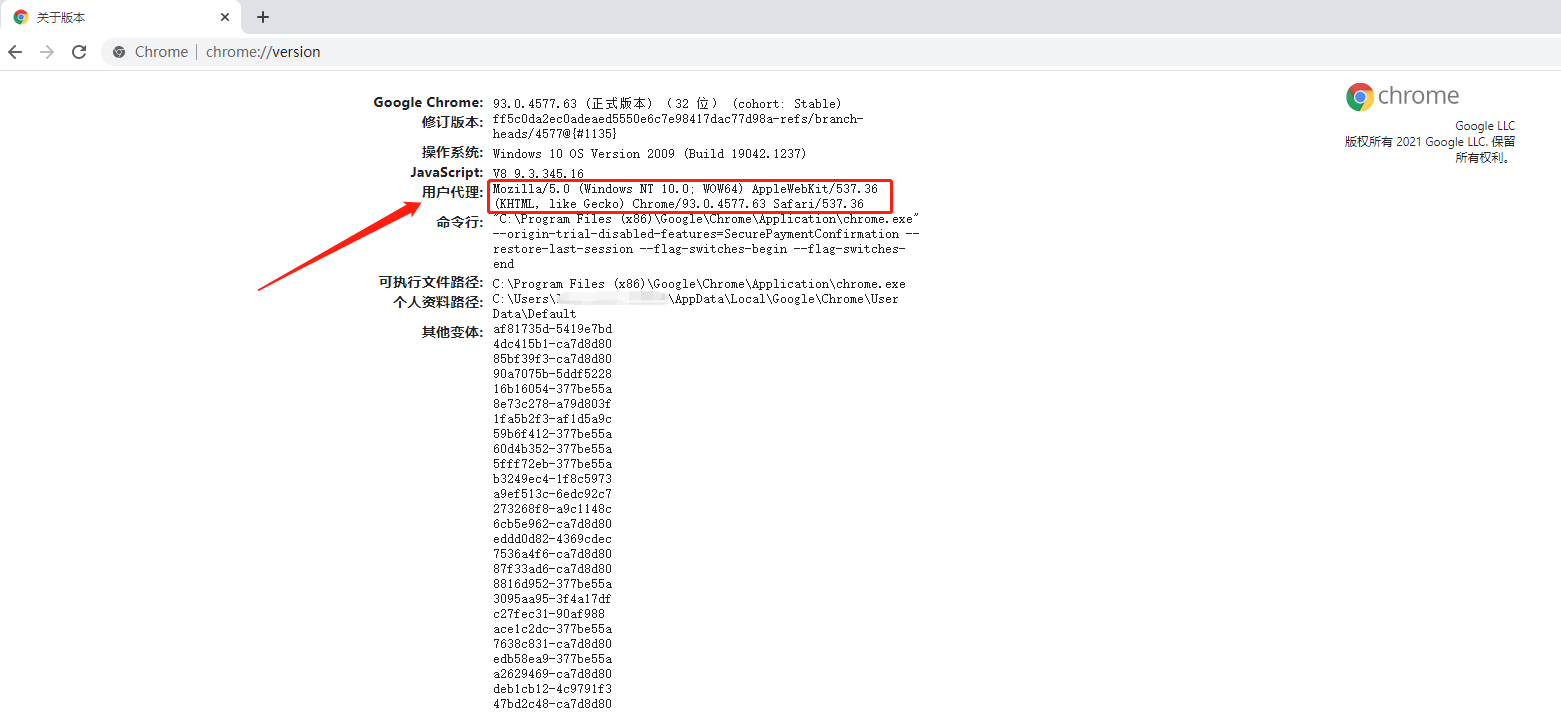
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。 由于网站会对UA进行过滤,有些老旧的UA会打不开该网页。此时就可以通过切换不同的UA来打开网页。以下教程讲解如何获取浏览器中的UA,以及将获得的UA保存在八爪鱼中。 方法一:以Chrome(谷歌)浏览器为例,在地址栏输入about:version,即可出现如下信息。图中的【用户代理】即【User-A…

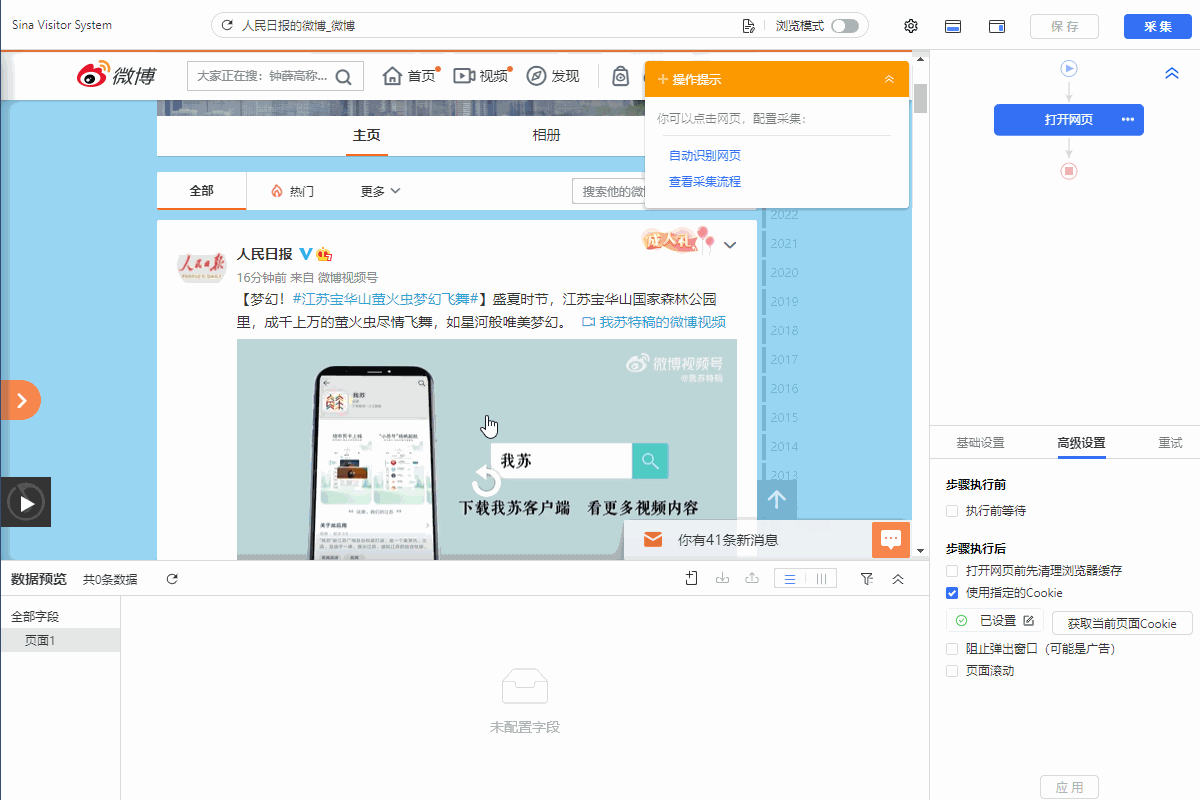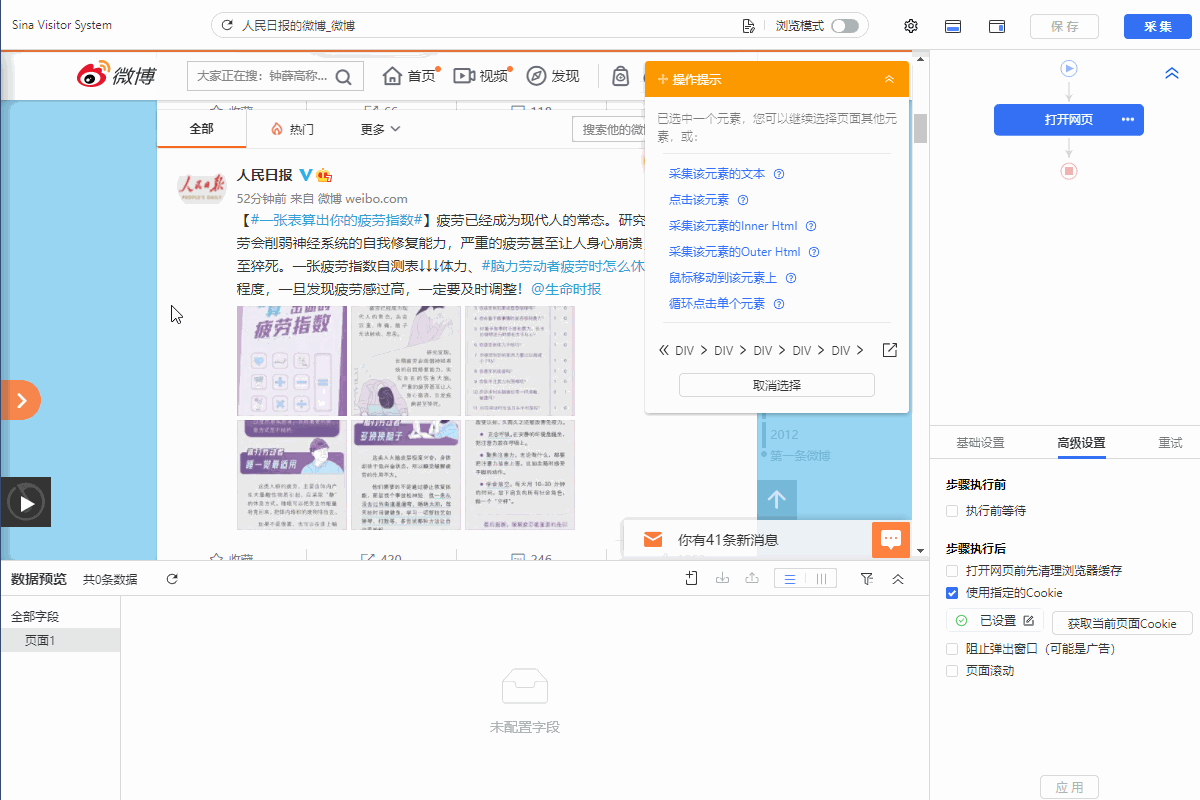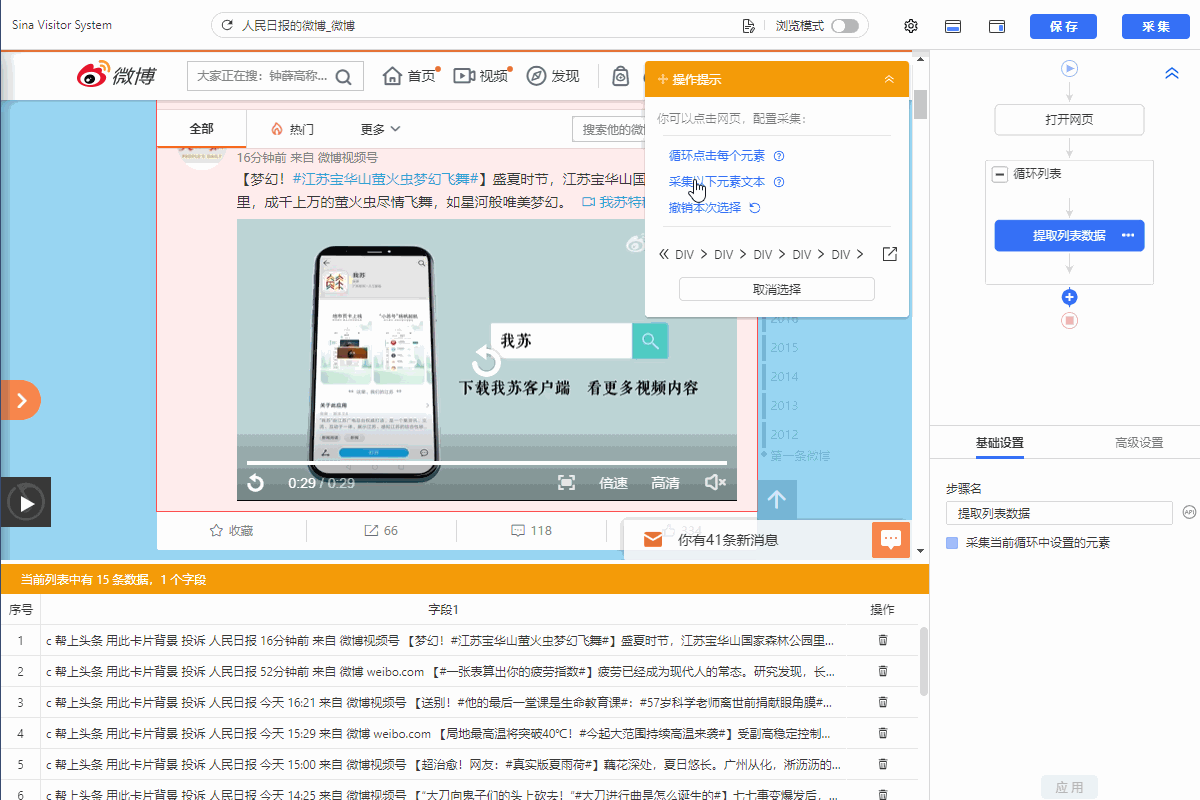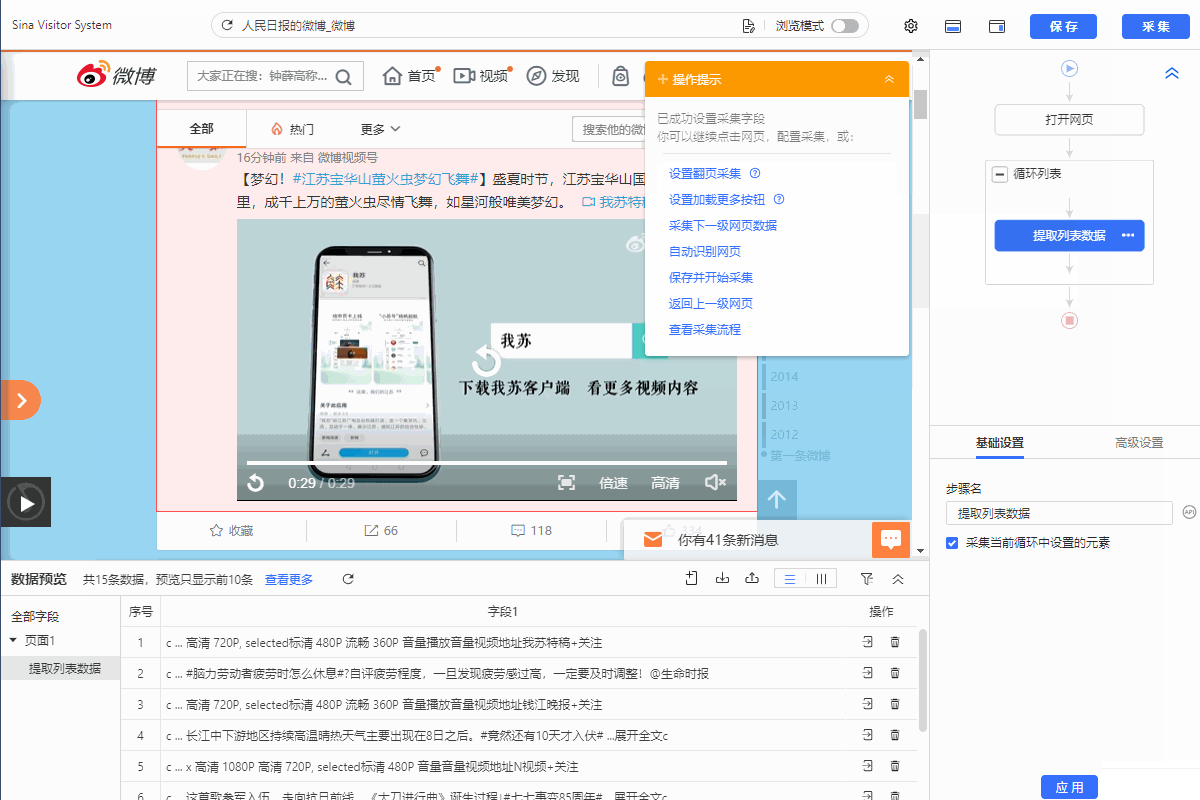
我们通过创建【循环列表】去采集多个列表或详情页的数据。创建【循环列表】的方式在 新手入门系列课程 中有详细讲过。 一般情况下,通过以上方法创建的【循环列表】不会出错,能够精准采集到全部数据。但有时候也会遇到一些问题:比如列表中有的部分不是我们想要的,需要进行丢弃。 这时候,可以手动修改XPath去定位列表丢弃不需要的部分。也可以用分支判断丢弃。 以下通过实例进行说明。 实例网址:https://weibo.com/2803301701?refer_flag=1001030103_ 一…