
在数据采集的时候,经常会需要采集详情页链接。本文通过三种方式来讲解如何利用我们后羿采集器的智能模式采集到详情页的链接,流程图模式同理。
方法一:通过自动识别获取
后羿采集器的智能模式会自动识别列表,一般网站在识别到列表的同时,就会将详情页的链接一并识别出来。
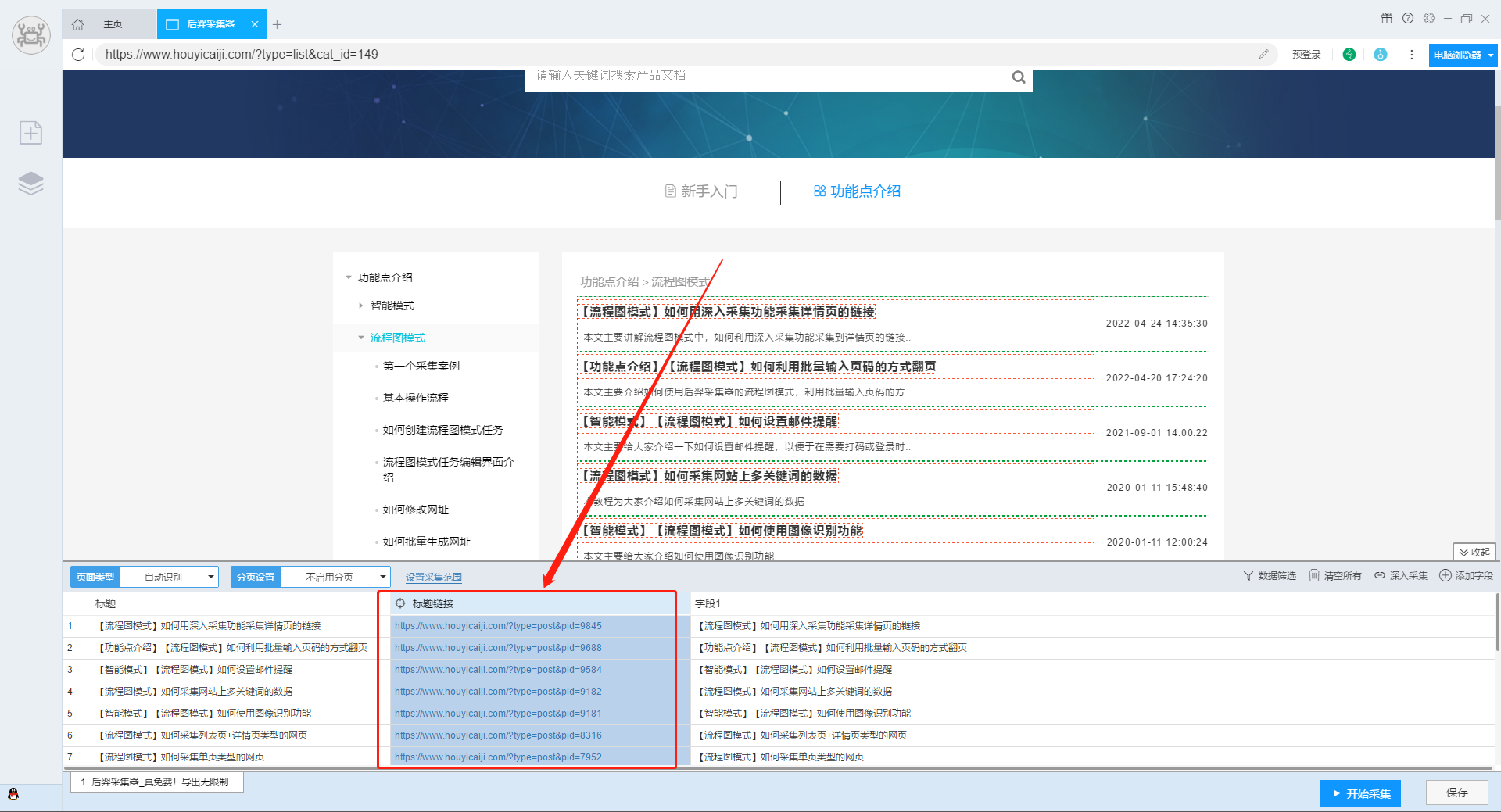
【温馨提示】如果自动识别不准确,也可以用手动点选的方式进行列表识别。
点此深入了解如何识别列表
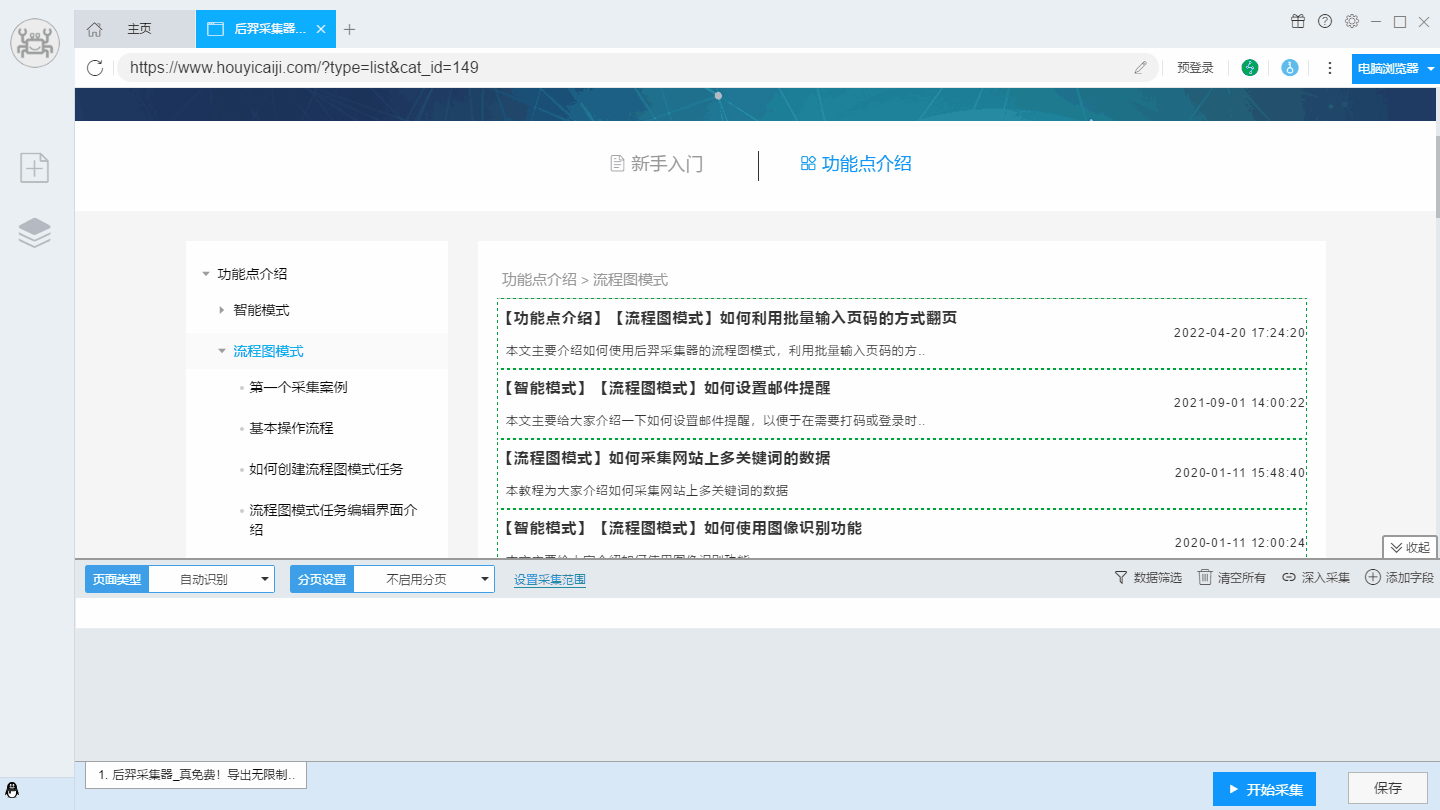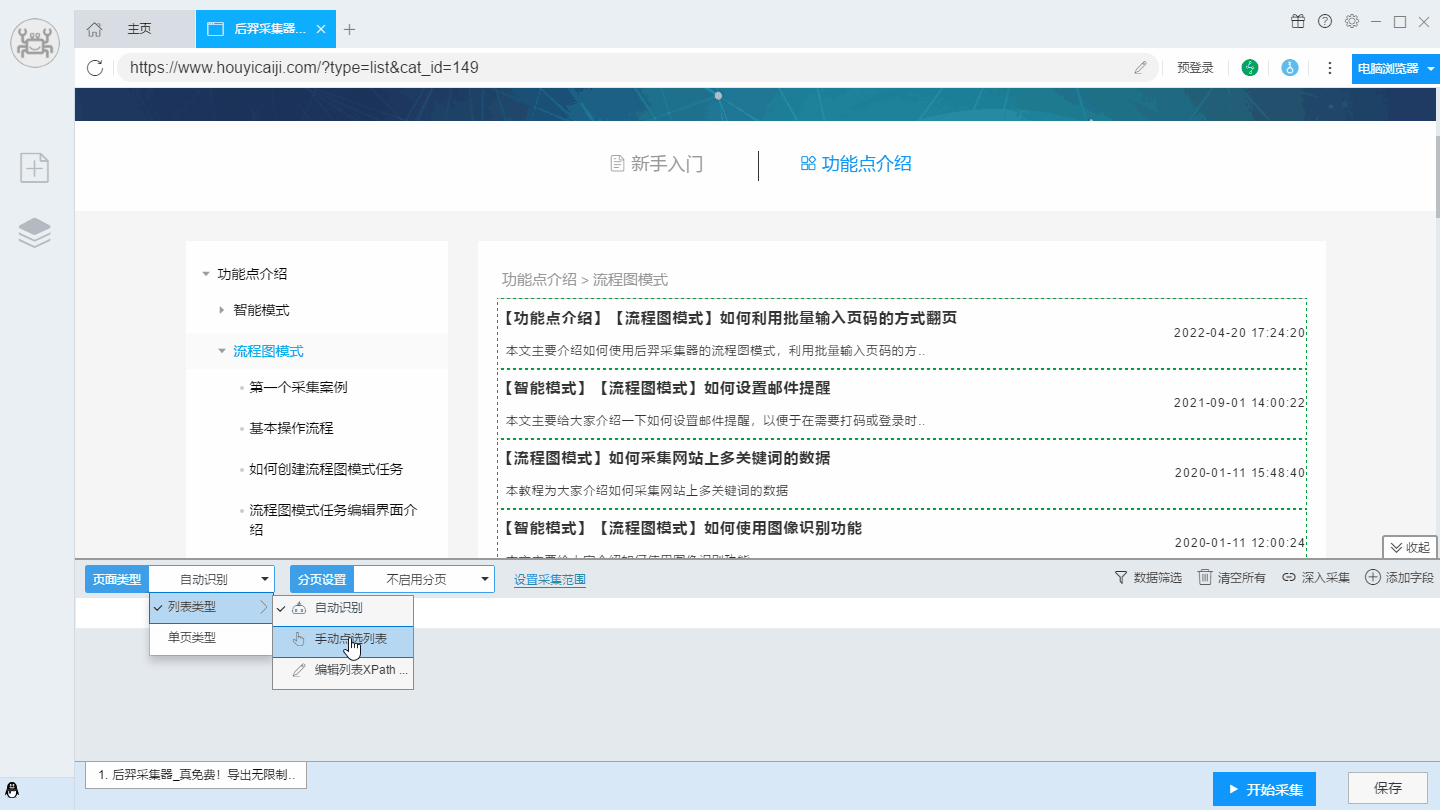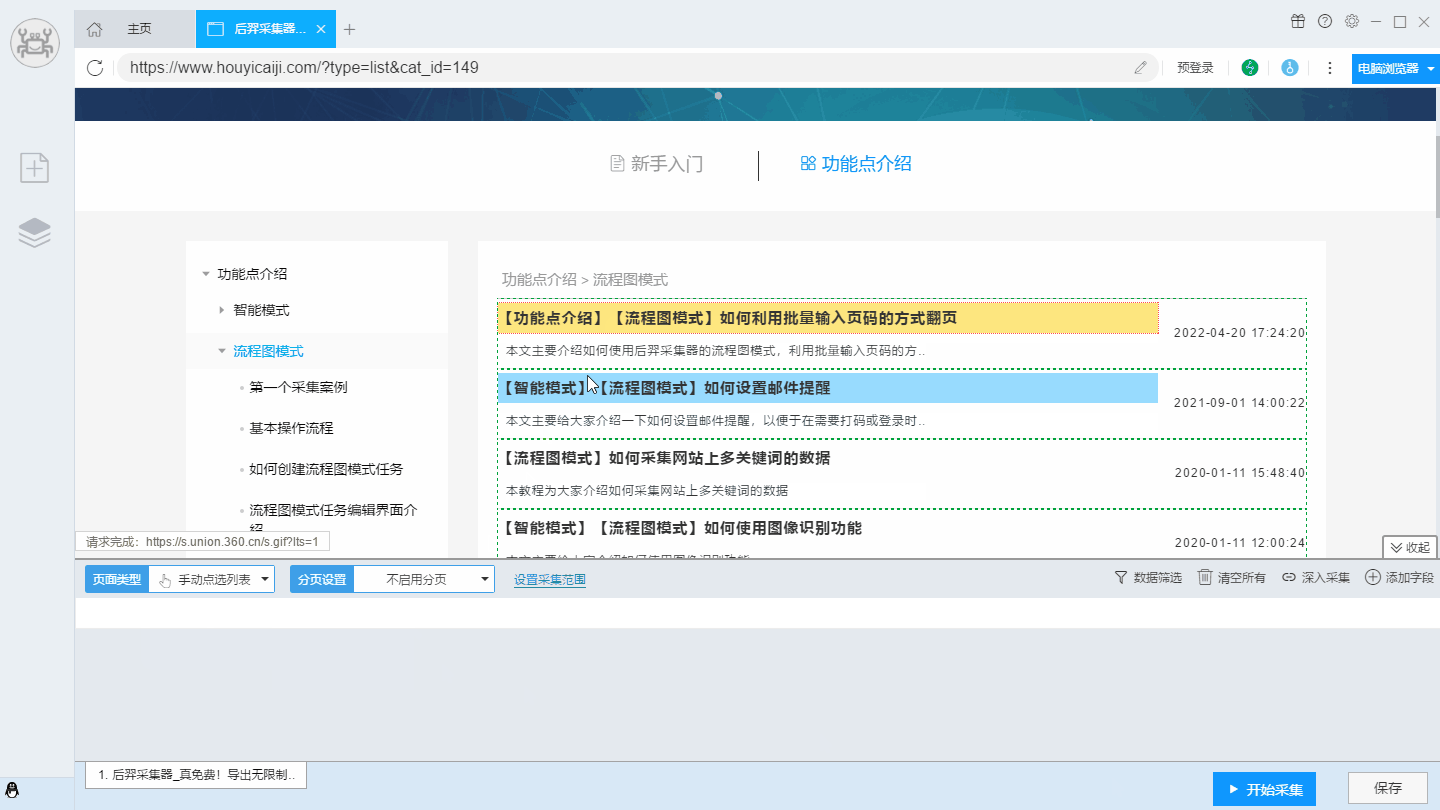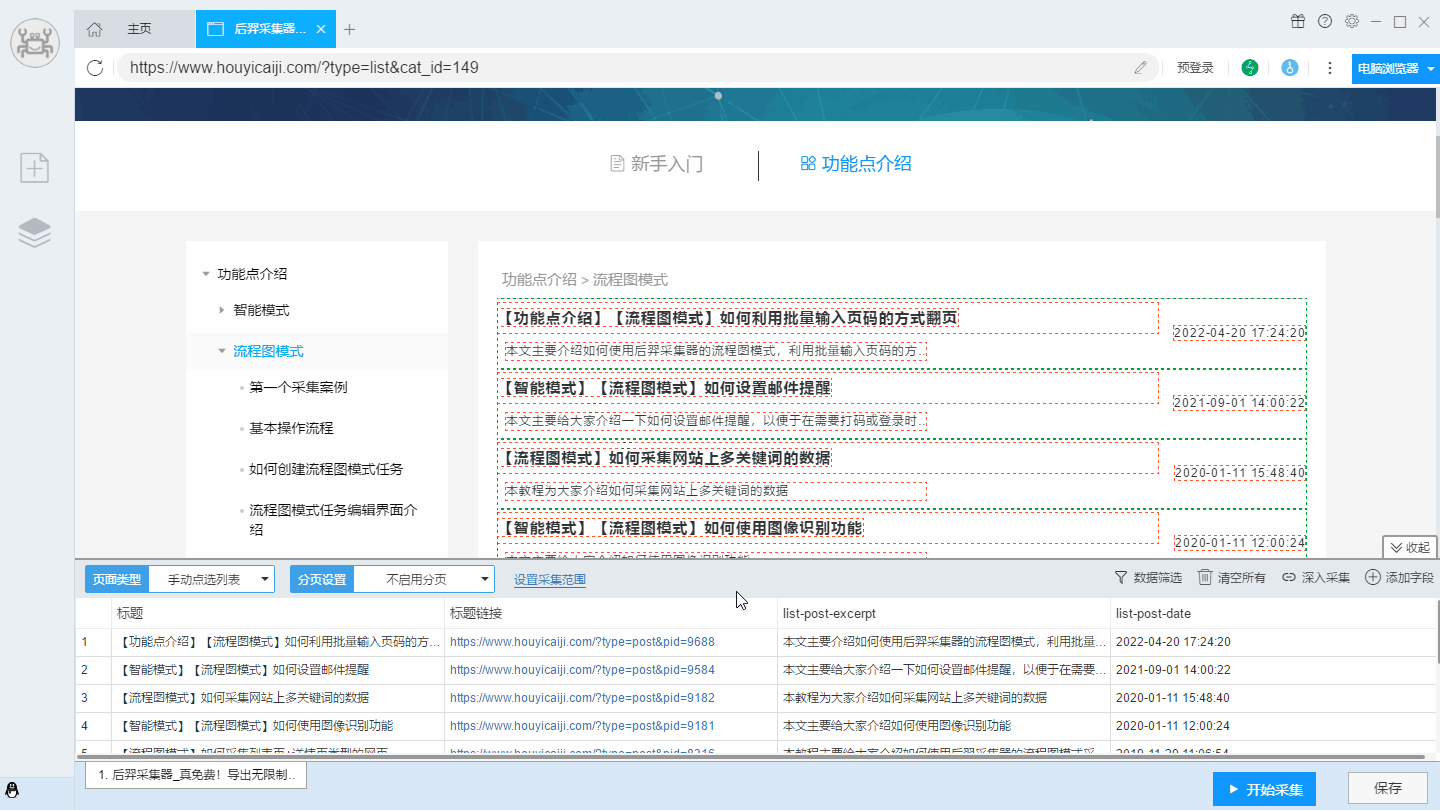
方法二:通过深入采集获取
在软件的列表识别过程中,有时候会遇到无法识别到详情页链接的情况。这时候我们就能用深入采集功能进入详情页,采集详情页的链接。
1.在识别到列表后,我们用添加字段功能,识别到带详情页链接的数据。软件会自动生成字段。
【温馨提示】带链接的数据一般是文章的标题,或者商品名等,如果无法确认可以在浏览器上操作确认一下。
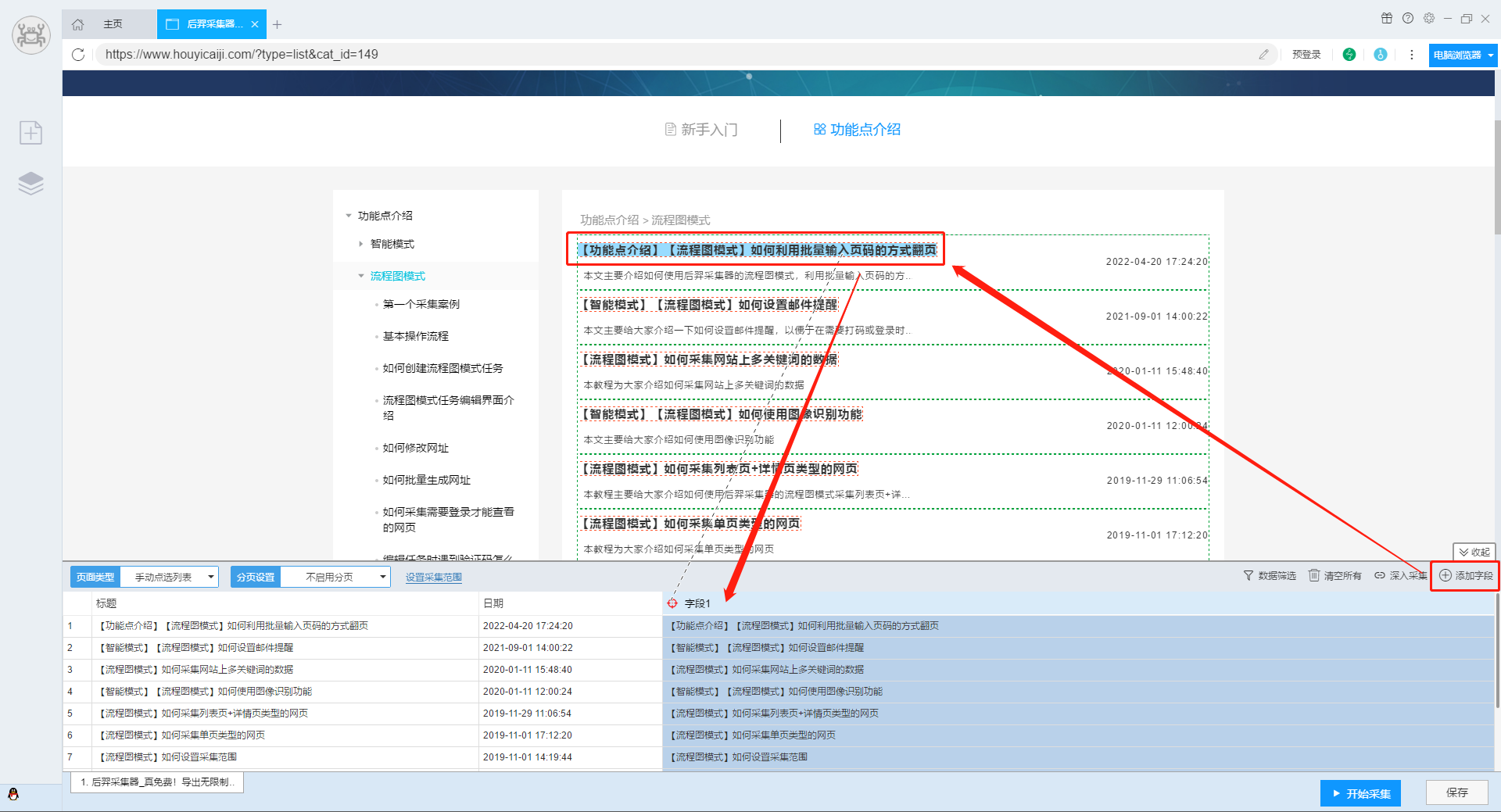
2.右键生成的字段,设置“取值属性”,选择“提取链接地址”。
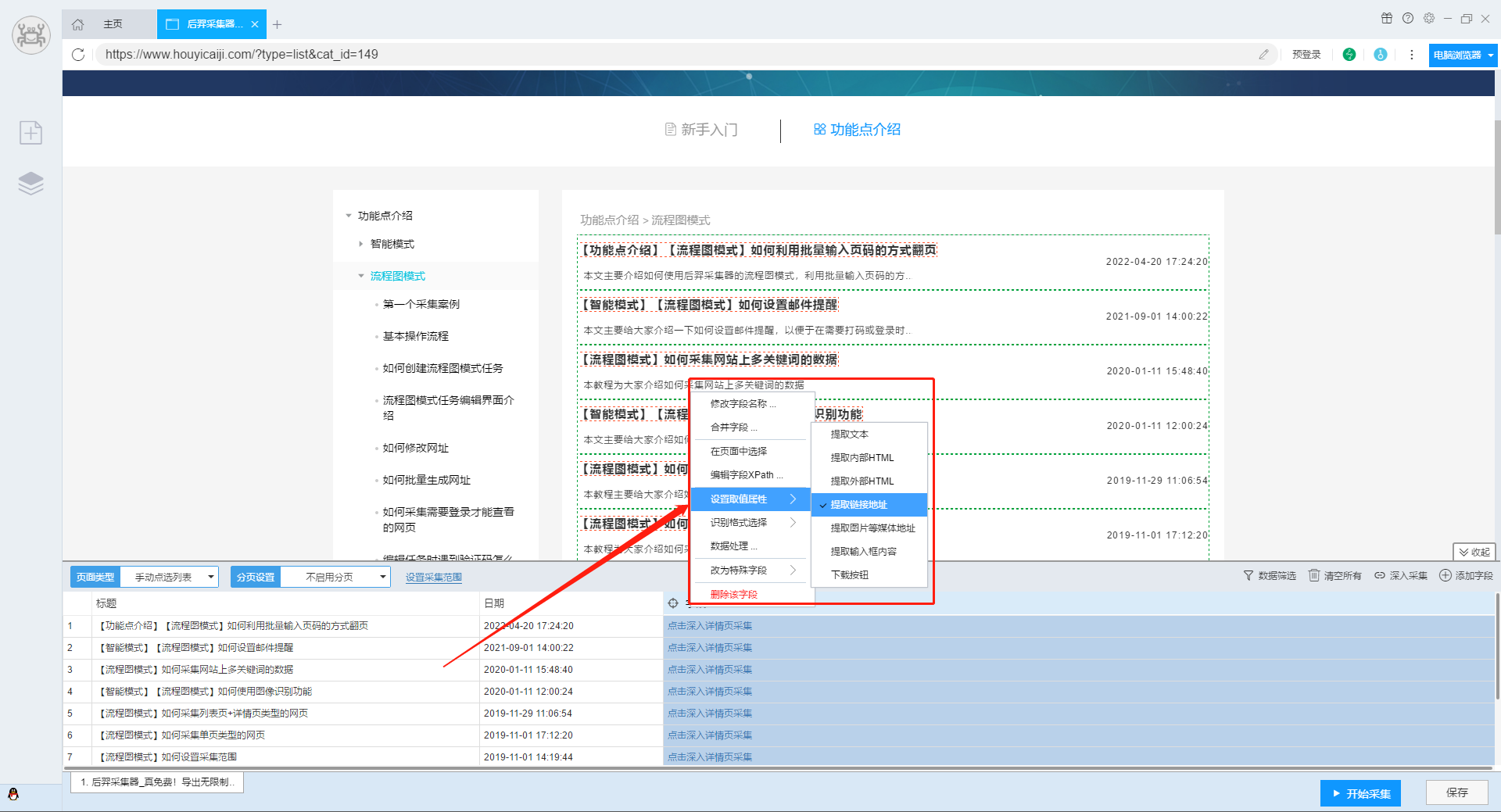
3.点击“深入采集”,进入详情页。
点此深入了解如何深入采集
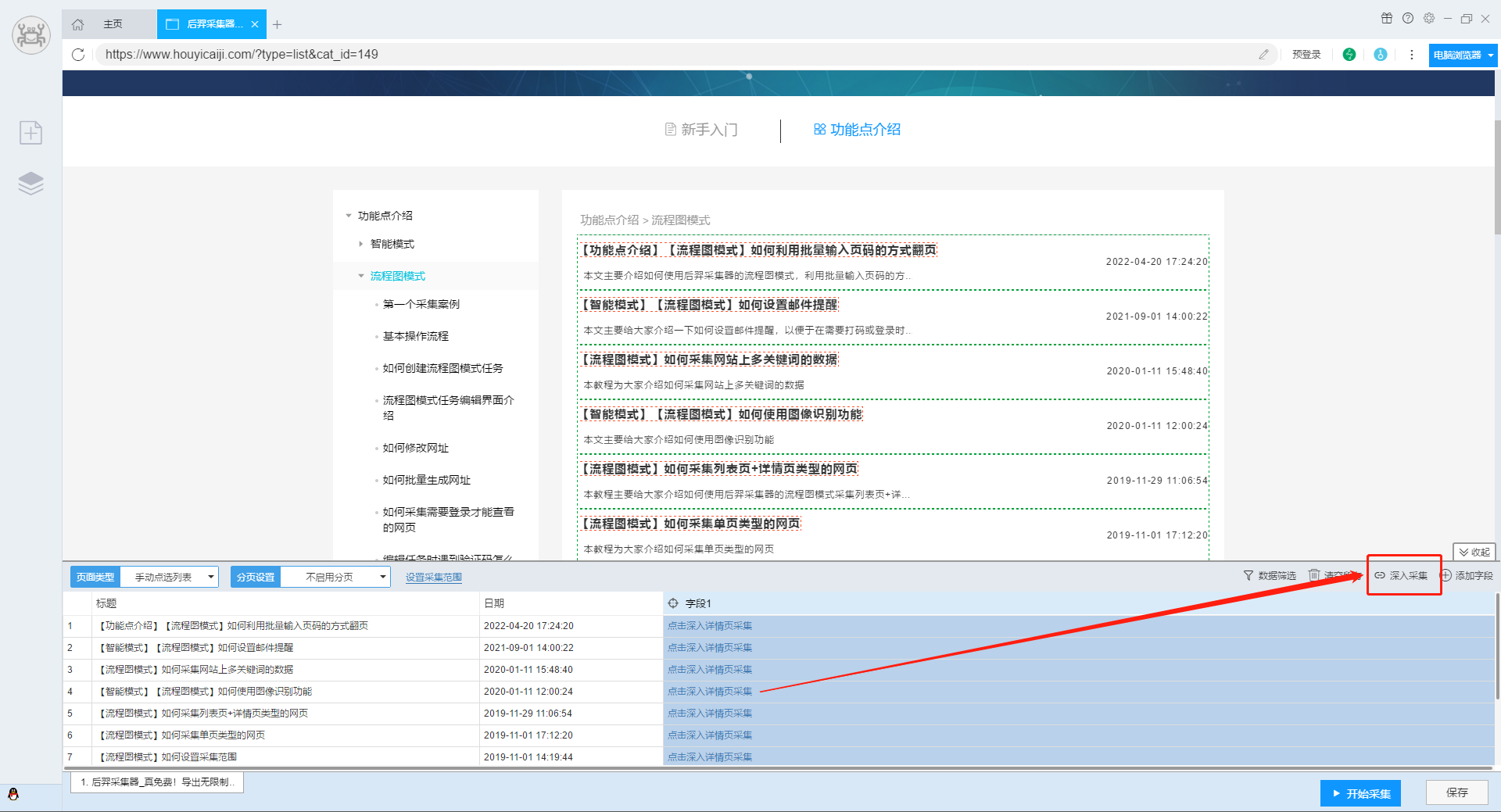
4.在进入详情页之后,我们可以任意添加一个字段,然后右键生成的字段,设置“改为特殊字段”,选择“当前页URL”。这样我们就能拿到详情页的链接了。
方法三:拼接出详情页的链接
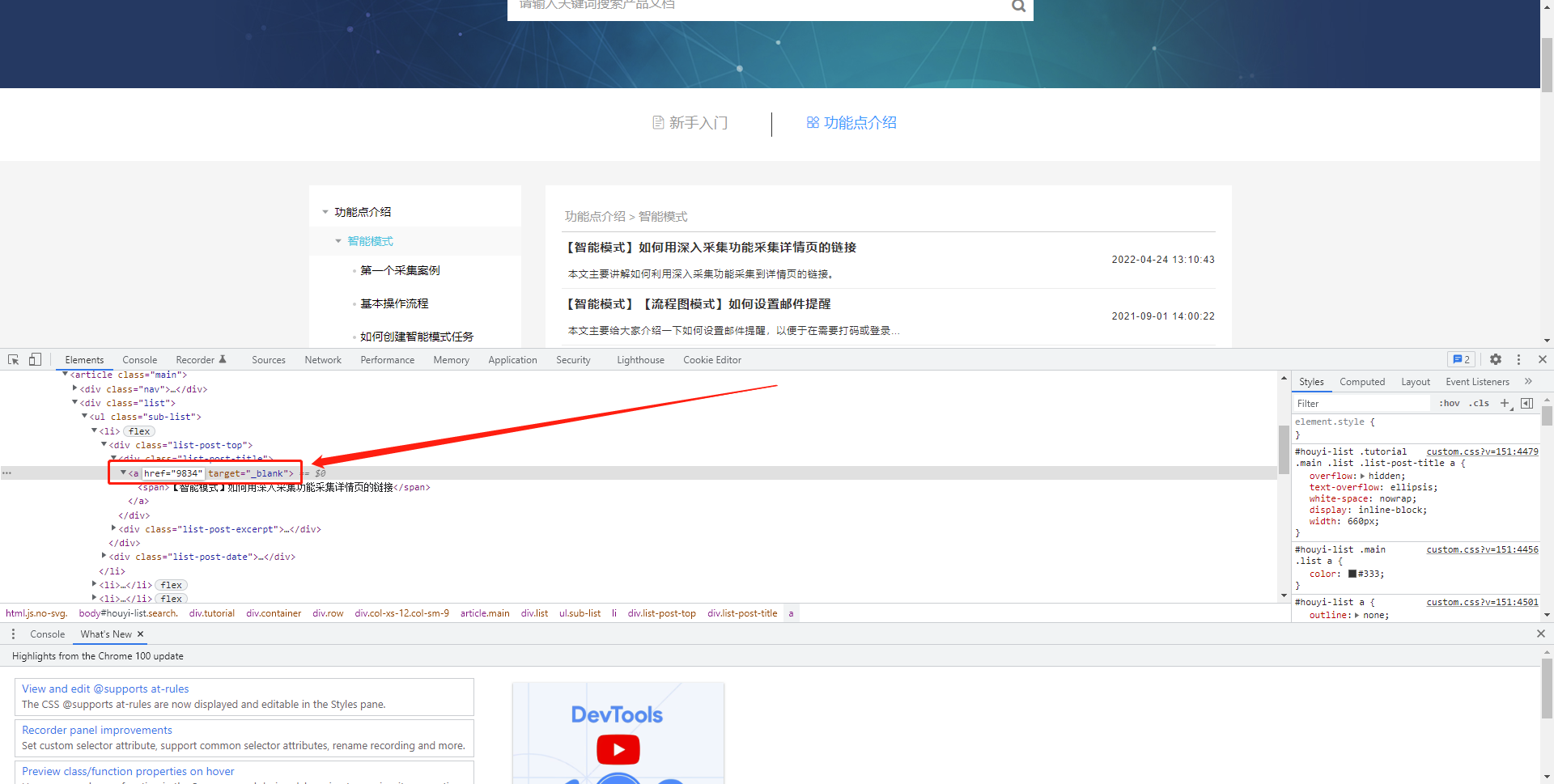
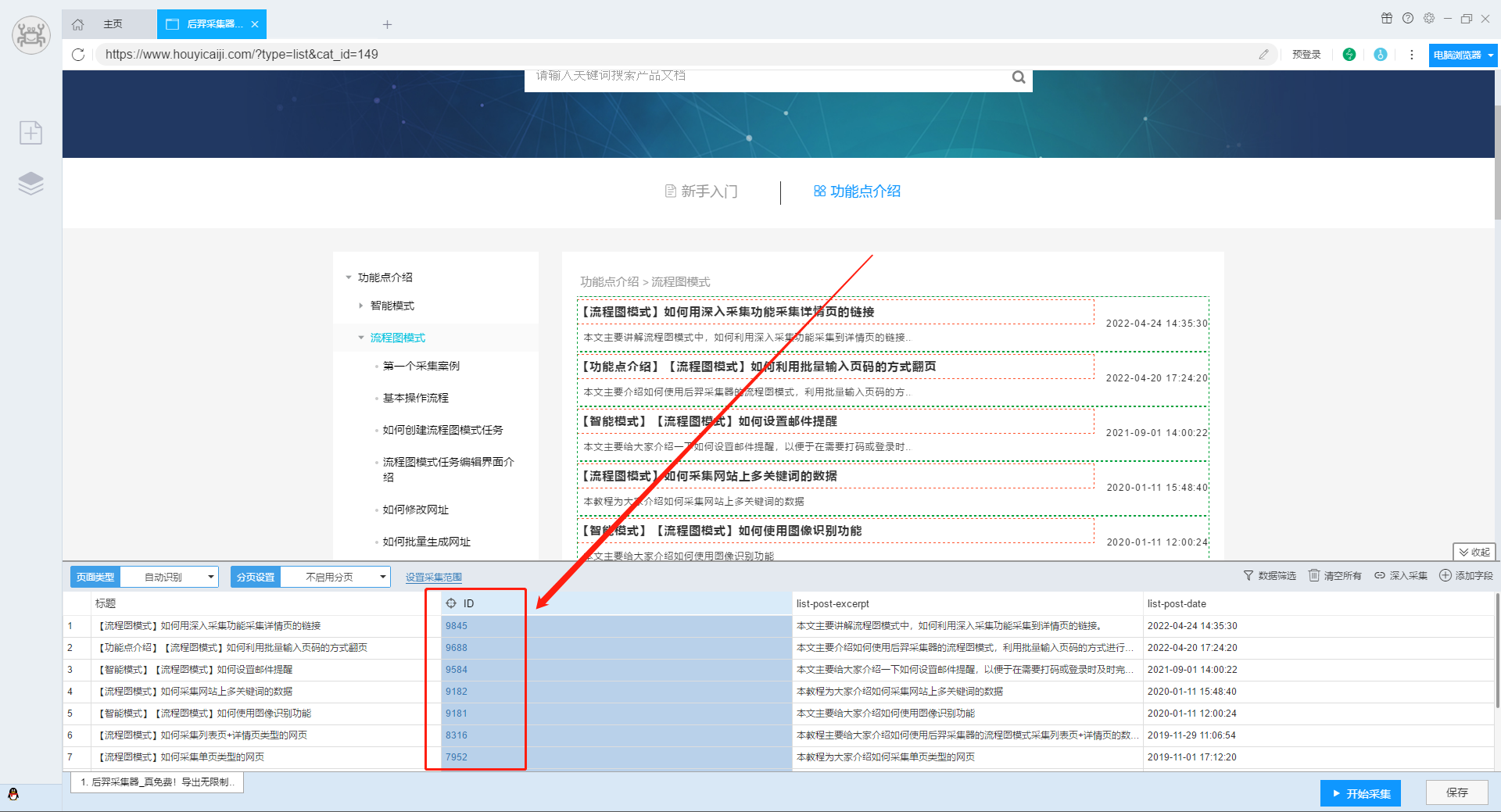
如果以上方法都无法顺利的采集到详情页的链接,而利用xpath或者正则可以提取到详情页ID的情况,可以利用数据处理拼接出详情页的链接。
【温馨提示】如果不会XPath或者正则表达式,请直接联系我们的定制客服进行定制。定制客服微信号:houyidingzhi
右键字段,设置”数据处理”,如图所示新建”添加前缀”。
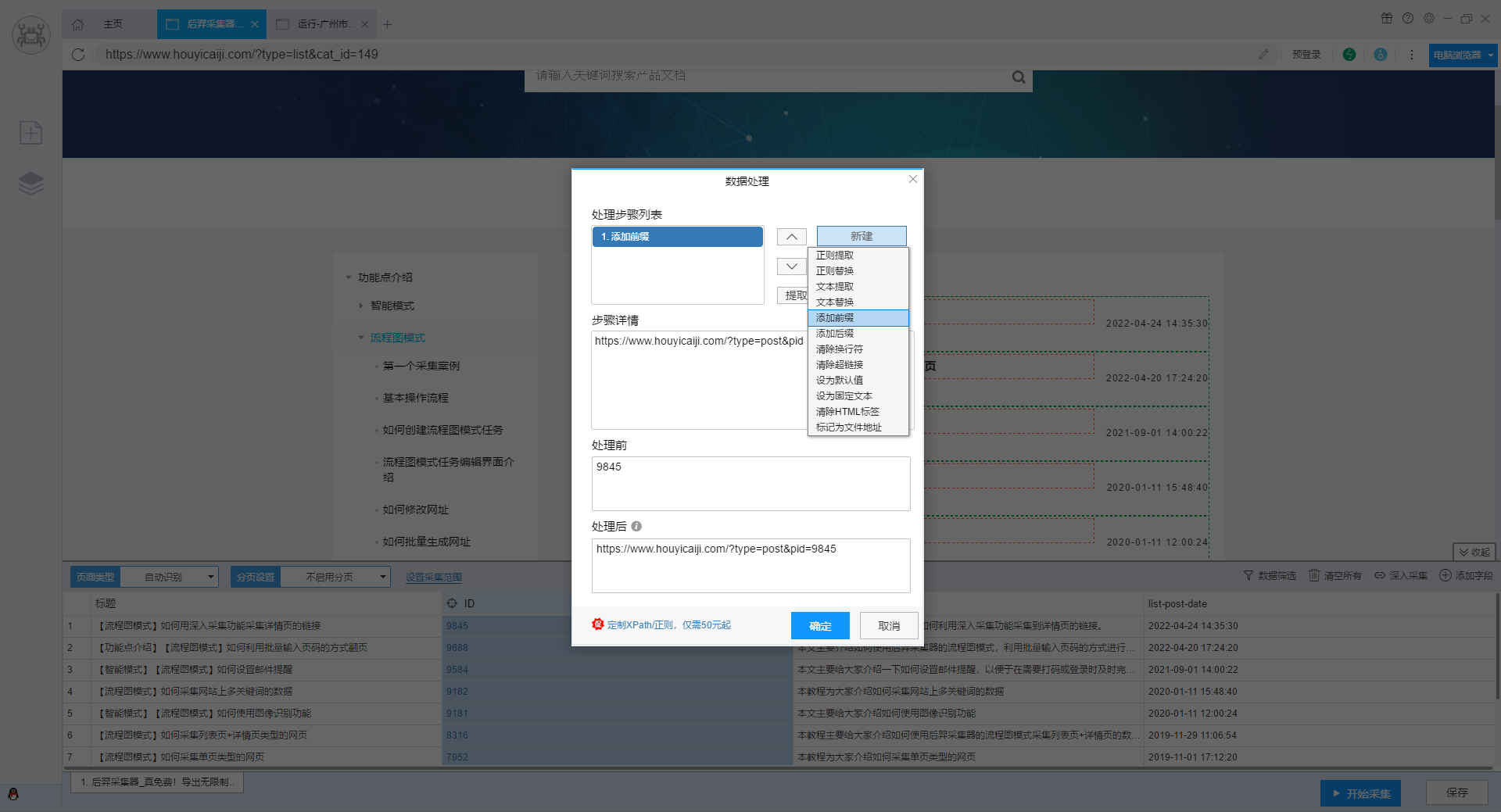
这样我们就能拿到详情页链接了。

文章评论