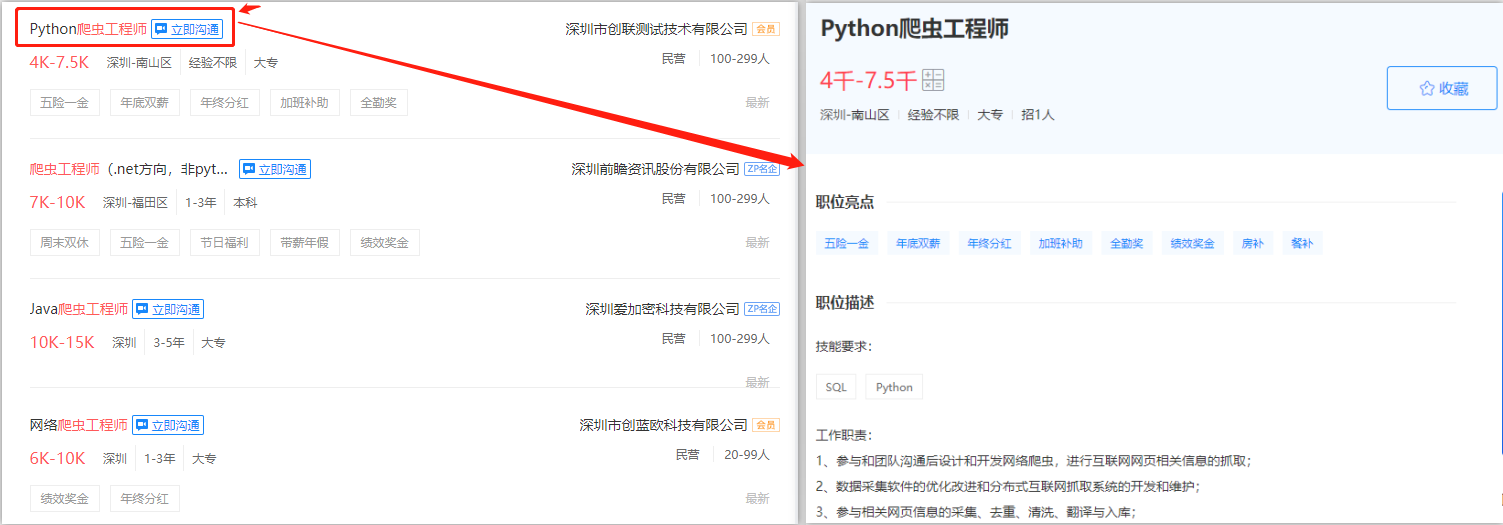
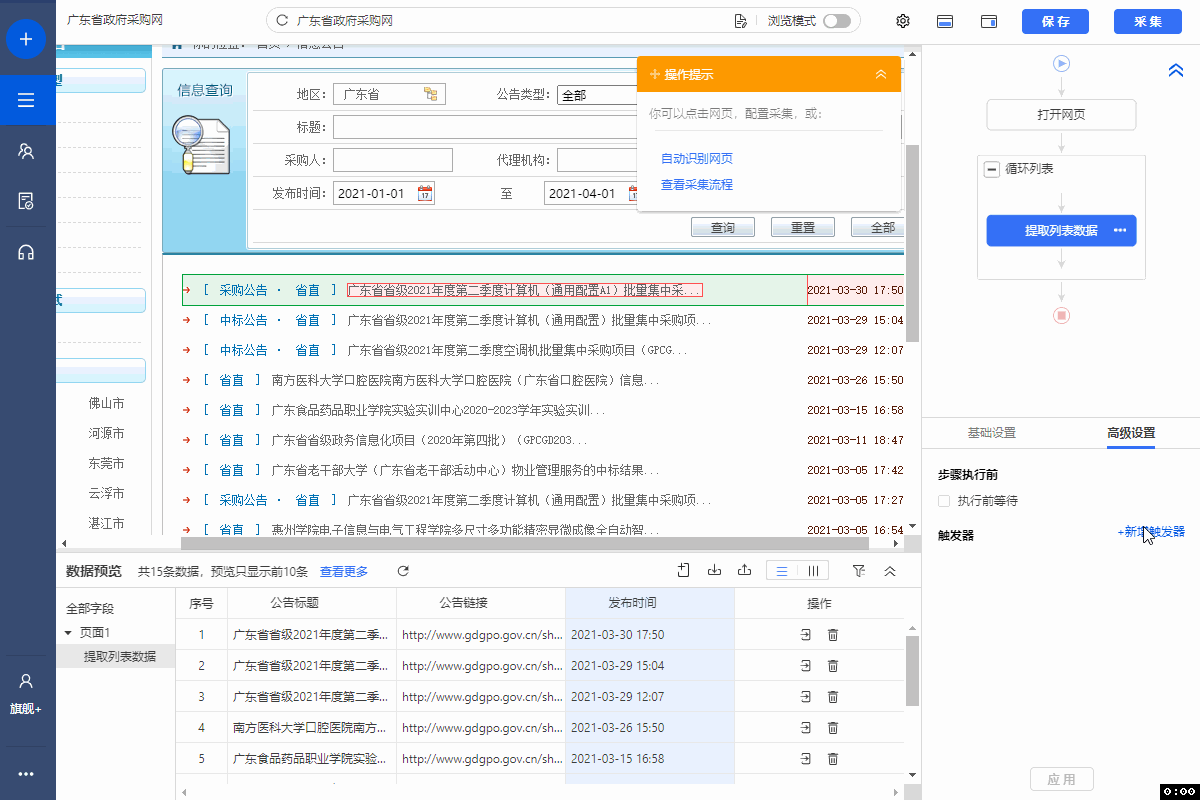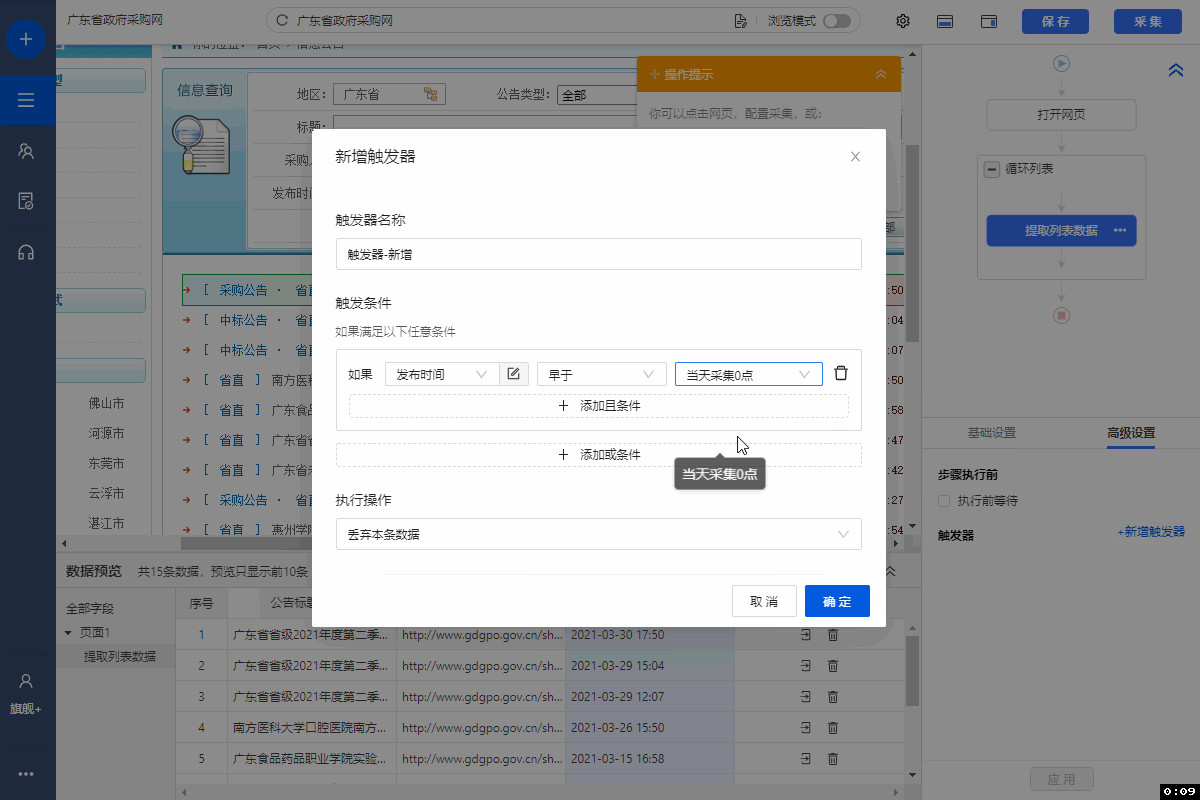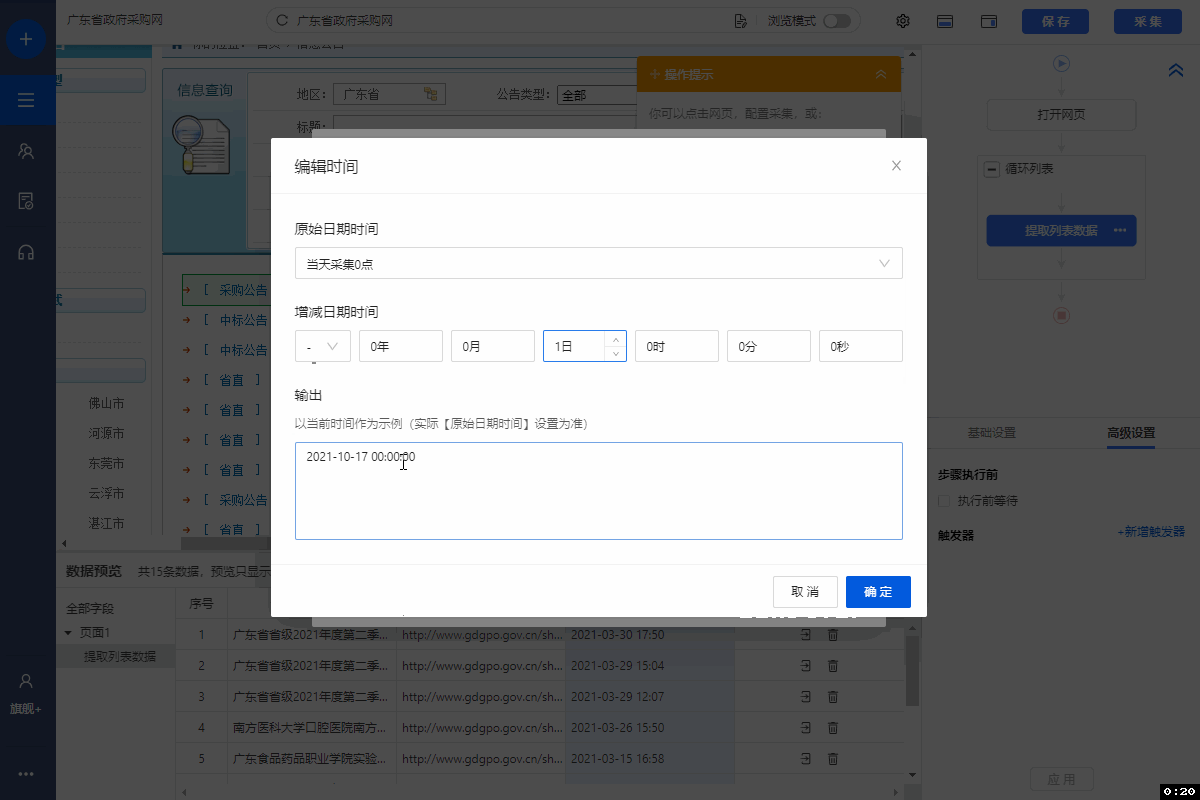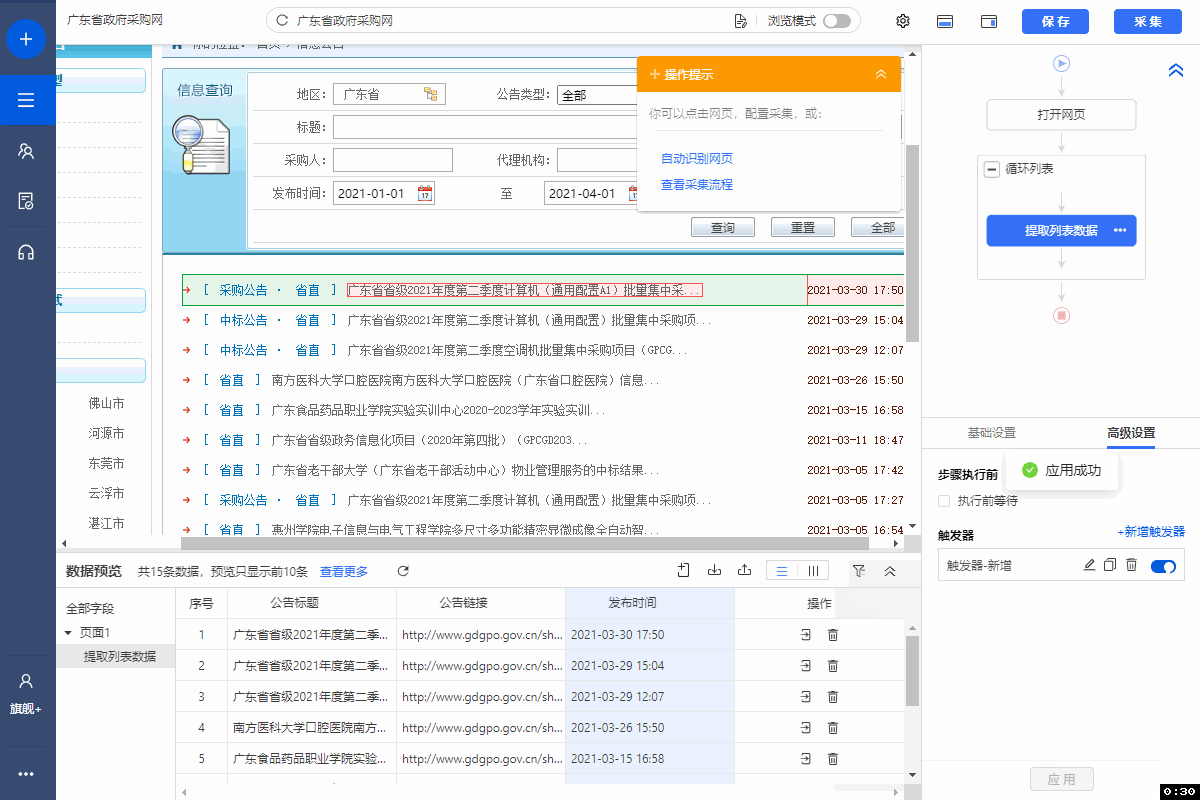
采集场景 在智联招聘地区招聘搜索页(https://sou.zhaopin.com/?jl=765), 输入关键词搜索(示例中的搜索关键词为【爬虫工程师】),搜索后得到招聘信息列表页。点击职位链接,进入职位详情页,采集详情页数据。 采集字段 职位名称、职位薪资、职位描述、职位链接等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 采集步骤 步骤一:打开网页 …
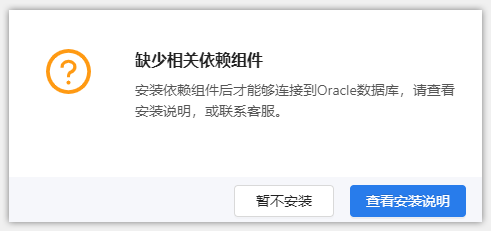
八爪鱼采集到的数据,支持导出到Oracle数据库中。可手动导出,也按照设置的定时导出计划,自动导出。 本教程将以云采集数据,演示手动/自动导出到Oracle数据库中的具体步骤。 准备工作:安装Oracle依赖组件 在正式导出到Oracle数据库前,需先安装Oracle依赖组件,否则点击【导出到Oracle】会提示: Oracle依赖组件安装步骤如下: Step1:下载Oracle依赖组件的ZIP文件 64位:https://www.oracle.com/database/technologies…
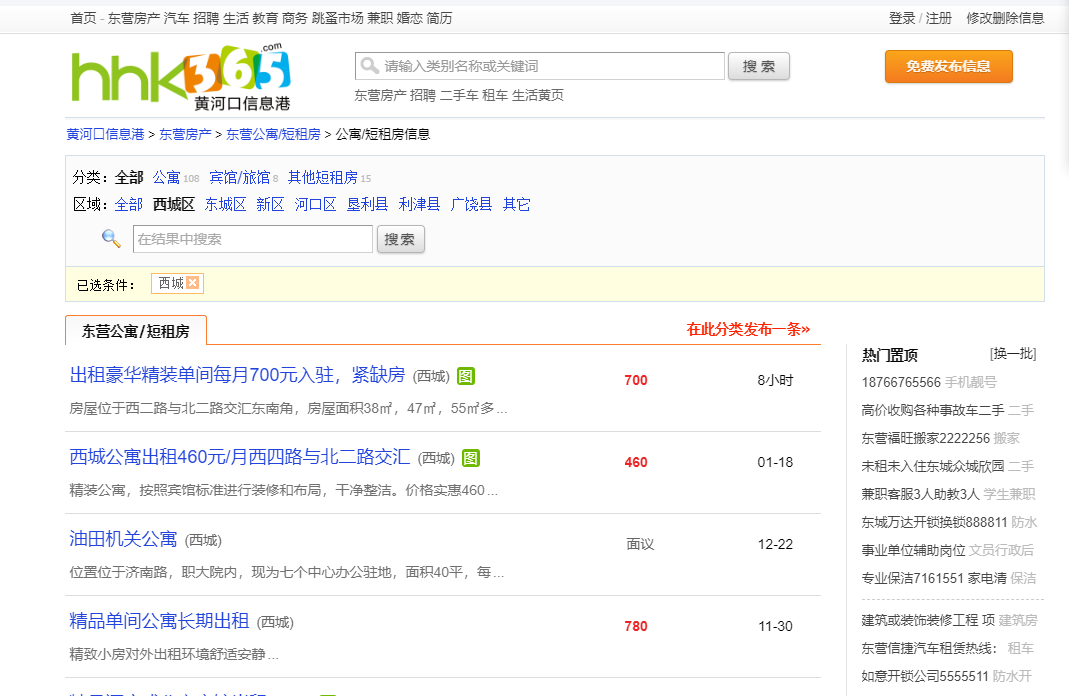
采集场景 采集黄河口信息港的短租房信息。 采集字段 区域、标题、标题链接、出租人、价格、位置等。 点击图片可查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2021/1/13 八爪鱼版本:V8.2.6 如果因网页改版造成网址或步骤无效,无法采集到目标数据,请联系官方客服,我们将及时修正。 采集步骤 步骤一、打开网页 步骤二、自动识别 步骤三、设置点击步骤,进入详情页 步骤…
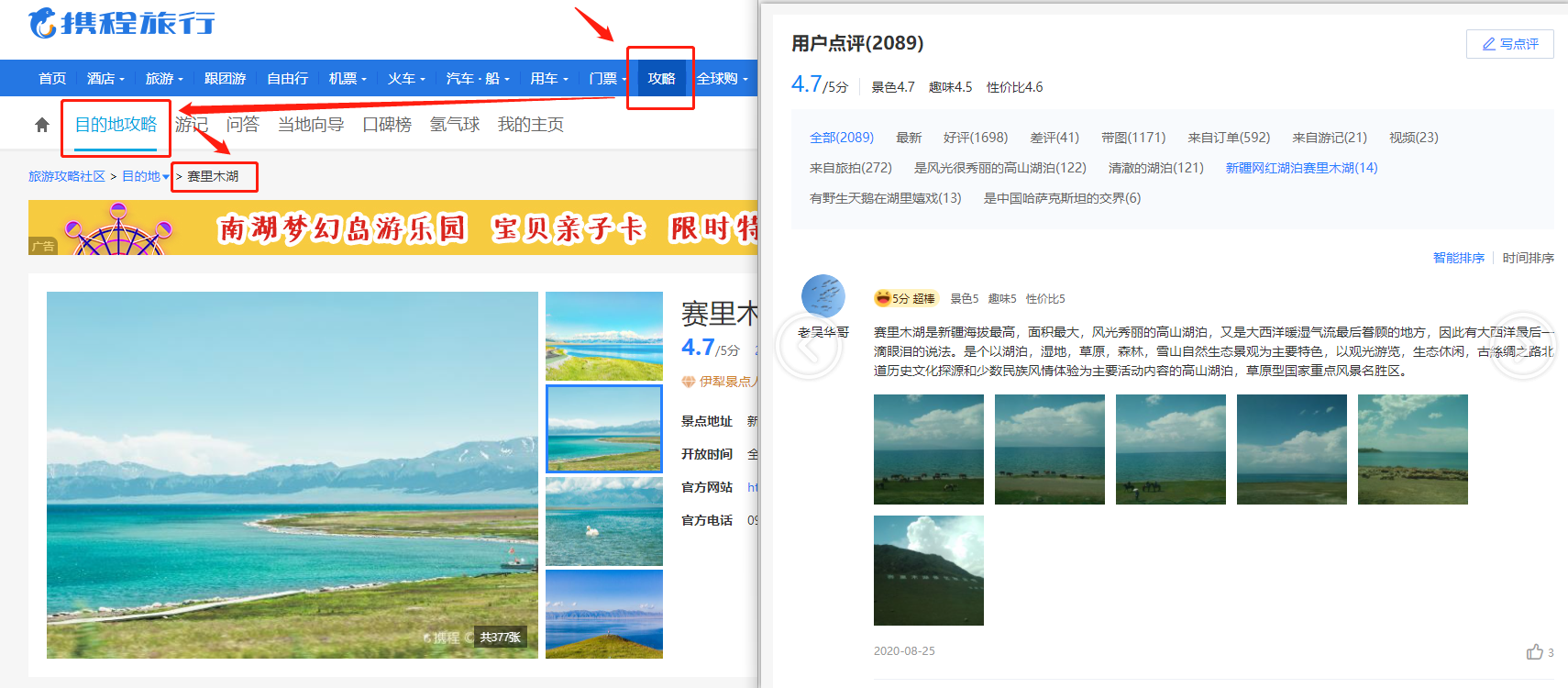
采集场景 在携程网点击【攻略】-【目的地攻略】- 【选择目的地】-【选择景点】,采集目的地景点下的评论。 示例网址:https://you.ctrip.com/sight/bole922/5500.html https://you.ctrip.com/sight/lijiang32/3049.html 采集字段 景点名、级别、总评分、评论数、景点地址、开放时间、景点介绍、整体景色、整体趣味、整体性价比、用户名、评分、景色、趣味、性价比、评论正文、评论时间。 点击查看高清大图,…
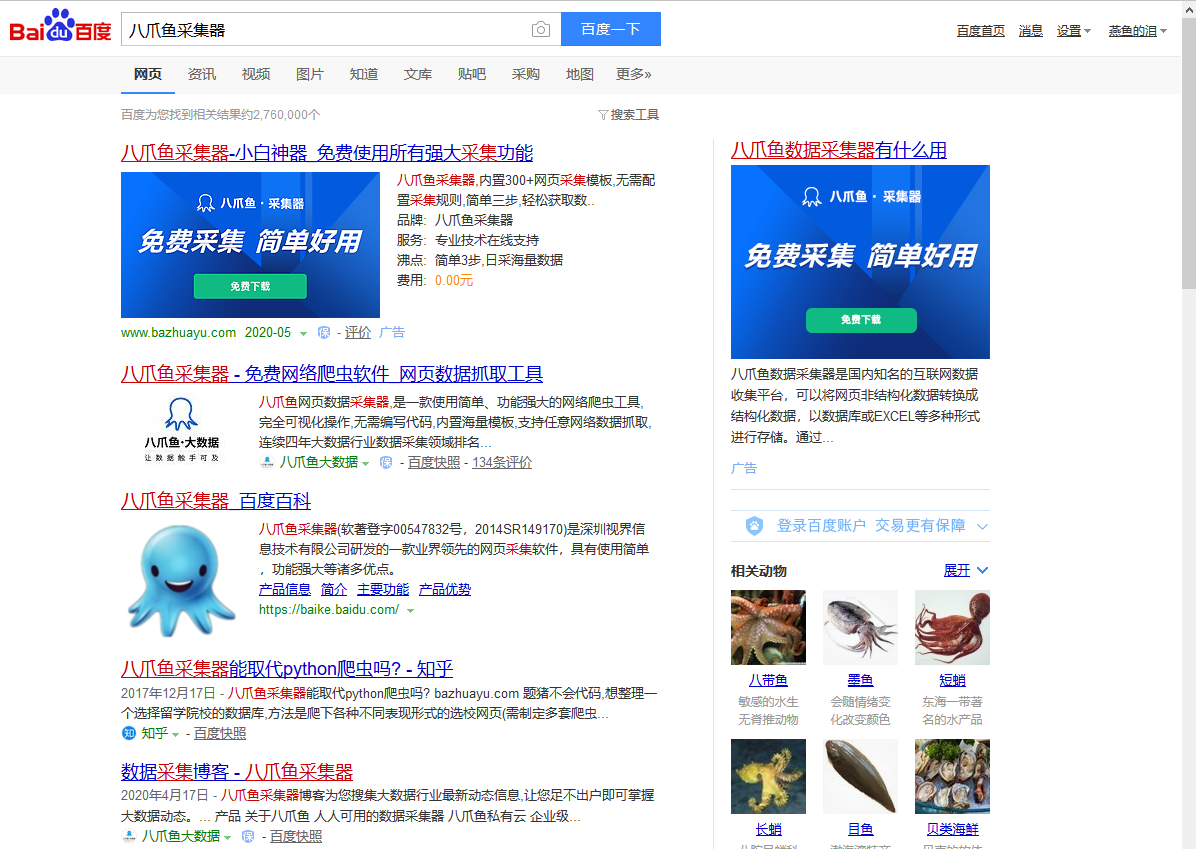
采集场景 在百度首页 https://www.baidu.com/ 输入关键词搜索,采集搜索后得到的搜索结果。 采集字段 标题、网页链接、简介 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇更新时间:2022/6/9 八爪鱼版本:V8.5.2 如果因网页改版造成网址或步骤无效,无法采集到目标数据,请联系官方客服,我们将及时修正。 采集步骤 步骤一、打开网页 步骤二、批量输入多个关键词并搜索 步骤三、创建【循环翻页】,采…
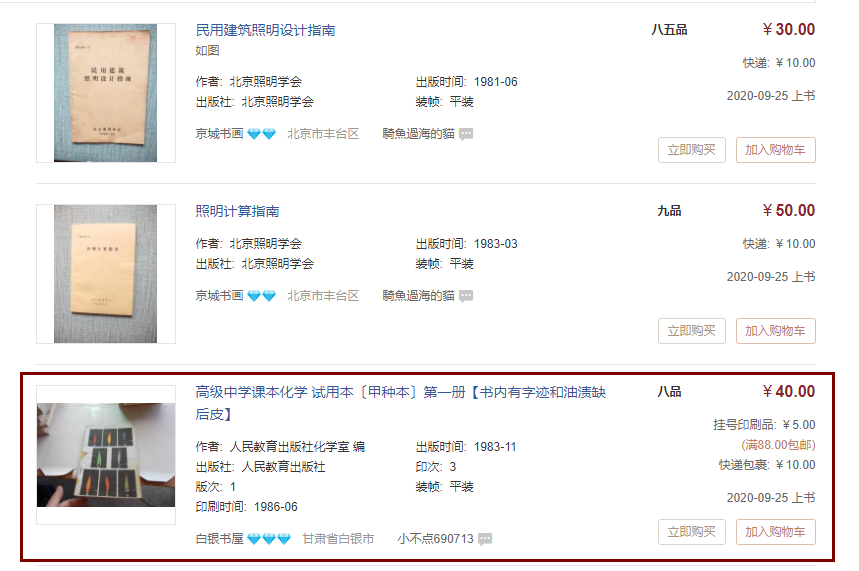
采集场景 孔夫子旧书网有非常多的类目,本教程讲解如何分类目采集图书列表页数据。 示例网址 http://book.kongfz.com/Cjishu/n1004000000/ 是【图书-工程技术-改革开放与80年代】类目的网址。 采集字段 书名、出版社、店铺名称、发货地址、品相、售价等字段。 点击查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/6/08 八爪鱼版本:…
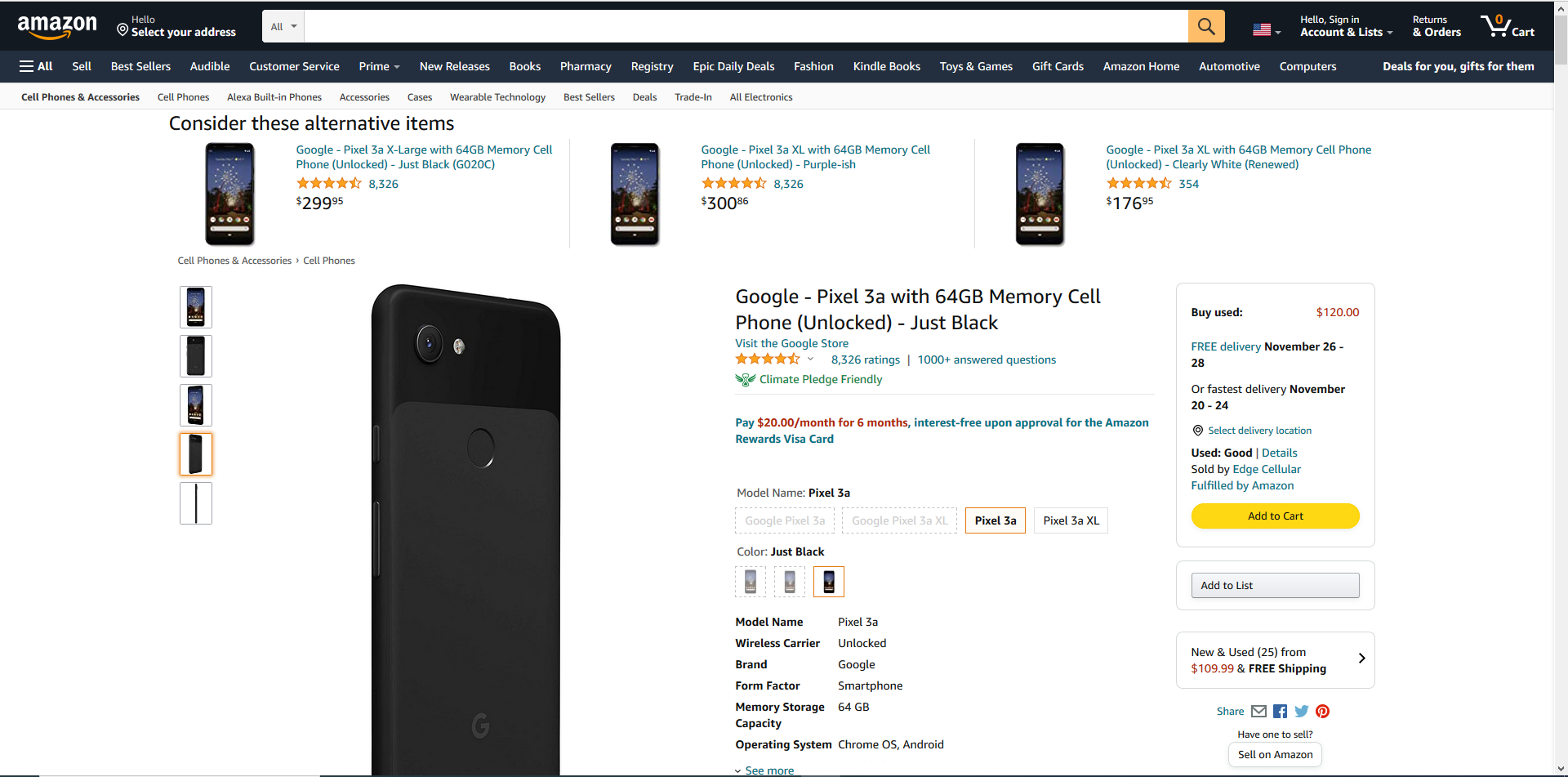
采集场景 采集Amazon商品详情页数据。Amazon商品详情页实例网址:https://www.amazon.com/dp/B07R7DY911。 采集字段 title、brand、stars、ratings、questions、price、details、productdimensions、itemweight、shippingweight、asin、itemmodelnumber、bestsellerrank、stock 等。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他…
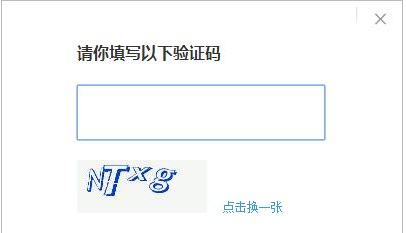
什么是防采集? 用大白话来说,就是我们想利用工具采集某个网站的数据(前提当然是公开合法数据),但网站不想给你采集而设置的技术阻挡措施。 网站常见的防采集套路有哪些? 防采套路1:输入验证码框验证 采集难度:★☆☆☆☆ 常见网站:搜狗微信 在采集某些网站过程中,爪子们是不是经常会遇到这样的情况,要求你输入验证码,否则就卡住进行不下去? 对的,这是网站最常用且最基础的防采措施之一,它要求你必须你手动输入验证码里的数字和字母,才能继续看到更多信息或者进行下一步,以此来判断你是机器人还是真人…

