
云采集排错教程
本教程针对本地采集有数据,云采集没有数据的排错教程,如果本地采集没有数据,请先参考本地采集排错教程
本地采集有数据,云采集没有数据主要原因为以下几点:
1.防采集
2.网站或网速原因
3.网络环境不同,源码有变,原xpath定位不准
4.网站只允许单浏览器或单IP登录
一、防采集
防采集主要是以下三类:IP被封禁止访问、出现验证码、云上需要登录
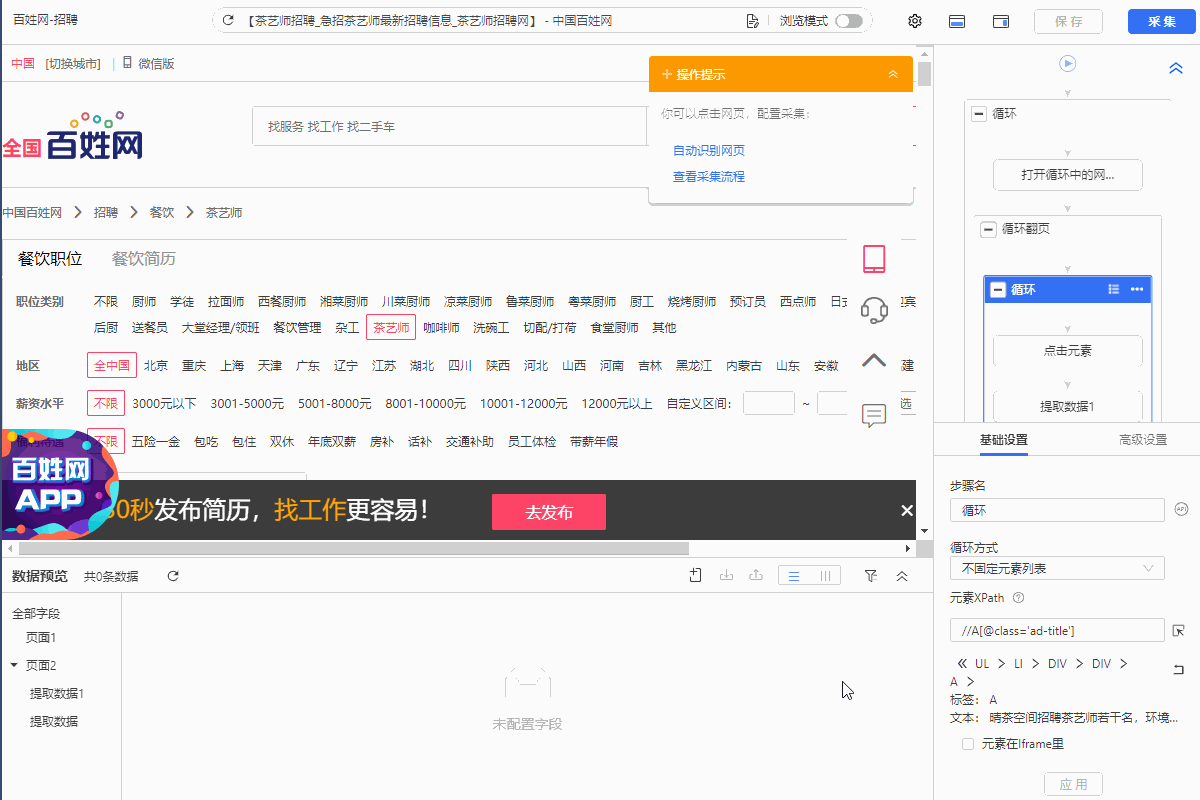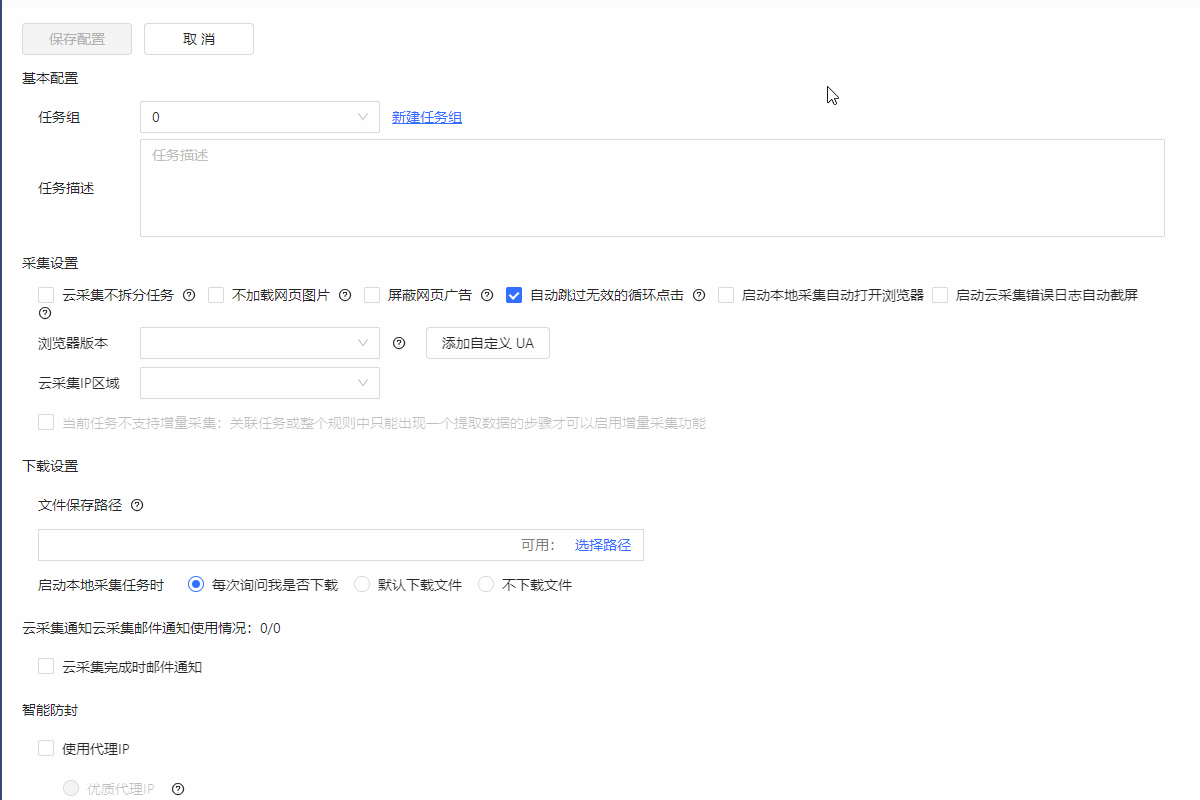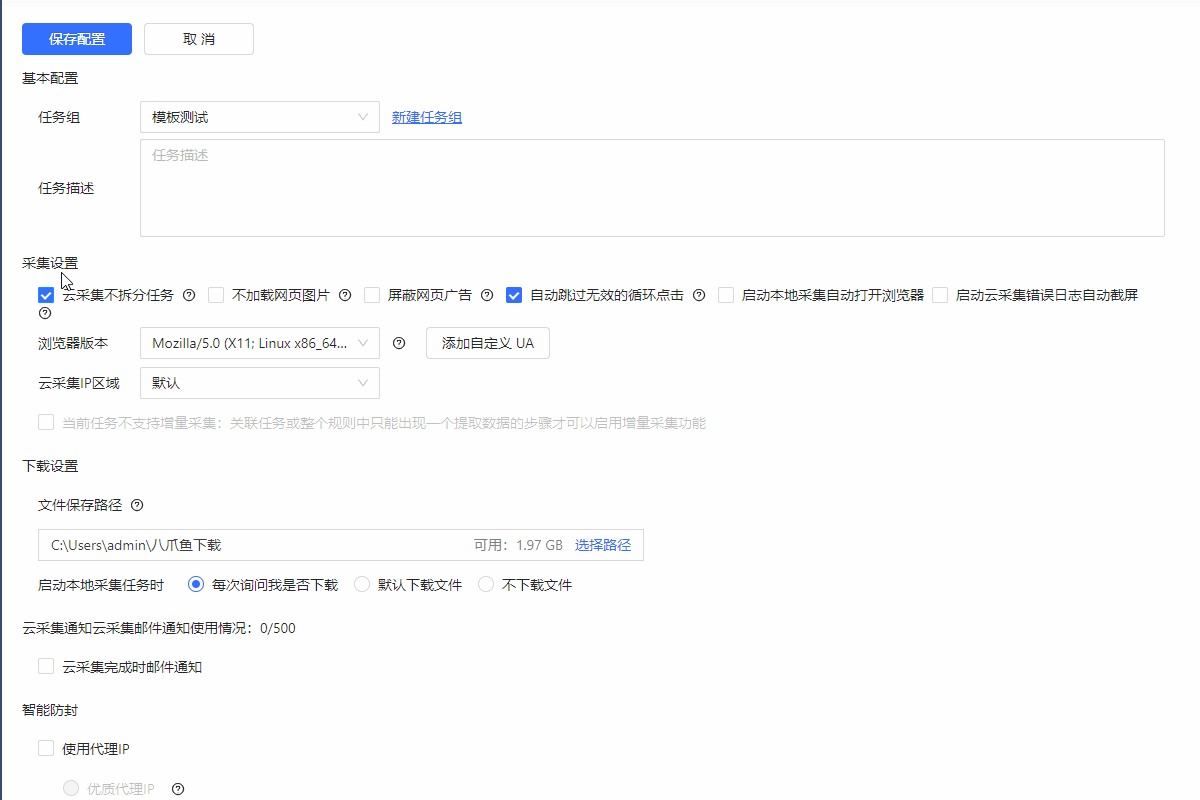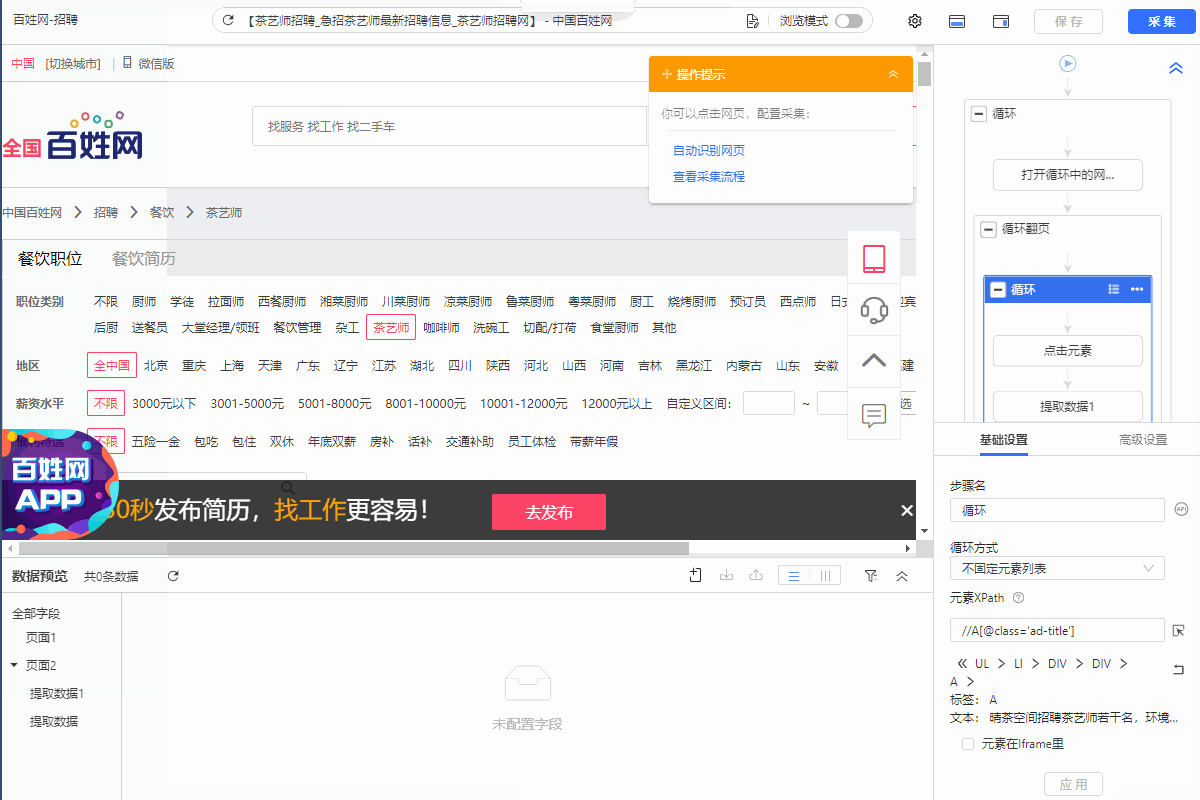
针对以上三种情况,都可以通过采集网页的html源码进行观察,这里我们以百姓网招聘数据采集为例。如下图1所示启动云采集后子任务出现采集为0的情况。
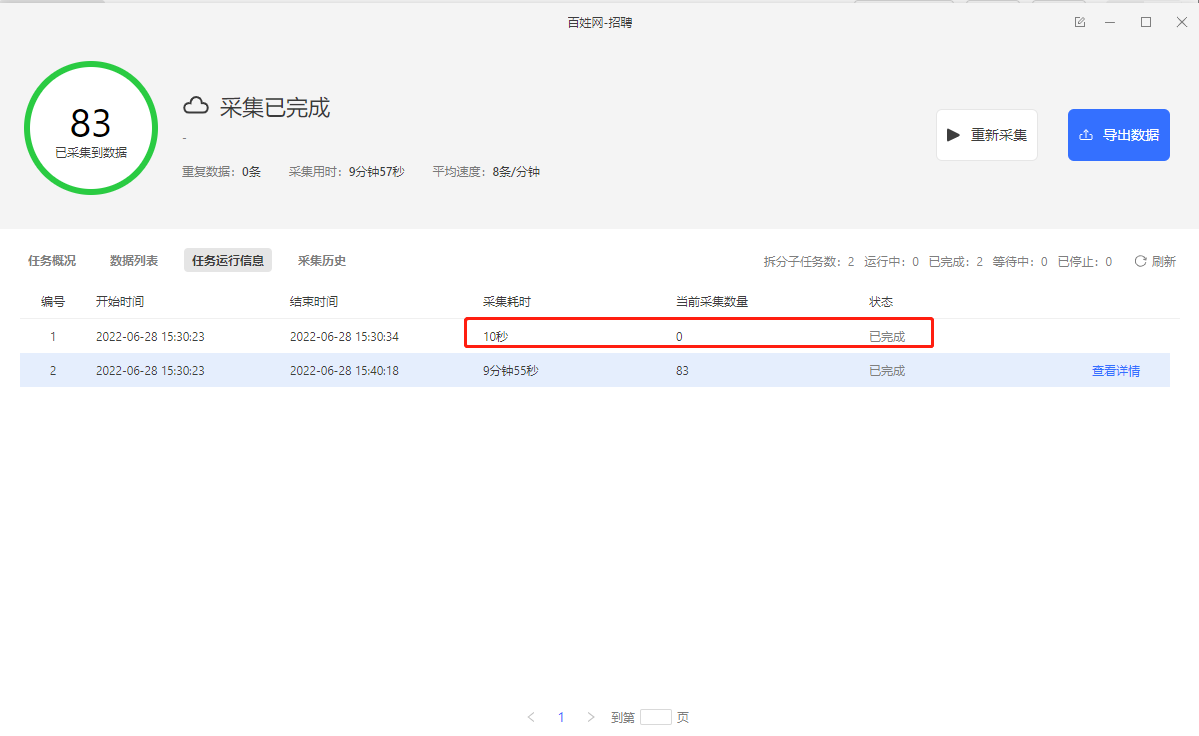
图1 云采集子任务状态
这时候我们可以采集网页源码观察网站在云上打开的情况去排查云采集为什么采集不到数据。
采集网页源码的具体步骤如下:
1.在规则对应位置增加【提取数据】步骤,然后再添加字段采集当前网页的源码。

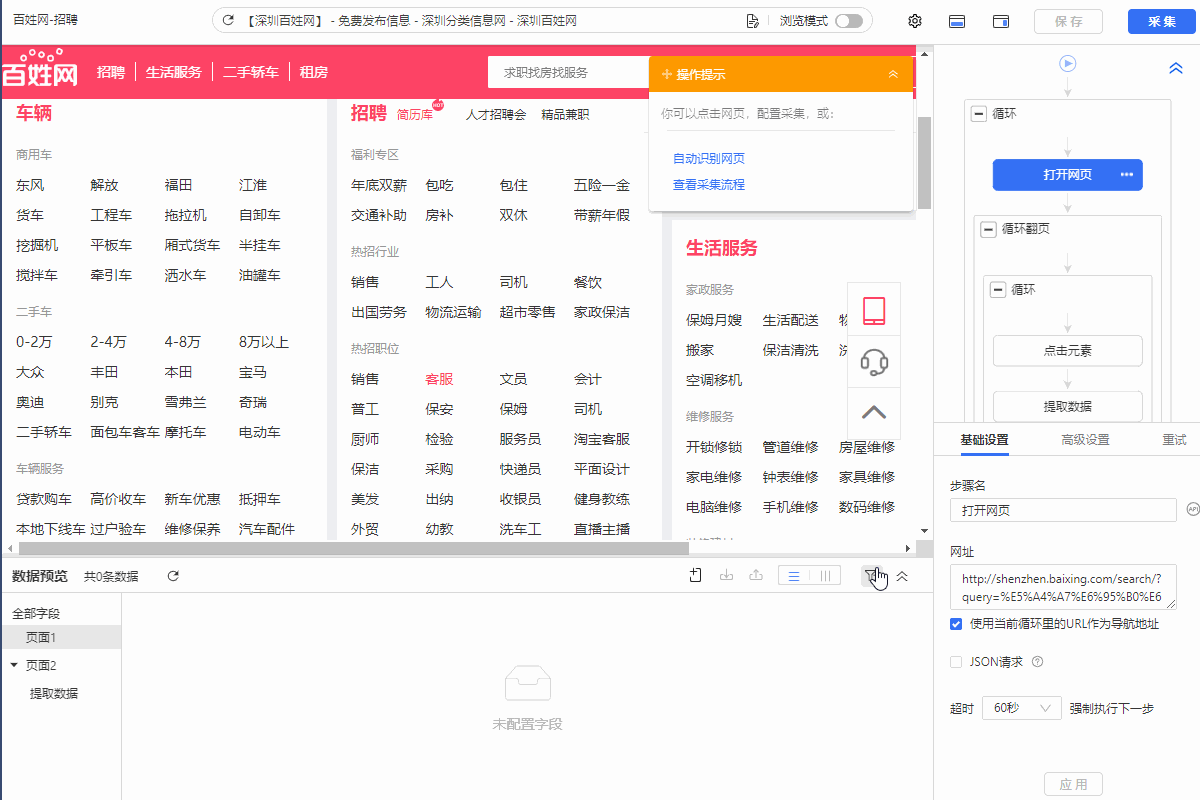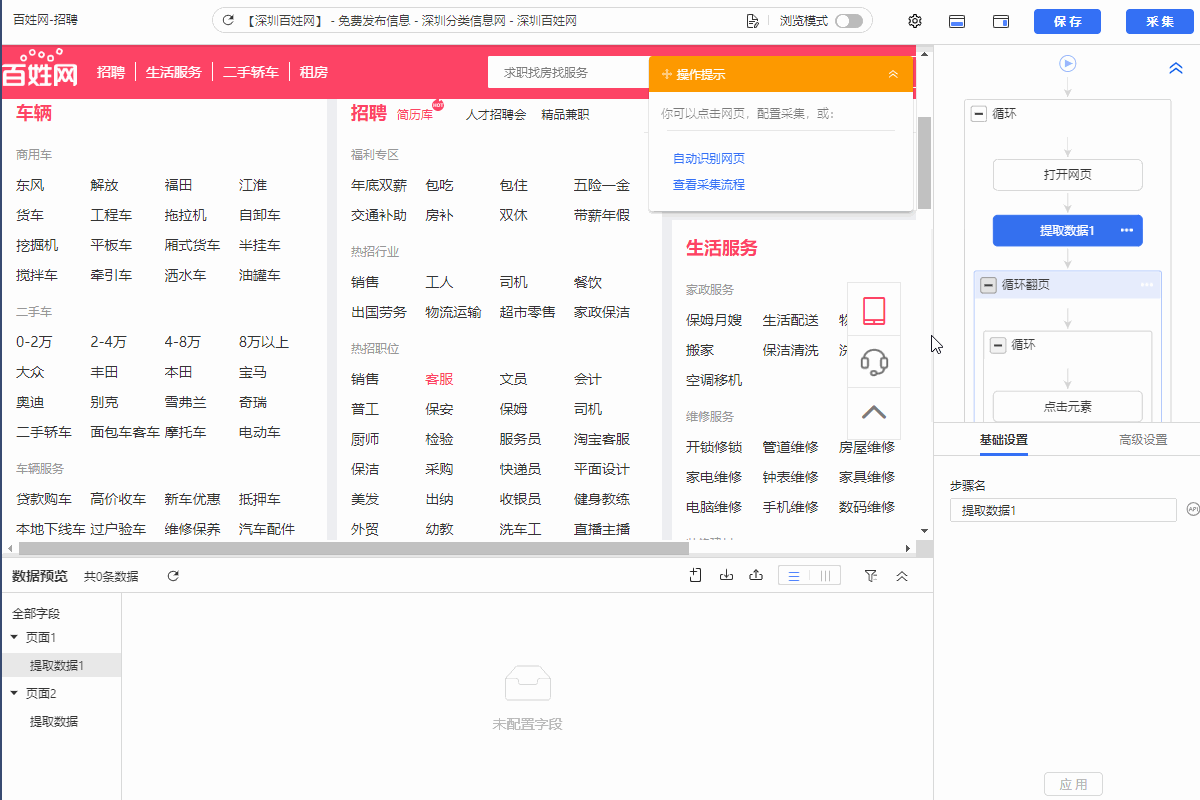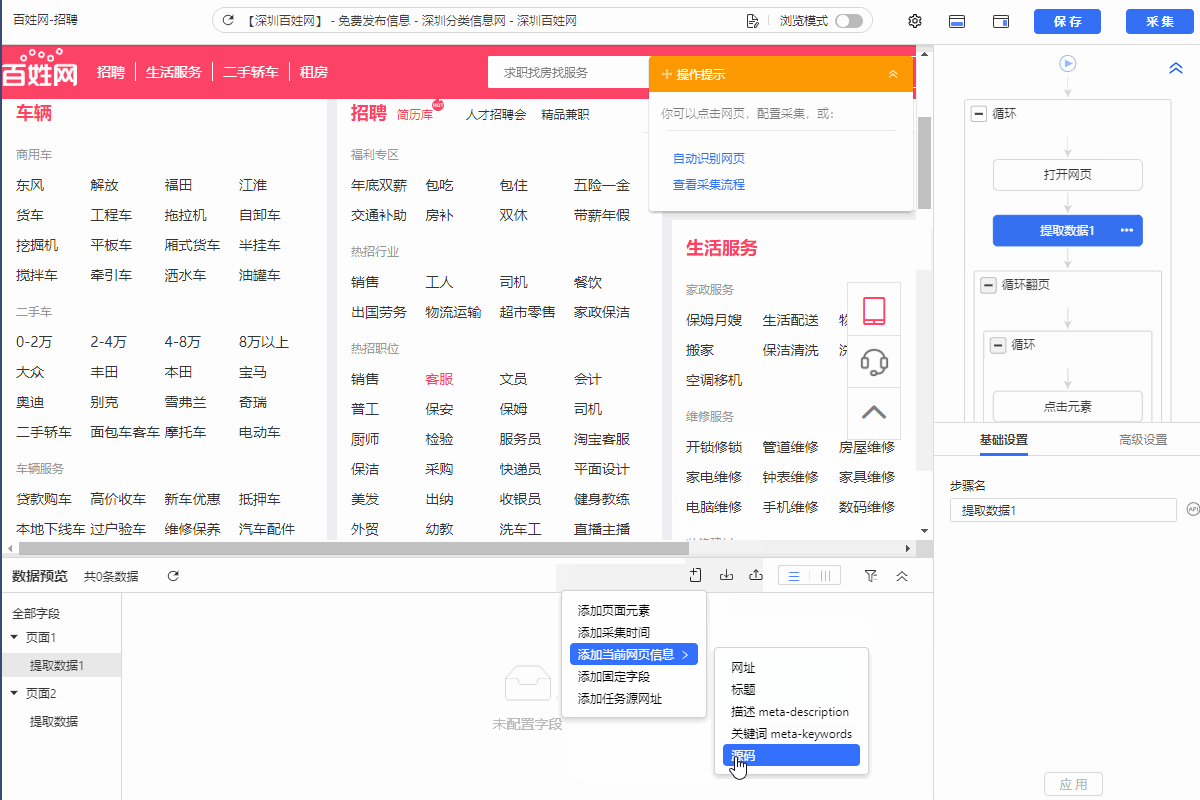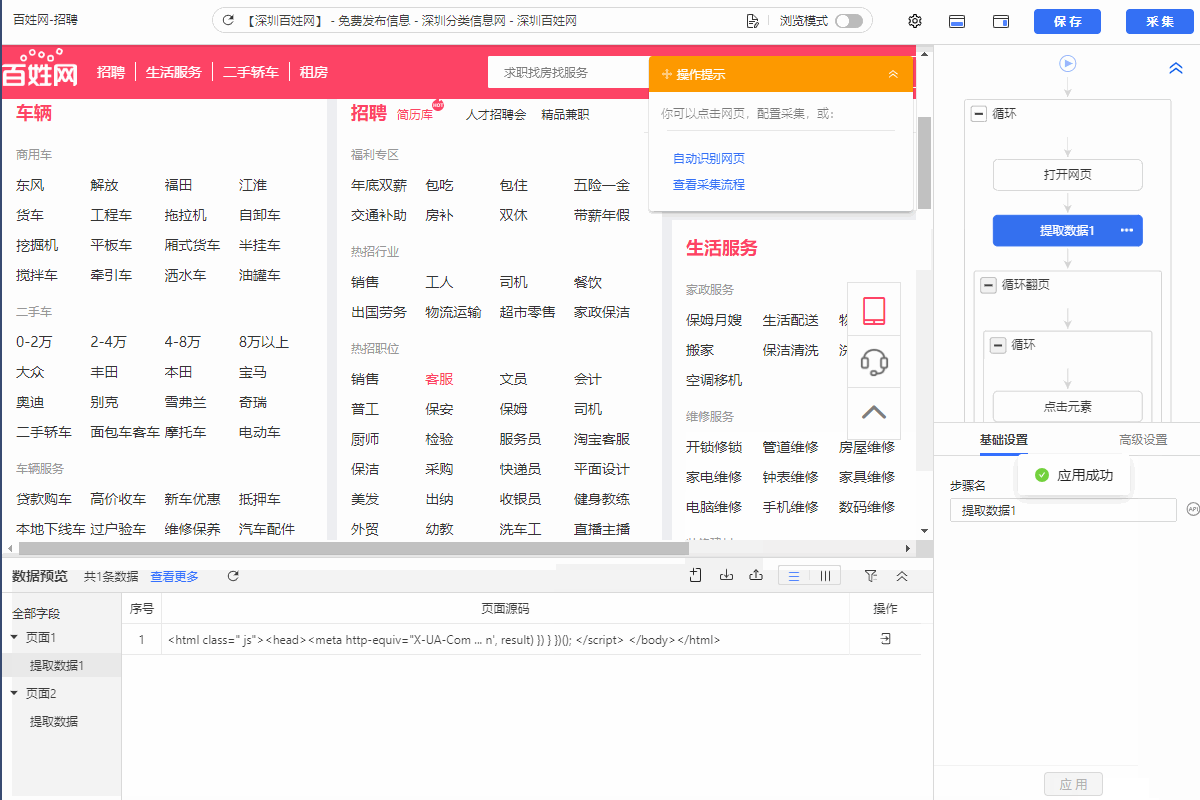
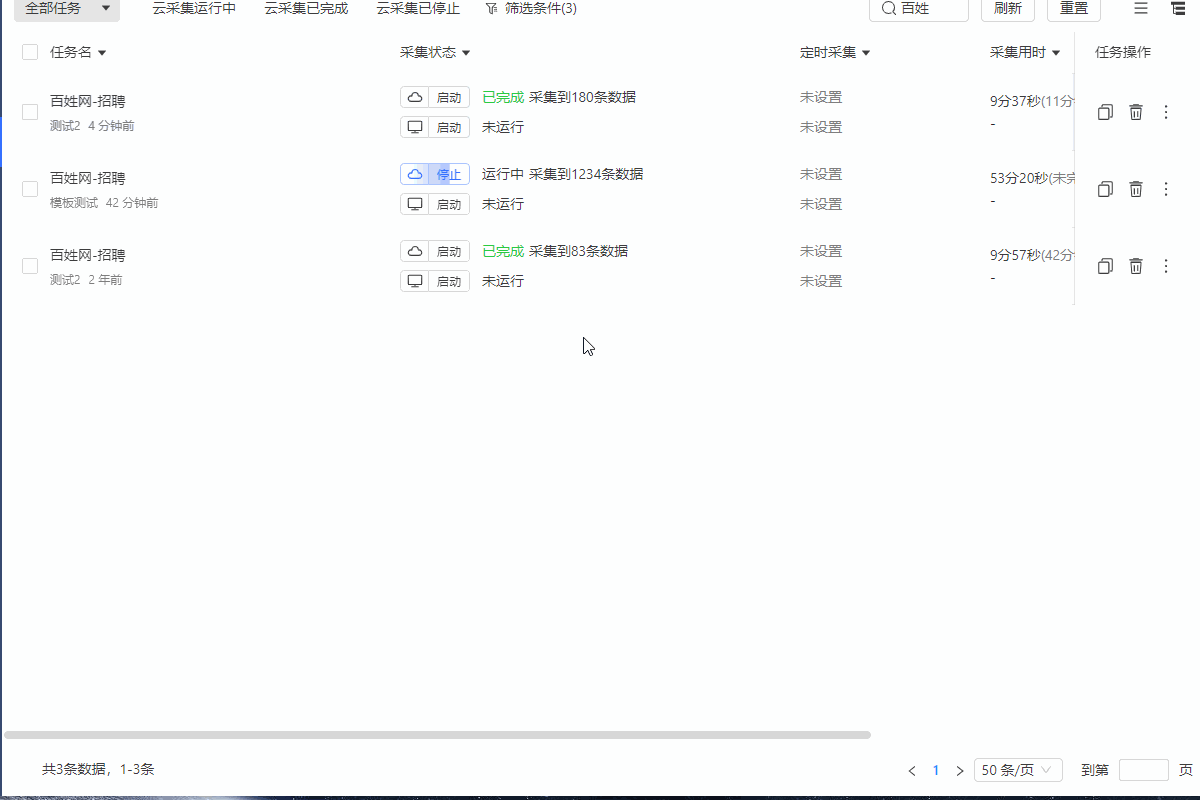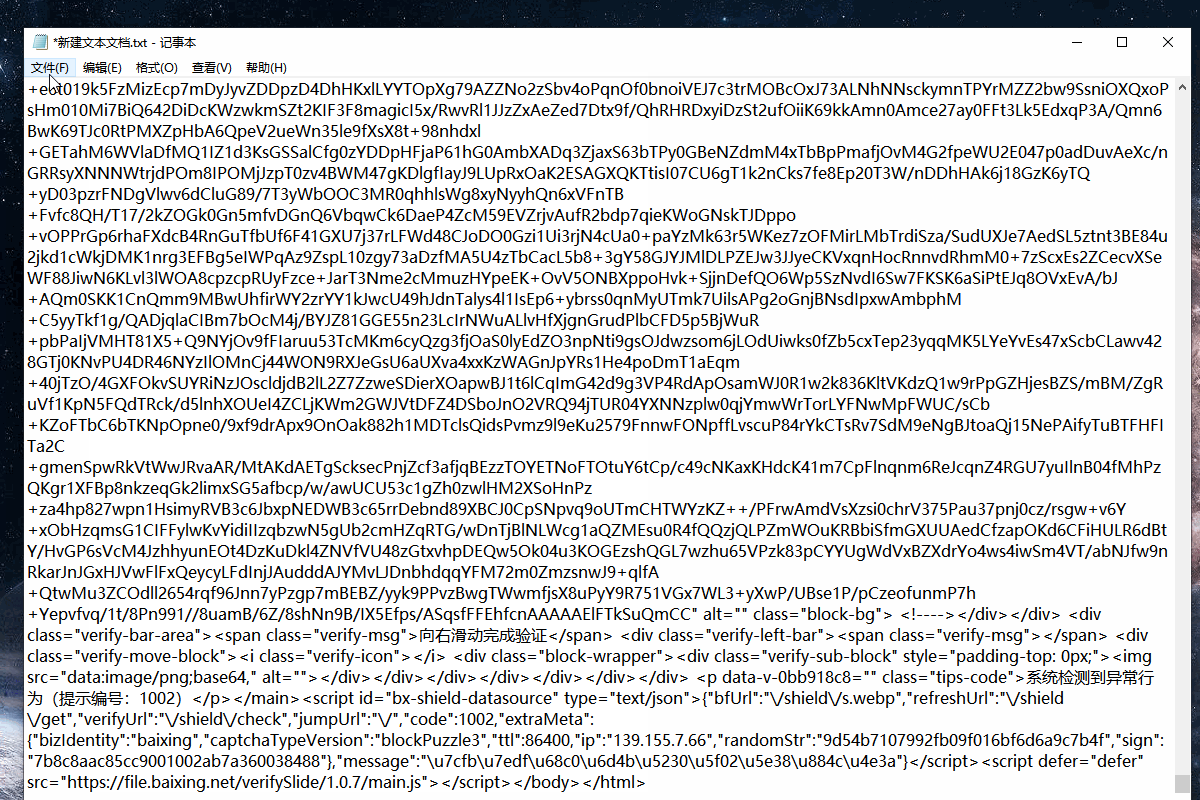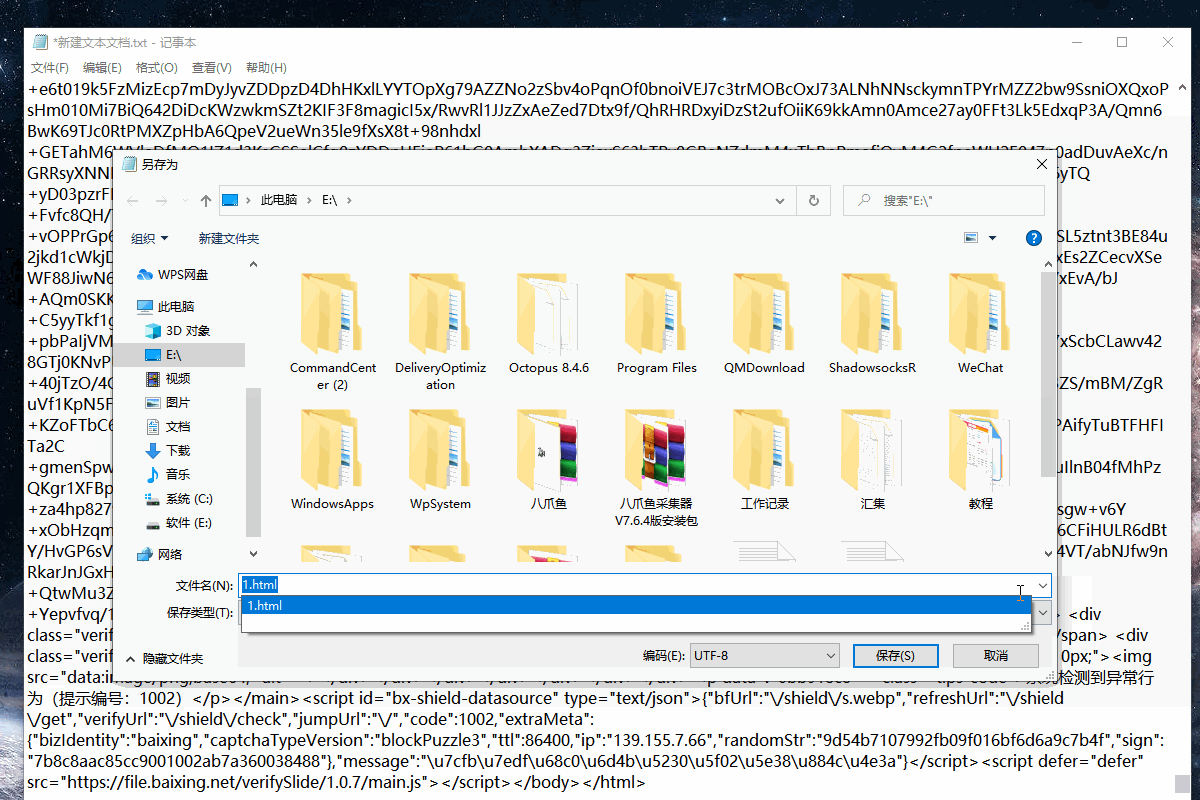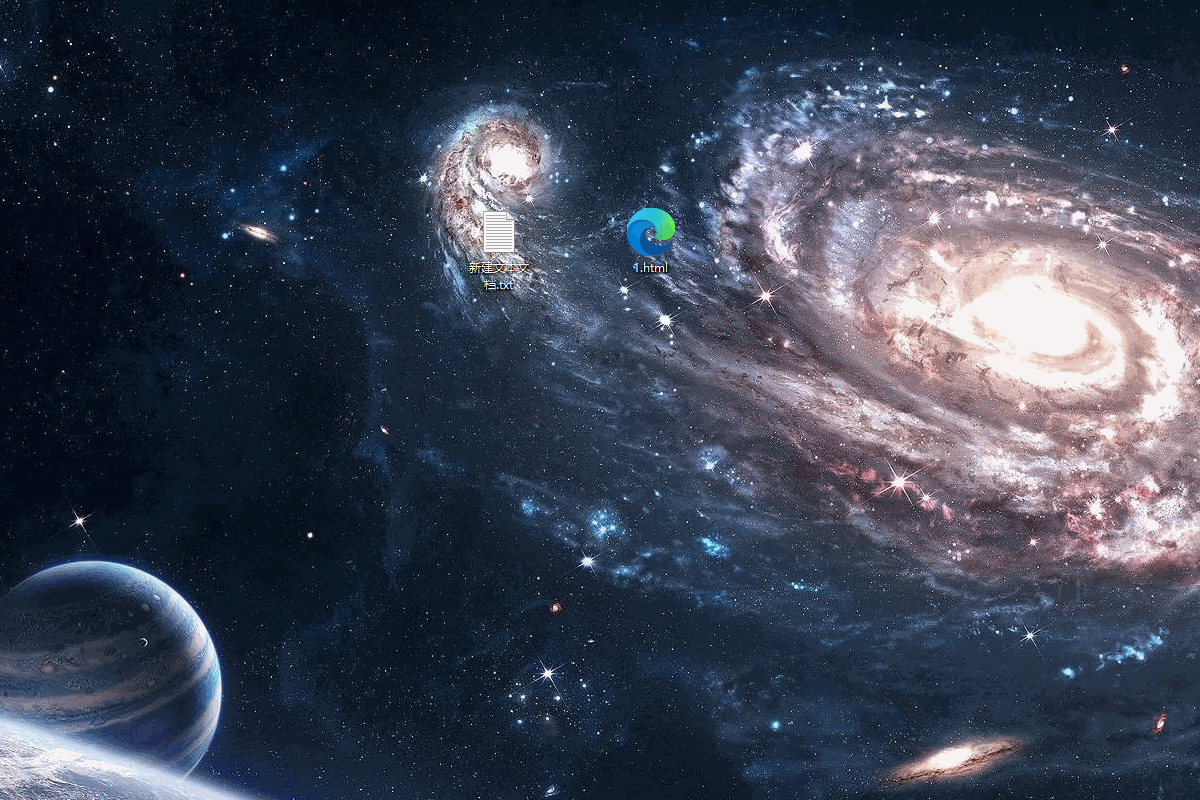
2.然后启动云采集查看云采集数据,将采集到的源码复制粘贴到txt文件,然后另存为.html文件。

3.将另存的.html文件在浏览器中打开查看,如下图2所示:

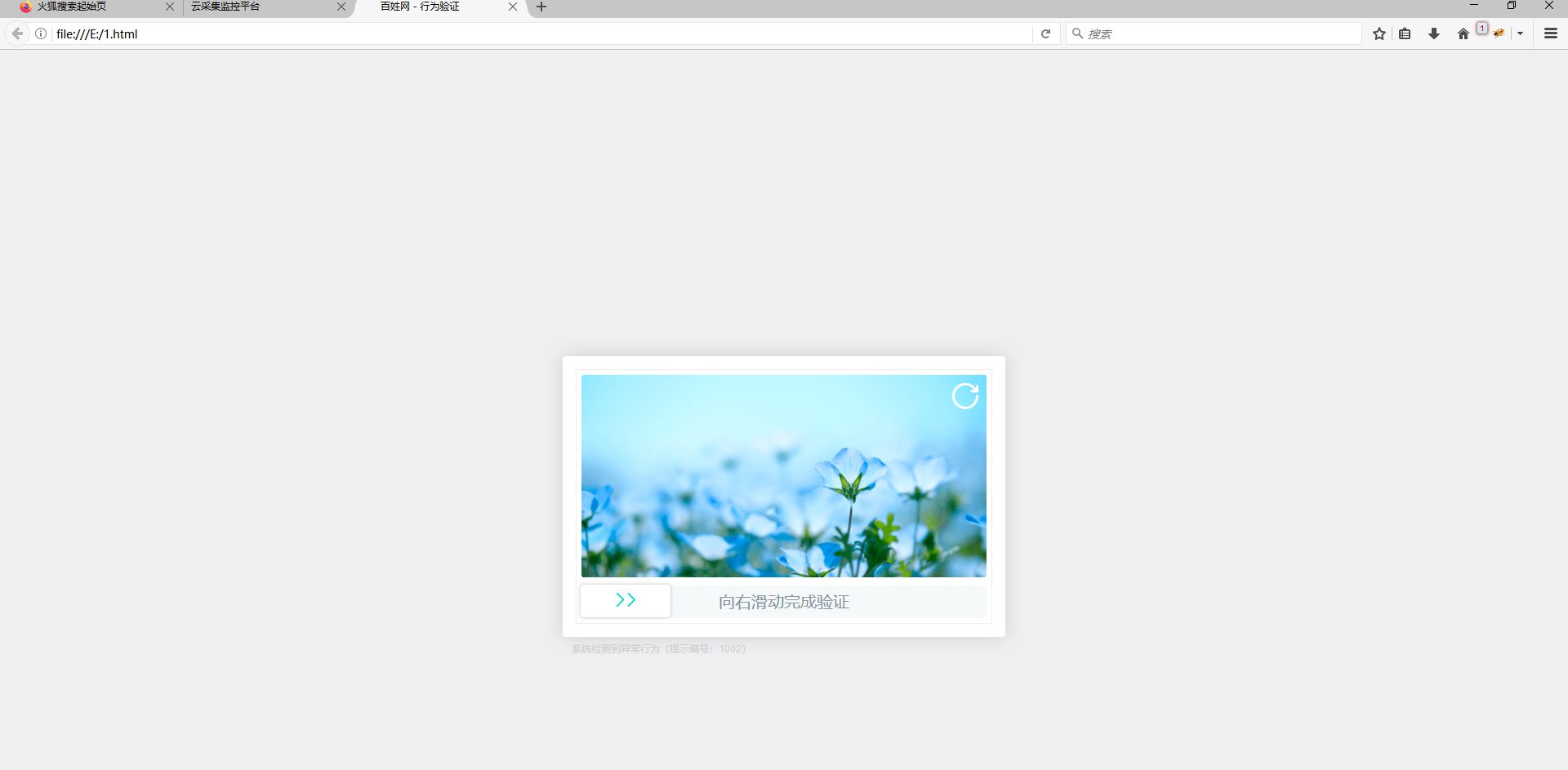
图2 浏览器中查看.html文件
通过采集的源码在浏览器中打开可以查看到,云上采集的时候出现的滑块验证,从而导致采集不到数据,滑块的验证码目前无法自动验证。如果是字母+数字类型的验证码,可以设置自动打码。支持自动打码的类型
如果是IP被封禁止访问、云上需要登录的情况,也可以通过以上方法采集网页源码后在浏览器里查看可以查看到。如果是需要登录则在规则里设置登录,ip被封可以尝试设置切换ip尝试采集。
二、网站或网速原因
知识补充如果一点网站未完全打开,则显示如图3红线处:

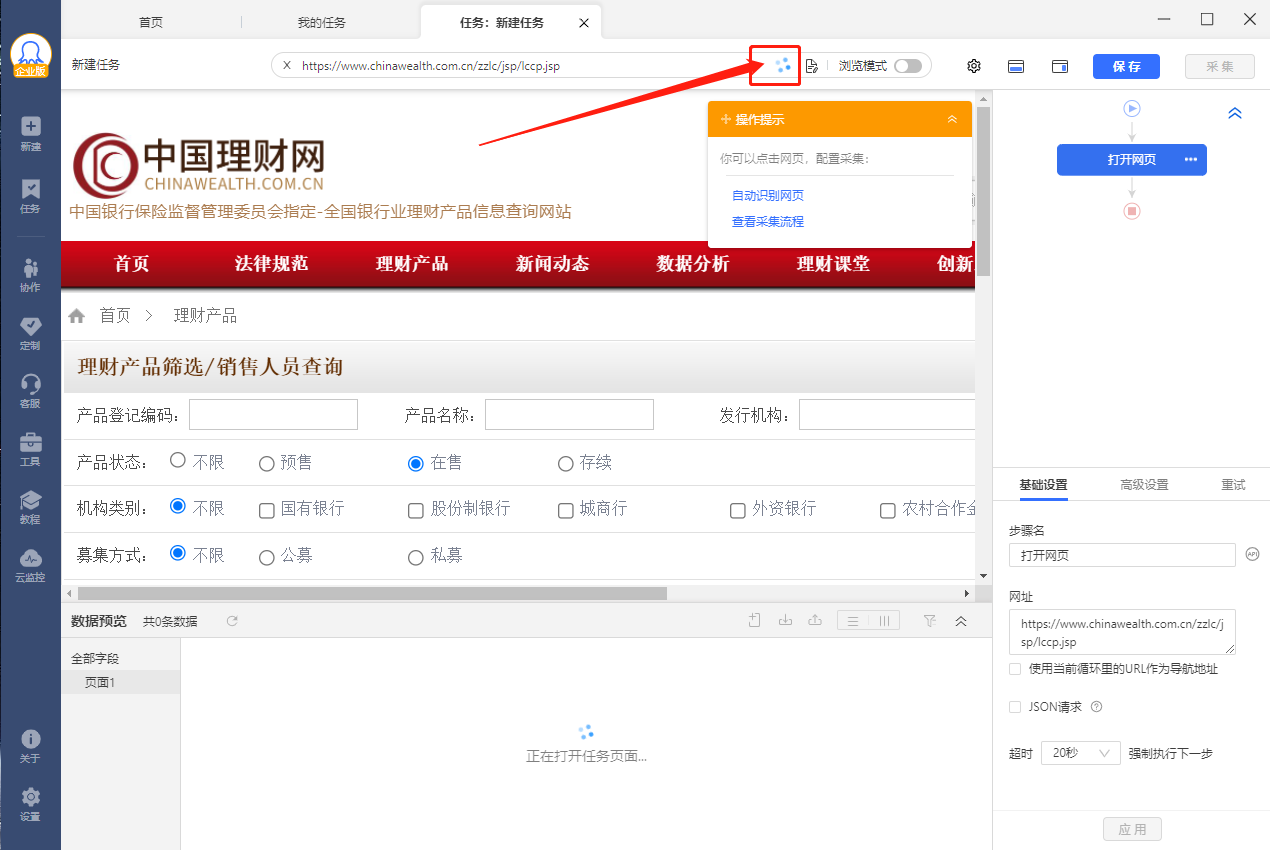
图3 未完全打开的网页
如上图,我们可以明显看到,网站网页URL明显有红框处在转的图标:
一个完全打开的网站,应该如图4所示:

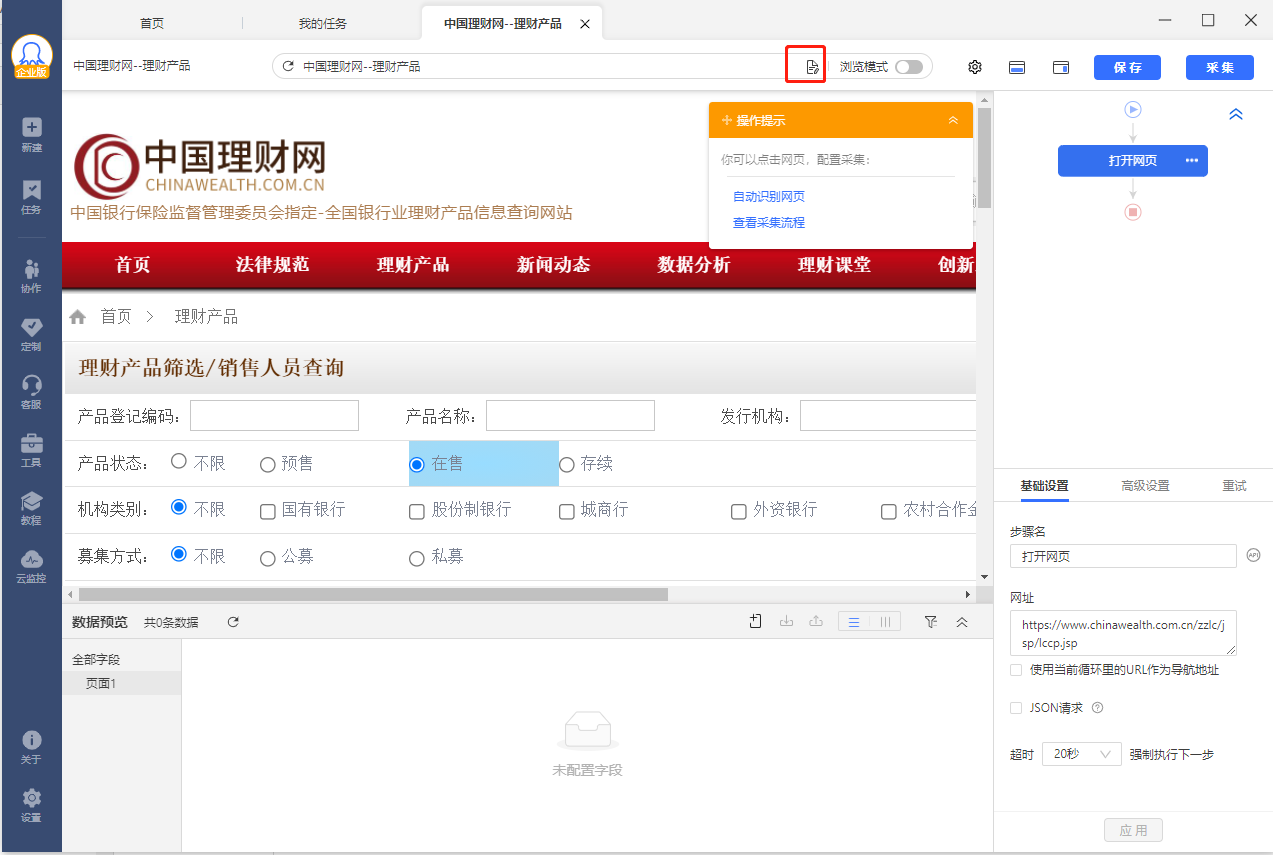
图4 完全打开的网页
有时候一个网页,即便完全打开了,列表数据也要延迟几秒才能加载出来,如图5所示:


图5 网页完全打开数据列表数据没有完全加载
如图红框1,网页已经处于完全打开状态,但是红框2的列表数据还没有加载出来,在八爪鱼中,如果一个操作已经完全执行完成(例如:网页完全打开),那么它会立即执行下一个操作步骤,但此时如图红框2,列表数据没有加载出来,所以执行失败,云采集没有数据。
解决措施:碰到这种因网速原因或者网站本身原因,导致数据加载过慢时,我们只需要做以下优化操作
规则优化可具体查看教程:如何优化规则采集更完整的数据
三、网络环境不同,源码有变,原xpath定位不准
部分网站在不同环境下打开网页源码会有变化,从而导致在本地采集是正常,但是在云上xpath定位不准导致采集不到数据。此类情况的解决办法如下:
1.用前面采集网页html源码的方法,采集网页的源码后保存为.html文件,然后再火狐浏览器中打开文件。
2.然后修改字段的xpath
这里修改xpath需要学习掌握xpath的知识
四、网站只允许单浏览器或单IP登录
网站只允许单浏览器或单IP登录,如果任务进行了拆分会导致云采集不到数据。解决的办法:设置云采集不拆分。

总结:以上就是我们云采集通用排错教程,仔细阅读并理解其原理能够帮我们更好的采集互联网公开数据
作者:Jeffrey
编辑:Jeffrey

文章评论