
采集场景
采集Amazon商品详情页数据。Amazon商品详情页实例网址:https://www.amazon.com/dp/B07R7DY911。
采集字段
title、brand、stars、ratings、questions、price、details、productdimensions、itemweight、shippingweight、asin、itemmodelnumber、bestsellerrank、stock 等。
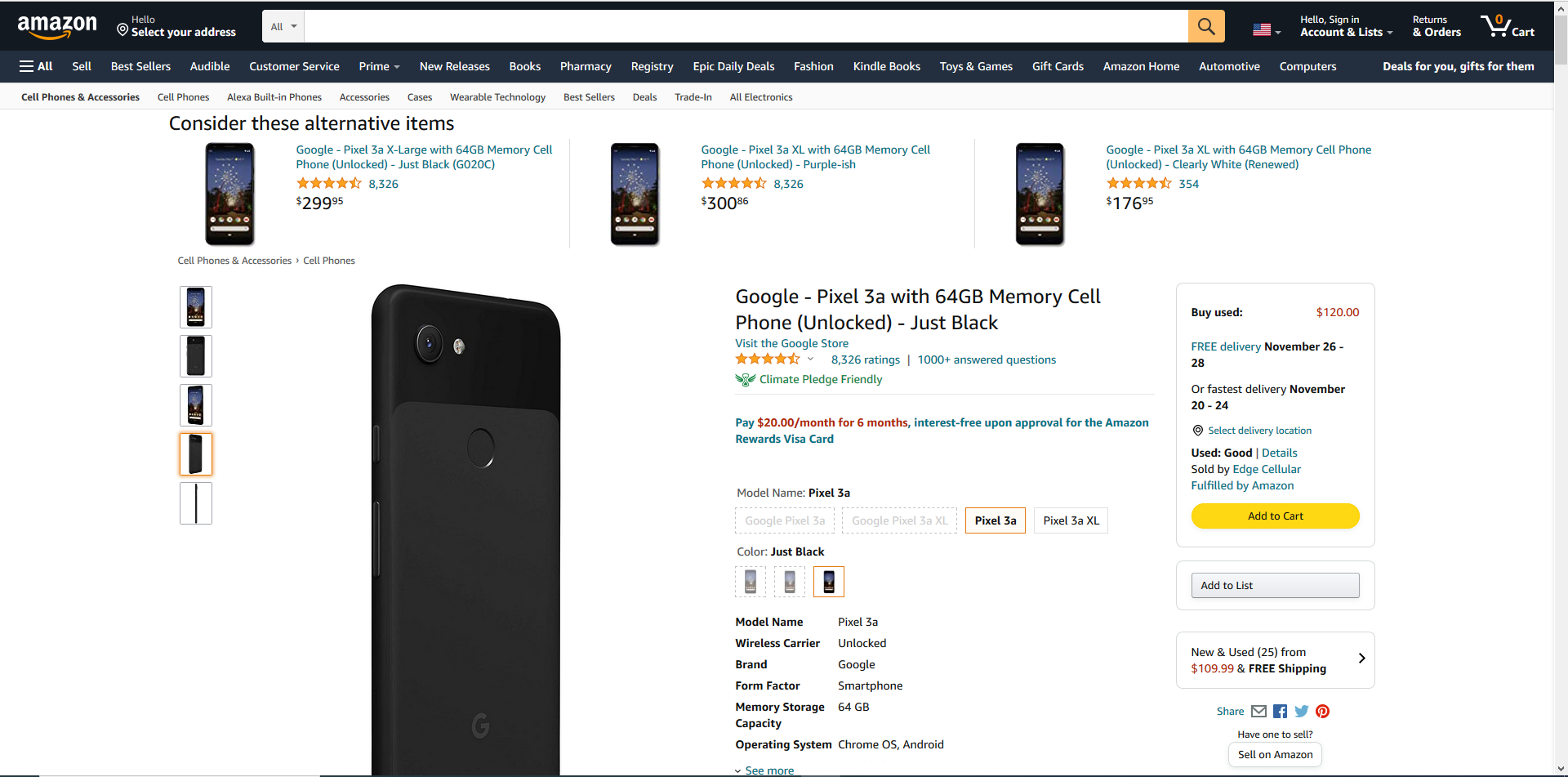
鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
采集结果
采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例:

教程说明
本篇更新时间:2021/10/25 八爪鱼版本:V8.4.2
如果因网页改版造成网址或步骤无效,无法采集到目标数据,请联系官方客服,我们将及时修正。
采集步骤
步骤一、打开网页
步骤二、选择配送地区
步骤三、创建【循环-打开网页】,以采集多个详情页数据
步骤四、采集详情页中的字段
步骤五、优化规则
步骤六、启动采集
示例网址:
https://www.amazon.com/dp/B07R7DY911
https://www.amazon.com/dp/B07PXGQC1Q
步骤一、打开网页
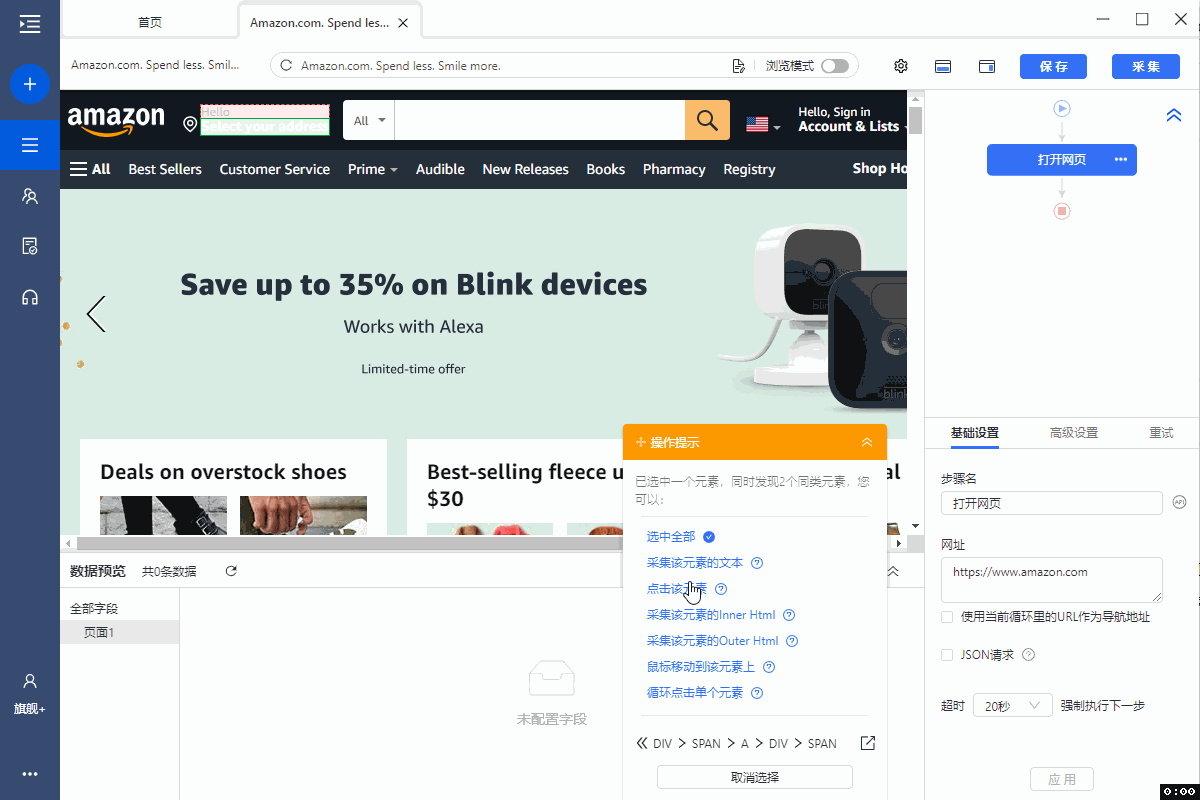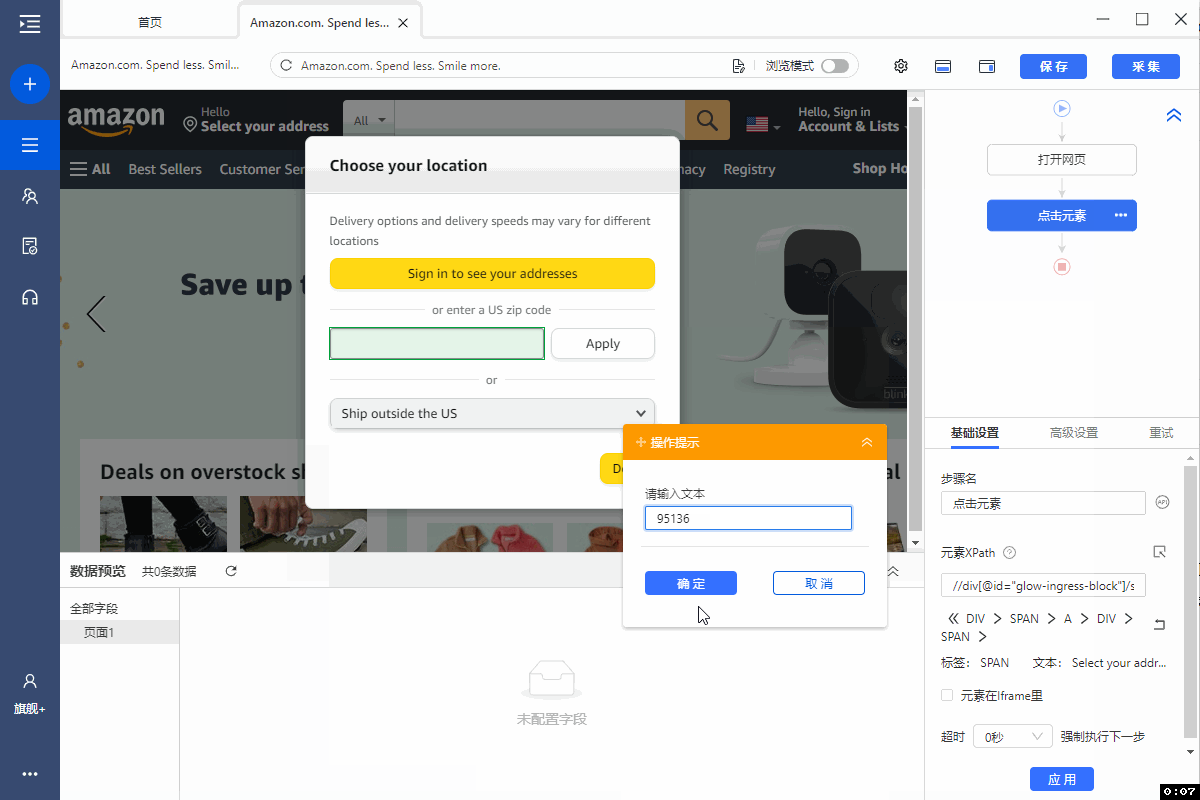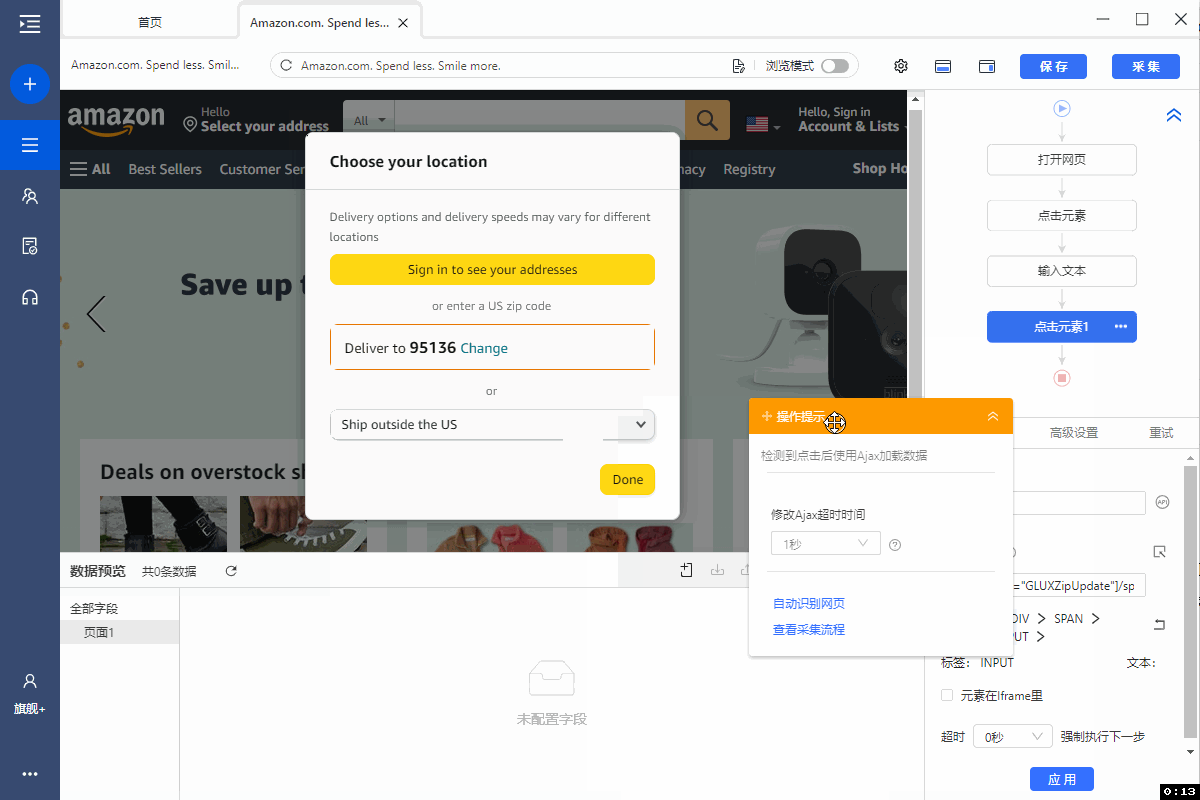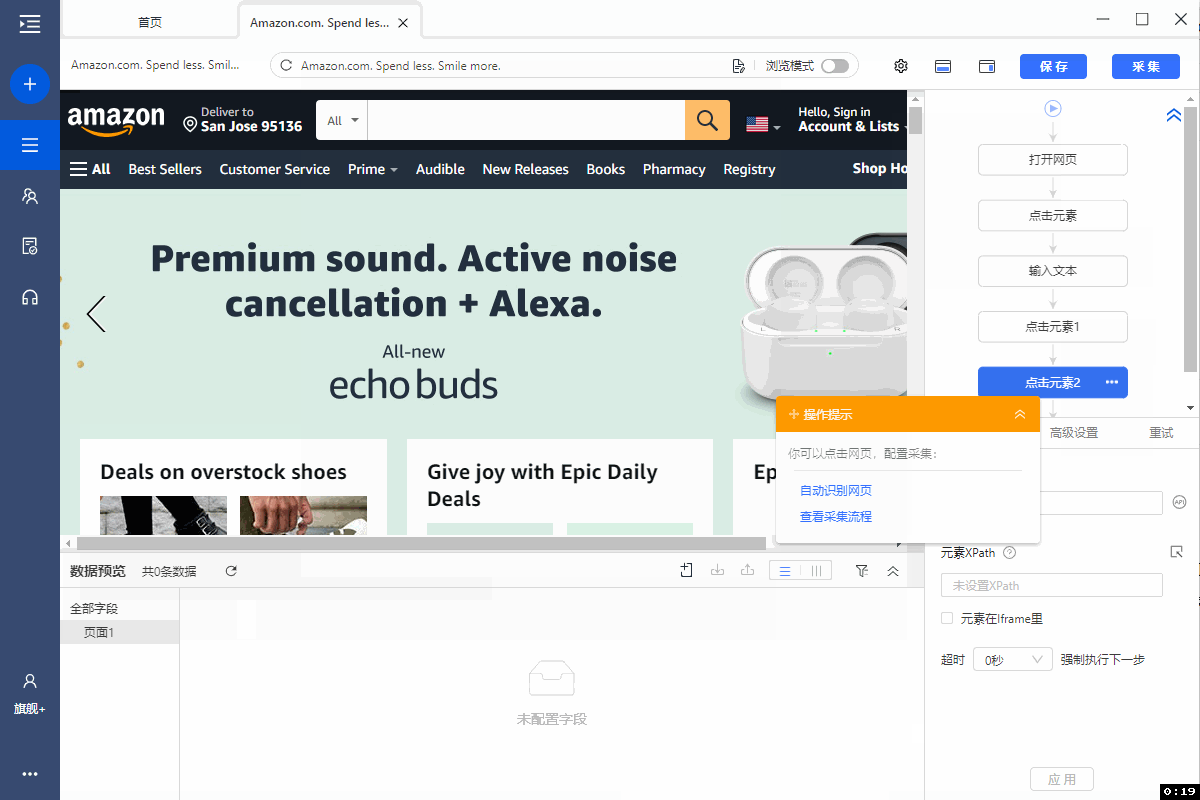
在首页输入框中,输入示例网址 https://www.amazon.com,然后点【开始采集】,八爪鱼自动打开网页。

步骤二、选择配送地区
在Amazon中,选择不同的配送地址,输入关键词搜索后得到的商品列表是不一样的。
示例中打开网页后,没有默认的配送地址为【中国大陆】。客户端如果有默认配送地址,且默认配送地址满足采集需求,可跳过此步骤。
如果需要修改配送地址,Amazon支持通过【登录账户并确认地址簿】、【输入美国邮政编码】和【选择美国境外其他国家】修改配送地址。
本文以【输入美国邮政编码】为例,输入 California (CA)的邮政编码:95136。具体操作如下:
1、在页面中选中【Select your Address】,在操作提示框中点击【点击该元素】,页面弹出位置输入框
2、选中位置输入框,在操作提示框中点击【输入文本】
3、在操作提示框中输入【95136】后保存
4、选中【设置】按钮,在操作提示框中点击【点击该元素】
5、选中【完成】,在操作提示框中选择【点击该按钮】,完成配送地址的修改。
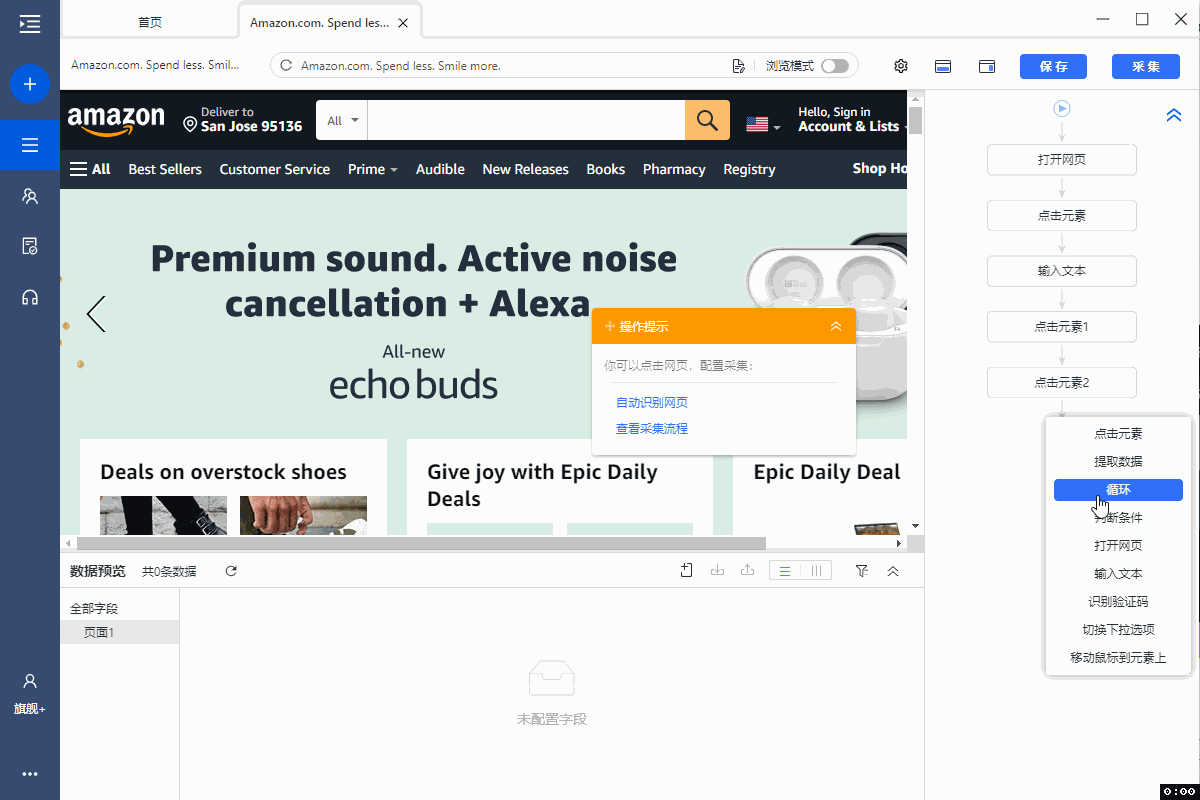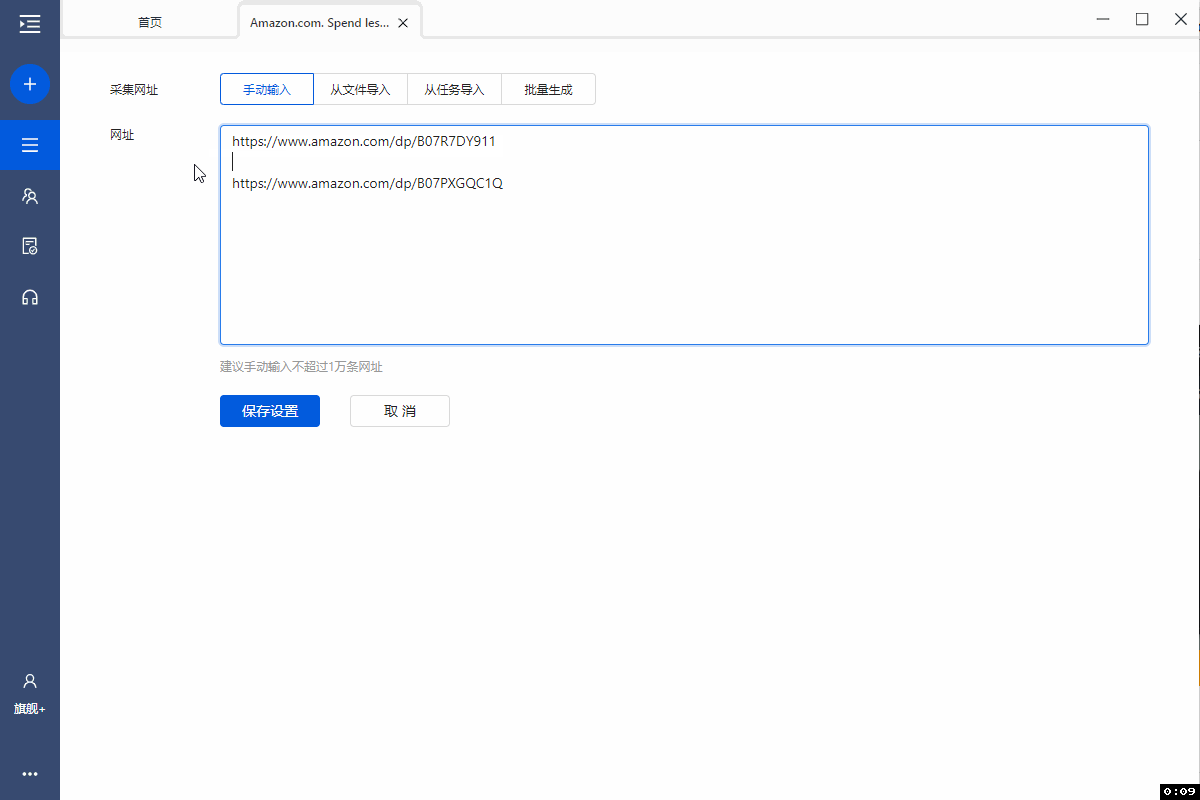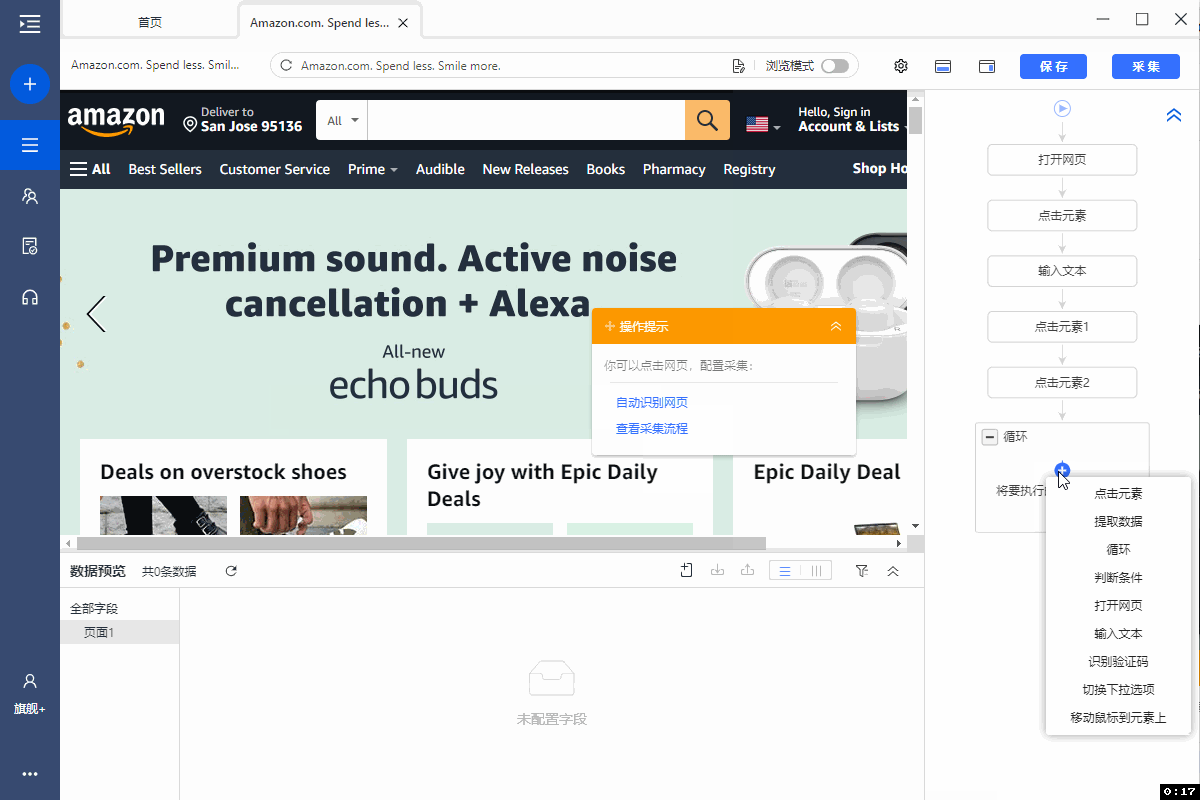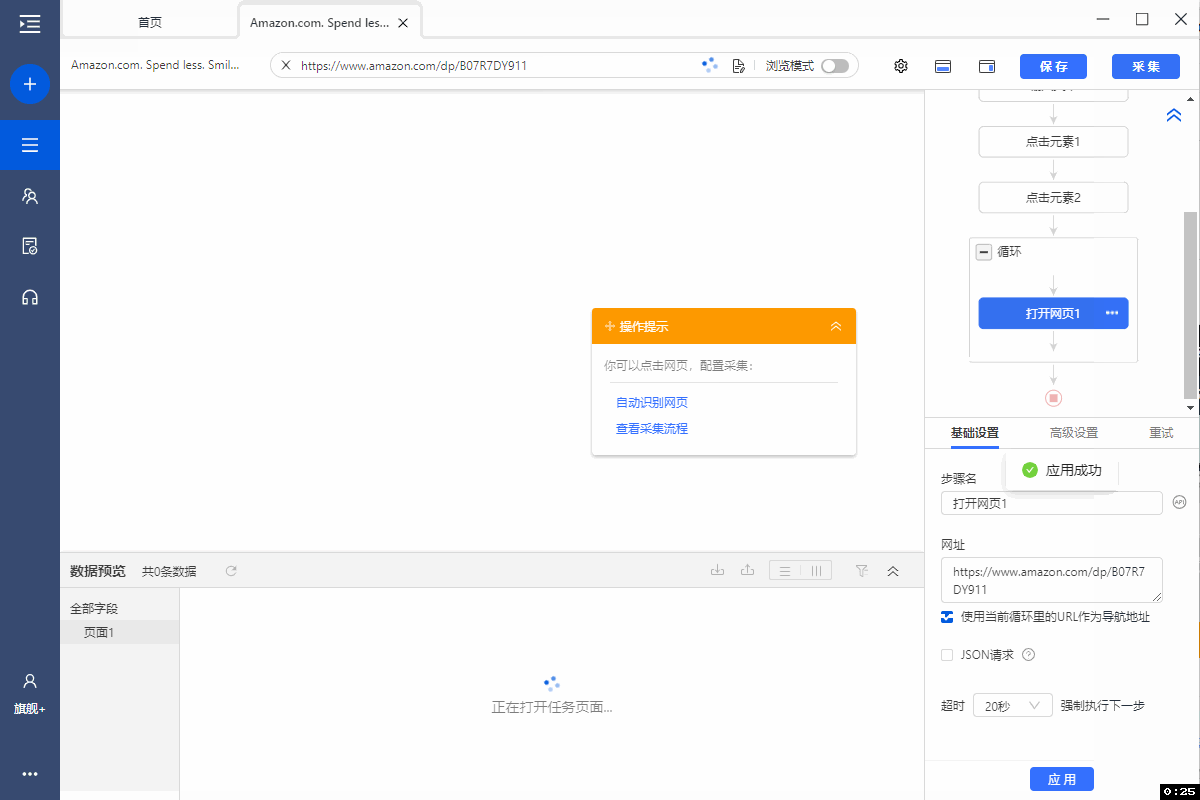
步骤三、创建【循环-打开网页】,以采集多个详情页数据
在【点击元素2】步骤后,添加一个【循环】。
进入【循环】设置页面。选择循环方式为【网址列表】,点击  按钮,将我们准备好的网址(可同时输入多个关键字,一行一个即可)后保存。
按钮,将我们准备好的网址(可同时输入多个关键字,一行一个即可)后保存。
步骤四、采集详情页中的字段
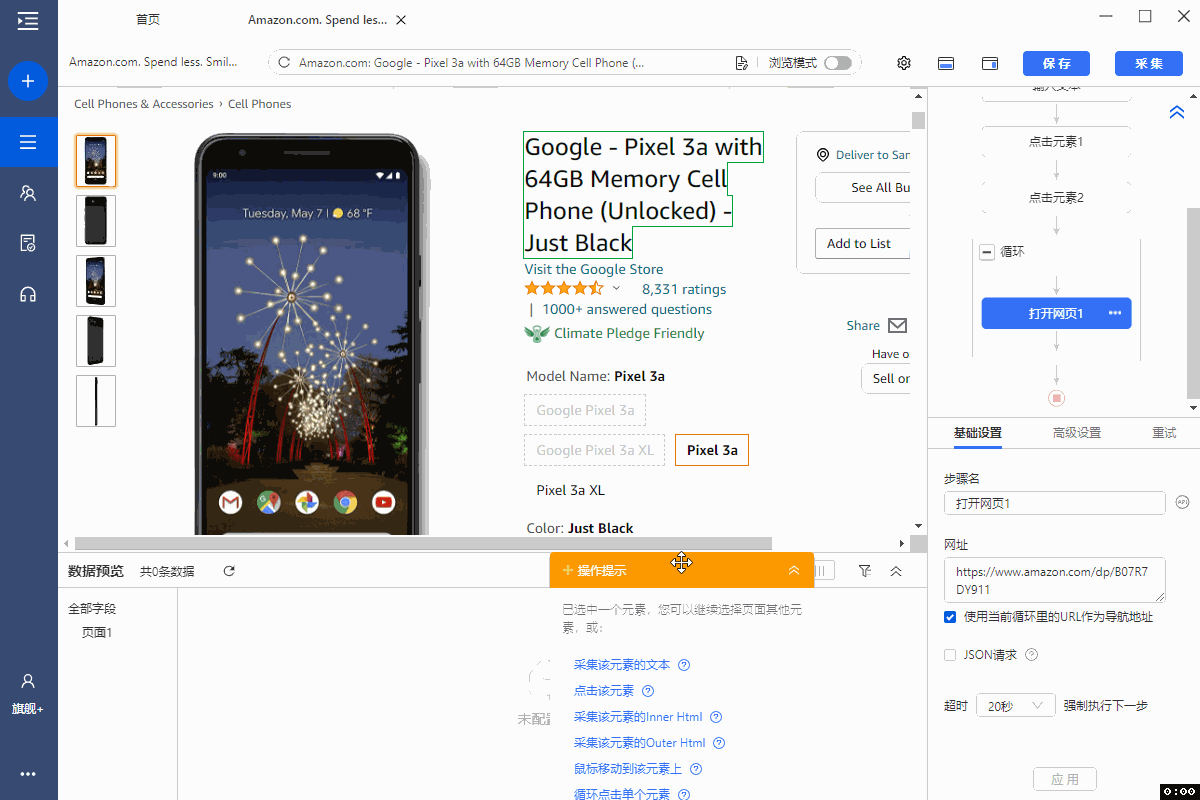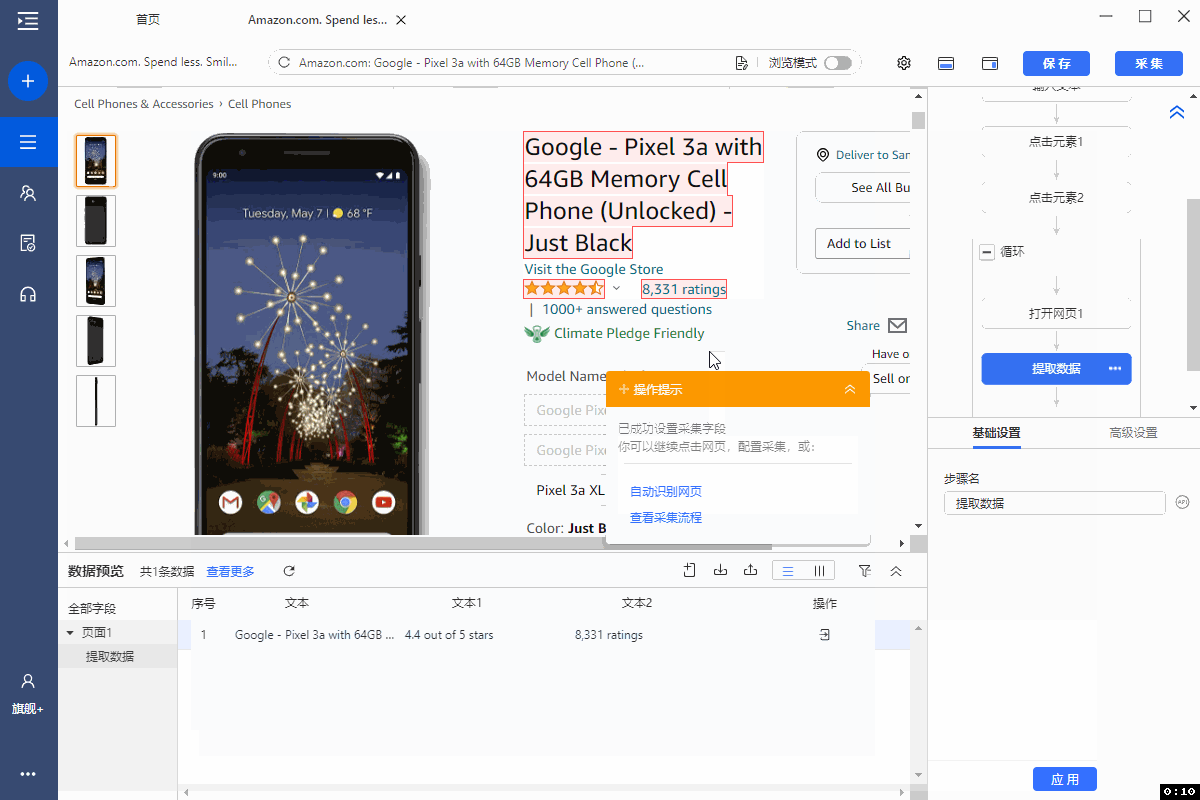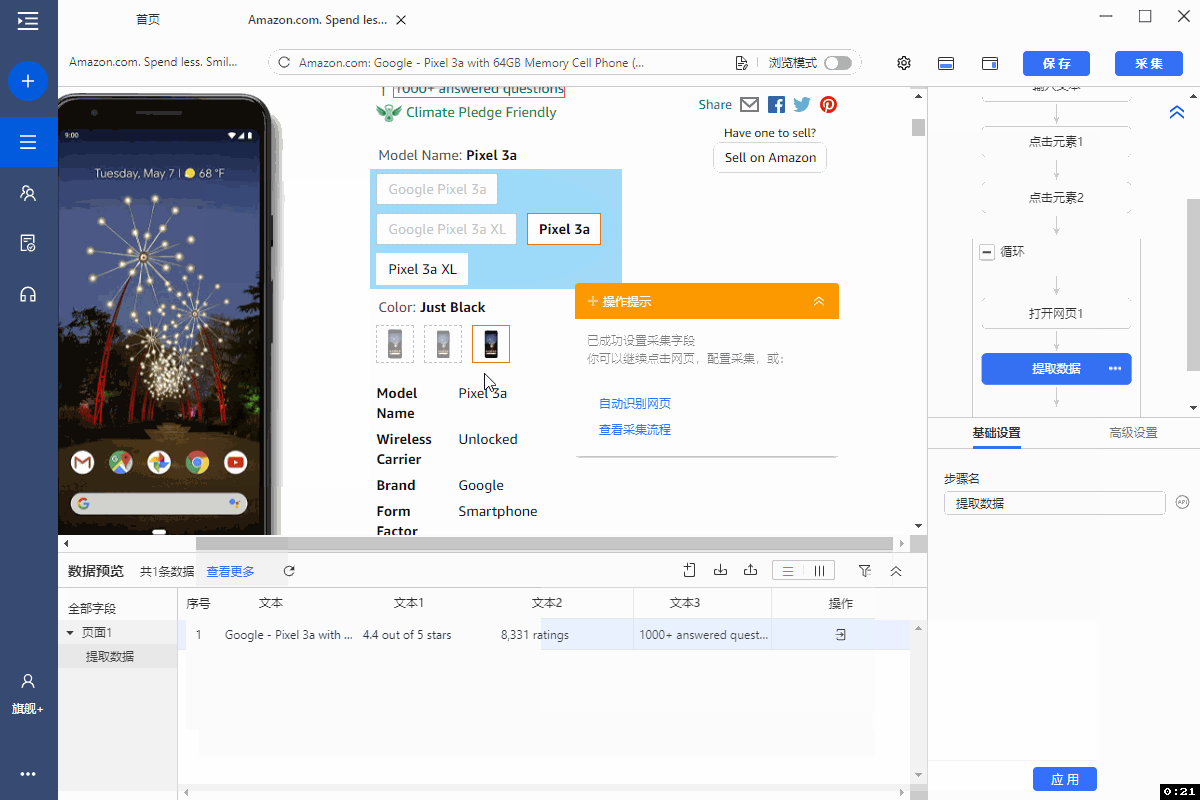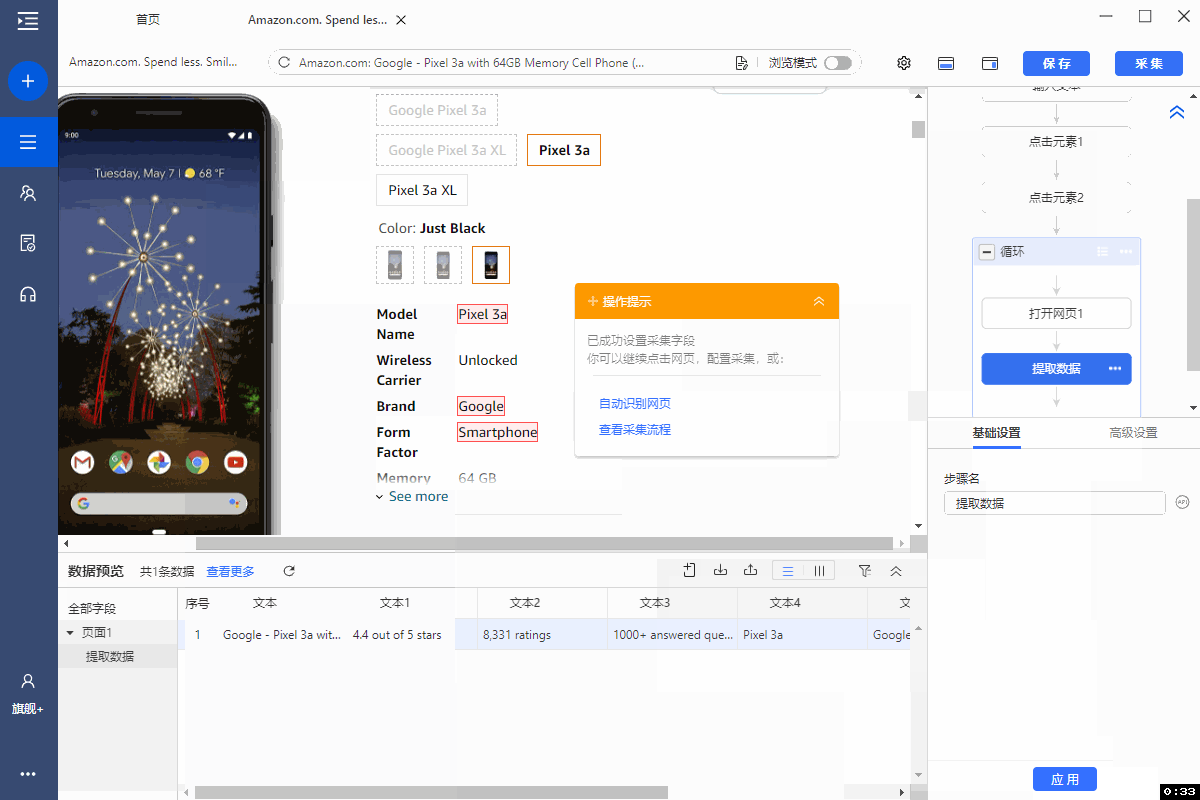
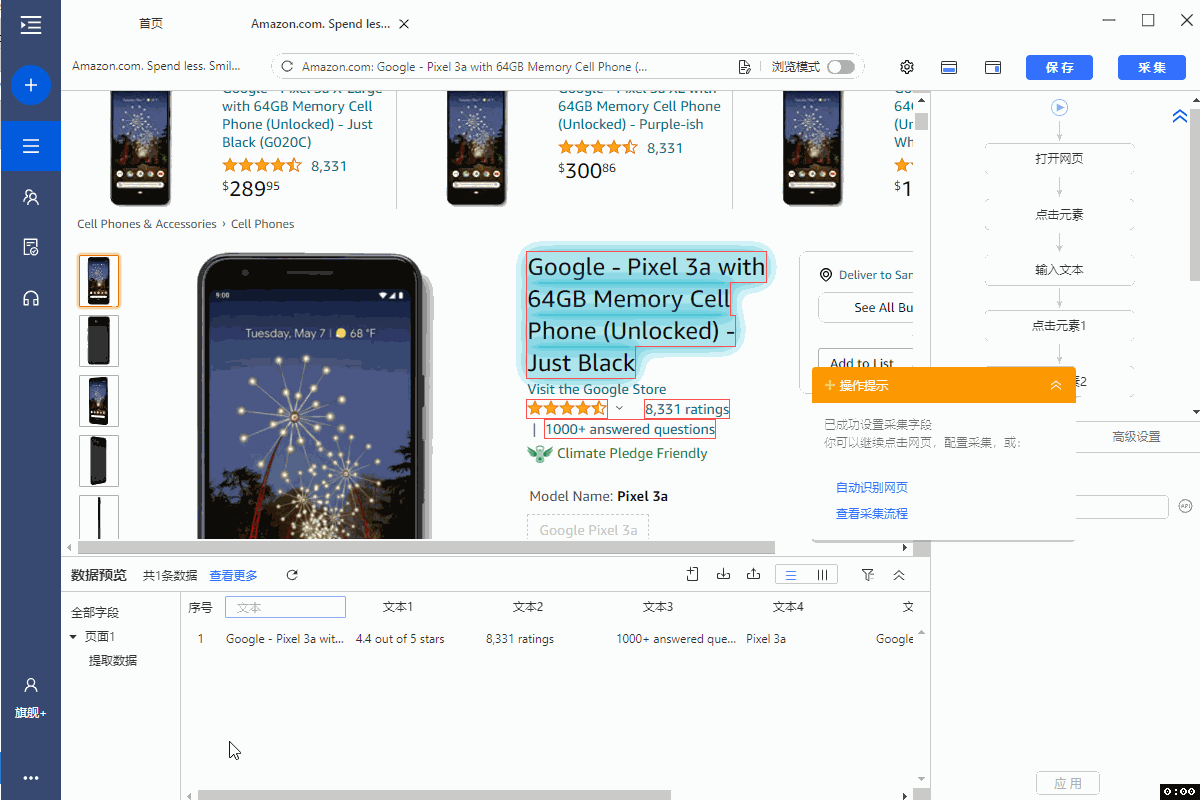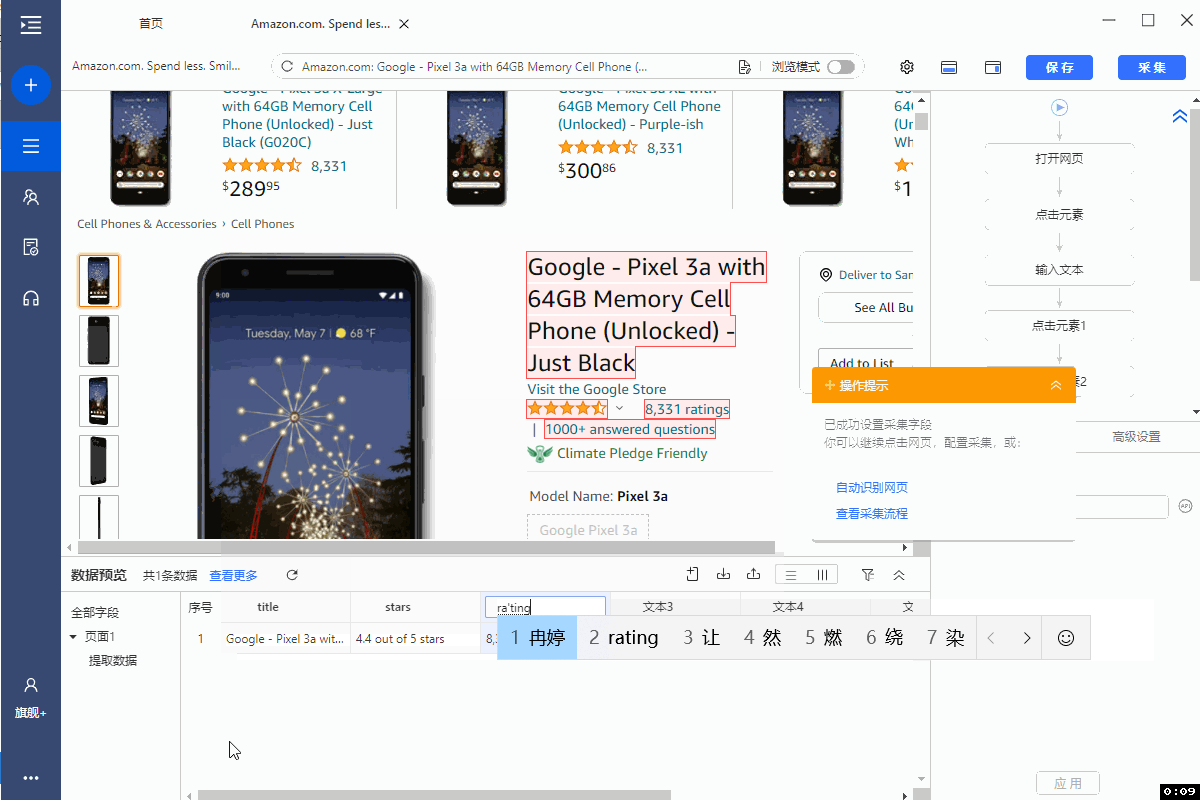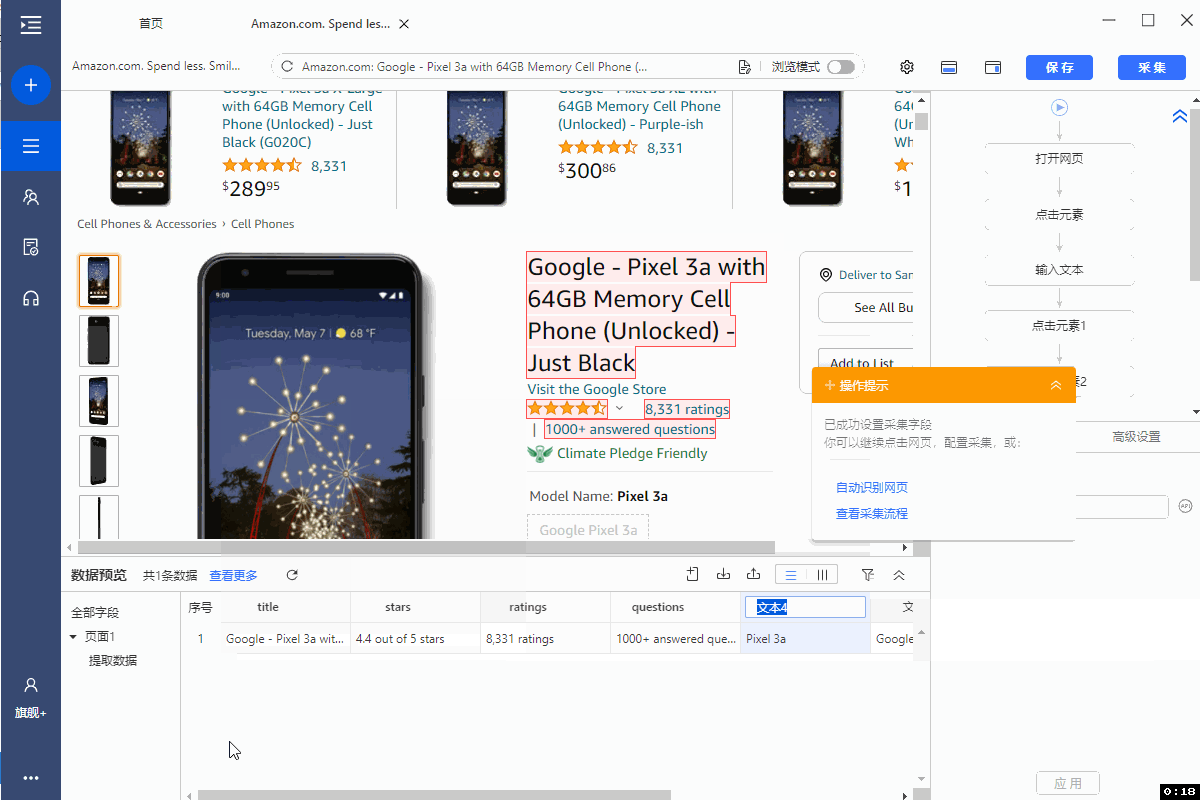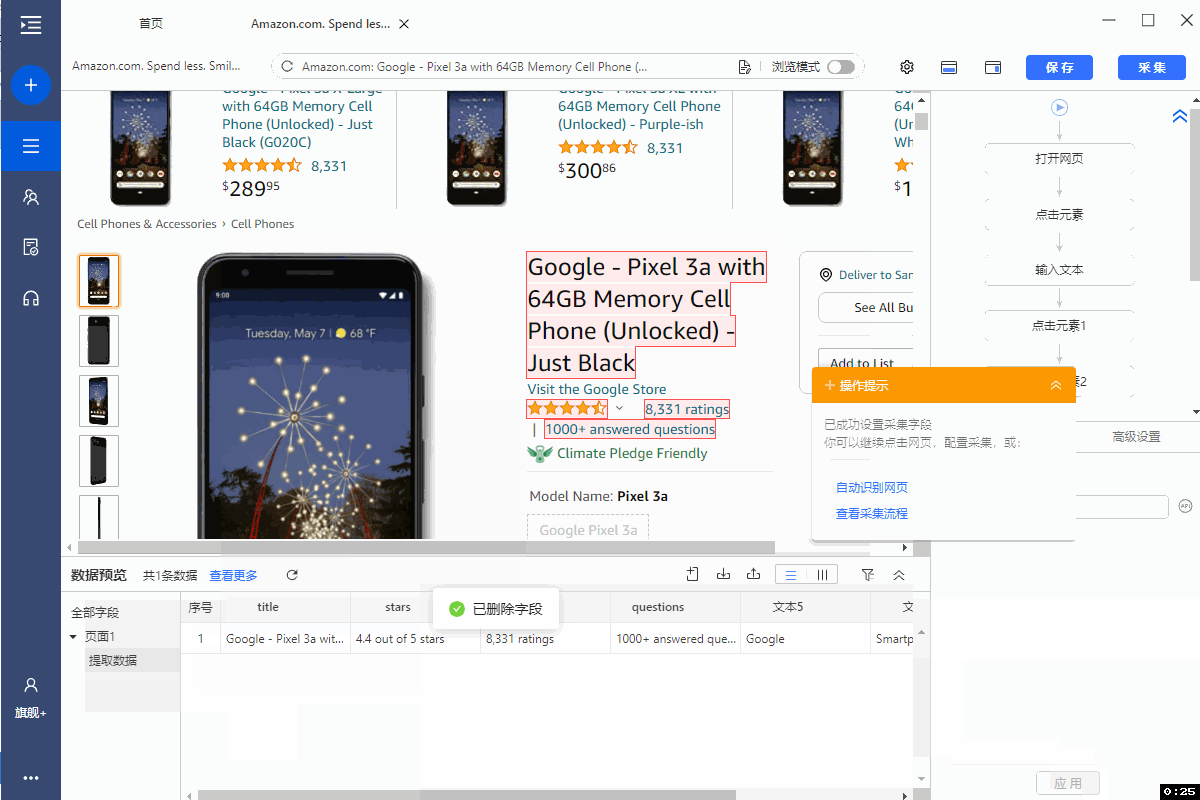
1、采集字段
选中网页中的目标字段,在操作提示框中点击【采集该元素的文本】。
所有文本类的字段都可这样提取,示例中提取了 title、brand、stars、ratings、questions、等。
2、编辑字段
在【当前页面数据预览】面板中,可删除多余字段,修改字段名,移动字段顺序等。
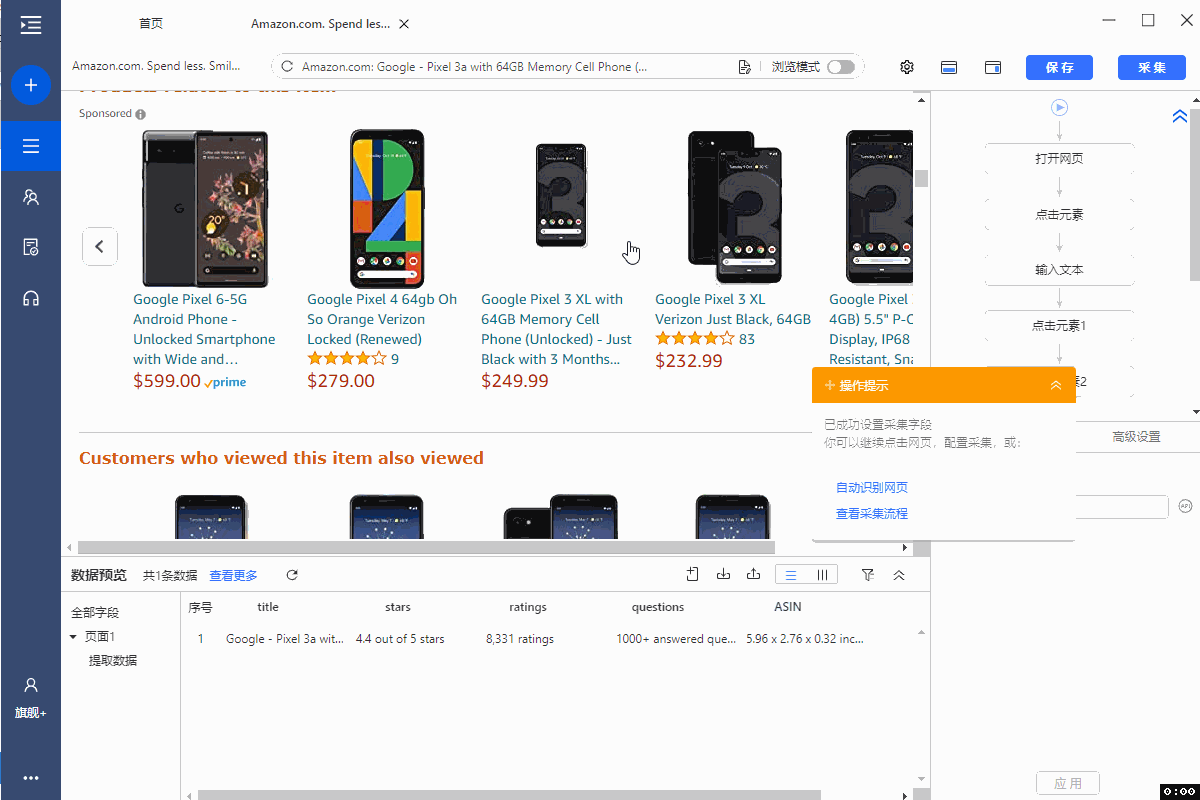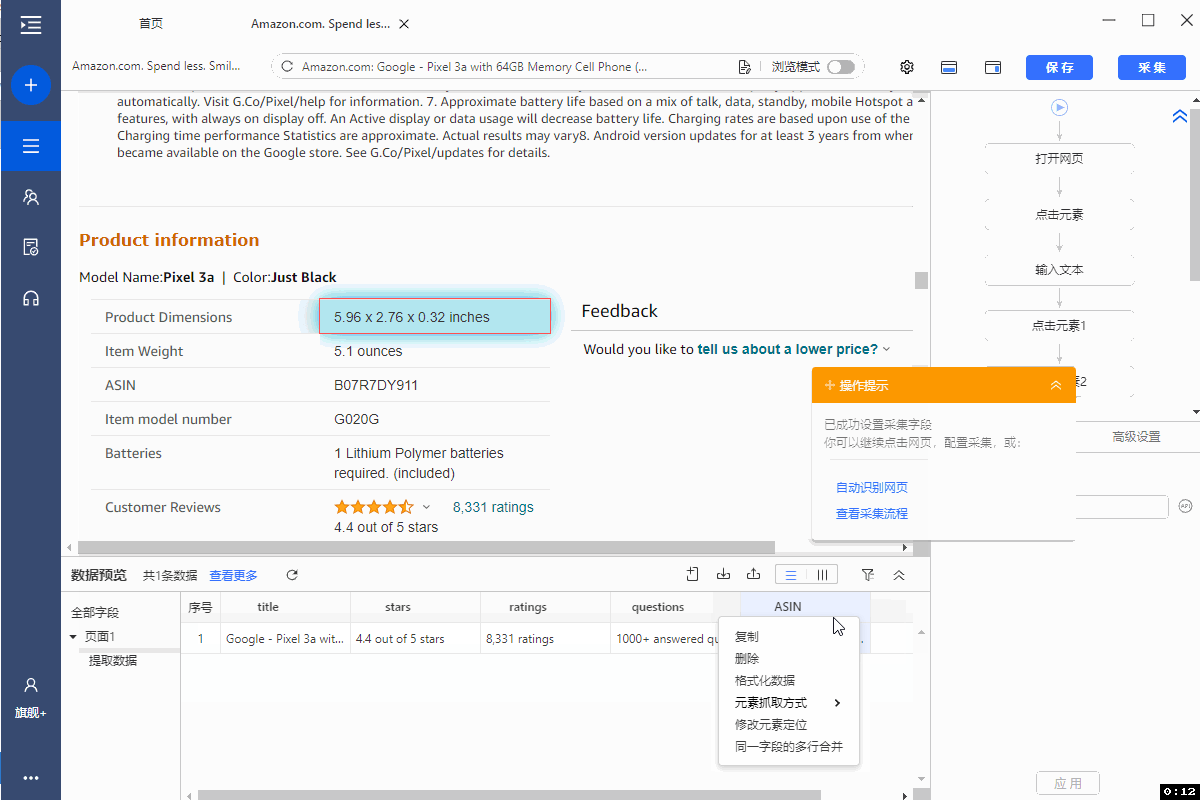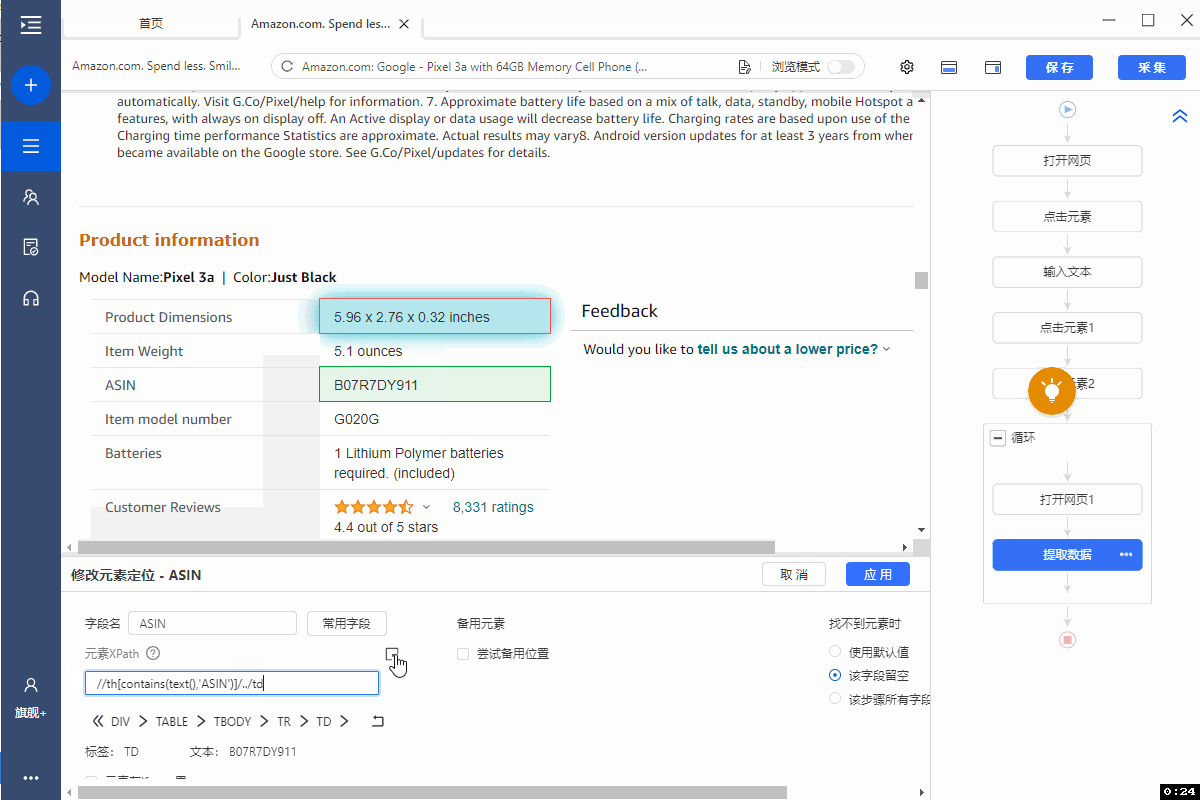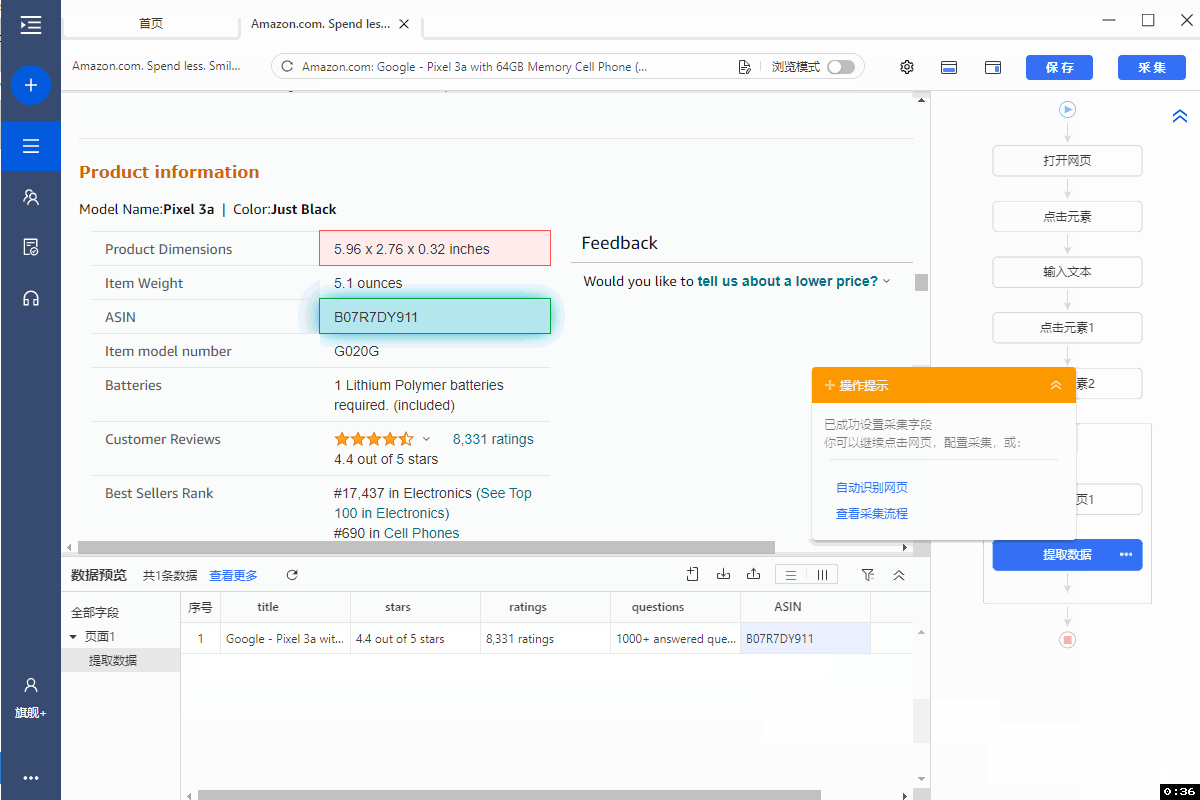
3、修改字段XPath
Product information栏目中的字段会出现数据错位,需手动修改字段XPath。以【asin】字段为例。
在该字段【...】,点击【修改元素定位】,修改XPath为://th[contains(text(),'ASIN')]/../td 。
特别说明:
a. 修改字段XPath,需要一定的XPath知识。点击查看 XPath学习与实例教程 。
b. 示例中以【asin】字段为例进行修改。其他字段的修改方法是类似的:
【itemModelNumber】XPath : //th[contains(text(),'Item model number')]/../td
【Best Sellers Rank】XPath: //th[contains(text(),'Best Sellers Rank')]/../td
【Shipping Weight】XPath: //th[contains(text(),'Shipping Weight')]/../td
【Product Dimensions】XPath: //th[contains(text(),'Product Dimensions')]/../td
【Item Weight】XPath : //th[contains(text(),'Item Weight')]/../td

文章评论