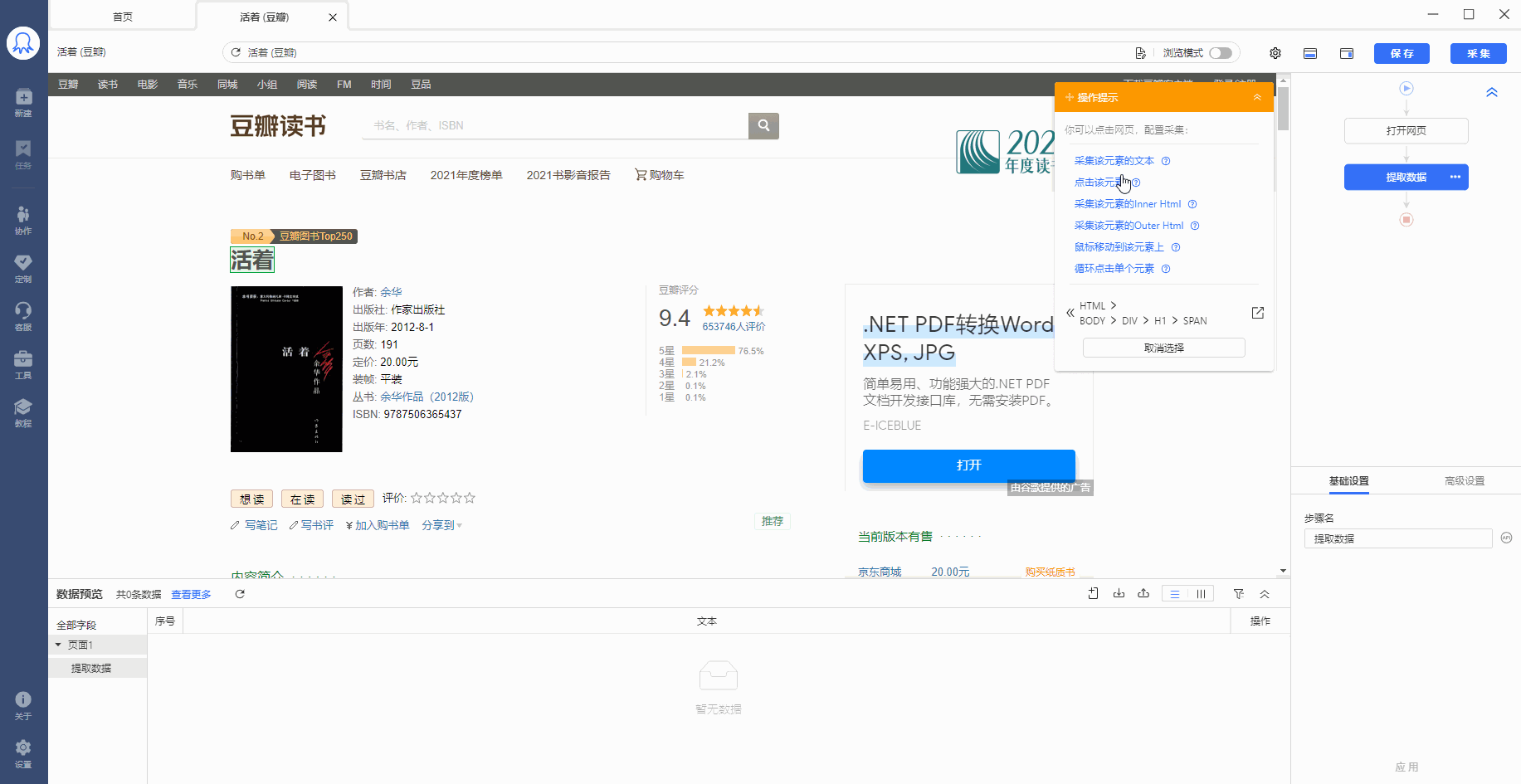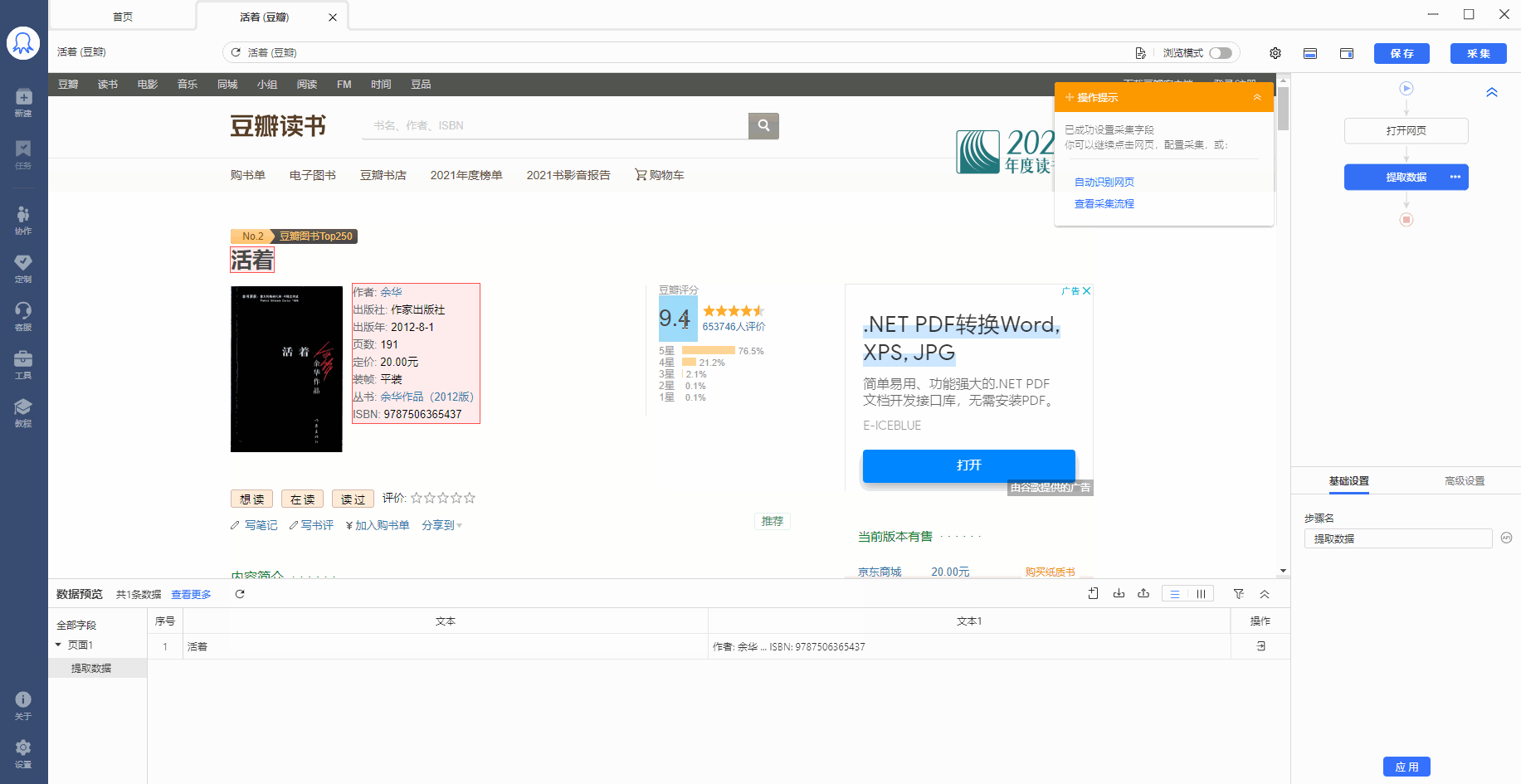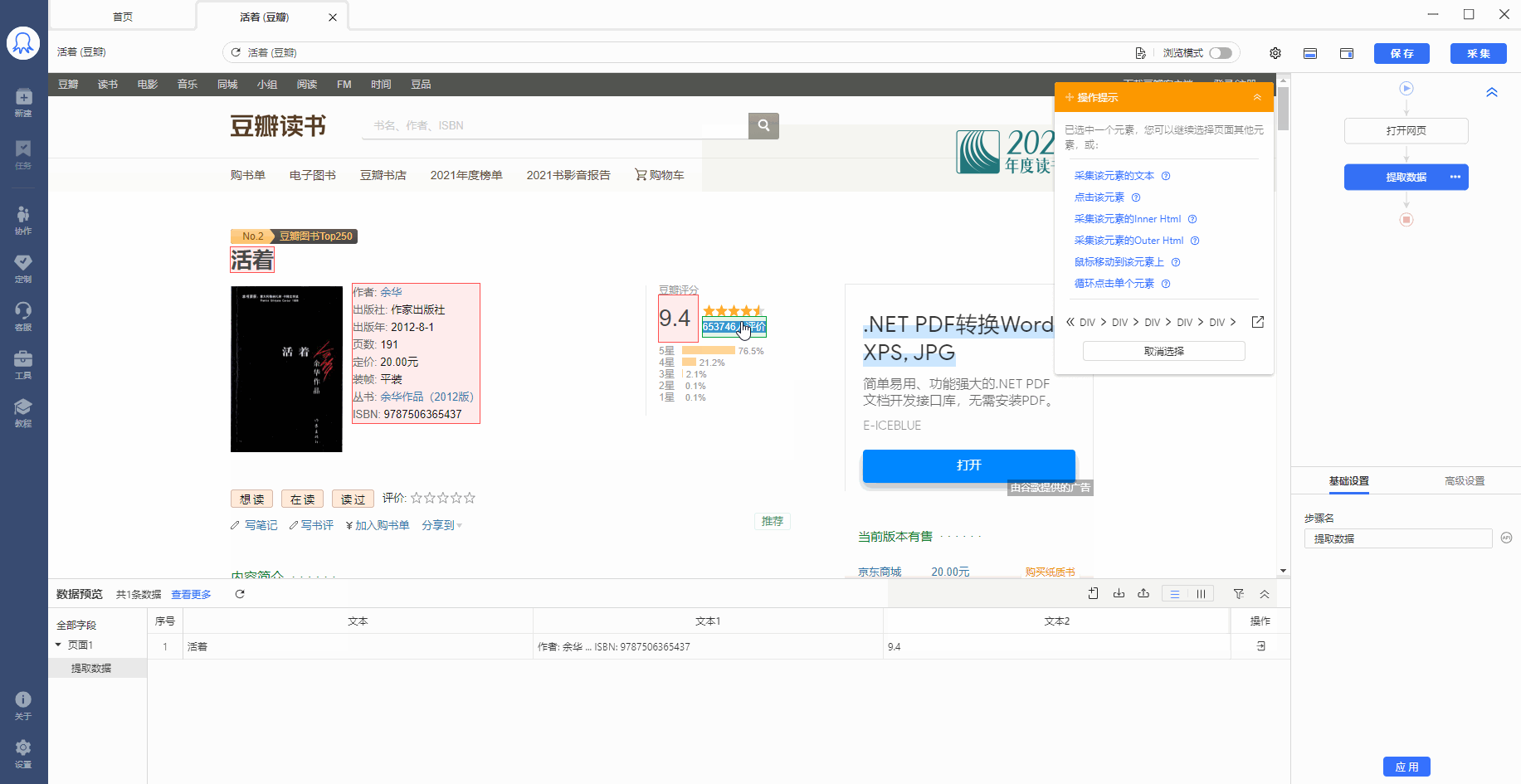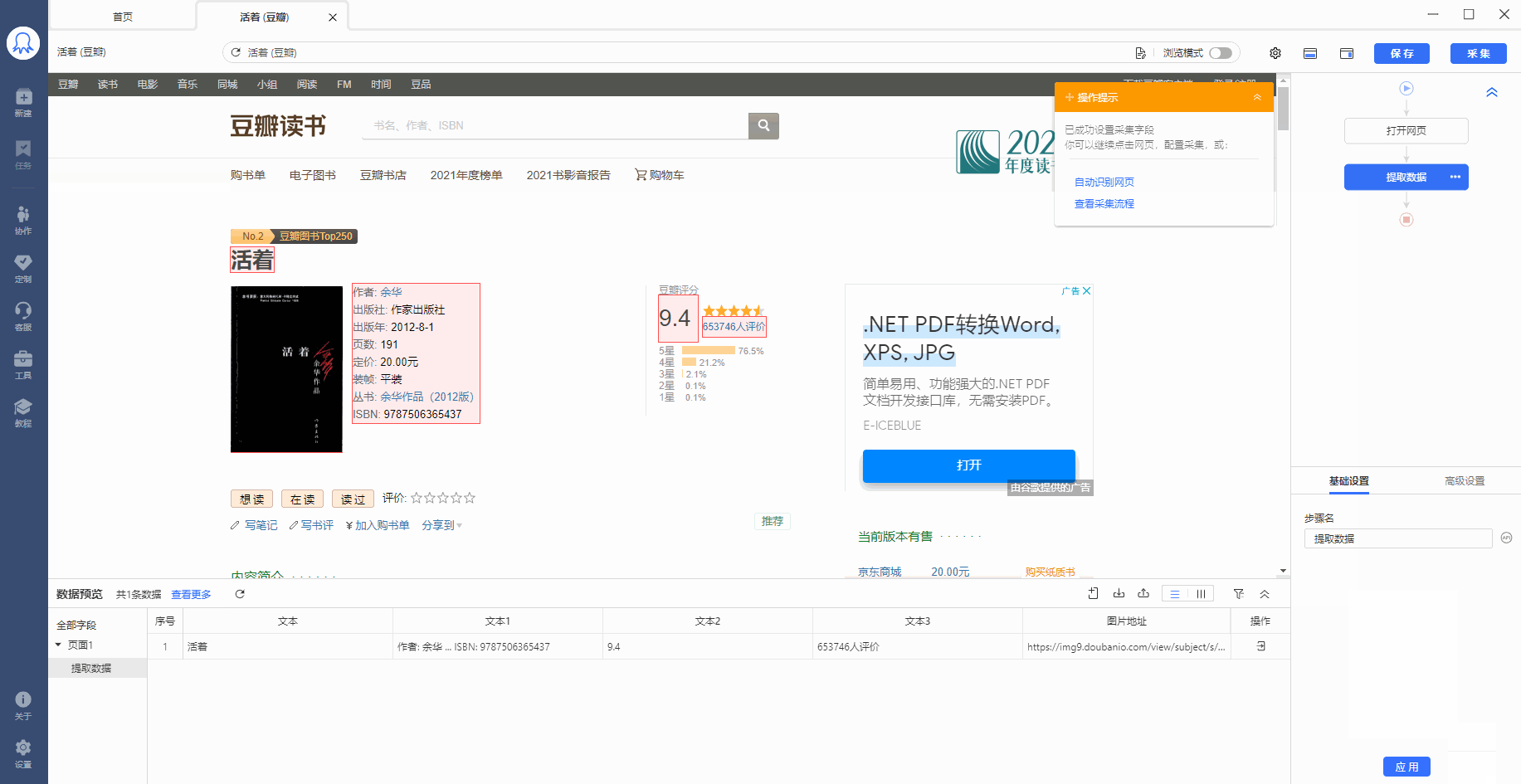
数据采集下来之后,有时候格式不是我们想要的,或者只想从一段数据里提取特定数据。以上需求,可通过八爪鱼的【格式化数据】功能实现。 本教程将结合实例,具体讲解。 一、【格式化数据】设置的位置 示例网址:https://book.douban.com/subject/4913064/ 【格式化数据】是对提取到的字段进行格式化操作,我们先按照采集需求,提取字段。本示例中,我们提取此网页中的图书标题、图书简介和图片网址。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 …
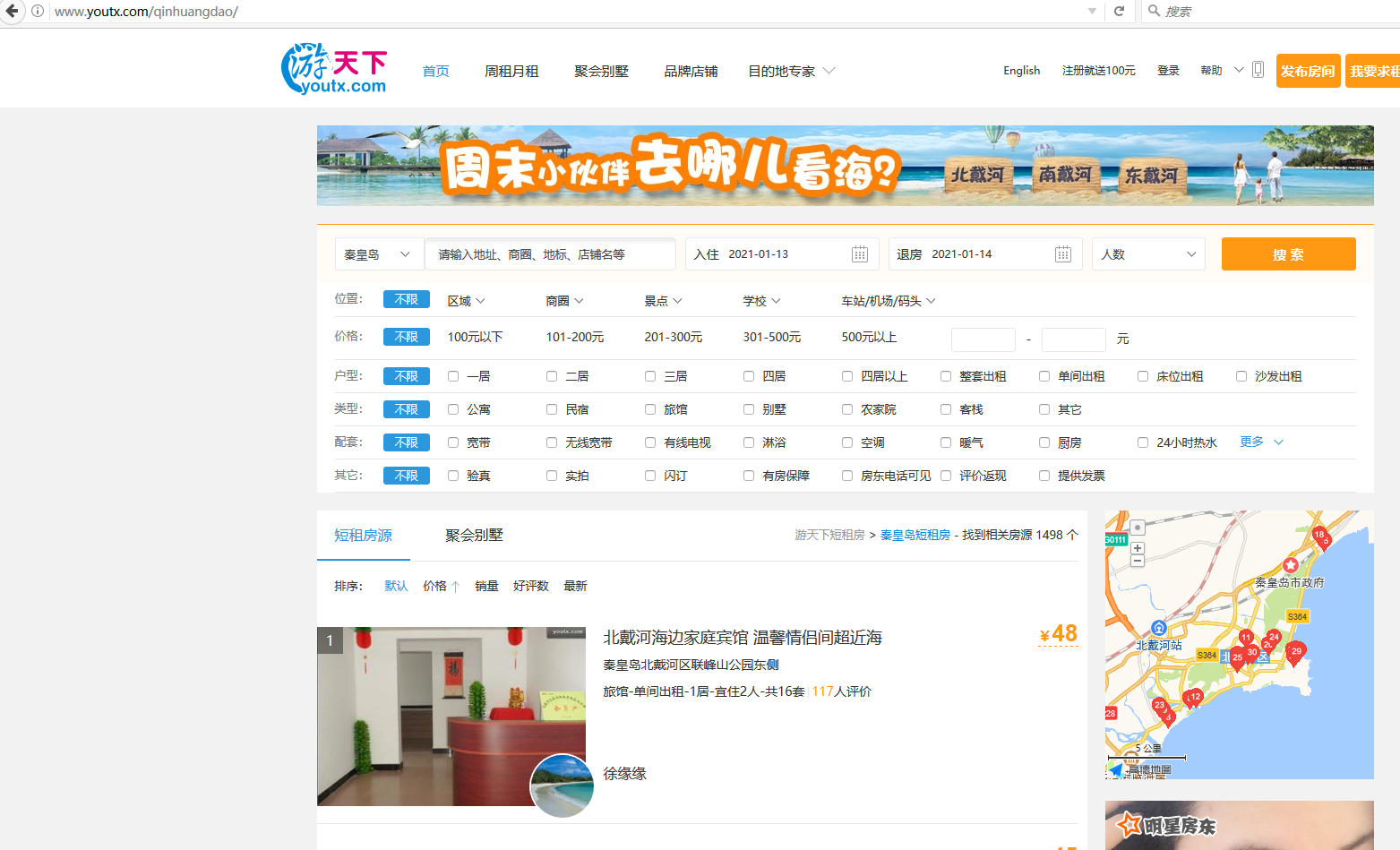
采集场景 采集采集游天下不同城市的租房信息。 采集字段 城市、标题、出租人、地址、价格、标题链接、坐标等。 点击图片可查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/06/20 八爪鱼版本:V8.5.2 目标数据,请联系官方客服,我们将及时修正。 采集步骤 步骤一、打开网页 步骤二、提取数据 步骤三、创建【循环列表】 步骤四、提取数据 步骤五、启动采集 以下…
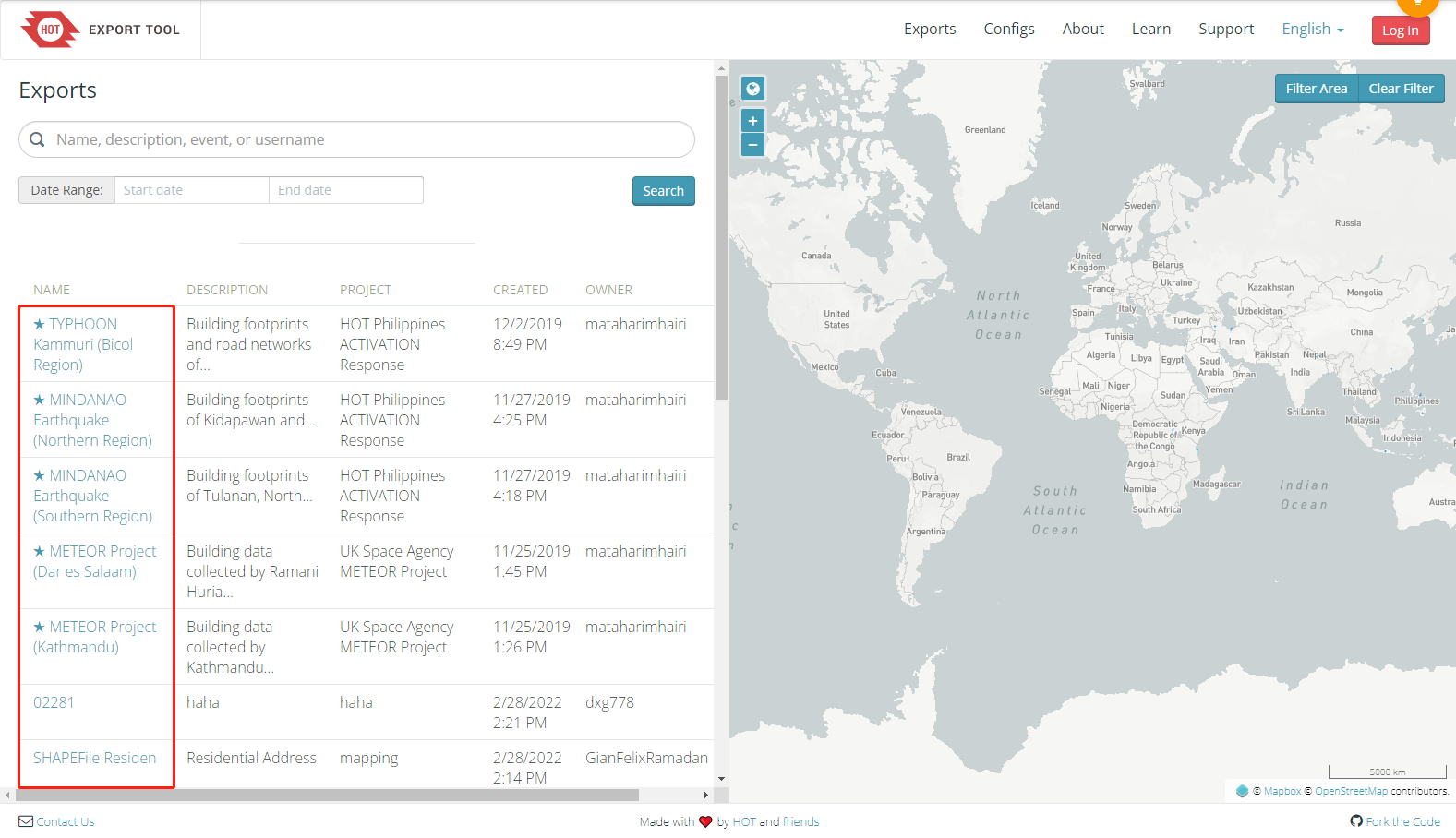
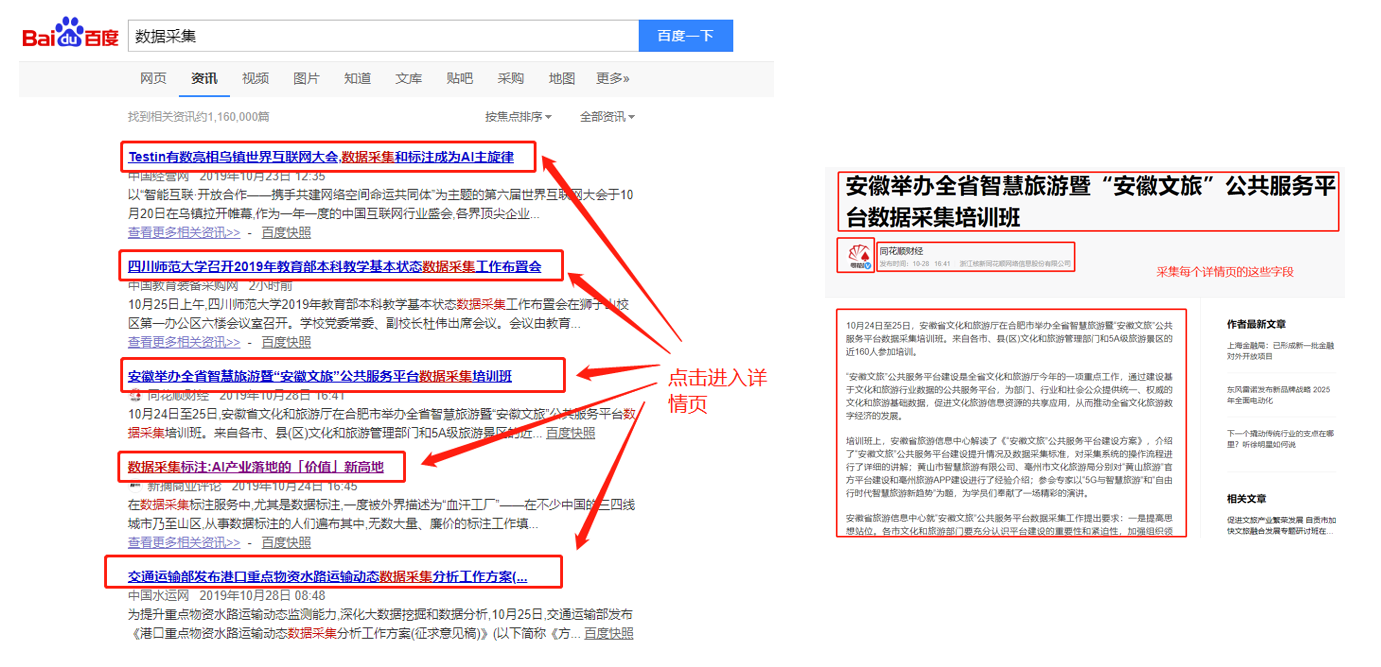
通过前几课的学习,我们已经学会了 采集列表数据、采集表格数据。如果一个页面上很多同类链接,需要依次点击每个链接进入详情页,然后采集每个详情页中的数据呢? 以百度百家号为例。现在有一个百家号资讯列表的网页:https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86&medium=2 可以看到,网页上有很多资讯链接,点击每个资讯链接进入详情页,每个详情页都有…
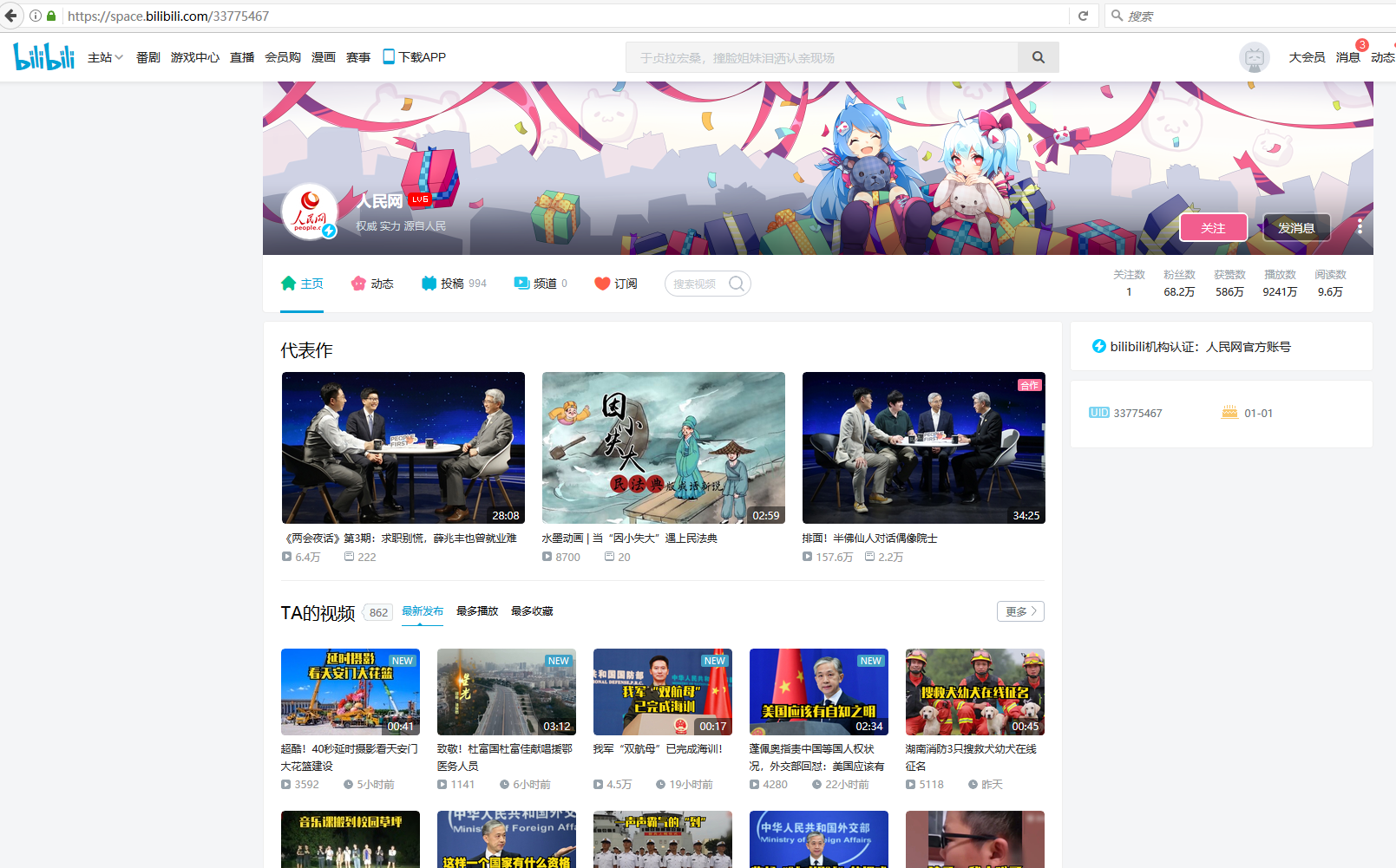
采集场景 采集B站UP主主页的视频列表数据。 示例网址: https://space.bilibili.com/33775467 https://space.bilibili.com/2282611 https://space.bilibili.com/21975459 采集字段 发布者、关注数、粉丝数、认证、UID、标题、视频连接、总播放数、发布时间、时长、视频封面链接 点击查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示…
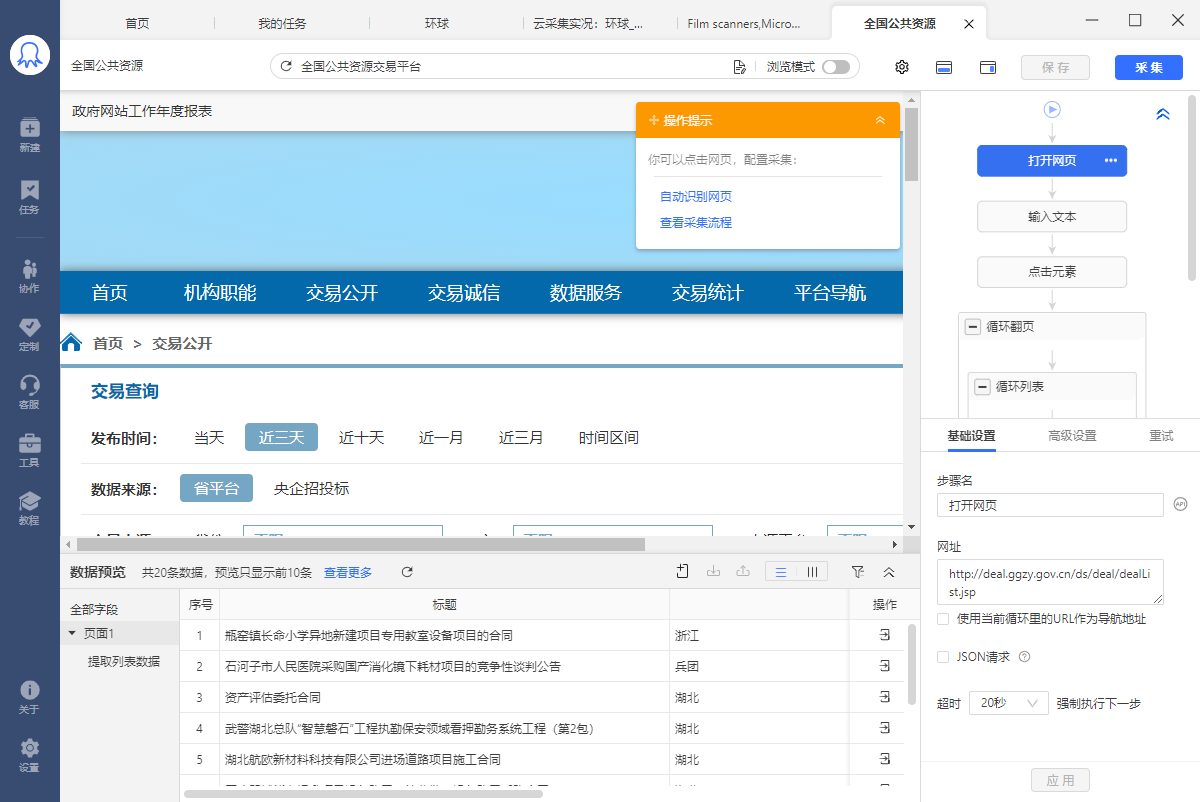
在 客户端界面介绍 里,我们简单讲了数据采集的2种模式:【使用模板采集数据】和【自定义配置采集数据】。 本文将详细讲解【自定义任务编辑界面介绍】,【自定义配置采集数据】可点击开始学习 。 一、自定义采集界面介绍 自定义任务界面是在自定义采集模式下出现的界面,该界面包含了不同的功能分区,自定义模式界面所下图示。 1)左上角红框为任务名,双击后可进行修改,修改完成后点击其他位置即可进行保存。 2)界面右上角为【切换浏览模式】、【设置】、【点击隐藏数据预览】、【点击隐藏流程图】、【保存】及【采集】按键。…
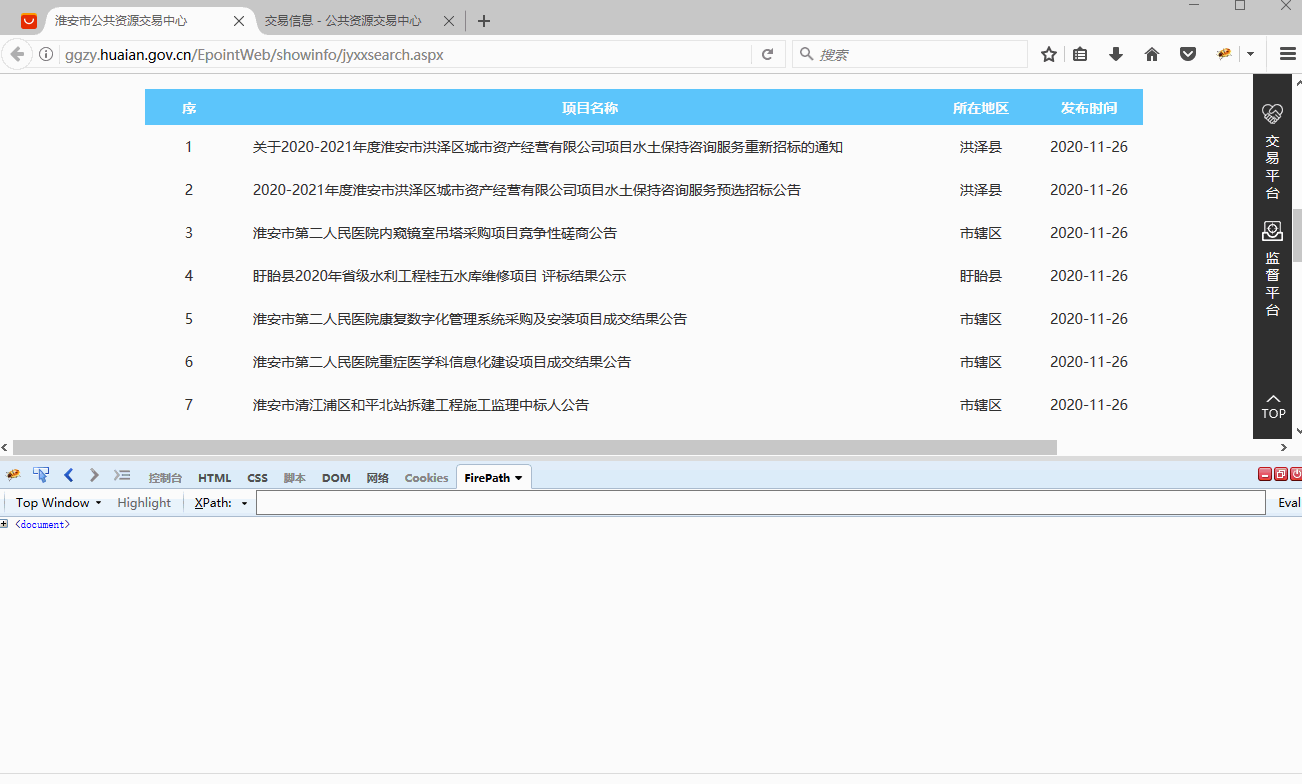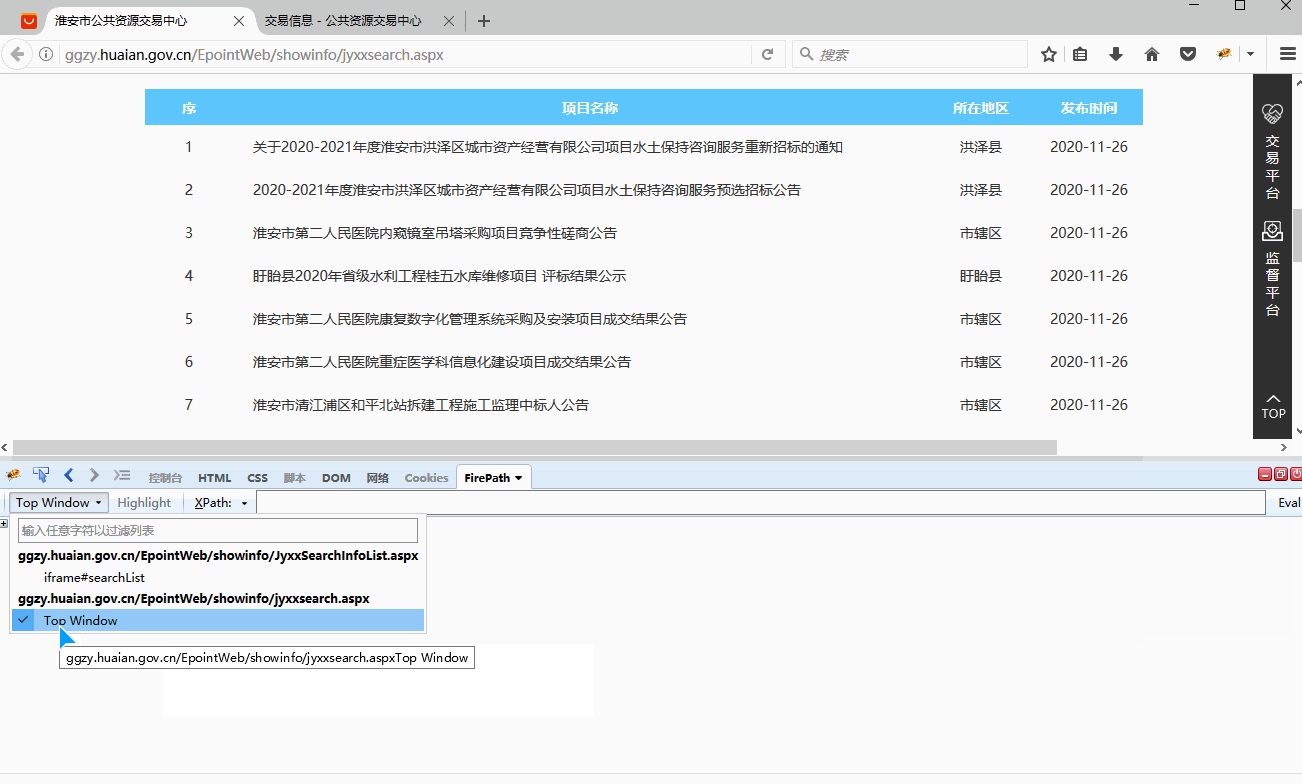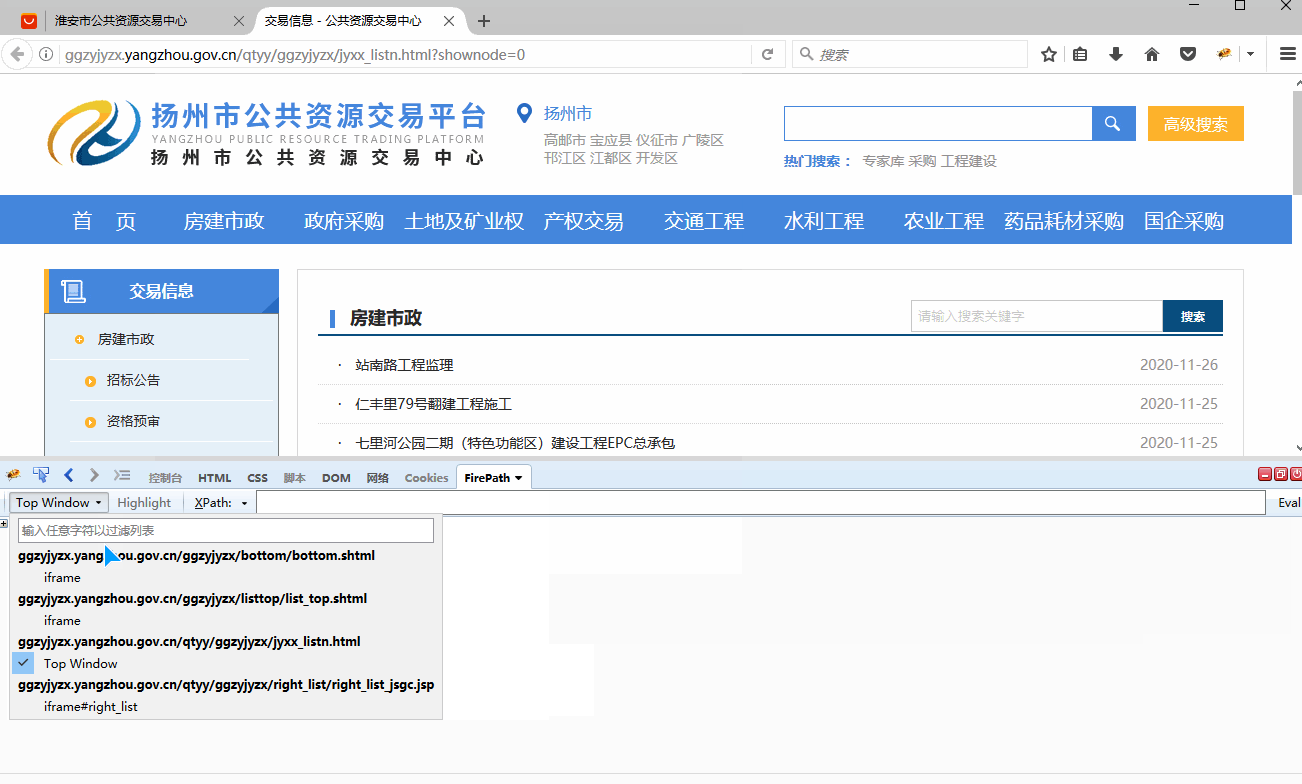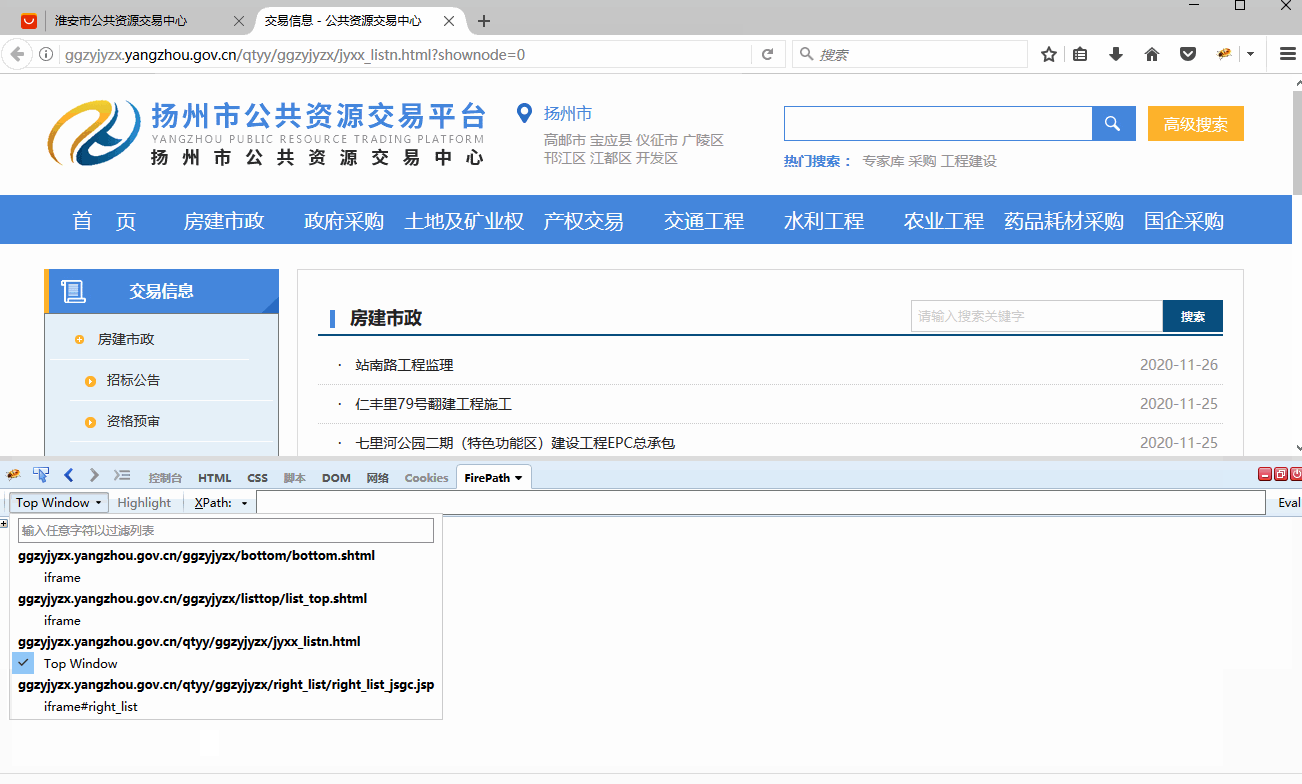
有的网页包含iframe框架,在八爪鱼中也需进行相应设置,本教程将详细讲解。 1、什么是iframe框架? 通俗来说,iframe框架就是在同一个页面中有多个网页,也就是网页中嵌套了其他的网页。 iframe框架可能有一层,也可能有多层。 如何判断网页有几层iframe框架? 借助火狐浏览器的irebug和firepath插件,我们可以很容易地判断出网页有几层iframe框架。 如果没有安装,请查看 火狐浏览器的irebug和firepath插件安装教程 。 安装好后,点击【Top Window】位置,会…
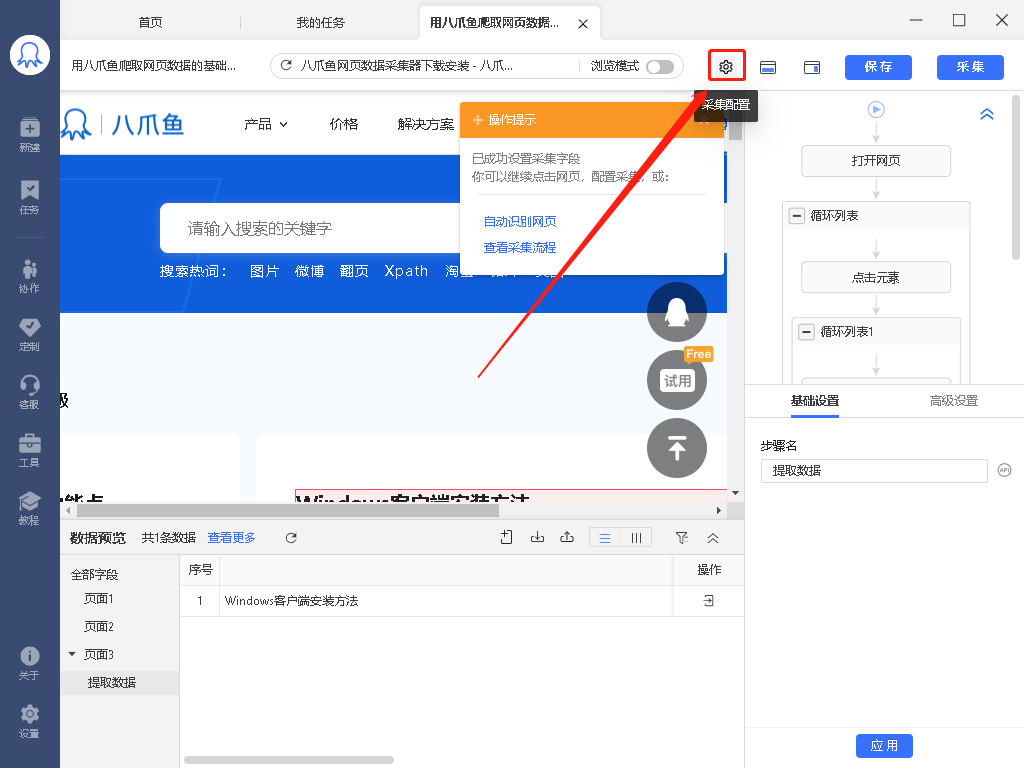
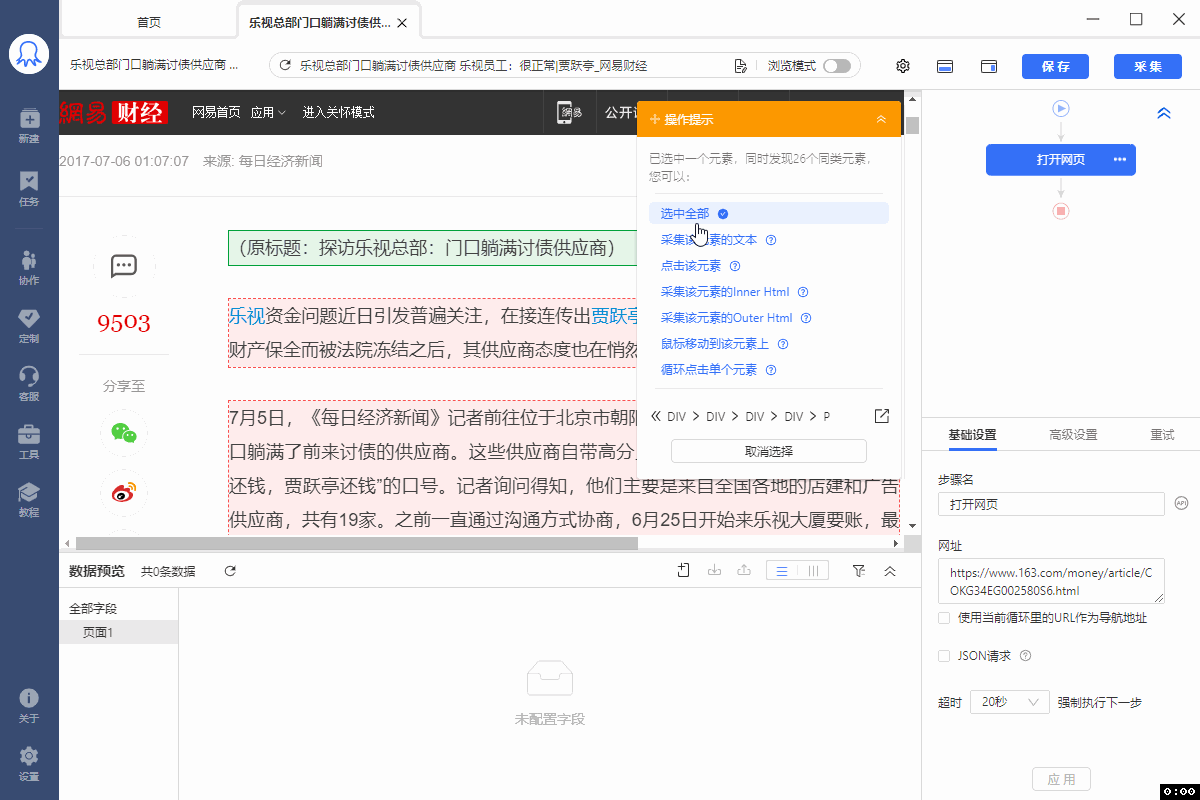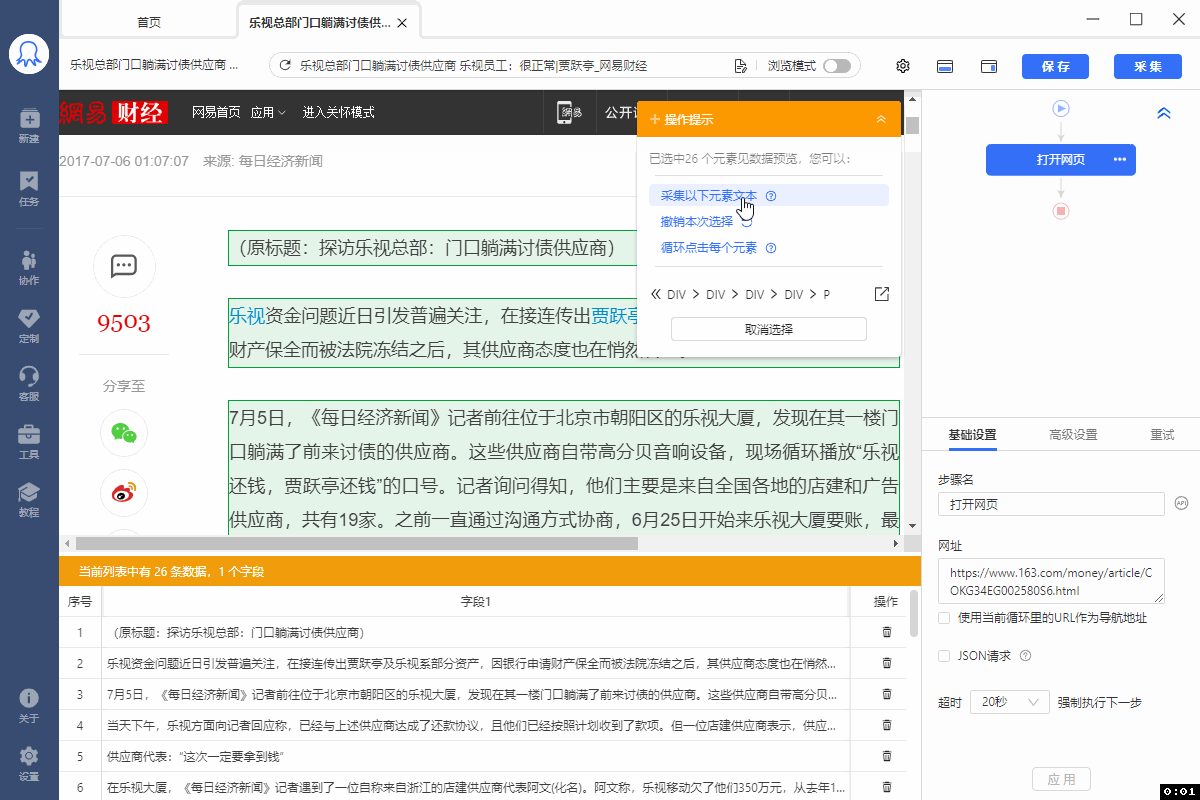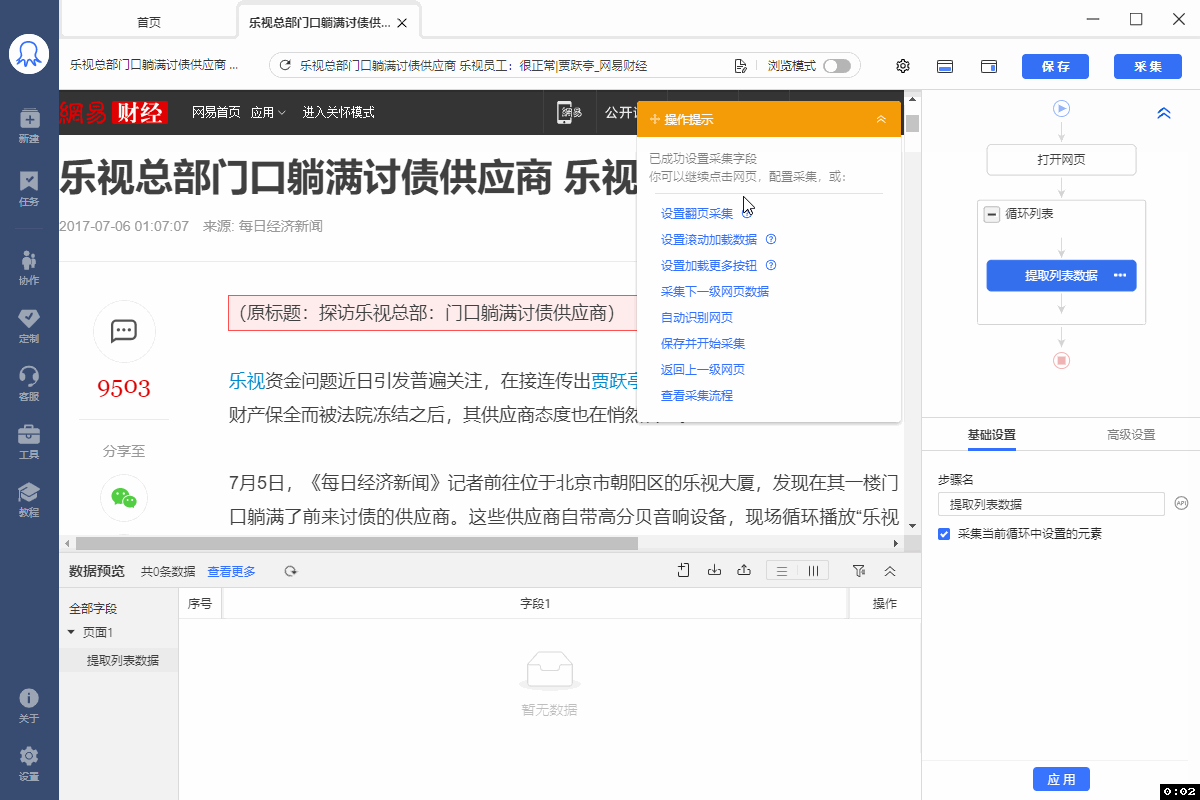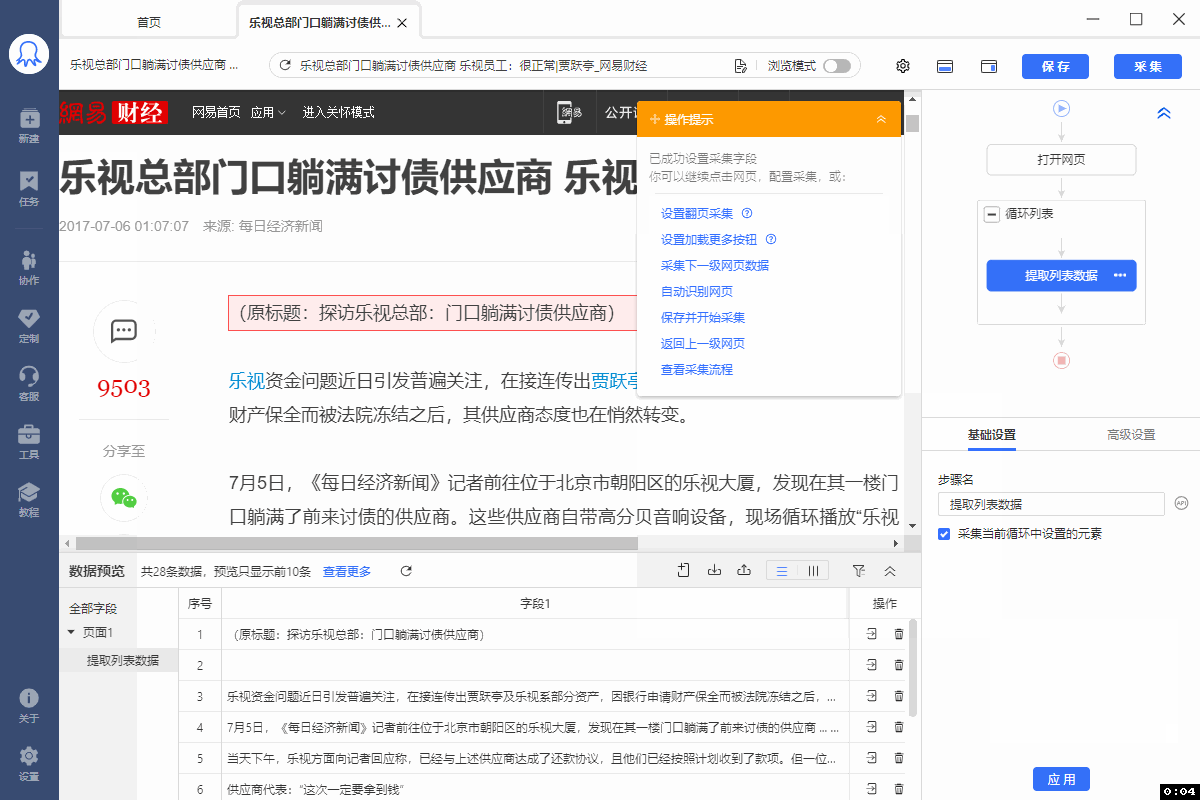
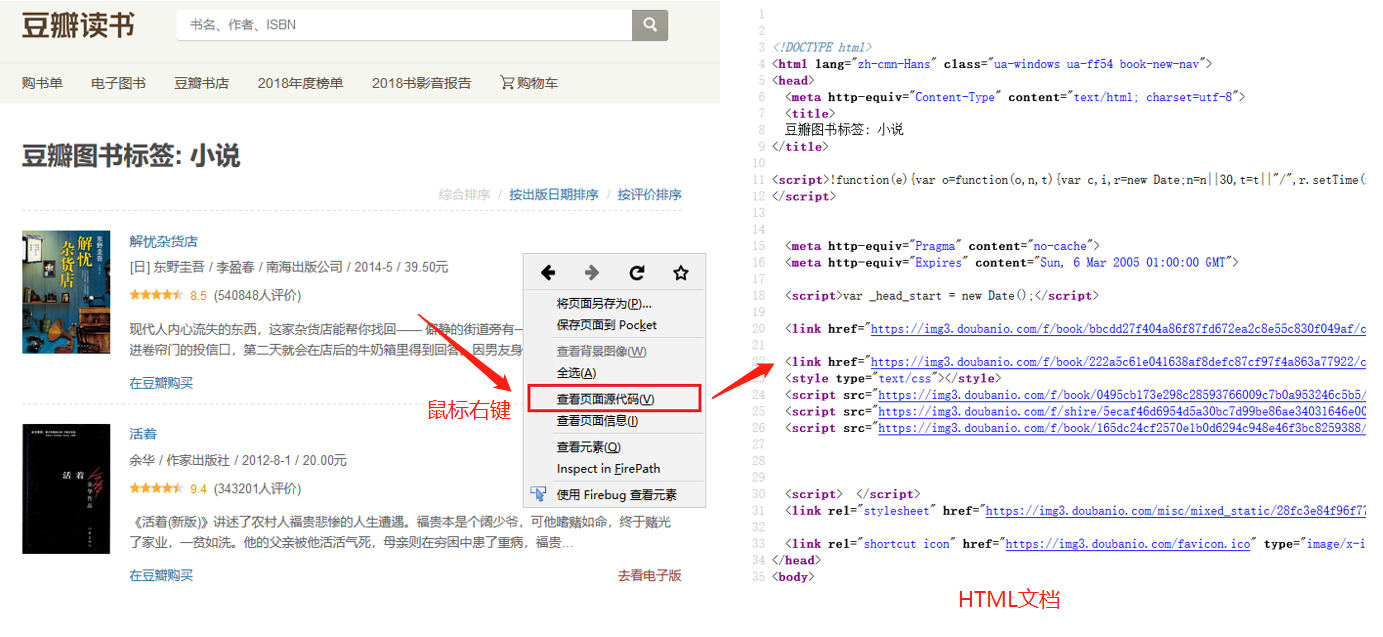
XPath对于八爪鱼数据采集十分重要。绝大多数的数据采集问题,都可以通过写一条正确的XPath解决。 本课将详细讲解XPath相关的问题。 一、HTML 与 XPath 我们日常浏览的网页本质上都是一个个HTML文档。打开网页后,鼠标右键打开菜单,选择【查看网页源代码】,就能看到该网站的HTML文档。网页上的数据,在其HTML文档中都有一个对应位置。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 如何在HTML文档中找到想要的数据?XPath是最常用的语言…
