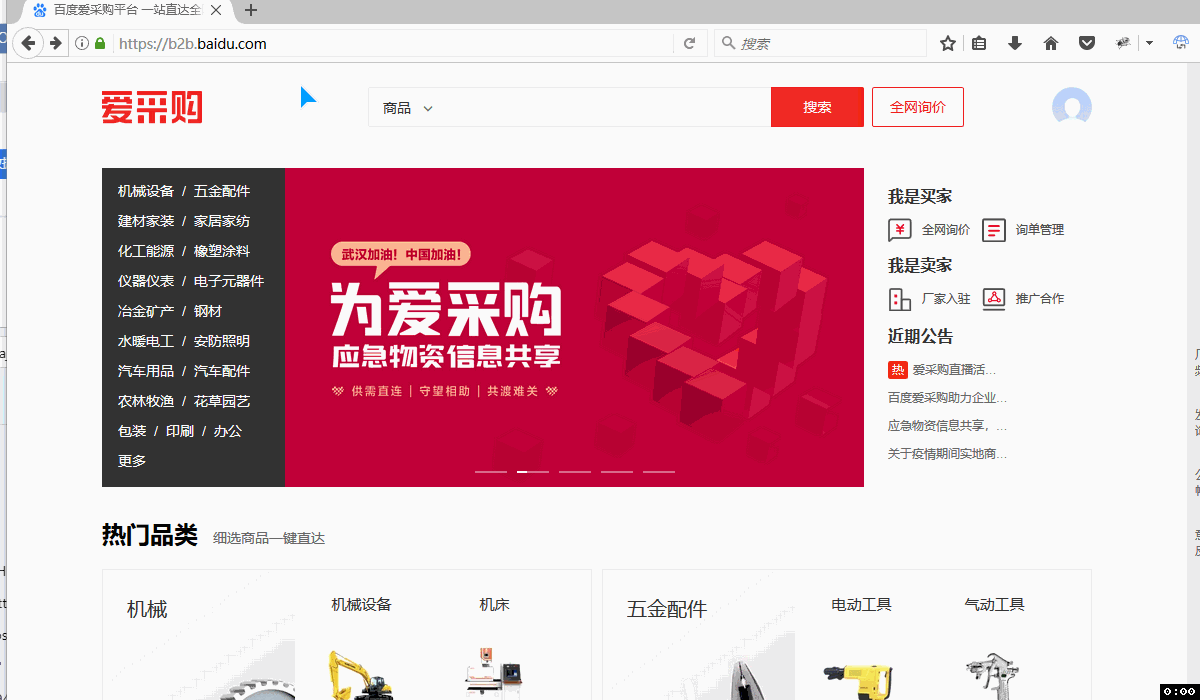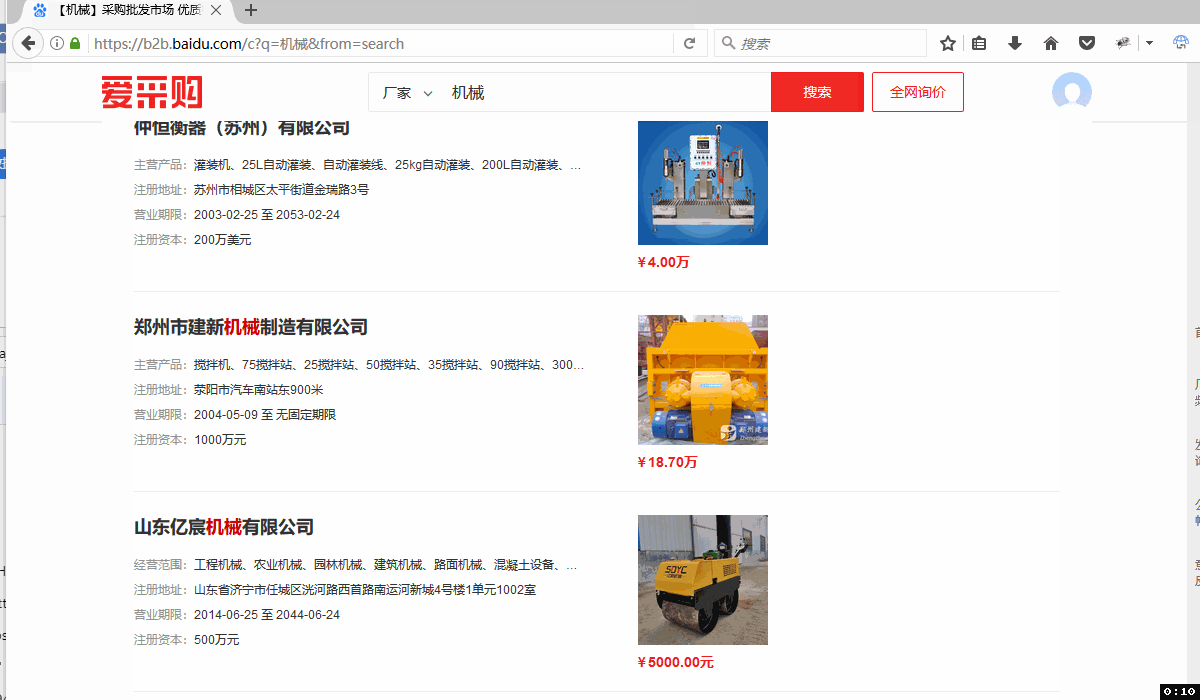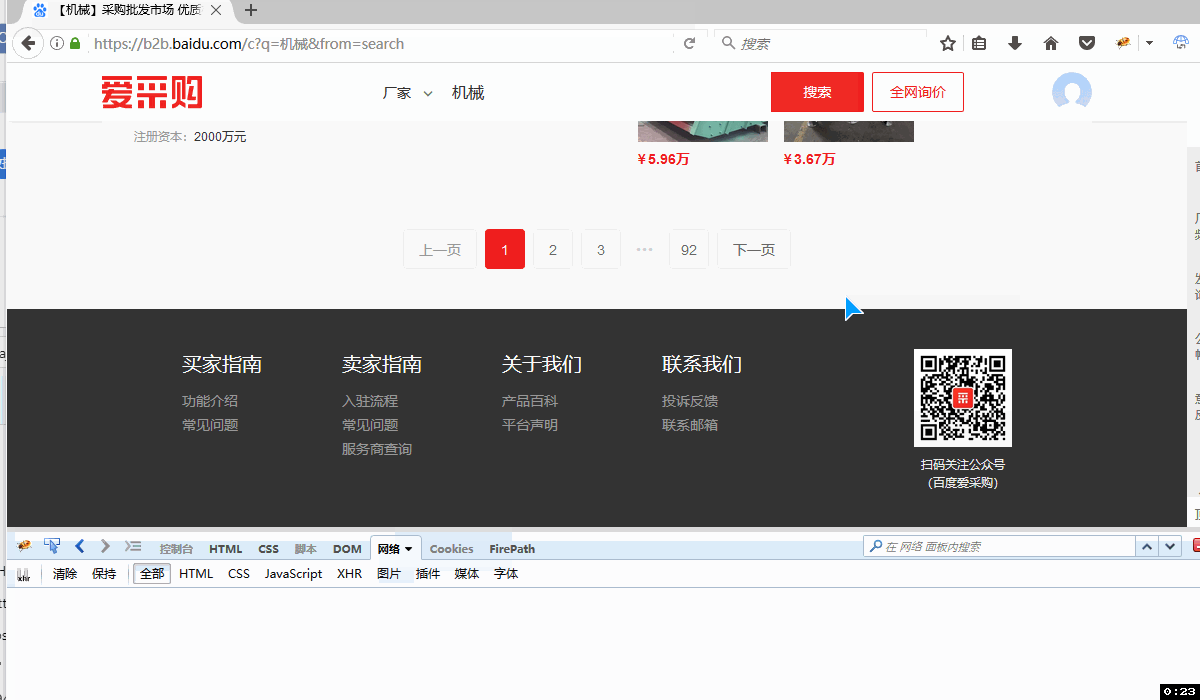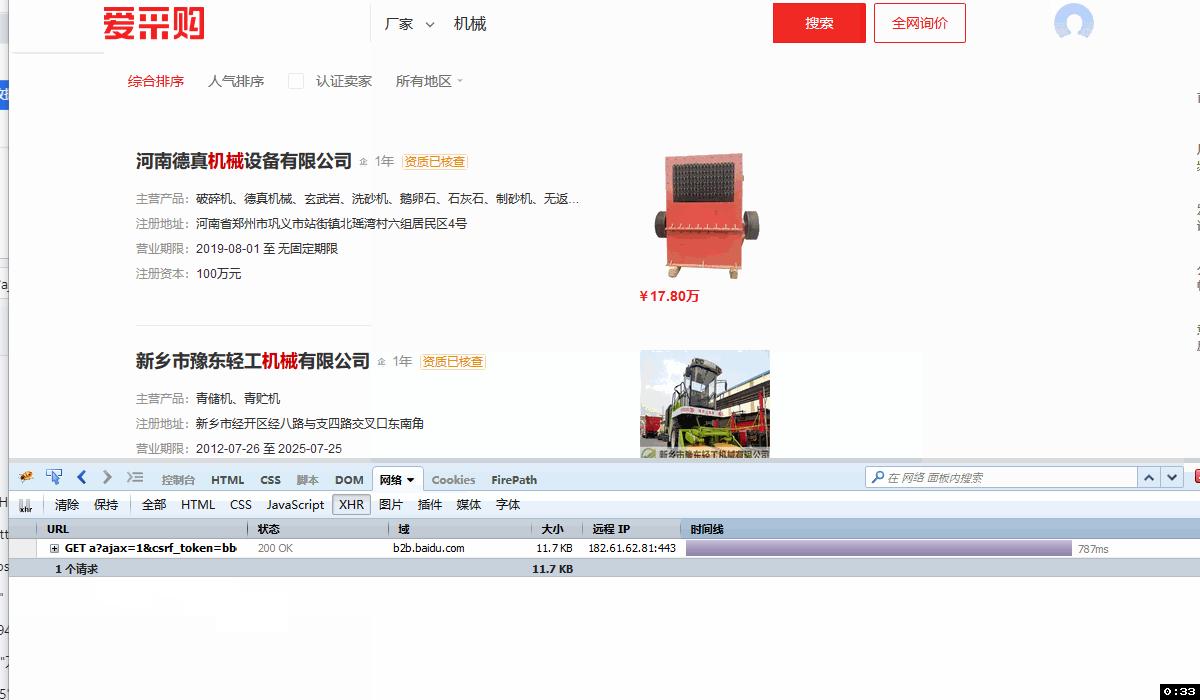
八爪鱼提供JSON采集功能,通过打开JSON网址,配置流程,能够进行JSON采集。 一、JSON是什么 JSON是一种轻量的数据交换格式,由于一些优秀的特性比如比 XML 更小、更快,更易解析和阅读,并有效地提升网络传输效率,而得到广泛使用。 二、JSON采集的优点 1、无需加载图片视频等信息,采集速度更快 2、部分网站防采集限制减少,采集更加顺畅 三、JSON采集实例 示例网址:https://b2b.baidu.com/ 需求:采集关键词为机械设备的信息地址,包括:公司名/链接/注册/产品/…
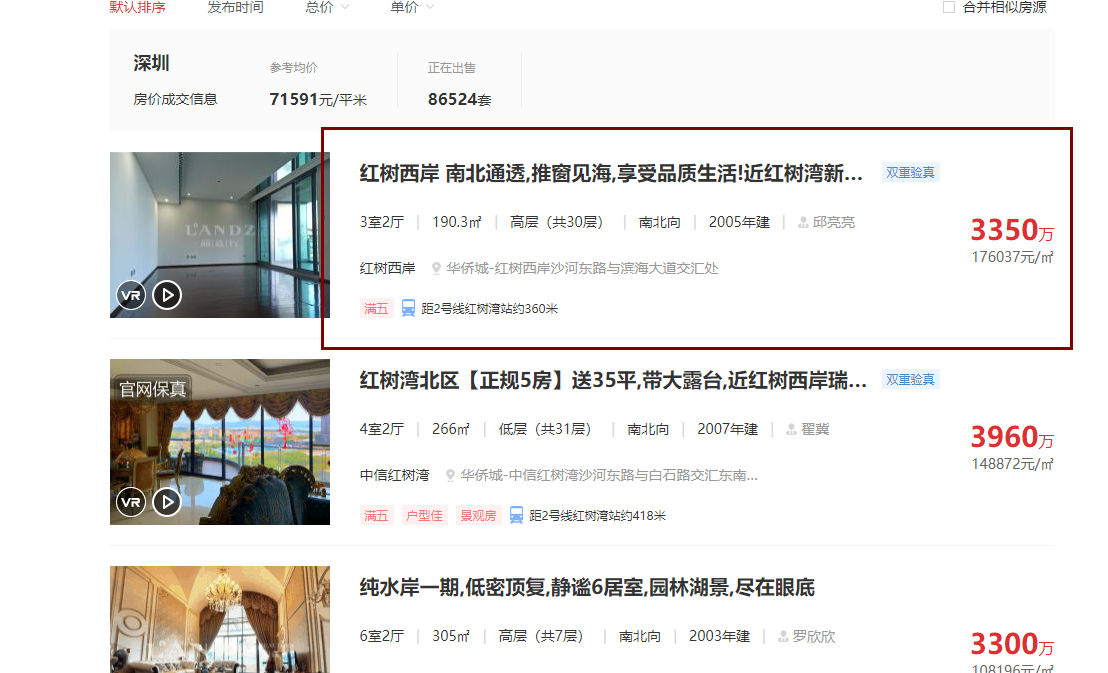
采集场景 点击房天下网站的【二手房】分类,采集【二手房】分类下的房屋数据。 采集时可选择目标城市,本示例以深圳二手房为例:https://sz.esf.fang.com 。 采集字段 房源名称、房屋介绍、联系人、售价、所在小区、具体地址、单位价格等。 点击查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 教程说明 本篇制作时间:2022/6/29 八爪鱼版本:V8.5.4 如果因网页改版造成网址或步骤无效,无…

有时候,我们有大量同类网页,希望八爪鱼能自动采集每个网页中的数据。通过设置【URL循环】,可实现此需求。 什么是同类网页?结构相同、字段差不多的网页。例: 京东商品详情页: https://item.jd.com/1138288.html https://item.jd.com/27305099378.html https://item.jd.com/46339353993.html 豆瓣电影详情页: https://movie.douban.com/subject/26387939/ https://…
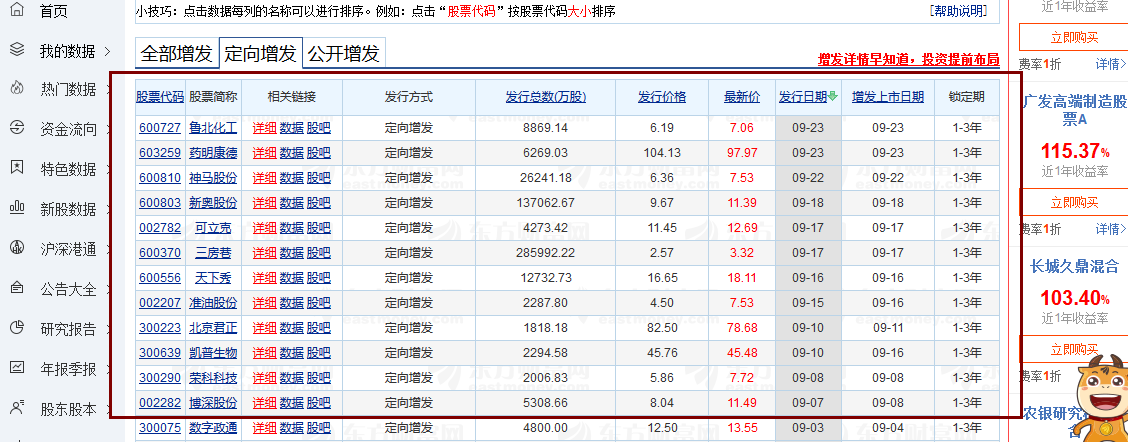
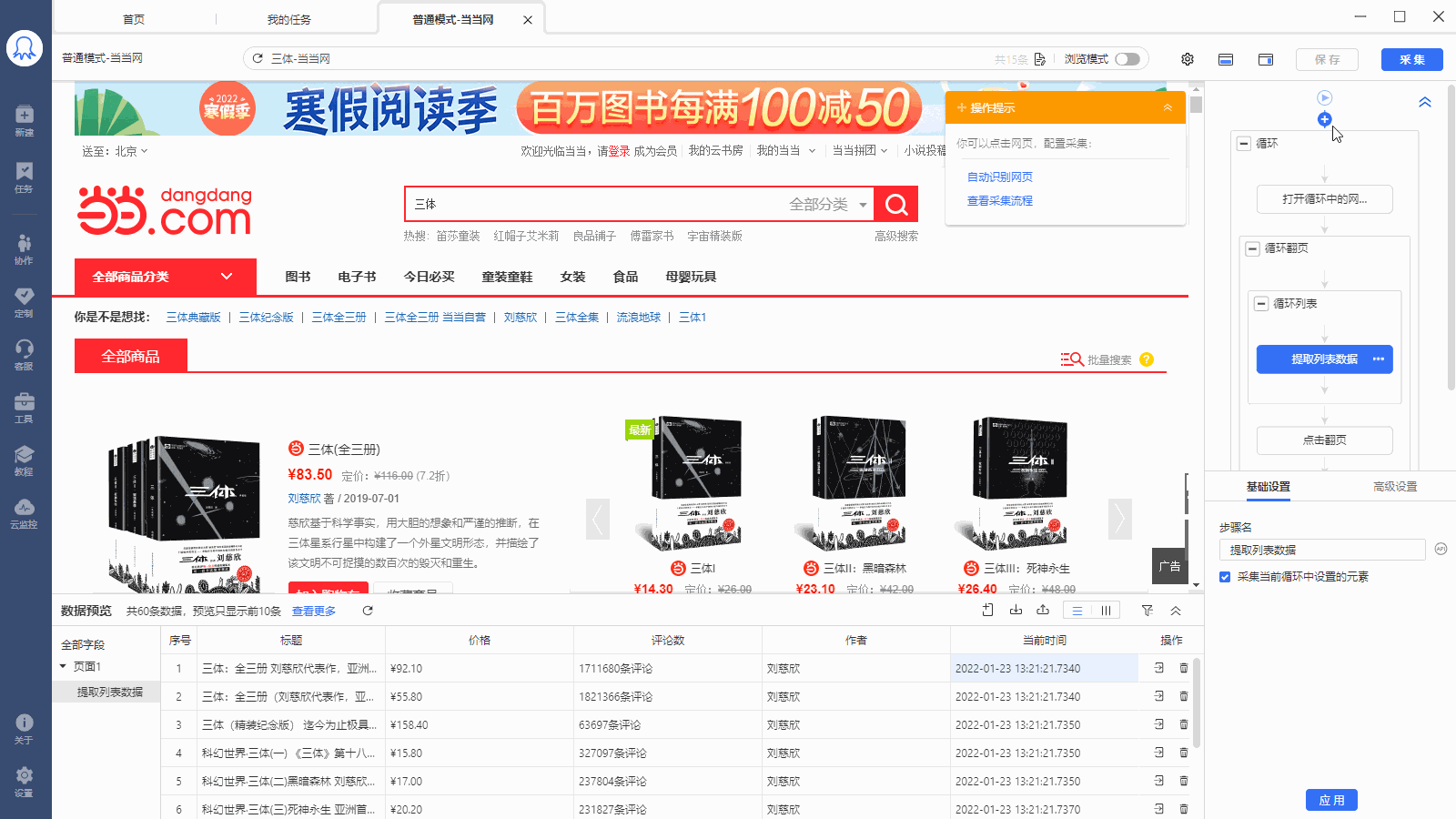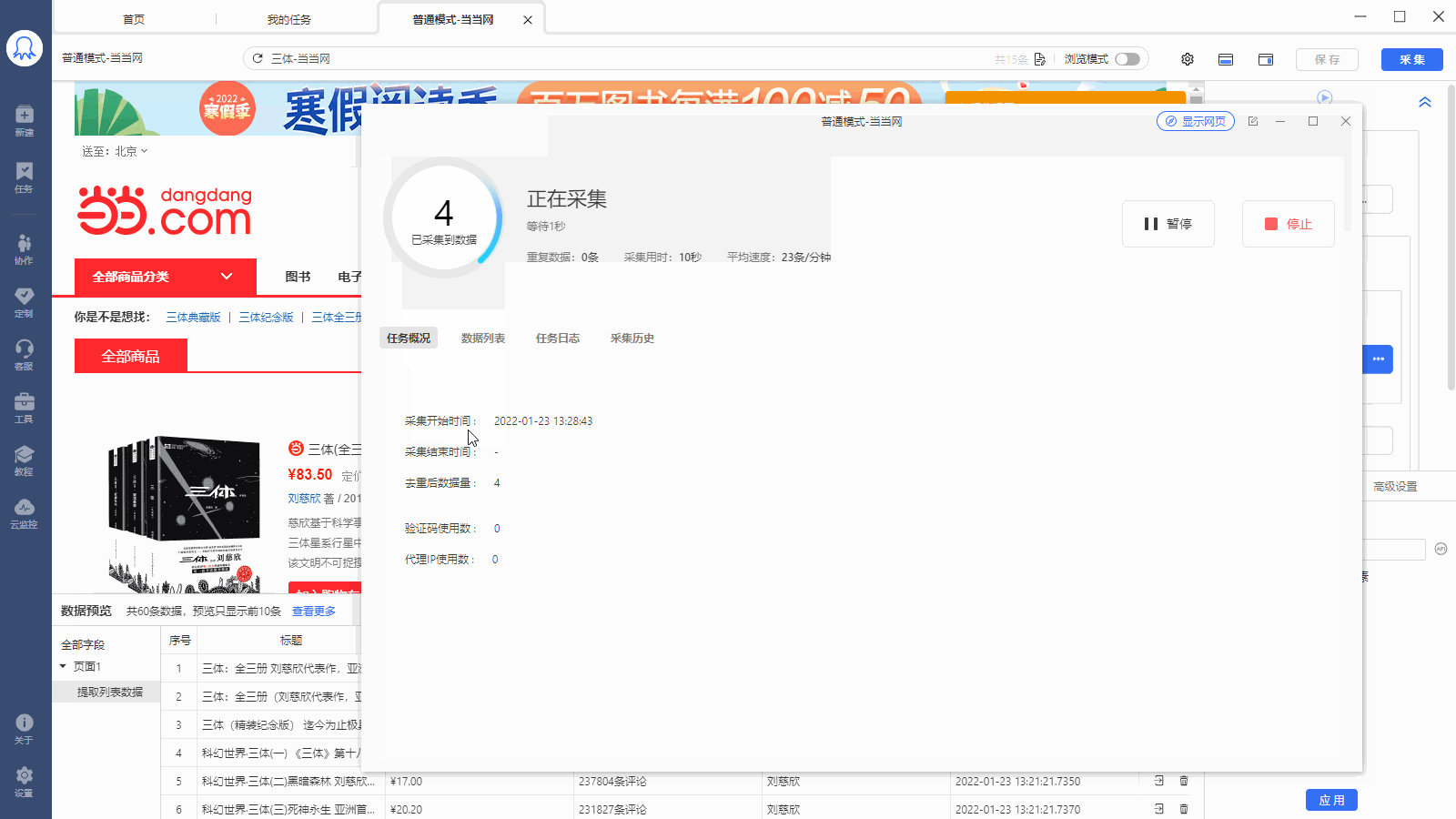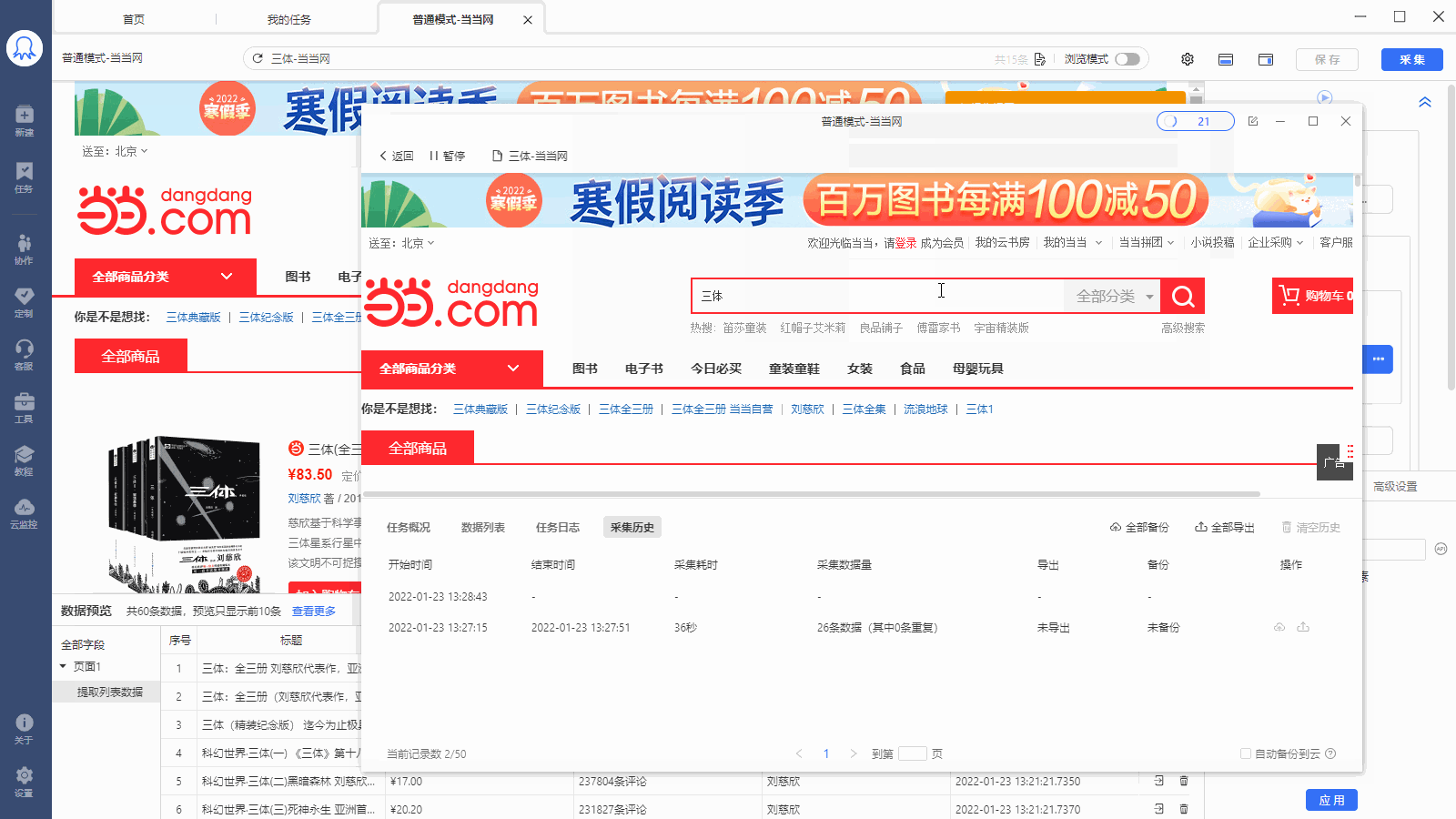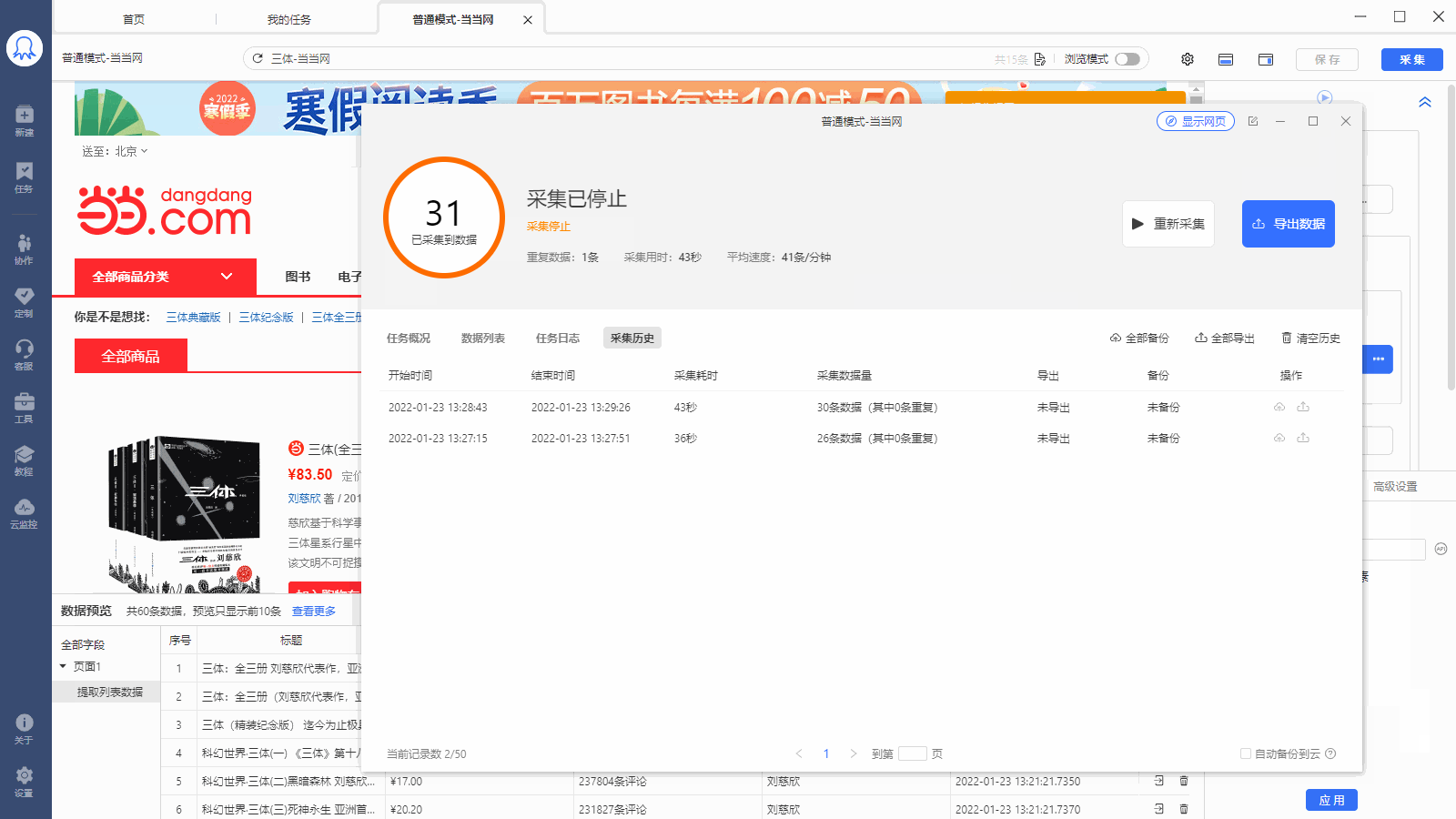
采集场景 打开东方财富网【定向增发股】类目的网页:http://data.eastmoney.com/other/dxzf.html ,采集页面上显示的股票信息。 采集字段 股票简称、基金代码、发行方式、发行总数、发行价格、最新价、发行日期、增发上市日期、锁定期、股票代码详情链接、当前采集时间等字段。 点击查看高清大图,下文其他图片同理 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 采集步骤 步骤一、打开网页 步骤二、创建【循环-提取…



八爪鱼采集到的数据,支持导出到Mysql数据库中。可手动导出,也按照设置的定时导出计划,自动导出。 本教程将以云采集数据,演示手动/自动导出到Mysql数据库中的具体步骤。 一、手动导出具体步骤 在任务采集完毕之后,将采集得到的数据,手动导出到数据库中。 本地采集和云采集数据,均可手动导出。 Step1:先在您的Mysql中,建好数据库和数据表。 Step2:在【我的任务】中,将鼠标移动到任务上,任务采集状态右侧会出现全部按钮,点击即可进入查看采集到的数据,这里点击云采集右侧的全部,查看全部云采集数…

在学习本教程之前,您需要具备八爪鱼基础操作和XPath相关知识,如果还未掌握,请先学习以下课程。 自定义模式入门:https://www.bazhuayu.com/tutorial8/xsrm/81zdyrm XPath 系统学习与实例:https://www.bazhuayu.com/tutorial8/81xpath 一、相对XPath 相对Xpath,即相对于循环框的Xpath,有两个典型特征:跟随循环联动;与循环框的XPath合并成一条完整的定位XPath。 有两种常见应用场景:提取循环内的数据;提取循…
