有很多网站,需要向下滚动页面,才能加载出新数据。那相对应的,在八爪鱼中也需设置【页面滚动】。 适用场景:将滚动条直接下来到网页底部,出现类似【加载中】字样,稍后马上有新数据出现,且滚动条变短回弹。 常见的网页:澎湃新闻首页、今日头条首页、百度图片搜索、新浪微博首页,都是这种情况。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 以澎湃新闻首页为例。https://www.thepaper.cn/,我们需采集新闻列表数据。就需要在打开网页后不断向下滚动,加载新数据。 …
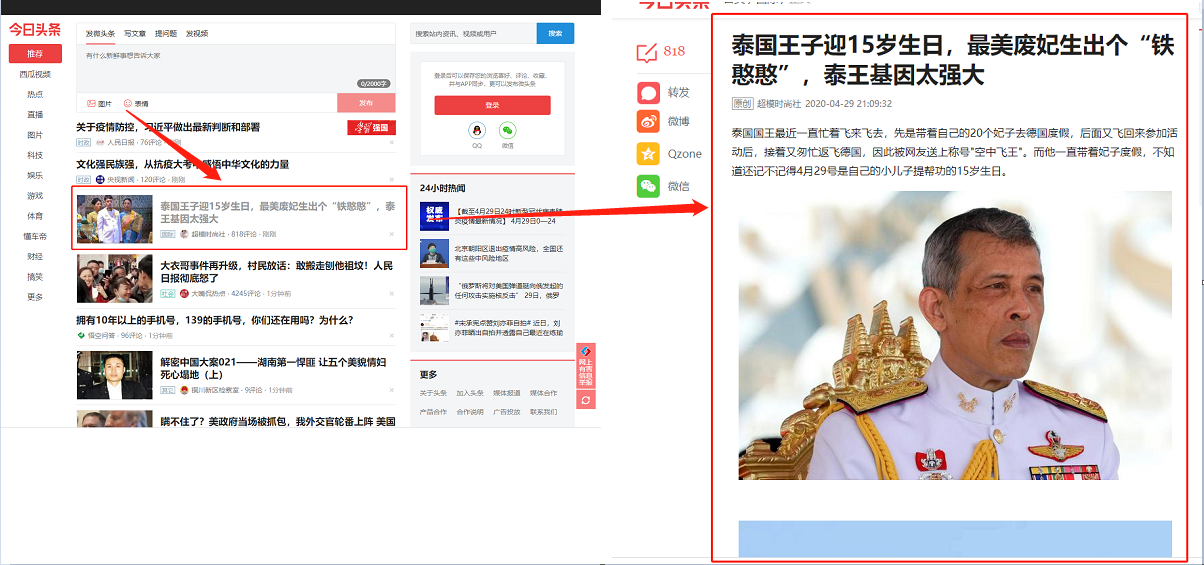
采集场景 今日头条是重要的新闻资讯网站,首页(https://www.toutiao.com/)默认展示最新的新闻列表,点击新闻标题,可进入新闻详情页,查看每条新闻的详情页数据。 采集字段 标题、来源、时间、正文、图片url等字段。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集结果 采集结果可导出为Excel,CSV,HTML,数据库等多种格式。导出为Excel示例: 教程说明 本篇更新时间:2022/6/18 八爪鱼版本:V8.5.2 如果…
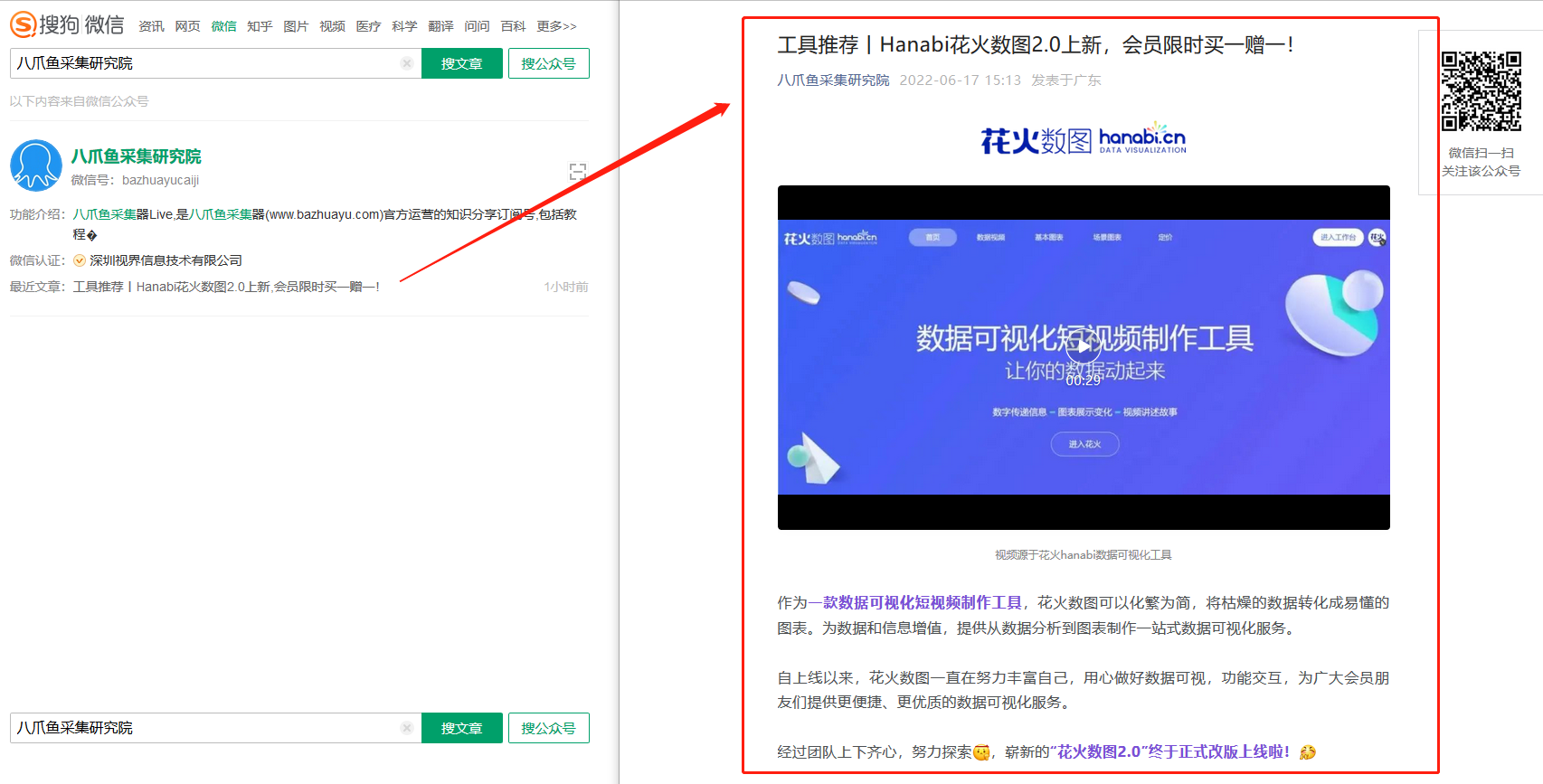
采集场景 我们一般通过搜狗微信(https://weixin.sogou.com/),去采集微信公众号文章。搜狗微信支持【公众号搜索】,通过输入公众号名称/ID,可搜索到目标公众号,查看目标公众号相关信息(公众号ID、微信号、功能介绍、微信认证)和其最新发布的一篇文章(文章标题和文章链接),点击文章链接可进入文章详情页,查看文章正文(文字+图片)。 采集字段 公众号名称、微信号、功能介绍、微信认证公司名、文章标题、文章来源、文章作者、发布日期、文章正文。 鼠标放到图片上,右键,选择【在新标签页中打开图片…
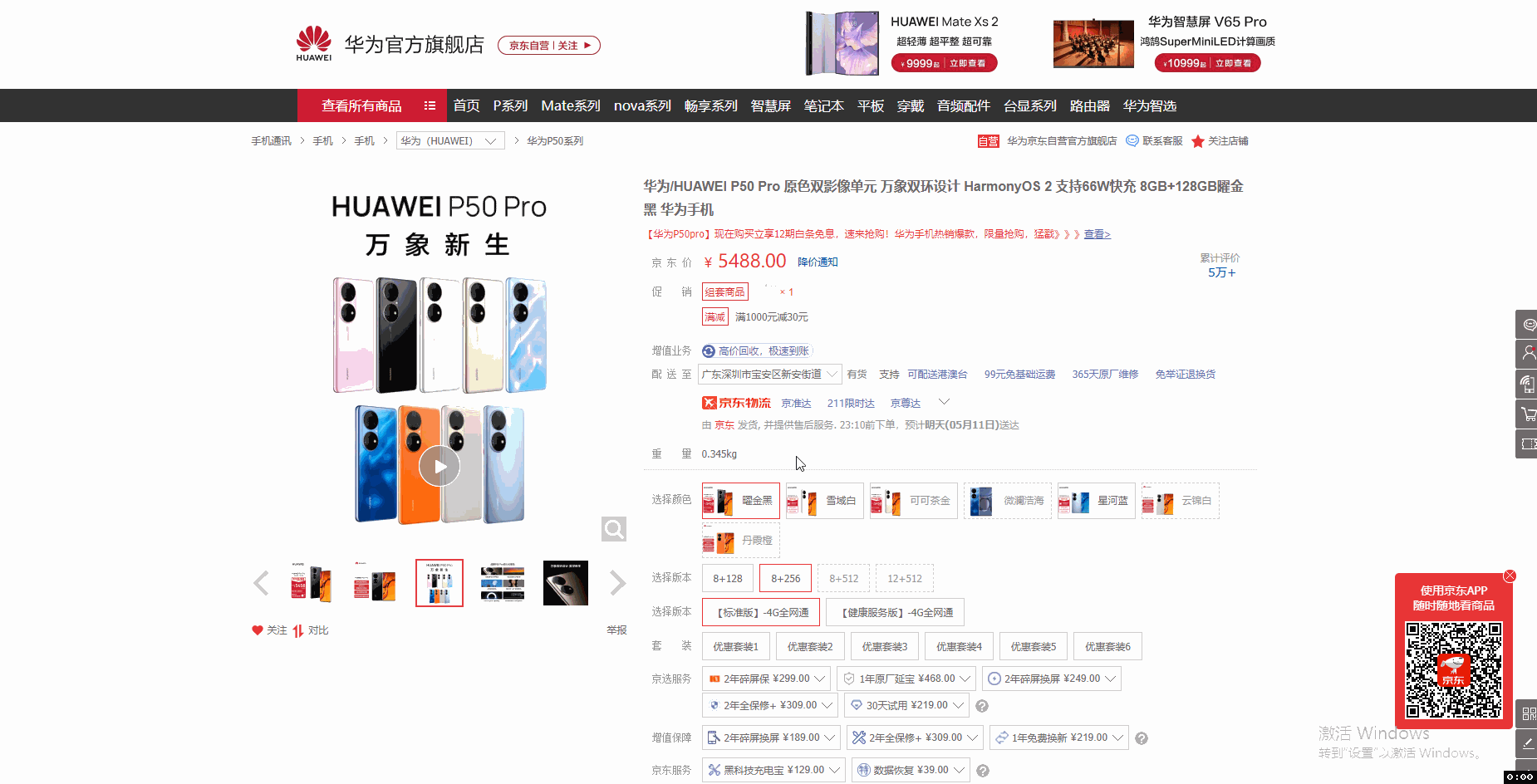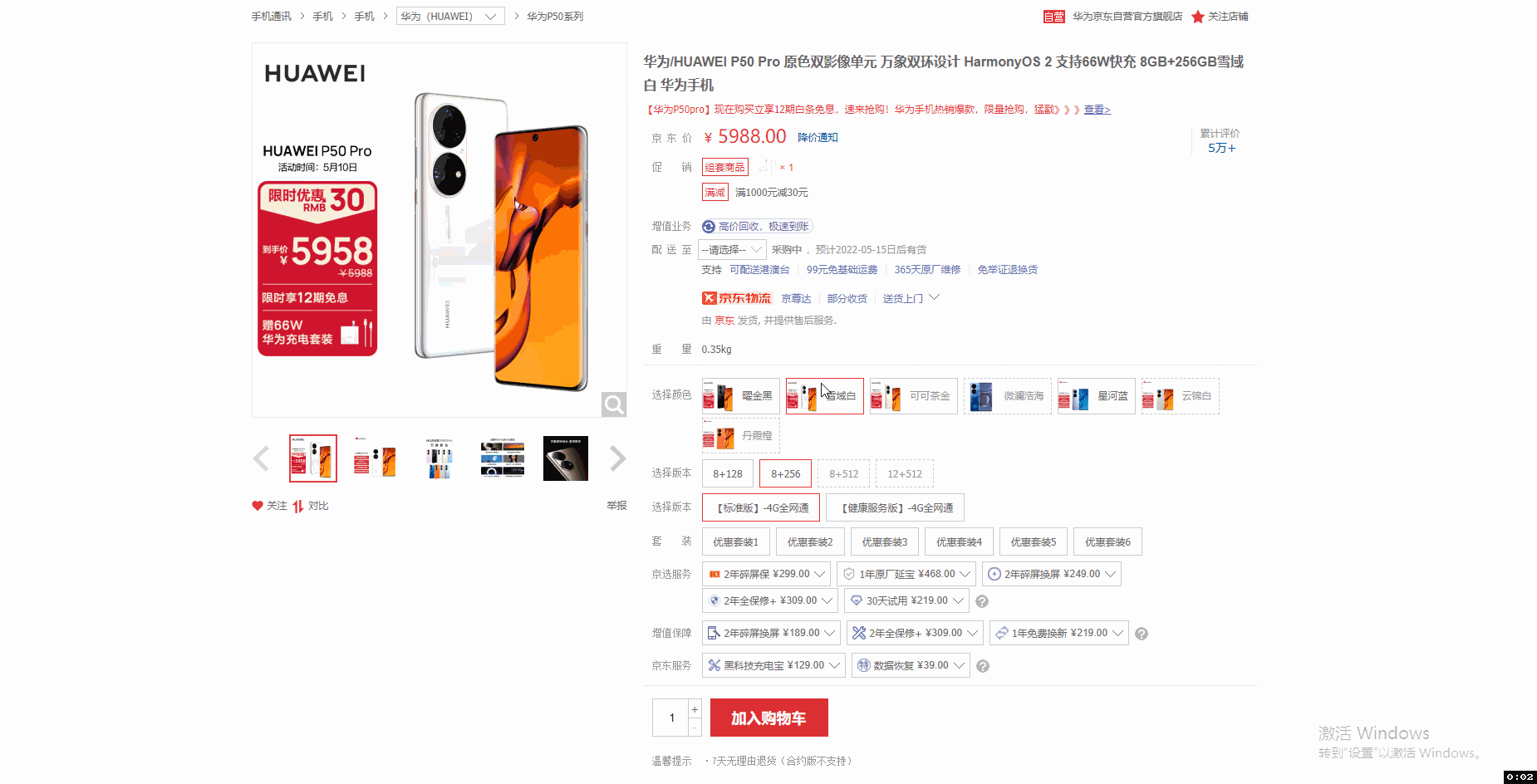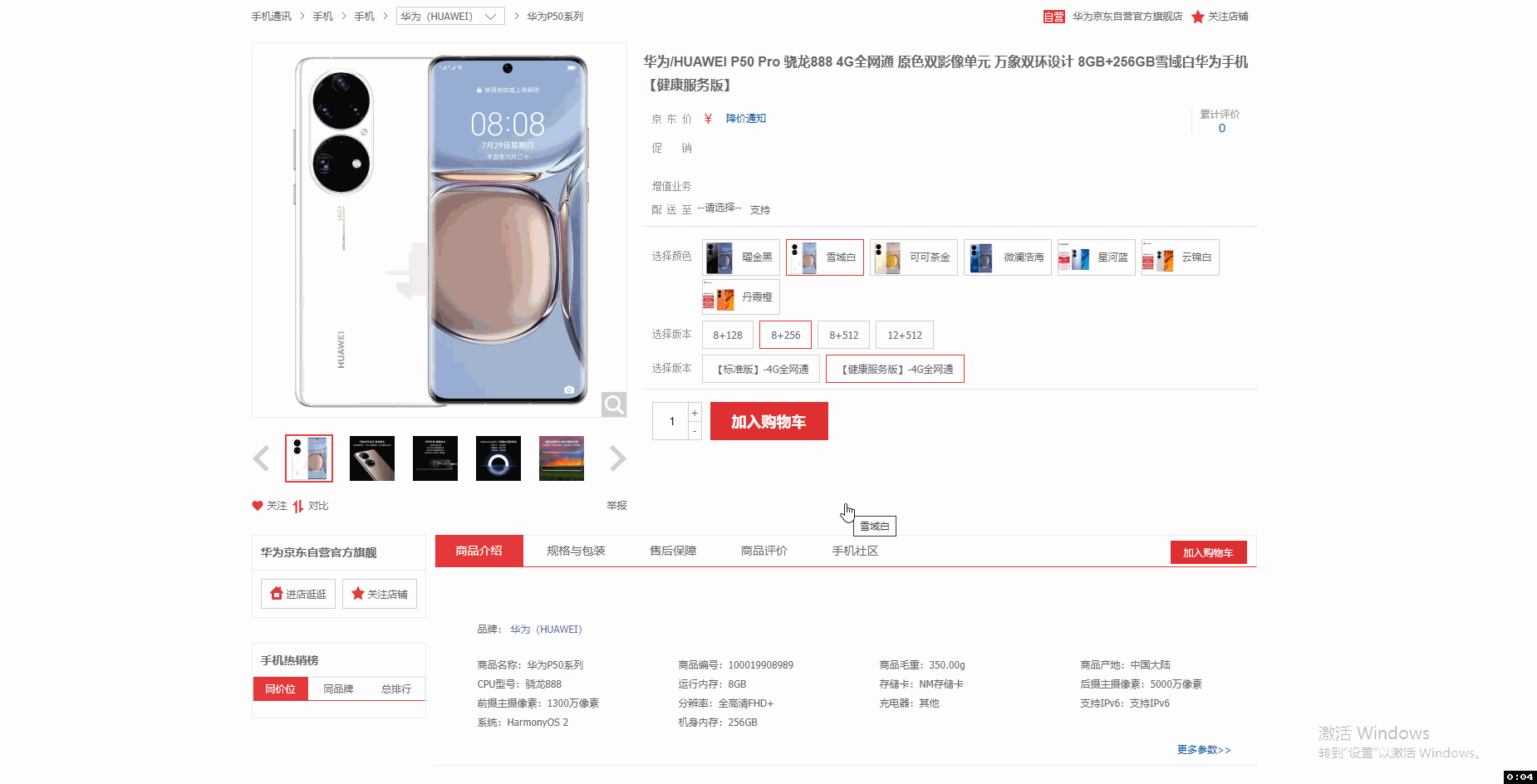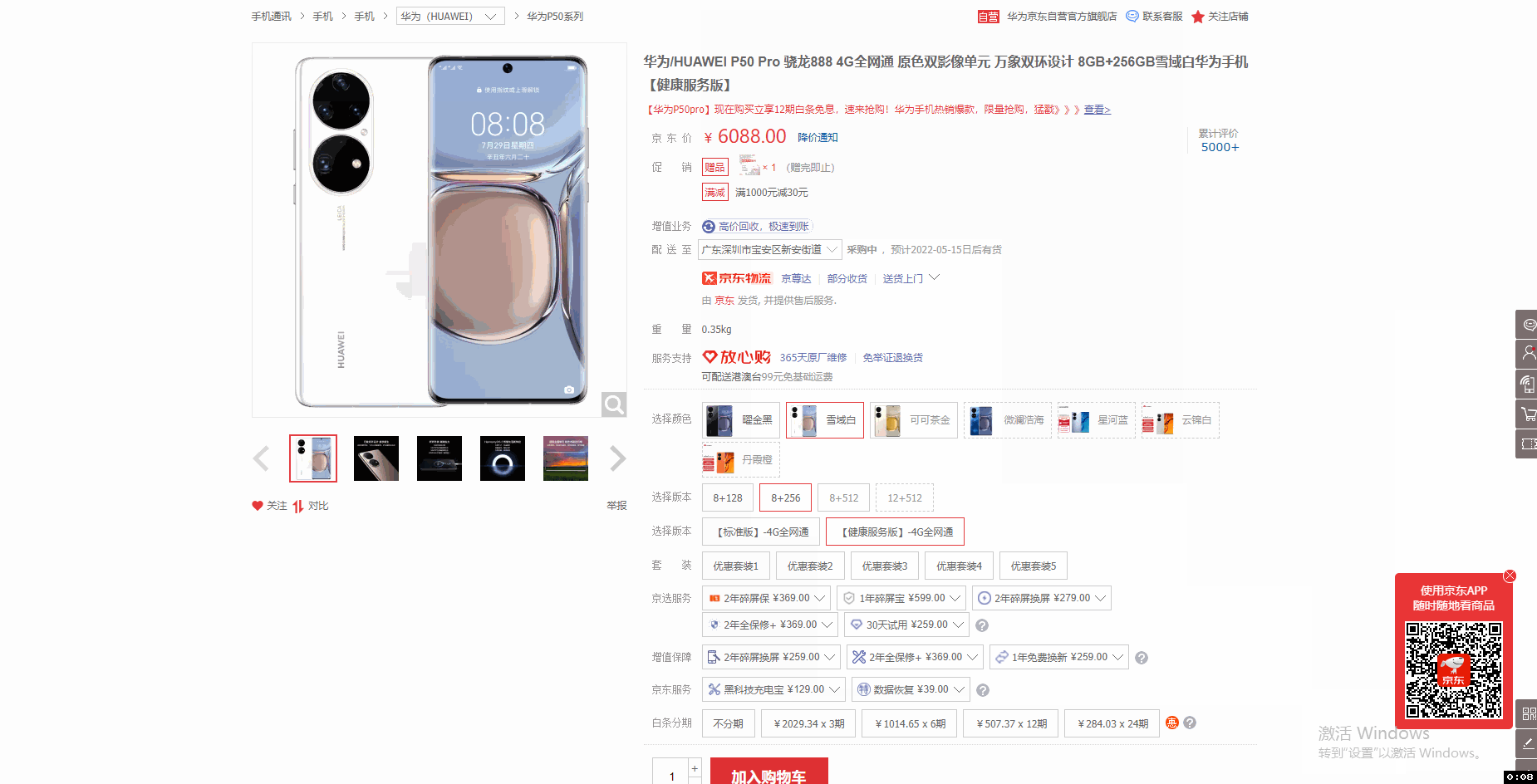
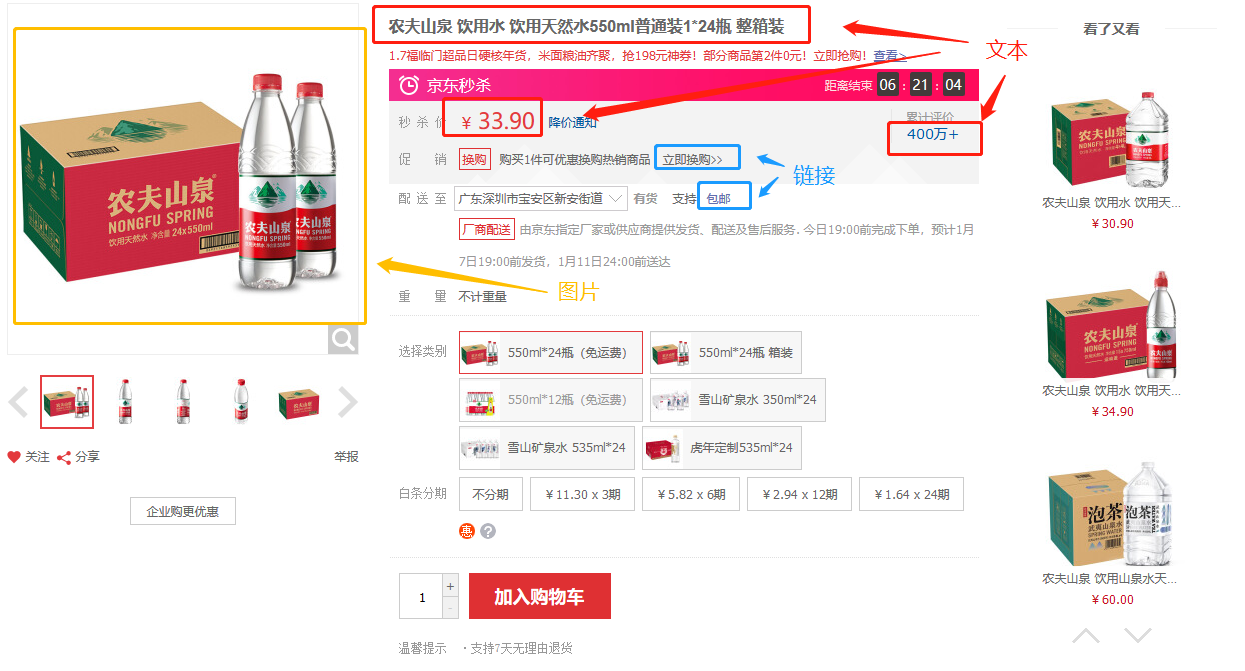
采集场景 打开京东商品详情页(实例网址:https://item.jd.com/100016944073.html ),采集点击不同的参数(颜色、版本等)后得到的数据(商品编号、价格、主图链接等字段会随着参数变化而变化)。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集字段 商品标题、颜色、版本、价格、商品名称、商品编号、图片网址等。 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 教程说明 本篇…


八爪鱼提供两套API接口,均可以获取通过八爪鱼采集到的数据,实现秒级导出; 获取任务信息,无需启动八爪鱼客户端即可控制任务启停;无缝对接企业的内部系统。 第一套接口今后将不再更新,为提升您今后的使用体验,推荐您使用第二套API接口。 第一套API接口 : 于2018年4月上线,分为 数据导出API 主域名:https://dataapi.bazhuayu.com/ 和 任务控制API 主域名:https://advancedapi.bazhuayu.com/ 第二套API接口 : 于2021年1…

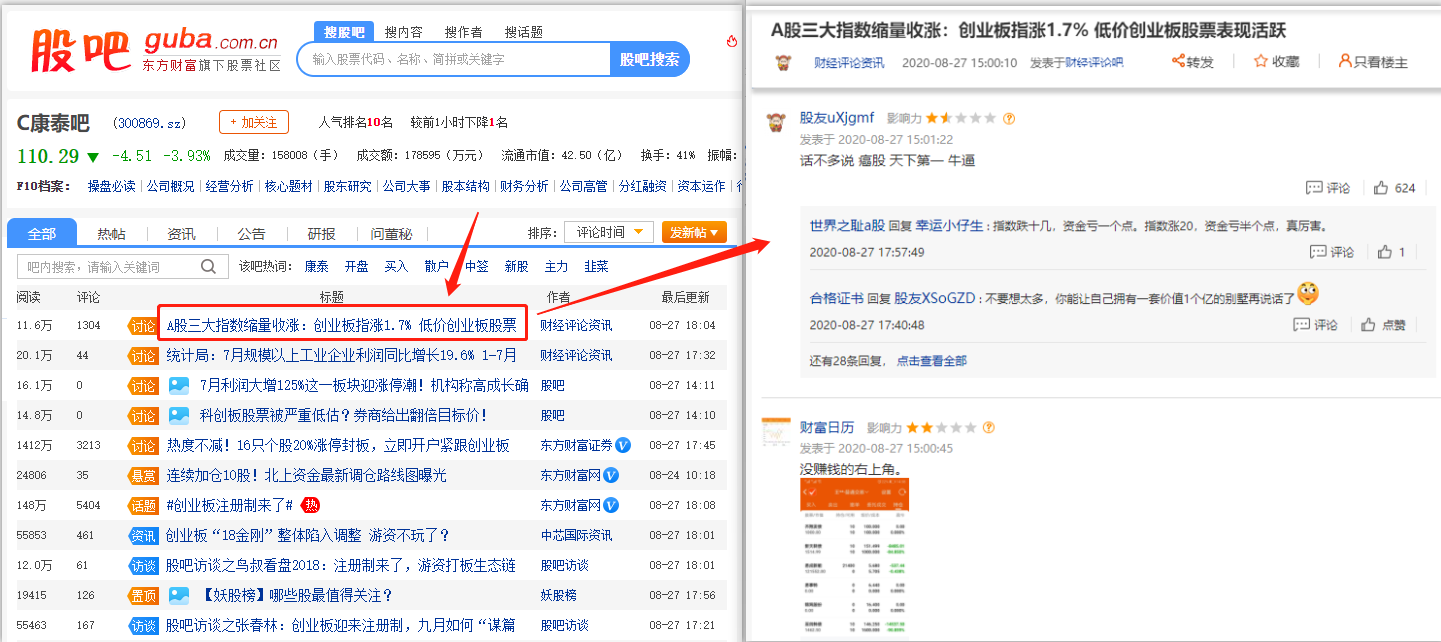
采集场景 在股吧中输入某一批股票的网址,打开其对应的股吧,会展示很多讨论帖。点击每个讨论帖进入详情页,采集详情页的帖子信息和评论信息。 示例网址:http://guba.eastmoney.com/list,300869.html http://guba.eastmoney.com/list,002108.html 采集字段 股吧名称、帖子作者名称、发布时间、文章标题、文章内容、评论者、评论时间、评论内容等内容。 点击查看高清大图,下文其他图片同理 采集结果 采集结果可…

一、什么是【边滚动边采集数据】 有很多网站,需要向下滚动页面,才能加载出新数据,像 今日头条首页、百度图片搜索、新浪微博首页 等页面都是这种情况。 在采集这类网页数据时,相对应的在八爪鱼中也需设置【页面滚动】。 八爪鱼V8.2.0之前的版本,需按照设置的滚动次数,将页面全部滚动完成之后,才会开始采集数据。 例:设置滚动20次,则需等页面滚动20次后,一次性采集前20次滚动后加载的全部数据。 详情请看教程:滚动加载数据采集方法 V8.2.0版本新增【边滚动边采集数据】功能,可以边滚动页面边采集数据。 例:…