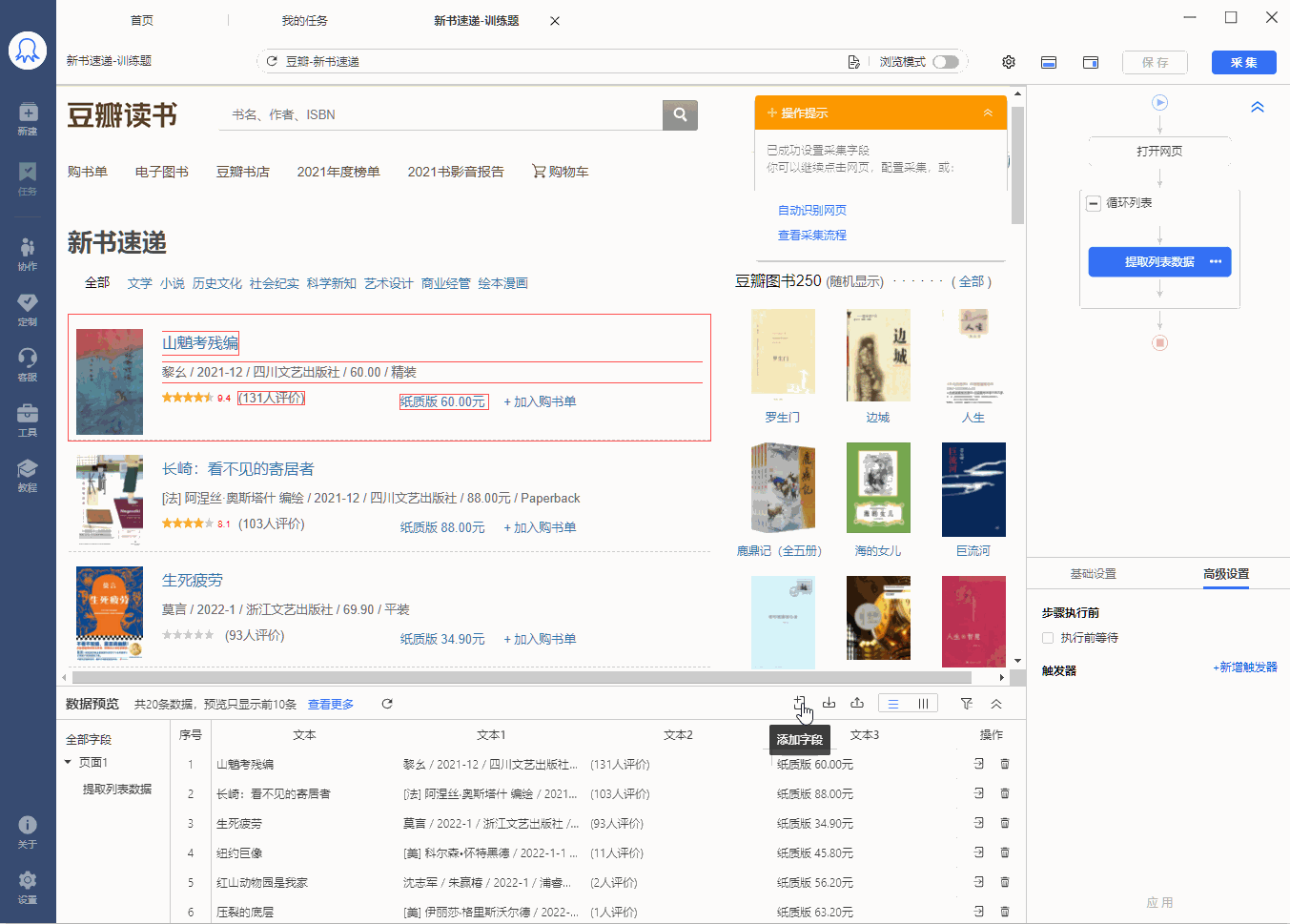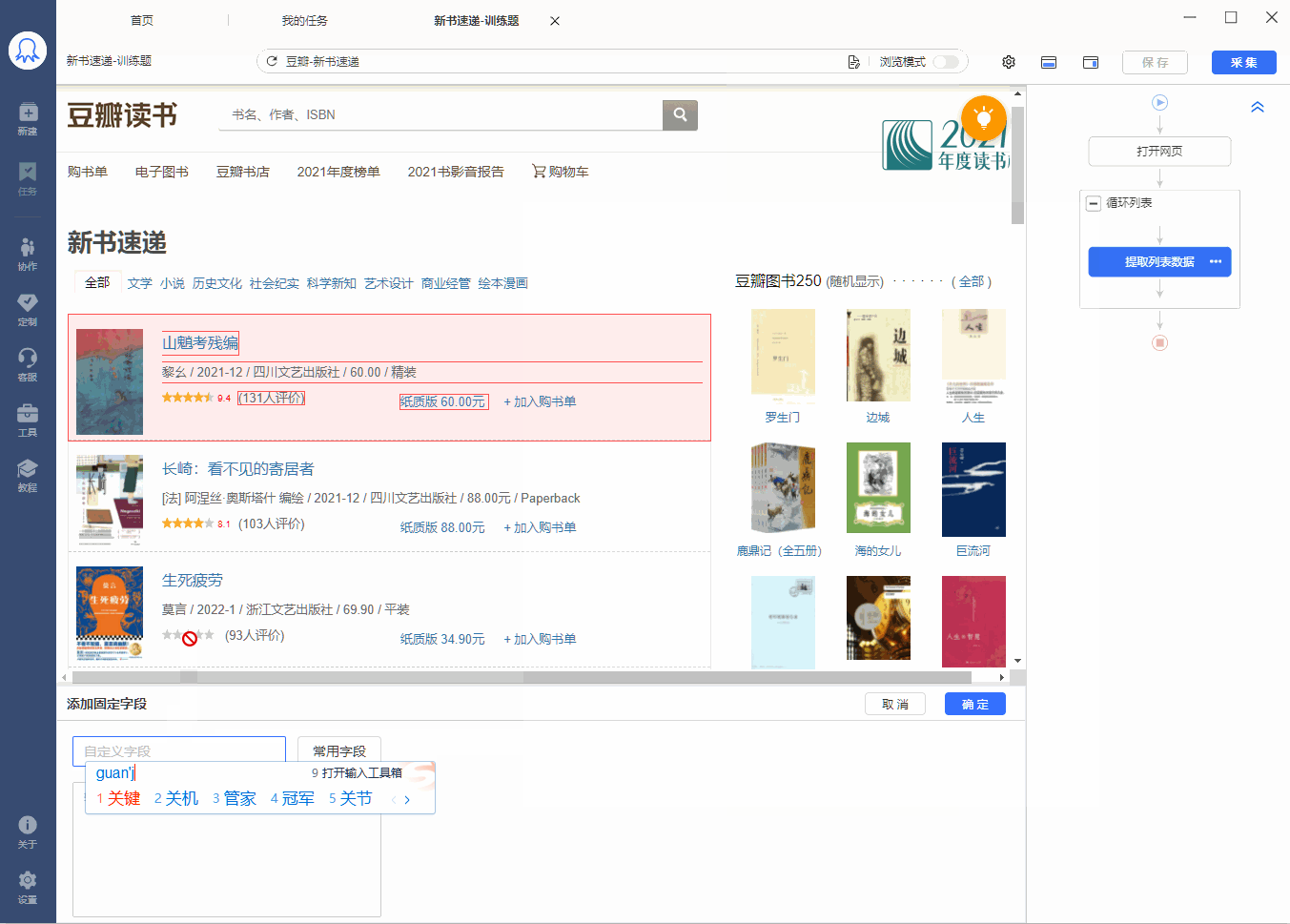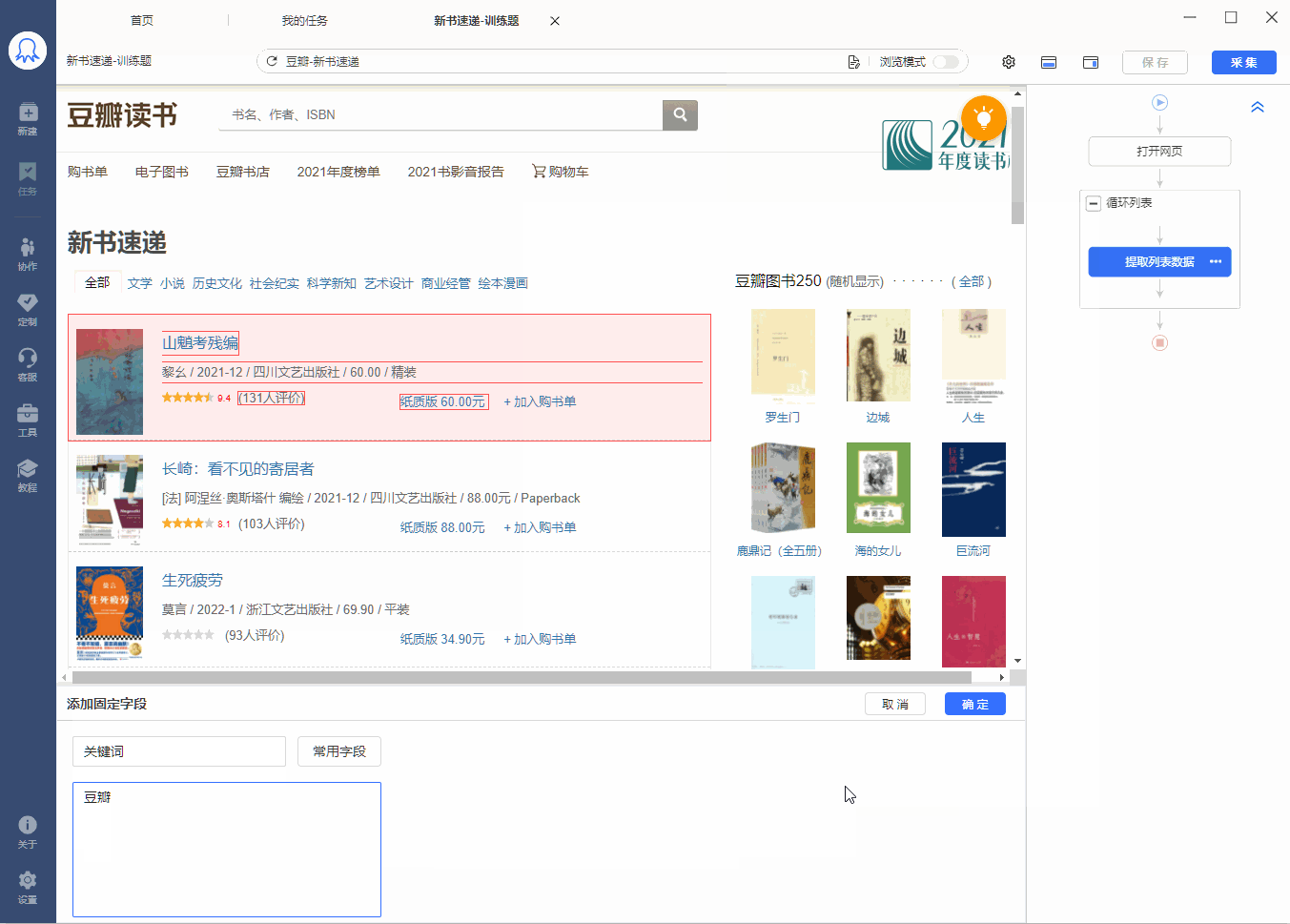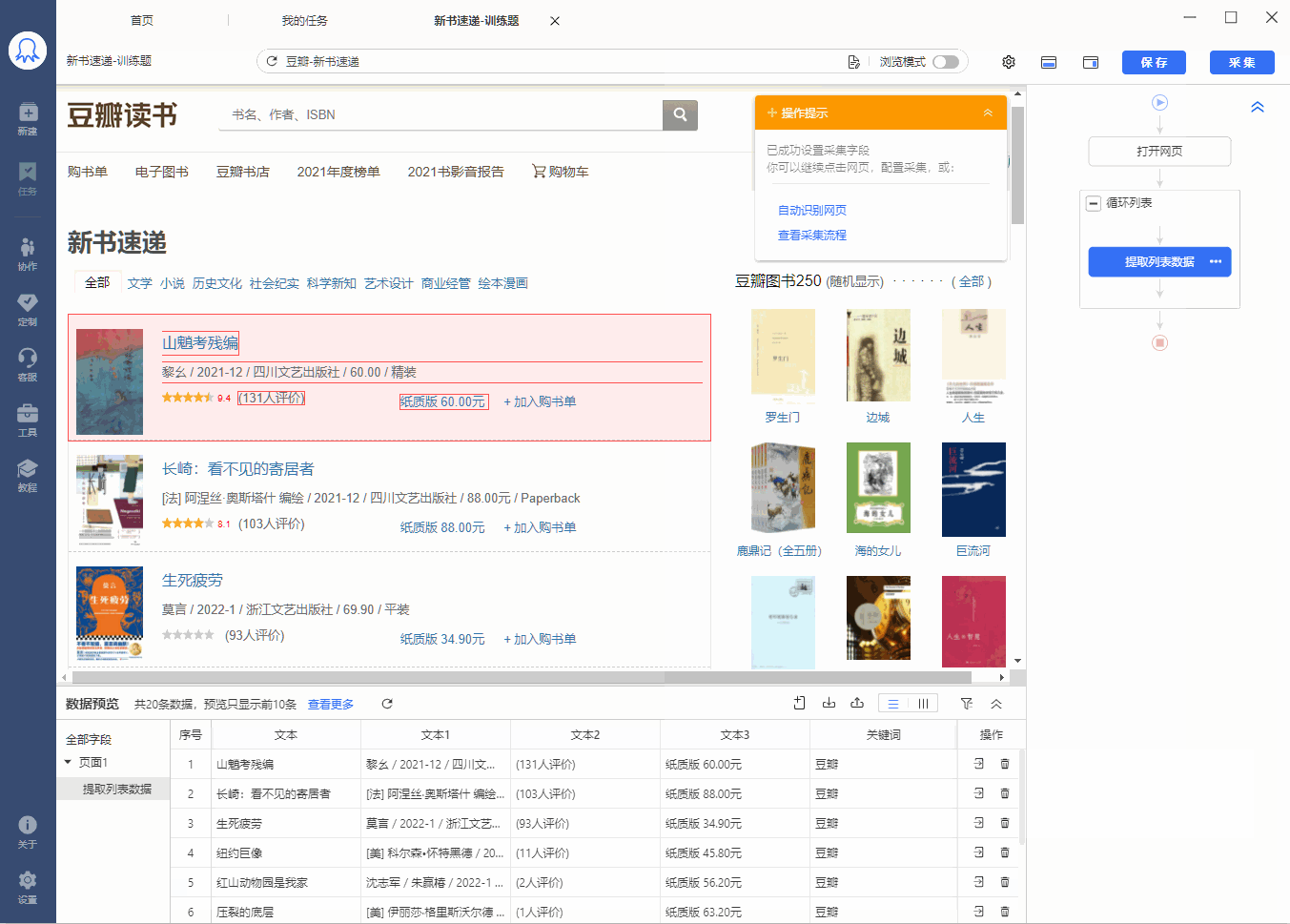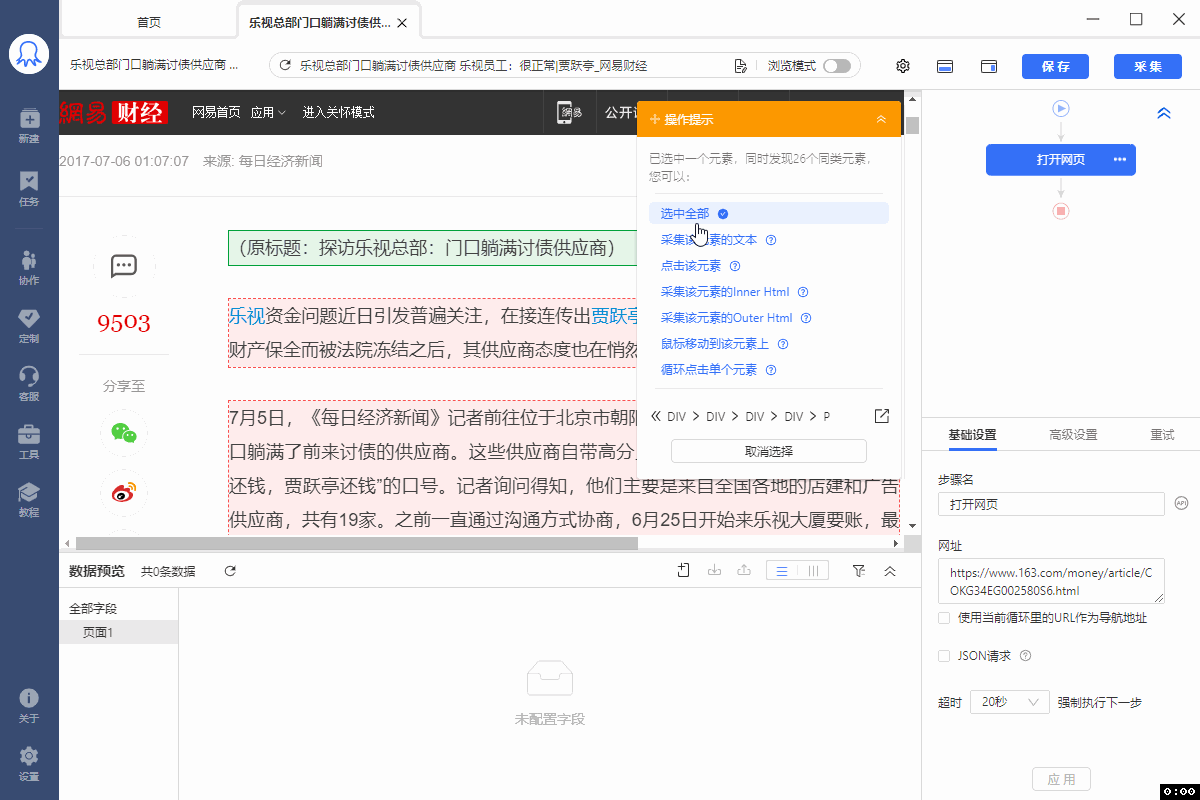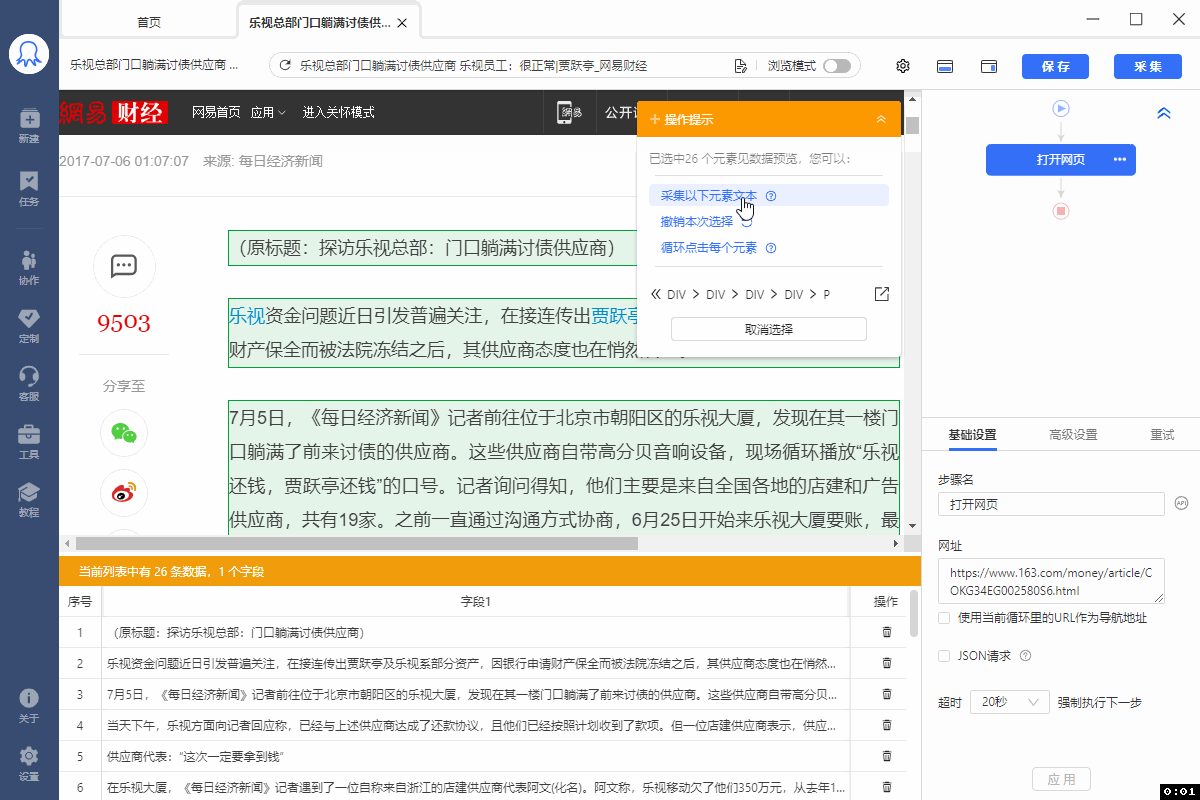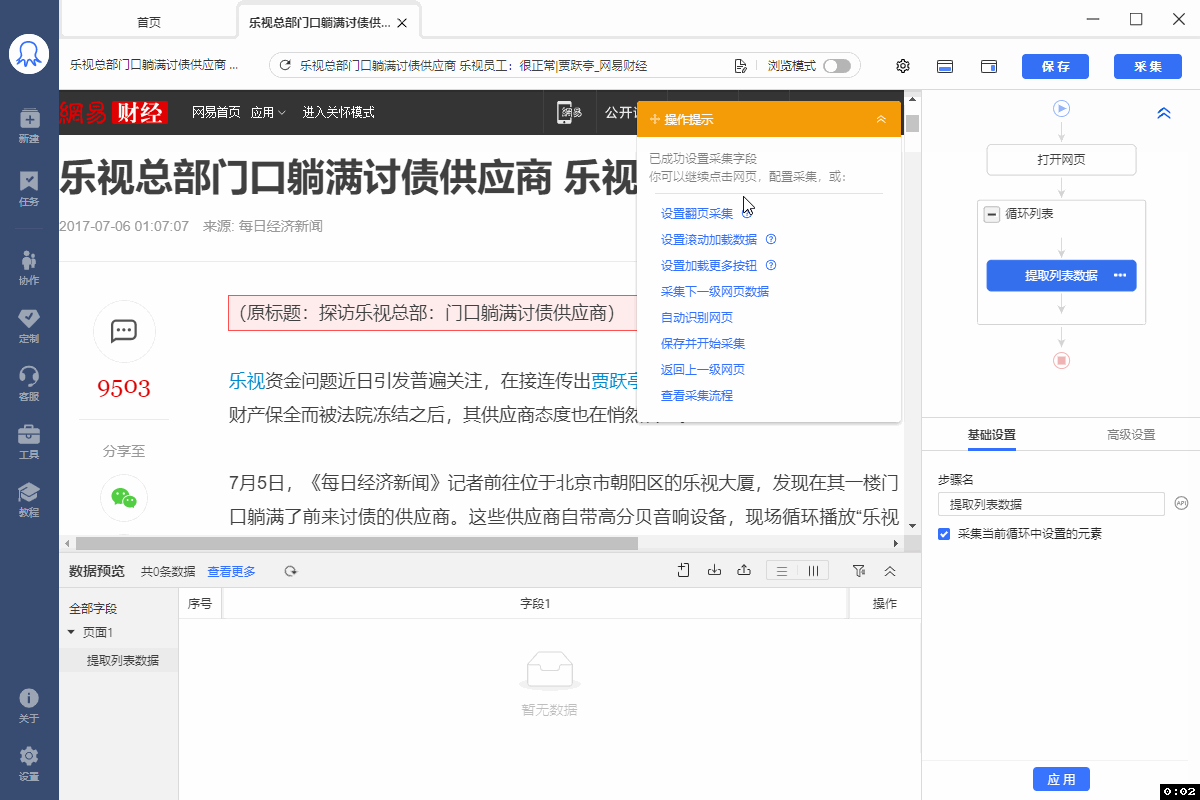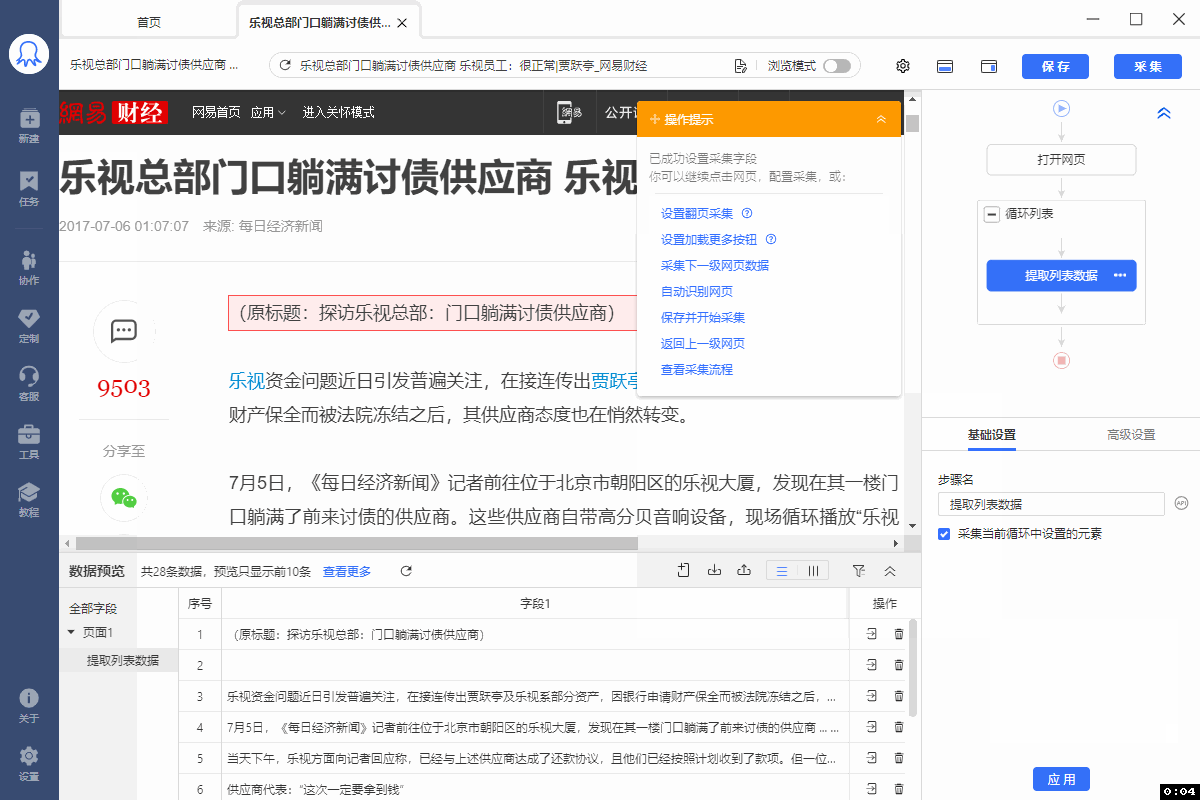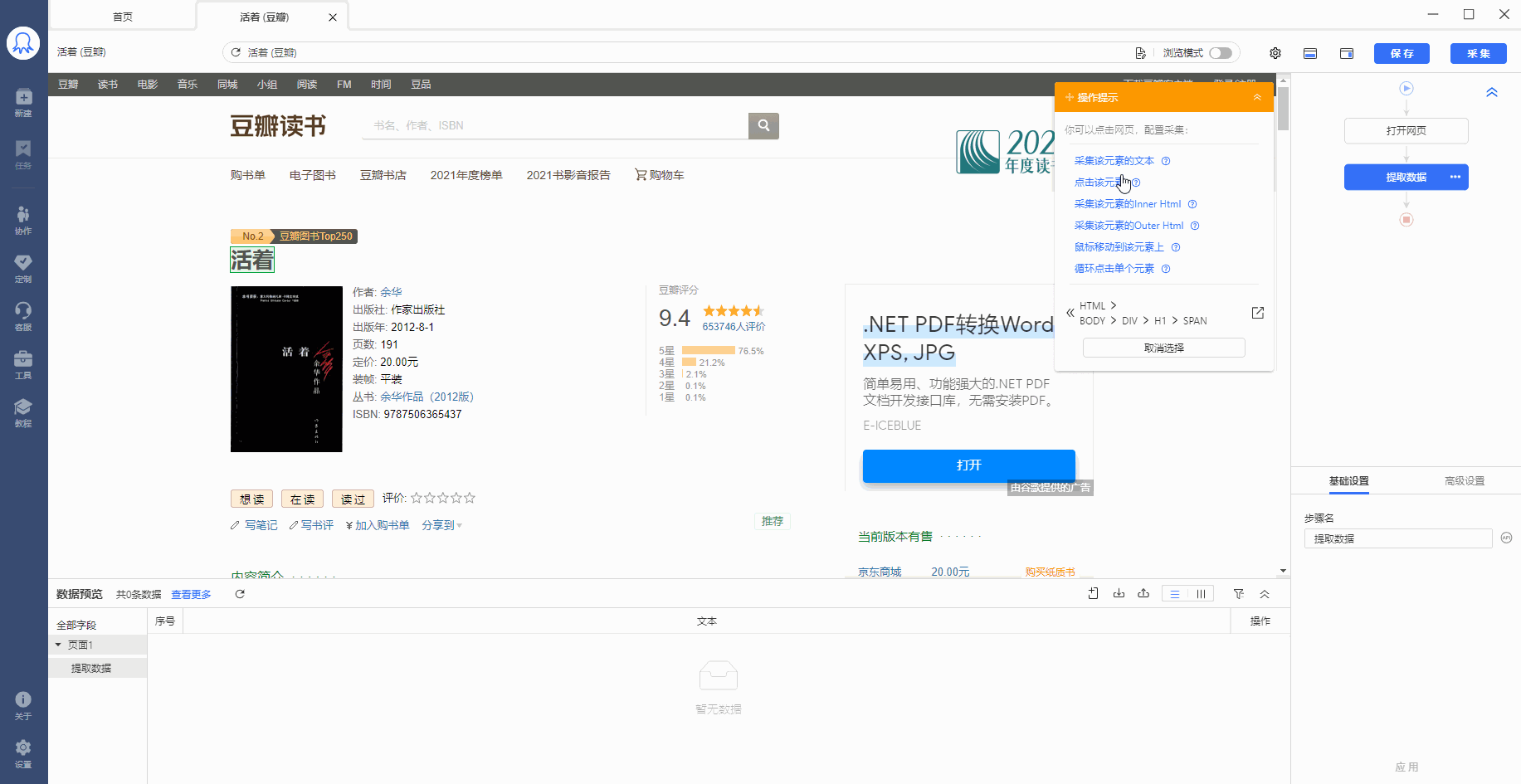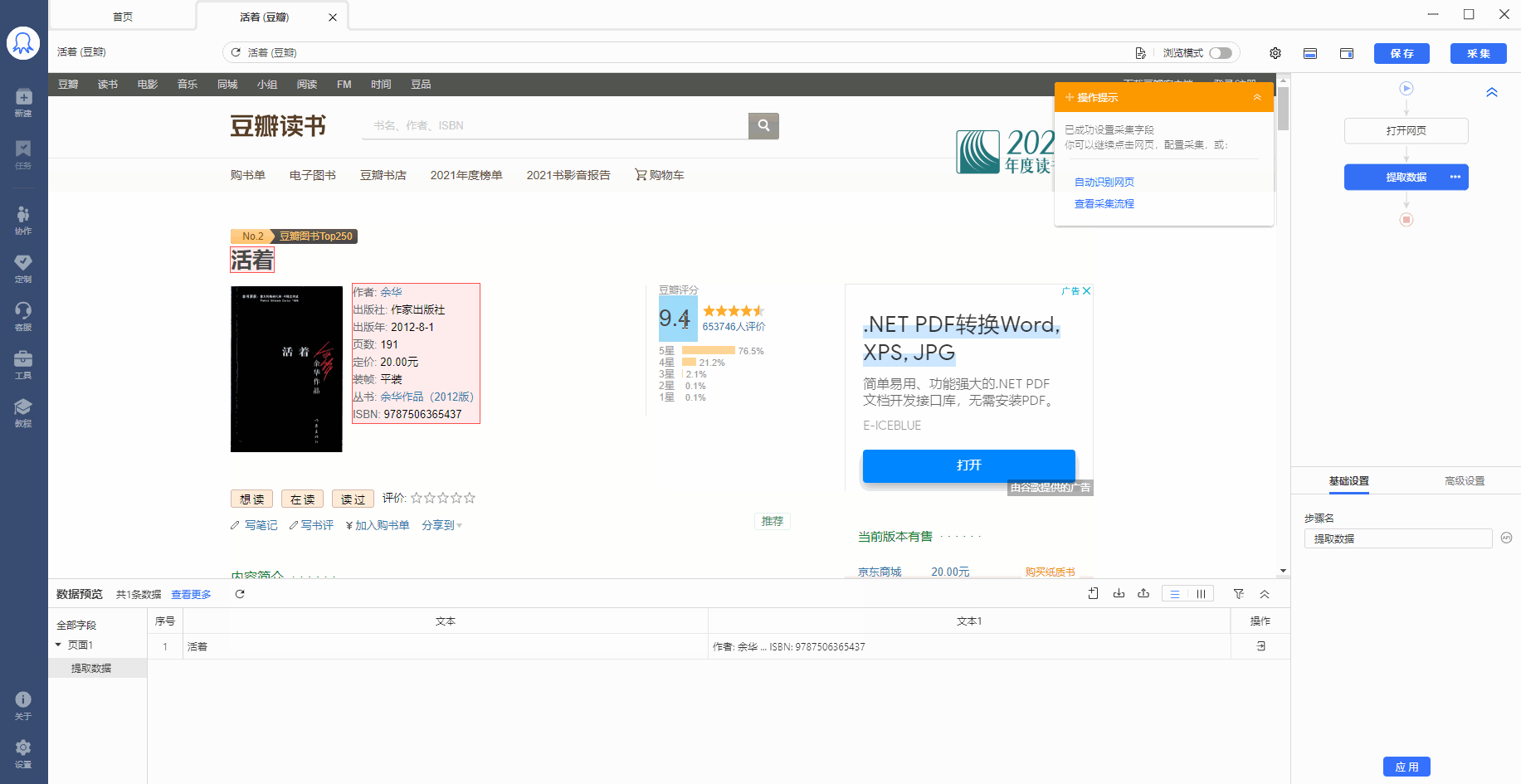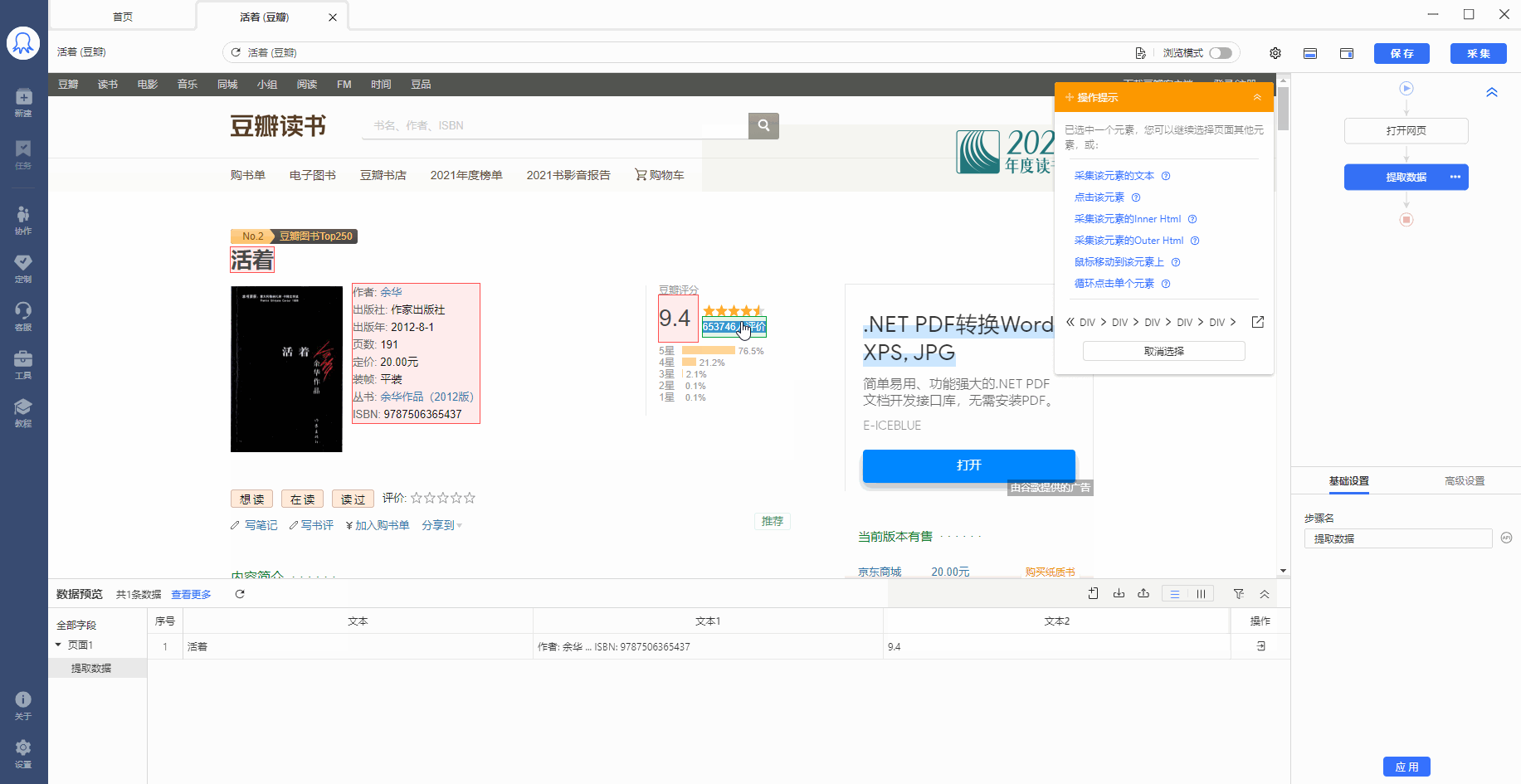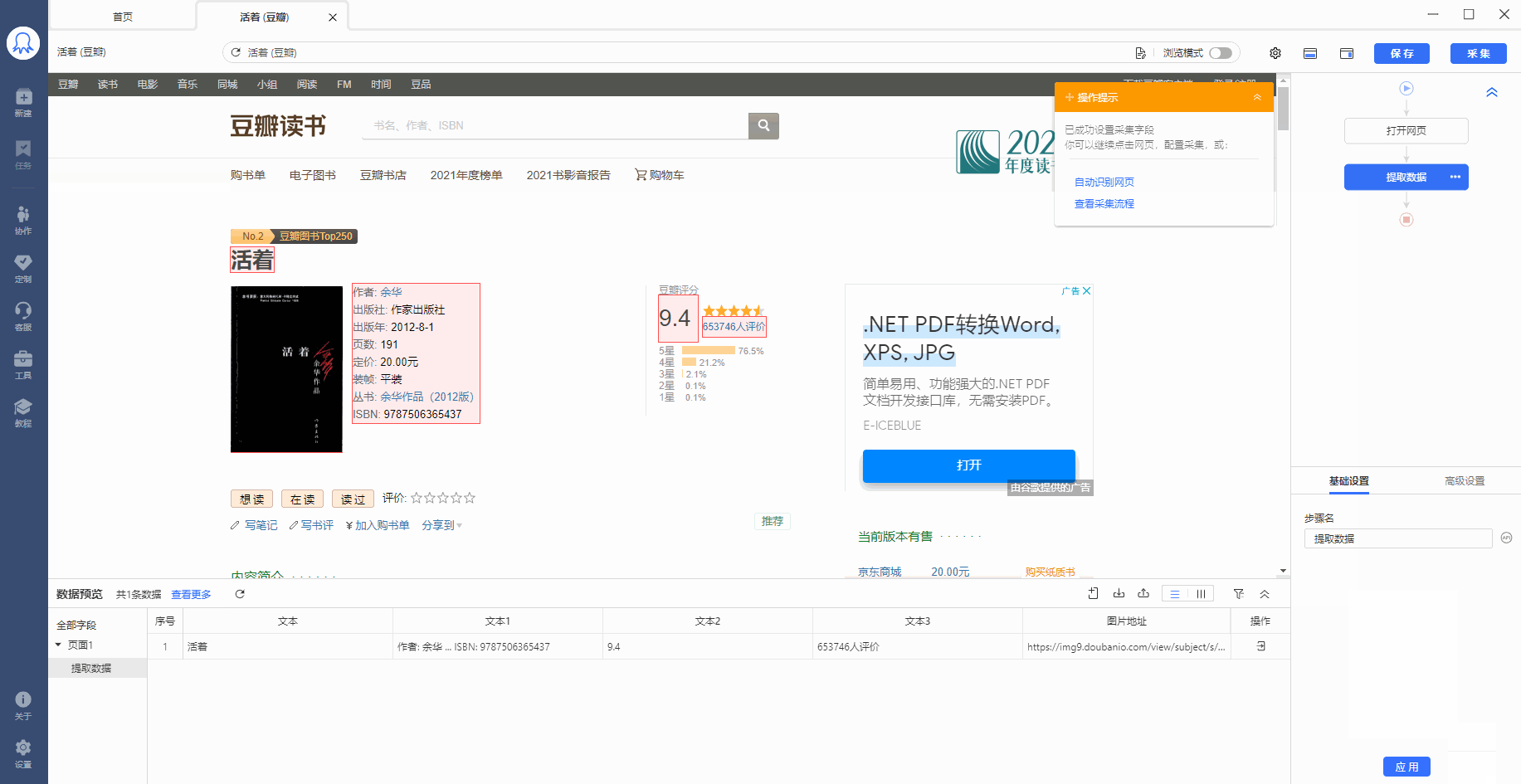
有的网页没有下一页按钮,但是有【加载更多】或【再显示20条】等按钮,通过不断点击这些按钮,可以实现翻页,加载出新数据。 像 搜狗微信首页 、微博评论 等页面都是这种情况。 针对这类网页,使用智能识别和自行配置的采集规则,都能实现翻页,具体设置方法如下: 1、智能识别实现【点击加载更多翻页】 示例网址如:https://weixin.sogou.com/ 八爪鱼的智能识别,支持【加载更多内容】这种翻页的智能识别,如下图所示: 在 新手入门第8课:采集原理与流程执行逻辑 中,我们讲过,流程的执行…
有的网页无下一页按钮,通过点击数字进行翻页,示例网址如:http://stock.cngold.org/news/ 使用智能识别和自行配置的采集规则,都能实现点击数字进行翻页,具体设置方法如下: 1、使用智能识别实现【数字翻页】 八爪鱼的智能识别,支持【数字翻页】的智能识别,如下图所示: 2、自己配置采集流程实现【数字翻页】 如果想了解背后的原理,我们可以来尝试自己配置这类网页的采集流程。 让八爪鱼不断点击数字进行翻页:当前页是第1页,点第2页;当前页是第2页,点第3页.......当前页是最后…

有很多网站,通过点击【加载更多】或【再显示20条】等按钮进行翻页。像 搜狗微信首页 、微博评论 等页面都是这种情况。 针对这种网页,八爪鱼V8.4.0版本新增【边点击边采集】功能,可以边点击【加载更多按钮】,加载出新数据,边采集每次加载的新数据。 例:设置点击20次,则点击1次后,采集第1次点击后加载的数据,继续点击第2次,采集第2次点击后加载的数据.......直至点击20次,采集第20次点击后加载的数据。 使用智能识别和自行配置的采集规则,都能实现【边点击边采集】,具体设置方法如下。 一、使用智…