
网页上的数据类型十分丰富:文本、图片、链接、源码等。在数据采集过程中,不同类型的数据类型,对应的抓取方式是不同的。本文将讲解常见的数据类型与其抓取方式。
示例网址:https://movie.douban.com/explore#!type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0
1、抓取文本:抓取显示在页面中的文本
操作:鼠标选中页面中的文本,在弹出的操作提示框中选择【采集该元素的文本】,目标文本就被采集下来了。
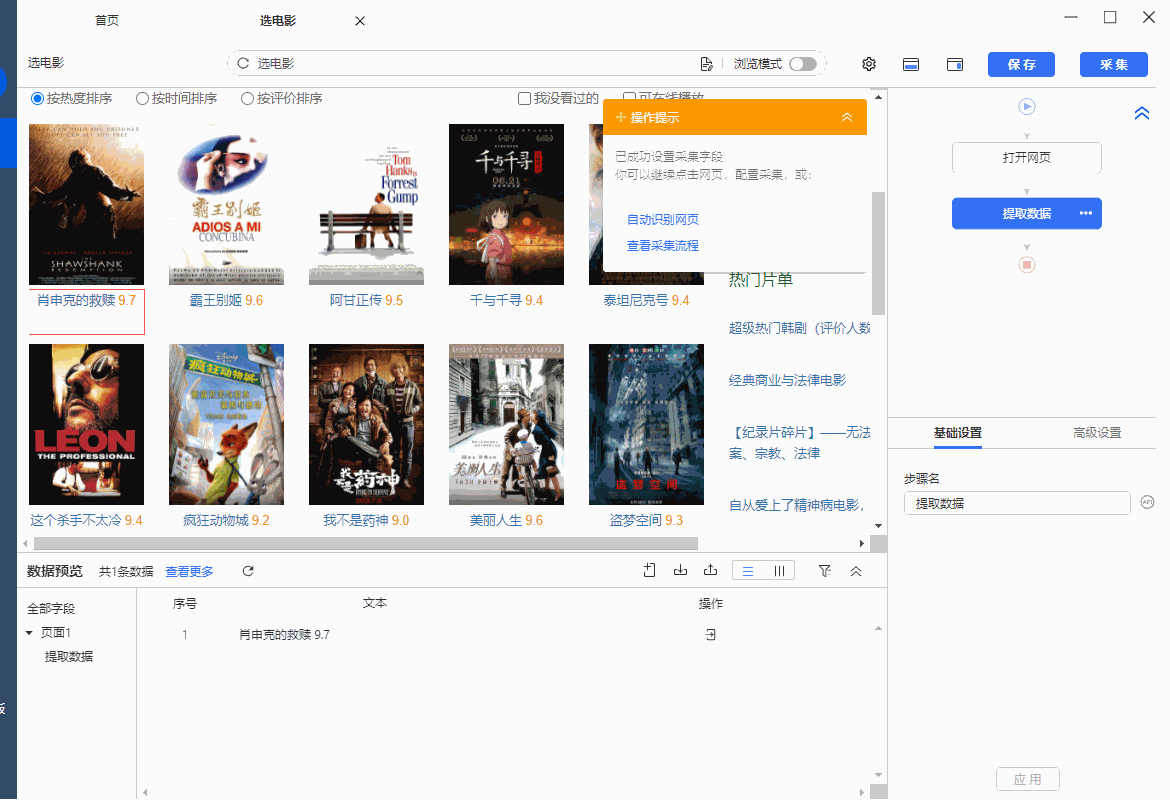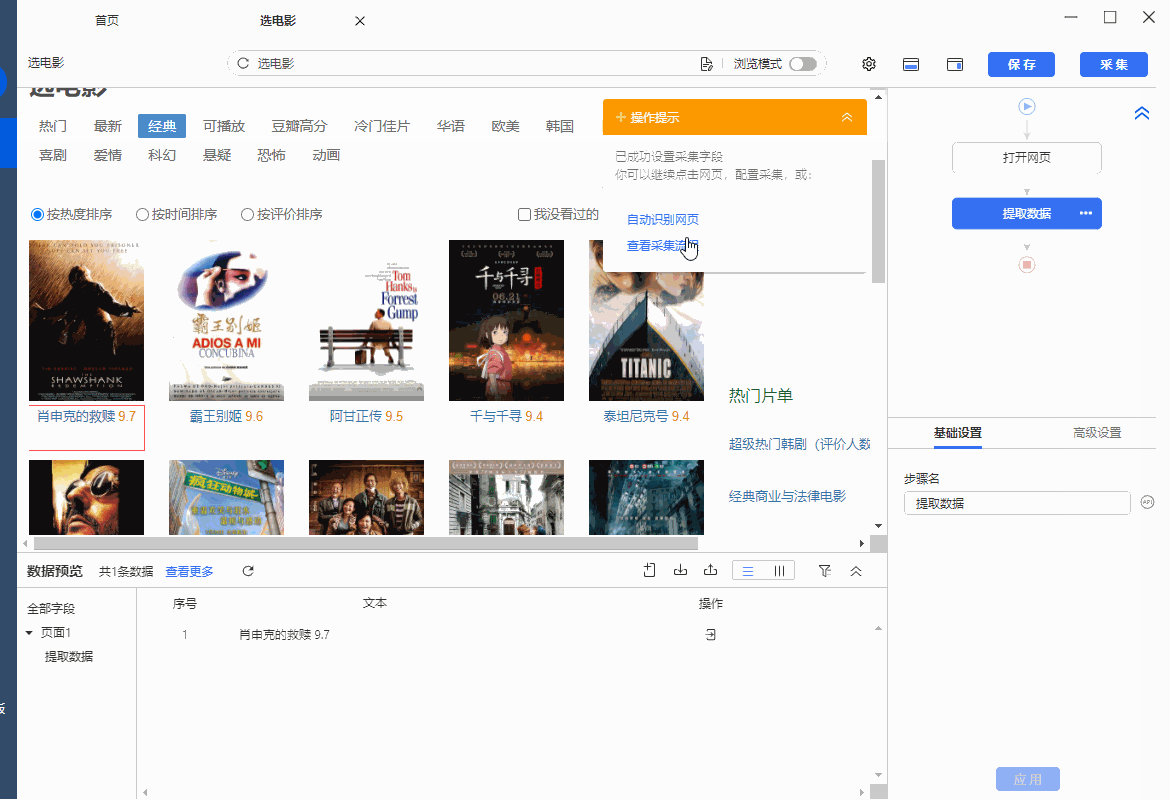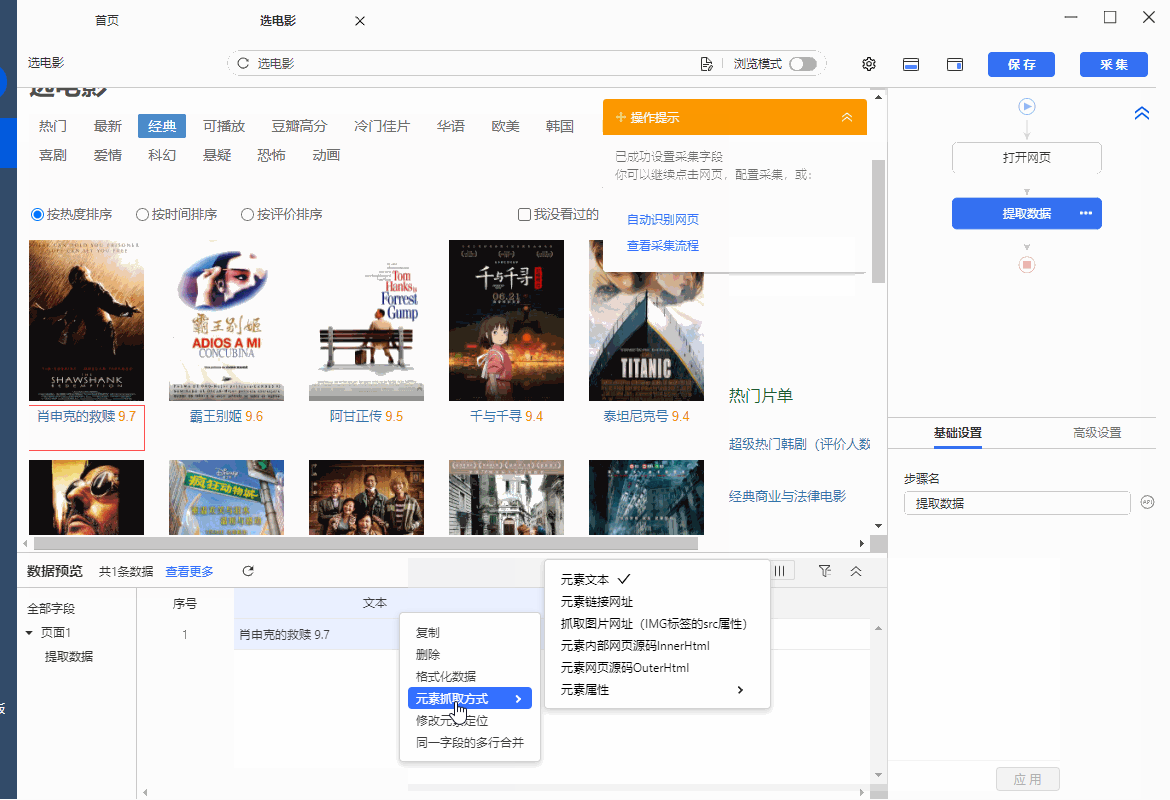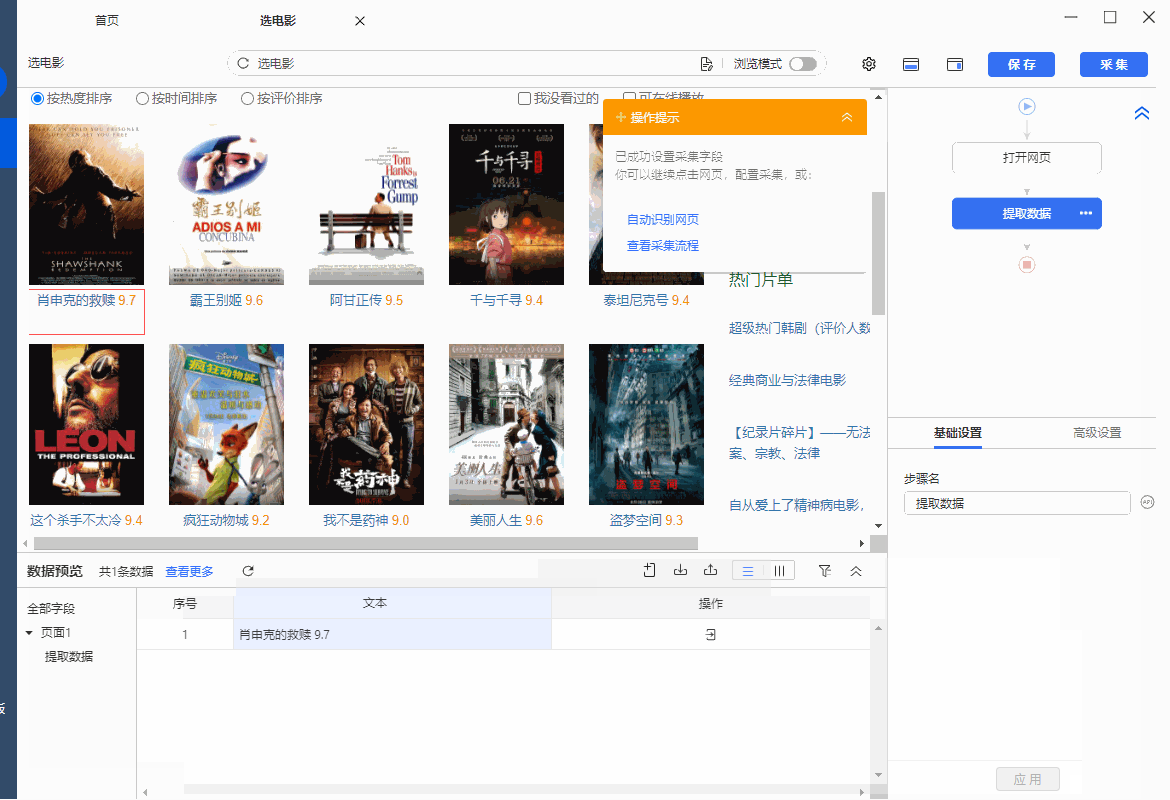
同时,将鼠标移动到字段名【文本】上,点击 进入本行预览,点击
进入本行预览,点击  按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【元素文本】。
按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【元素文本】。
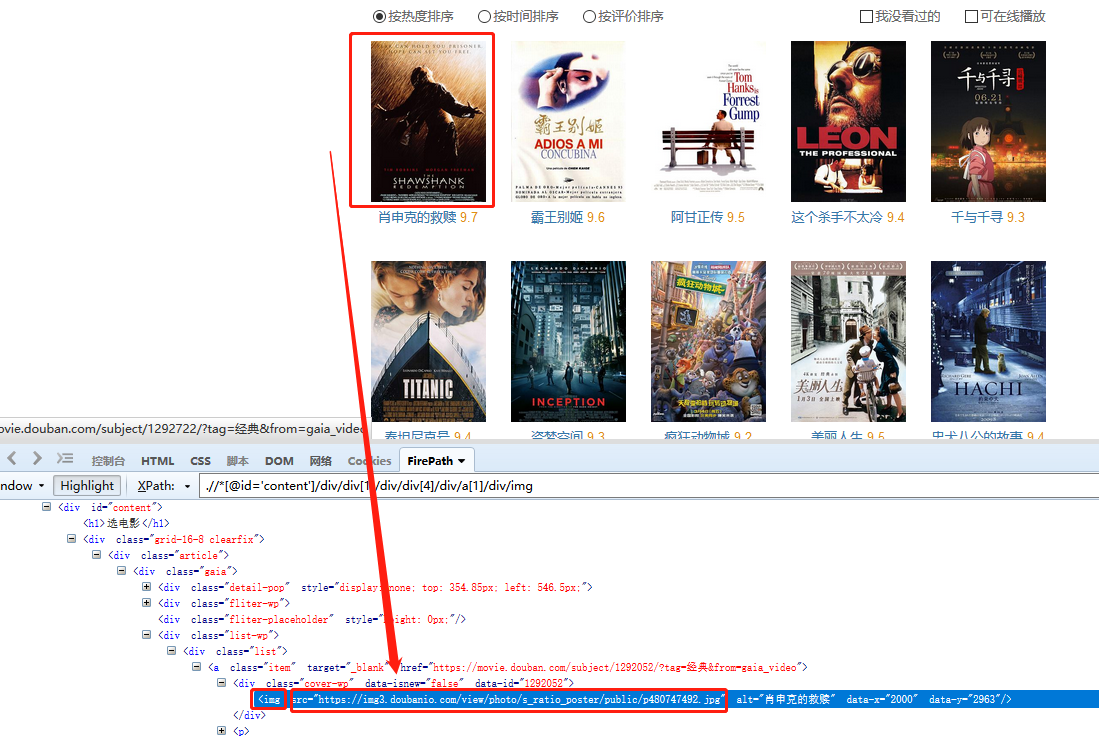
2、抓取图片网址:抓取图片的网址
操作:鼠标选中页面中的图片,在弹出的操作提示框中选择【采集该图片地址】,图片网址就被提取下来了。
同时,将鼠标移动到字段名【图片地址】上,点击 按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【抓取图片网址(IMG标签的src属性)】。
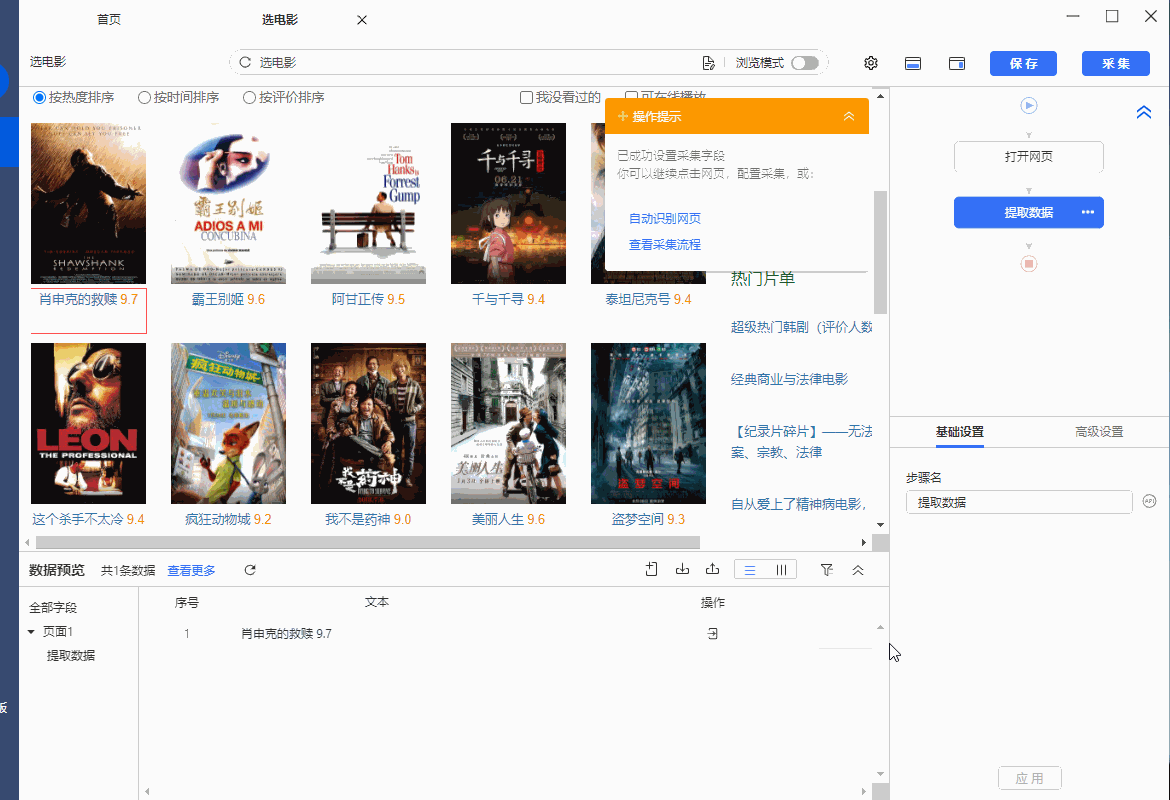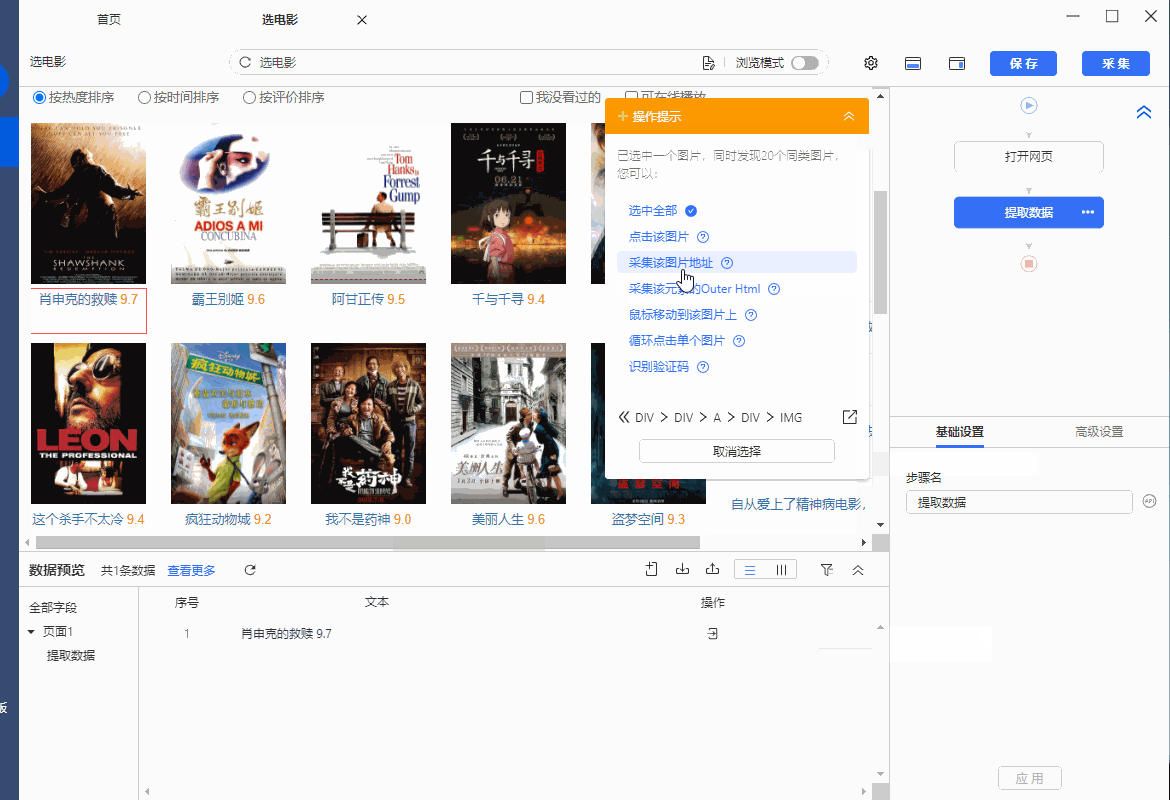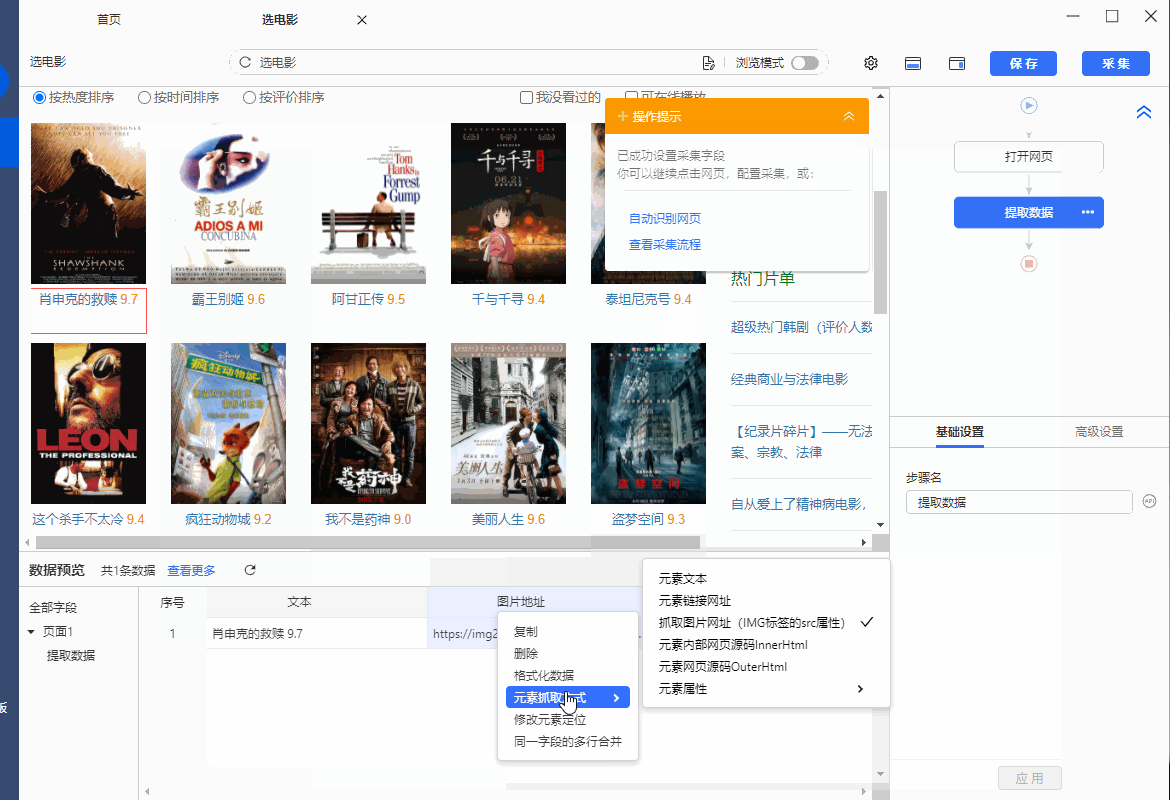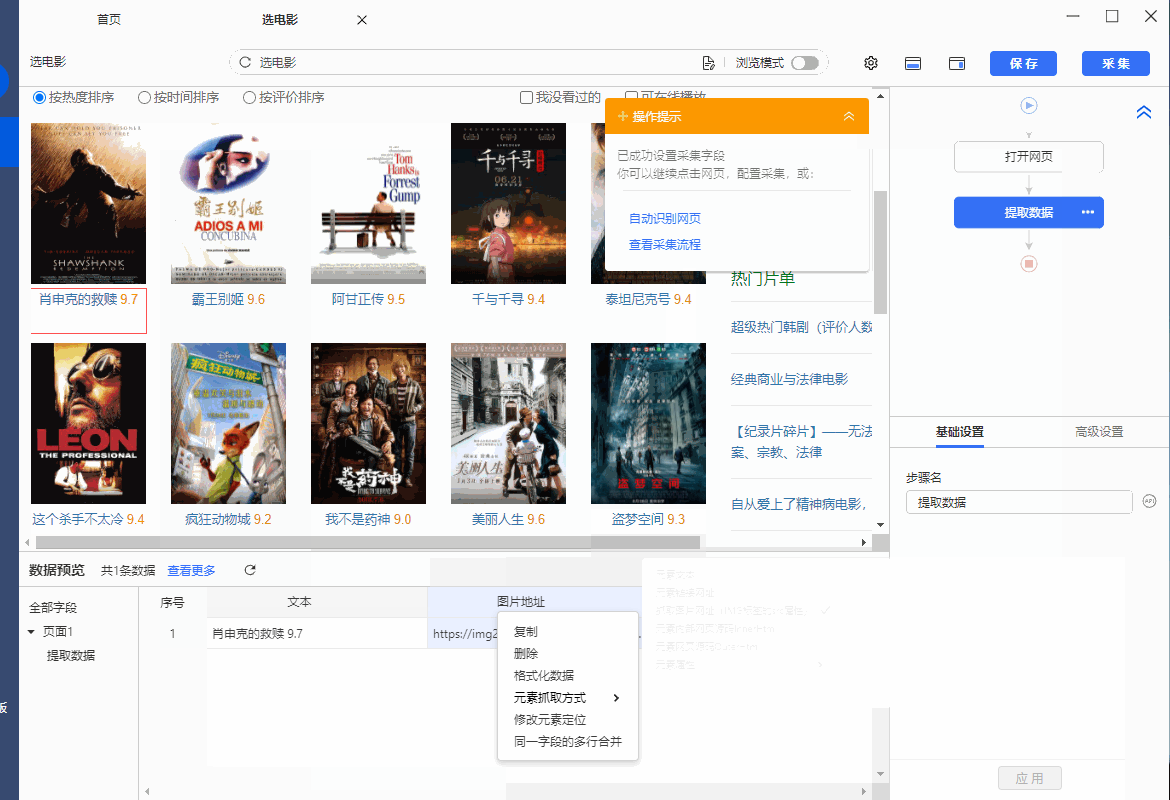
为什么是【IMG标签的src属性】?在 XPath教程 中,我们讲过网页Html相关知识,网页上的图片一般都是用IMG标签表示,其图片地址会放在IMG标签的src属性中。
所以,当我们要提取图片网址时,本质上是用XPath定位到Img标签,再从IMG标签中提取src属性,src属性的值,就是图片网址。
这里演示的只是抓取图片时使用的抓取方式,具体的图片采集,请看教程:图片采集与下载到本地
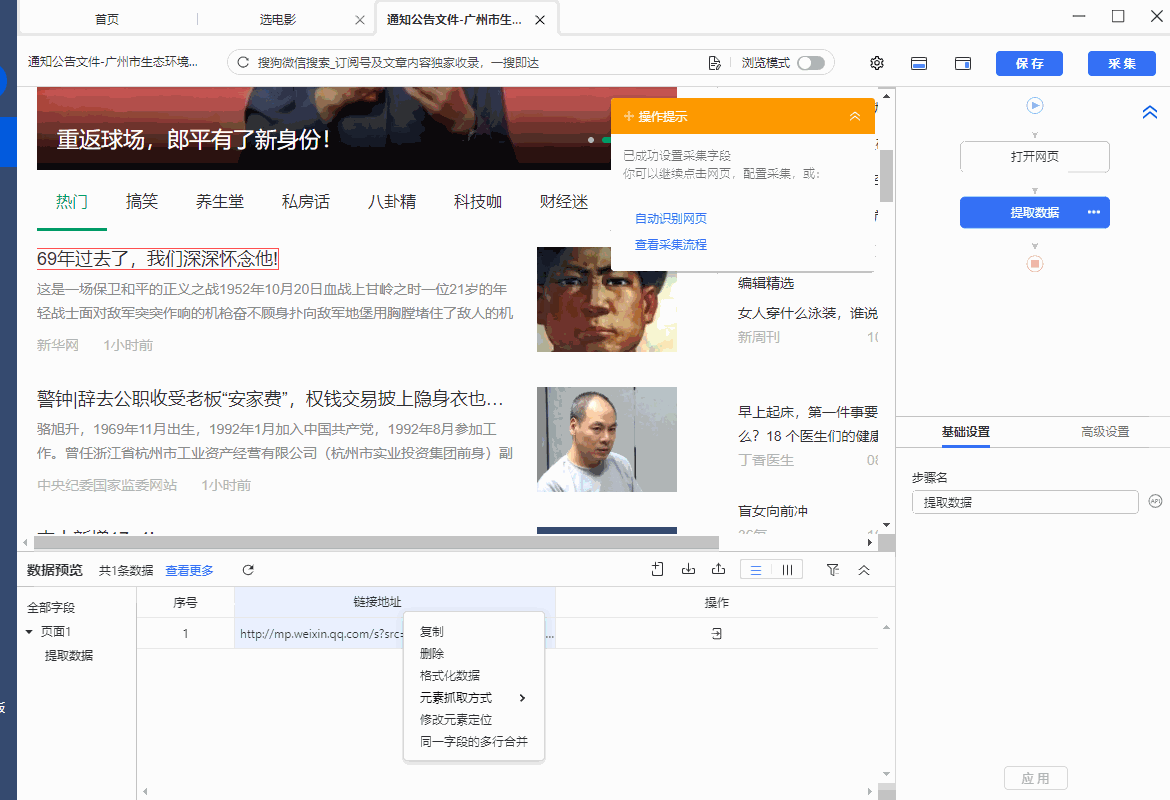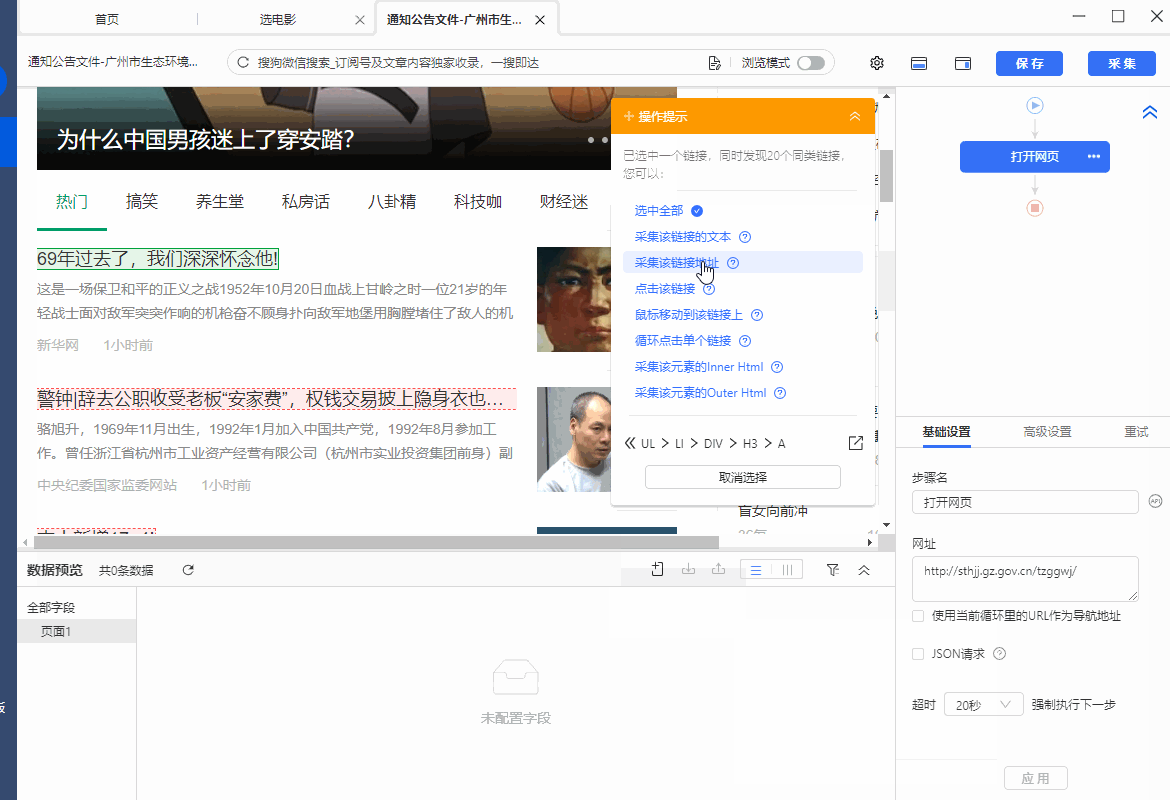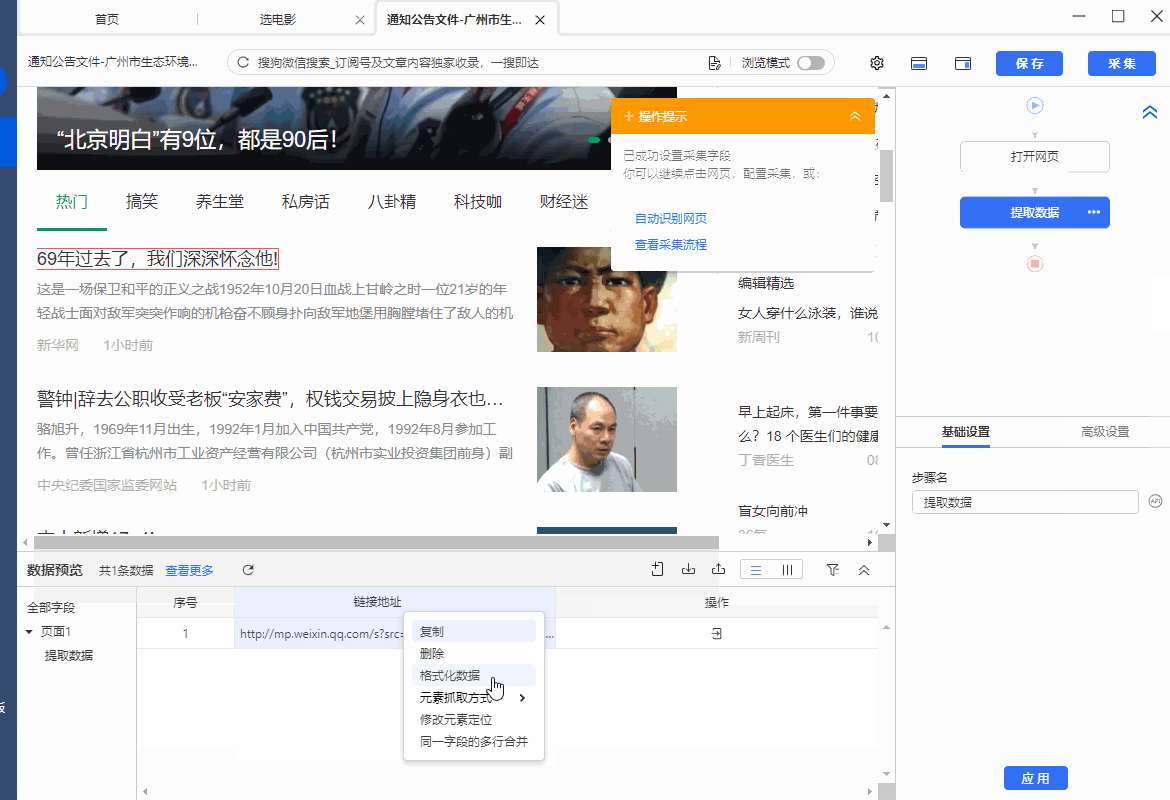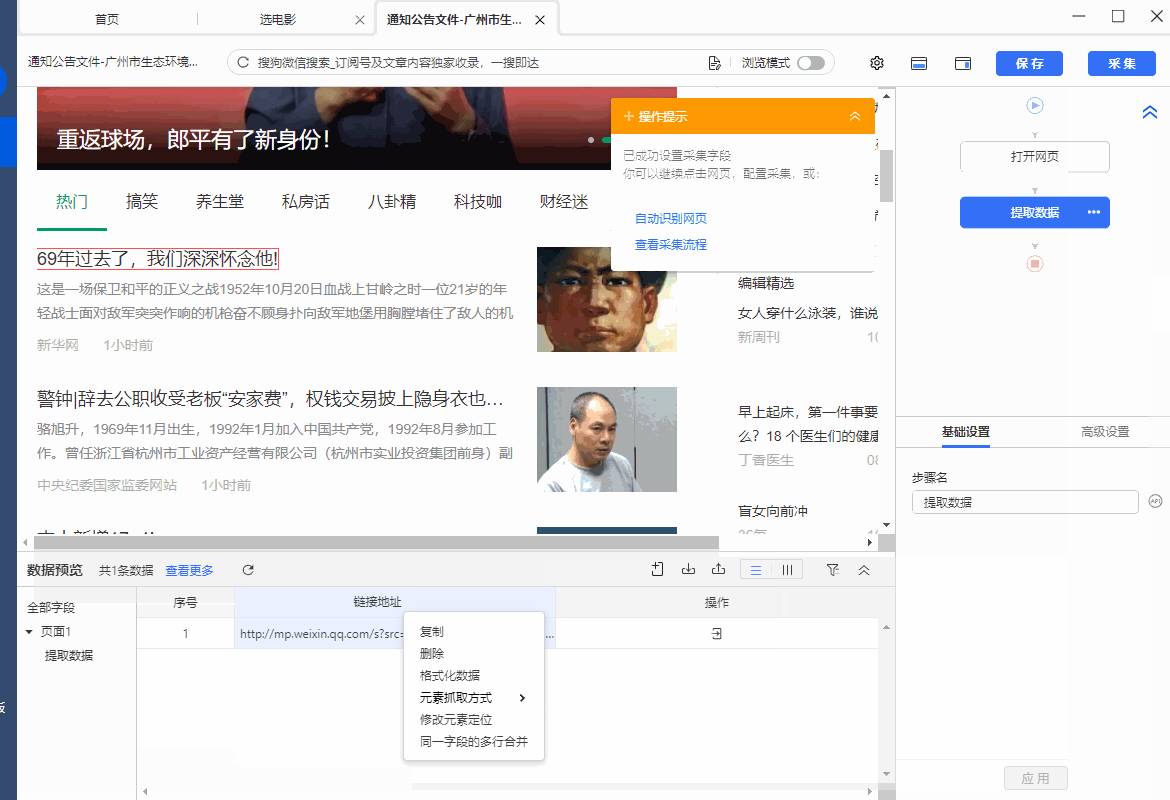
3、抓取链接网址,抓取网页上超链接的网址
示例网址:https://weixin.sogou.com/为例
操作:鼠标选中页面中的超链接(一般是放在标题文本、图片中,可点击跳转),在弹出的操作提示框中选择【采集该链接地址】,超链接的网址就被提取下来了。
同时,将鼠标移动到字段名【链接地址】上,点击 按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【元素链接网址】。
在 XPath教程 中,我们讲过网页Html相关知识,网页上的超链接一般都是用A标签表示,超链接会放在IMG标签的href属性中。
所以,当我们要提取超链接网址时,本质上是用XPath定位到A标签,再从A标签中提取href属性,href属性的值,就是超链接网址。
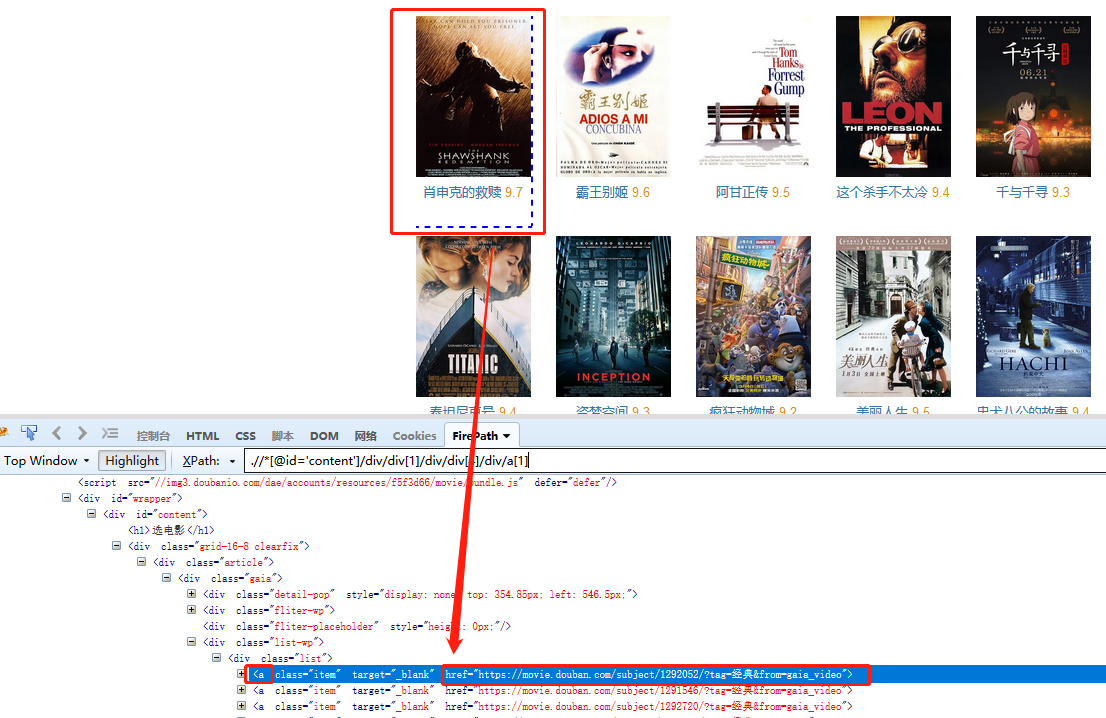
4、抓取输入框的值:抓取文本输入框中的文本
示例网址:
https://search.douban.com/movie/subject_search?search_text=%E9%9C%B8%E7%8E%8B%E5%88%AB%E5%A7%AC&cat=1002
操作:鼠标选中页面中文本输入框(文本输入已有输入值),在弹出的操作提示框中选择【采集该文本框的值】,文本输入框中的关键词就被提取下来了。
同时,将鼠标移动到字段名【文本框值】上,点击 按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【抓取值(INPUT标签的value属性)】。
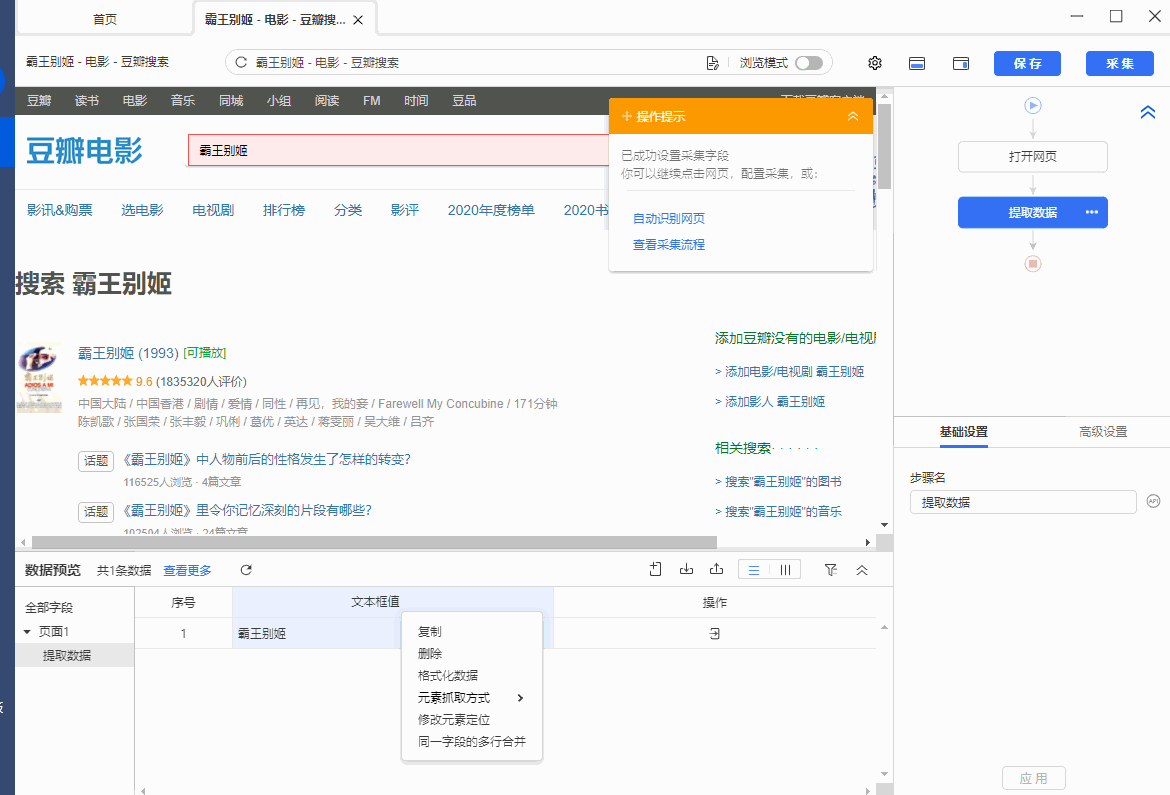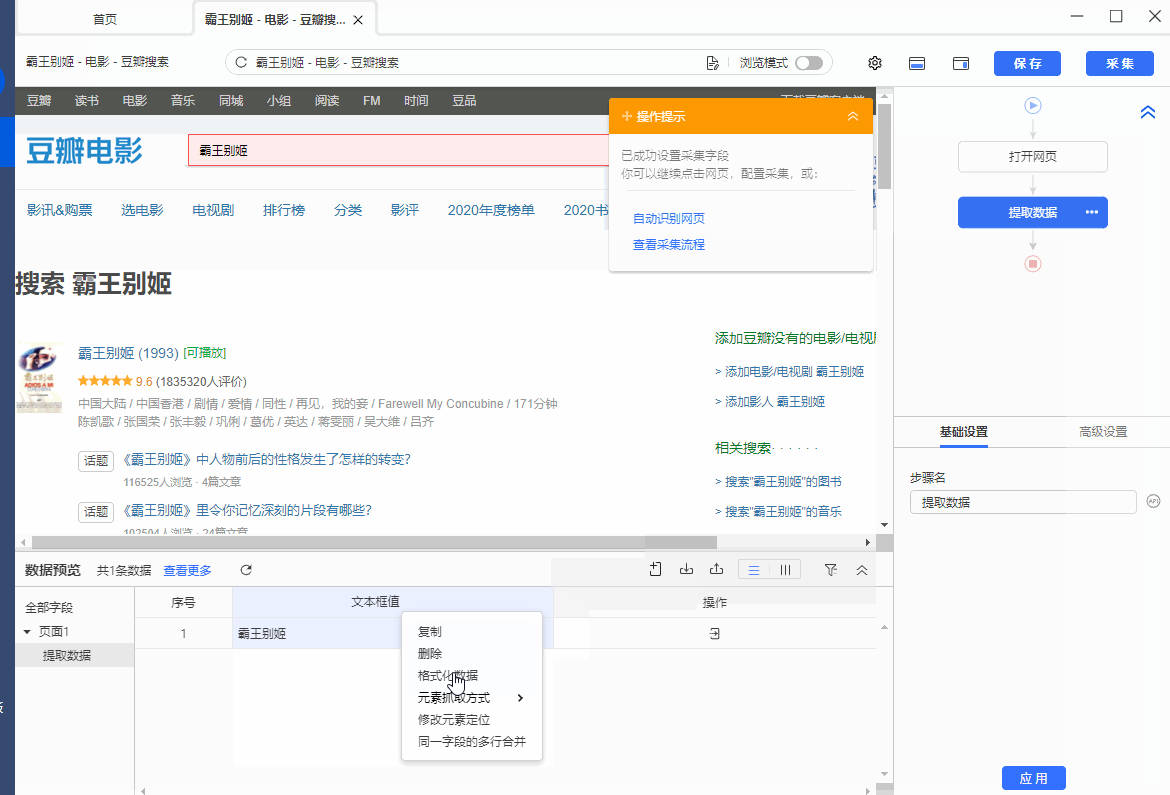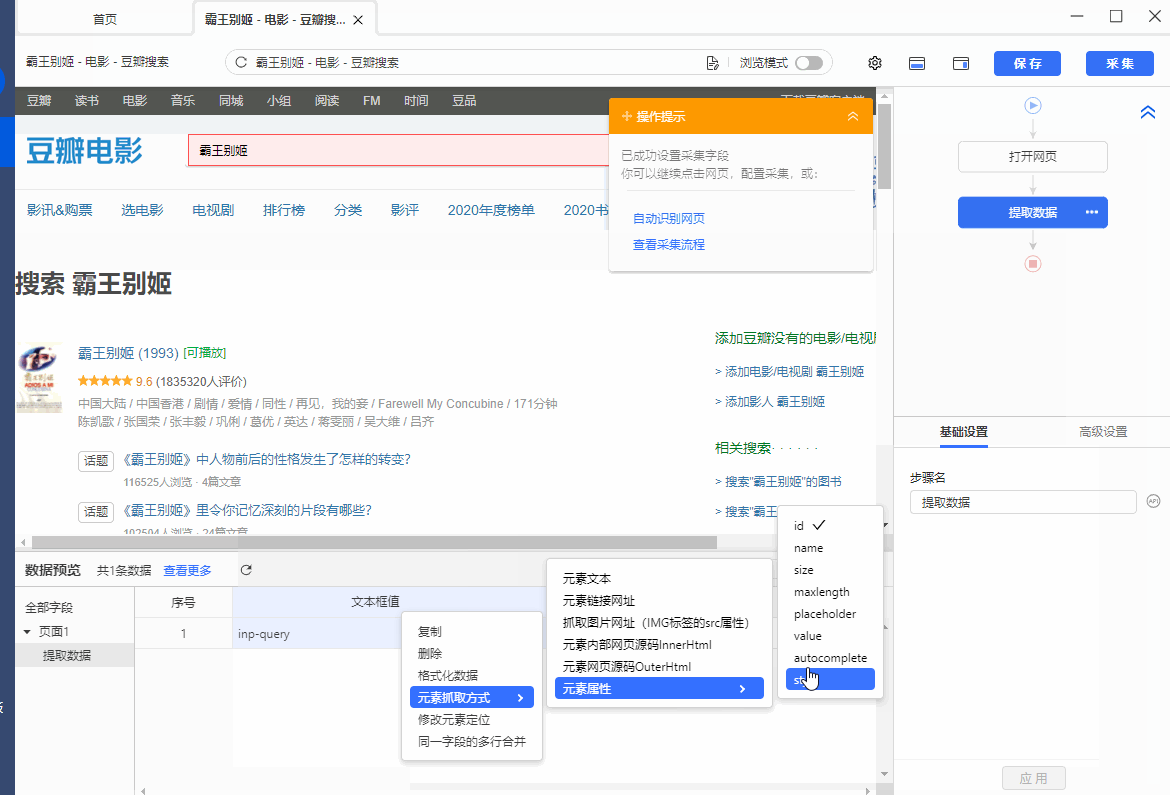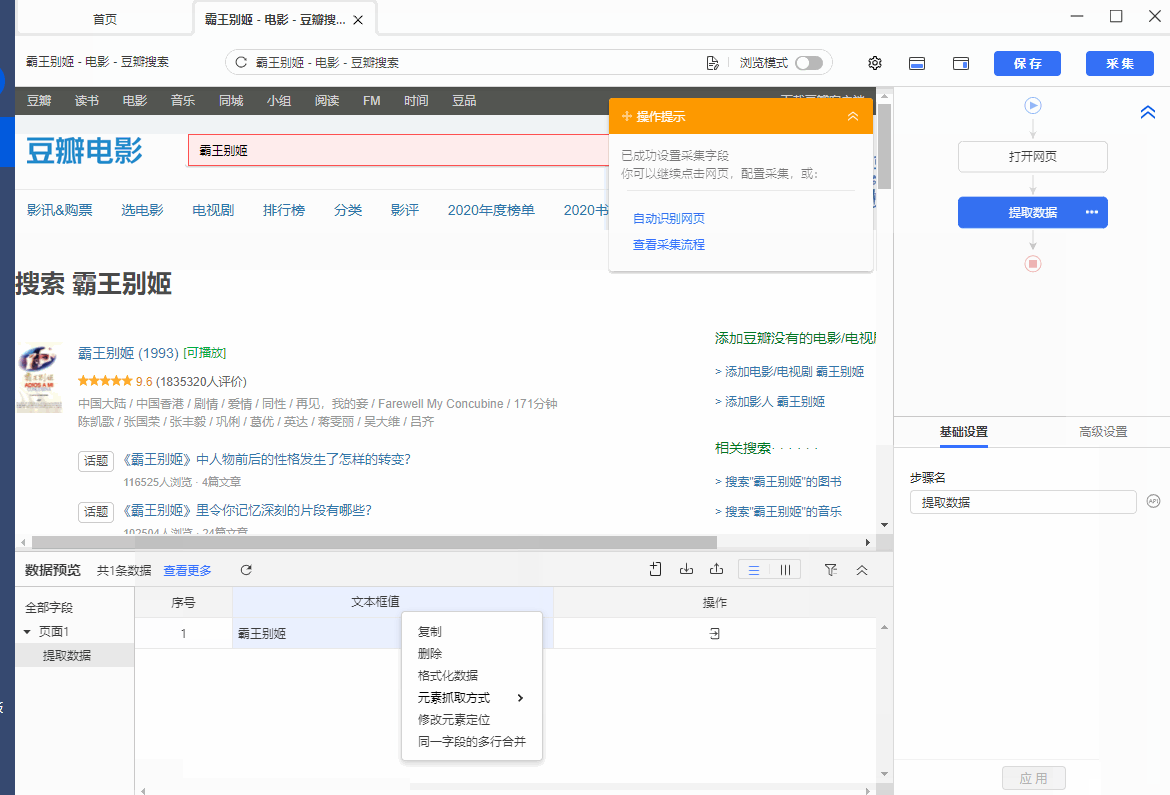
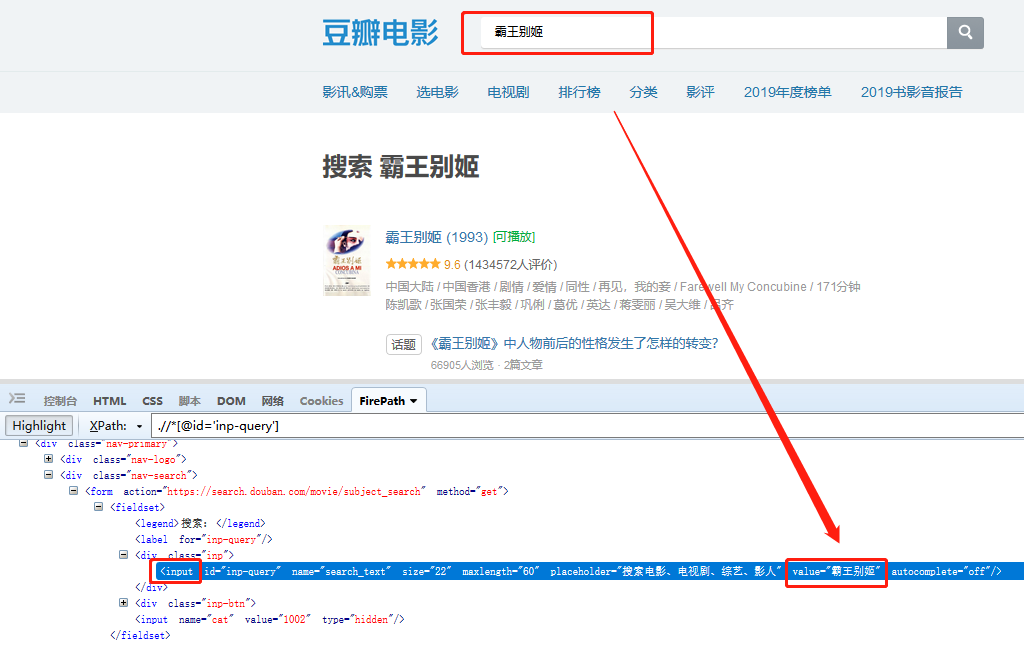
在 XPath教程 中,我们讲过网页Html相关知识,网页上的文本输入框一般都是用INPUT标签表示,在文本框中输入的关键词,会显示在INPUT标签的某个属性中。
所以,当我们要提取文本框中的关键词时,本质上是用XPath定位到INPUT标签,再从INPUT标签中提取指定属性,该属性的值,就是输入框中的关键词。
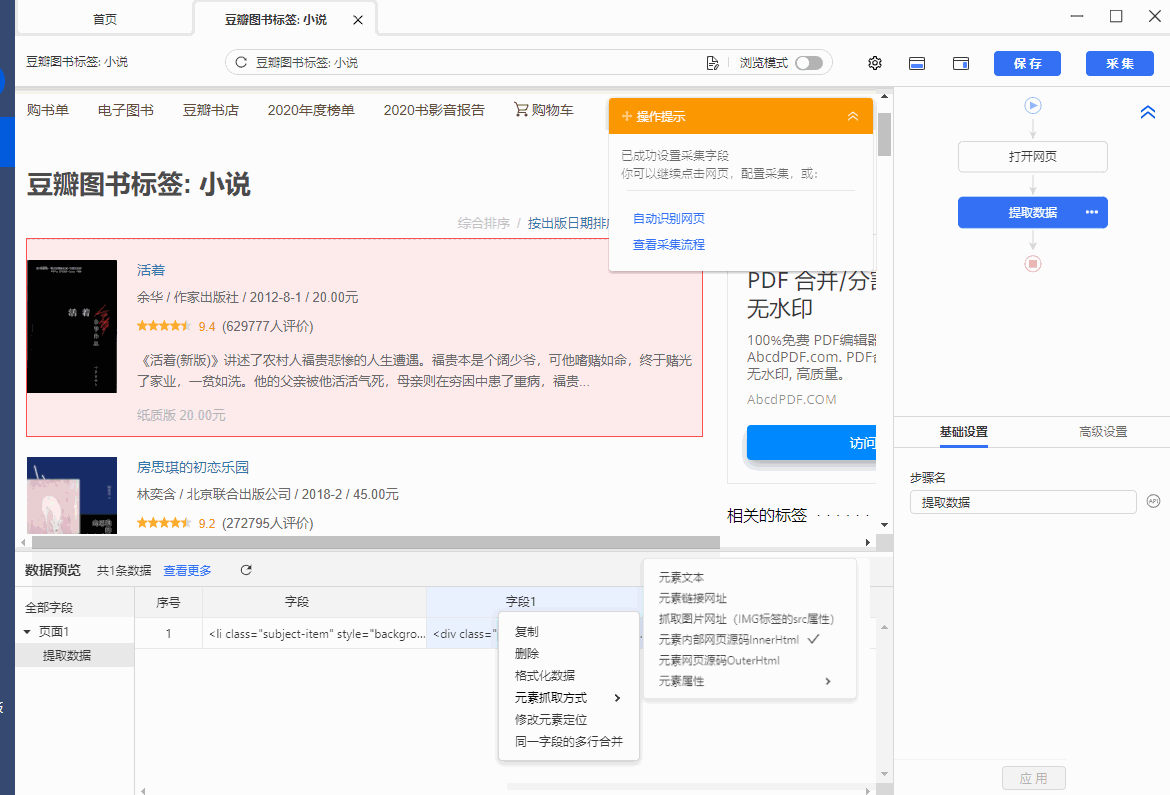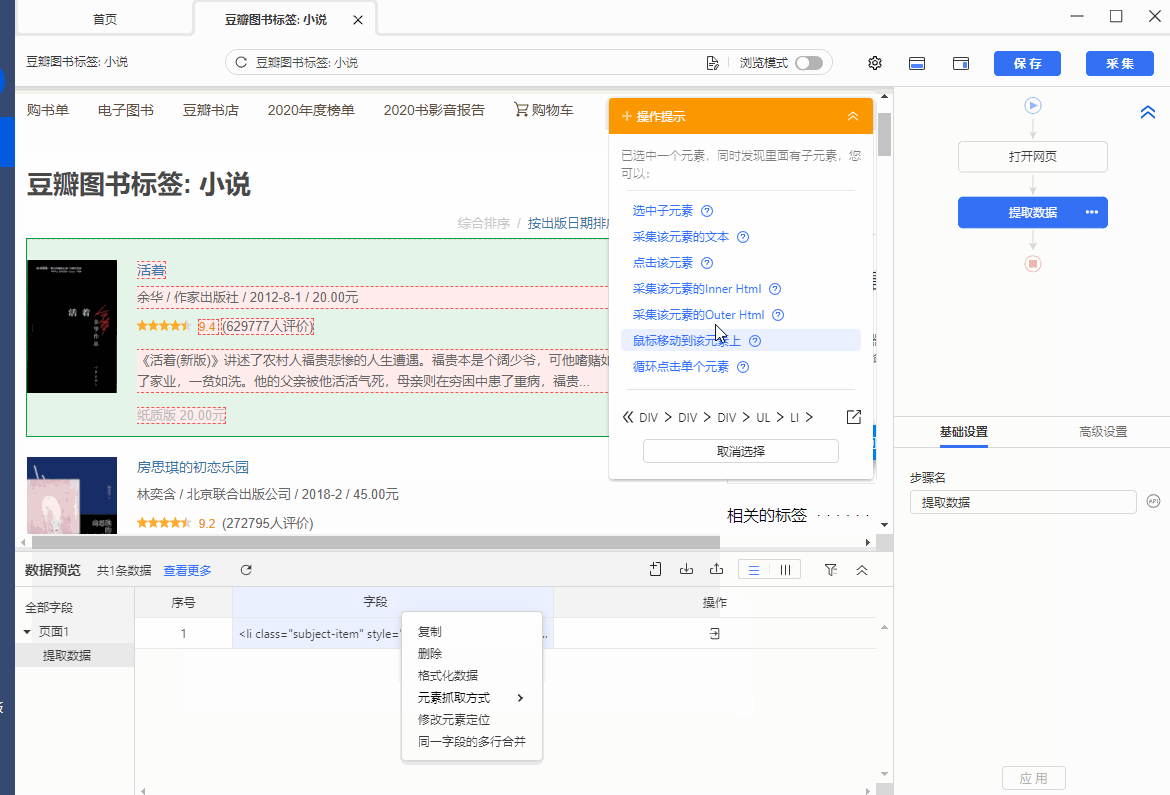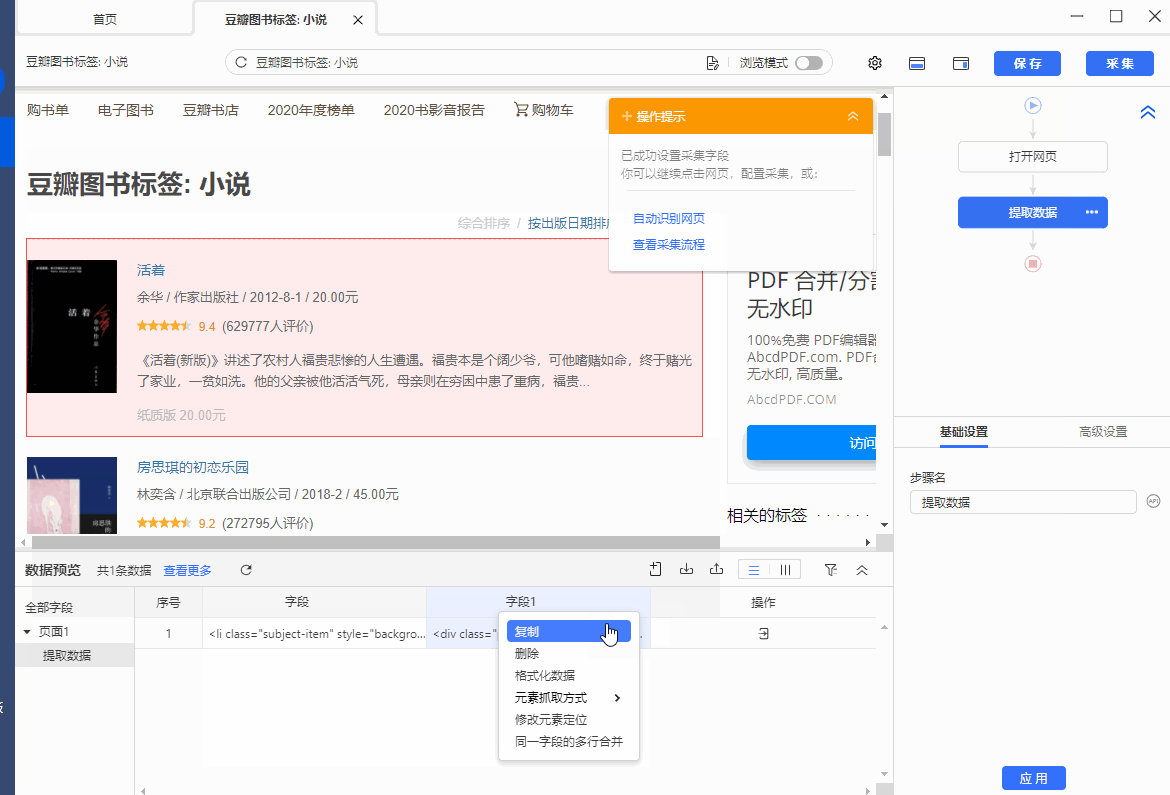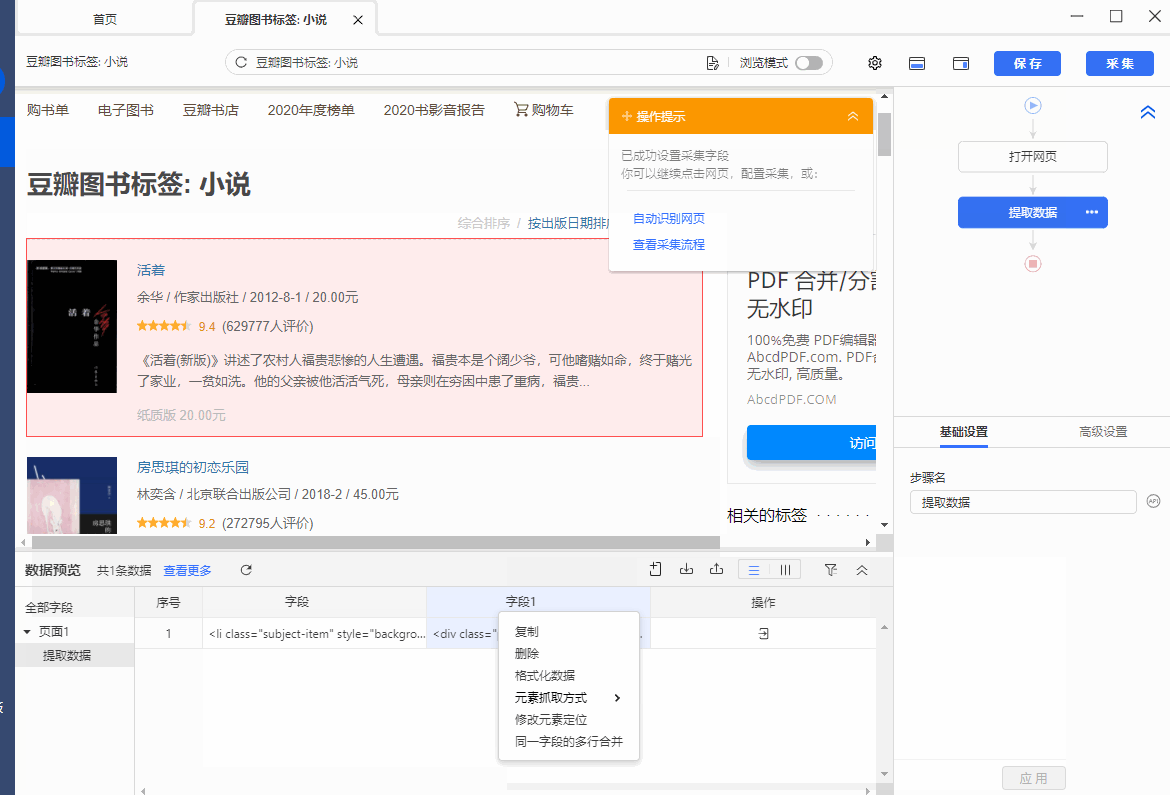
5、抓取网页源码:抓取网页元素对应的源码
示例网址:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4
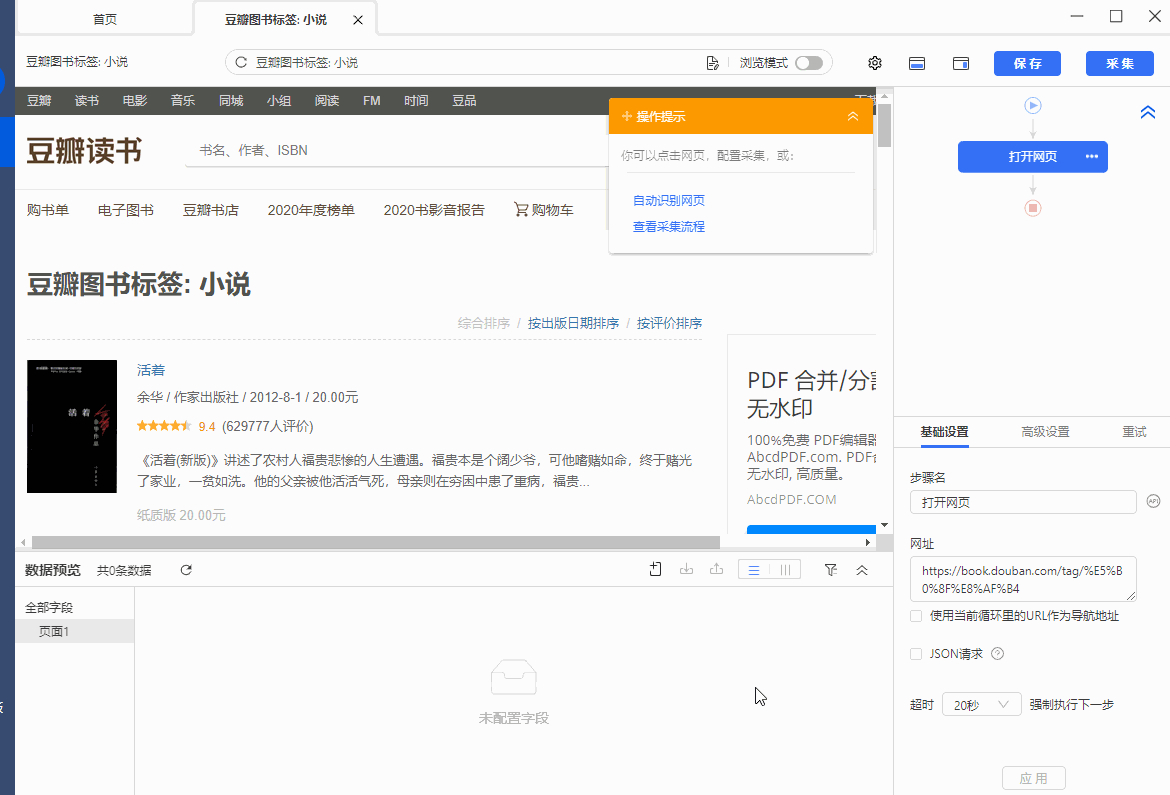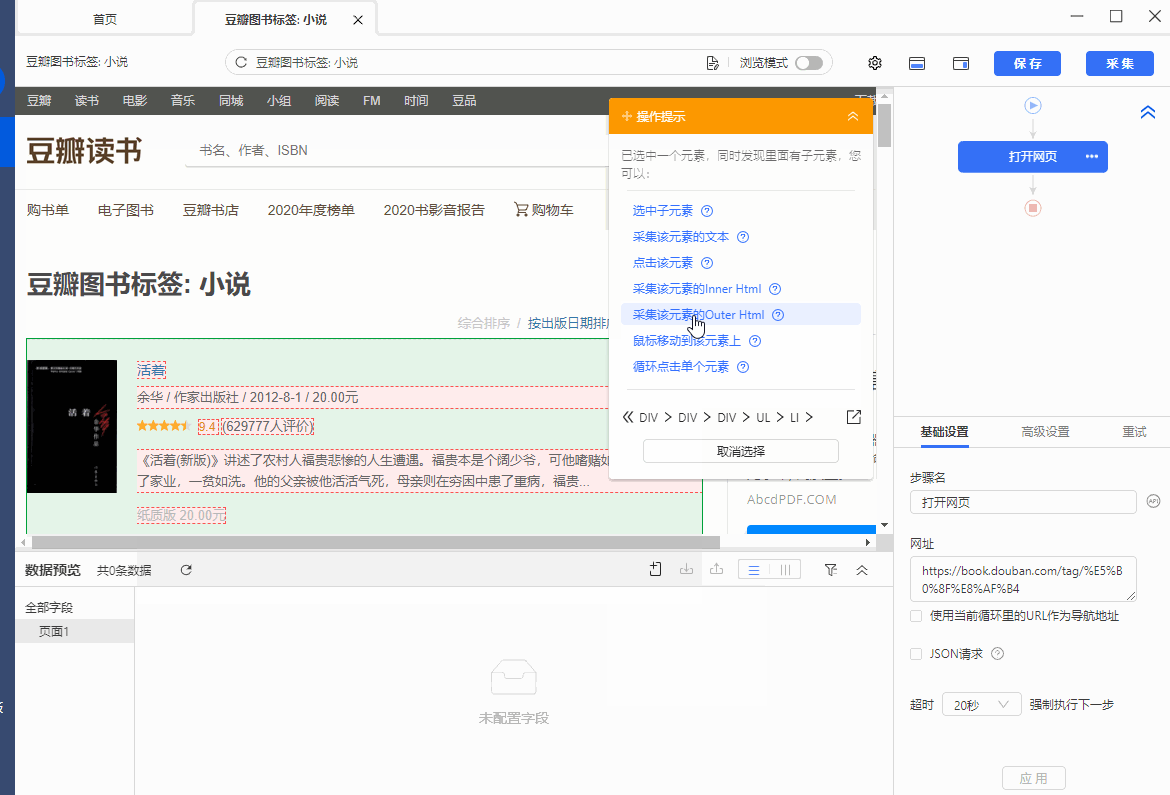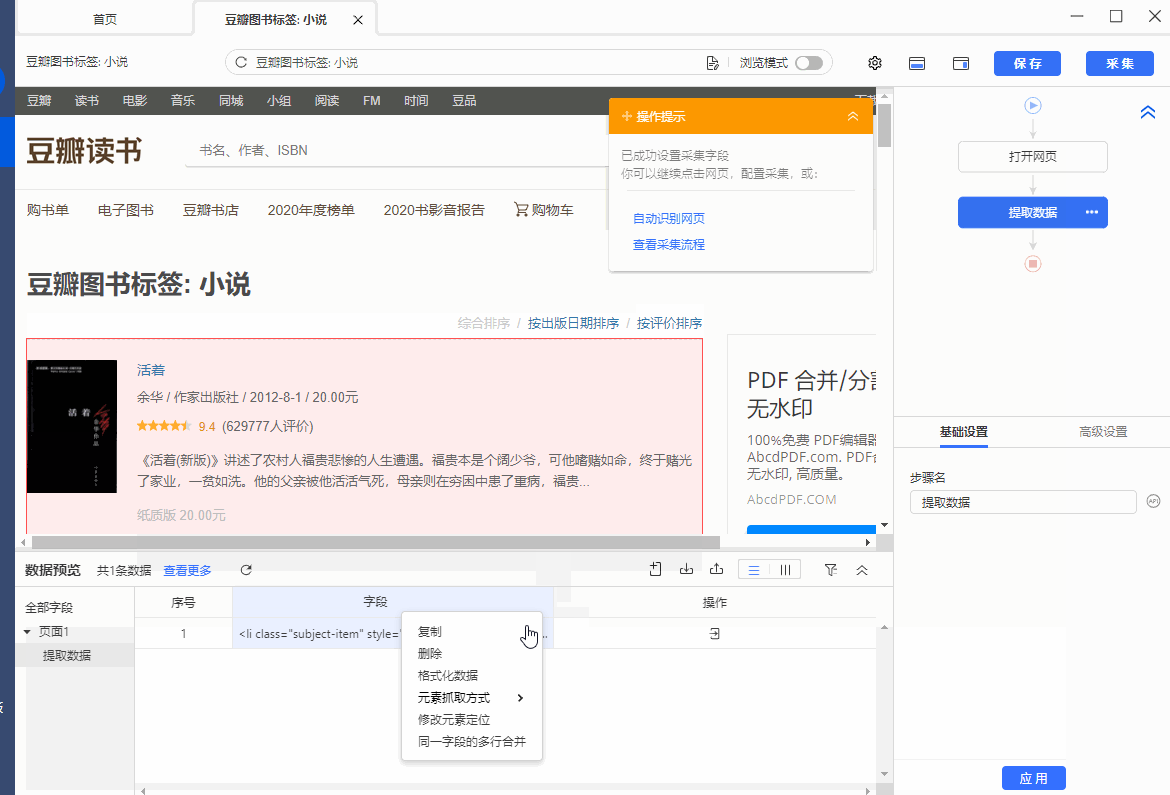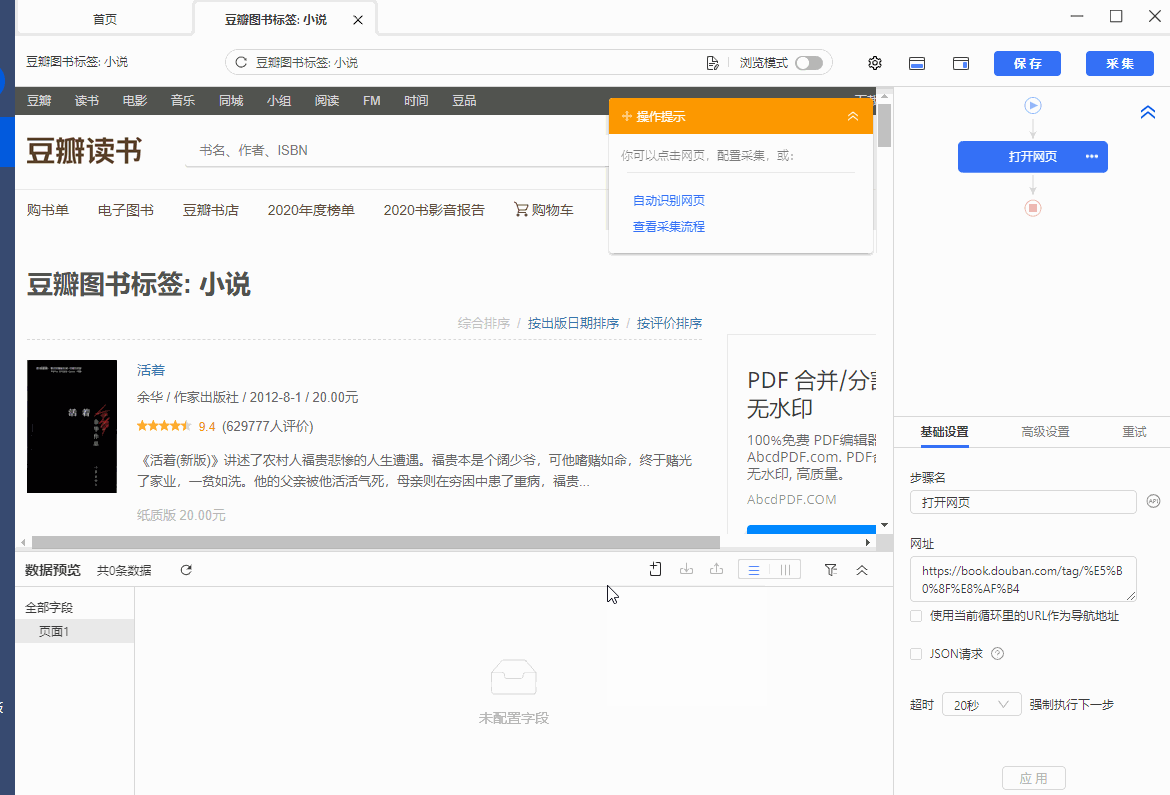
抓取网页源码Outer Html
操作:鼠标选中页面中要抓取的元素,在弹出的操作提示框中选择【采集该元素的Outer Html】,该元素对应的源码(Outer Html)就被采集下来了。
同时,将鼠标移动到字段名【OuterHtml】上,点击 按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【元素网页源码(Outer Html】。
抓取网页源码Inner Html
操作:鼠标选中页面中要抓取的元素,在弹出的操作提示框中选择【采集该元素的Inner Html】,该元素对应的源码(Inner Html)就被采集下来了。
同时,将鼠标移动到字段名【Inner Html】上,点击 按钮,选择【元素抓取方式】,可以看到八爪鱼自动为我们选择了【元素内部网页源码(Inner Html】。
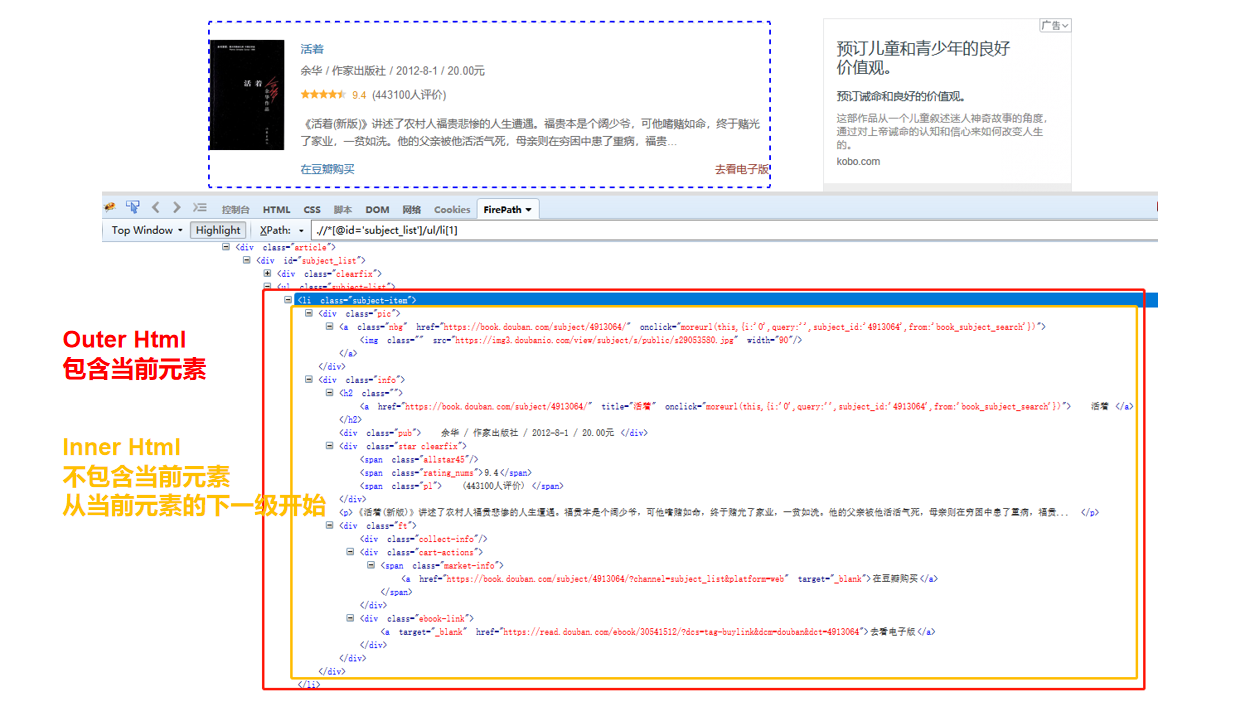
Outer Html 和 Inner Html有何区别?
Outer Html:包含当前元素
Inner Html:不包含当前元素,从当前元素的下一级开始
6、抓取元素属性值
先用XPath找到当前元素的源码,观察当前源码中存在什么属性值、需要提取哪个属性值,然后提取存在且需要的属性值即可。
示例网址:https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&page=7&s=177&click=0
操作步骤:
如图,是一个京东商品列表页。每一个商品,都有一个商品ID,现在需要采集这个商品ID。
第1个商品列表的定位XPath为.//*[@id='J_goodsList']/ul/li[1],对应的网页源码中,有class、data-sku、data-spu、data-pid四个属性。我们需要抓取data-sku这个属性的属性值。
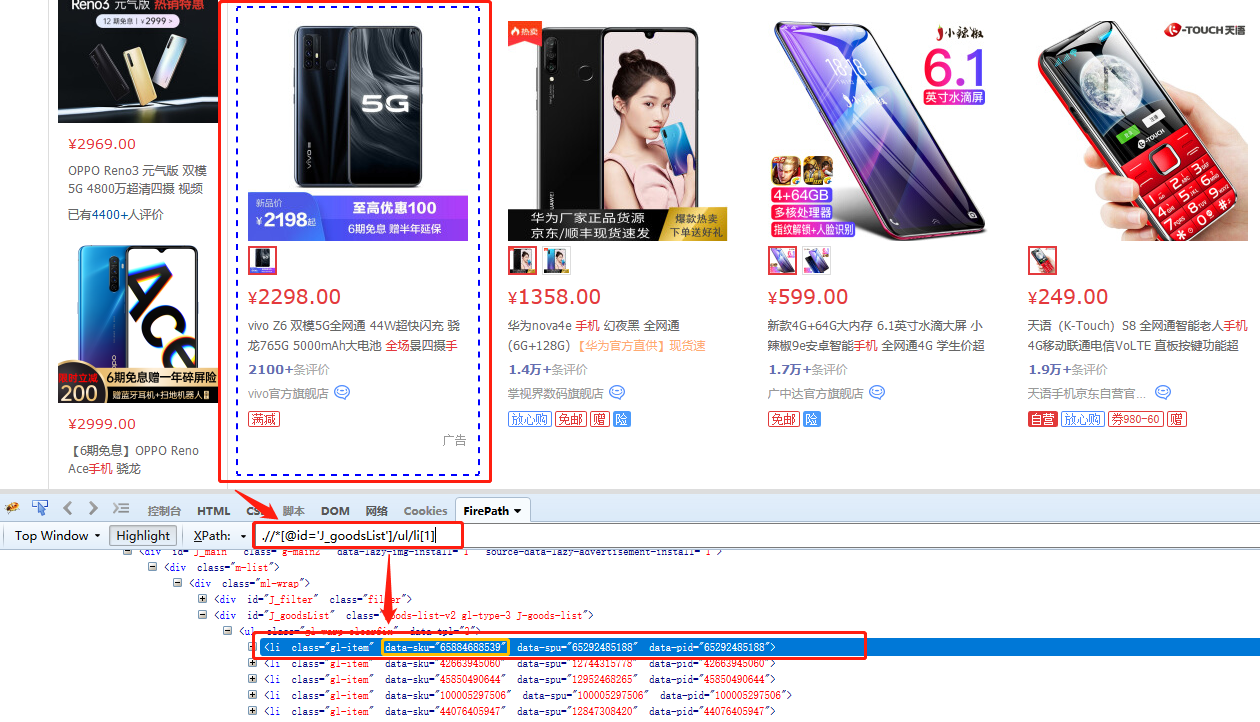
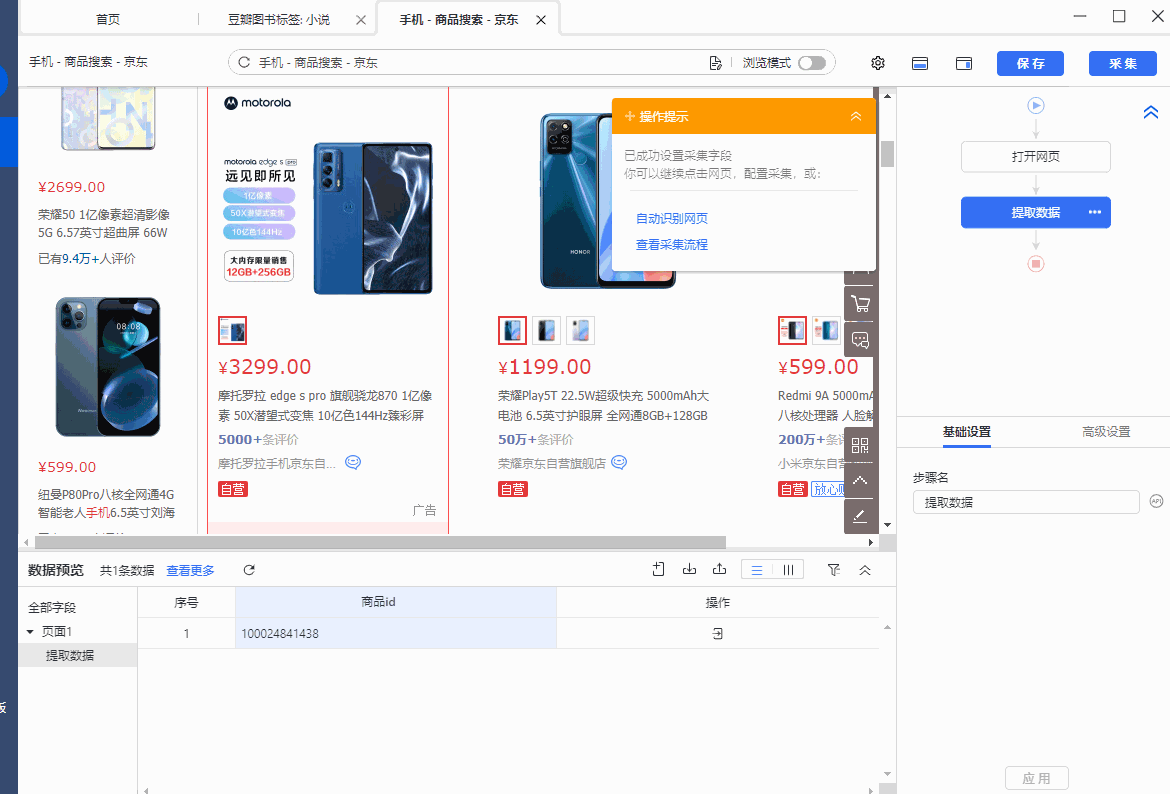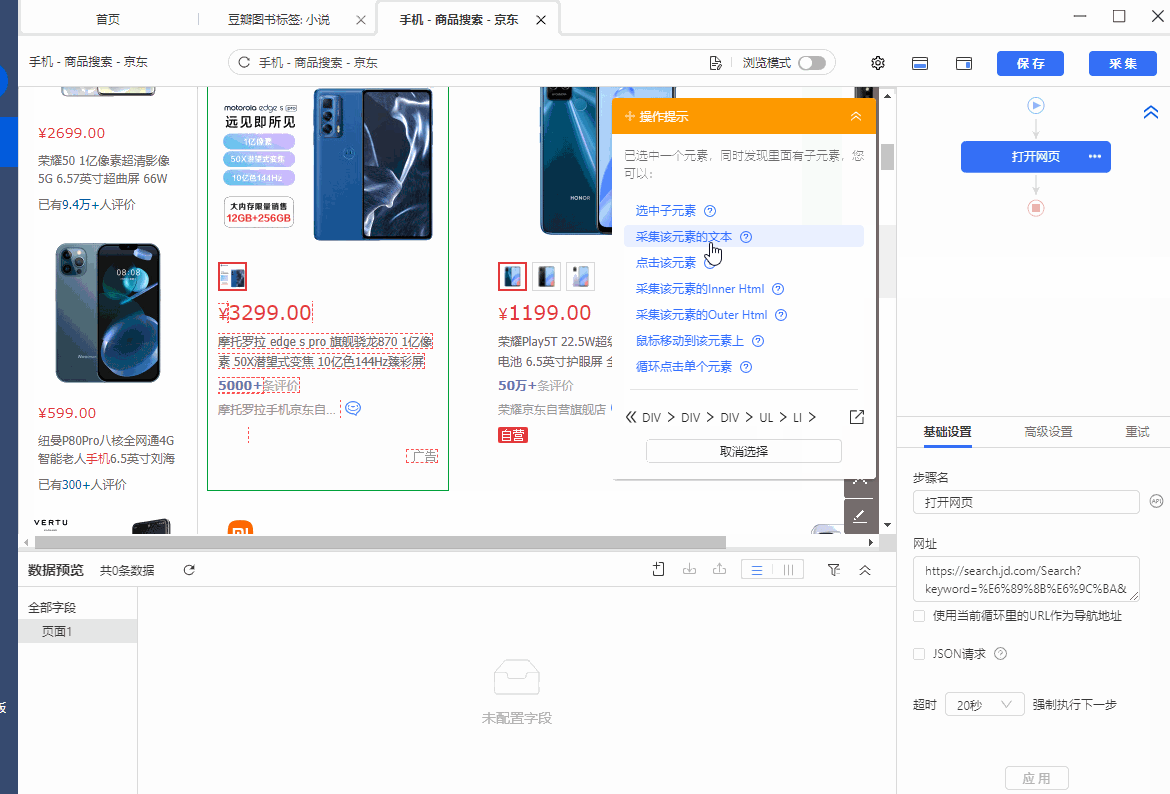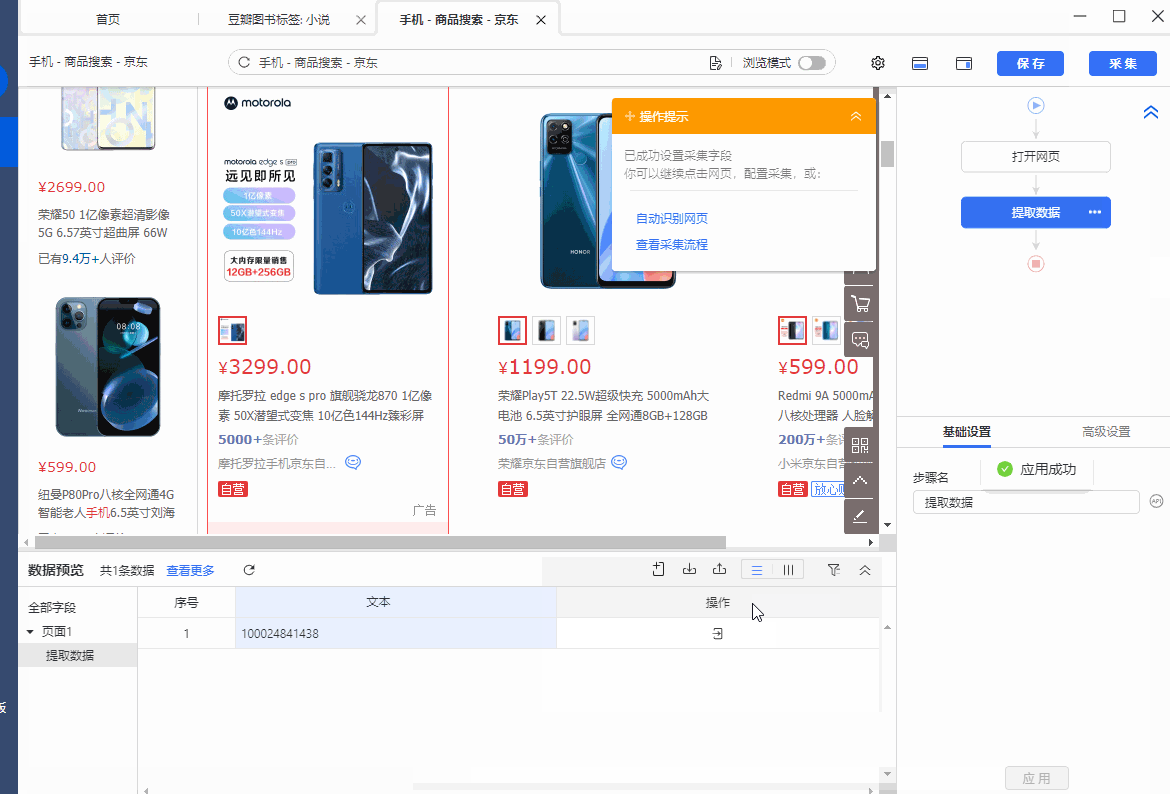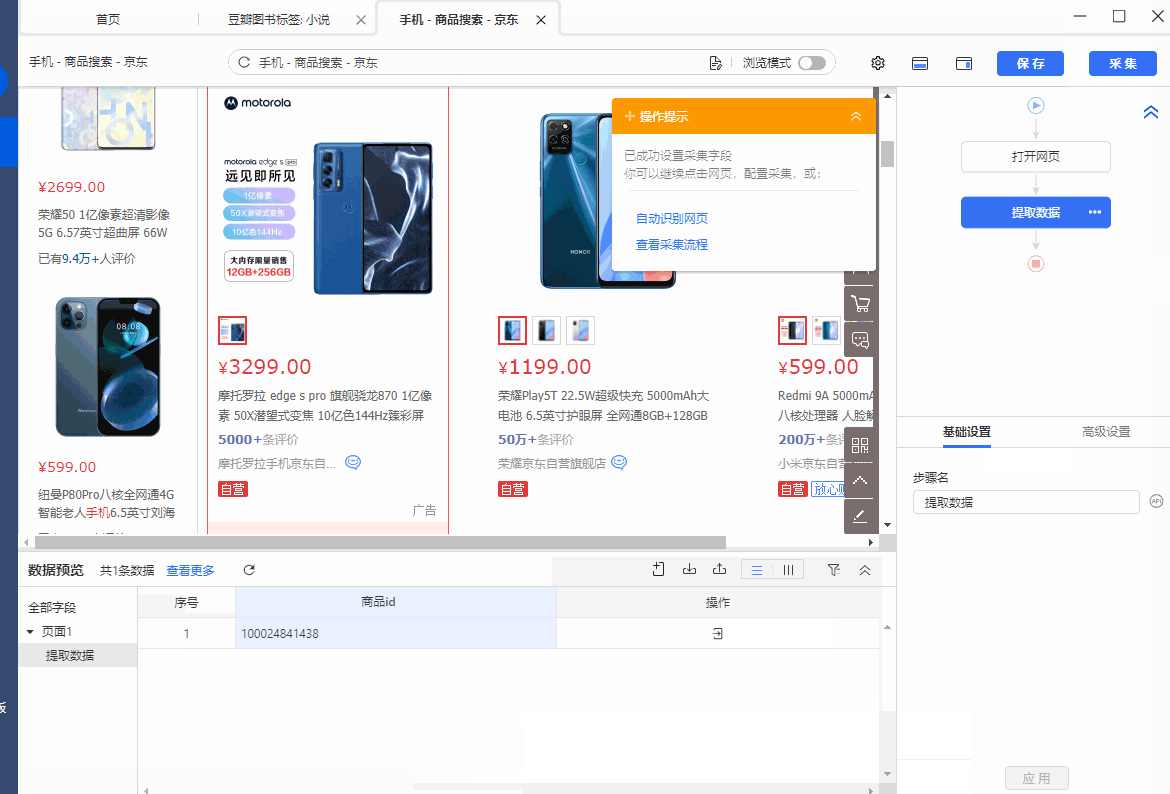
我们先选中第一个商品列表,在弹出的操作提示框中,选择【采集该元素的文本】,这个步骤只是为了获得定位到列表的XPath。
我们真正想抓取的,是data-sku的属性值,所以将鼠标移动到字段名【文本】上,点击 按钮,选择【元素抓取方式】,将抓取方式更改为【抓取元素属性值】,并在下拉框中,选择【data-sku】,这样,我们就将data-sku属性的值采集下来了,这个值就是我们需要的数值。最后,点击【应用】,保存配置即可。

文章评论