
2311版本新增TCP网络请求测试工具,修复内存泄露等问题。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 网络爬虫,也称为Web爬虫或网络蜘蛛,是一种自动化的程序或脚本,被设计用来浏览互联网,以收集信息、数据或执行特定任务。这些任务可以包括搜索引擎索引、数据挖掘、价格比较、内容抓取、自动化测试等等。
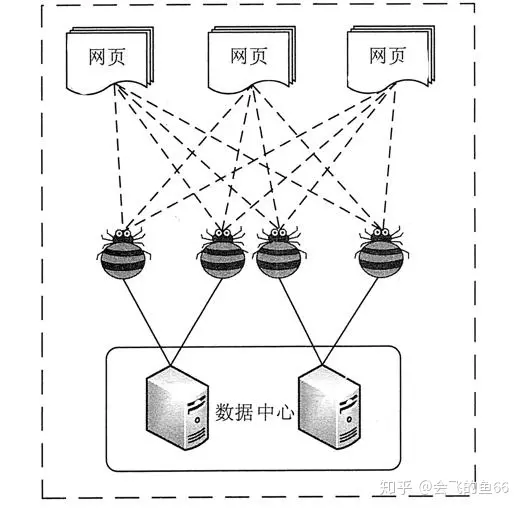
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。 在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。 在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。目前已经知道的各种网络爬虫工具已经有上百个,网络爬虫工具基本可以分为 3 类。 分布式网络爬虫工具,如 Nutch。 Java 网络爬虫工具,如 Crawler4…
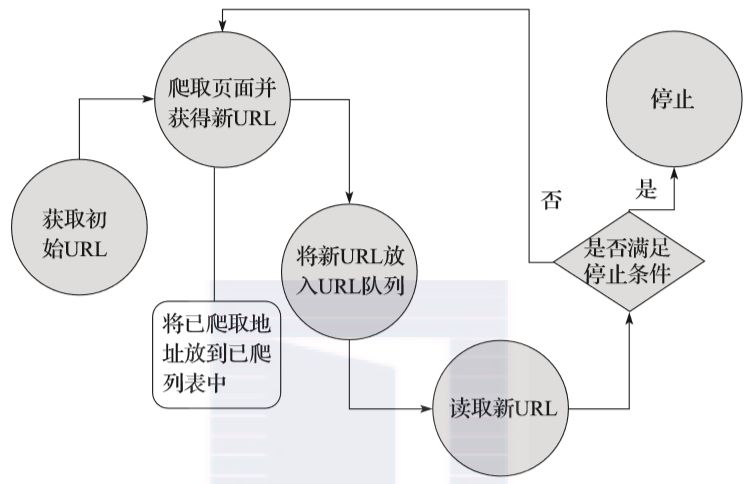
01 网络爬虫实现原理详解 不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。在此,我们将以两种典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。 1. 通用网络爬虫 首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要概括如下(见图3-1)。 ▲图3-1 通用网络爬虫的实现原理及过程 获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。 根据初始的URL爬取页面并获得新的URL。获…
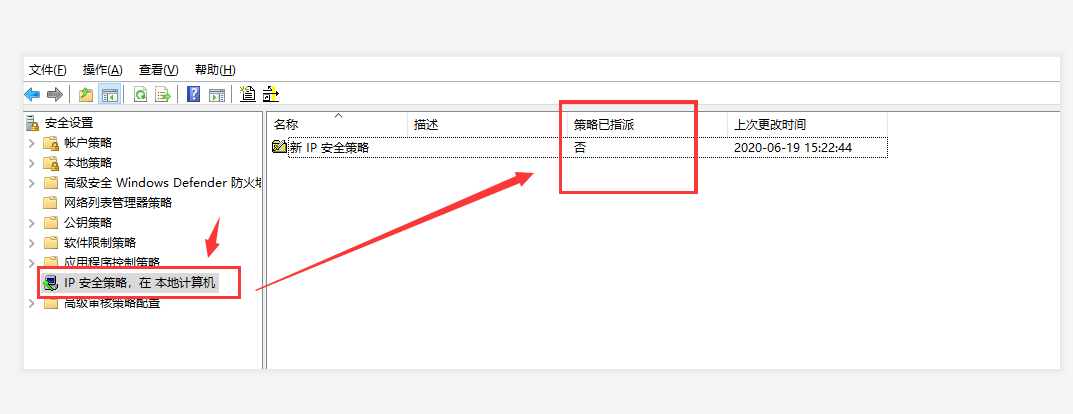
1. 当采集器在服务器无法登陆时,如果抓包分析请求接口返回502状态码,可以尝试关闭防火墙放行918端口,浏览器请求地址 http://115.29.224.93:918/,看看是否可以正常打开。 2. 如若还是登陆失败,请检查本地“本地安全策略”中的“IP安全策略”,是否有建立新的IP安全策略,如果有直接把“策略已指派”改为“否”即可正常登陆采集器(修改方式:新建的ip安全策略记录上右击,菜单里面有个“所有任务选线”设置为“否”…
