
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 网络爬虫,也称为Web爬虫或网络蜘蛛,是一种自动化的程序或脚本,被设计用来浏览互联网,以收集信息、数据或执行特定任务。这些任务可以包括搜索引擎索引、数据挖掘、价格比较、内容抓取、自动化测试等等。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。
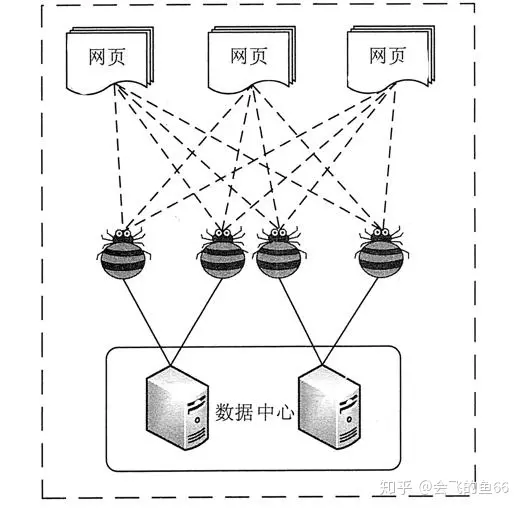
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。 在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。 在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。目前已经知道的各种网络爬虫工具已经有上百个,网络爬虫工具基本可以分为 3 类。 分布式网络爬虫工具,如 Nutch。 Java 网络爬虫工具,如 Crawler4…
爬虫入门系列教程: python爬虫入门教程(一):开始爬虫前的准备工作 python爬虫入门教程(二):开始一个简单的爬虫 python爬虫入门教程(三):淘女郎爬虫 ( 接口解析 | 图片下载 ) 等待更新… 上一篇讲了开始爬虫前的准备工作。当我们完成开发环境的安装、IDE的配置之后,就可以开始开发爬虫了。 这一篇,我们开始写一个超级简单的爬虫。 1.爬虫的过程分析 当人类去访问一个网页时,是如何进行的? ①打开浏览器,输入要访问的网址,发起请求。 ②等待服务器返回数据,通过浏览器加载网页。 ③从网页中找…
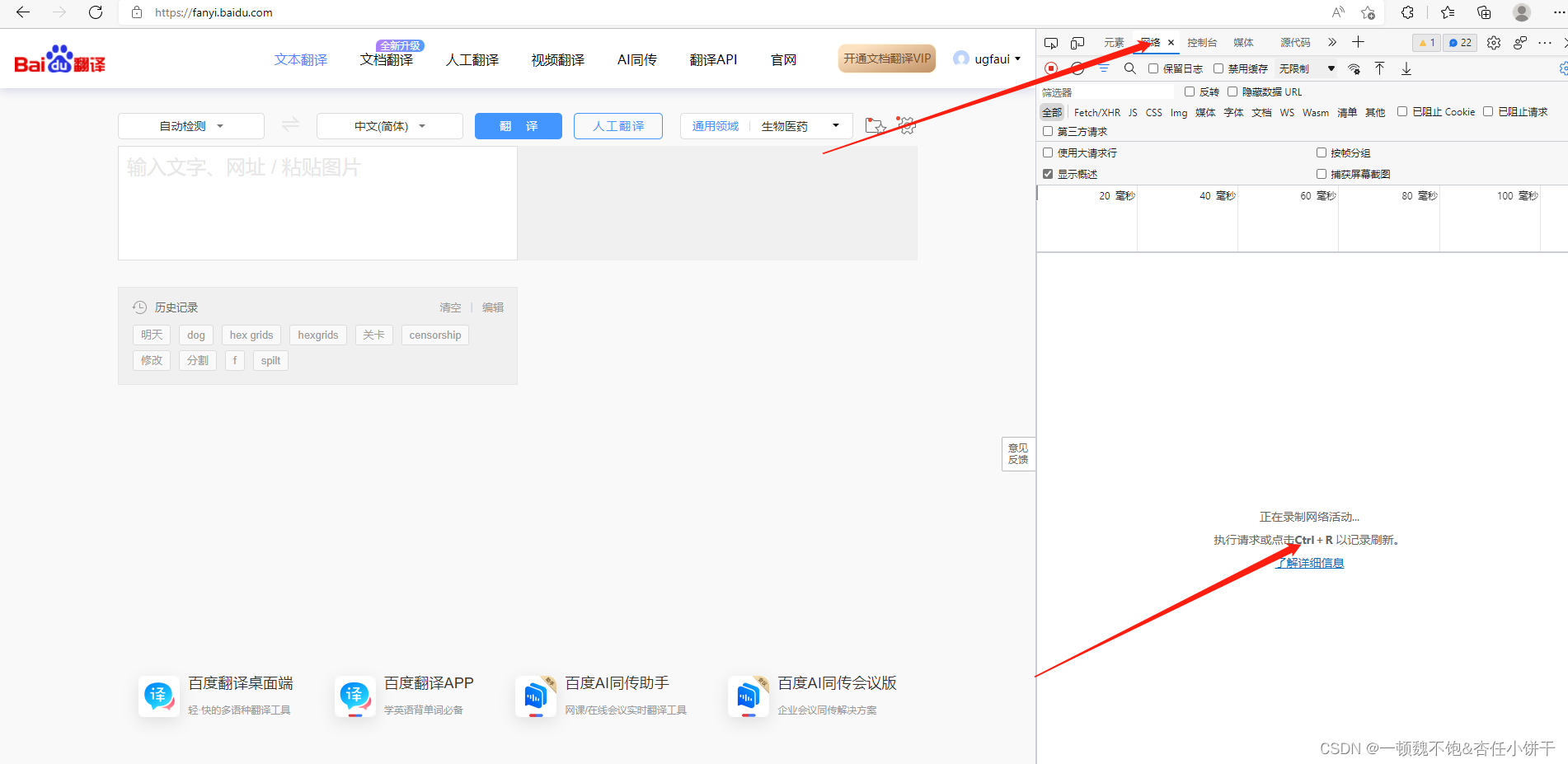
关于爬虫是什么,怎样保证爬虫的合法性小编在这就不再过多的阐述,从本章起,小编将和大家一起分享在学习python爬虫中的所学,希望可以和大家一起进步,也希望各位可以关注一下我!首先我们来初步了解下如何使用开发者工具进行抓包。以 https://fanyi.baidu.com/ 为例。在网页界面右键点击检查,或使用CTRL+SHIFT+I打开。如图打开了开发者工具后我们点击网络得到如上界面。接着按照提示按CTRL+R进行刷新。刷新后如下图所示:此时我们即可看到我们获取到了很多很多的数据包,但是想要完成一个爬虫程序的第一…

这是一篇详细介绍 Python 爬虫入门的教程,从实战出发,适合初学者。读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫。这篇 Python 爬虫教程主要讲解以下 5 部分内容: 了解网页; 使用 requests 库抓取网站数据; 使用 Beautiful Soup 解析网页; 清洗和组织数据; 爬虫攻防战; 了解网页 以中国旅游网首页(http://www.cntour.cn/)为例,抓取中国旅游网首页首条信息(标题和链接),数据以明文的形式出面在源码中。在中…

爬虫一直是一种有效的数据采集方式,但从技术层面来说,它并不是一种完全符合规则的技术,根据国内现有的法律和司法实践,它有可能违反了以下几个方面的法律规定。 一、反不公平竞争法维度 如果没有得到被爬行者的许可,那么就会破坏 Robots的规则。Robots是一种由机器人编程实现的,它是一种由机器人和被爬行者在攀爬过程中进行交流的方法。十二个公司于2012年11月1号联合发布了《互联网搜索引擎服务自律公约》,该公约规定所有的公司必须严格按照 Robots的规则行事。 在实际操作中, Robots协定虽然不在12个公司的管…
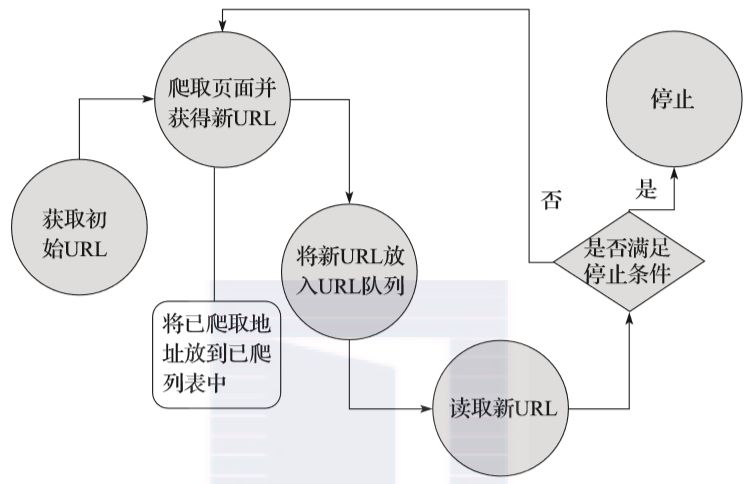
01 网络爬虫实现原理详解 不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。在此,我们将以两种典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。 1. 通用网络爬虫 首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要概括如下(见图3-1)。 ▲图3-1 通用网络爬虫的实现原理及过程 获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。 根据初始的URL爬取页面并获得新的URL。获…

网络爬虫,也叫网络蜘蛛(Web Crawler),从本质上来说它是一套可以实现高效下载的程序。它能够按照指定的规则,通过遍历网络内容的方式,搜集、提取所需的网页数据并下载到本地。它还有另外的名字,例如:自动索引、网络蚂蚁、蠕虫。 当今的互联网世界当中,百分之五十的流量都是由爬虫创造的,可以说没有爬虫就没有互联网如今的繁荣。 举个例子,每当遇到春运或者是节假日期间,大家总能看到各种抢票行为在微信群中疯狂转发。每个人都希望互相帮助点个加速,好能够早一点买到回家或者是旅行的车票。但无论你如何努力,往往总是在最后的千钧一发…
