
HTML代码示例:<img src=***.png> 这是一个不正常的img标签。因为src的属性值没有使用引号括起来,导致标签处理时,勾选“文件与图片下载”之后,实际采集并没有下载图片。 解决方法: 转换为正常的img标签格式。对标签内容增加“标签数据二次处理”——“正则表达式替换”,并填入正则表达式:<img src=([^'"<>\s]{1,250})(.*?)>,替换为<…

问题: 需要翻墙的外网采集,翻墙后仍无法采集数据怎么办? 设置的时候是能看到数据,但是开始采集之后就采集不到,打开查网页界面显示的无法打开相应的网站。 回答: 建议是下载后羿采集器3.5.4版本进行测试。Windows电脑下载链接 提取码: ntgaMac电脑下载链接 提取码: uibx
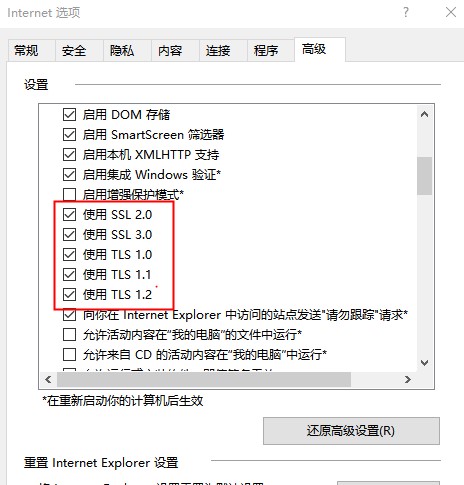
出现这种问题一般是由于系统的原因,下面介绍针对这种情况的解决方法: 一.由于IE未启动服务,以及.net版本不支持,下面介绍具体设置方法: (1)如下图配置IE。 (2)安装.net4.0 ,安装完成后重启电脑,然后再测试下网站是否能够采集
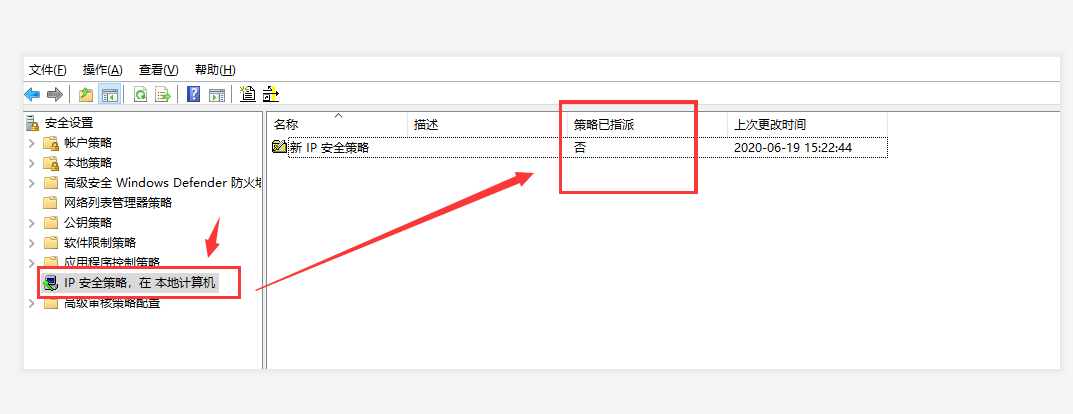
1. 当采集器在服务器无法登陆时,如果抓包分析请求接口返回502状态码,可以尝试关闭防火墙放行918端口,浏览器请求地址 http://115.29.224.93:918/,看看是否可以正常打开。 2. 如若还是登陆失败,请检查本地“本地安全策略”中的“IP安全策略”,是否有建立新的IP安全策略,如果有直接把“策略已指派”改为“否”即可正常登陆采集器(修改方式:新建的ip安全策略记录上右击,菜单里面有个“所有任务选线”设置为“否”…
