
HTTP2和HTTP3的发展历史,蜜蜂采集器对HTTP/2和HTTP/3的功能支持。
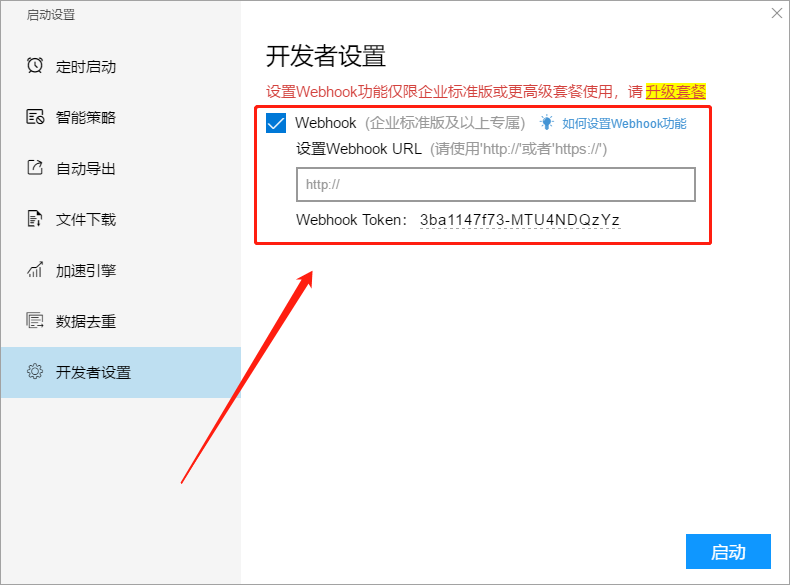
后羿采集器支持Webhook功能,通过使用该功能,后羿采集器可以将采集到的数据实时发布到用户的HTTP地址,用户需要自行开发Webhook接收端代码。 Webhook的设置在启动任务的设置中,具体如下图所示: 开启Webhook功能之后,采集到的数据将以JSON格式进行发送。在任务采集结束时会发送一个采集结束的事件通知。 Webhook以HTTP POST的方式发送数据到用户的HTTP地址。 HTTP Header为"Content-Type: application/json; charset=utf-8"。 用…
后羿采集器支持图像识别功能,可以识别图像中的文字,但是并非所有图像都可以识别,大家可以先进行测试,如果测试不成功,说明你遇到的情况暂时无法支持。 我们以智能模式中采集后羿采集器官网教程页为例,流程图模式的设置方式与此相同。 如下图所示,我们可以看到标题字段中有很多乱码,这是因为我们在网页中使用了图片替代了文字,这些图片在网页中和其他文字看起来是一样的,但是采集下来时就会变成乱码。 此时我们可以右击字段,然后在识别格式中选择“内容乱码”。 之后在字段上会出现“识别”按钮。 点击“识别”按钮,软件会进行图像识别,识别结…
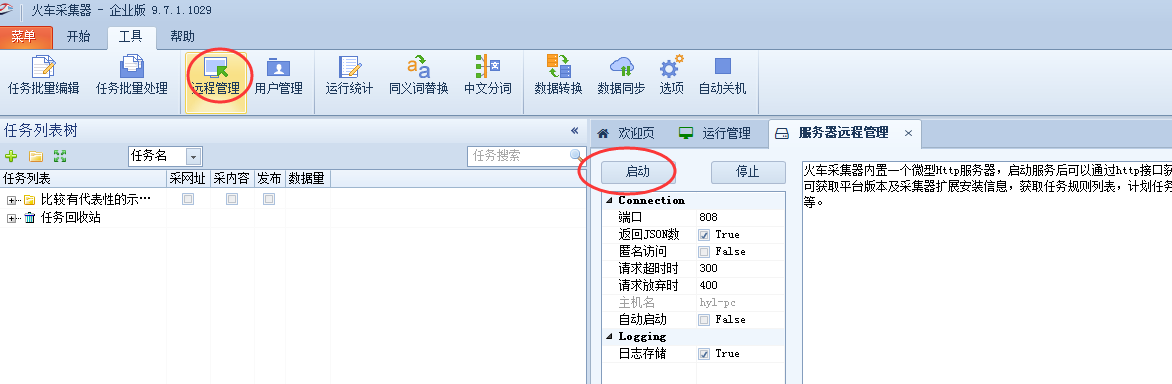
火车采集器企业版本软件是专门提供给多人协同使用的版本,因此有多种便于管理的功能,而其中的远程管理功能是其中的重要功能点。 远程管理功能使用方便,但是一开始的接口界面较简单,因此在此次V9版本中做了一个较大的改版,将界面、性能以及功能都做了优化改动,下面介绍下详细的功能介绍以及使用方法。 一.功能介绍 远程管理功能允许用户在本地启动一个服务接口,该接口可以实现对火车采集器的软件的远程管理,比如对任务进行新建、…
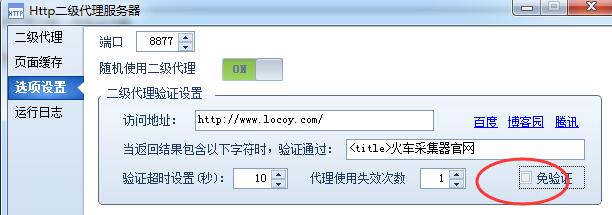
火车采集器二级代理功能,默认是会对获取的代理IP进行一个验证,验证IP是否起效,这样有助于进行IP的筛选,剔除失效IP。 但有些客户有一些特殊的需求,并不需要提前验证IP的真实性,因此开发出这种免验证代理IP的功能,导入的IP直接就显示通过的状态,不会通过我们软件自带的验证功能,导入的IP立刻就能使用,及时性更高。
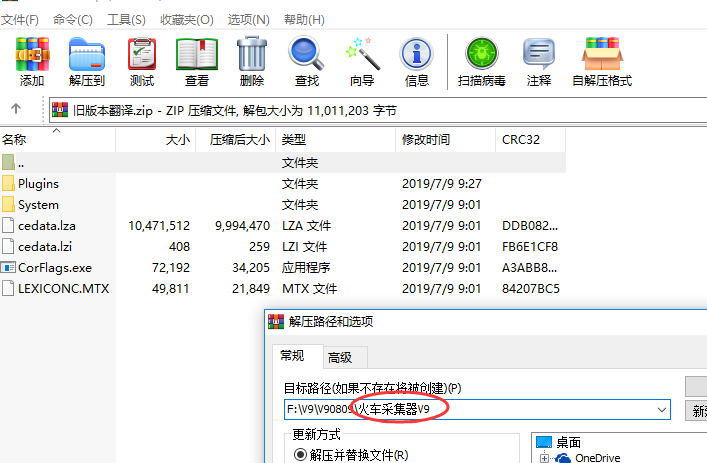
在V9中内置翻译的插件,使用以下步骤: 1.下载下面这个压缩包,并解压到采集器根目录下,注意解压的过程中要关闭火车采集器 翻译插件点击下载链接 2.若您是32位系统,那么现在直接重启下火车采集器即可使用翻译插件。 若您是64位系统,那么您需要使用在火车采集器目录打开任务管理器,打开方法是:win7及以上版本支持,按住“shift”键,然后鼠标右击,在弹窗中选择“在此处打开命令窗口”。如下图所示: 并运行指令:CorFlags.exe LocoySpider.exe /32BIT+,然后重启火车采集器即可…
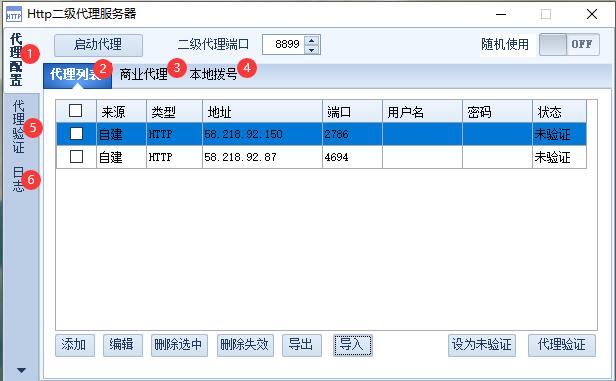
下面介绍下火车采集器二级代理功能,我们按照实际在规则中设置的方式来介绍下如何在火车采集器中使用二级代理列表 1.获取IP 获取ip有三种方式: (1)手动添加:可以手动添加不同类型的IP,并添加用户名密码 (2)文本导入:通过文本导入,文本中IP一行一个保存,然后点击导入按钮保存即可 (3)商业代理IP导入 首先,我们要[点击启用]。然后使用商业代理网站提供的api网址来获取代理IP,一行一个的格式即可,比如如图,在浏览器中打开该网址(这类api是由代理IP网站提供的api接口),可以获取到两个一行一…
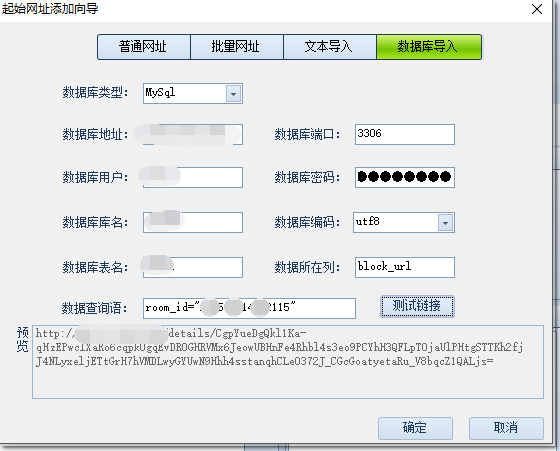
起始网址目前支持四种导入方式,下面介绍数据库导入功能: 数据库导入支持mysql以及sqlserver两种数据库类型, 在使用此功能时需要填写数据库相应的连接信息,以及所需信息所在数据库、表以及列信息。 若所在列需要有where条件查询,如下图,where条件写在数据查询语句中,需要注意的是,不需要写where此关键词,直接写具体条件语句即可
