
介绍了XPath解析的使用方法,多用户帐号采集的Cookie设置,以及如何下载图片等。
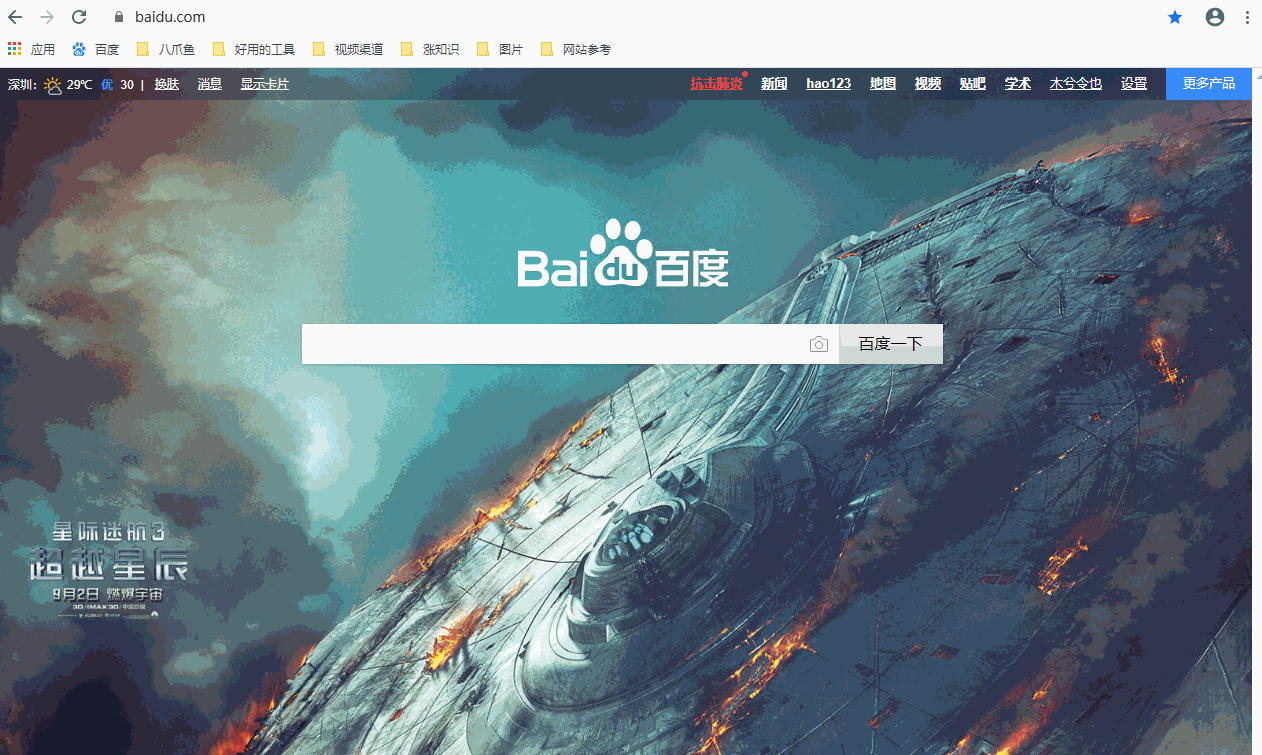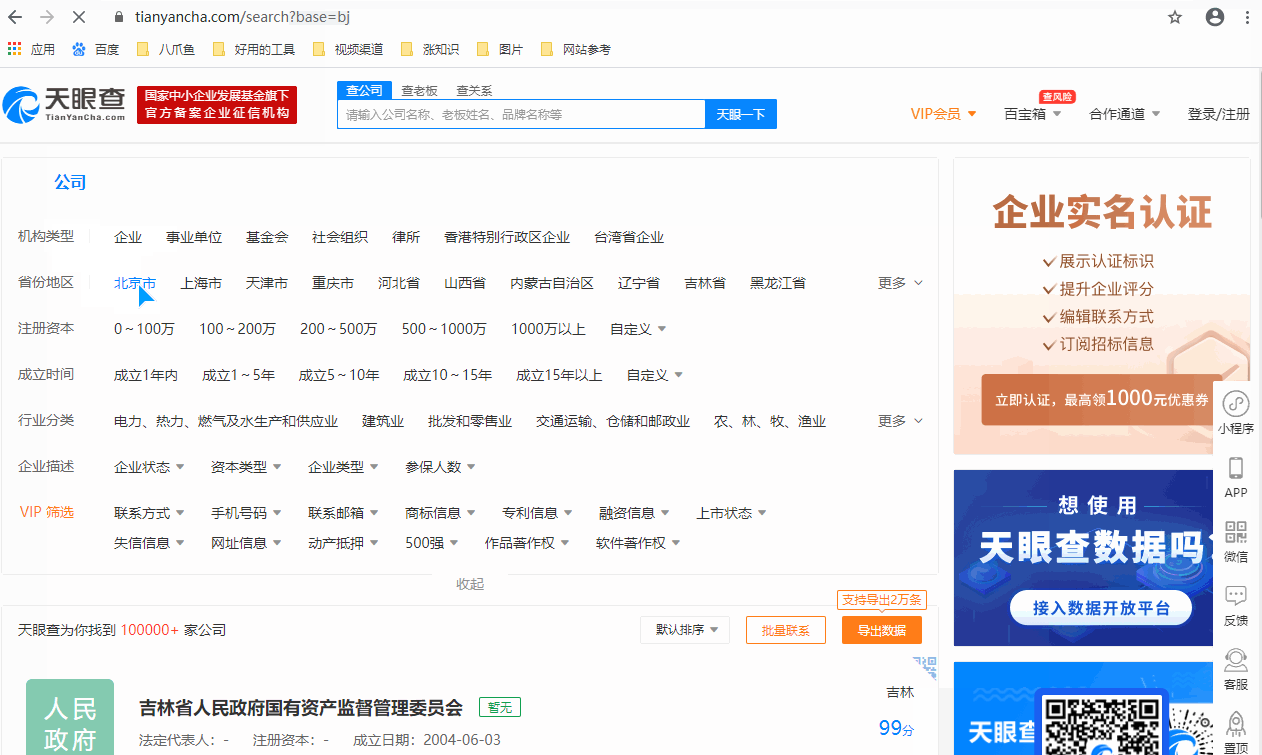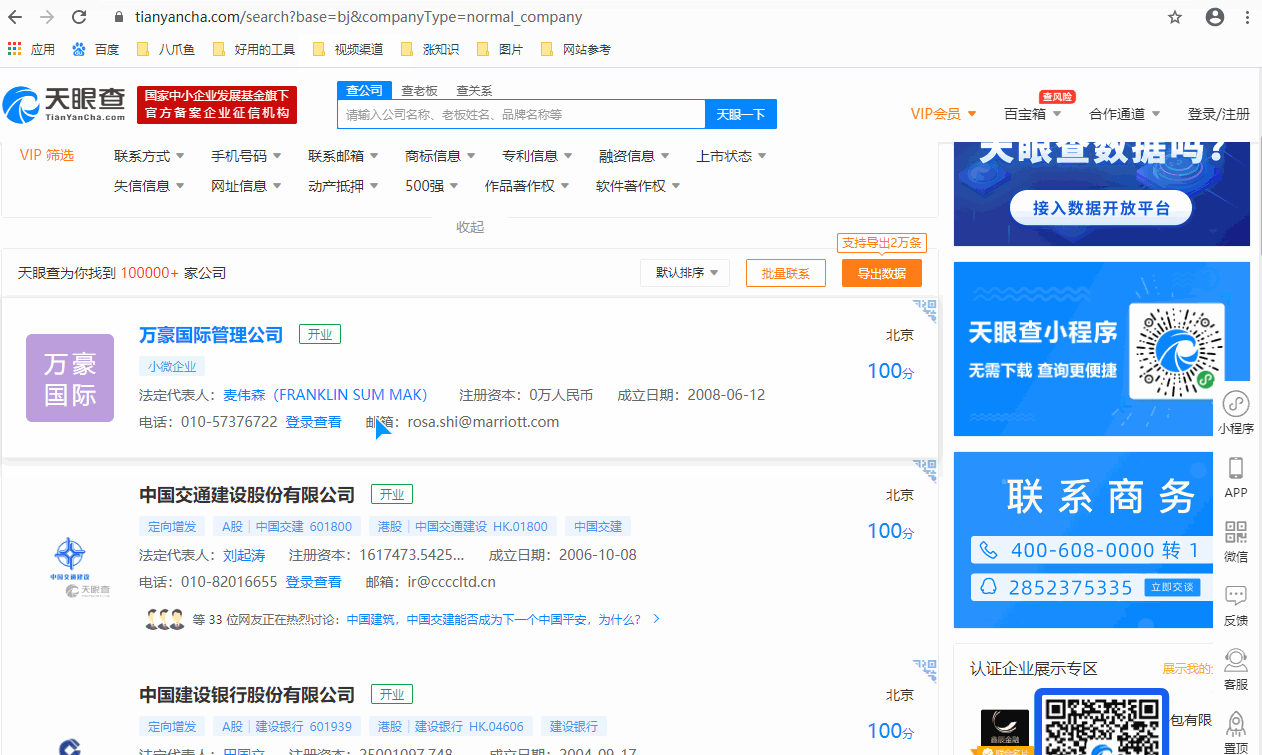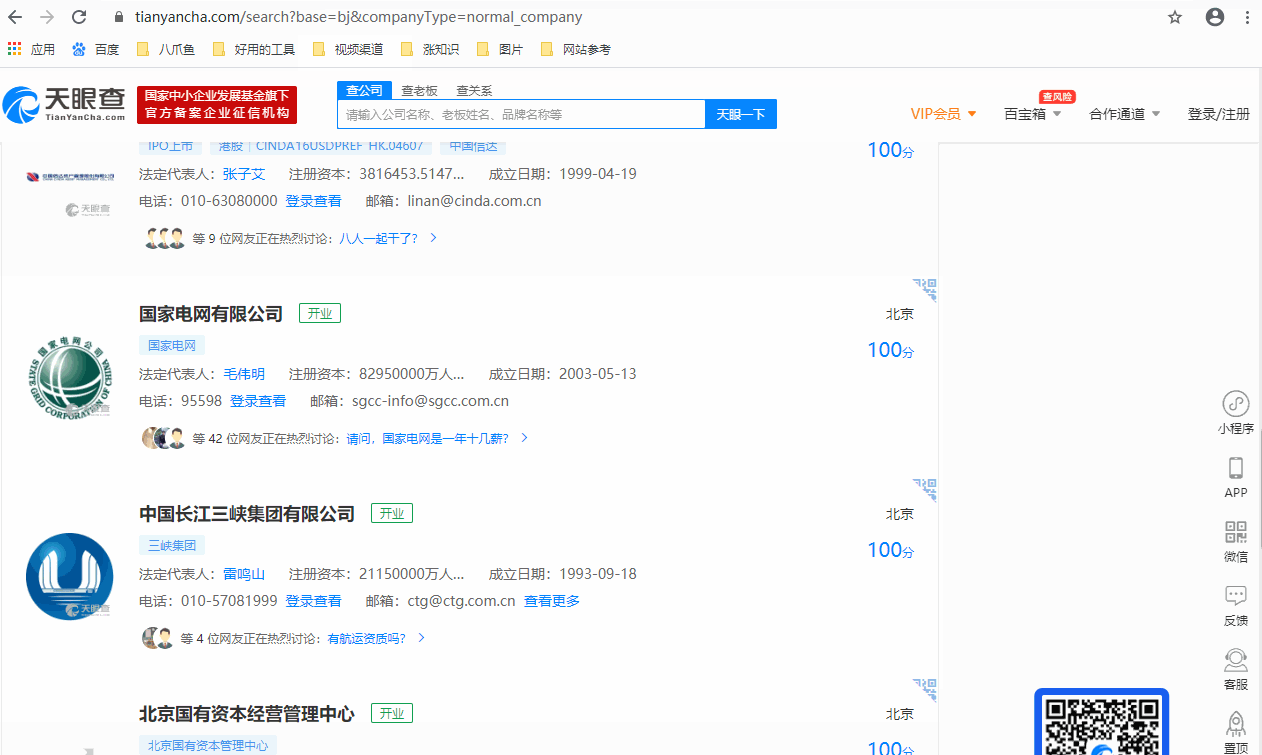
采集场景 在天眼查搜索页面(https://www.tianyancha.com/search),选择条件查询,得到条件查询后的结果列表页。实例网址:https://www.tianyancha.com/search?base=bj&companyType=normal_company,是选择了2个查询条件(省份地区:北京市;机构类型:企业)后得到的列表页。然后点击企业链接进入详情页,采集企业详情页的数据。 鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图 下文其他图片同理 采集…
采集场景 在58同城地区首页(https://sz.58.com/ ,示例中默认为深圳) ,进入招聘频道,输入职位名称搜索,得到搜索结果列表。点击职位标题链接进入详情页,采集该职位具体信息。 采集字段 职位、薪酬、更新时间、浏览人数、申请人数等字段。 采集结果 采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例: 采集步骤 步骤一:打开网页 步骤二、输入关键词并搜索 步骤三、建立【循环-点击元素】,进入每个职位的详情页 步骤四、提取职位详情页中的字段 步骤五、编…
