问题: 后羿采集器能采什么数据? 回答: 后羿采集器是一款通用的网页数据采集软件,通过内置浏览器访问网页并采集数据,满足以下2个条件的数据均可采集:①网页上公开显示的数据,包含通过账号密码登录后可以查看到的数据。②可以用鼠标复制粘贴下来的数据、网页上没显示但是网页HTML源码中有的数据。 【温馨提示】采集过程中请遵守Robots协议,请勿使用后羿采集器采集任何个人隐私数据,请勿非法使用采集到的数据。为了保护您的隐私,您所有的任务及配置都以加密形式存储于云端,除了您个人外任何人都无法查看具体的内容,您在采集过程中输入…
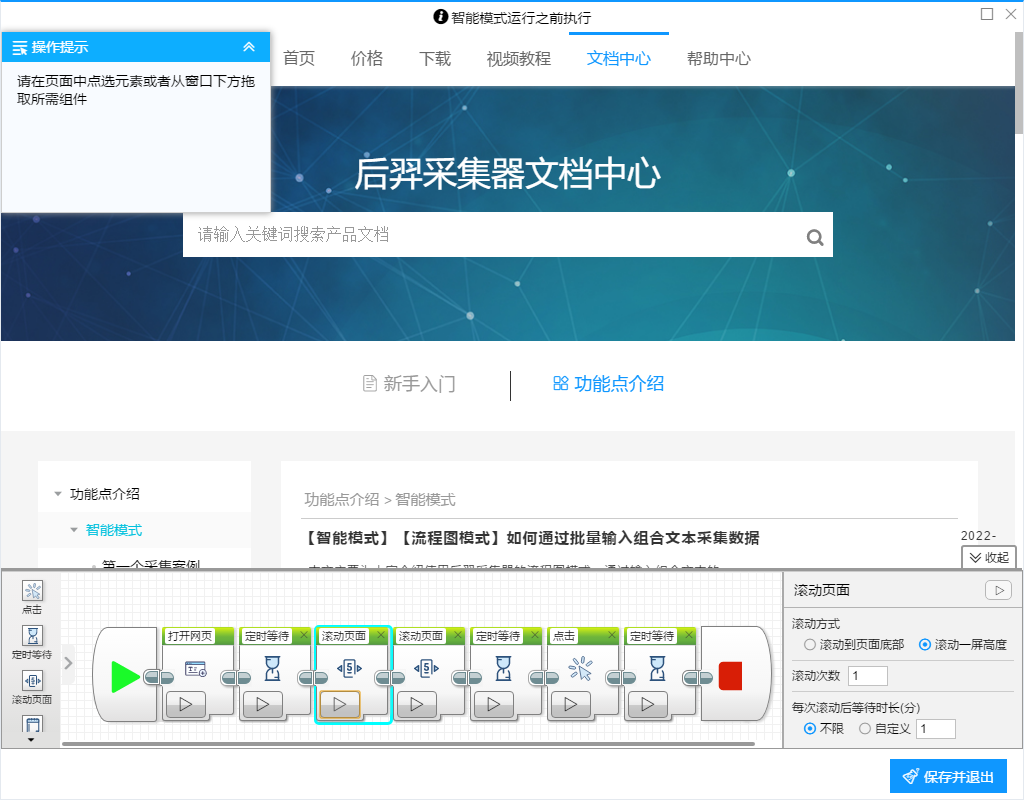
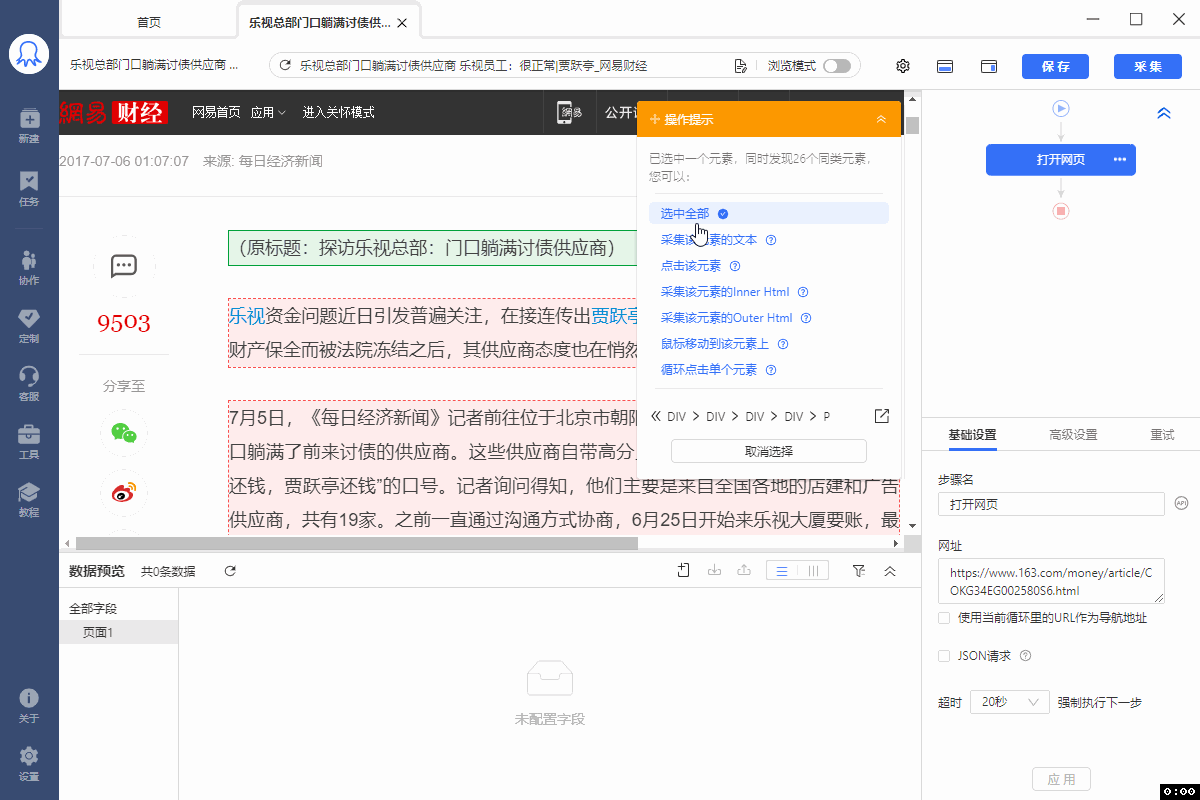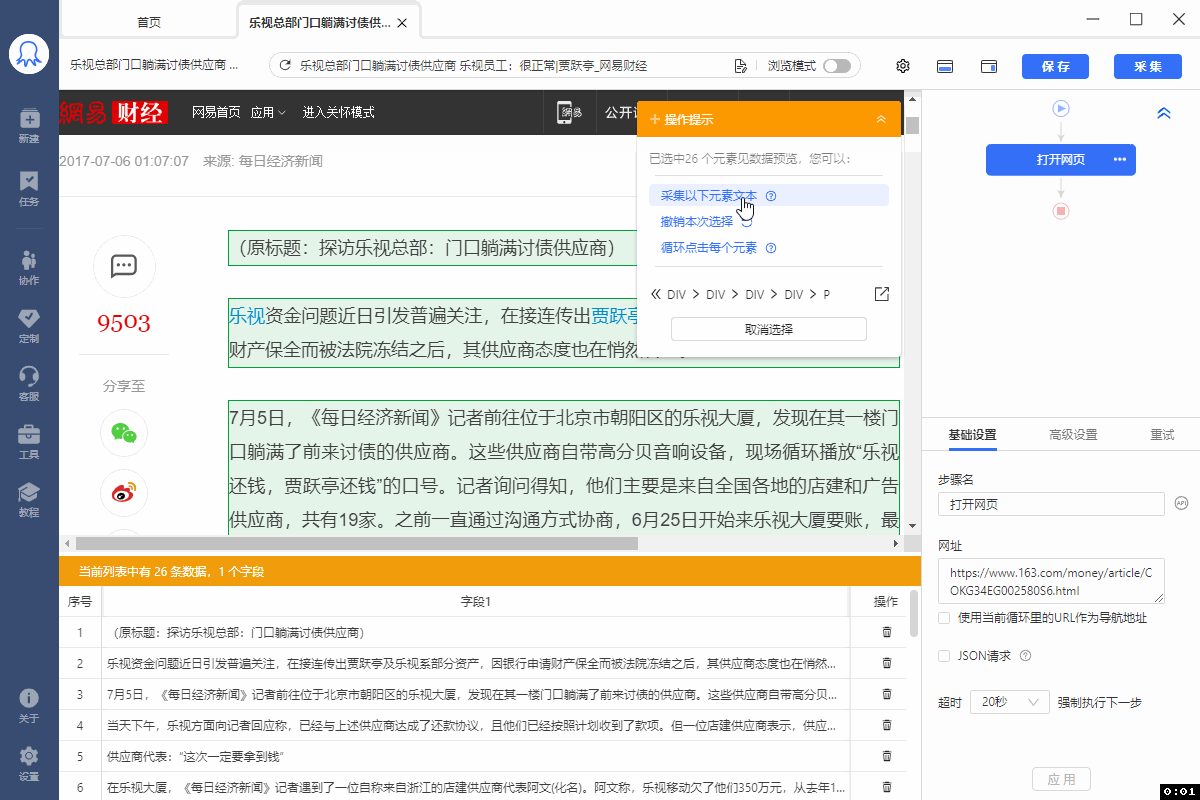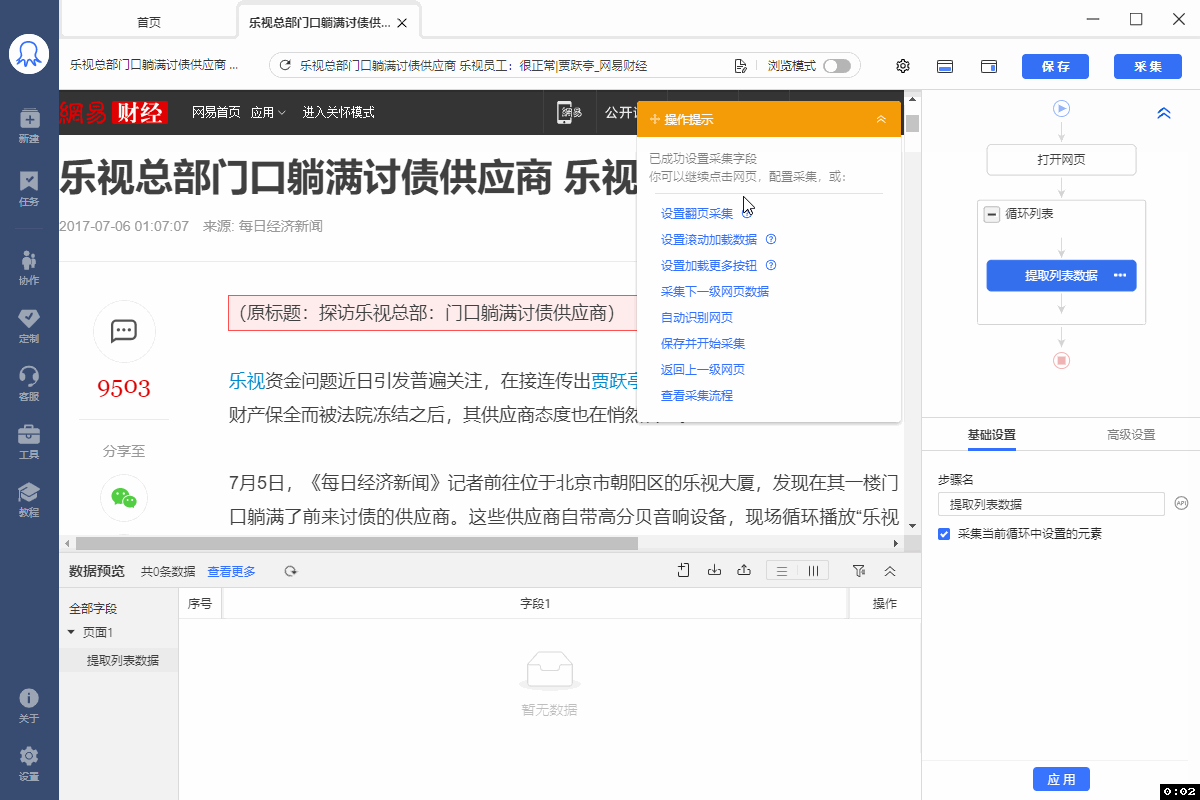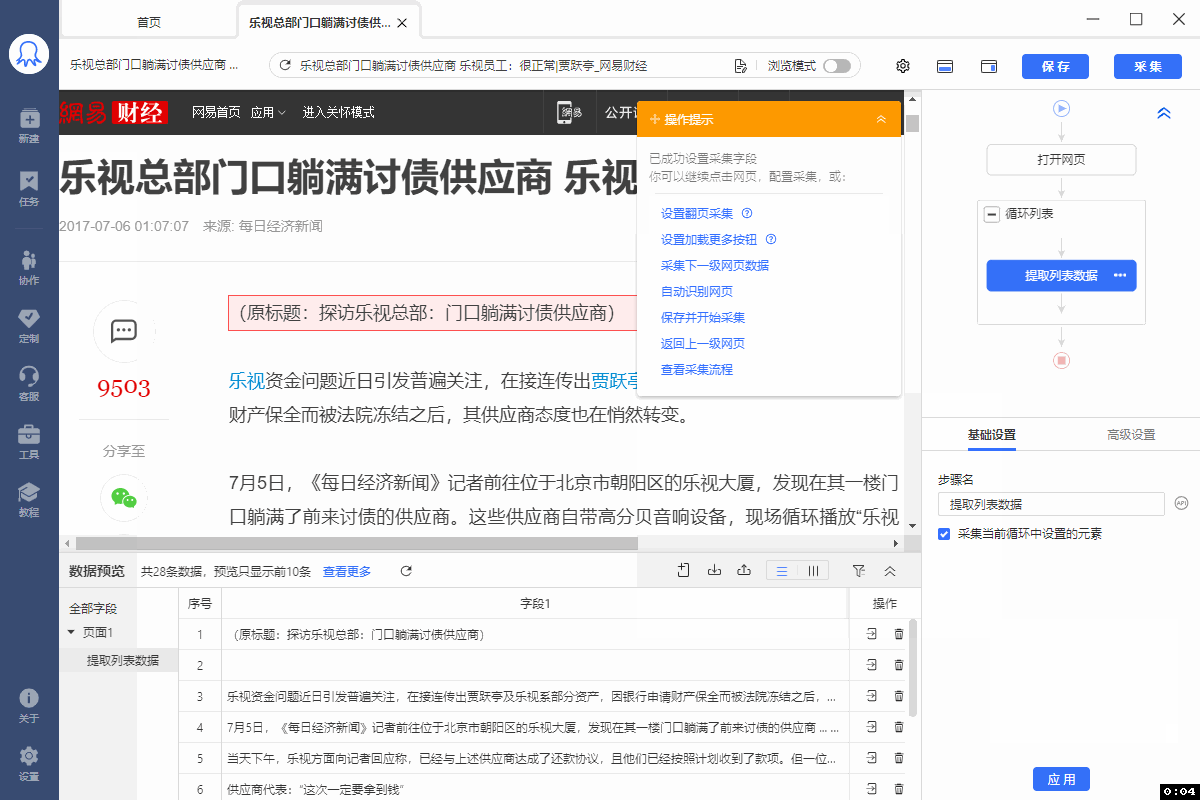
问题: 电商网站的评论采集不出来怎么办? 回答: 部分电商网站会针对评论页面的展开进行限制,需要在软件内添加组件进行跳转。 智能模式需要先在右上角绿色按钮“预执行操作”界面添加以下组件:定时等待+滚动(设置成滚动一屏次数一次)+滚动+定时等待+点击(选中跳转到评论的按钮)+定时等待

这个就更厉害了! 流程图模式是后羿采集器团队为了满足用户丰富的个性化数据采集需求而研发的操作模式。 流程图模式支持可视化的网页点选操作,完全符合人工浏览网页的思维方式,用户只需要打开被采集的网站,用鼠标点击几下就能自动生成复杂的数据采集规则。 流程图模式可以采集目前互联网上99%的网页数据。流程图模式不仅支持单个网址的采集和多个网址的批量采集,支持从本地文件批量导入网址,而且还支持参数网址批量生成。 点此进一步了解流程图模式的使用方法。
1、什么样的网页是列表类型的网页 列表类型的网页是具有相同元素的内容页按照一定的线性顺序排列分布的网页,如下图所示: 2、如何采集列表类型的网页 在智能模式下,后羿采集器默认按照列表类型的网页进行智能识别,并完成页面列表元素内部所有字段的自动识别和采集。 如果后羿采集器自动识别的结果不符合您的需求,您可以手动点选列表。 (1)软件自动识别列表元素内部字段并进行采集 (2)手动点选列表 关于采集字段的设置可以看这里→_→ 如何对采集字段进行配置
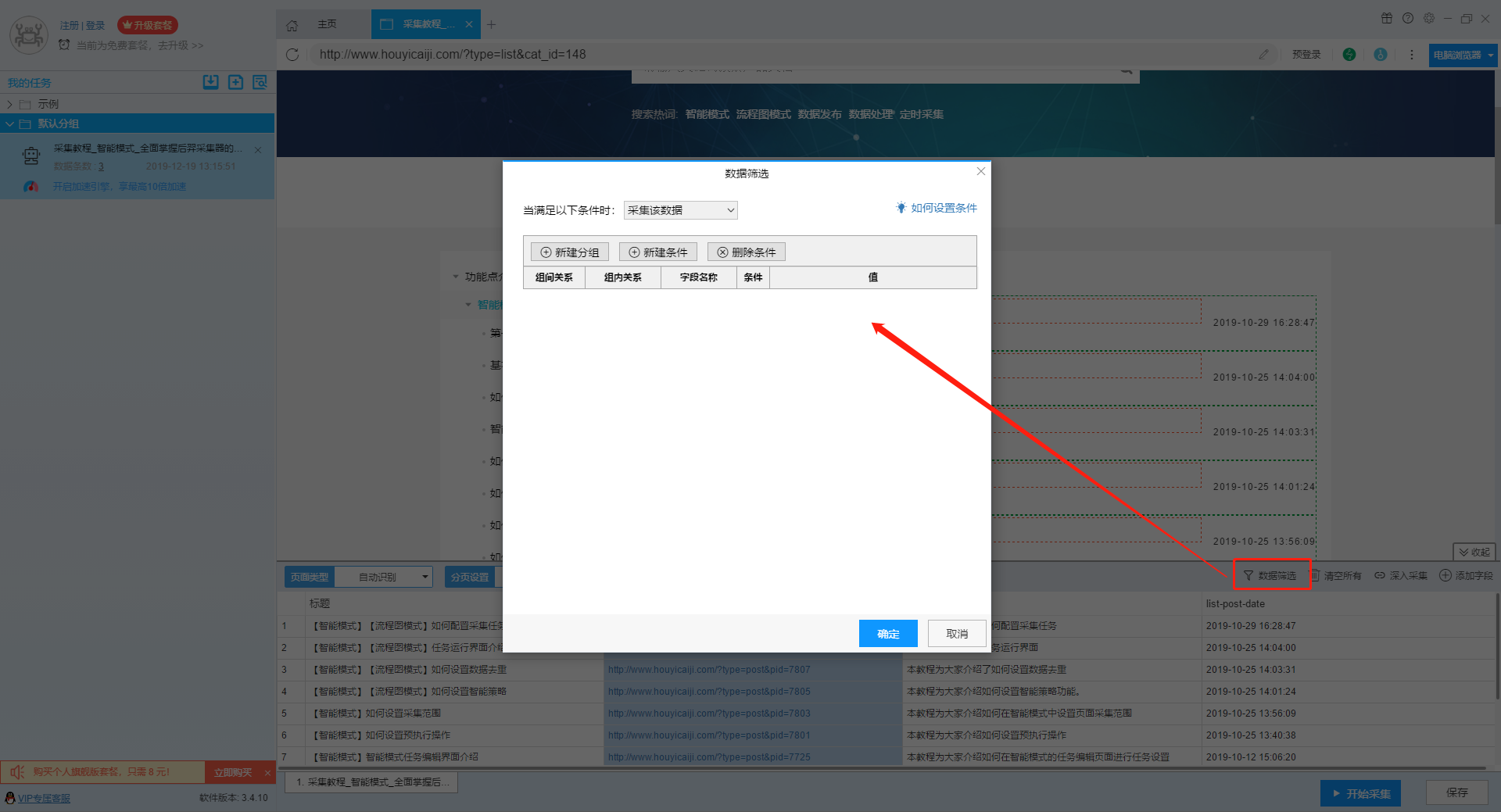
在设置采集任务的过程中,有时候我们会遇到一些不需要采集的数据,如某些数值为空的数据或者包含某些字符的数据,从而在一定程度上影响了采集速度和效果,针对这种情况我们可以使用数据筛选功能,避免采集到无效数据。 智能模式中,“数据筛选”功能按钮在任务操作栏的右上角,点击之后会打开筛选条件设置窗口,如下图所示。 流程图模式中,“数据筛选”功能在提取数据组件菜单栏的右上角,,点击之后会打开筛选条件设置窗口,如下图所示。(如果流程图中有多个提取数据组件,数据筛选是共享的,在任意一个提取数据组件中打开设置都可以) 在数据筛选功能界…
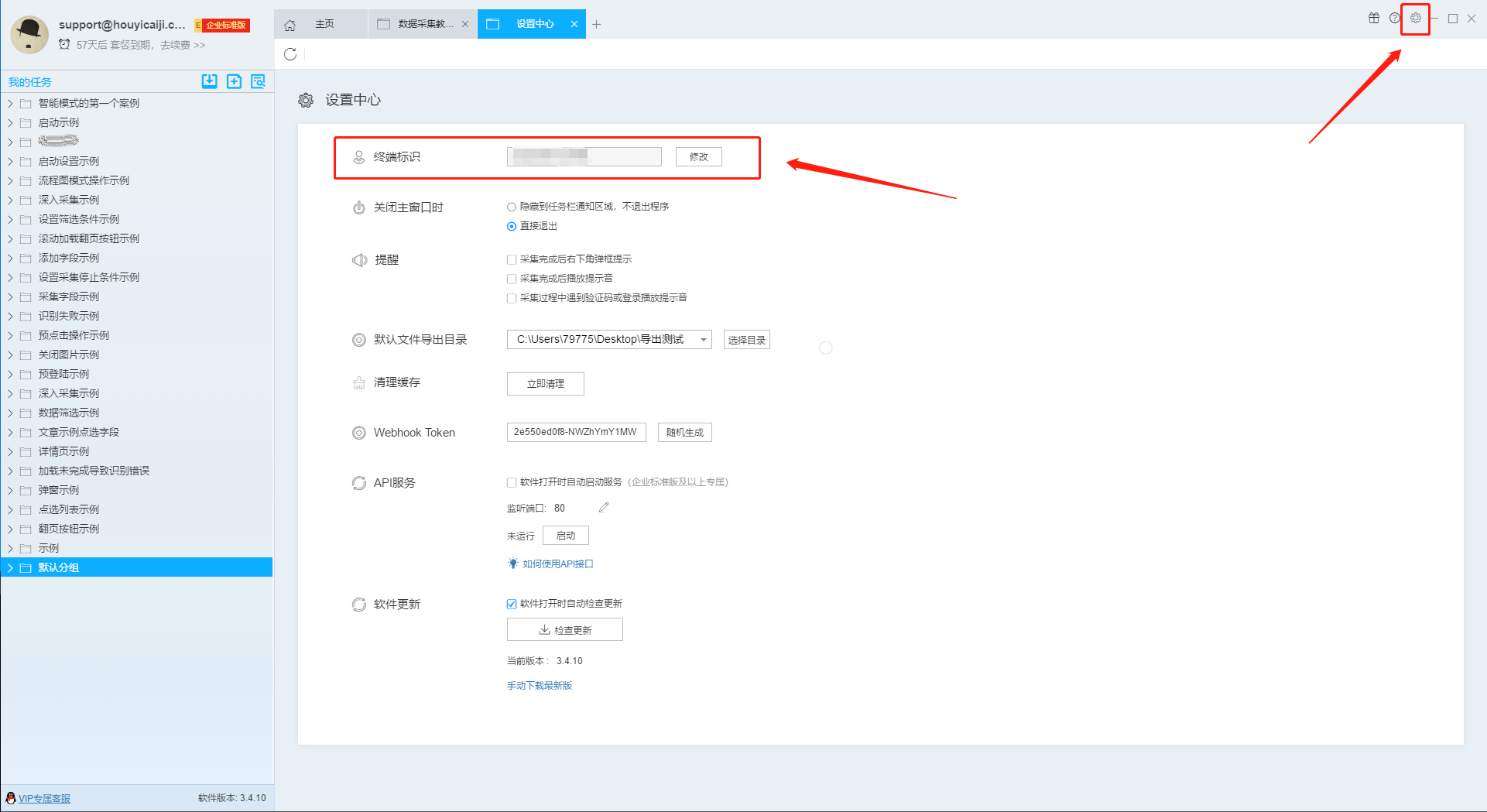
终端标识可以理解为您当前电脑中所安装的后羿采集器软件的身份证号码,默认生成的终端标识由您的“电脑名称+随机数”构成,您也可以在设置中心进行修改。 终端标识主要用于同一个账号在多台电脑上登录的场景,当您的账号在多台电脑上登录时,如果您同时登录的电脑数量超过了套餐限制(后羿采集器的账号可以在任意一台电脑上登录,但是同时登录的电脑数量存在限制,具体可以参考官网价格页面的介绍),软件会显示出所有正在登录中的终端标识,并提示您需要断开其中一个正在登录中的终端,然后才能进行登录操作。 终端标识和账号存在关联,因此同一个账号在不…
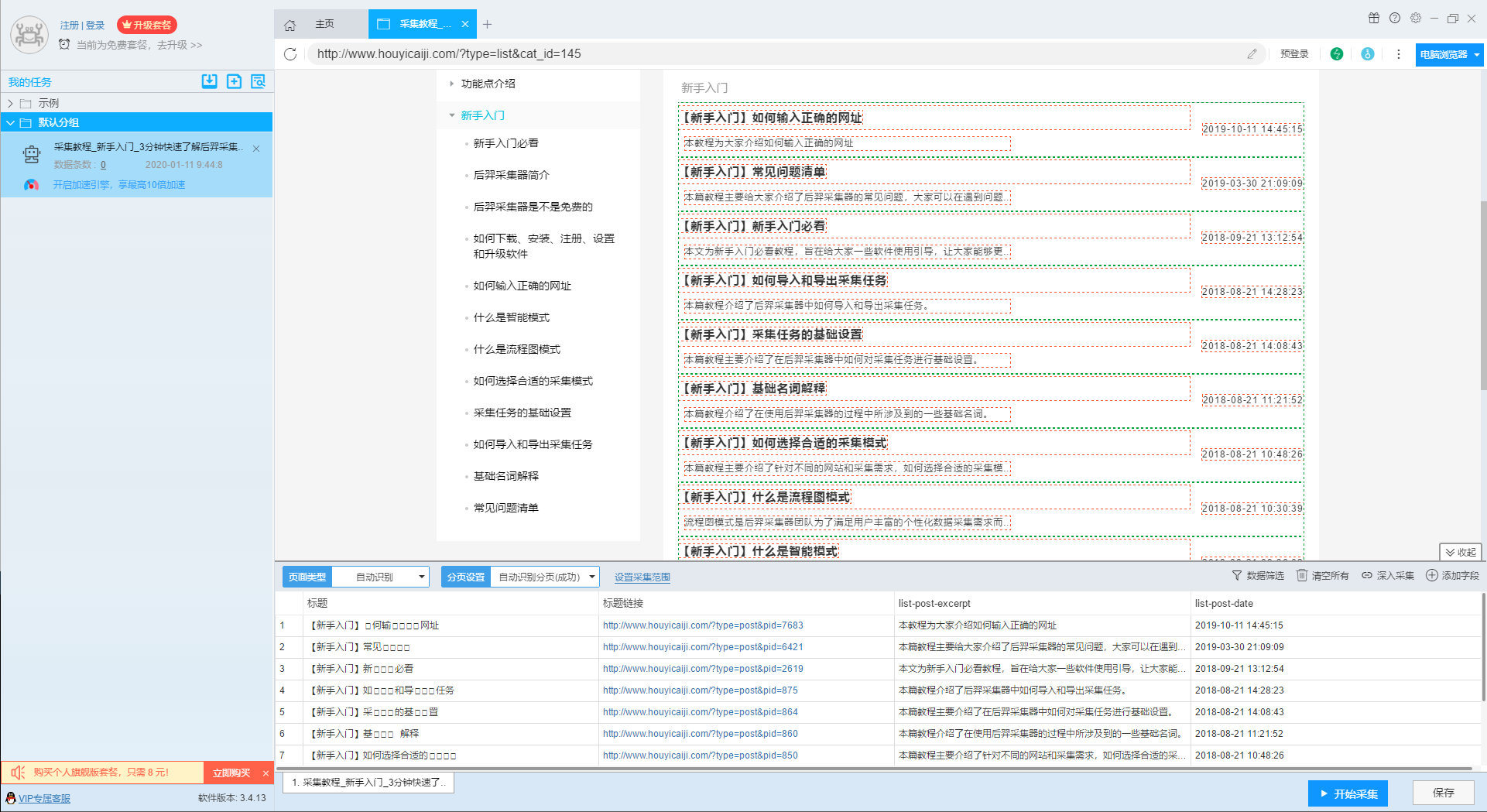
后羿采集器支持图像识别功能,可以识别图像中的文字,但是并非所有图像都可以识别,大家可以先进行测试,如果测试不成功,说明你遇到的情况暂时无法支持。 我们以智能模式中采集后羿采集器官网教程页为例,流程图模式的设置方式与此相同。 如下图所示,我们可以看到标题字段中有很多乱码,这是因为我们在网页中使用了图片替代了文字,这些图片在网页中和其他文字看起来是一样的,但是采集下来时就会变成乱码。 此时我们可以右击字段,然后在识别格式中选择“内容乱码”。 之后在字段上会出现“识别”按钮。 点击“识别”按钮,软件会进行图像识别,识别结…
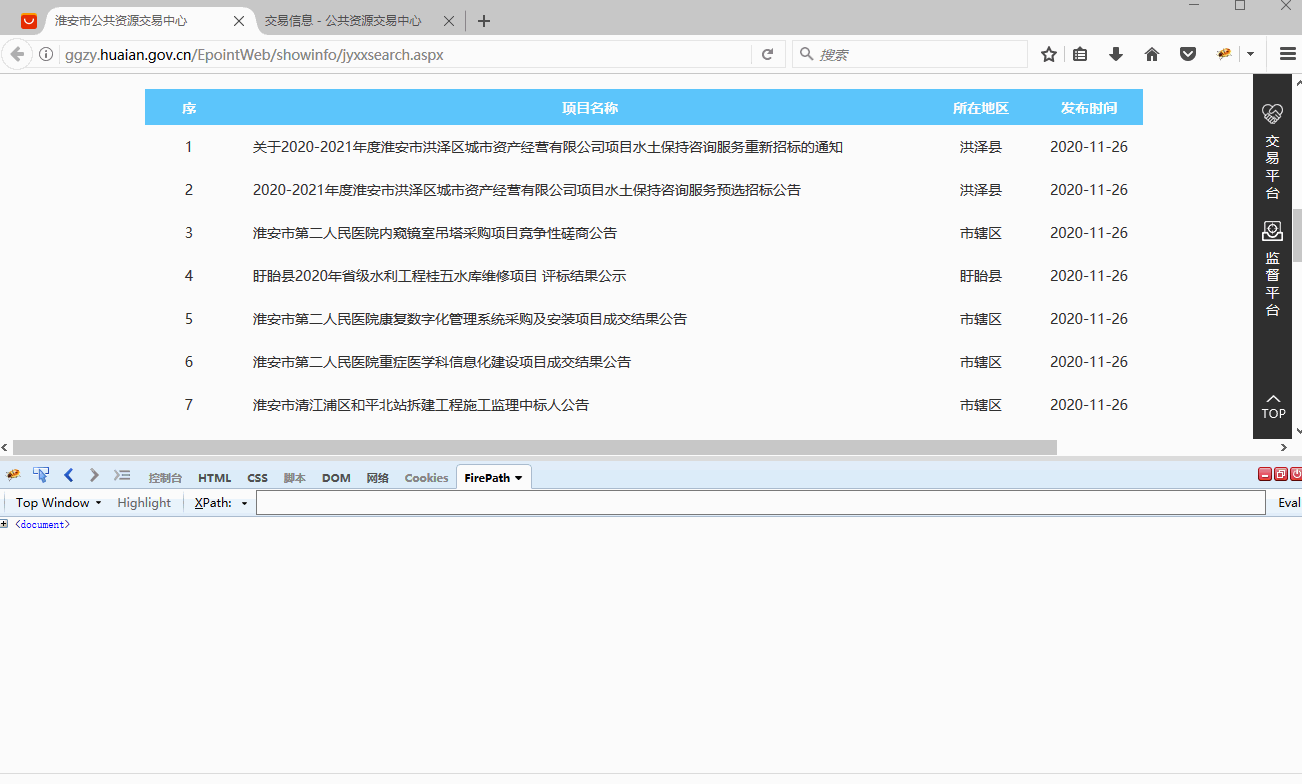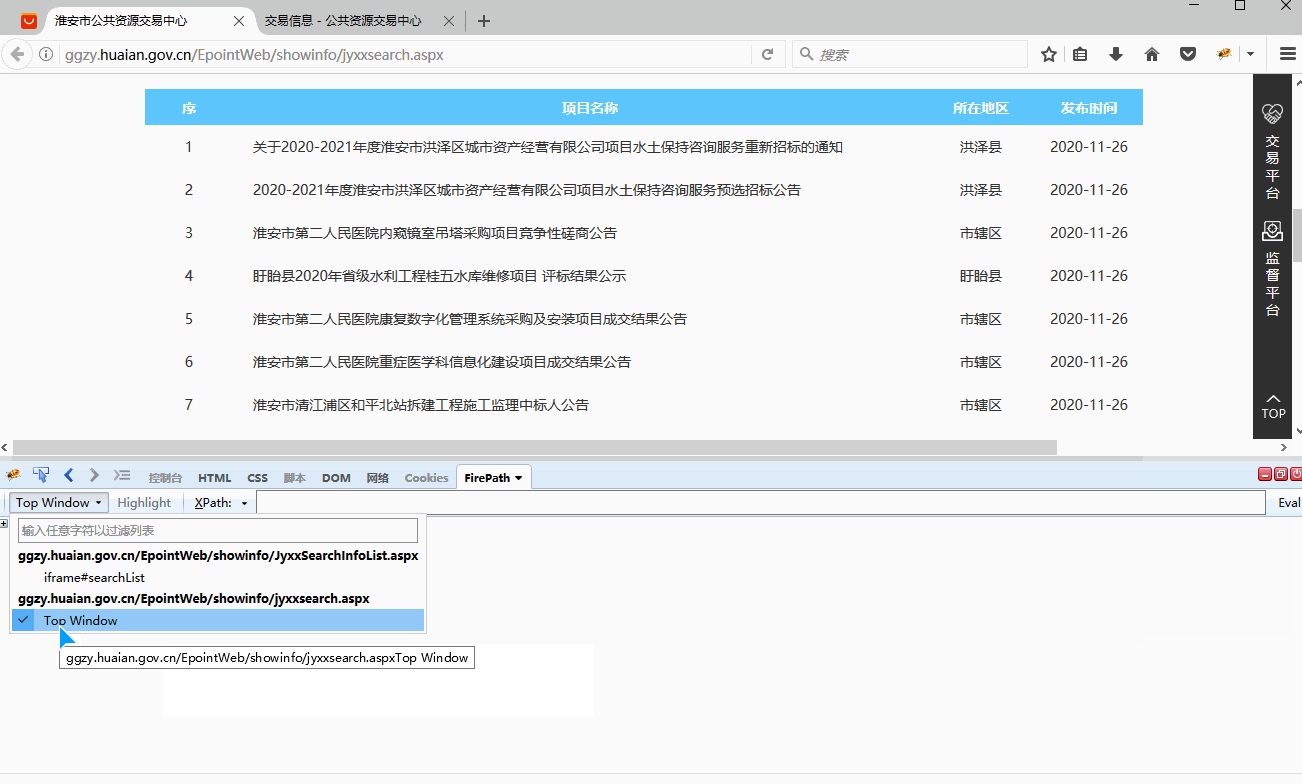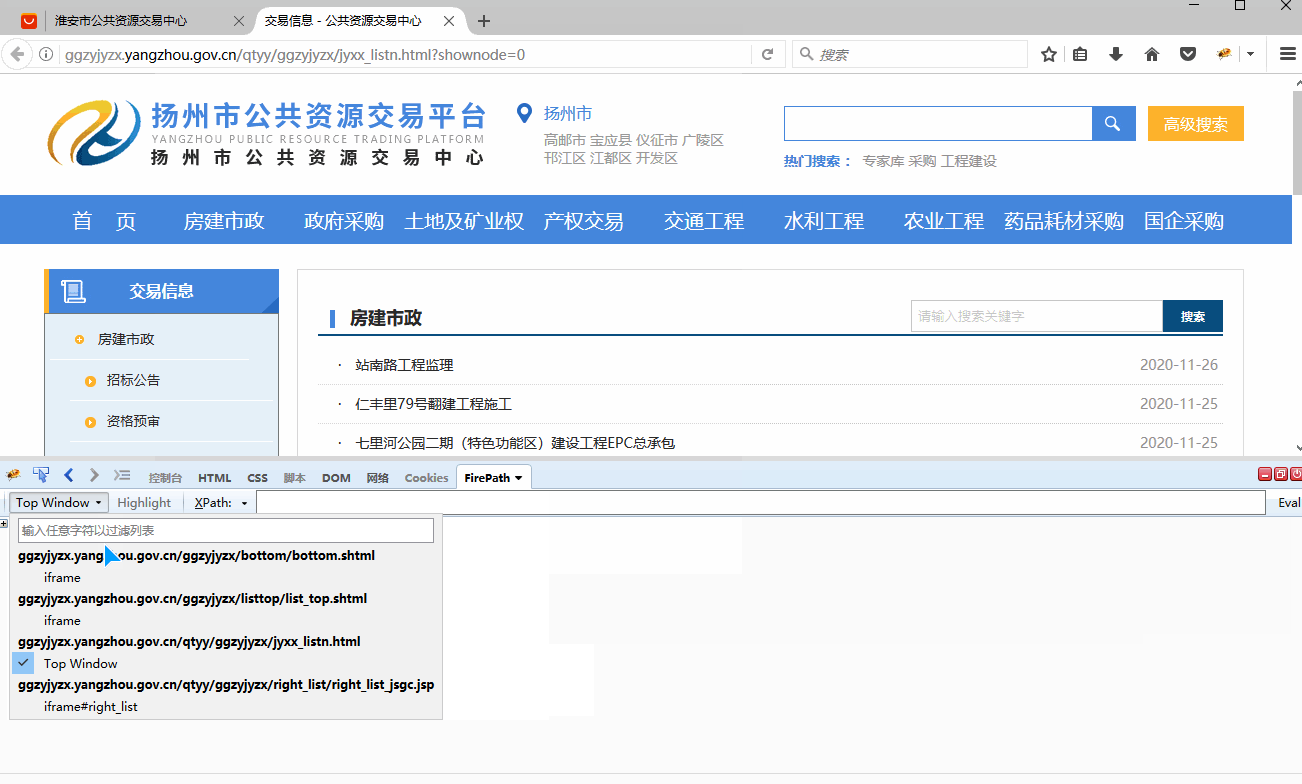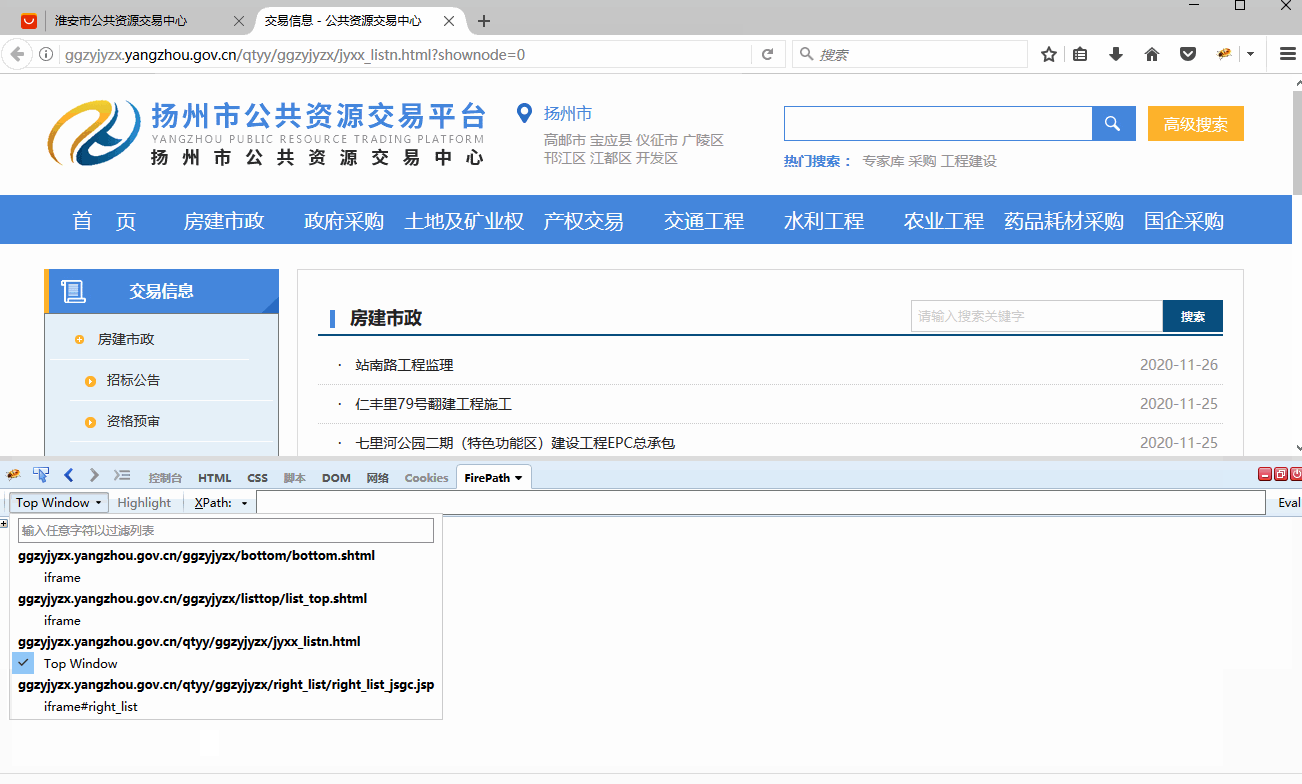
有的网页包含iframe框架,在八爪鱼中也需进行相应设置,本教程将详细讲解。 1、什么是iframe框架? 通俗来说,iframe框架就是在同一个页面中有多个网页,也就是网页中嵌套了其他的网页。 iframe框架可能有一层,也可能有多层。 如何判断网页有几层iframe框架? 借助火狐浏览器的irebug和firepath插件,我们可以很容易地判断出网页有几层iframe框架。 如果没有安装,请查看 火狐浏览器的irebug和firepath插件安装教程 。 安装好后,点击【Top Window】位置,会…