
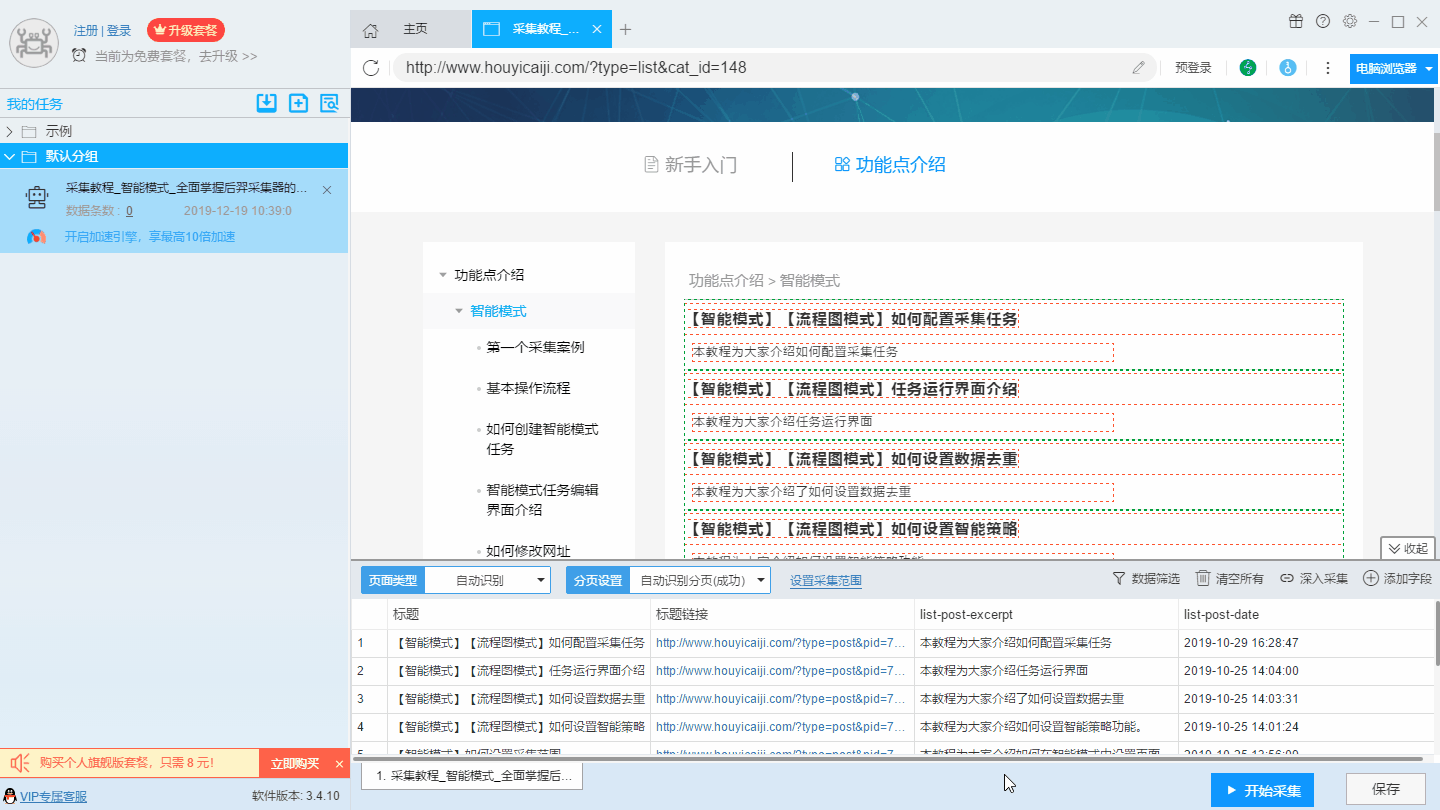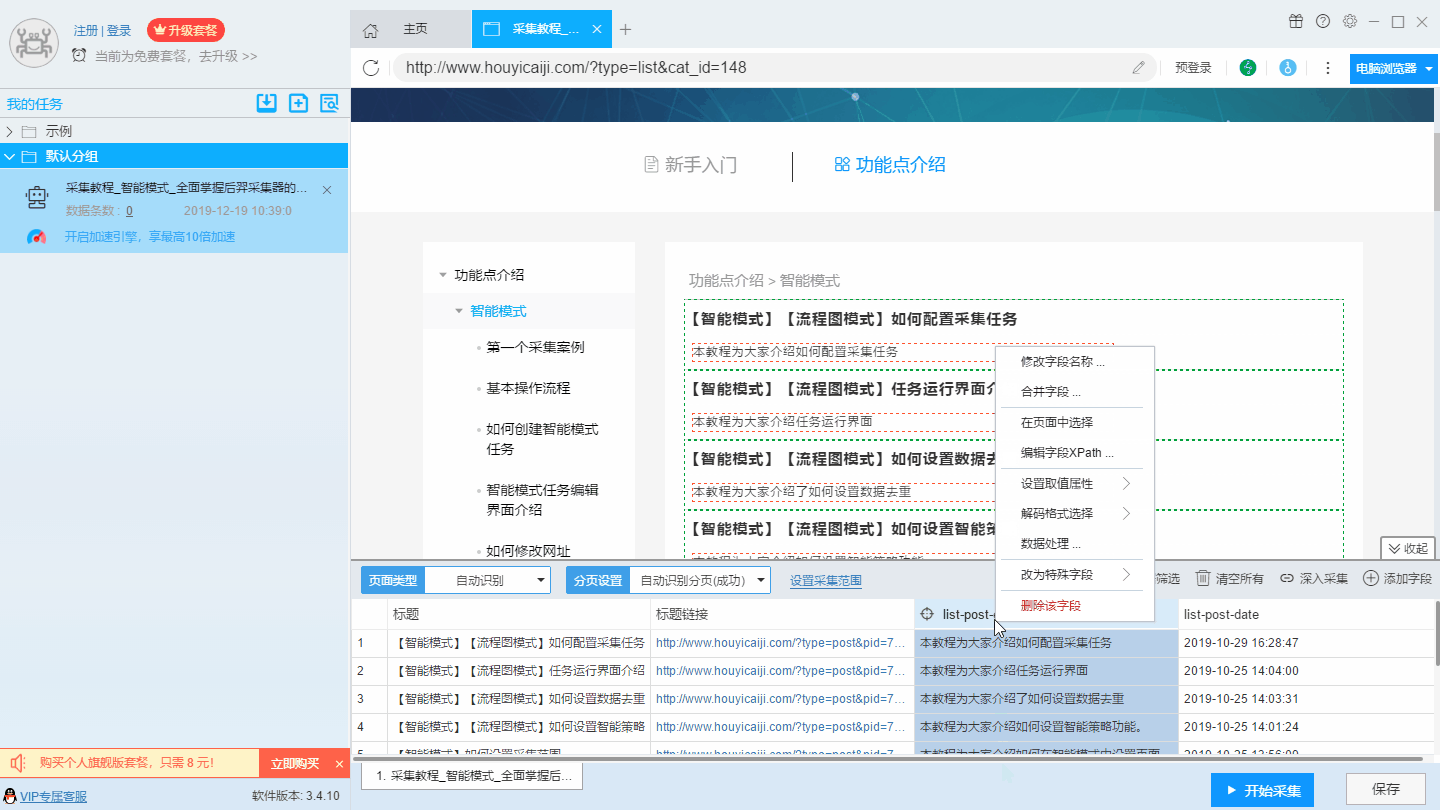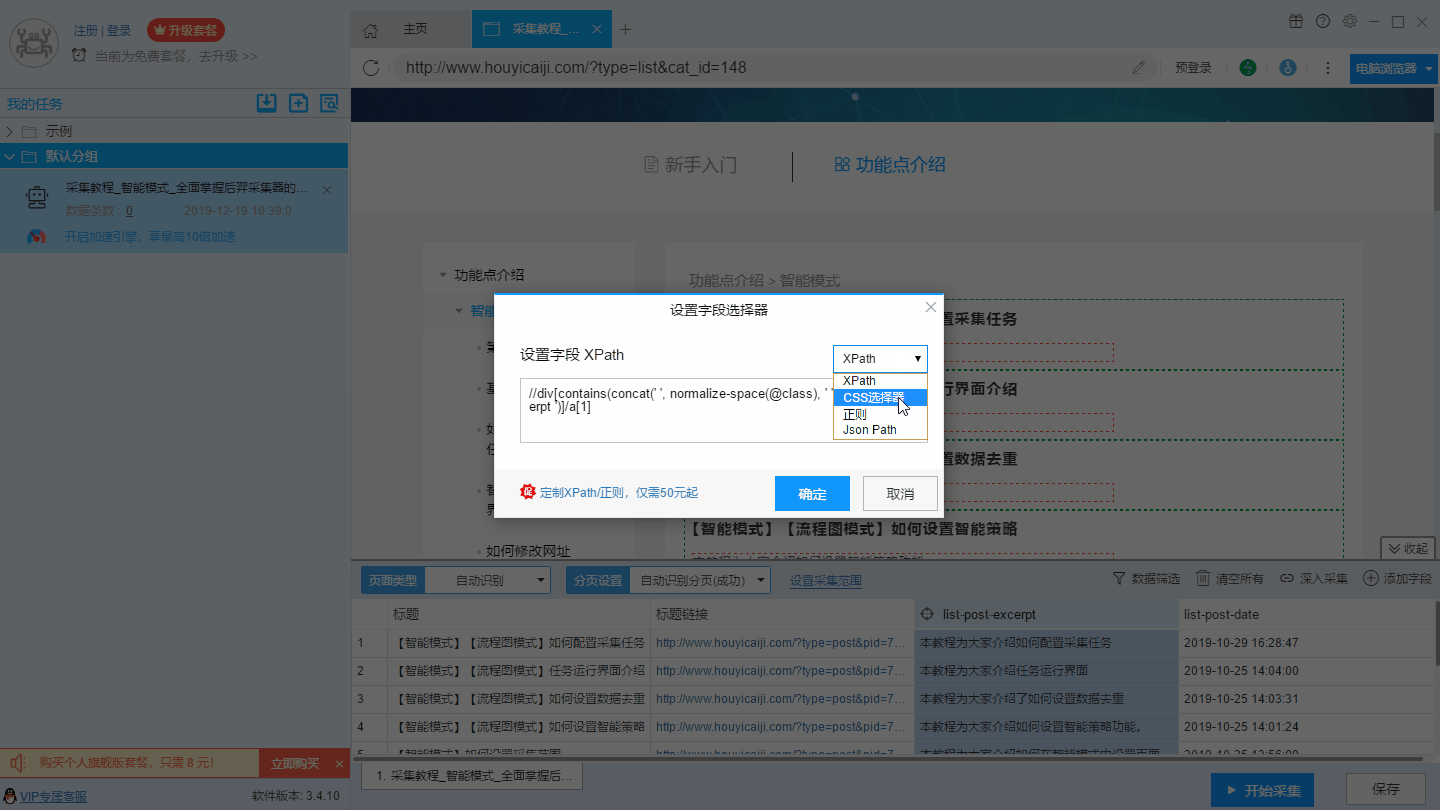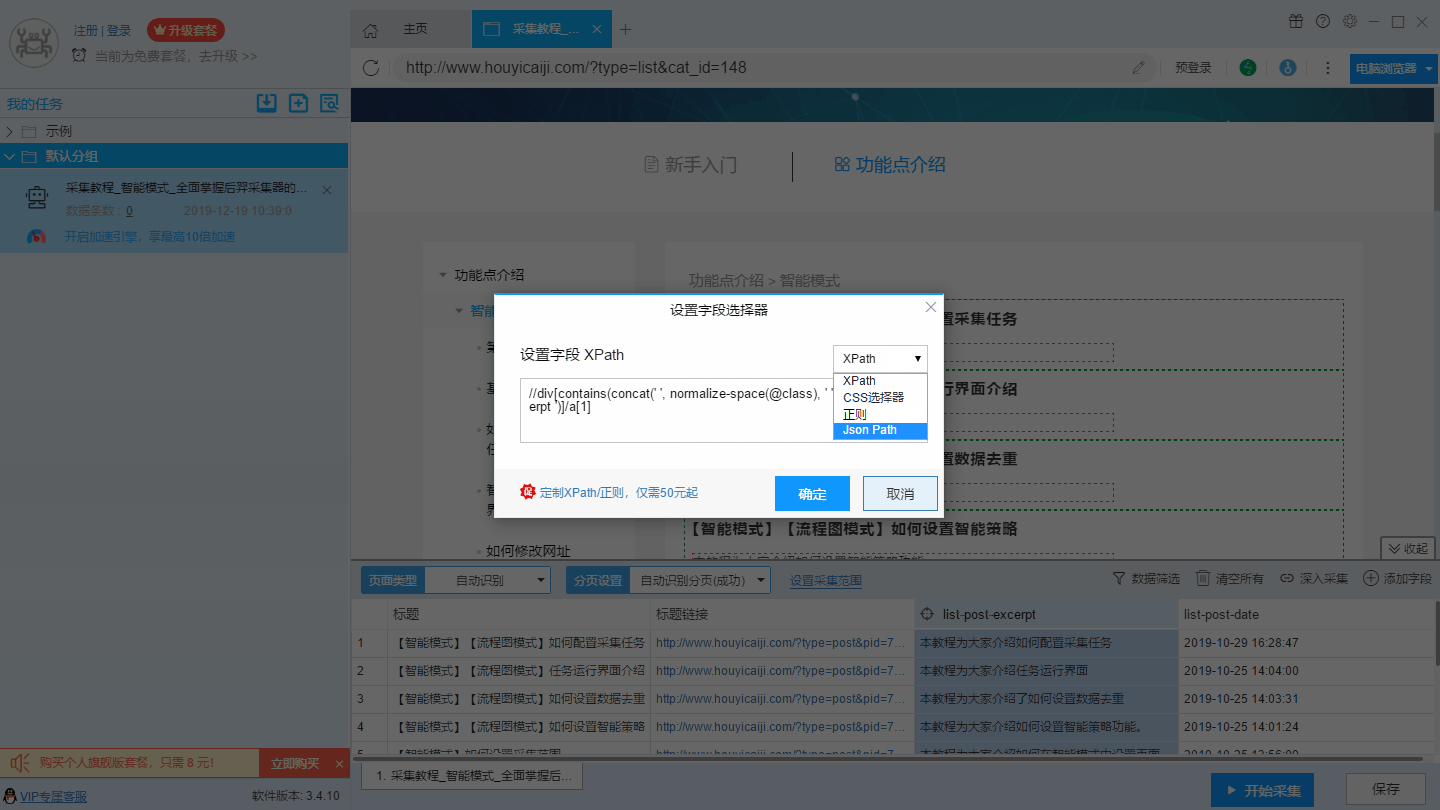
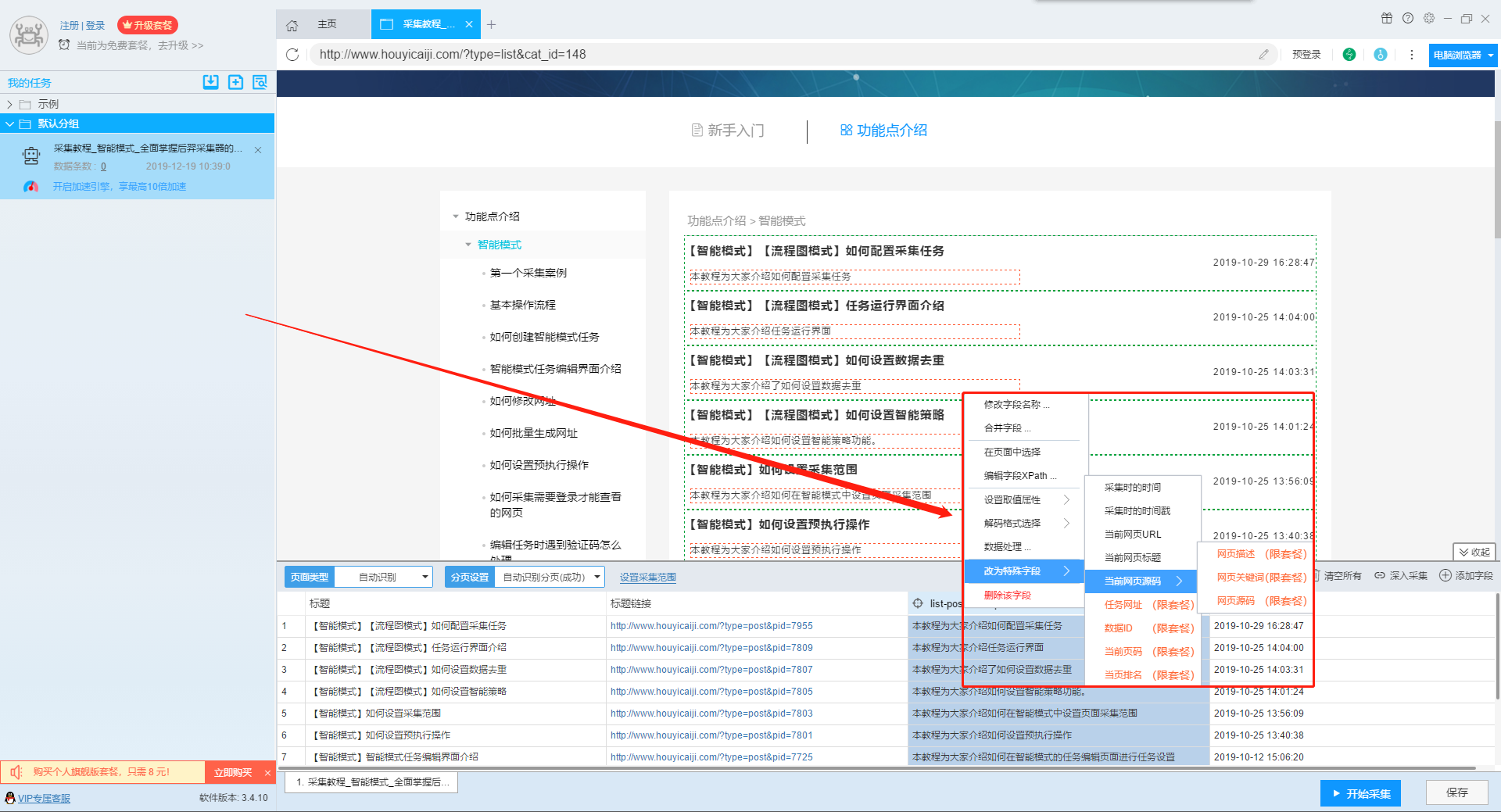
在智能模式下,后羿采集器会按照列表类型对网址进行识别并采集列表元素中的字段,如果软件自动识别的字段不符合您的需求,或者您需要修改字段的相关信息,那么您可以右击字段,然后在弹出的菜单栏中进行设置,如下图所示:
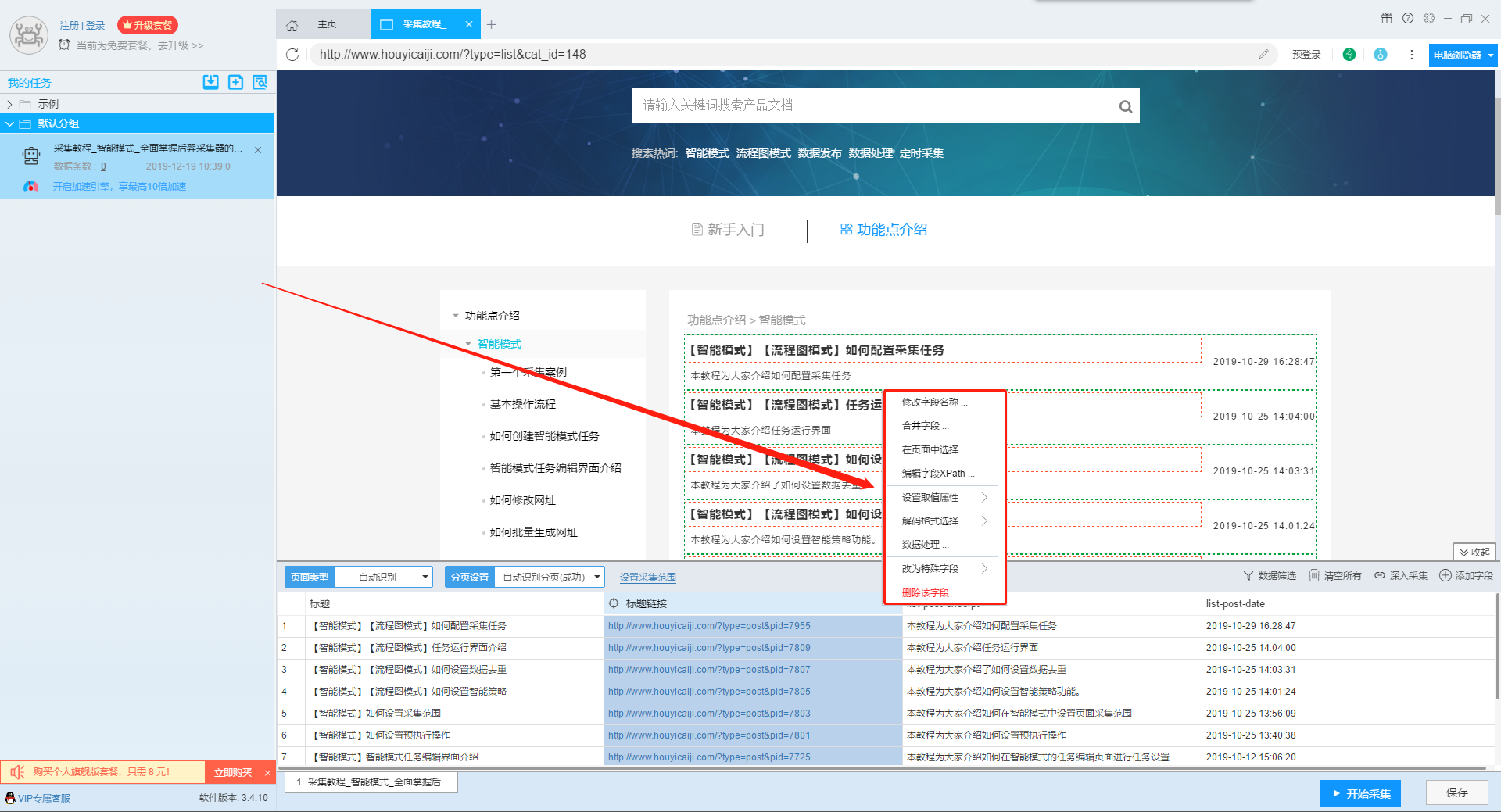
具体设置的详细介绍如下:
1、修改字段名称
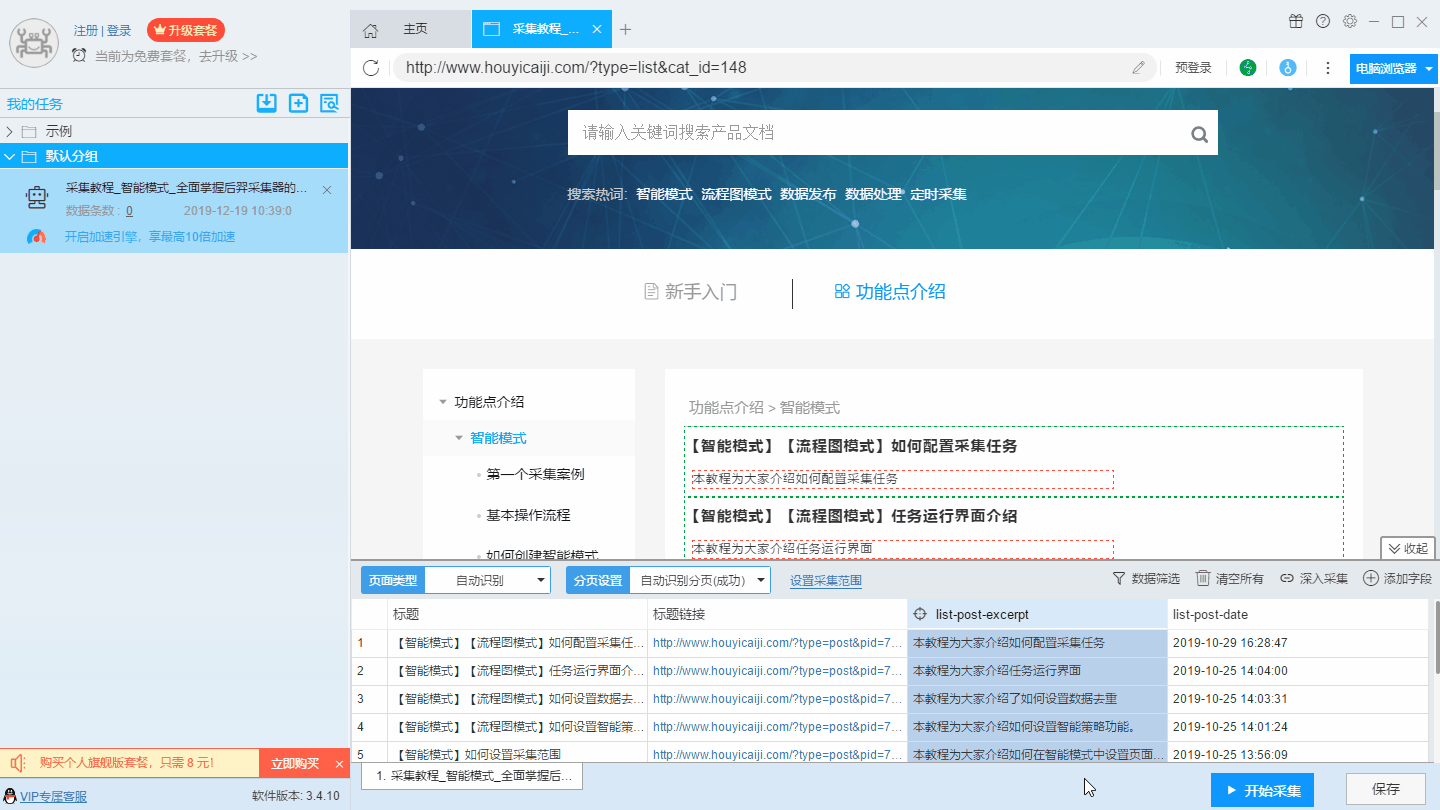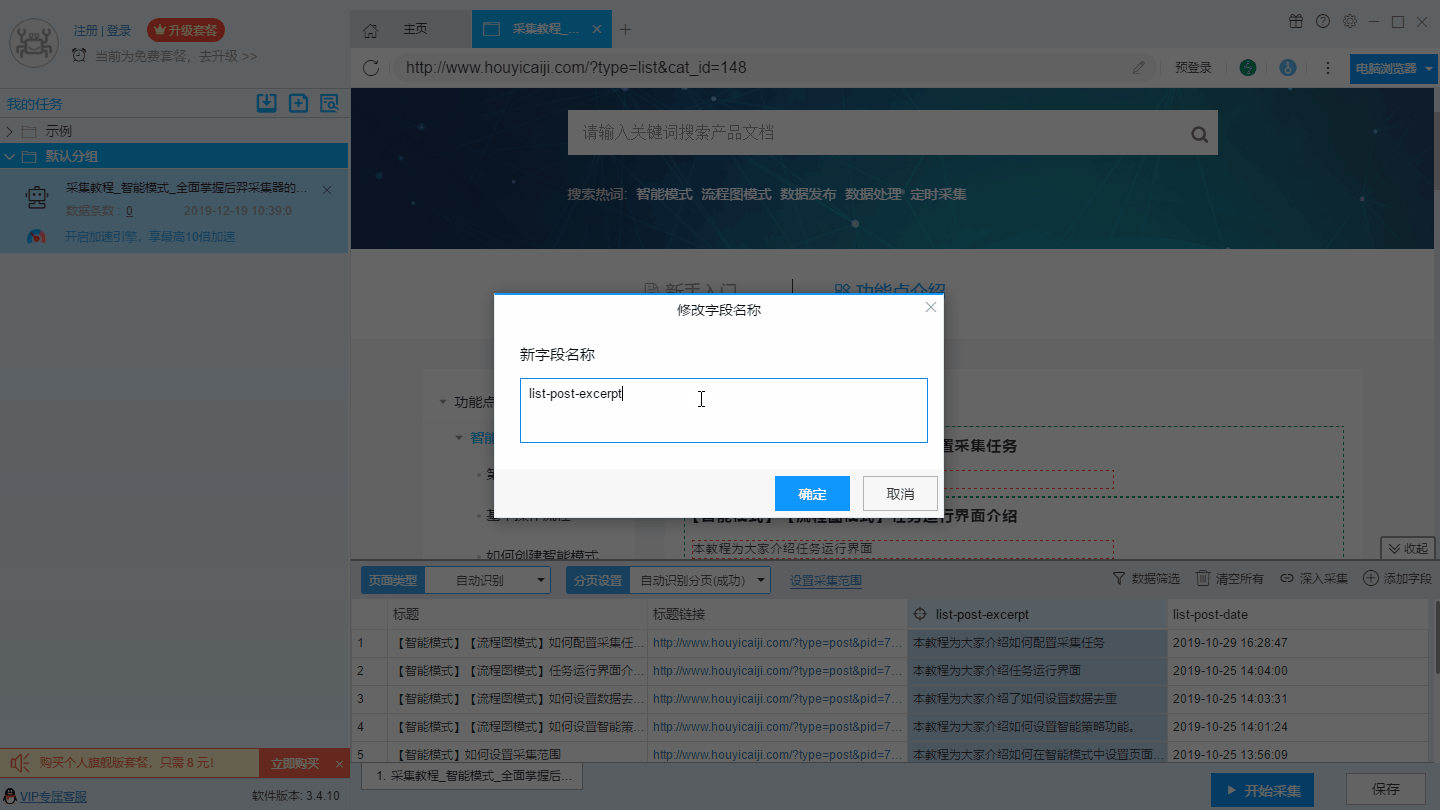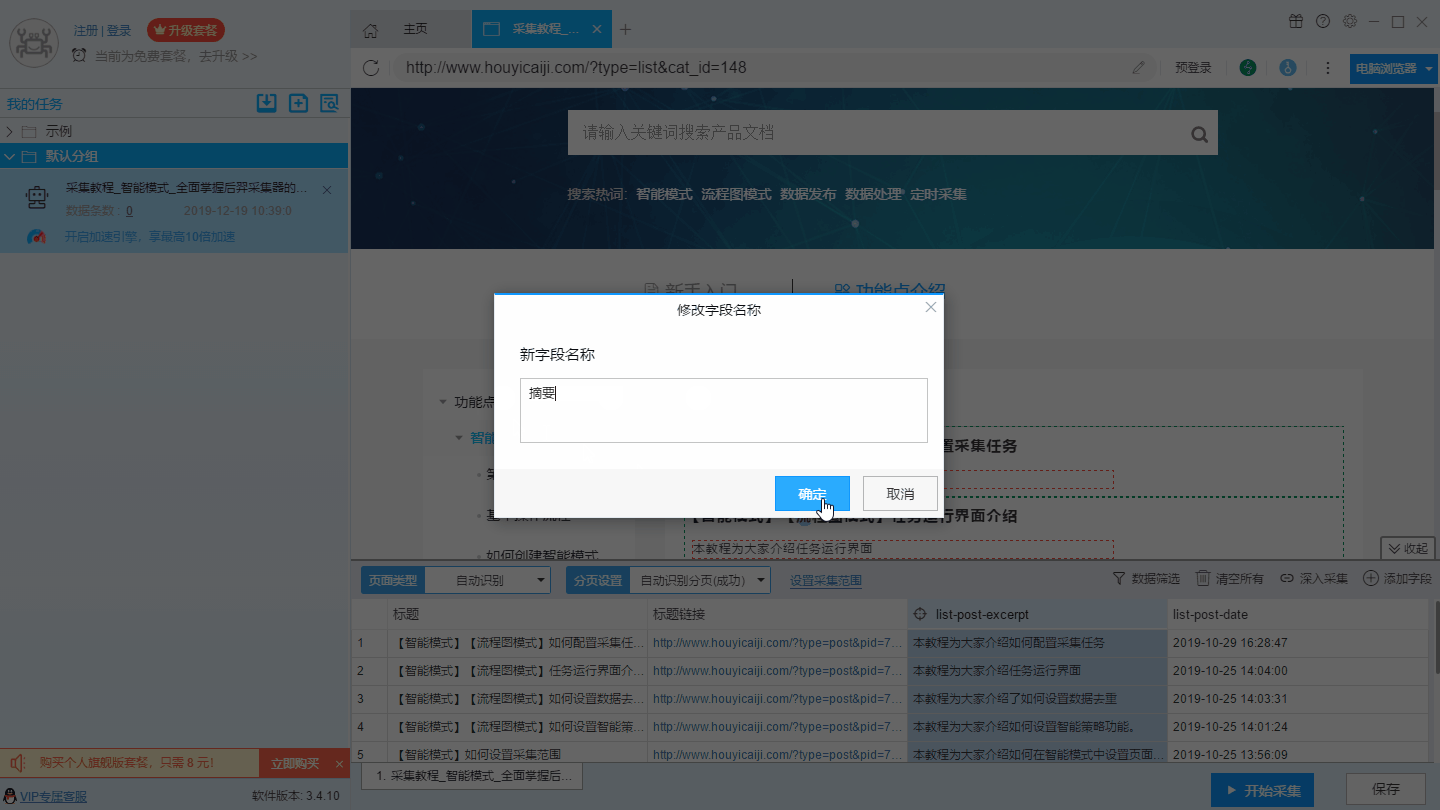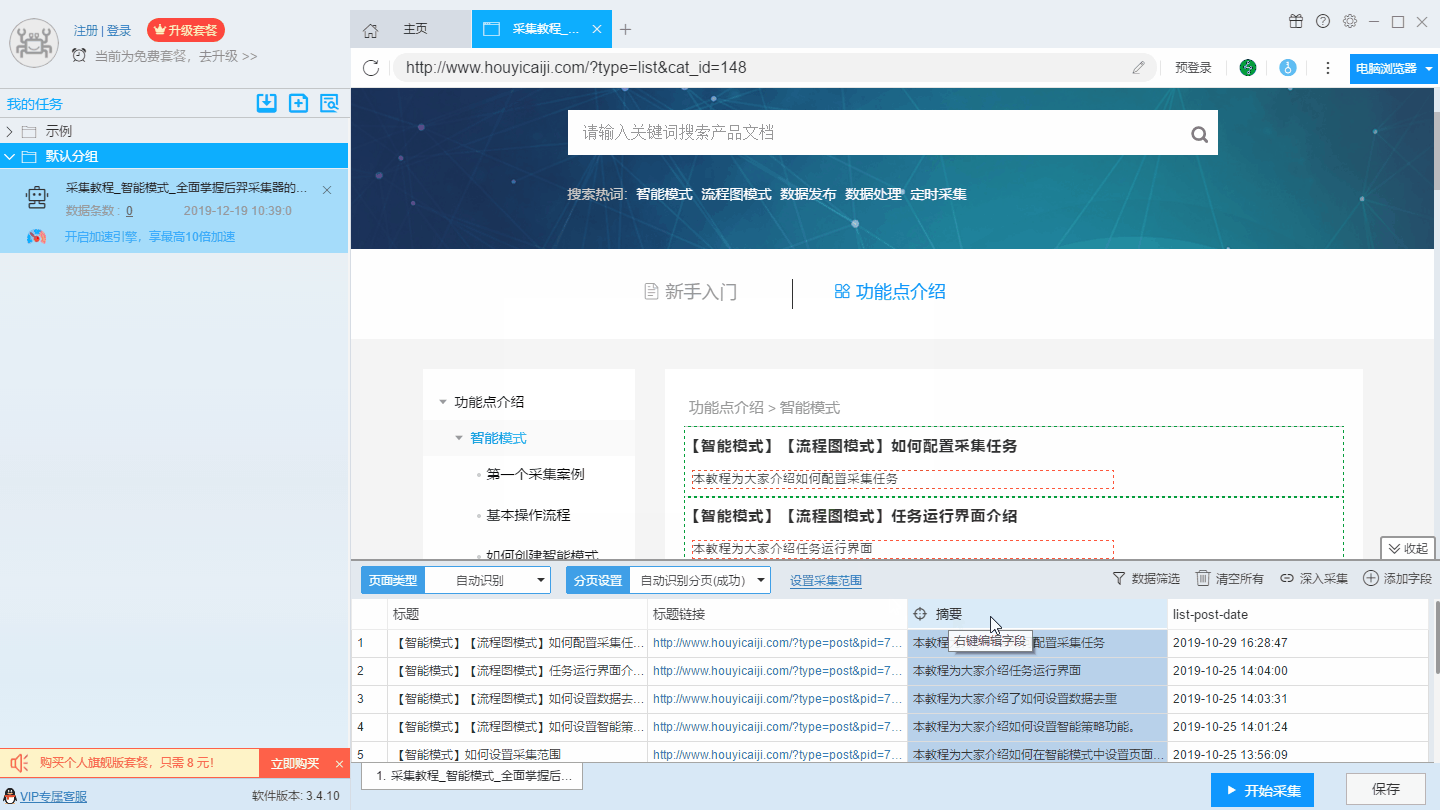
2、合并字段
合并字段有两种办法,一种是点击一条需要合并的字段,右击选择“合并字段”,然后在页面中选择需要合并的字段,这种方式适合两个字段的合并。在合并字段中,用户可以设置两个字段内容之间的分隔符,如果不需要分隔符,在分隔符部分直接设置为空白就好。
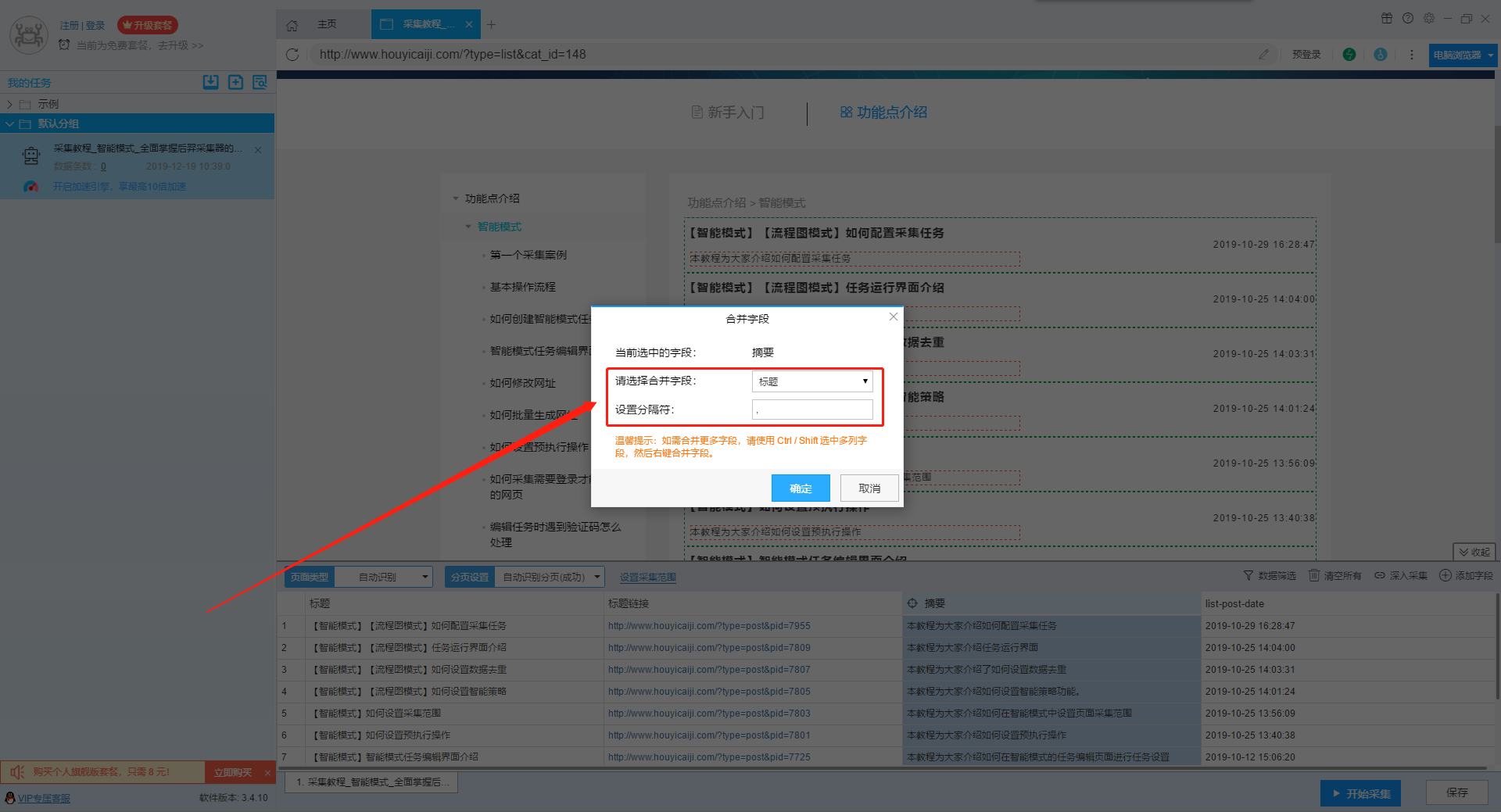
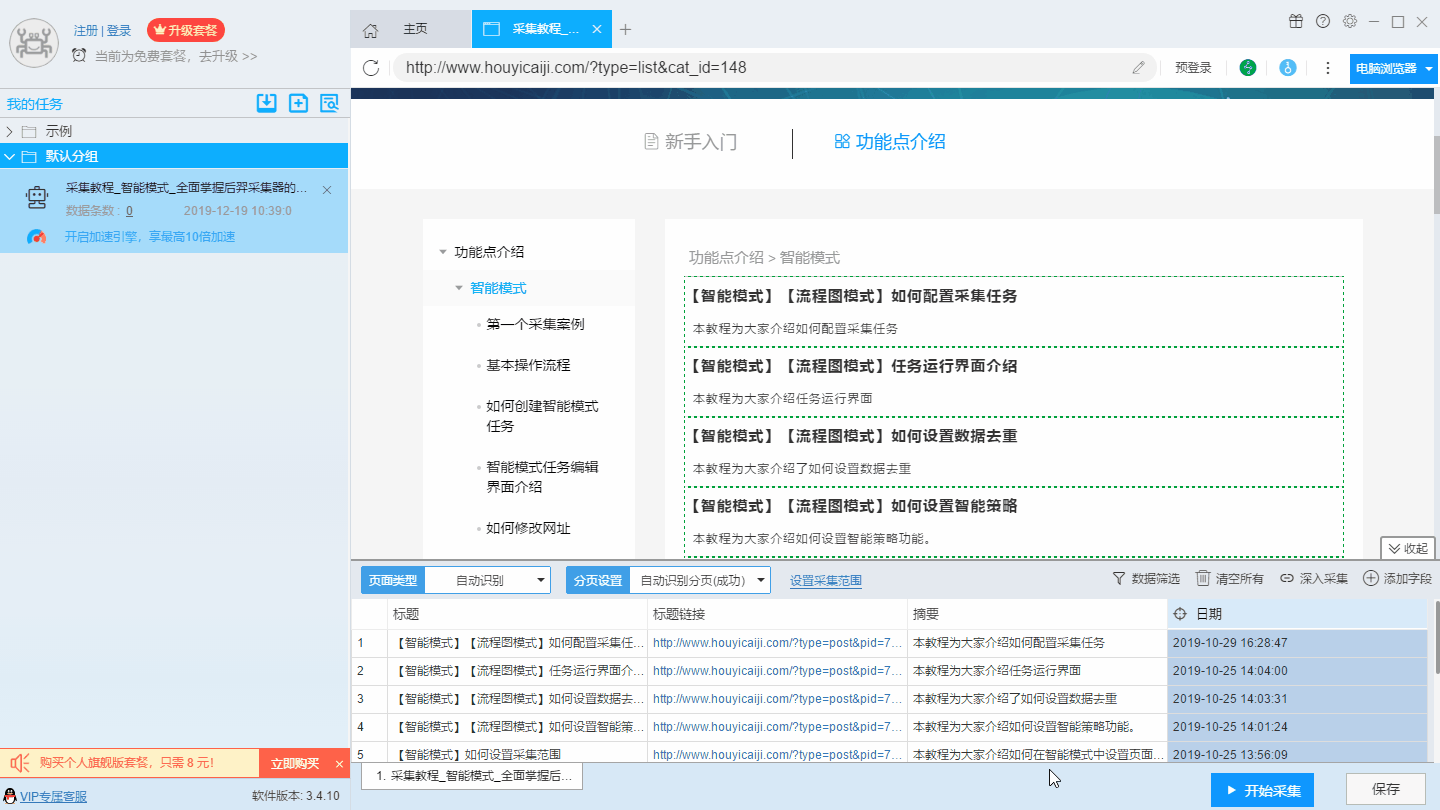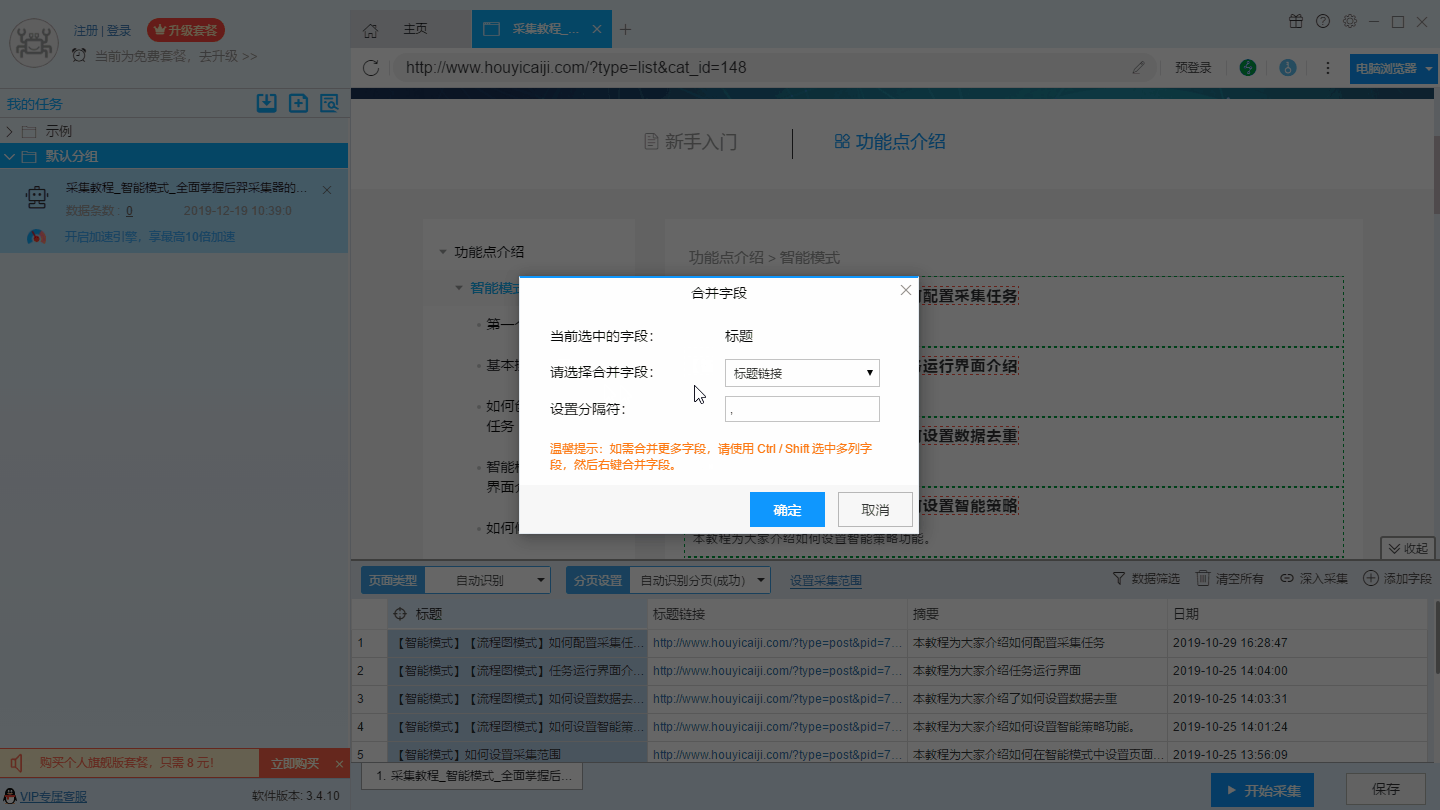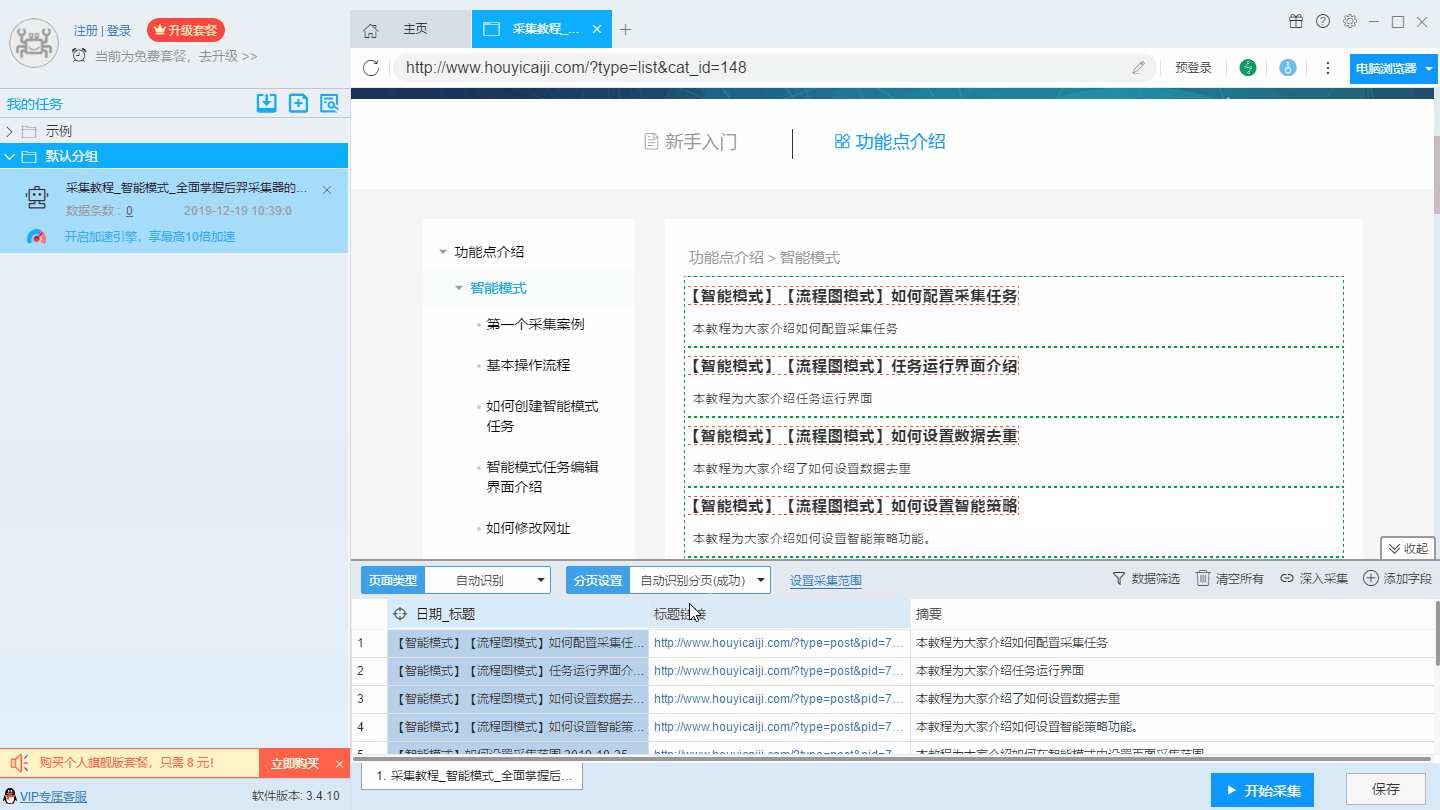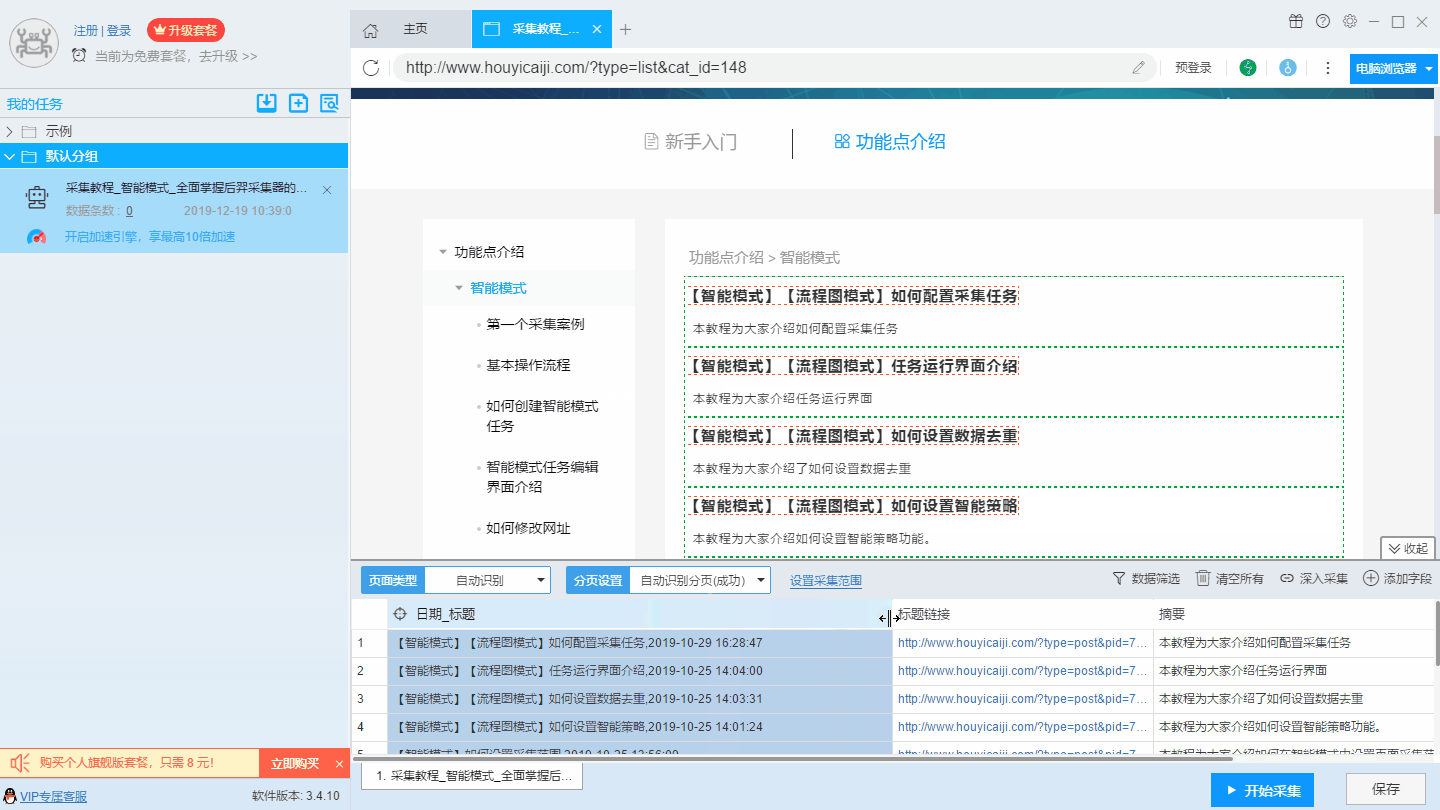
另外一种方法是按crtl或shift选中多个字段,然后右击“合并字段”,这种方法适合多个字段的合并。
3、在页面中选择
如果要修改字段中提取的内容,或者在添加新字段时进行提取对象的设置,可以点击“在页面中选择”或者字段上的瞄准器图标,然后在网页中点击需要的数据。
4、编辑字段Xpath
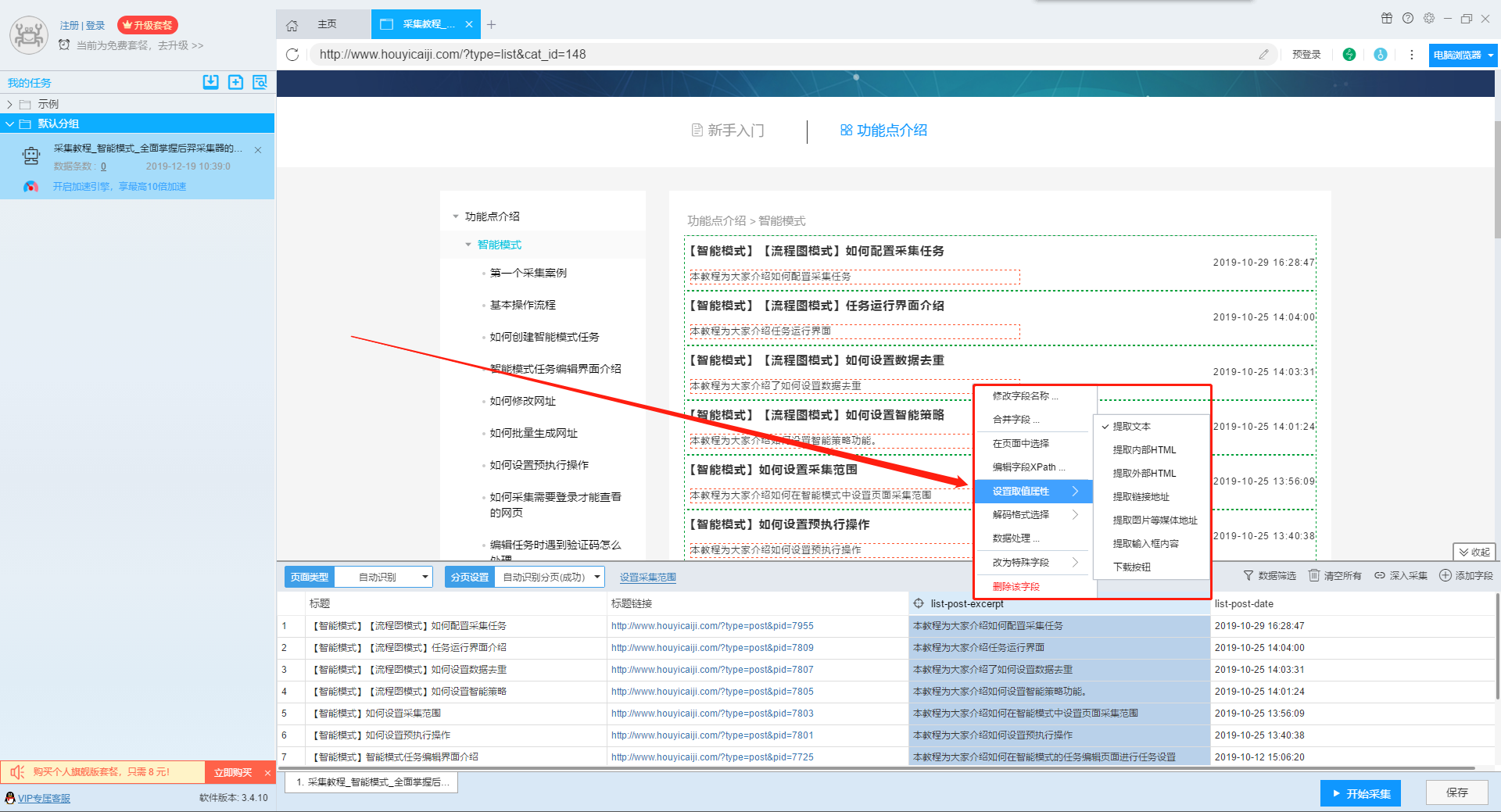
5、设置取值属性
不同的数据需要设置不同的取值属性,在设置新字段的时候,字段的取值默认的是文本字段,一般情况下,在您选取新数据时,后羿采集器会自动帮你判断好字段属性,您不需要另外设置,但如果出现判断失误的情况下,您可以自己设置字段的取值属性。
提取文本:适合普通的文本数据
提取内部HTML:适合提取不包括内容自身的HTML
提取外部HTML:适合提取包括内容自身的HTML
提取链接地址:适合提取链接的数据
提取图片等媒体地址:适合提取图片等媒体资源
提取输入框内容:适合提取输入框的文字,多用于关键词采集时使用
下载按钮:用于提取下载地址
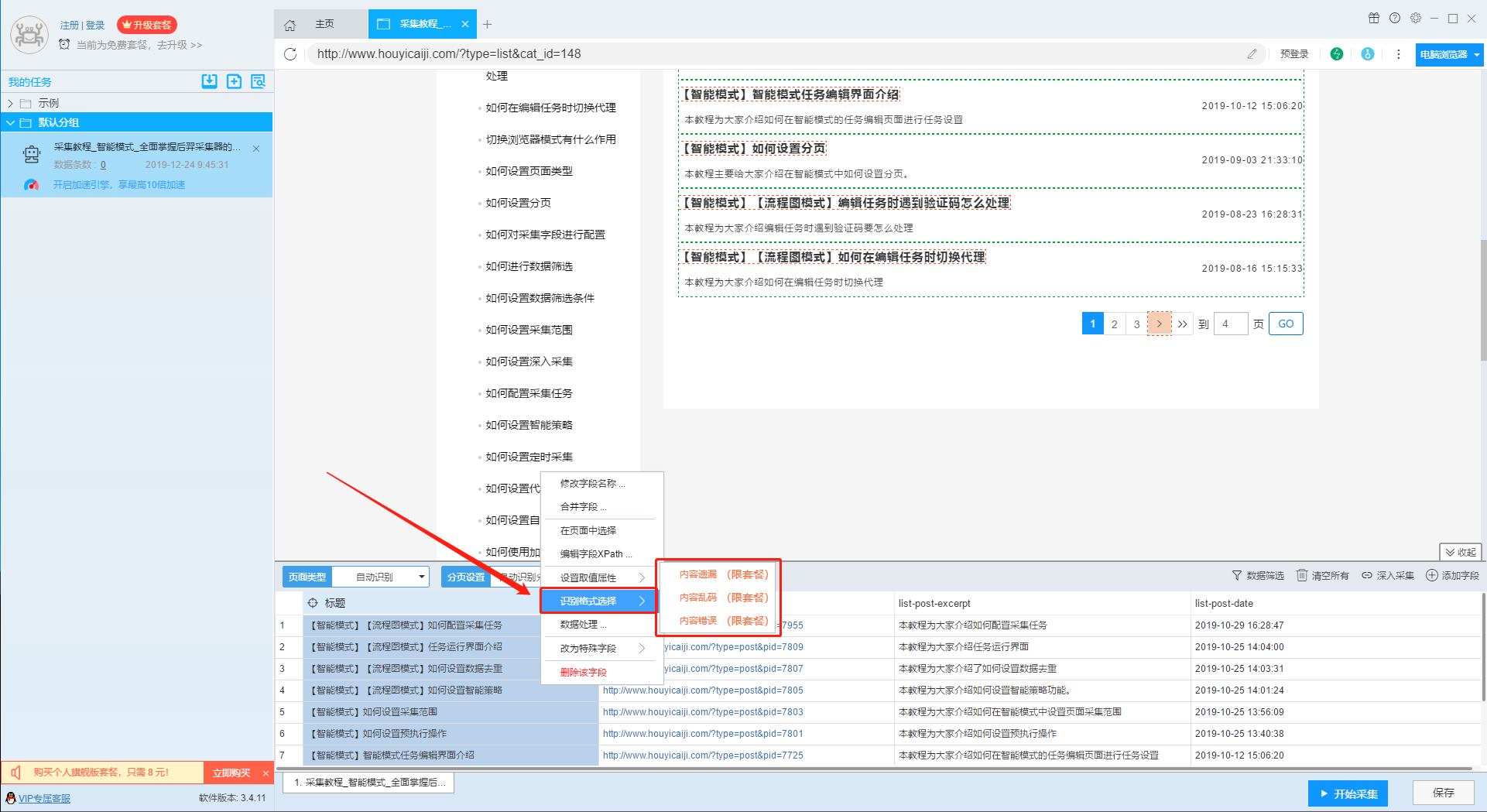
6、识别格式选择
在进行图像识别时,通常软件会自动检测到识别格式,如果有些内容未识别到或者识别结果不正确,我们可以手动选择识别格式。需要注意的是,图像识别功能为企业版功能。
7、数据处理
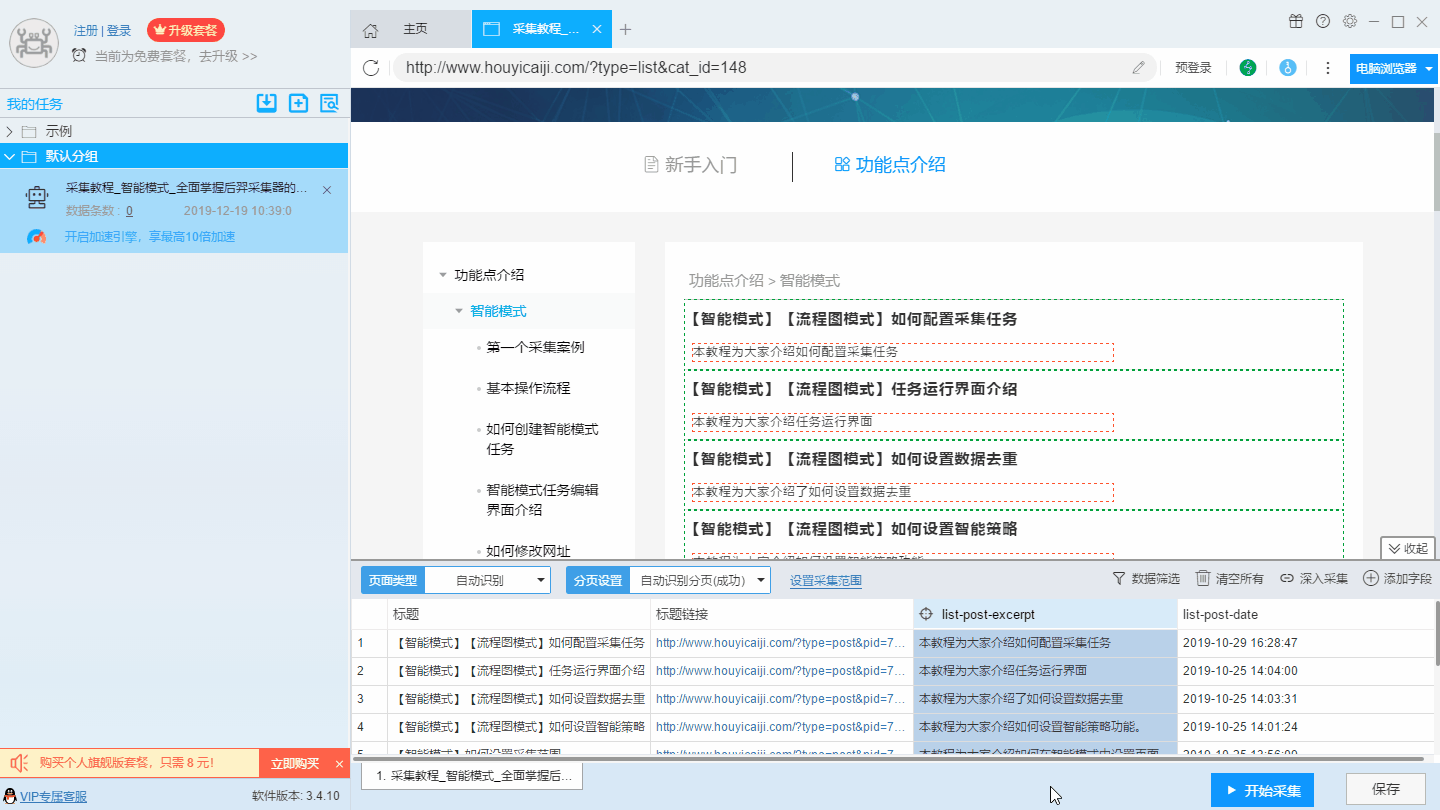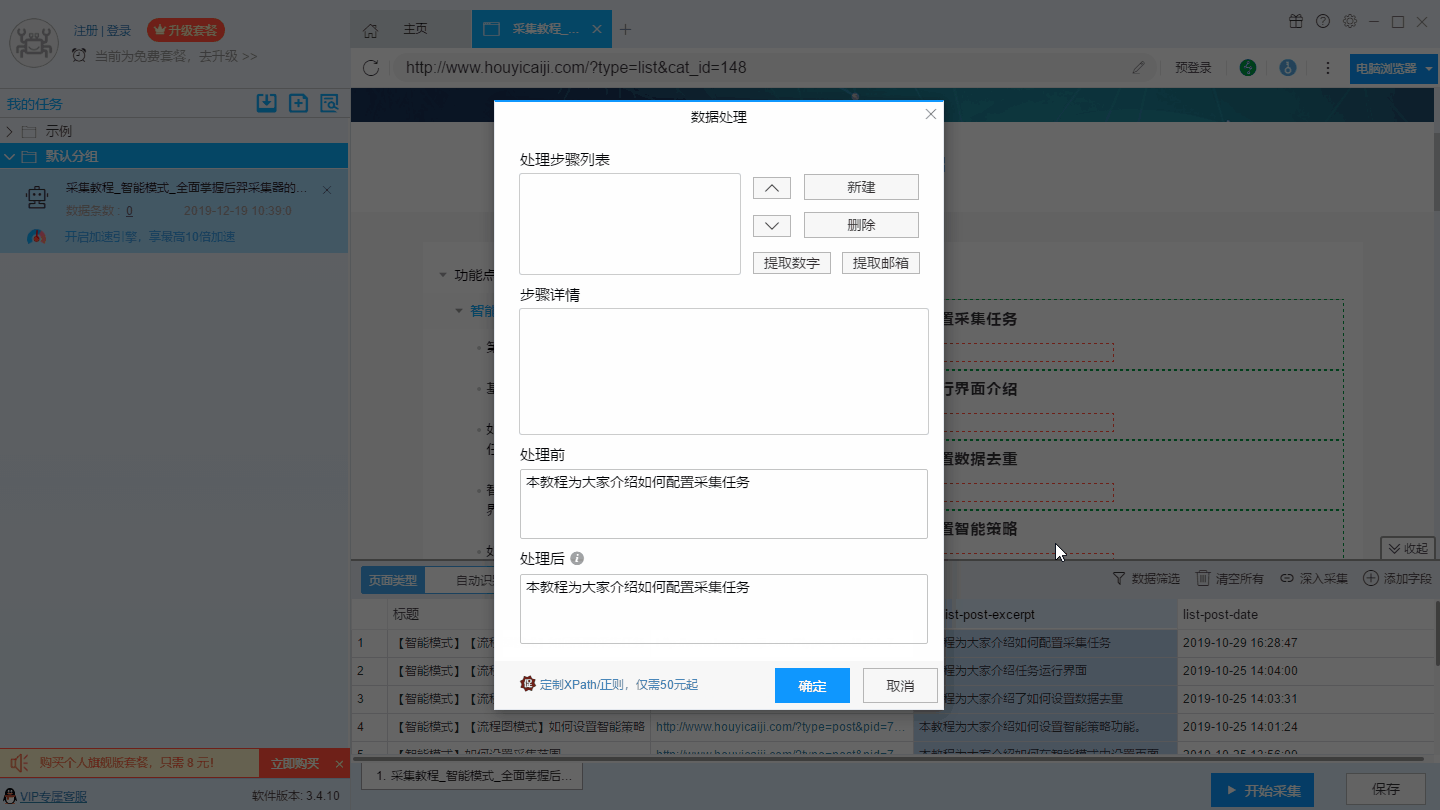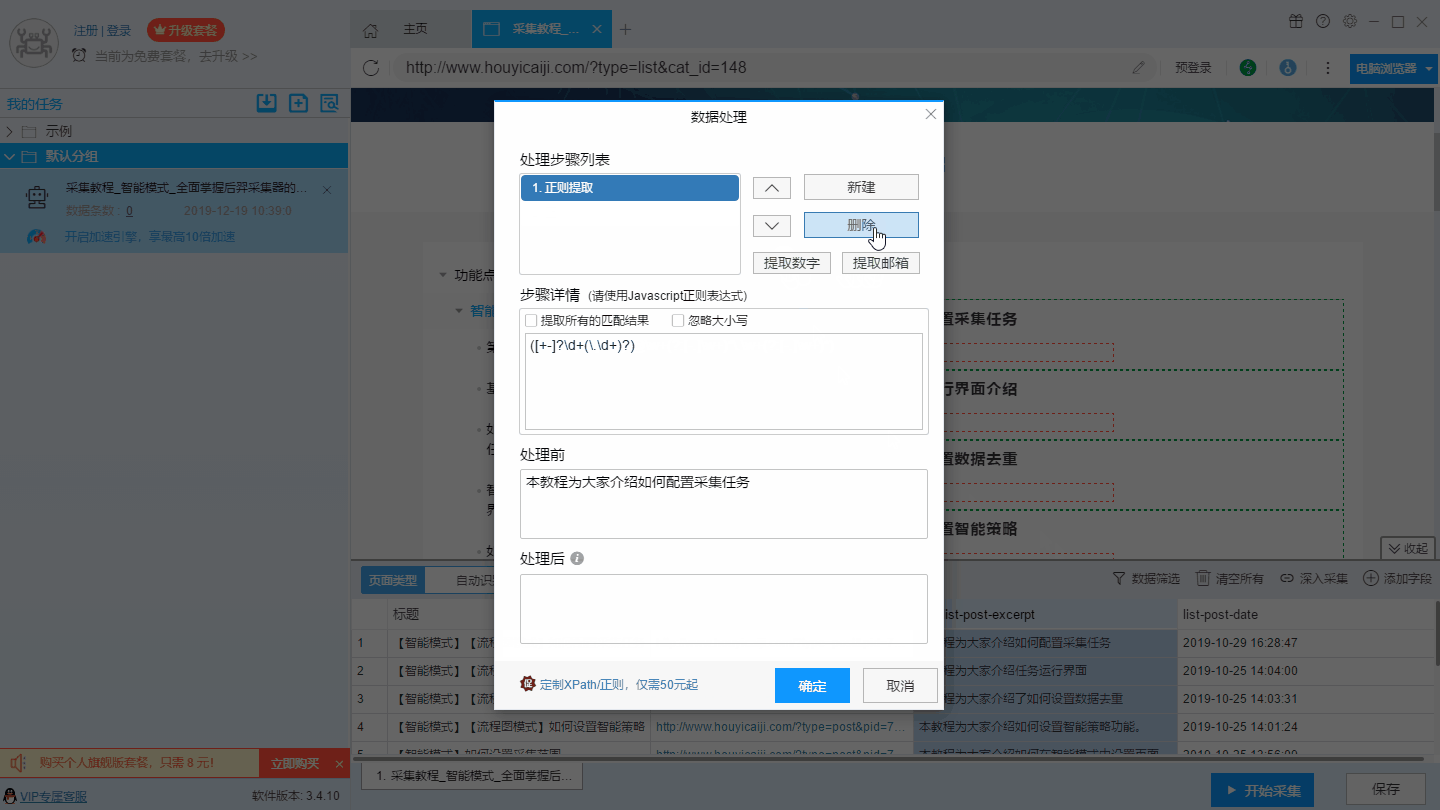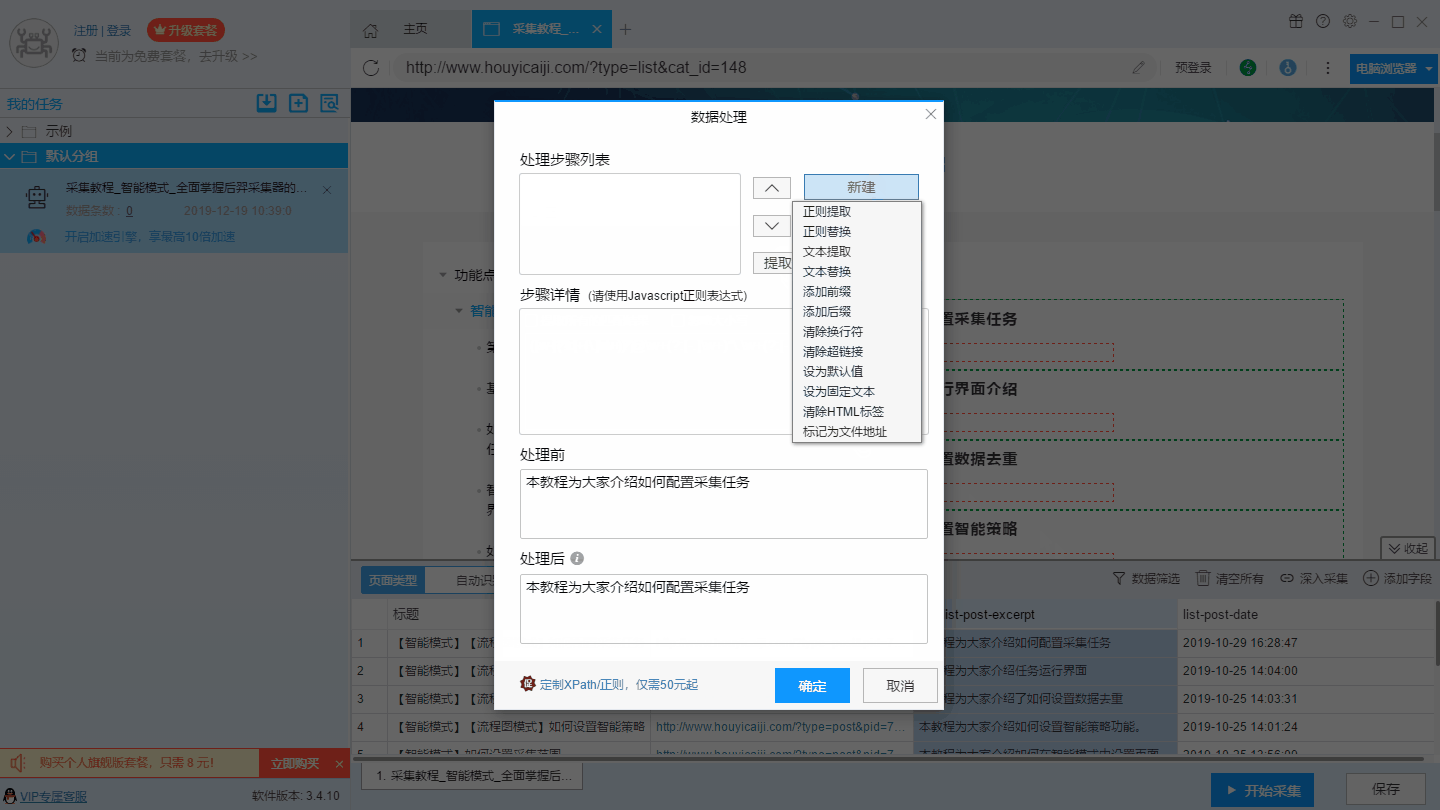
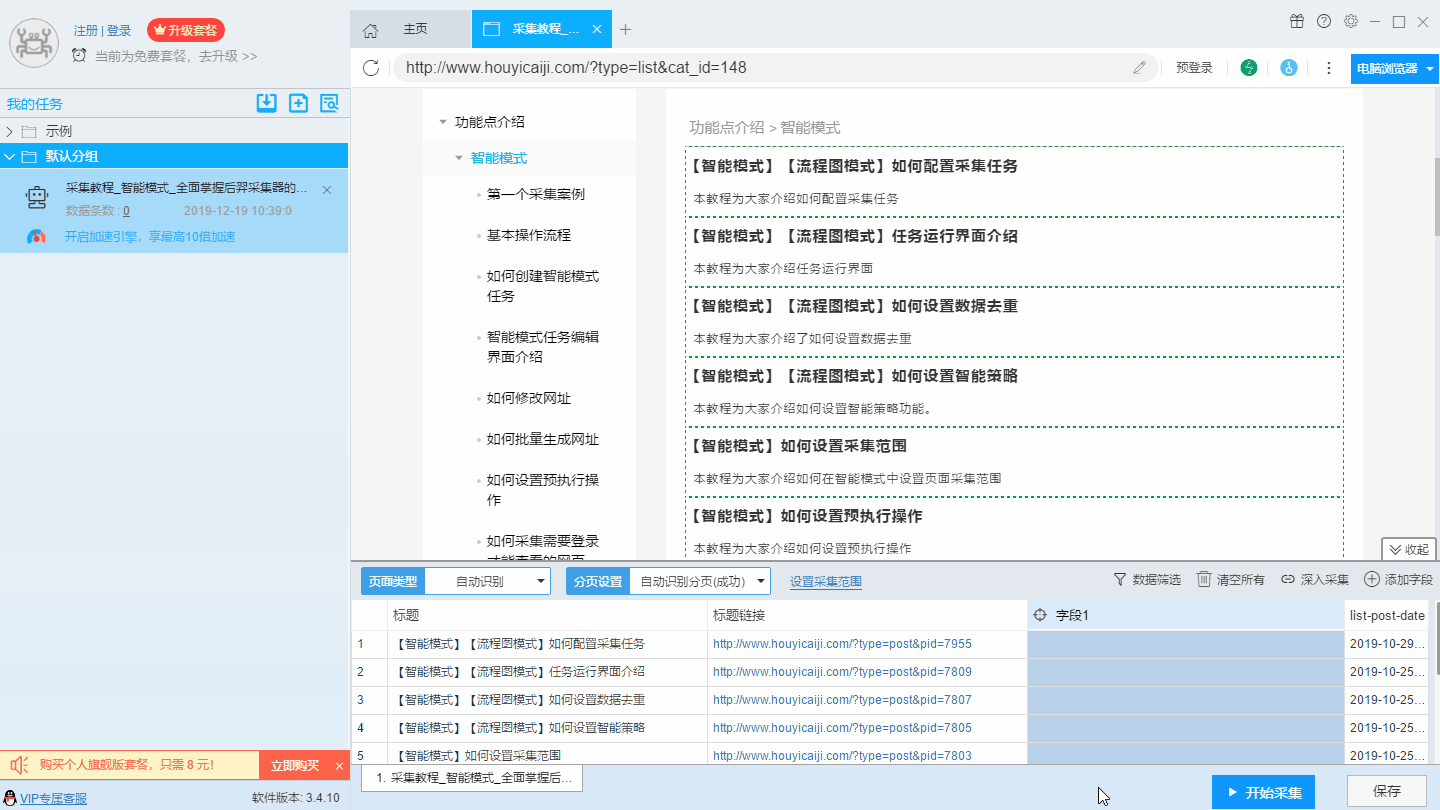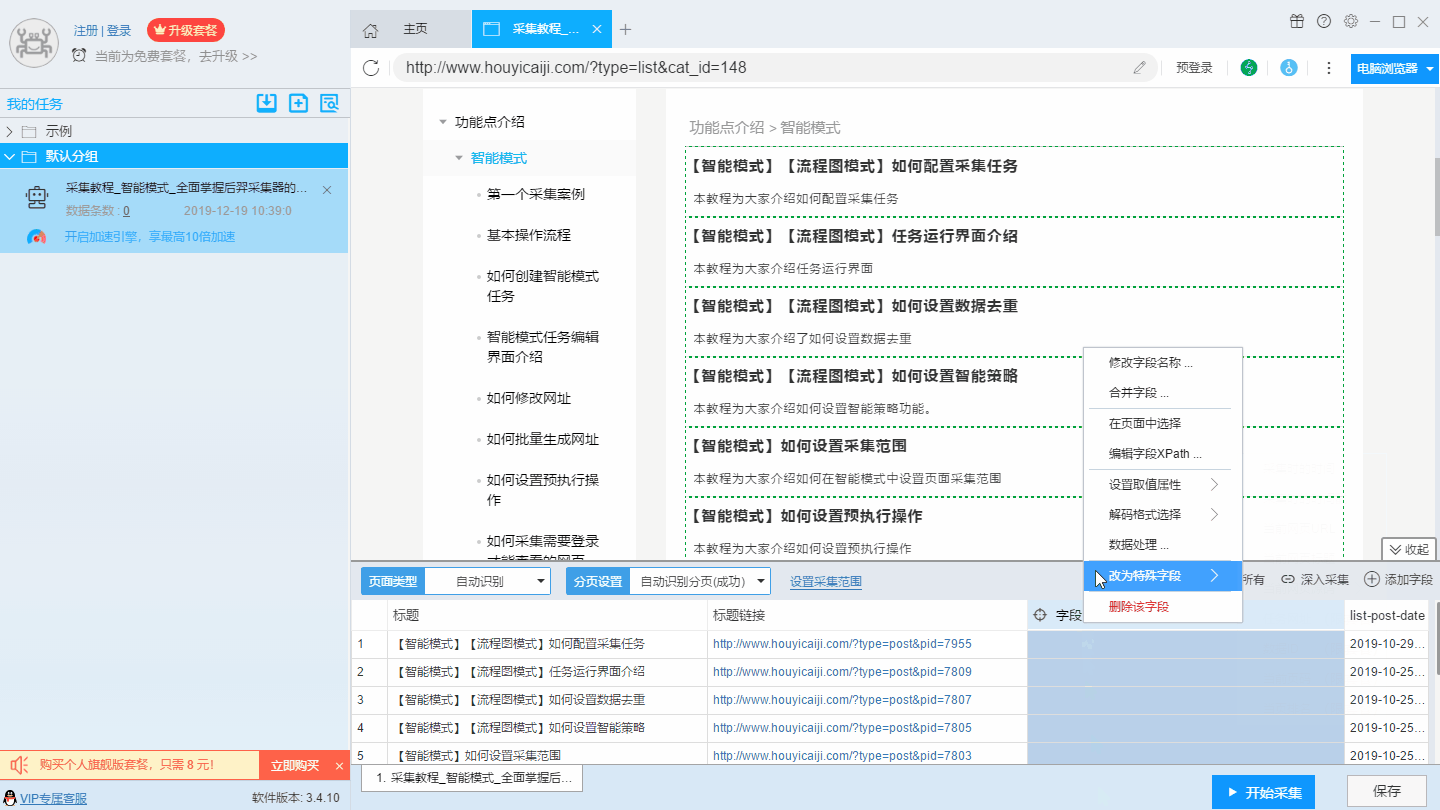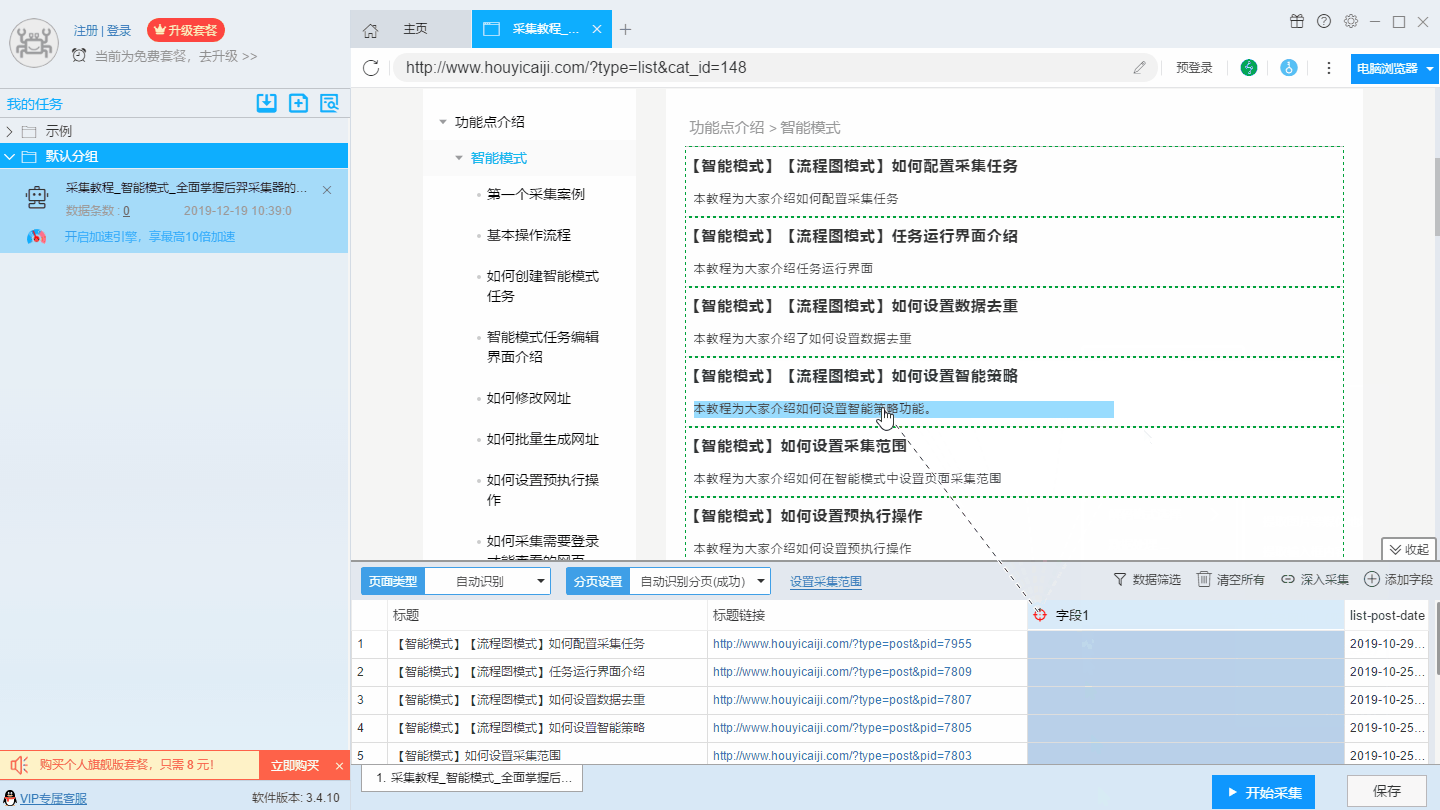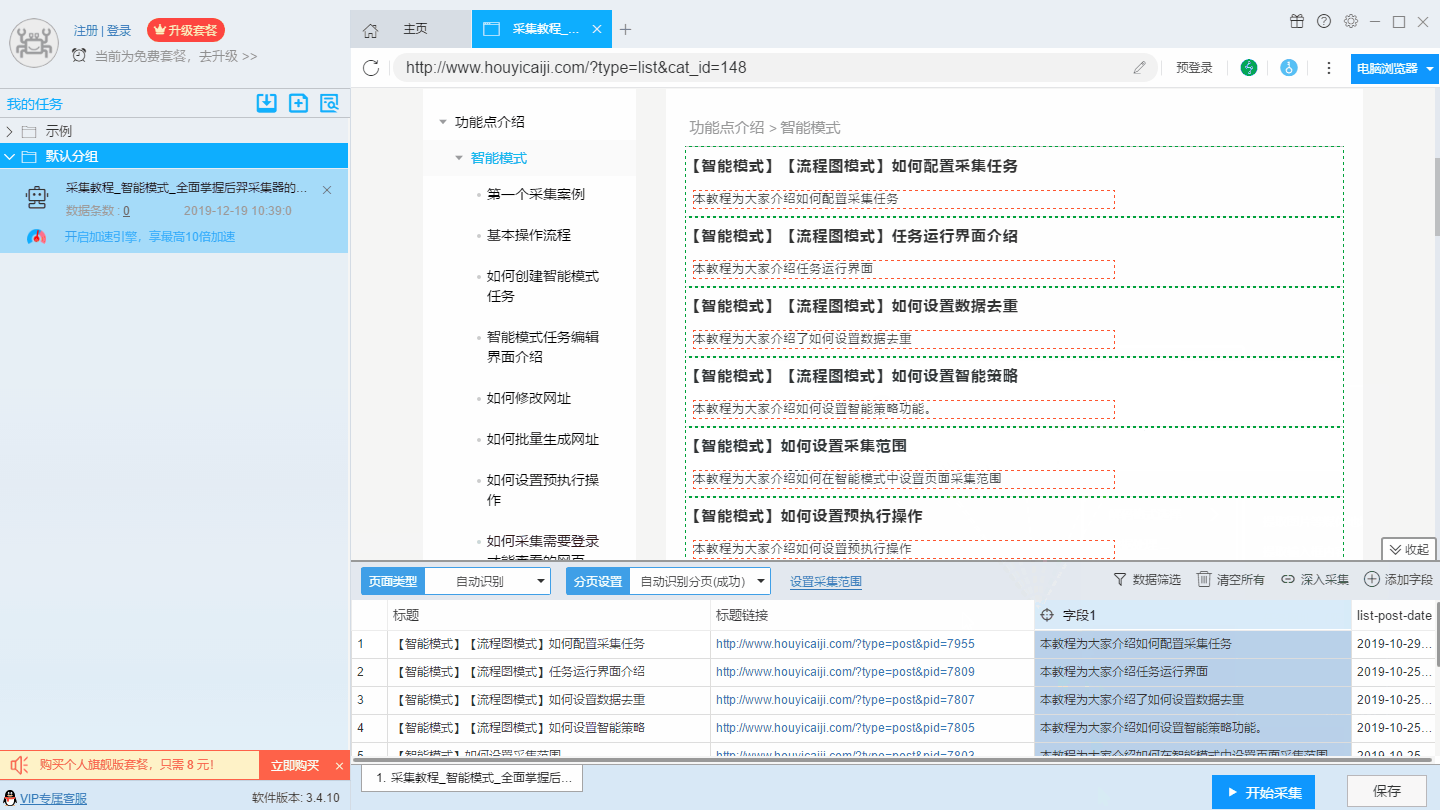
8、设置特殊字段
在数据采集过程中,如果需要采集一些特殊字段,如采集时的时间、当前网页标题、当前网页URL等,这些字段无法直接在网页中提取,那么可以使用“改为特殊字段”功能进行字段设置,通常我们会新建字段,然后把字段改为特殊字段,我们也可以直接把其他字段改为特殊字段。
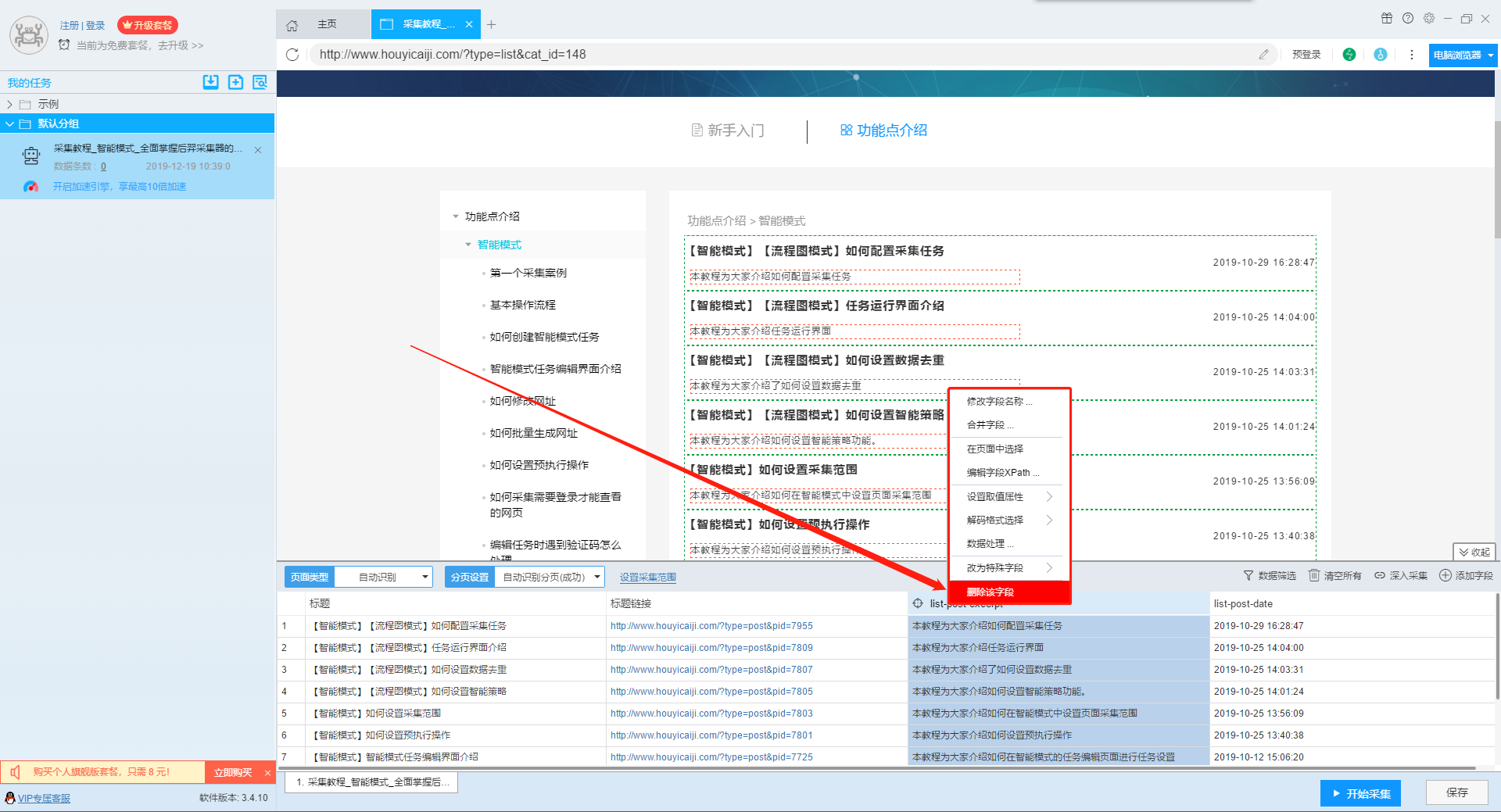
9、删除字段
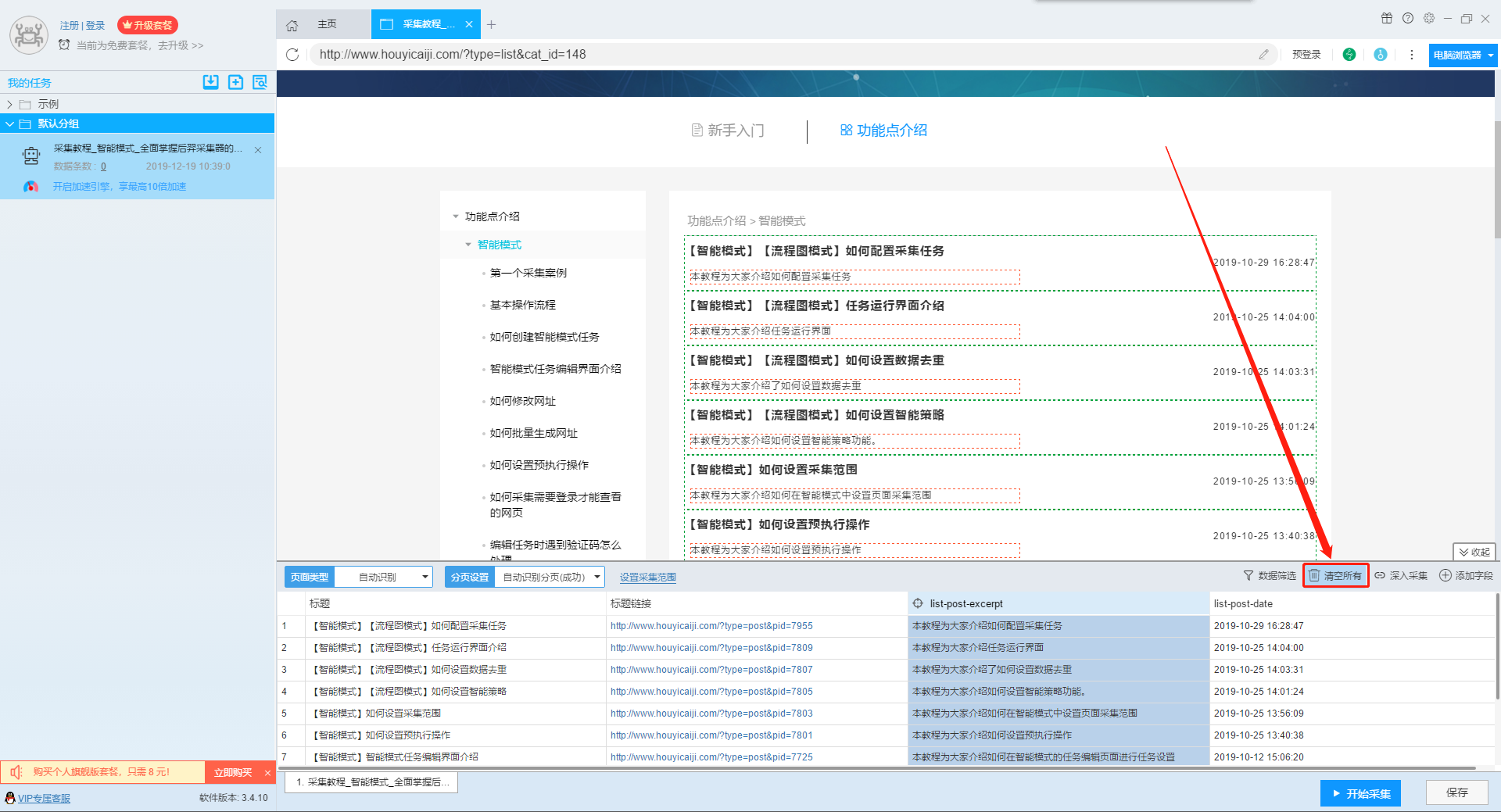
10、清空所有
如果不需要软件自动识别出来的字段,可以使用“清空所有”功能清空字段,重新设置需要的字段。
11、添加字段
如果要增加新字段,可以点击“添加字段”按钮新增字段,然后到页面中点击需要采集的数据。

文章评论