
采集场景
在孔夫子旧书网搜索页面:http://search.kongfz.com/product_result/,输入图书的关键词(含ISBN)搜索,搜索后得到图书列表,然后从列表点击图书链接进入详情页,采集详情页数据。
ISBN是专门为识别图书等文献而设计的国际编号,如果使用的是ISBN搜索,则搜索结果都是关于某本特定书籍的。
采集字段
作者、书名、售价、定价、库存、品相、出版时间等字段。
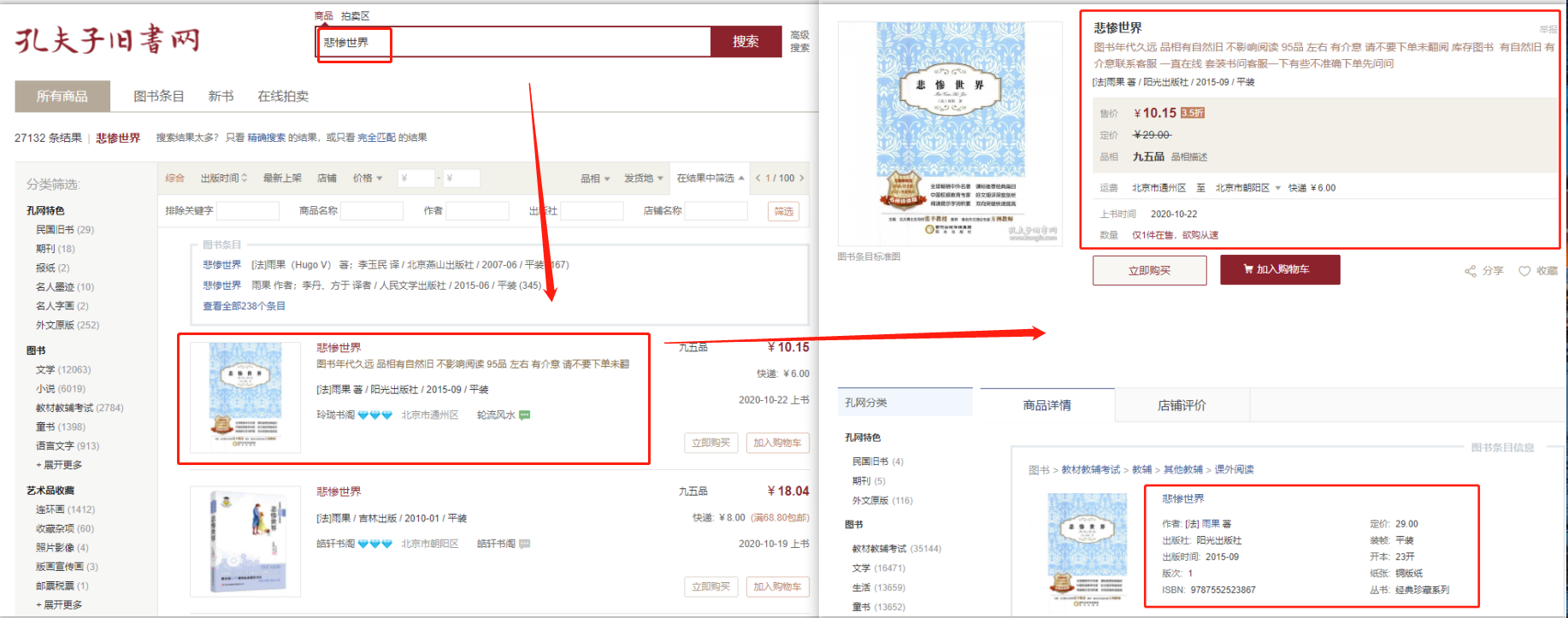
点击查看高清大图,下文其他图片同理
采集结果
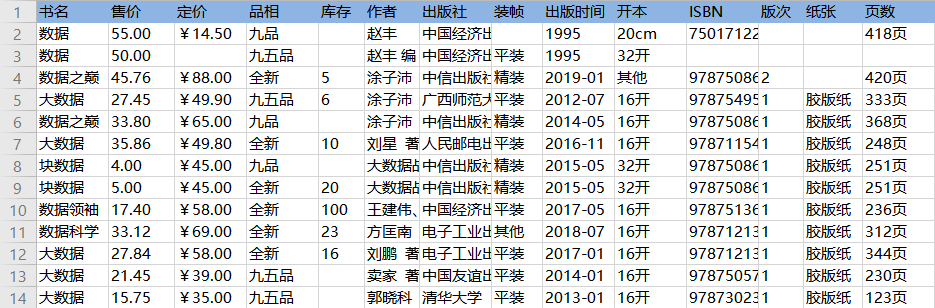
采集结果可导出为Excel、CSV、HTML、数据库等多种格式。导出为Excel示例:
教程说明
本篇制作时间:2022/6/9 八爪鱼版本:V8.5.2
如果因网页改版造成网址或步骤无效,无法收集到目标数据,请联系官方客服,我们将及时修正。
采集步骤
步骤一、打开网页
步骤二、批量输入多个关键词并搜索
步骤三、建立【循环-点击元素】,进入每个商品的详情页
步骤四、设置【提取数据】,采集所需字段
步骤五、建立【翻页循环】,采集多页数据
步骤六、编辑字段
步骤七、设置滚动和执行前等待
步骤八、启动采集
以下为具体步骤:
步骤一、打开网页
在首页【输入框】中输入目标网址:http://search.kongfz.com/product_result/,点击【开始采集】,八爪鱼自动打开网页。

特别说明:
a. 打开网页后,如果开始开始【自动识别】,请点击【不再自动识别】或【取消识别】将其关掉。因为本文不适合使用【自动识别】。
b. 【自动识别】适用于自动识别网页上的列表、滚动和翻页,识别成功后直接启动采集即可获取数据。详情点击查看 【自动识别】教程

文章评论