
在 第3课中,我们学会了如何采集多个列表中的数据,相信大家都已学会创建【循环-提取数据】。本节课将学习一种特殊格式的列表数据——表格数据采集。
表格是一种很常见的网页样式,例:球探网的赛事比分表,天天基金网的基金排名表,东方财富网的股票信息表,中国证券业协会的年报披露表格等等。
表格作为列表数据的特殊形式,我们可以将表格的每一行看作为列表的每一个数据的大区块范围, 表格每一行的全部单元格字段,相当于列表每个数据区块内的多个子字段。那么上节课讲的【循环-提取数据】创建方法在本课也能用。
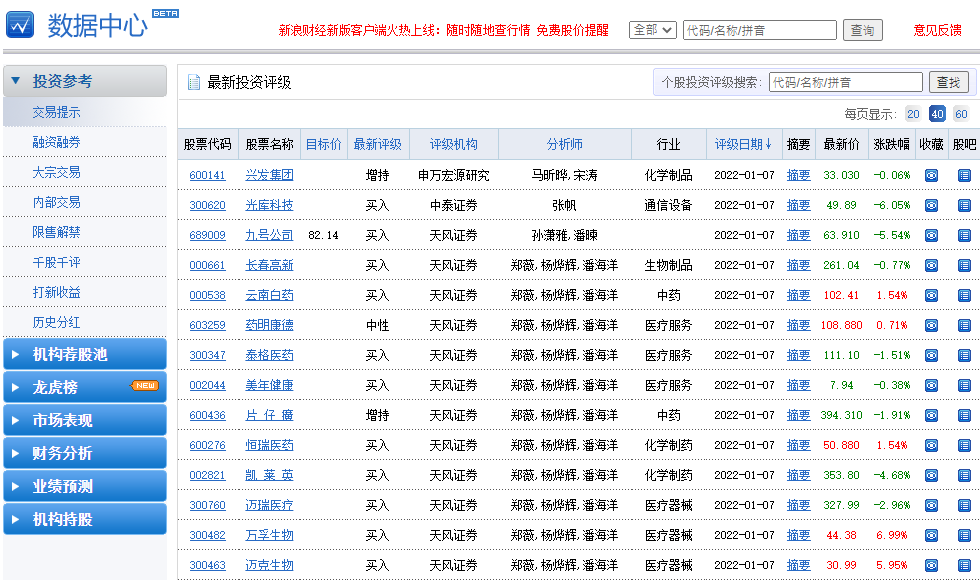
现在有一个新浪财经股票表格的网页:
http://stock.finance.sina.com.cn/stock/go.php/vIR_RatingNewest/index.phtml 表格结构非常整齐,每条股票信息各占表格的一行,一行股票中包含多个字段信息:股票代码、股票名称、目标价、最新评级、评级机构等。
鼠标放到图片上,右键,选择【在新标签页中打开图片】可查看高清大图
下文其他图片同理
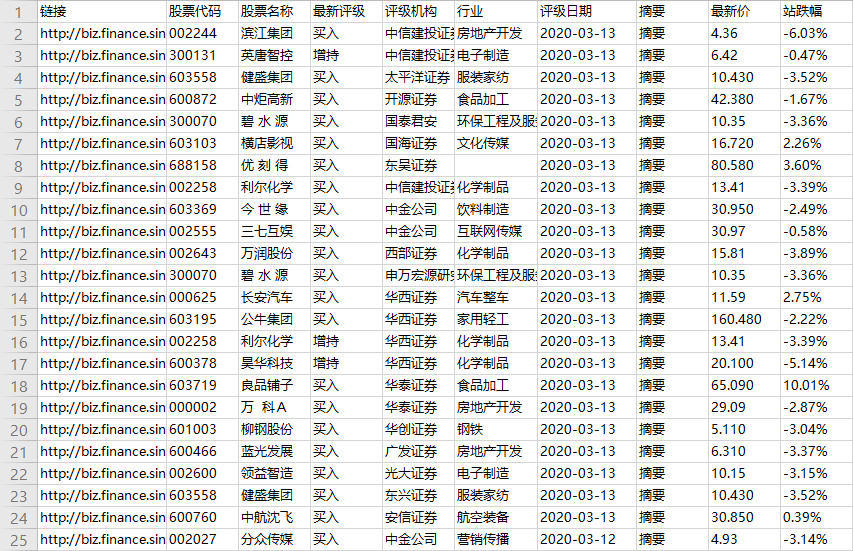
我们想要将这些字段采集下来并以Excel等形式存储下来,如下图所示。
在八爪鱼中该如何操作?
示例网址:http://stock.finance.sina.com.cn/stock/go.php/vIR_RatingNewest/index.phtml
一、智能识别
表格型的网页,八爪鱼支持智能识别。使用智能识别,只需输入网址就能自动获取数据,并生成采集流程,如下图所示。
点击了解 智能识别详情 。
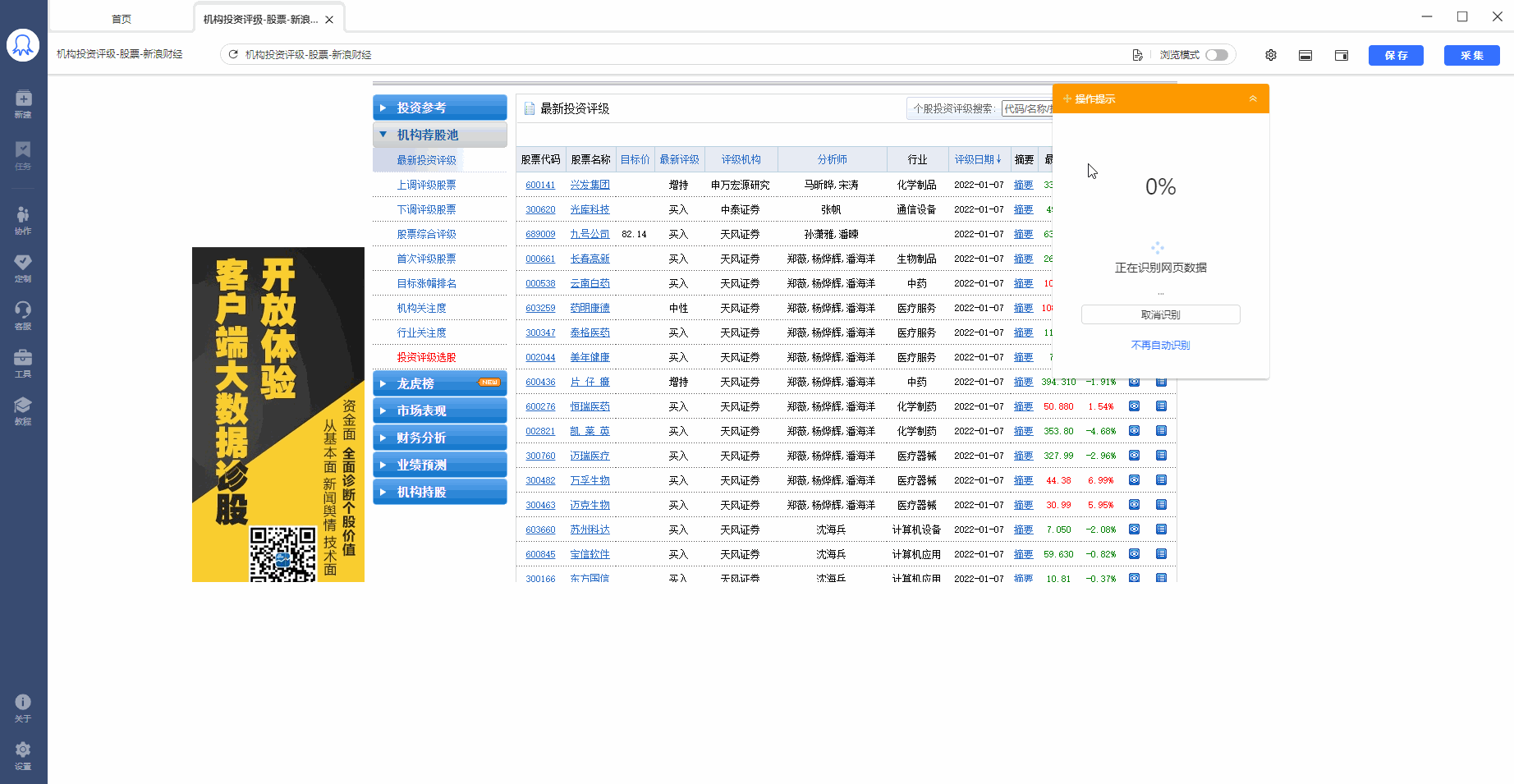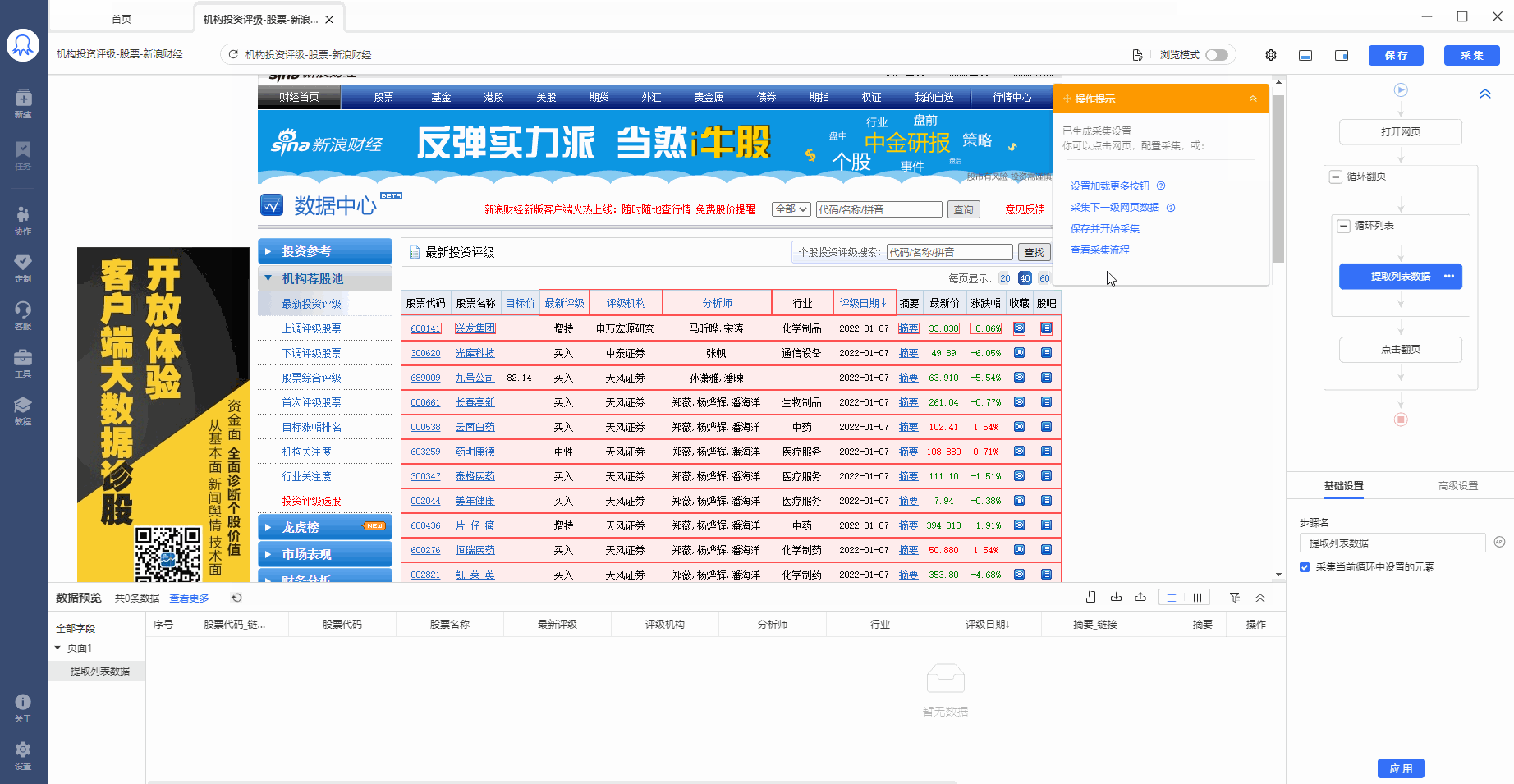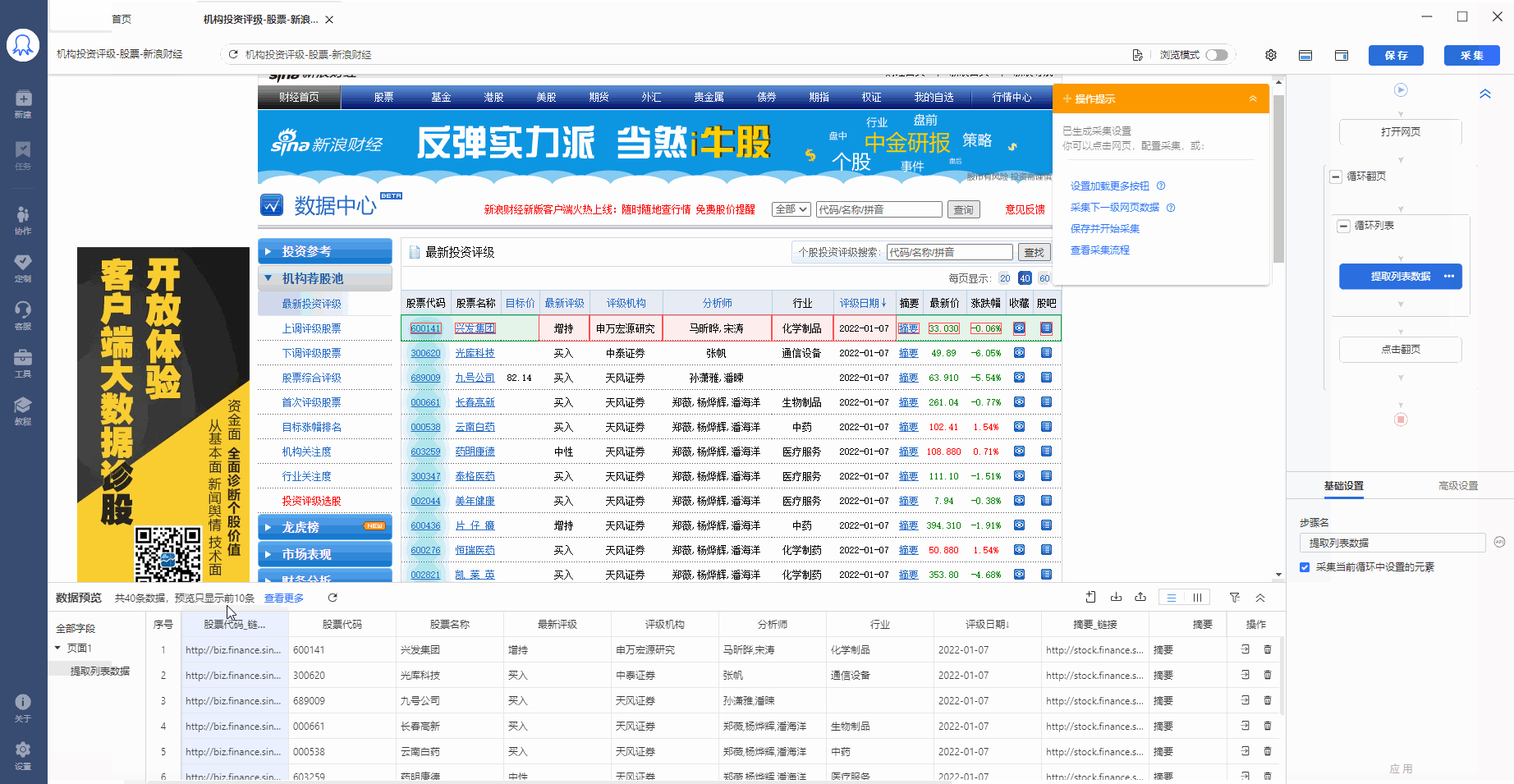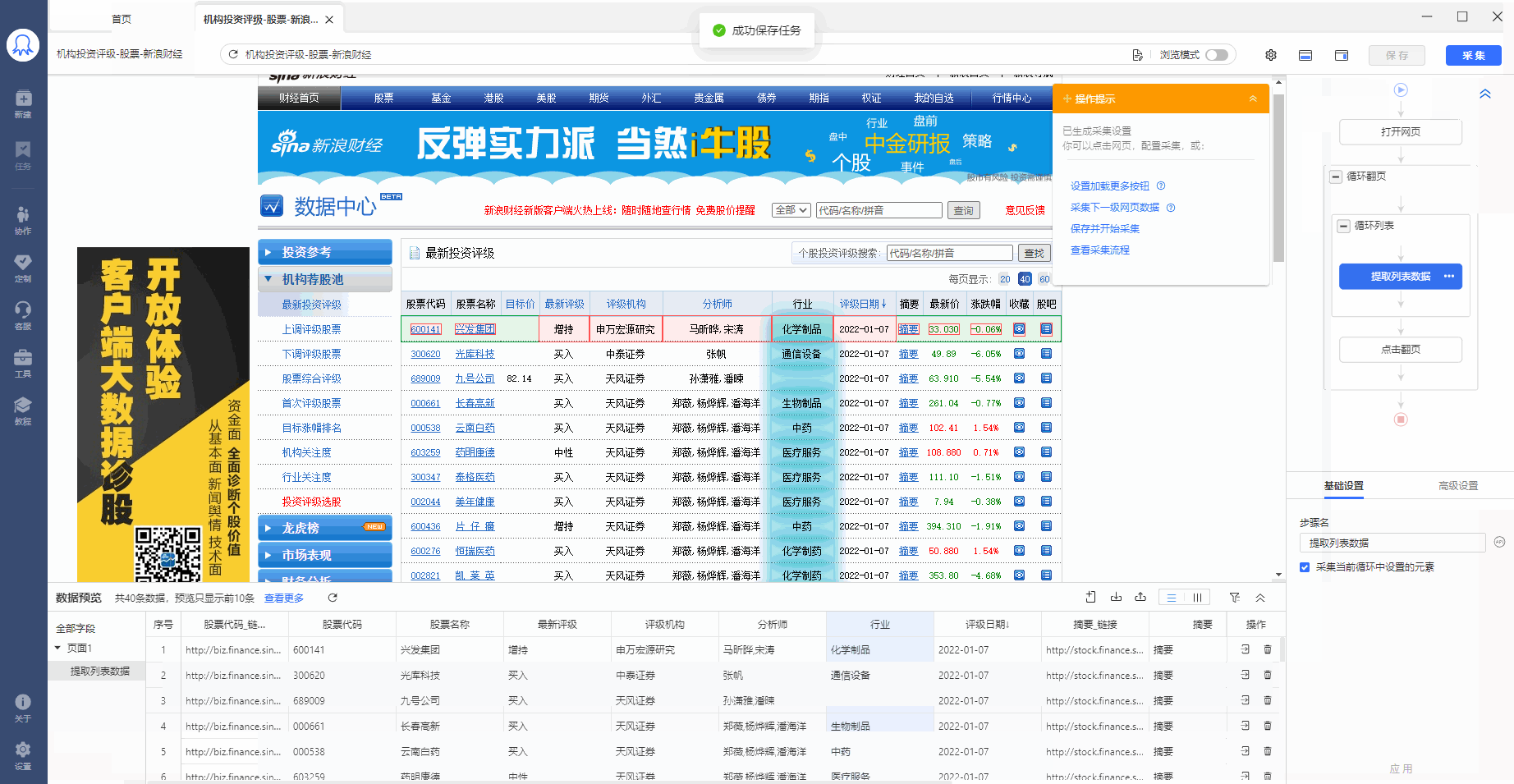
二、自行配置采集流程
如果想要自行配置采集流程,怎么办?以下为具体步骤:
步骤一、输入网址
在首页【输入框】中输入目标网址,点击【开始采集】,八爪鱼自动打开网页。如果自动开始智能识别,可点击【不再自动识别】或【取消识别】。如果已关闭智能识别,可进行接下来的步骤。
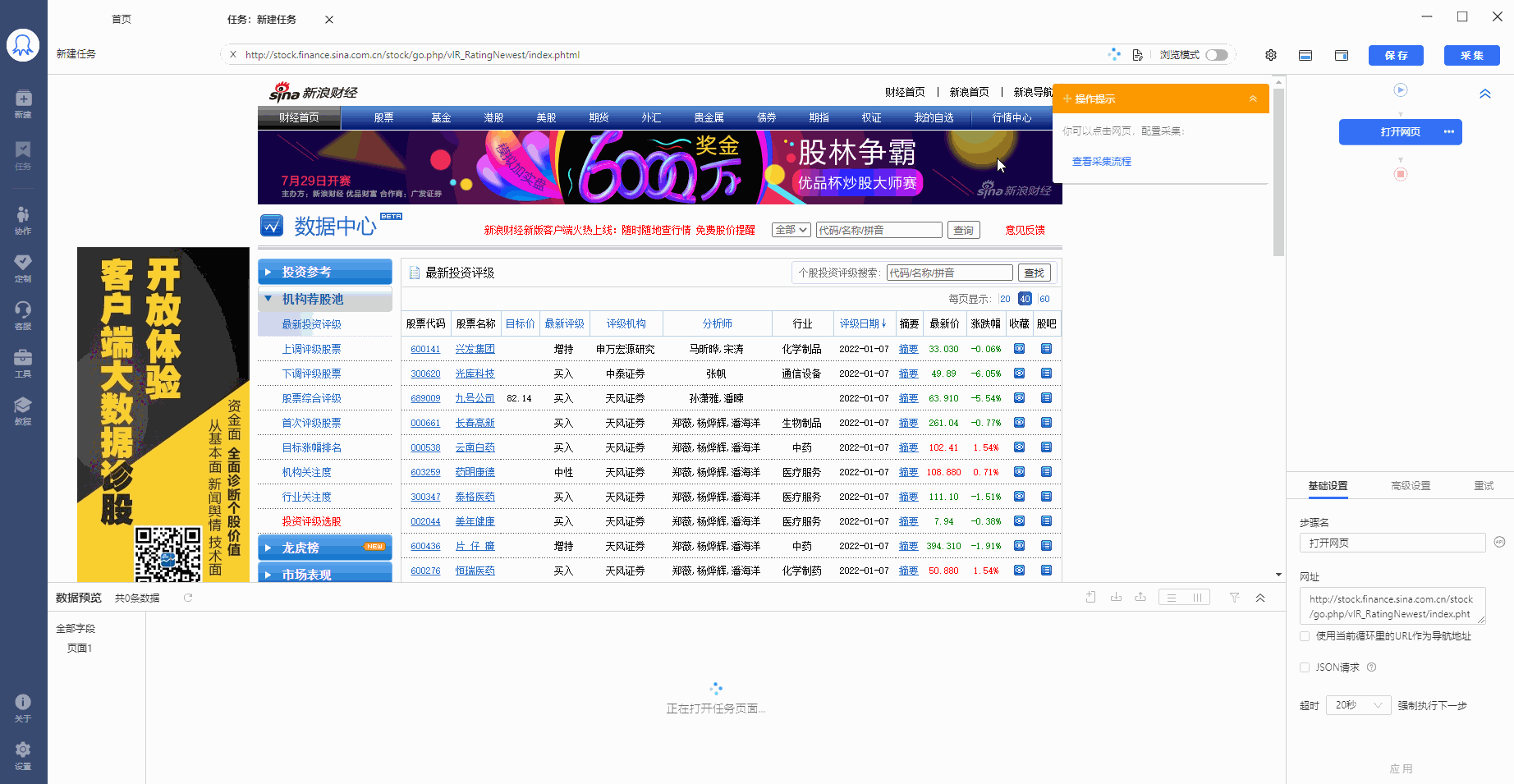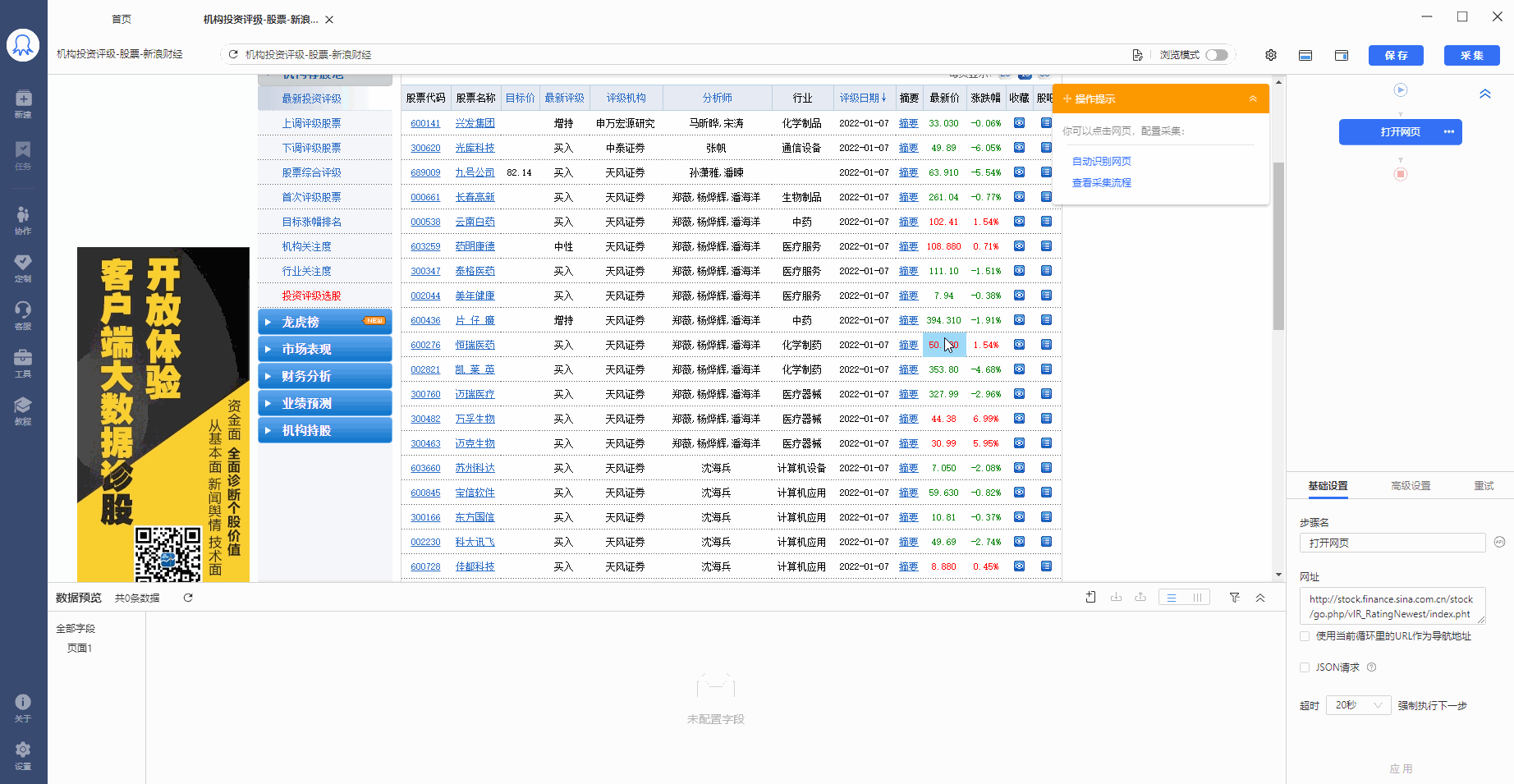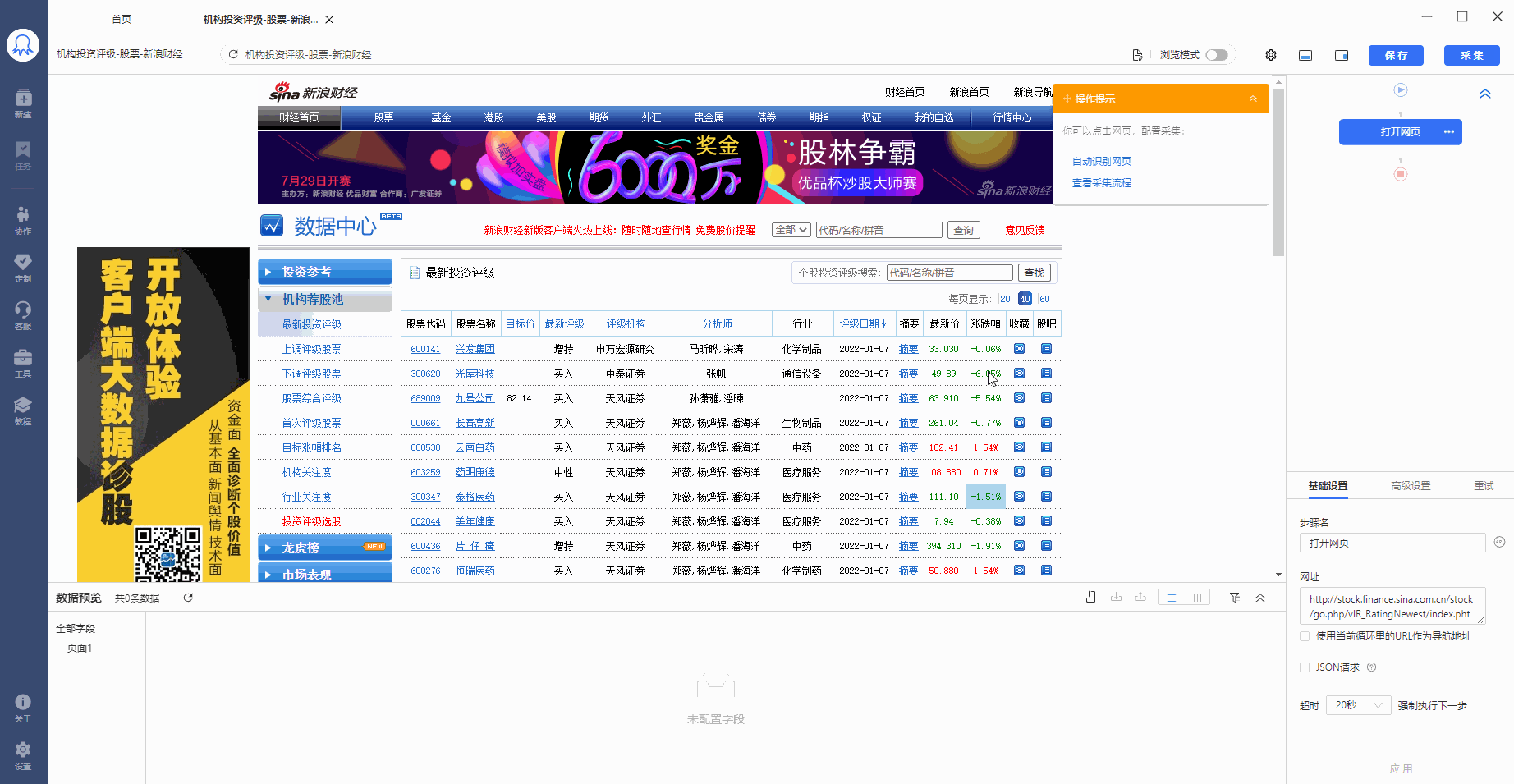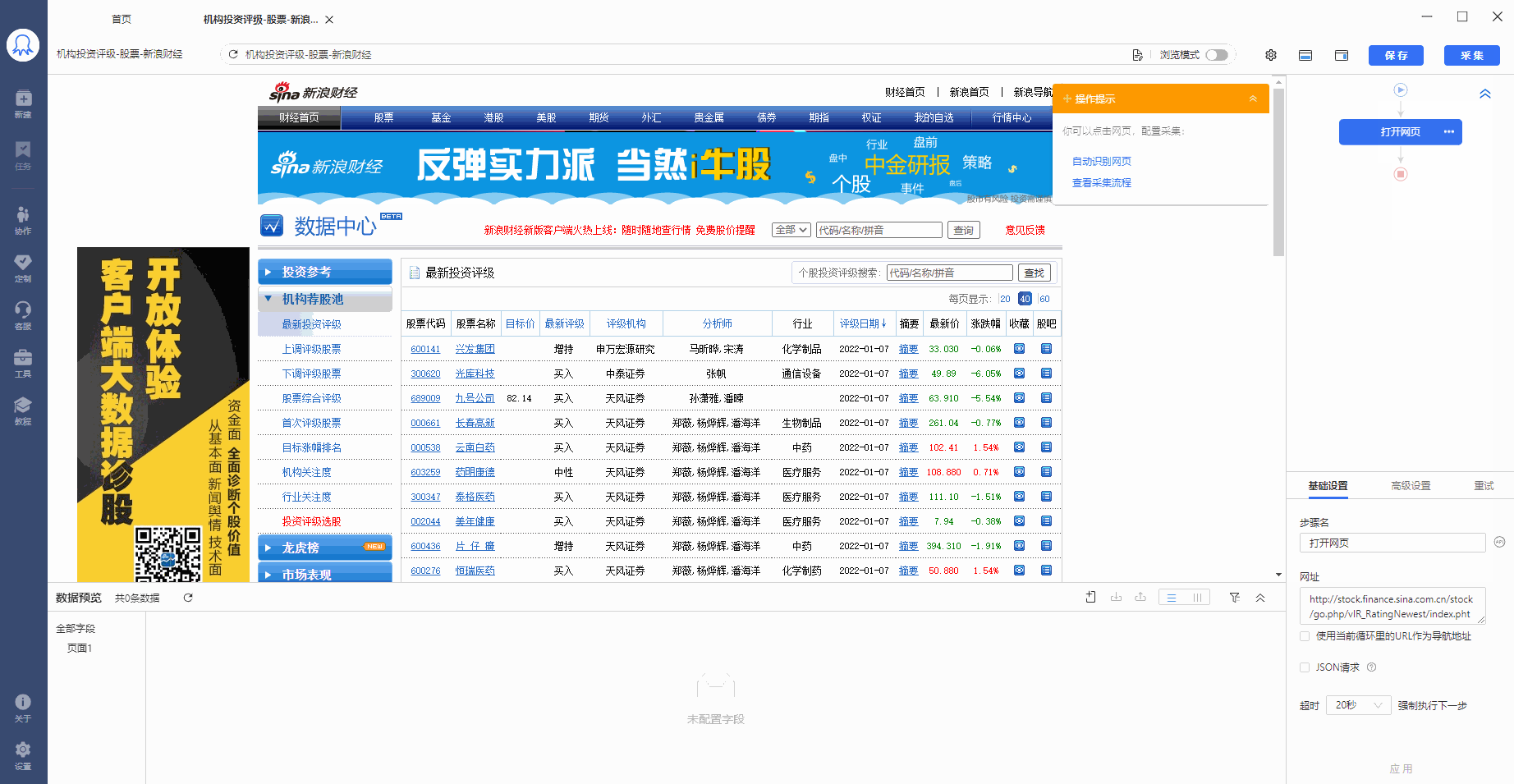
步骤二、建立【循环-提取数据】
我们可以联想到上节课中讲过的知识点,将表格作为列表数据的特殊形式,将每一行股票作为列表中每一条数据的大区块范围来看, 创建【循环-提取数据】,让八爪鱼自动识别到全部股票,和每个股票数据的全部子元素。
先看一个包含所有具体步骤的动图:
再拆分每个步骤,进行详情说明:
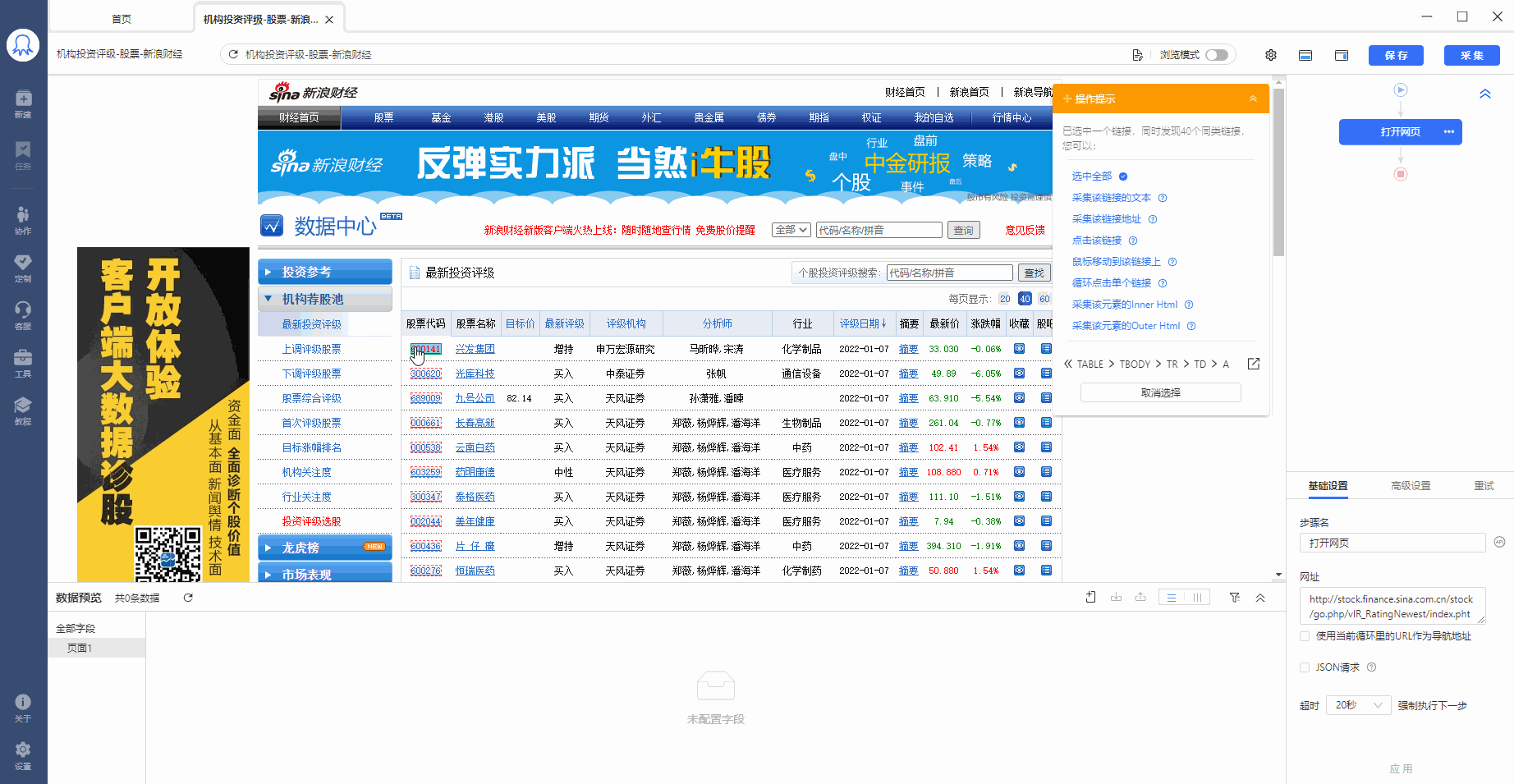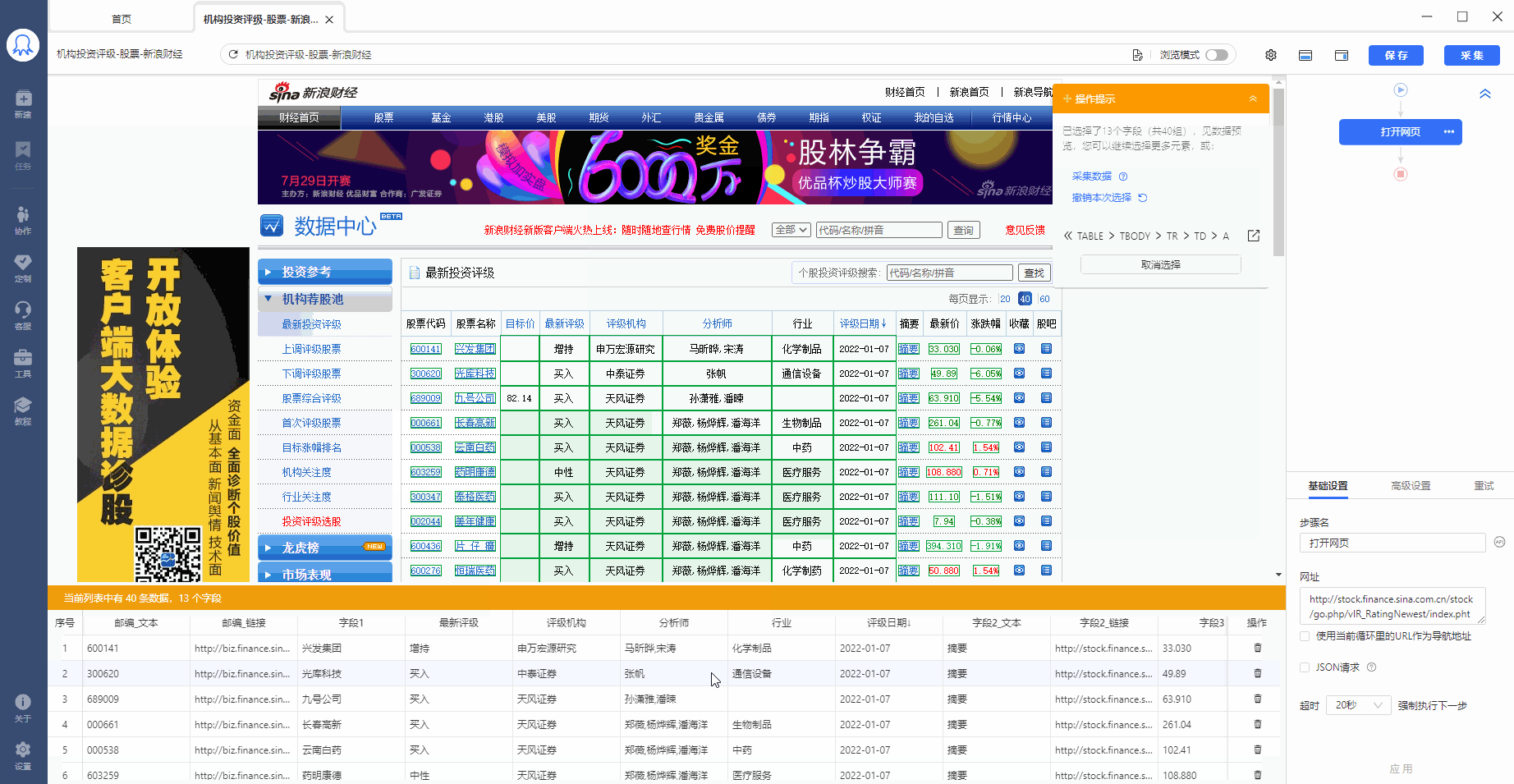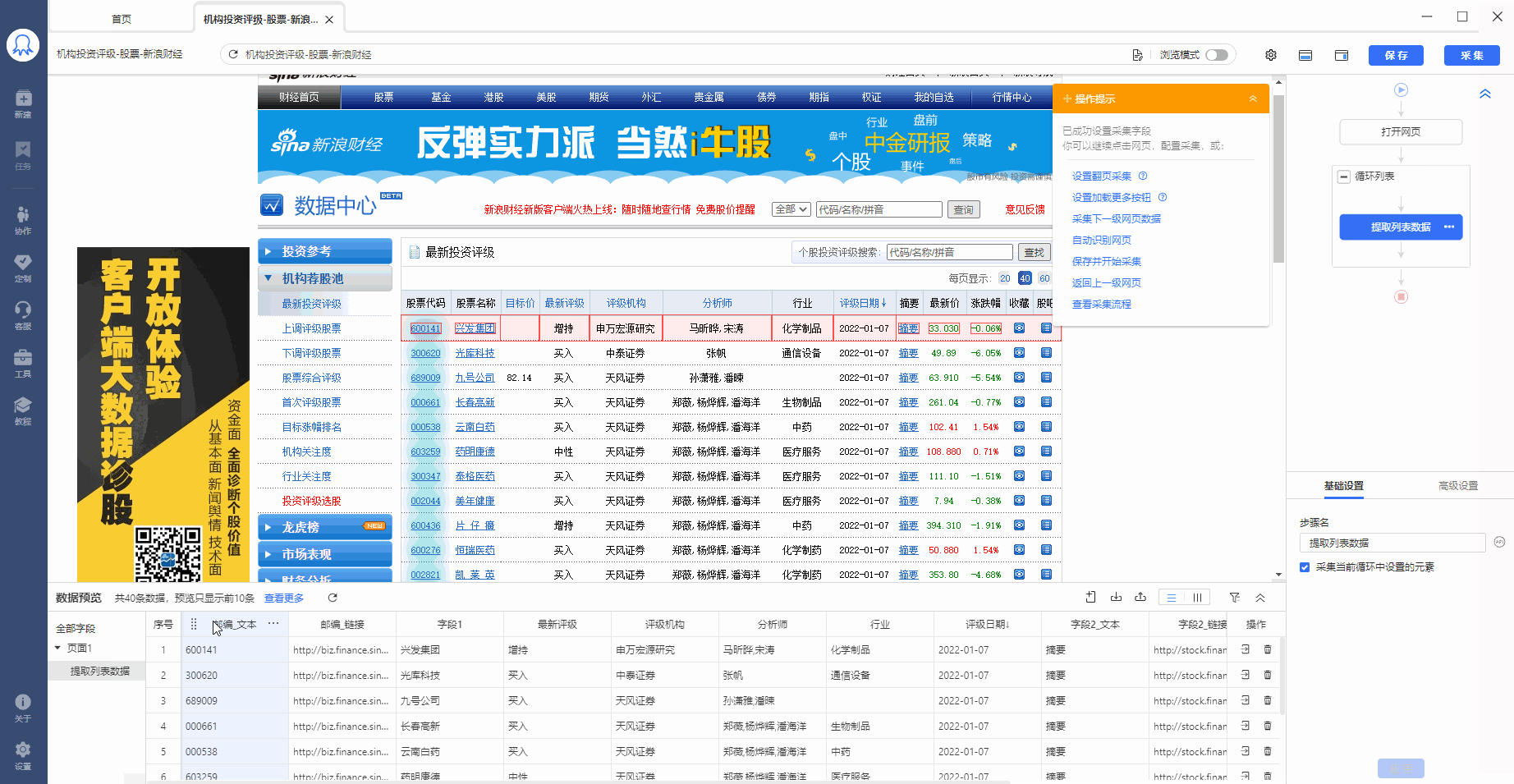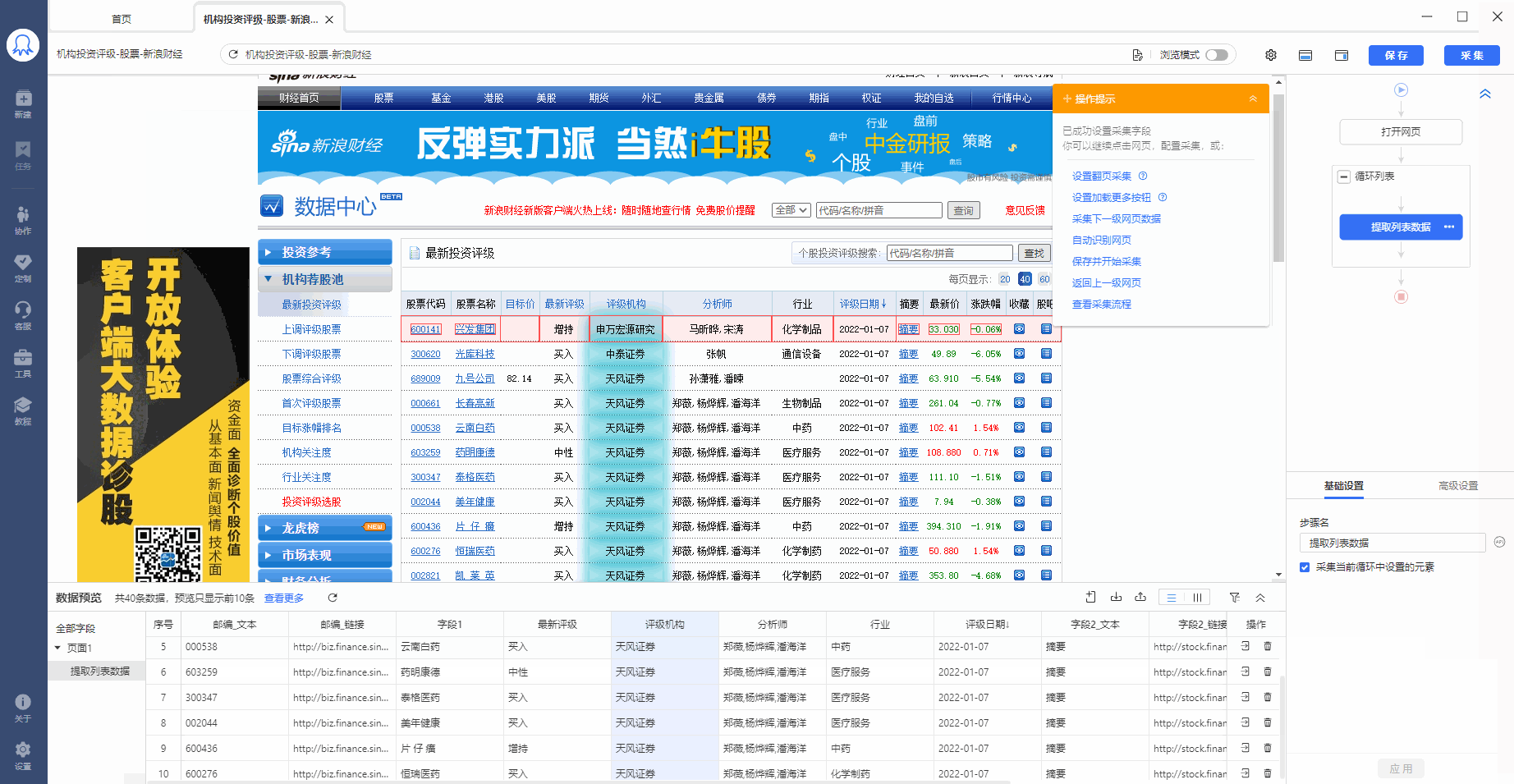
1、先选中页面上第一个列表的第一个单元格,再点击提示框右下角的【tr】按钮阔选fa,选中至一整行。
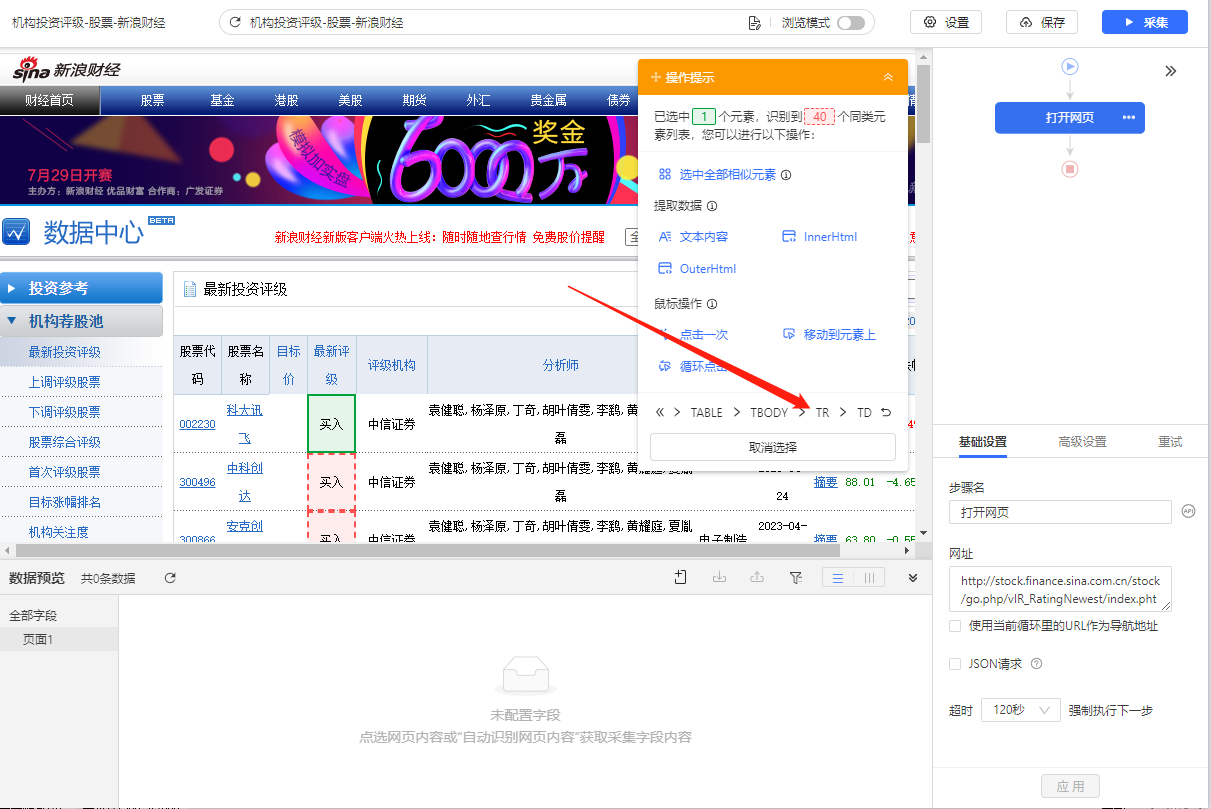
选中后,提示框会提示发现了【子元素】,【子元素】即八爪鱼自动识别到的每一行的具体字段,想问你是否要定位这些子元素。
 特别说明:
特别说明:
a. 点击tr扩大范围按钮时,如果点击1次没有选中一行,可点击多次,直至选中一行。
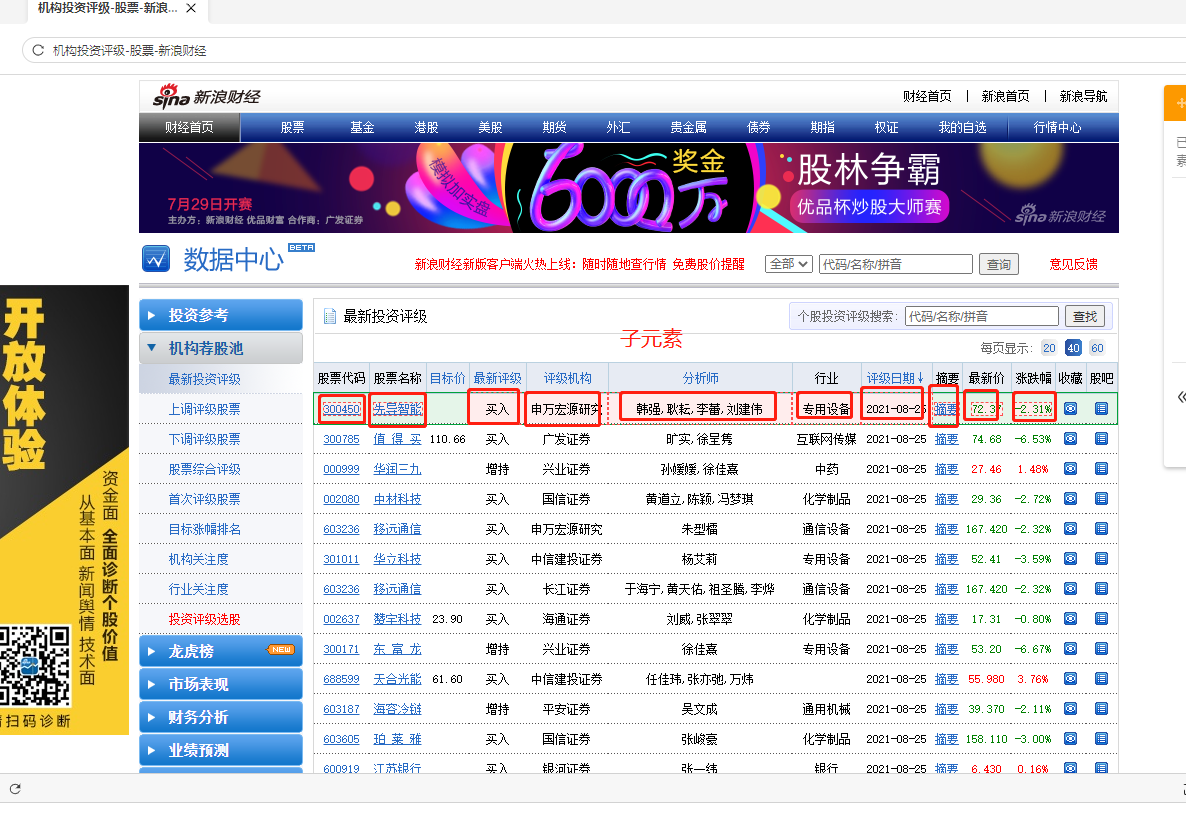
2、在提示框中,选择【选中全部子元素】。第1个股票中的具体字段就被选中了,这时八爪鱼又自动识别到页面中其他股票列表具有相同的【子元素】。
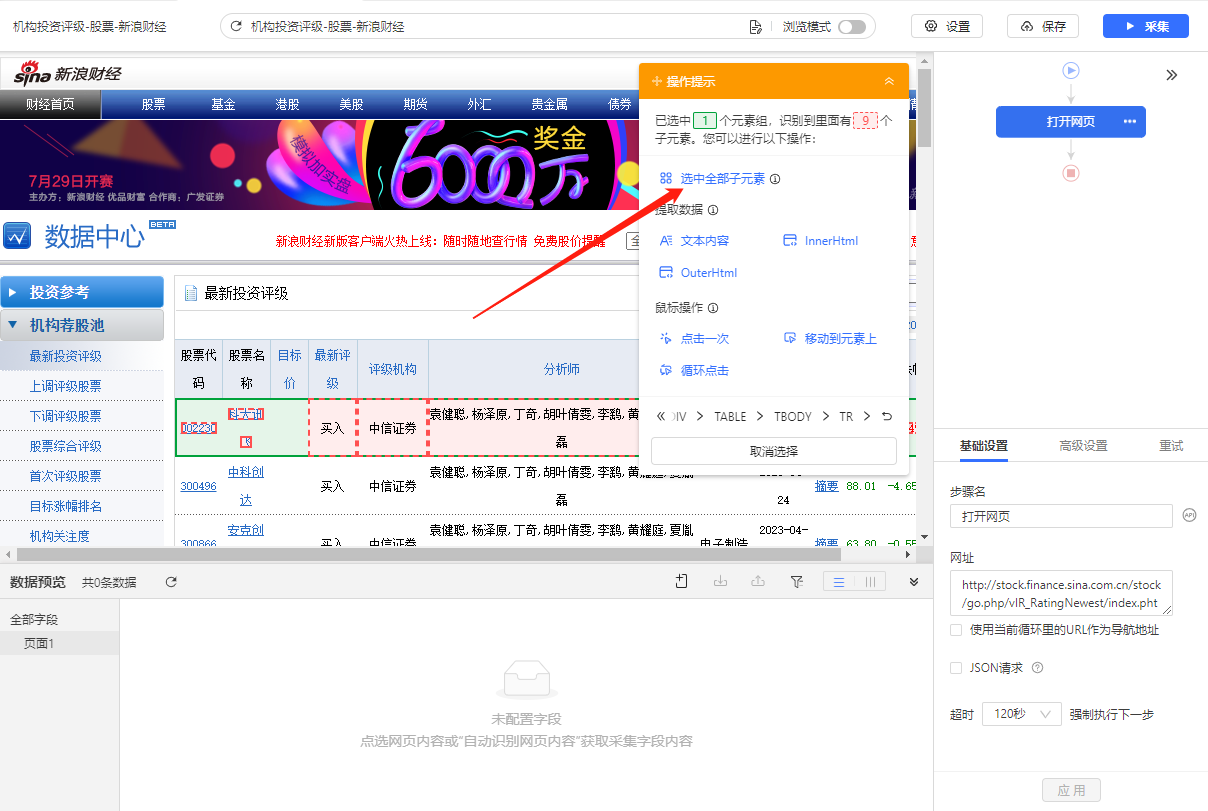
3、在提示框中,选择【选中全部相似组】。可以看到页面中所有股票列表中的子元素也都被选中了,被绿色框框起来。
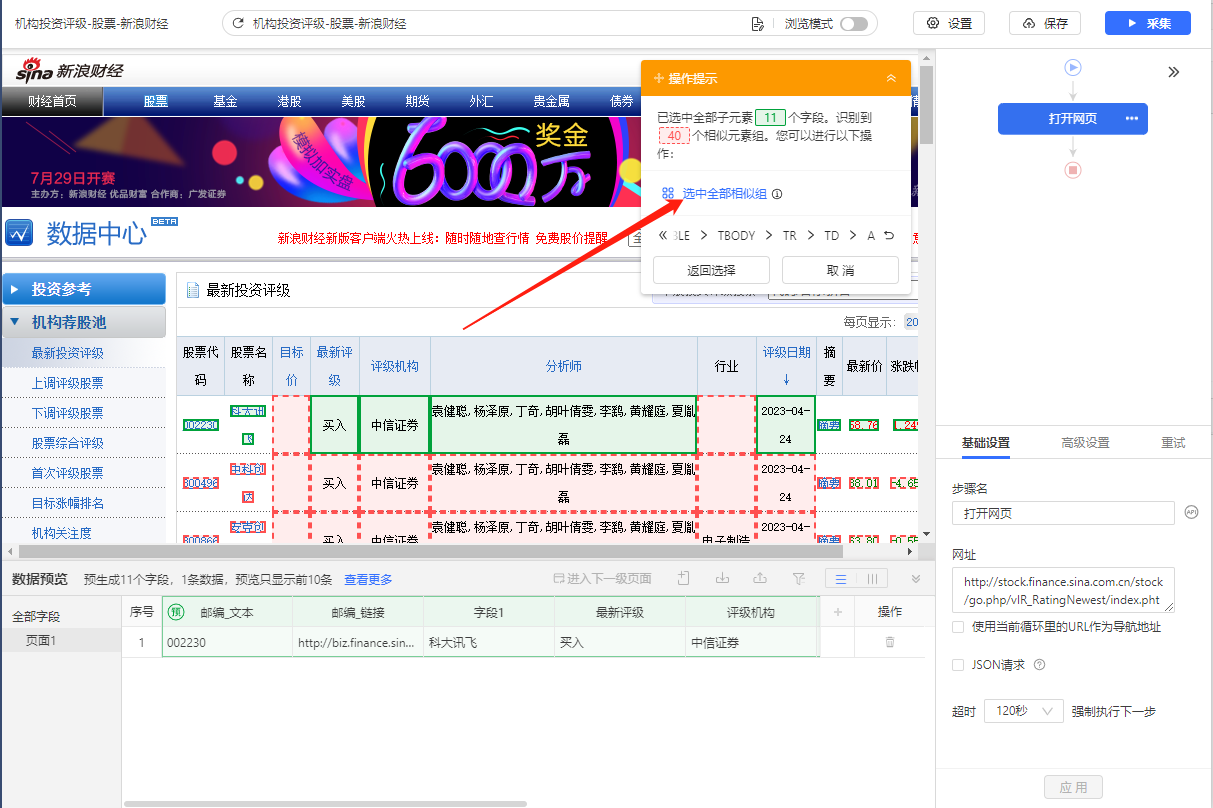
4、在提示框中,选择提取数据【元素中数据内容】。这时候,八爪鱼就将表格中的字段都提取下来了。
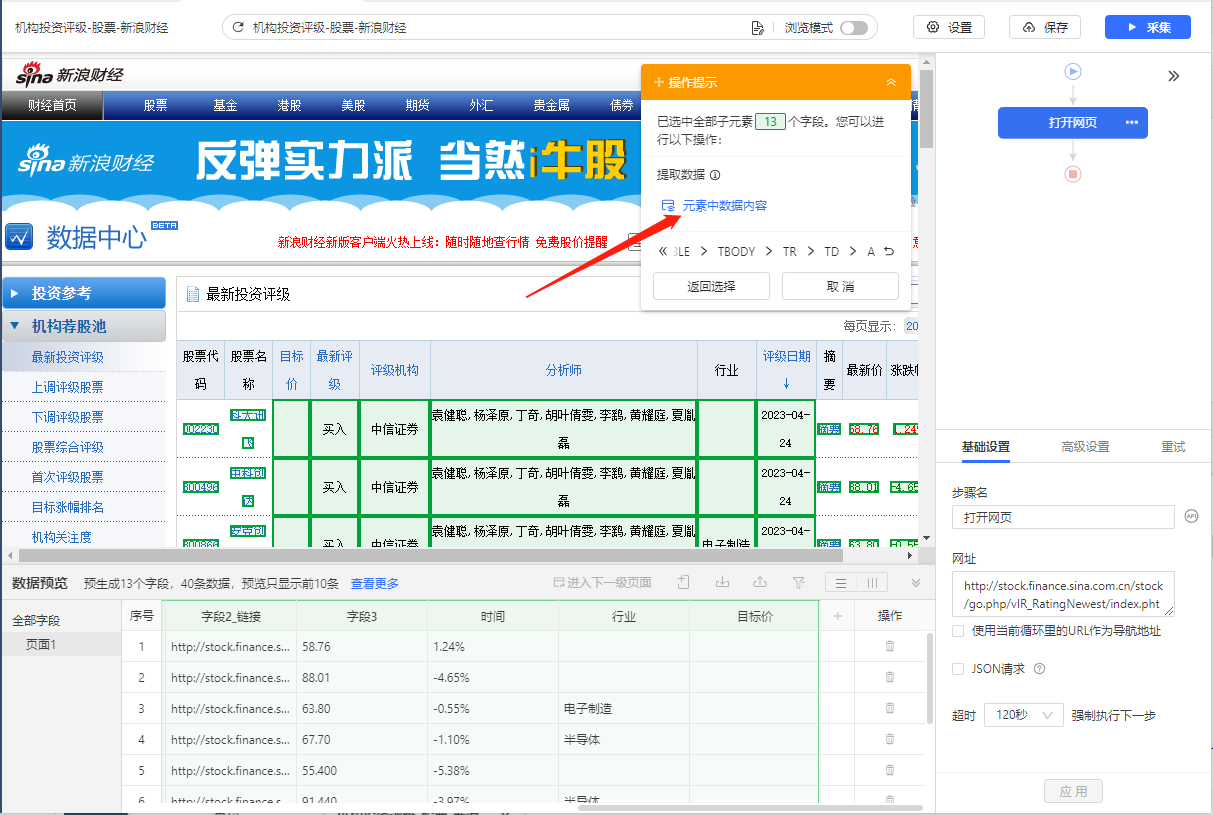
经过以上4步,【循环-提取数据】创建完成。流程区中自动生成了1个【循环-提取数据】步骤。循环中包含了页面上全部股票的行数,提取数据中包含了一个股票中的全部字段。
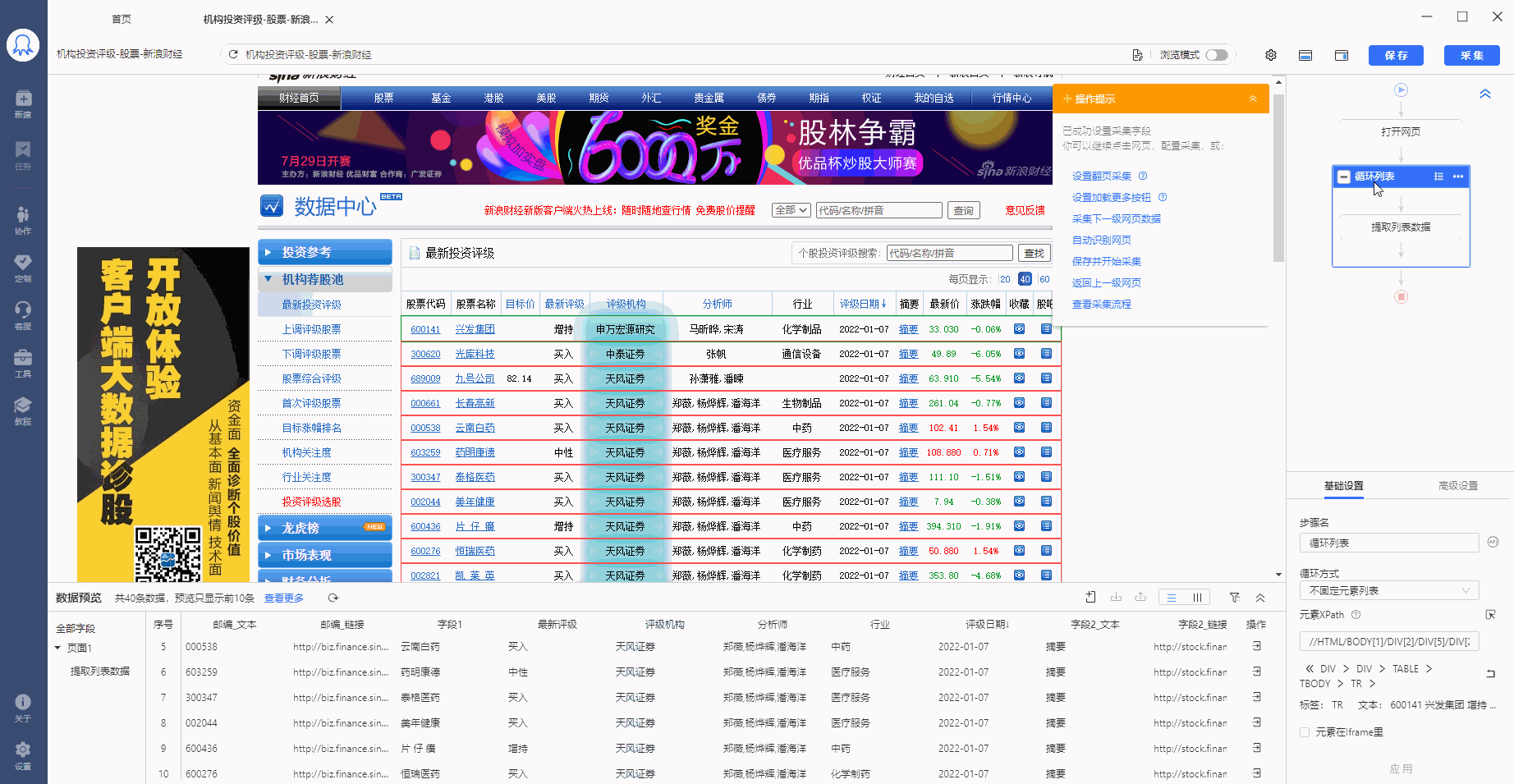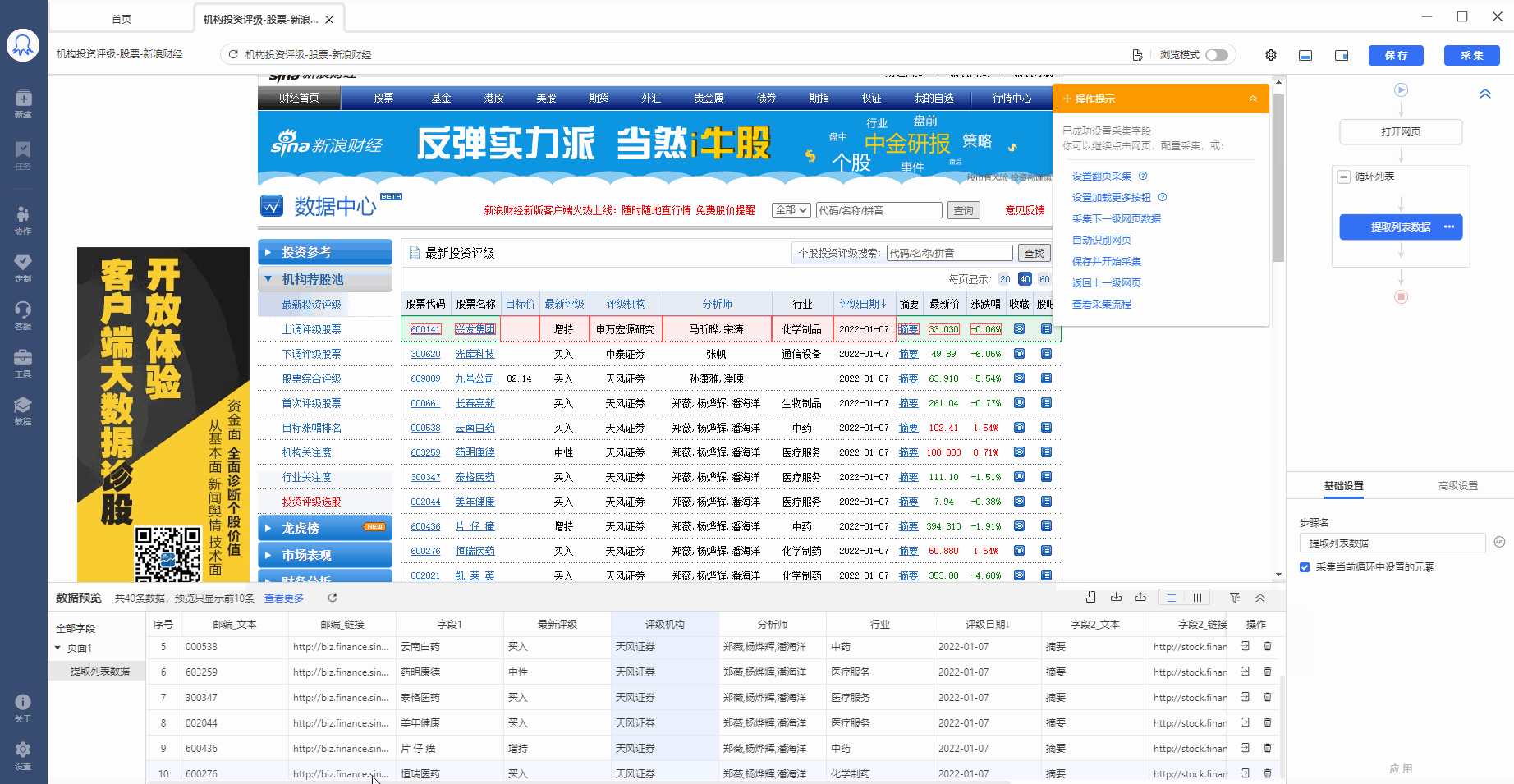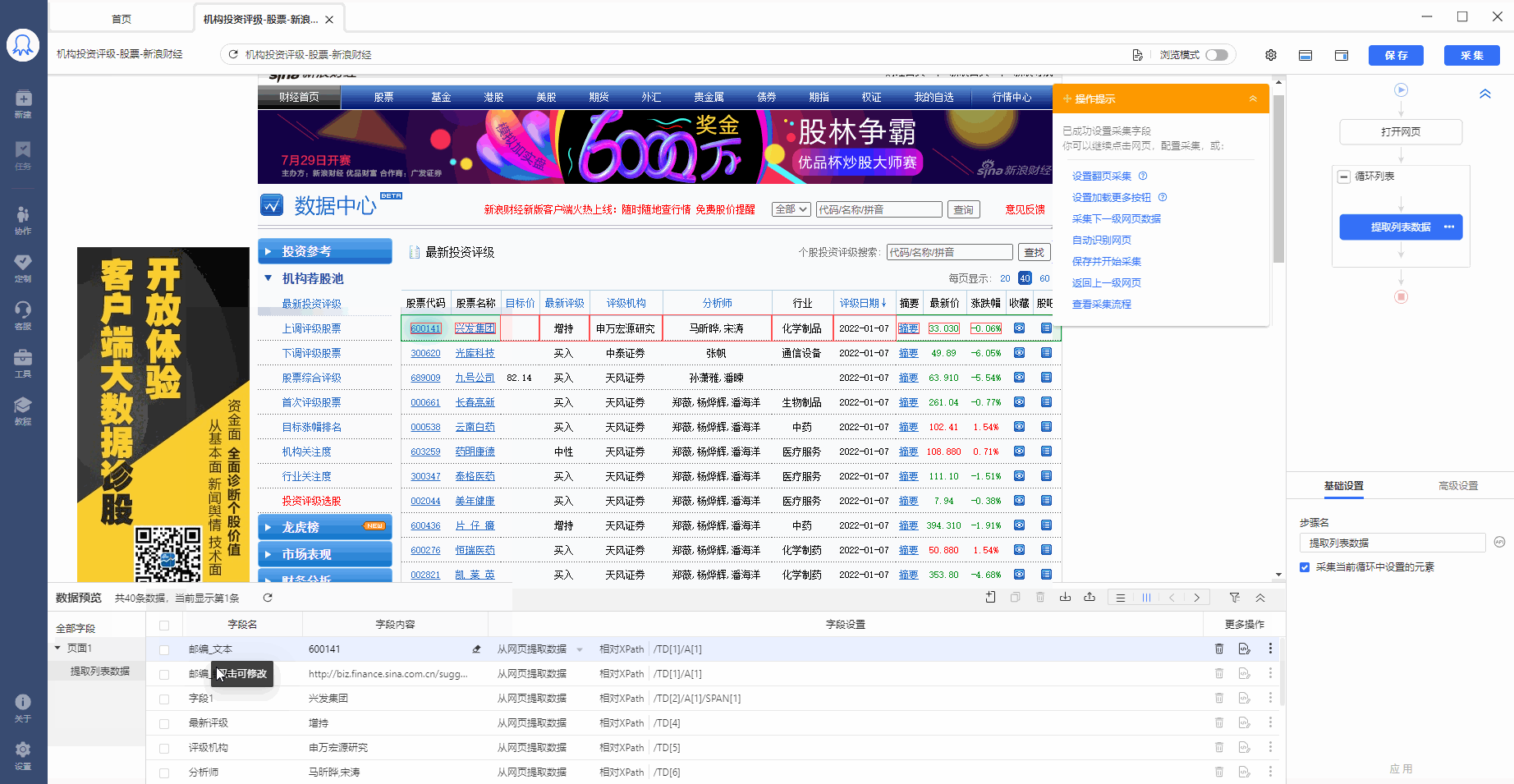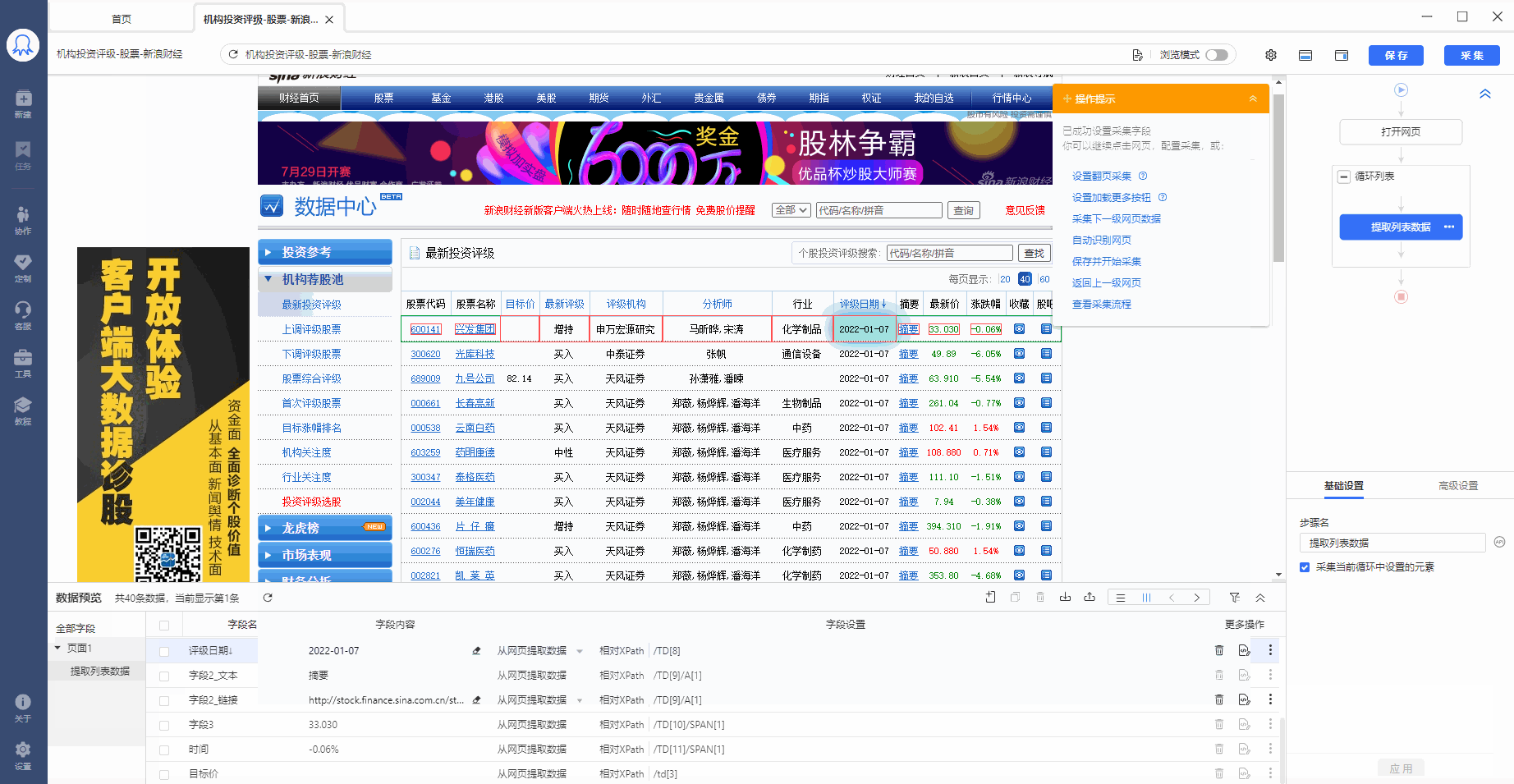
步骤3、编辑字段
八爪鱼自动为我们提取了列表中的所有字段,我们可以对这些字段进行删除、修改字段名称等操作。
鼠标双击到名称上,可修改字段名称。
鼠标移动到  按钮上,可对字段进行更多操作:删除、复制、格式化等。
按钮上,可对字段进行更多操作:删除、复制、格式化等。
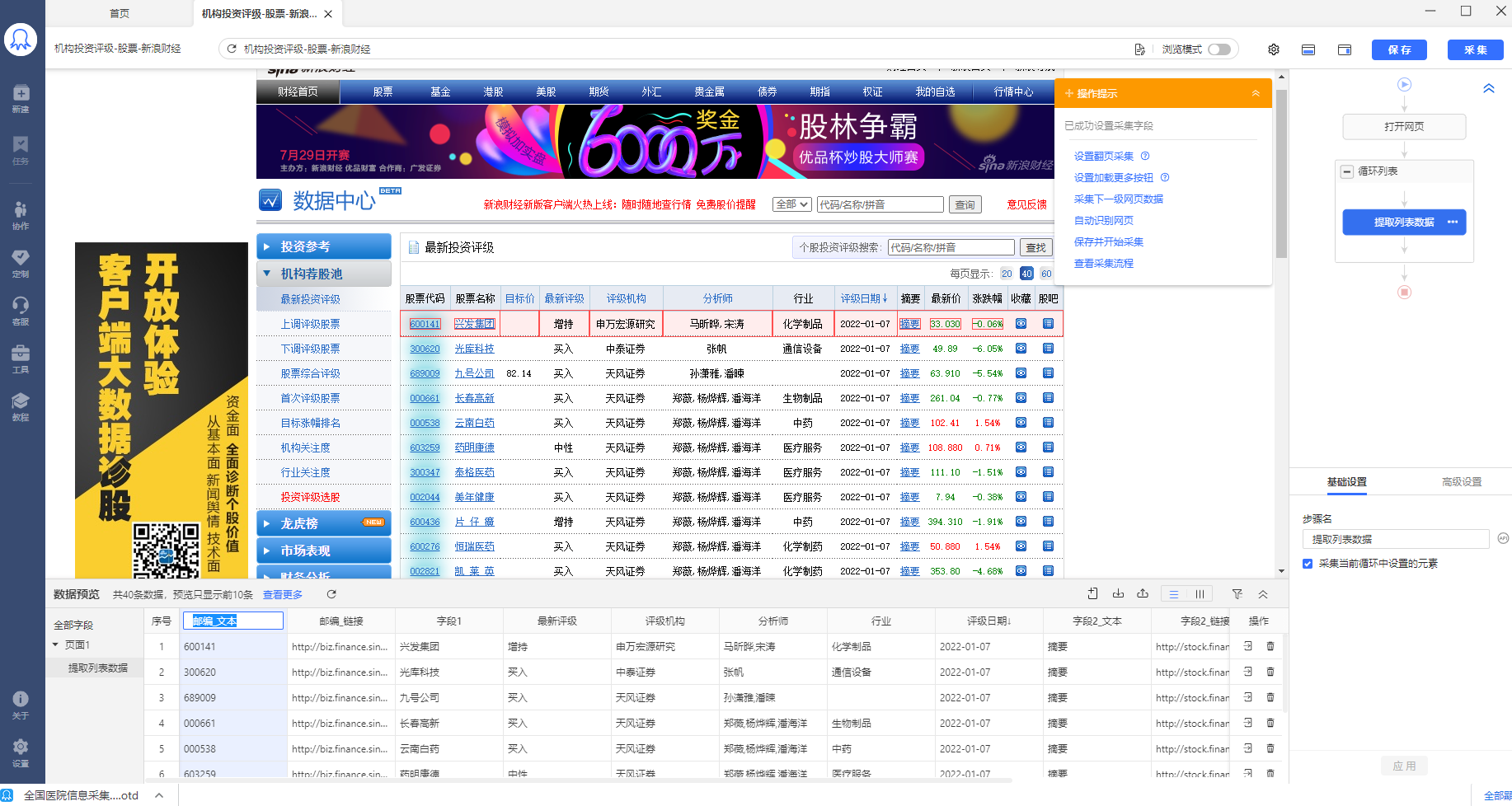
步骤4、启动采集
1、点击【保存并启动】,选择【启动本地采集】。八爪鱼跳出采集窗口,我们可以看见采集窗口中在进行自动采集。
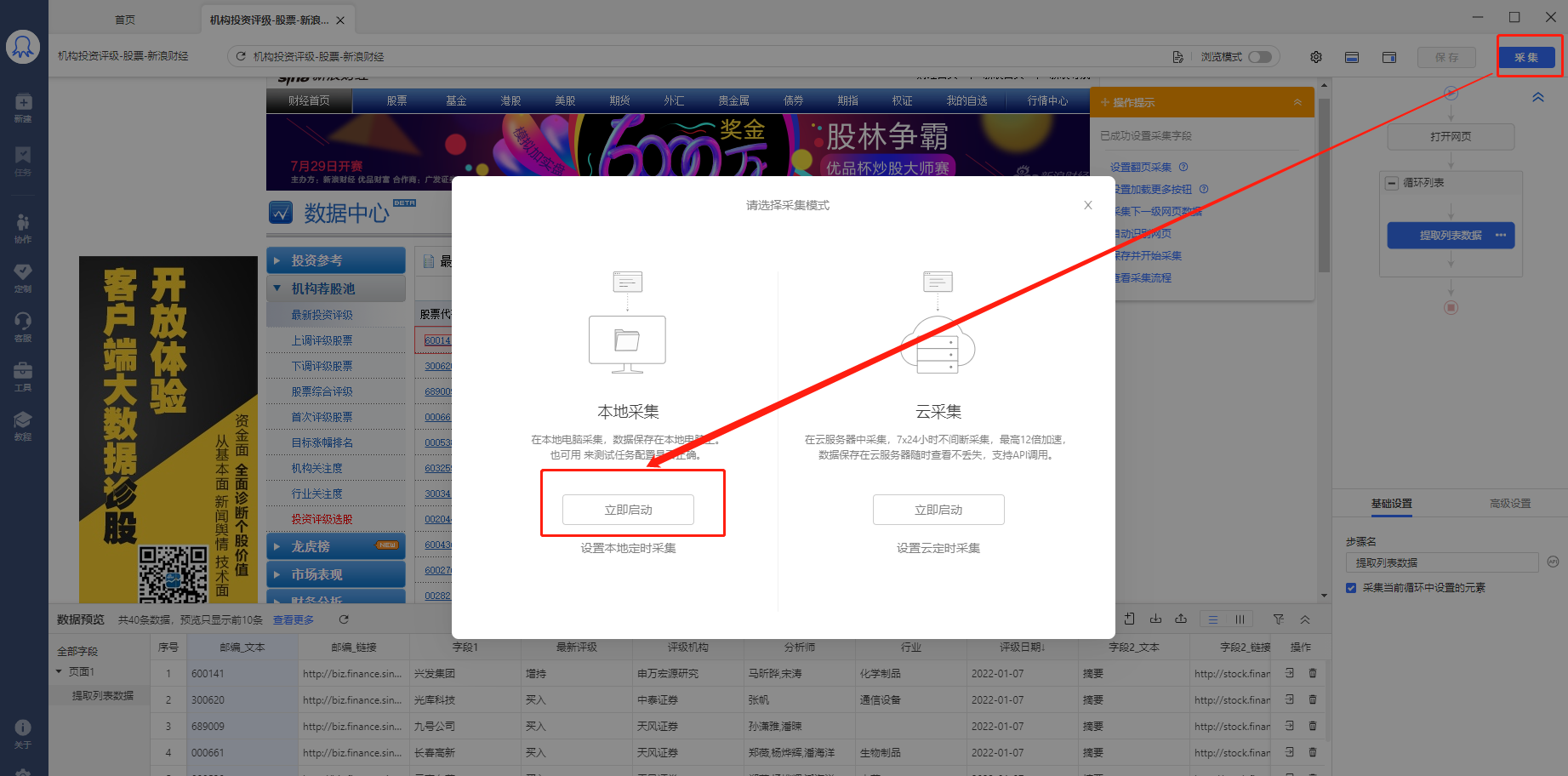
2、采集完成后,选择合适的导出方式导出数据。支持导出为Excel、CSV、HTML。这里导出为Excel。数据示例:
作者:西瓜
编辑:Aisling

文章评论