
很多用户在制作规则的时候,可能会遇到总是在一二页循环提取数据,而不会转到第三页的情况,这其实是由于Xpath定位不好导致的,我们需要通过修改Xpath来解决这个翻页问题。
在出现这个问题的时候,我们可以直接在流程里面找到问题所在,下面的规则是直接按照新手入门的步骤做的。
示例网址:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E5%A4%A7%E6%95%B0%E6%8D%AE&fenlei=256&oq=%25E5%2586%25AC%25E5%25A5%25A5%25E4%25BC%259A&rsv_pq=834522bb00017899&rsv_t=46e2I%2F550HGI44YjdOVPdp9vLKx9Fdy9gibwppjeYk%2BdhpRulDesPJQJP3A&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=9&rsv_sug1=6&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=1227&rsv_sug4=452935
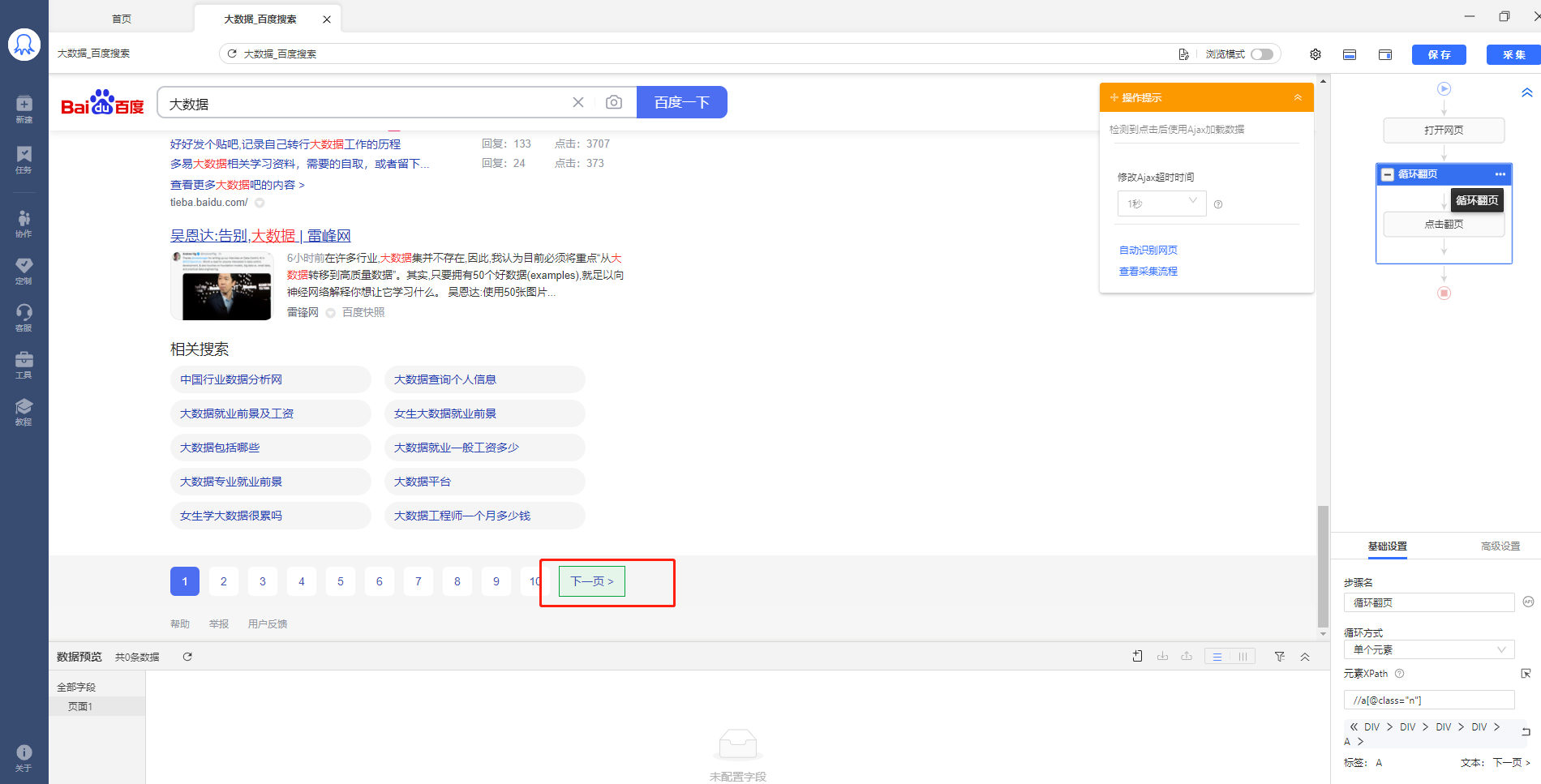
如上图,在点击循环的时候可以看到循环的是下一页按钮,我们可以直接在流程里选择点击翻页,这时八爪鱼下面的浏览器会直接跳到第二页:
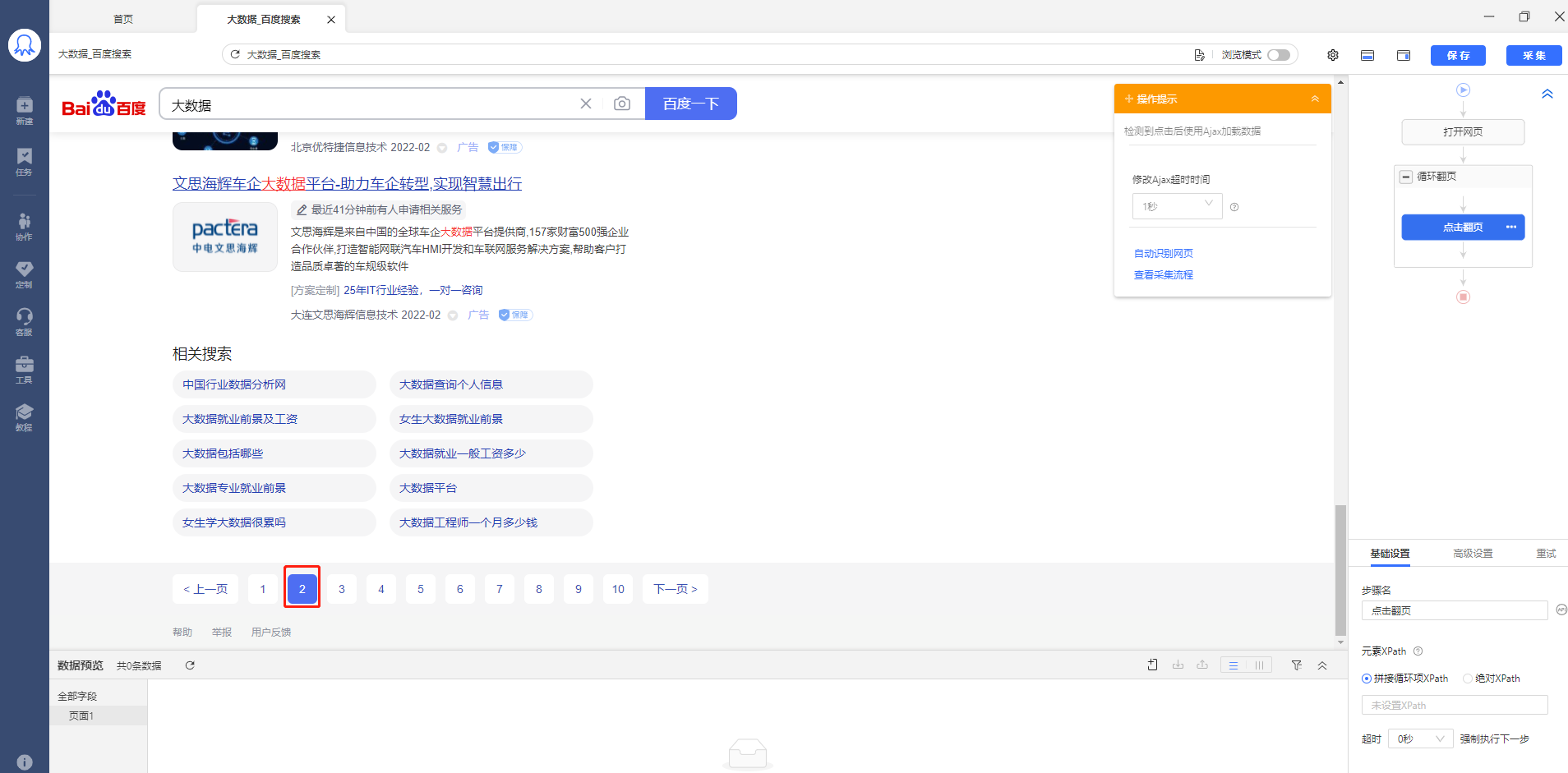
这个时候我们再点击流程图里面的循环,可以看到循环列表已经变成了上一页,这样系统再点击翻页的时候就会直接跳回第一页,提取第一页的数据,如此一直重复循环:
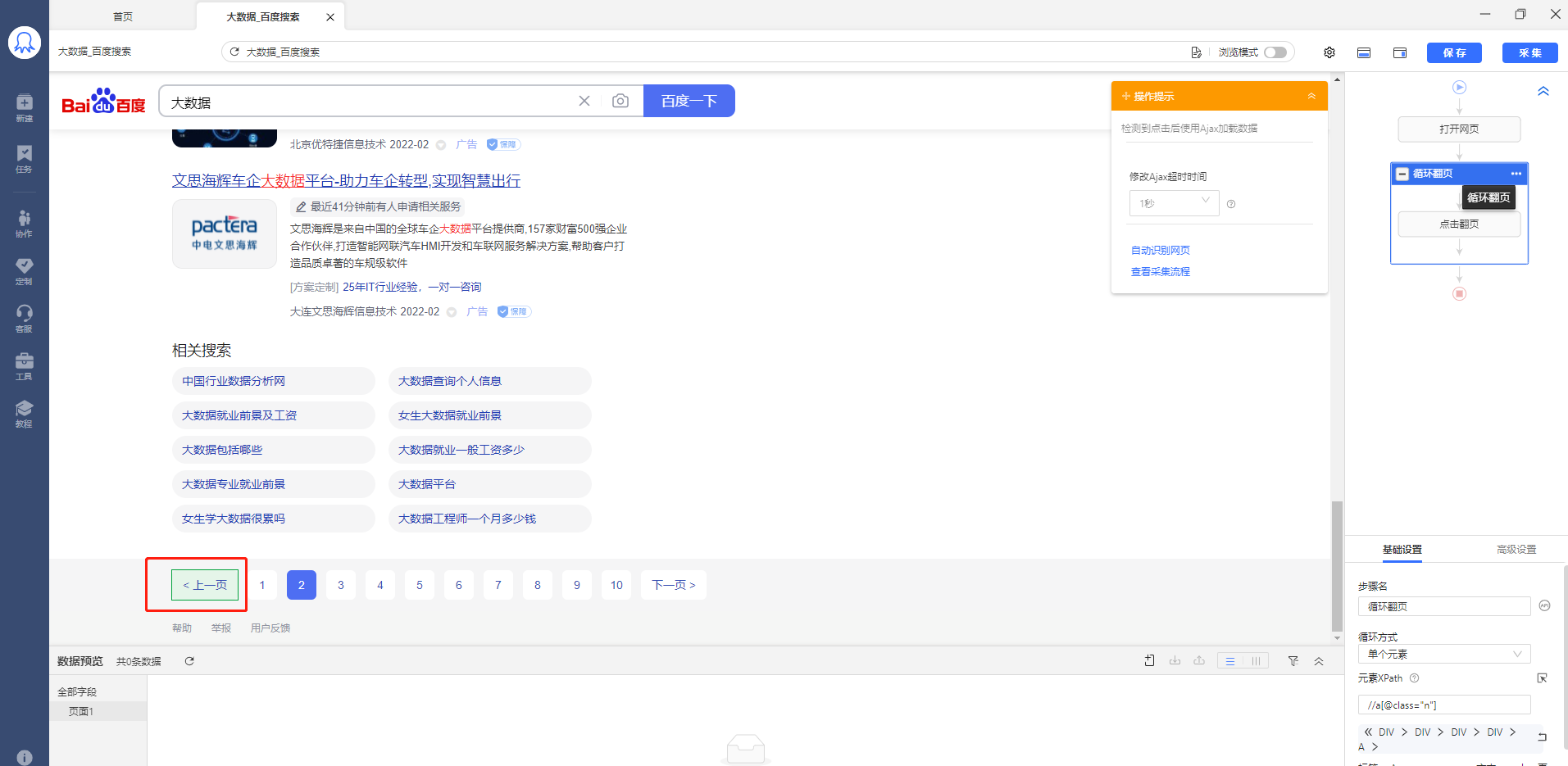
在循环里面的高级选项下方,可以看到下一页的XPath如下图所示:
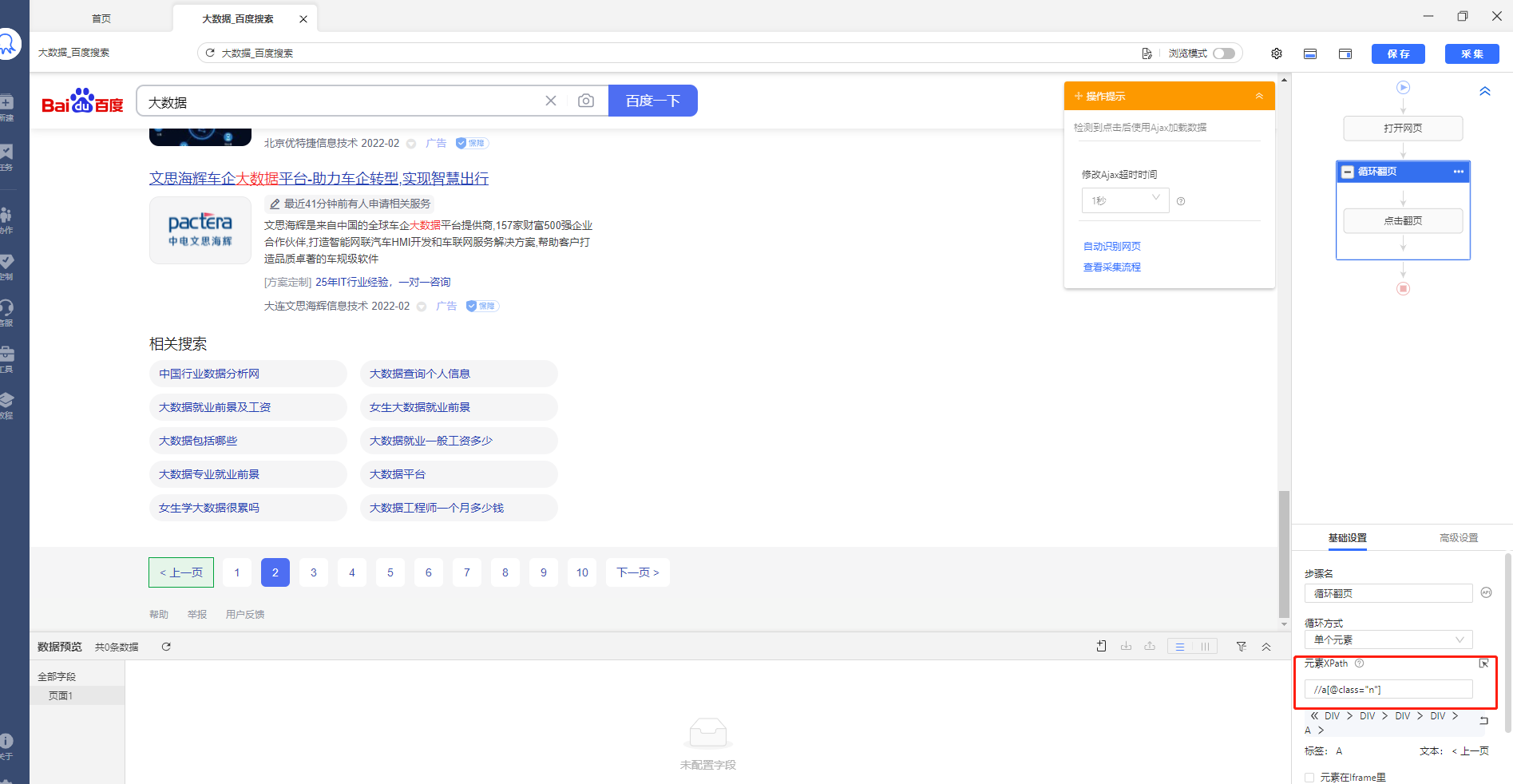
我们把这个XPath复制到火狐里面去,发现在第一页是的确可以定位下一页的,但是在第二页就变了,可以看到这个XPath在火狐里面上一页和下一页都定位了,因为八爪鱼自动识别的都是当前页面的XPath,系统没有翻到第二页不知道第二页的情况,所以我们翻页的XPath只有在第一页里面是正常的:
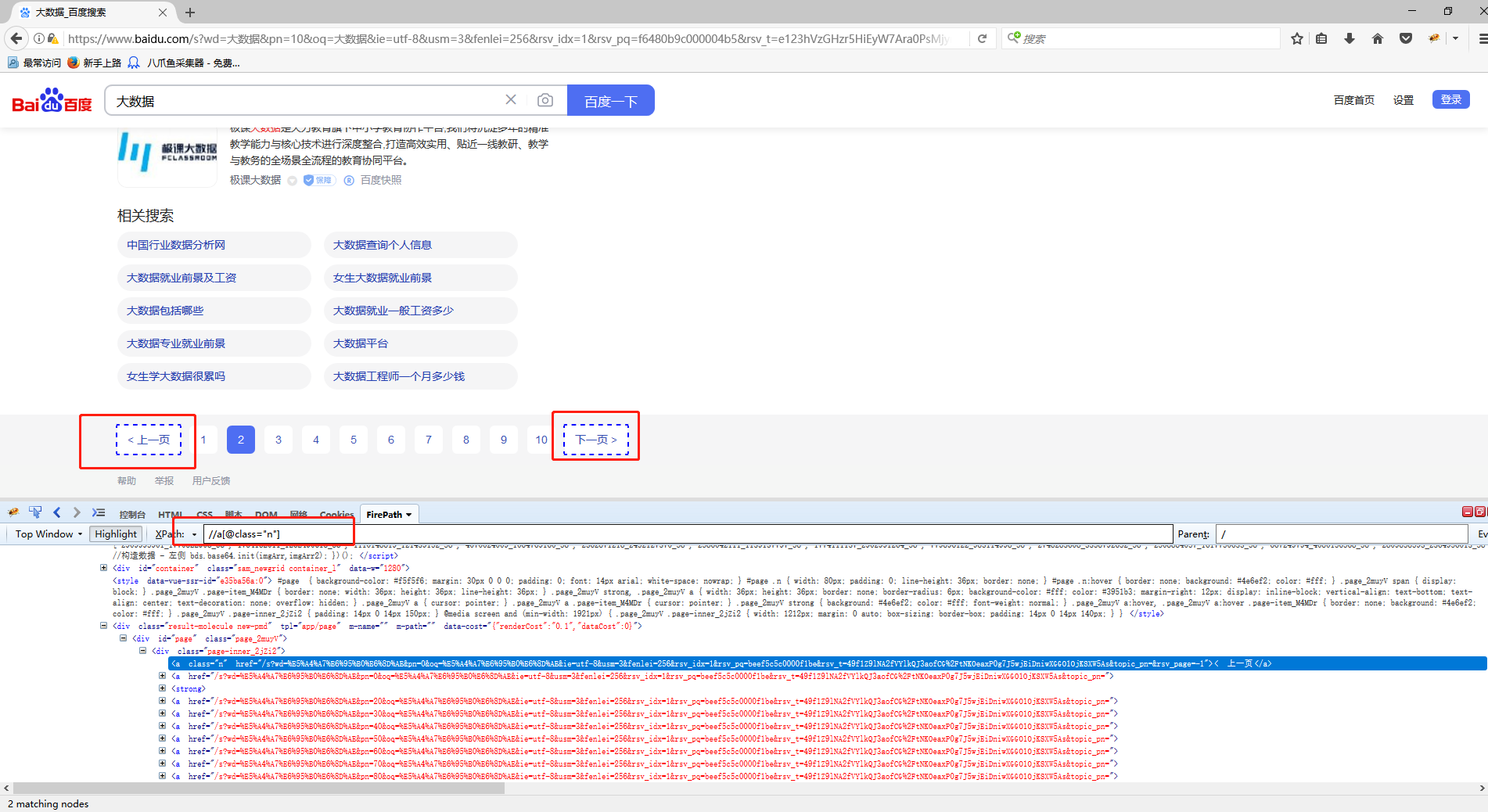
再看一下火狐浏览器里面的源码,在第二页里面这个XPath对应的不正确,直接把上一页和下一页都对应到了,所以我们需要通过修改XPath来正确定位下一页:

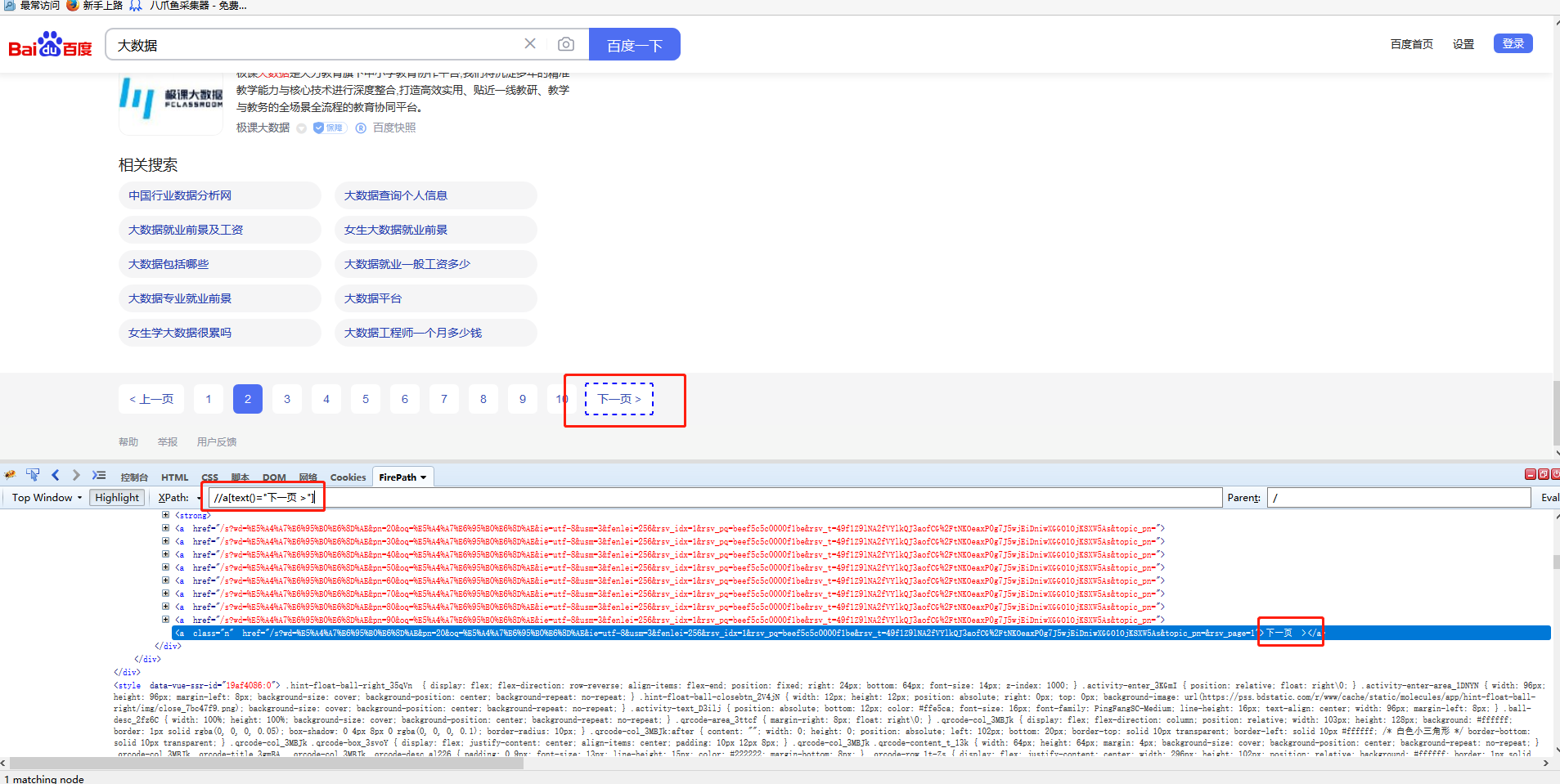
手动在火狐里面直接写,可以看到这个网页的下一页特点的,我们直接可以用text()函数,前面在XPath入门2里面给大家介绍过这个函数的意思,是一个文本函数,直接可以定位源码里面包含的文本,在火狐里面写成//A[text()='下一页']即可,然后将这条XPath再复制到八爪鱼里面。

文章评论