
有些网站可能我们用系统做好的规则在采集的时候可能明明已经采集最后一页了,就是不停止,一直在最后一页循环采集,这种情况其实是由于Xpath定位不对导致的,我们需要通过修改Xpath来解决这个翻页问题。
在出现这个问题的时候,我们可以直接在流程里面找到问题所在,下面的规则是直接按照新手入门的步骤做的(列表循环-翻页循环):
此教程引用的示例网址:http://www.gzebpubservice.cn/dlzbgg/index_590.htm
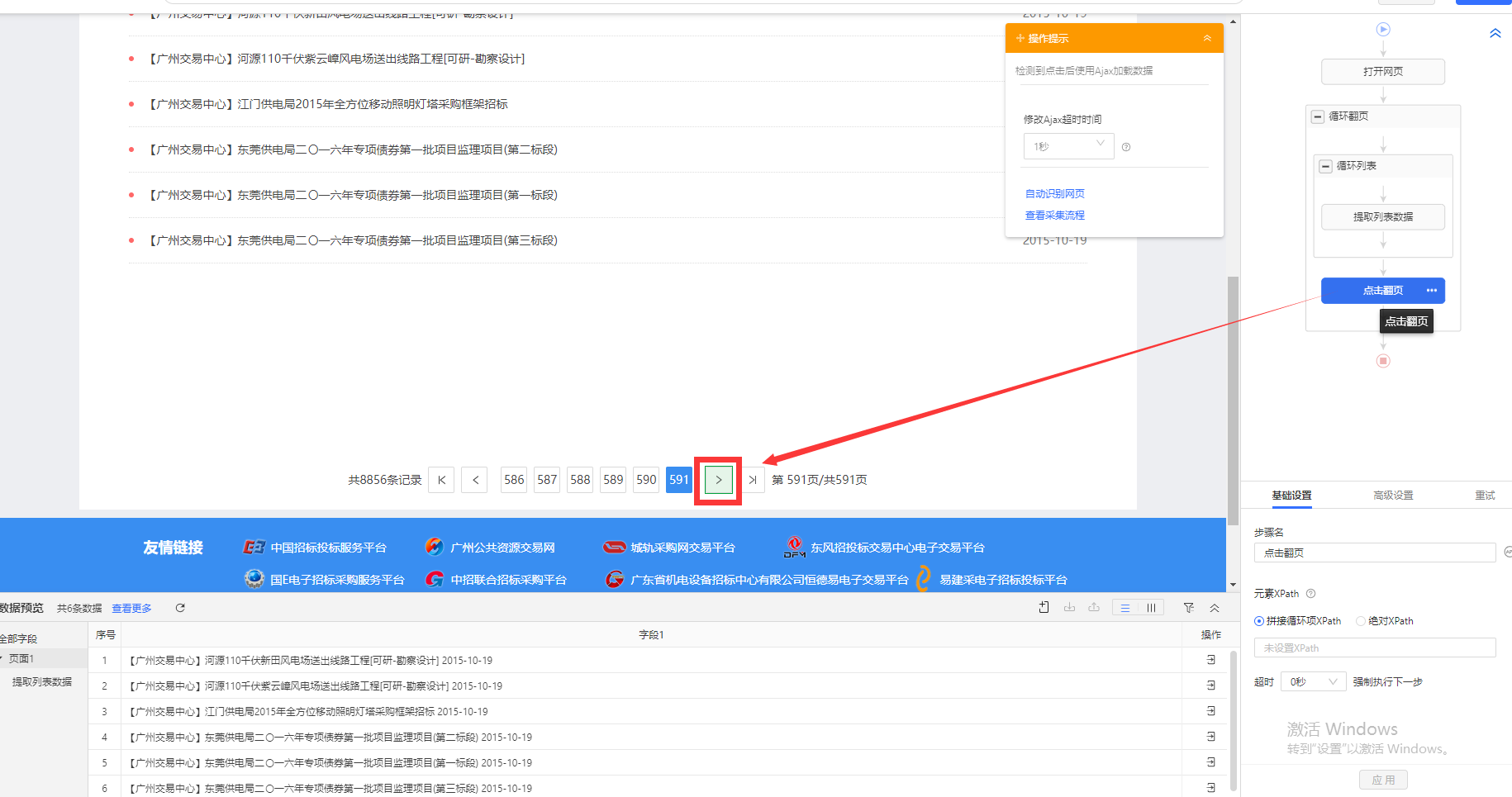
如上图中,浏览器中要采集的数据已经在最后一页了,可是我们在循环列表中依旧能找到下一页的按钮,代表一直都可以点击这个按钮进行采集,循环是结束不了的。那么我们点开循环列表的高级设置按钮,可以看下一页的Xpath如下图所示:
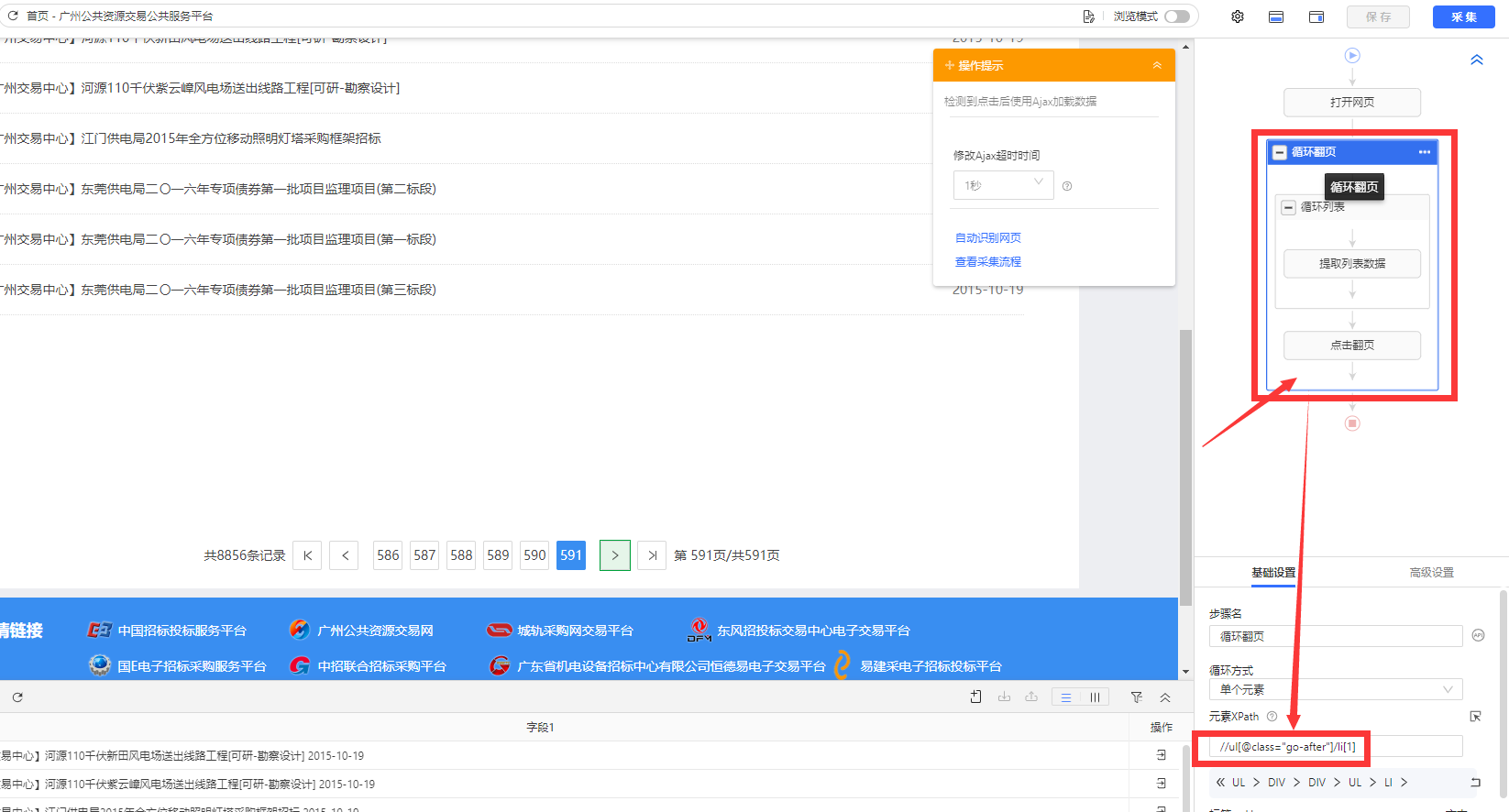
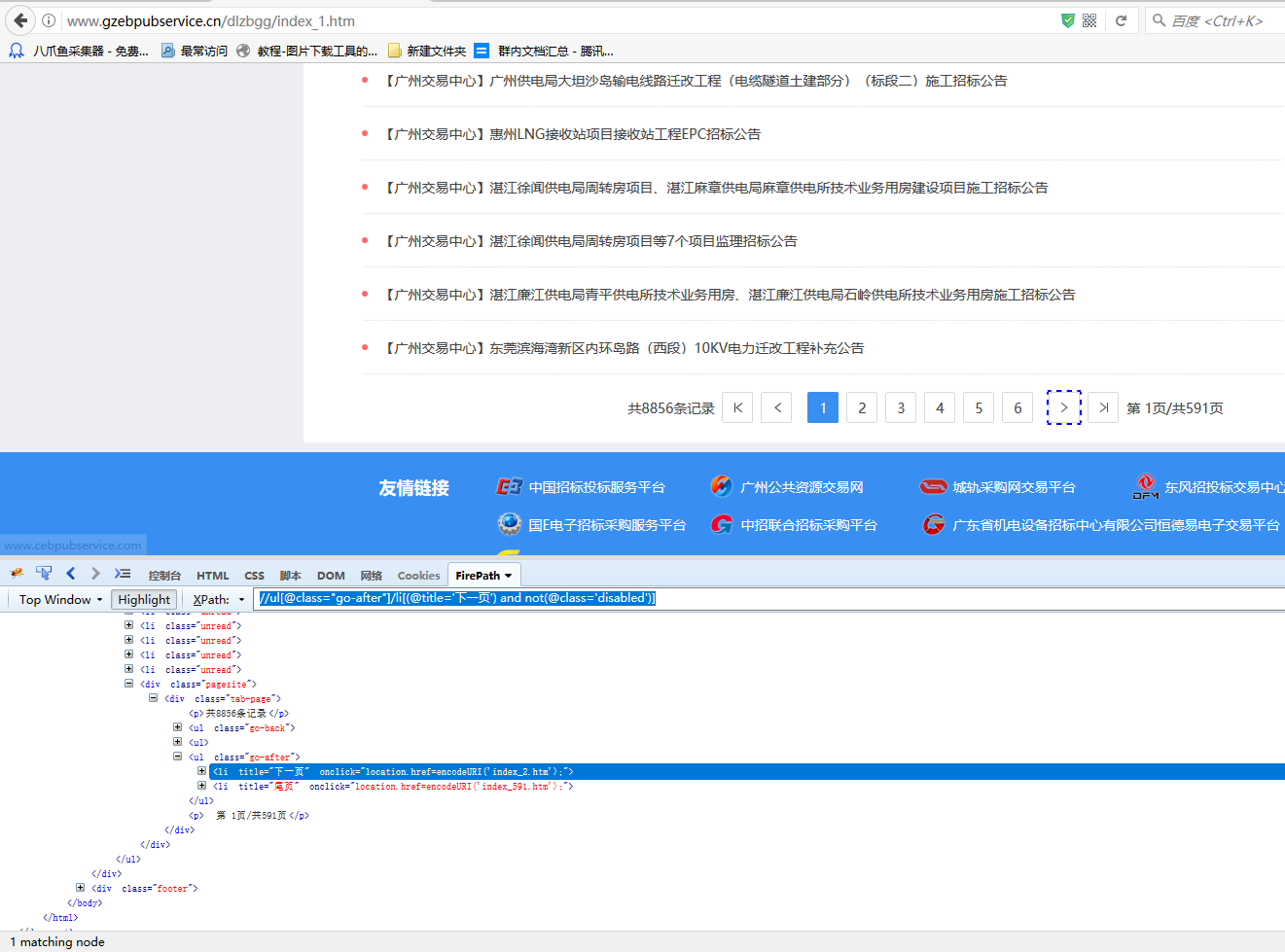
我们把这个Xpath复制到火狐里面去,发现在第590页等其他页面是的确可以定位到下一页的,并且可以看到这个Xpath在火狐里面每一页都能定位。那么我们看一下第590页和最后一页里面源码的区别:
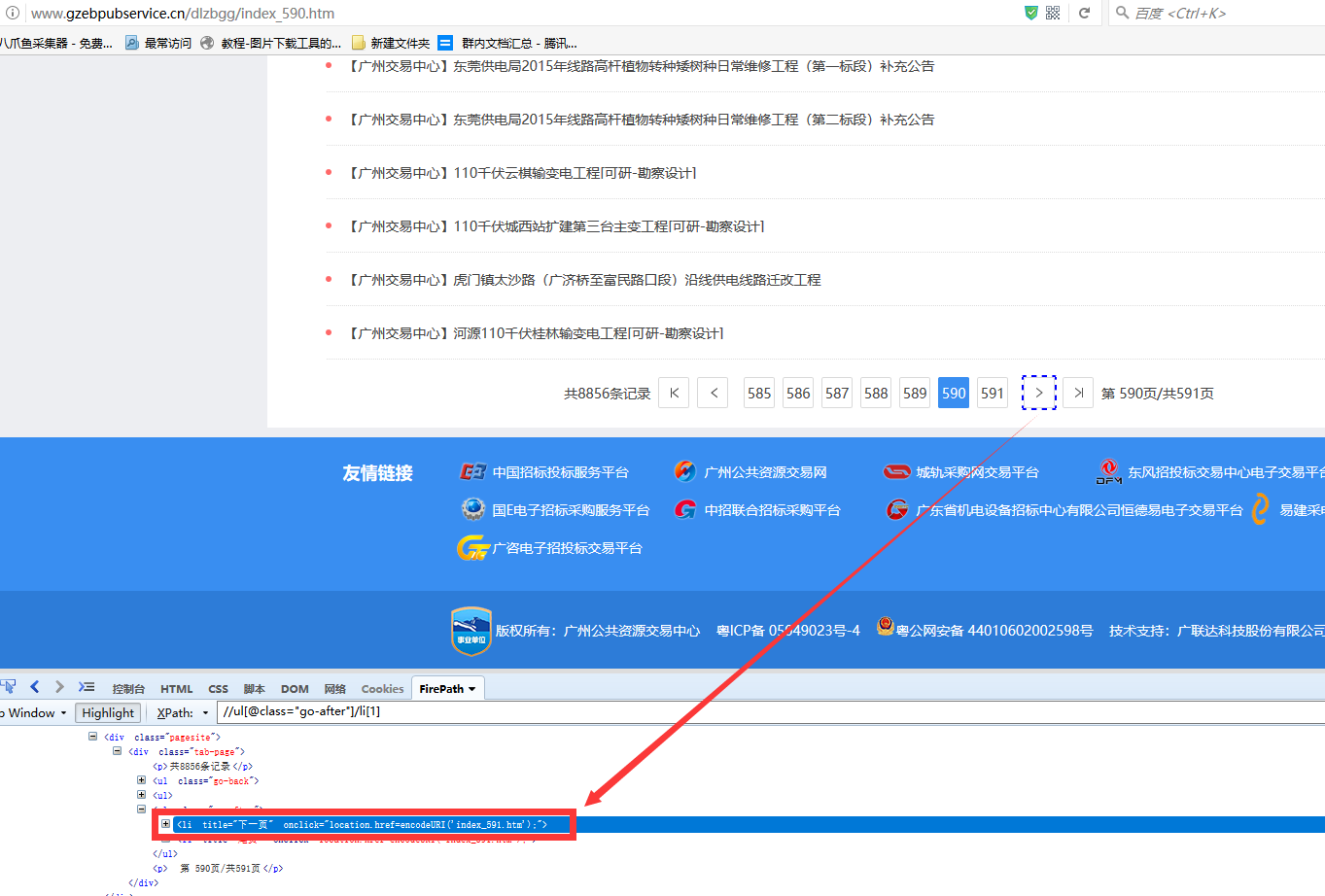
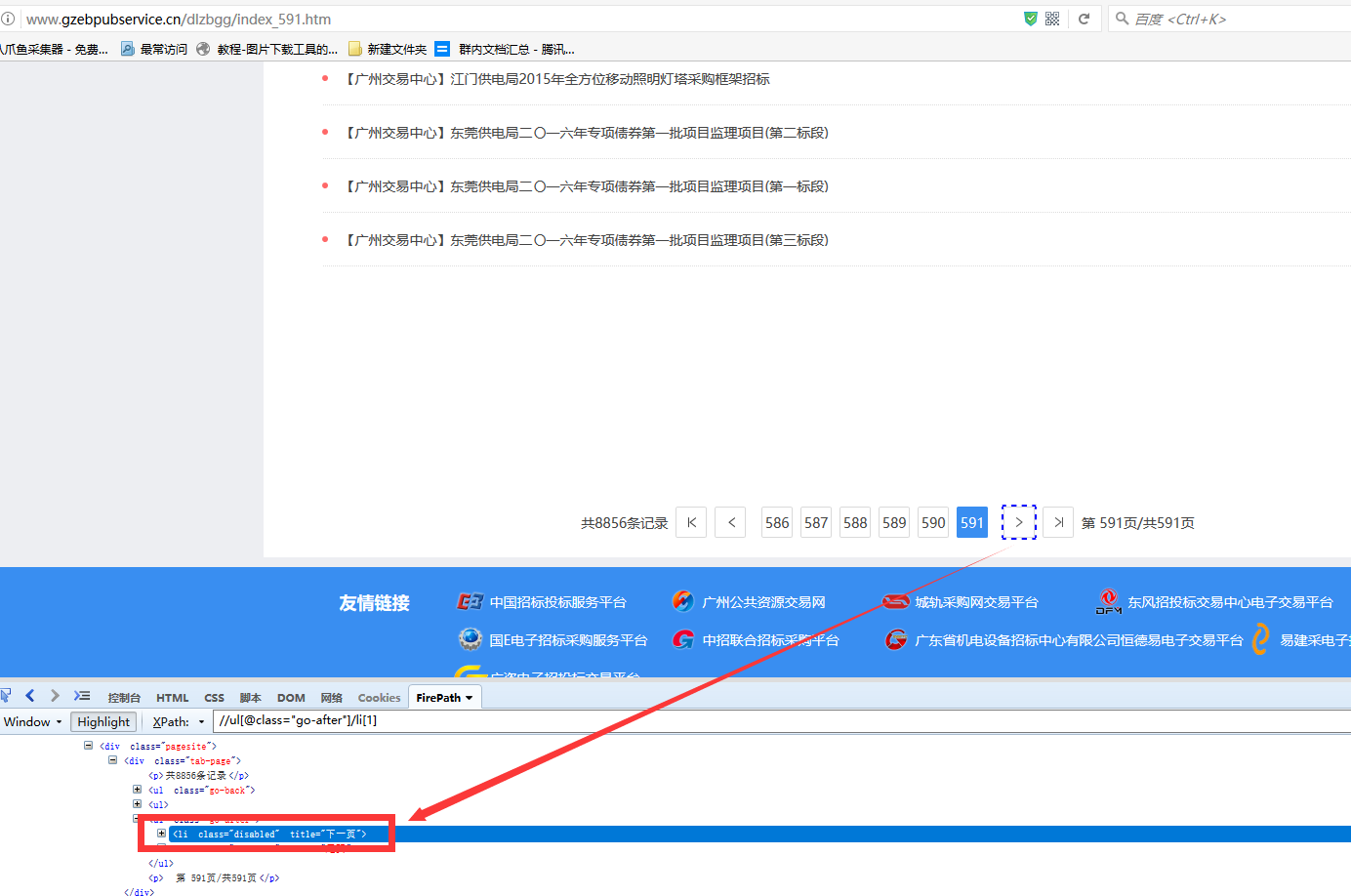
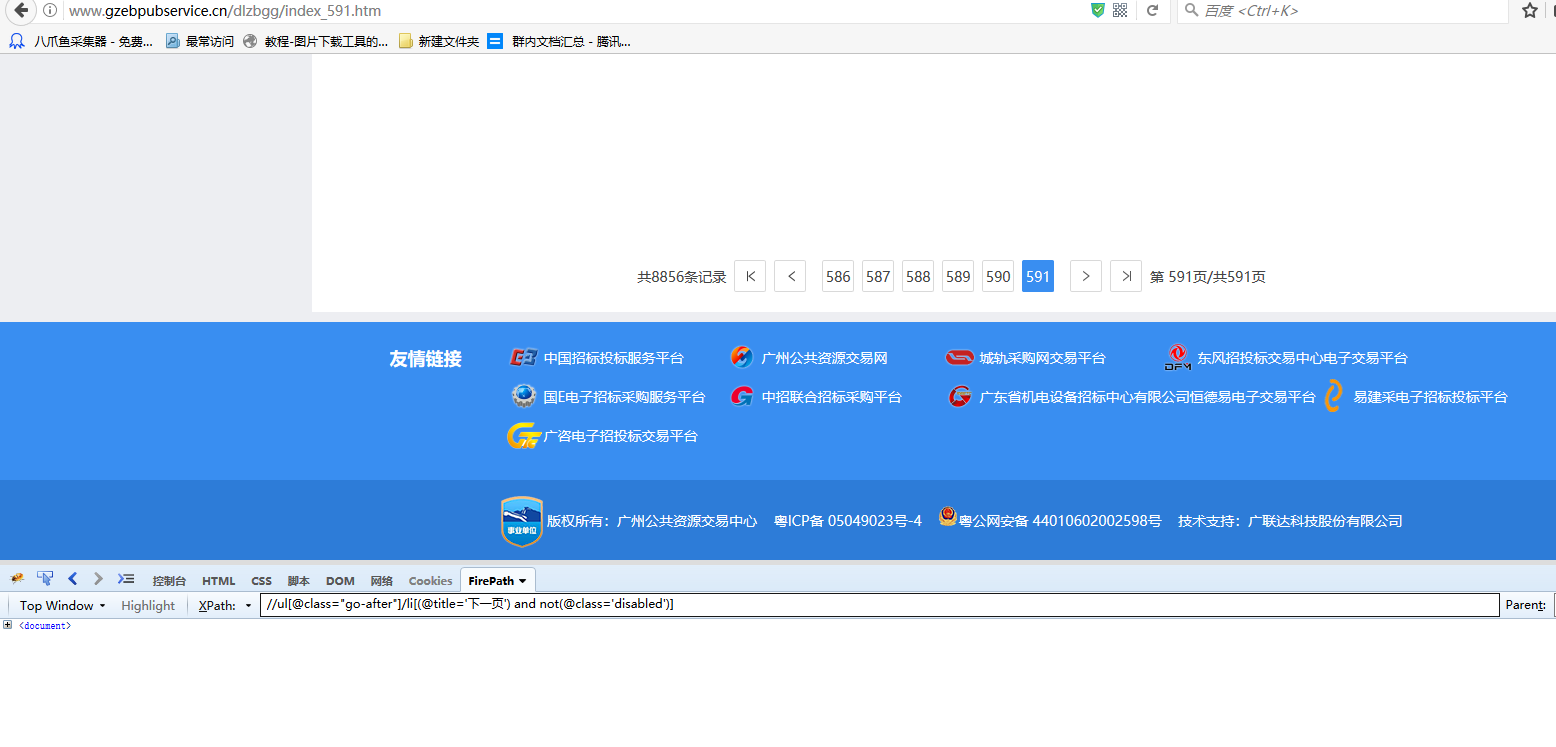
可以看到第590页和最后一页里面,第590页是没有class属性的,而最后一页的下一页是有一个class属性的,并且都有一个共同属性就是title='下一页',现在我们的需求是前面几页的下一页能正确定位,但是最后一页是不需要的,这样可以直接用class属性来区别,手动在火狐里面直接写,只需要将li里面的属性改为li[(@title='下一页') and not(@class='disabled')],然后将//ul[@class="go-after"]/li[(@title='下一页') and not(@class='disabled')]这条Xpath再复制到八爪鱼里面。
在火狐里面调试可以看到,第590页正常定位到了下一页,最后一页定位不到下一页了
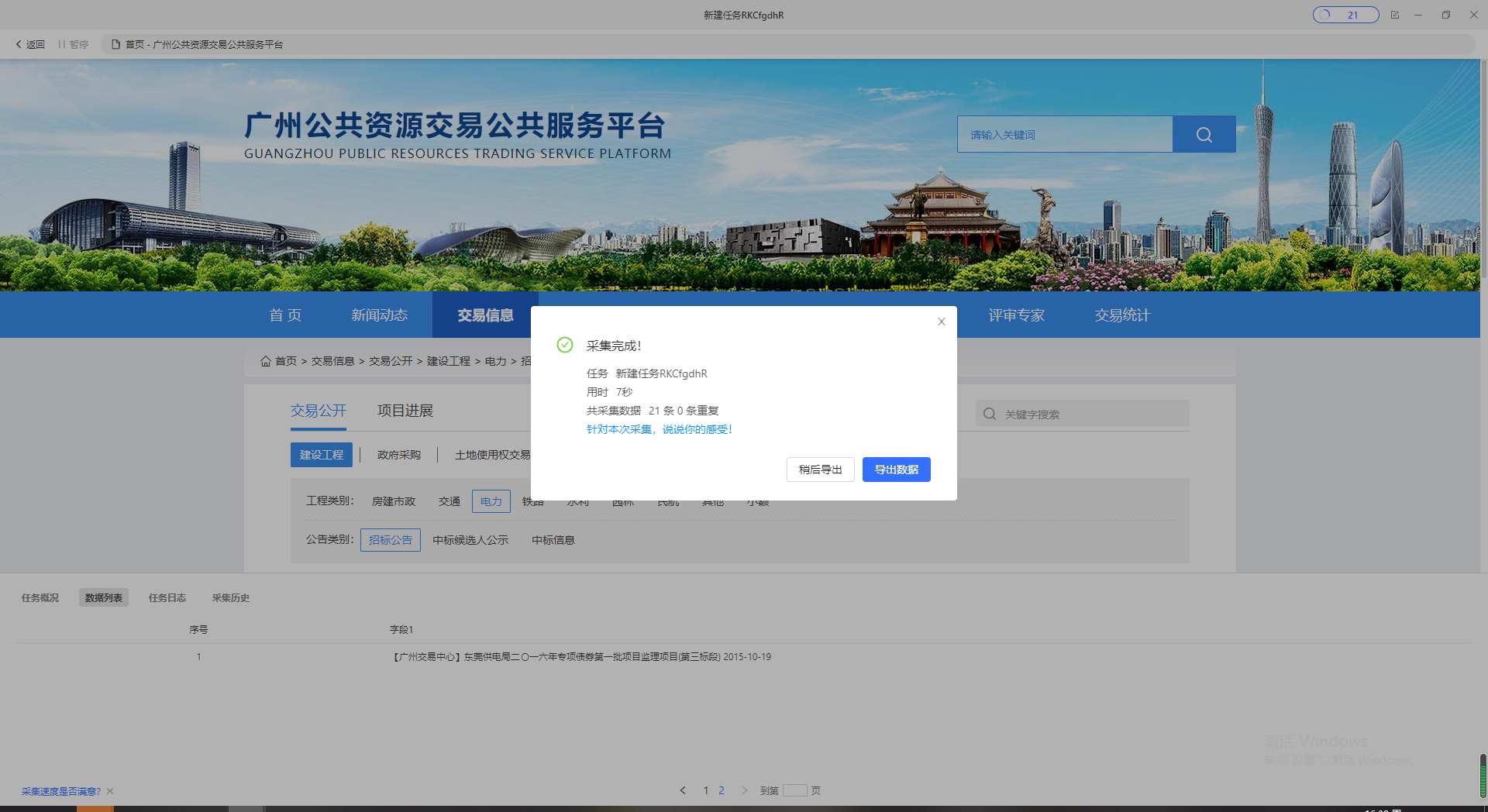
配置完成之后单机采集可以看到规则能正常完成。

文章评论