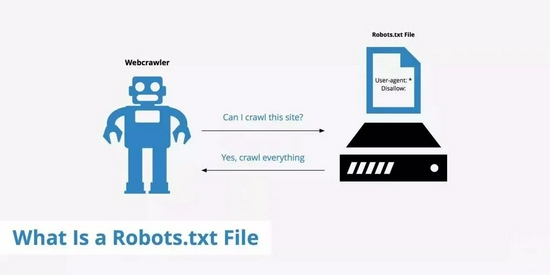
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 Robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个Robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 网络爬虫,也称为Web爬虫或网络蜘蛛,是一种自动化的程序或脚本,被设计用来浏览互联网,以收集信息、数据或执行特定任务。这些任务可以包括搜索引擎索引、数据挖掘、价格比较、内容抓取、自动化测试等等。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 数据清洗,又称数据预处理或数据净化,是数据分析和挖掘过程中的一个重要步骤。它涉及识别、校正和移除数据集中的不准确、不完整、冗余或不一致的部分,以确保数据质量和可靠性。数据清洗的主要目标是使数据适合进一步分析和建模,以提高分析的准确性和可信度。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 数据抓取,也被称为网络爬虫、网页抓取、数据挖掘或网络数据采集,是指自动从互联网或计算机网络上提取信息、数据和内容的过程。这个过程通常通过编写计算机程序来实现,这些程序被称为爬虫或抓取器。


后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 IP地址(Internet Protocol Address)是一种用于在计算机网络中标识和定位设备的数字标识符。它允许网络上的设备相互通信和传输数据。IP地址是互联网中的基本构建块之一,允许数据在全球范围内进行路由和传输。

后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。


后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。 简介 User Agent是HTTP请求头中的一部分,它是一个字符串,用于标识发起HTTP请求的用户代理程序(通常是浏览器或应用程序)的信息。User Agent字符串包含了关于用户代理程序的详细信息,如应用程序的名称、版本、操作系统、硬件类型、浏览器类型和版本等。

